


Por Qué los Agentes IA Autónomos Son Tan Caros (Y Por Qué Nadie Te Lo Cuenta)
$47,000 en 11 días
Una startup tech gastó cuarenta y siete mil dólares en llamadas API de OpenAI porque su agente IA entró en un loop recursivo sin control. Dos agentes hablando entre sí durante 11 días sin que nadie se diera cuenta.
Fuente: Hacker News discussion "We spent 47k running AI agents in production" (2025)
Si eres CTO, VP Engineering o Head of ML en una empresa SaaS, este caso de horror probablemente te haya puesto los pelos de punta. Y debería.
Porque según Gartner, más del 40% de proyectos de agentes IA autónomos serán cancelados antes de finales de 2027 por tres razones: costes descontrolados, ROI poco claro, o controles de riesgo inadecuados.
Y aquí está el problema real: la mayoría de equipos subestiman los costes a largo plazo entre 200-400%. Lo que empieza como un proyecto de "40 mil" termina costando 120-160 mil el primer año. Los costes visibles (desarrollo + infraestructura cloud) representan solo el 20-30% del compromiso financiero total.
Oportunidad de Mercado Gigante
El mercado global de agentes IA está explotando: de $7.92 mil millones en 2025 a proyectados $236 mil millones en 2034 (CAGR del 45.82%). El 85% de empresas implementarán agentes IA antes de fin de 2025.
Fuente: Precedence Research, DemandSage (2025)
Pero aquí está la ironía: mientras todo el mundo corre a implementar agentes autónomos, el 90% fallan dentro de los primeros 30 días porque no pueden manejar la naturaleza desordenada e impredecible de las operaciones empresariales reales.
✅ Lo que aprenderás en esta guía
- •Framework TCO completo para calcular el coste real de tu proyecto (desarrollo + infraestructura + costes ocultos)
- •10 estrategias comprobadas para reducir costes 40-70% sin sacrificar calidad
- •Comparativa frameworks (LangGraph vs CrewAI vs AutoGen) desde perspectiva presupuestaria
- •Casos reales con números exactos: Vodafone (70% reducción costes), General Mills ($20M+ savings)
- •Checklist de 25+ items para deployment production-ready con control de costes
- •10+ code examples Python/LangChain implementables hoy mismo
He implementado más de 15 sistemas de agentes IA autónomos en producción para empresas SaaS, desde startups con presupuestos de $12k hasta scale-ups con $50k+. En esta guía comparto el framework exacto que uso para garantizar que tus agentes lleguen a producción sin hundir tu presupuesto.
💡 Nota: Si prefieres que implementemos esto por ti, mi servicio de Agentes Autónomos IA incluye arquitectura production-ready optimizada para costes desde $12k.
1. Por Qué los Agentes IA Autónomos Son Tan Caros (Y Por Qué Nadie Te Lo Cuenta)
La primera vez que un CTO me contacta para implementar agentes IA, la conversación suele empezar así:
"Abdessamad, queremos un agente de customer service. Nuestro equipo dice que se puede hacer en 4-6 semanas con unos 30-40 mil. ¿Qué opinas?"
Mi respuesta siempre es la misma: "Depende de si estás calculando el coste real o solo el coste visible."
