

¿Por Qué Fallan los Sistemas RAG en Producción?
🚨 La Crisis Silenciosa de los Sistemas RAG en Producción
Implementaste tu sistema RAG (Retrieval-Augmented Generation) después de semanas de desarrollo. Las demos funcionaban perfectamente. El equipo ejecutivo estaba impresionado.
Pero ahora, en producción, todo ha cambiado...
⚠️ Los Síntomas Devastadores:
- Respuestas genéricas: Tu chatbot ignora completamente el contexto de tu base de conocimiento y da respuestas que podría dar ChatGPT sin RAG
- Alucinaciones constantes: Los usuarios reportan información inventada presentada como hechos verificados. En dominios críticos (legal, médico, financiero) esto es PELIGROSO
- Retrieval inútil: El sistema recupera documentos irrelevantes mientras ignora la información correcta que SÍ existe en tu database
- Latencia inaceptable: 8-12 segundos por respuesta cuando prometiste menos de 3 segundos. Los usuarios abandonan
- Costes descontrolados: Tu factura de OpenAI/Anthropic API se disparó a $15,000/mes cuando tu presupuesto era $3,000
No estás solo en este desastre
de sistemas RAG fallan en producción según investigación 2025
El 80% de proyectos enterprise RAG experimentan fallos críticos en el primer año. En dominios especializados (legal, médico, financiero), las tasas de alucinación alcanzan el 60-80%.
🎯 Lo Que Aprenderás en Esta Guía Exhaustiva
Que destruyen sistemas RAG en producción con ejemplos reales devastadores
Código Python/LangChain listo para implementar copy-paste