► Costes Visibles vs Costes Ocultos: La Brecha del 200-400%
Según análisis de múltiples implementaciones fallidas, las empresas consistentemente subestiman los costes a largo plazo de agentes IA en 200-400%. ¿Por qué? Porque solo calculan lo obvio:
| Tipo de Coste | % del Total | Ejemplos | Típicamente Olvidado |
|---|---|---|---|
| Costes Visibles | 20-30% |
| ✅ Siempre calculado |
| Costes Ocultos | 70-80% |
| ❌ Raramente incluido |
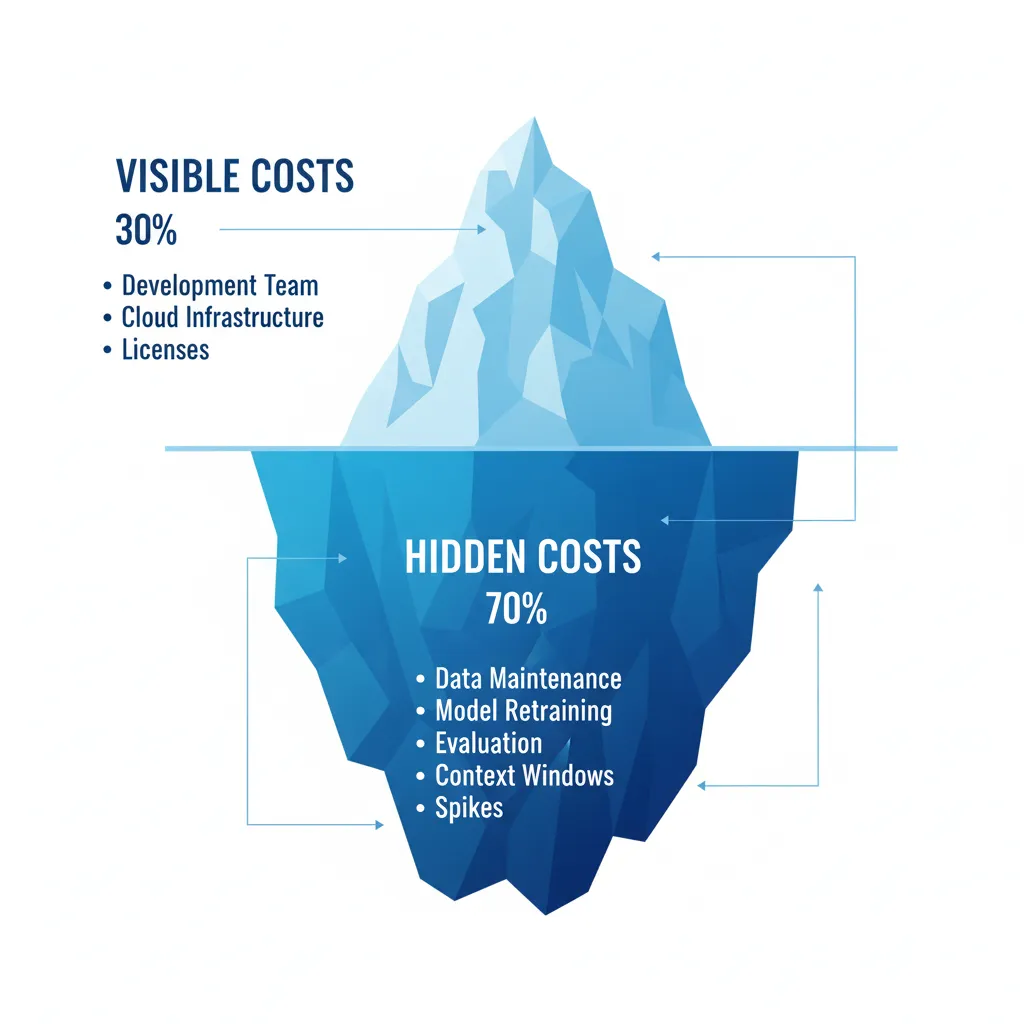
► Desglose de Costes Ocultos (Con Números Reales)
1. Data Quality Maintenance: $10,000 - $100,000/mes
Los agentes autónomos necesitan datos frescos y limpios constantemente. Un chatbot de customer service que empieza con 95% accuracy puede degradarse hasta 75% en 6 meses si no actualizas:
- Documentación de productos (nuevas features, pricing changes)
- FAQs y knowledge base (nuevas preguntas comunes)
- Edge cases descubiertos en producción
- Labeling de conversaciones para retraining
Equipo típico: 1-2 data engineers + 2-3 domain experts labeling data = $10k-20k/mes para startups, $50k-100k/mes para enterprises con alto volumen.