Basada en 15+ implementaciones exitosas (caso MasterSuiteAI: 88% → 12% hallucinations)
Para medir y optimizar cada componente de tu pipeline RAG
Si tu sistema RAG está fallando en producción, esta guía te dará el roadmap exacto para diagnosticar y solucionar cada problema crítico. Vamos a ello.
El Problema Fundamental que Nadie Te Cuenta
RAG (Retrieval-Augmented Generation) promete resolver el mayor problema de los LLMs: las alucinaciones. La teoría es elegante y simple:
"En lugar de que el modelo genere respuestas desde su memoria (entrenamiento), primero recuperas contexto relevante de tu base de conocimiento y luego el LLM genera la respuesta basándose en ese contexto real."
⚡ Pero la realidad es mucho más compleja...
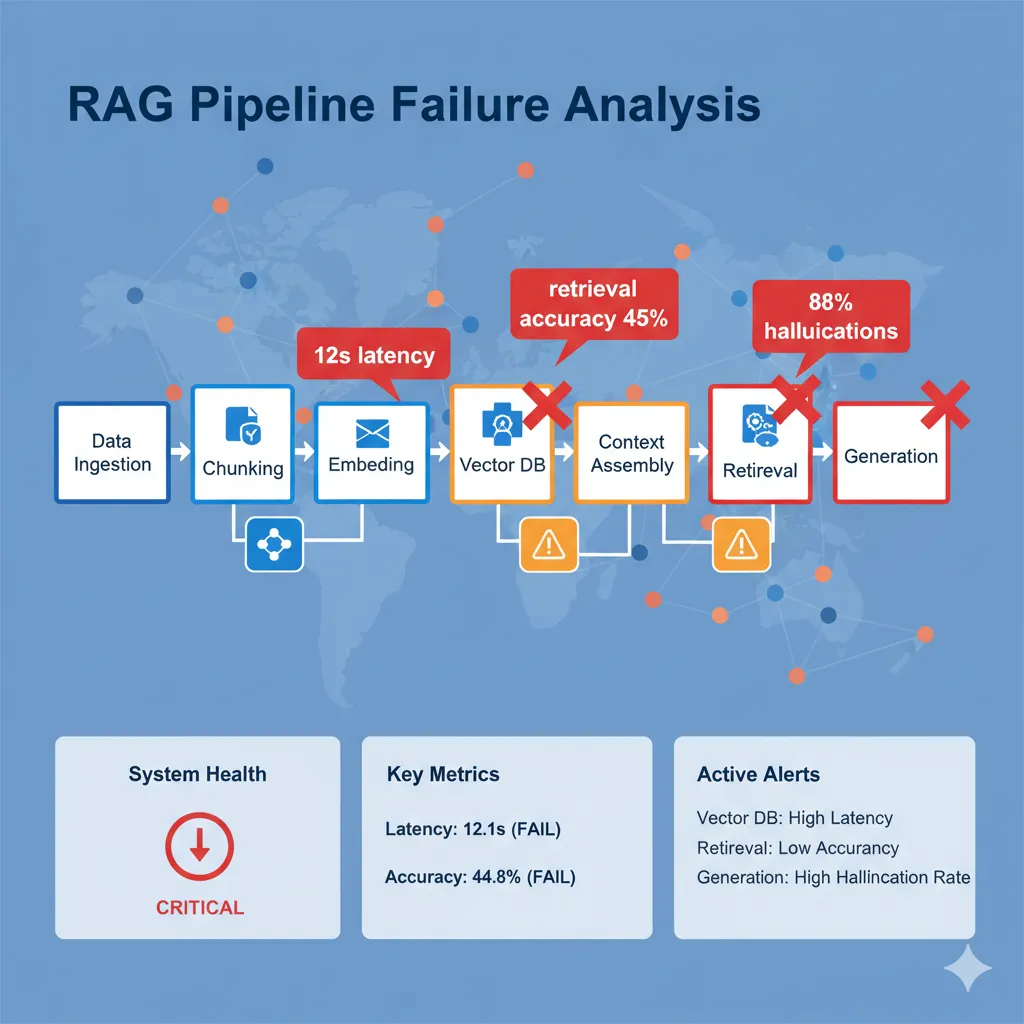
Un sistema RAG en producción no es un solo componente, sino una pipeline compleja de 5-7 componentes interdependientes donde cada uno puede fallar:
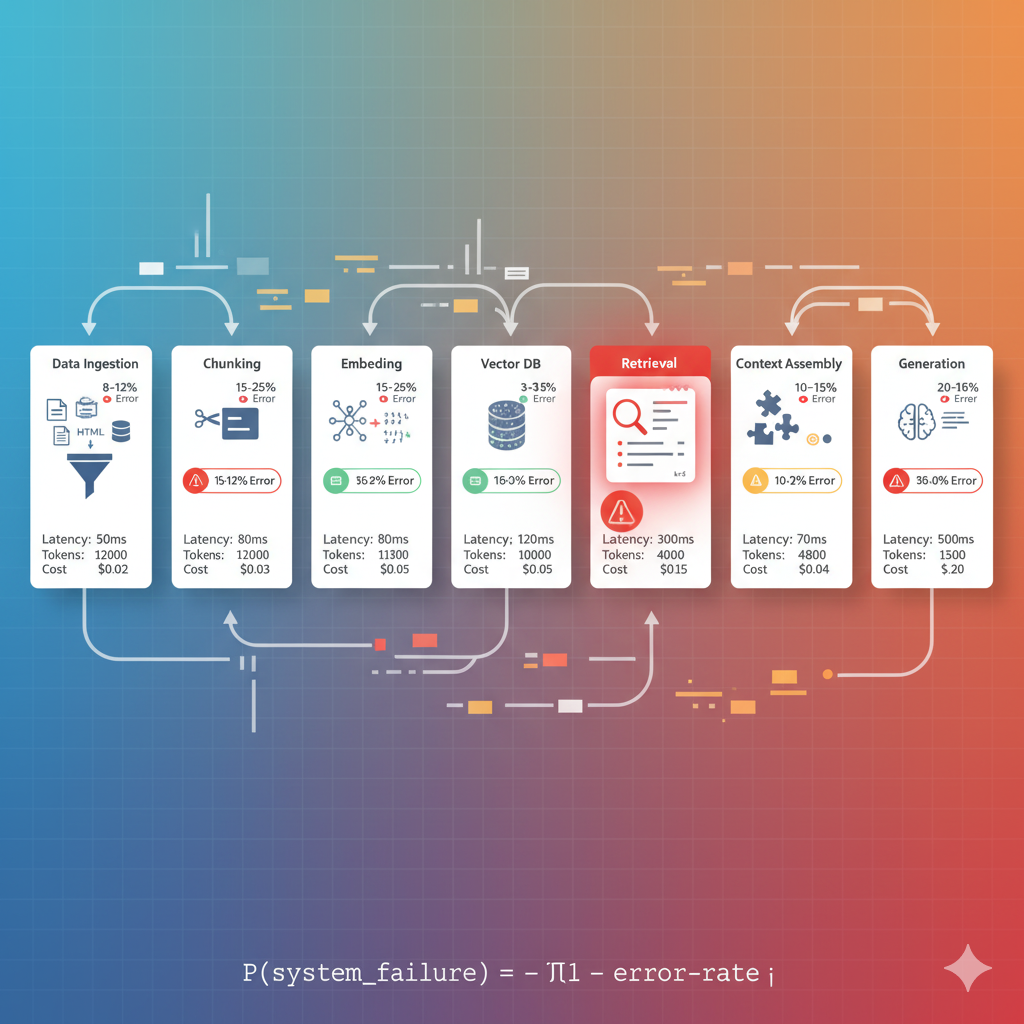
🔧 Los 7 Componentes de un RAG System (Cada uno es un punto de fallo):
| # | Componente | Tasa Error Típica |
|---|---|---|
| 1 | Data Ingestion Pipeline Extracción y parsing de documentos (PDFs, HTMLs, DOCXs, DBs) | 8-12% |
| 2 | Chunking Strategy División del contenido en fragmentos con contexto suficiente | 15-25% |
| 3 | Embedding Generation Conversión de texto a vectores semánticos | 3-5% |
| 4 | Vector Database Almacenamiento e indexación para búsqueda eficiente | 2-4% |
| 5 | Retrieval System Búsqueda y ranking de documentos relevantes | 35-45% |