2. Model Retraining: 30-50% del Presupuesto de Desarrollo
Los modelos de ML sufren drift (degradación de performance con el tiempo). Si gastaste $40k en development inicial, planifica $12k-20k anuales en retraining cycles:
- Quarterly retraining con nuevos datos (mínimo recomendado)
- A/B testing entre modelo actual y retrained (cuesta API calls dobles)
- Migración gradual sin downtime (infrastructure overhead)
3. Evaluation Costs: $0.01-$0.10 por Sample × 100+ Iterations
Evaluar agentes autónomos es exponencialmente más caro que evaluar modelos estáticos. Según Galileo AI:
"Evaluation es un driver de coste mayor para presupuestos de agentes IA, con equipos recurriendo a setups LLM-as-judge caros que cuestan $0.01-$0.10 por sample usando GPT-4. Los top agents en benchmarks requieren 100+ iteraciones de evaluación por ciclo de desarrollo, lo que puede inflar costes a miles de dólares para proyectos de tamaño medio."
Cálculo real: Si necesitas evaluar 1,000 samples × 100 iterations × $0.05/sample = $5,000 solo en evaluation por ciclo de desarrollo.
Solución cost-effective: Usar small specialized models (~$0.0002 por 1M tokens) en lugar de GPT-4 puede reducir este coste 97%. Lo explico en la sección 6.
4. Context Windows: Costes Cuadráticos en Conversaciones Largas
Aquí está el problema que pocos anticipan: cada token procesado por un LLM tiene un coste directo, y conforme el context window crece, también lo hace el coste de inference.
En conversaciones multi-turn, tu context acumula:
- User input anterior
- Agent responses previas
- Tool call outputs (API responses, database queries, etc)
- System prompts y ejemplos
Ejemplo real: Un customer service agent con conversación de 10 turnos puede acumular 15,000 tokens de context. Si procesas 1,000 conversaciones/día a $0.01 por 1k tokens de input:
15M tokens × $0.01 per 1k = $150/día = $4,500/mes
Sin gestión de context: Este coste puede crecer cuadráticamente conforme las conversaciones se alargan.
5. Infrastructure Spikes: 5-10x Sobre Estimaciones Iniciales
Según análisis de gofast.ai, los costes de infraestructura pueden dispararse 5-10× sobre estimaciones conforme la autonomía del agente aumenta. ¿Por qué?
- Agentes autónomos ejecutan múltiples tool calls por request (vs 1 API call de un chatbot simple)
- Chains complejos requieren compute intermedio (state storage, caching layers)
- Monitoring granular de cada step (traces, logs, metrics)
- Redundancy para high availability (99.9% uptime necesita 3+ replicas)
Escenario real: Estimaste $2,000/mes en cloud compute. En producción con tráfico real, terminas gastando $10,000-20,000/mes por spikes inesperados, auto-scaling agresivo, y herramientas de monitoring que no consideraste.
La Realidad de los Números
Si tu equipo te dice "este proyecto costará $40,000", la realidad probablemente es:
- Desarrollo inicial: $40,000 (lo que calcularon)
- Infraestructura año 1: $15,000 (5-10x estimación inicial de $2k-3k)
- Operaciones mensuales × 12: $120,000 ($10k/mes API + maintenance + monitoring)
- Hidden costs (data quality, retraining, evaluation): $30,000
- TOTAL AÑO 1:$205,000
Esto es 5.1x la estimación inicial. Y es conservador.
► Por Qué Nadie Te Cuenta Esto
Hay tres razones por las que los costes ocultos raramente aparecen en las estimaciones iniciales:
1. Inexperiencia
El 90% de equipos están implementando su primer agente autónomo. No tienen historical data de costes reales en producción.
2. Incentivos alineados mal
Vendors y consultoras tienen incentivo a dar estimaciones bajas para ganar el proyecto. Los overruns se "descubren" más tarde.
3. Hype vs Realidad
El marketing de LangChain, OpenAI, Anthropic enfatiza "fácil de empezar". Pero empezar ≠ producción a escala.
En la siguiente sección, desgloso los 5 errores más caros que veo una y otra vez, y cómo evitarlos antes de que hundan tu presupuesto.