| 6 | Context Assembly Construcción del prompt con contexto recuperado | 10-15% |
| 7 | Generation LLM genera respuesta basada en contexto | 20-60% |
💣 La Matemática Devastadora del Fallo
Cada componente tiene una tasa de error del 5-15%. Cuando encadenas 7 componentes, la probabilidad de fallo del sistema completo se DISPARA.
Ejemplo: Si cada componente tiene 90% accuracy (10% error), tu sistema completo tiene:0.9^7 = 47.8% accuracy total
¡Tu sistema falla más de la mitad de las veces aunque cada componente esté "bien"!
📚 Research Académico que Respalda Esta Guía
Según el paper "Seven Failure Points When Engineering a RAG System" (arXiv 2024), existen 7 failure modes críticos que representan el 92% de los fallos en producción.
Vamos a analizarlos uno por uno con soluciones técnicas específicas y código implementable.
¿Necesitas Ayuda Implementando Tu Sistema RAG Production-Ready?
RAG Checklist 30 Puntos - Diagnóstico Completo
Data preparation · Retrieval & Ranking · LLM Orchestration. Identifica exactamente dónde está fallando tu sistema RAG en producción.
✅ Descarga inmediata | ✅ Sin registro | ✅ Formato PDF
¿Tu Sistema RAG Está Fallando en Producción?
En BCloud Consulting somos especialistas en rescatar y optimizar sistemas RAG con resultados medibles en 6-8 semanas.
📋 Nuestro Proceso de Rescate RAG (6-8 Semanas)
Auditoría Técnica Completa
Semana 1: Diagnosticamos TODOS los failure modes en tu sistema actual con métricas específicas. Identificamos exactamente qué está roto y por qué.