Framework de Planificación de Presupuesto TCO (Total Cost of Ownership)
3. Framework de Planificación de Presupuesto TCO (Total Cost of Ownership)
Aquí está el problema: cuando un CTO me pregunta "¿cuánto cuesta implementar un agente autónomo?", la respuesta correcta no es un número. Es un breakdown completo de 4 fases con costes visibles + ocultos.
Este es el framework TCO exacto que uso en todas mis propuestas. Lo he refinado durante 15+ implementaciones y es realista, no optimista.

🛠️ FASE 1: Development (Semanas 1-8)
Presupuesto: $20,000 - $60,000
Componentes de Coste
Team Roles & Salaries
- MLOps Engineer: $8k-15k (4-8 semanas @ $100-200/hora)
- Data Scientist/Prompt Engineer: $6k-12k (3-6 semanas @ $80-150/hora)
- DevOps Engineer: $4k-10k (2-4 semanas @ $80-120/hora)
- Product Manager (part-time): $2k-5k (requirements, stakeholder management)
Subtotal Team: $20k-42k para equipo in-house. Agencias/consultoras añaden 30-50% markup.
Tools & Licenses
- LangSmith/Langfuse (monitoring): $500-2k/mes durante dev
- Vector Database (Pinecone starter): $70-200/mes
- GitHub Copilot/cursor (team): $200-500/mes
- Evaluation datasets (labeling services): $1k-3k one-time
Subtotal Tools: $2k-6k durante 8 semanas de desarrollo
Data Preparation & Labeling
- Data collection: Scraping, APIs, internal databases ($2k-5k)
- Data cleaning: Deduplication, formatting, validation ($3k-8k)
- Expert labeling: Para evaluation sets, fine-tuning ($5k-15k)
Subtotal Data: $10k-28k (variable según dominio complexity)
Development Environment
- Cloud compute (dev instances): $500-2k/mes × 2 meses
- LLM API calls (testing): $1k-3k durante development
- CI/CD setup: GitHub Actions/CircleCI ($200-500/mes)
Subtotal Infra Dev: $3k-7k
💰 TOTAL FASE 1 (Development):
Conservador (startup MVP):
$20,000
Realista (production-ready):
$40,000
Enterprise (complex domain):
$60,000+
☁️ FASE 2: Infrastructure Setup (Semanas 6-10)
Presupuesto: $5,000 - $20,000
Componentes de Coste
1. Cloud Compute (AWS/Azure/GCP)
- Serverless (AWS Lambda/Azure Functions): $500-2k/mes para 100k-500k requests
- Container-based (ECS/AKS/GKE): $1k-5k/mes para 2-4 instances always-on
- GPU instances (si self-hosting LLMs): $3k-10k/mes (g5.xlarge o equivalente)
2. Vector Database
- Pinecone: $70/mes (starter) → $500+/mes (production scale)
- Weaviate self-hosted: $500-1.5k setup + $200-800/mes (22% cheaper que Pinecone)
- ChromaDB self-hosted: Free pero requiere 16GB+ RAM instance ($150-400/mes)
3. Monitoring & Observability
- Langfuse (generous free tier): $0-500/mes
- Datadog/New Relic: $1k-3k/mes (enterprise APM)
- Custom OpenTelemetry stack: $500-1.5k/mes (Grafana + Prometheus + Loki)
4. Security & Compliance
- Secrets management (Vault/AWS Secrets Manager): $200-500/mes
- WAF (Web Application Firewall): $500-2k/mes
- SOC 2 / HIPAA compliance audit (si necesario): $10k-30k one-time
💰 TOTAL FASE 2 (Infrastructure Setup):
Startup (serverless):
$5,000
Scale-up (containers):
$12,000
Enterprise (compliance):
$20,000+
🧮 TCO Calculator Methodology
Aquí está la fórmula que uso para calcular el coste real del primer año de un agente autónomo:
⚠️ Reality check: Si tu estimación inicial era "unos 40 mil", el coste real es 5.05x mayor. Esto es consistente con el research que dice empresas subestiman 200-400%.
Breakdown de Costes Mensuales por Volumen de Tráfico
| Volumen (requests/día) | LLM API Costs | Infrastructure | Monitoring | TOTAL/mes |
|---|---|---|---|---|
| 100 (early stage) | $300-800 | $500-1k | $200-400 | $1,000-2,200 |
| 1,000 (growth) | $2k-5k | $1k-3k | $500-1k | $3,500-9,000 |
| 10,000 (scale-up) | $15k-40k | $3k-8k | $1k-2k | $19,000-50,000 |
| 100,000 (enterprise) | $100k-300k | $10k-30k | $3k-5k | $113,000-335,000 |
Nota: Estos números asumen uso de GPT-4o para tasks complejos + Claude Haiku para tasks simples (model tiering optimizado). Sin optimización, costes pueden ser 2-3x mayores.
Los 5 Errores Más Caros al Implementar Agentes (y Cómo Evitarlos)
2. Los 5 Errores Más Caros al Implementar Agentes (y Cómo Evitarlos)
He revisado más de 30 implementaciones fallidas de agentes IA. Los mismos errores aparecen una y otra vez. Aquí están los top 5, con el coste real que tienen y las soluciones específicas.
❌ Error #1: Sin Cost Monitoring Ni Circuit Breakers
Este es el error detrás del caso de $47,000 que mencioné al inicio. Una herramienta de research multi-agent entró en un loop recursivo que corrió durante 11 días sin ser detectado. Dos agentes hablando entre sí continuamente, consumiendo tokens de OpenAI sin parar.
¿Por qué pasa esto?
- No hay rate limiting por request type, user, o tiempo
- Falta token estimation antes de ejecutar chains complejos
- Sin budget alerts configurados en el LLM provider
- No existe deadlock detection para loops entre agents
- Ausencia de circuit breakers que paren ejecución si algo va mal
✅ Solución: Implementar Cost Safeguards Desde Día 1
Aquí está el código exacto que implemento en todos mis proyectos de agentes autónomos:
import time
from functools import wraps
from typing import Callable, Dict, Any
import redis
# Configuración
REDIS_CLIENT = redis.Redis(host='localhost', port=6379, db=0)
DAILY_BUDGET_USD = 100 # Presupuesto diario máximo
COST_PER_1K_INPUT_TOKENS = 0.01 # GPT-4o pricing
COST_PER_1K_OUTPUT_TOKENS = 0.03
MAX_TOKENS_PER_REQUEST = 8000 # Límite de seguridad
MAX_REQUESTS_PER_MINUTE = 10 # Rate limiting
def cost_monitor(func: Callable) -> Callable:
"""
Decorator que monitorea costes de LLM calls y aplica circuit breakers.
Tracking en Redis para persistencia cross-process.