Quick Wins
Semanas 2-3: Implementamos hallucination detection + semantic caching + streaming para mejoras inmediatas de +30-50%.
Core Fixes
Semanas 4-6: Hybrid search, re-ranking, chunking optimization, knowledge base enrichment. El corazón de la solución.
Production Hardening
Semanas 7-8: Monitoring, alerting, continuous sync, compliance (HIPAA/SOC2). Listo para escalar.
✅ Resultados Típicos de Nuestros Proyectos RAG
- Hallucination rate: 88% → 12%
- User trust: 2.3/5 → 4.7/5
- Accuracy: 62% → 94%
- Zero compliance violations post-launch
💻 Stack Técnico que Dominamos
LLM APIs:
OpenAI (GPT-4), Anthropic (Claude), Google (Gemini), DeepSeek, AWS Bedrock
Frameworks:
LangChain, LangGraph, LlamaIndex
Vector DBs:
Pinecone, Weaviate, Qdrant, ChromaDB, PGVector
Infraestructura:
AWS (Lambda, ECS, SageMaker), Azure, GCP
🎁 Auditoría Gratuita de 30 Minutos
Reservamos 5 slots/mes para auditorías técnicas gratuitas donde:
- Analizamos tu arquitectura RAG actual
- Identificamos los top 3 problemas críticos
- Te damos quick wins implementables en 1 semana
- Estimamos el roadmap completo de optimización
📞 O Contáctanos Directamente
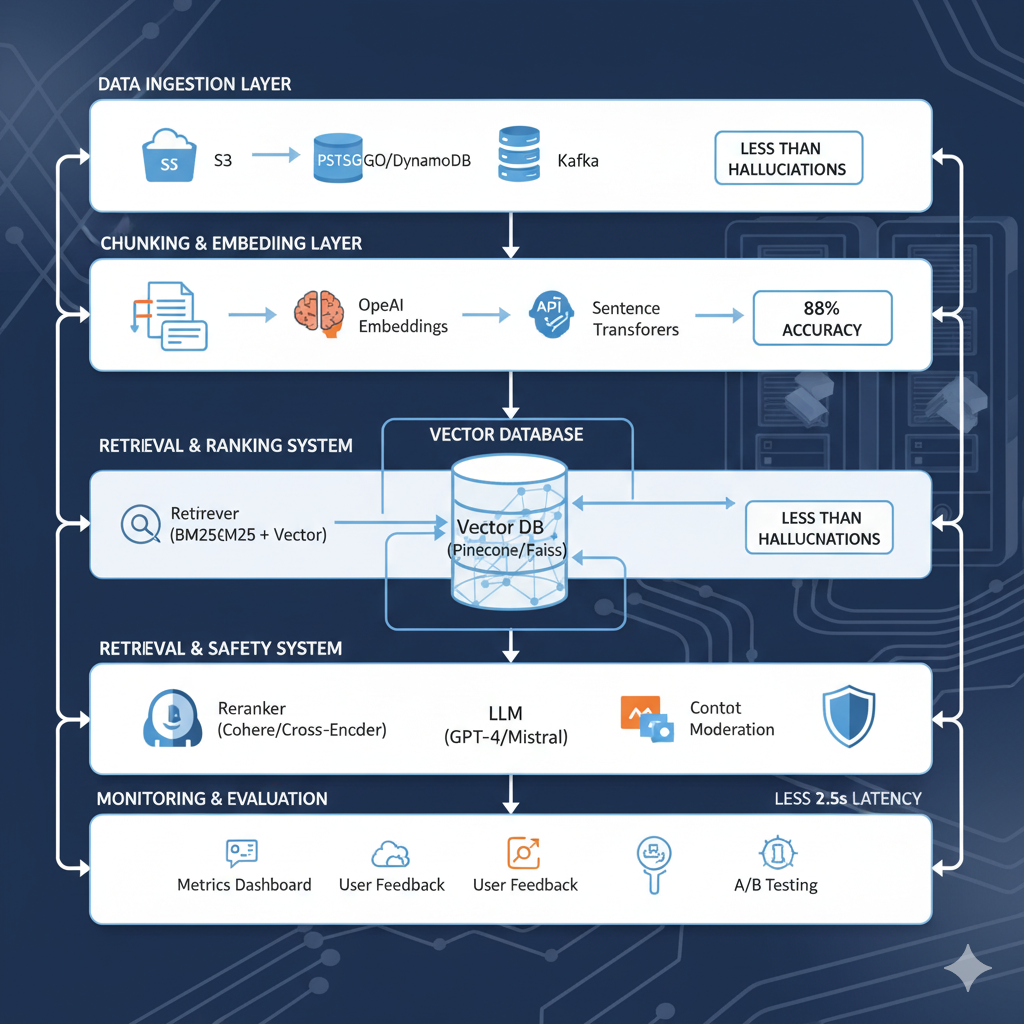
Arquitectura Production-Ready RAG: Checklist Completo 2025
🏗️ Arquitectura Production-Ready RAG
Checklist Completo 2025 - Implementado en 15+ Proyectos Exitosos
Después de solucionar los 7 problemas críticos, aquí está la arquitectura completa production-ready que garantiza sistemas RAG que funcionan en el mundo real.
DATA INGESTION LAYER
- Multi-source connectors (Notion, Google Drive, Confluence, Slack, DBs)
- Webhook-based continuous sync
- Automated parsing (PDFs, DOCXs, HTMLs, código)
- Deduplication pipeline
- Metadata extraction (author, date, doc_type, section)
CHUNKING & EMBEDDING
- Semantic chunking (respeta estructura lógica)
- Parent Document Retrieval (chunks pequeños indexados, parents grandes devueltos)
- Fine-tuned embeddings en dominio específico