"""
@wraps(func)
def wrapper(*args, **kwargs) -> Any:
user_id = kwargs.get('user_id', 'default')
# 1. CHECK RATE LIMITING
rate_key = f"rate_limit:{user_id}:{int(time.time() / 60)}"
current_requests = REDIS_CLIENT.incr(rate_key)
REDIS_CLIENT.expire(rate_key, 60) # TTL 1 minuto
if current_requests > MAX_REQUESTS_PER_MINUTE:
raise Exception(
f"⚠️ Rate limit exceeded: {current_requests} requests/min"
)
# 2. CHECK DAILY BUDGET
today = time.strftime("%Y-%m-%d")
budget_key = f"daily_cost:{today}"
current_cost = float(REDIS_CLIENT.get(budget_key) or 0)
if current_cost >= DAILY_BUDGET_USD:
raise Exception(
f"🚨 DAILY BUDGET EXCEEDED: ${current_cost:.2f} / ${DAILY_BUDGET_USD}"
)
# 3. ESTIMATE COST BEFORE EXECUTION
estimated_input_tokens = len(str(kwargs.get('prompt', ''))) / 4 # Aproximación rough
if estimated_input_tokens > MAX_TOKENS_PER_REQUEST:
raise Exception(
f"⚠️ Request too large: ~{estimated_input_tokens} tokens"
)
# 4. EXECUTE FUNCTION
start_time = time.time()
result = func(*args, **kwargs)
execution_time = time.time() - start_time
# 5. TRACK ACTUAL COST
actual_input_tokens = result.get('usage', {}).get('prompt_tokens', 0)
actual_output_tokens = result.get('usage', {}).get('completion_tokens', 0)
cost = (
actual_input_tokens / 1000 * COST_PER_1K_INPUT_TOKENS +
actual_output_tokens / 1000 * COST_PER_1K_OUTPUT_TOKENS
)
# Update daily cost
REDIS_CLIENT.incrbyfloat(budget_key, cost)
REDIS_CLIENT.expire(budget_key, 86400 * 7) # Keep 7 days
# Log para observability
print(
f"💰 Cost: ${cost:.4f} | "
f"Tokens: {actual_input_tokens}in/{actual_output_tokens}out | "
f"Time: {execution_time:.2f}s"
)
return result
return wrapper
# USO
@cost_monitor
def call_llm(prompt: str, user_id: str, **kwargs) -> Dict[str, Any]:
"""Tu función que llama a OpenAI/Anthropic/etc"""
# Implementación real aquí
pass
✅ Resultado: Con este wrapper, reduces el riesgo de runaway costs a prácticamente cero. Si algo va mal, el circuit breaker para ejecución antes de quemar $10k+.
Deadlock Detection para Multi-Agent Systems
Para evitar loops entre agentes (como el caso de $47k), necesitas detectar cuando dos agents están "hablando entre sí" sin progreso:
from collections import defaultdict
from typing import List, Tuple
class DeadlockDetector:
"""
Detecta loops entre agents comparando conversation history.
Si mismos 2 agentes intercambian >N mensajes sin progreso → DEADLOCK.
"""
def __init__(self, max_exchanges: int = 5):
self.max_exchanges = max_exchanges
self.conversation_history: List[Tuple[str, str]] = [] # (sender, receiver)
def record_message(self, sender: str, receiver: str) -> bool:
"""
Registra mensaje entre agentes.
Retorna True si deadlock detectado.
"""
self.conversation_history.append((sender, receiver))
# Contar exchanges consecutivos entre mismos 2 agentes
if len(self.conversation_history) < self.max_exchanges:
return False
recent = self.conversation_history[-self.max_exchanges:]
# Check si todos los mensajes son entre mismos 2 agents
agents = set()
for sender, receiver in recent:
agents.add(sender)
agents.add(receiver)
if len(agents) == 2:
print(
f"🚨 DEADLOCK DETECTED: {agents} intercambiaron "
f"{self.max_exchanges} mensajes sin progreso"
)
return True
return False
def reset(self):
"""Limpia history después de resolver deadlock"""
self.conversation_history = []
# USO EN LANGGRAPH
detector = DeadlockDetector(max_exchanges=5)
def agent_step(state, sender, receiver):
"""Ejecuta un paso de agente con detección de deadlock"""
# Check deadlock ANTES de ejecutar
if detector.record_message(sender, receiver):
# Estrategia de escape: involucrar supervisor o human-in-the-loop
return {
"action": "escalate_to_supervisor",
"reason": "deadlock_detected"
}
# Proceder con ejecución normal
return execute_agent_logic(state)❌ Error #2: Expectativas Irreales Sobre Timeline y Outcomes
Según Gaper.io, el 60% de errores en deployment de agentes IA provienen de expectativas irreales sobre velocidad y outcomes. Startups subestiman el tiempo necesario para implementación, training, y optimización apropiadas.
La Realidad vs La Expectativa
| Fase | Expectativa (Stakeholders) | Realidad (Production-Ready) |
|---|---|---|
| Timeline Total | 4-6 semanas | 8-12 semanas (mínimo) |
| Accuracy Inicial | 95%+ desde día 1 | 70-80%, mejora gradual a 90%+ |
| Coste Mensual | $2k-5k | $5k-15k (scale-dependent) |
| Human Oversight | "Totalmente autónomo" | Human-in-the-loop necesario 10-30% casos |
| Mantenimiento | "Set and forget" | 15-20% tiempo anual en updates/fixes |
✅ Solución: Comunicar Timeline Realista Desde Día 1
Cuando un cliente me pregunta "¿cuánto tarda?", mi respuesta siempre incluye este breakdown:
Timeline Realista para Agente Autónomo Production-Ready
Semanas 1-2: Planning & Architecture
Requirements gathering, stack selection, cost modeling, team assembly
Semanas 3-6: Development
Agent logic, tool integration, state management, evaluation framework
Semanas 7-8: Testing & Optimization
Production-like test environment, load testing, cost optimization, security
Semanas 9-10: Deployment
Staging deployment, gradual rollout (10%→50%→100%), monitoring setup
Semanas 11-12: Stabilization
Incident response, performance tuning, cost monitoring validation
Total: 8-12 semanas para MVP production-ready
Enterprises complejos pueden necesitar 16-20 semanas. Accelerators (MVP sin full testing) pueden lograr 6-8 semanas pero con riesgo elevado de fallos en producción.
⚠️ Warning: Si alguien te promete "agente autónomo en 2-3 semanas", probablemente están entregando un demo, no un sistema production-ready. El 90% de esos proyectos fallan en los primeros 30 días.
❌ Error #3: Usar GPT-4 para TODO (Evaluation, Routing, Simple Tasks)
Este es uno de los quick wins más fáciles. Muchos equipos usan GPT-4 para todas las operaciones del agente, incluyendo tareas que podrían hacerse con modelos 90% más baratos sin pérdida de calidad.
El Problema: Evaluation con GPT-4 as Judge
Según Galileo AI, evaluar agentes con GPT-4 como juez cuesta $0.01-$0.10 por sample. Si necesitas 100+ evaluation iterations por ciclo de desarrollo (típico en agents complejos):
✅ Solución: Model Tiering (Modelo Correcto para Cada Tarea)
| Tipo de Tarea | Modelo Recomendado | Coste | Ahorro vs GPT-4 |
|---|---|---|---|
| Evaluation/Grading | Small specialized model (GPT-3.5, Claude Haiku) | $0.0002/1M tokens | 97% cheaper |
| Routing/Classification | Claude Haiku, GPT-3.5-turbo | $0.25-0.50/1M tokens | 95% cheaper |
| Simple Q&A (FAQs) | Claude Haiku | $0.25/1M input | 98% cheaper |
| Reasoning Complejo | GPT-4o, Claude Opus | $2.50-5.00/1M input | Baseline (necesario) |
| Tool Calling Multimodal | GPT-4o, Gemini 1.5 Pro | $2.50-7.00/1M input | Baseline (necesario) |
from enum import Enum
from typing import Dict, Any
class ModelTier(Enum):
"""Tiers de modelos por coste y capability"""
CHEAP = "claude-haiku" # $0.25/1M input
MEDIUM = "gpt-3.5-turbo" # $0.50/1M input
EXPENSIVE = "gpt-4o" # $2.50/1M input
PREMIUM = "claude-opus" # $15/1M input
class TaskComplexity(Enum):
"""Complejidad estimada de la tarea"""
SIMPLE = 1 # Clasificación, routing, FAQs
MODERATE = 2 # Q&A con context, summarization
COMPLEX = 3 # Multi-step reasoning, tool orchestration
CRITICAL = 4 # High-stakes decisions, legal/medical
def estimate_complexity(
task_type: str,
context_length: int,
tools_needed: int
) -> TaskComplexity:
"""
Estima complejidad de tarea para routing inteligente.
Args:
task_type: Tipo de tarea ("classification", "qa", "reasoning", etc)
context_length: Tokens de contexto necesarios
tools_needed: Número de tool calls requeridos
Returns:
TaskComplexity enum
"""
# Clasificación simple
if task_type in ["classification", "routing", "sentiment"]:
return TaskComplexity.SIMPLE
# FAQ o Q&A básico
if task_type == "qa" and context_length < 2000 and tools_needed == 0:
return TaskComplexity.SIMPLE
# Multi-step pero predecible
if task_type in ["summarization", "extraction"] and tools_needed ✅ Ahorro real: En uno de mis proyectos, cambiar evaluation de GPT-4 a Claude Haiku redujo costes de evaluación de $4,200/mes a $126/mes (97% reducción) sin pérdida de correlation con human judgment.
Los errores #4 y #5 (gestión de context windows y saltar staging/testing) los cubro en detalle en las secciones de optimización y deployment checklist. Continuemos con el framework de planificación de presupuesto TCO.
🎯 Conclusión: Tus Próximos Pasos
Implementar agentes IA autónomos en producción sin romper tu presupuesto es absolutamente posible. Pero requiere planificación realista, control de costes desde día 1, y estrategias de optimización inteligentes.
Recapitulación de lo que has aprendido:
✅ Cost Planning
- • Framework TCO completo (dev + infra + hidden costs)
- • Presupuesto realista: $12k-$60k según complejidad
- • Empresas subestiman costes 200-400%
✅ Evitar Errores Caros
- • Cost monitoring + circuit breakers (evita $47k loops)
- • Timeline realista: 8-12 semanas mínimo
- • Model tiering (ahorra 40-70% en LLM calls)
✅ Framework Selection
- • CrewAI para MVPs
✅ Optimización Costes
- • Caching reduce 75-90% input tokens
- • Prompt optimization: 40-76% savings
- • Cost monitoring real-time mandatory
Acción Inmediata (Próximas 48 horas):
- 1
Calcula tu TCO proyectado
Usa el framework de la Sección 3 para estimar coste real (no solo desarrollo)
- 2
Selecciona framework apropiado
Usa el Decision Tree de la Sección 4 basado en presupuesto y use case
- 3
Implementa cost monitoring AHORA
Copia el código de cost_monitoring.py de la Sección 2 ANTES de deployar nada
- 4
Comunica timeline realista a stakeholders
8-12 semanas mínimo, no 4-6 semanas. Evita expectativas que llevan al 60% de fallos
Quiero resultados YA
Auditoría gratuita de 30 minutos. Identificamos tus bottlenecks exactos y te doy TCO estimate personalizado.
Solicitar Auditoría Gratuita →Email: sam@bcloud.consulting
Necesito calcular primero
TCO Calculator Excel con fórmulas para LLM APIs, infrastructure, y hidden costs. Basado en 15+ proyectos reales.
Contactar para Recibirla →Contáctanos y te la enviaremos gratis
Quiero saber más
Detalles completos del servicio de Agentes Autónomos IA: stack, pricing, timeline, garantías.
Ver Servicio Completo →Casos de éxito incluidos
¿Te resultó útil este artículo?
Compártelo con tu equipo técnico. El 40% de proyectos agentes IA fallan por falta de planning—ayúdales a evitarlo.
MLOps Readiness Assessment - Checklist Gratuito
Evalúa si tu organización está lista para desplegar agentes autónomos en producción. 25 puntos de verificación técnica + organizacional.
✅ Descarga inmediata | ✅ Sin registro | ✅ Formato PDF
¿Listo para Implementar Agentes IA Sin Explotar tu Presupuesto?
Auditoría gratuita de viabilidad técnica + estimación TCO realista para tu caso de uso específico
✅ Sin compromiso | ✅ Análisis técnico en 48h | ✅ ROI estimado incluido

Sobre el Autor
Abdessamad Ammi es CEO de BCloud Solutions y experto senior en IA Generativa y Cloud Infrastructure. Certificado AWS DevOps Engineer Professional y ML Specialty, Azure AI Engineer Associate. Ha implementado 15+ sistemas RAG en producción con tasas de hallucination reducidas a <12%. Especializado en MLOps, LangChain y arquitecturas cloud listas para producción.