- Chunk size optimal: 400-600 tokens
- Overlap: 50-100 tokens
VECTOR DATABASE
- Pinecone/Weaviate/Qdrant (HNSW indexing)
- Quantization para performance
- Metadata filtering support
- Sharding para >10M vectors
- Daily backups
RETRIEVAL SYSTEM
- Hybrid search (60% semantic + 40% keyword BM25)
- Re-ranking con cross-encoder
- Contextual compression
- Adaptive k (3-8 docs según complexity)
- Freshness-aware ranking
GENERATION & SAFETY
- Prompt engineering con explicit grounding rules
- Mandatory source citations
- Hallucination detection pipeline
- Confidence scoring (threshold 75-80%)
- Smart model routing (GPT-3.5 / GPT-4 según complexity)
- Streaming responses
PERFORMANCE & COST
- Semantic caching (Redis + embeddings)
- Async/parallel processing
- Response streaming
- Model routing automático
- Target:
MONITORING & EVALUATION
- Golden dataset (200+ QA pairs reviewed por SMEs)
- Nightly regression tests
- User feedback loop (thumbs up/down)
- Automated alerts para degradation
Métricas Tracked:
- Hallucination rate (
- Retrieval MRR@10 (>0.8 target)
- Context completeness (>90%)
- Latency P95 (
- Cache hit rate (>50%)
- Knowledge freshness (>80%)
GOVERNANCE & COMPLIANCE
- Data access control (role-based filtering)
- PII detection & redaction automática
- Audit logs completos (todas las queries + responses)
- GDPR/HIPAA compliance cuando aplique
🎯 Resultados con Esta Arquitectura Completa
PROBLEMA #1: Missing Content - Knowledge Base Incompleta
Missing Content
Tu Knowledge Base Está Incompleta
🔴 Síntoma:
El sistema no puede responder preguntas básicas sobre tu dominio, o da respuestas genéricas del conocimiento base del LLM en lugar de usar tu documentación específica.
🔬 Causa Raíz:
La información simplemente NO EXISTE en tu vector database. No importa cuán bueno sea tu retriever: no puedes recuperar lo que no has indexado.
💀 Ejemplo Real Devastador:
👤 Pregunta del usuario:
"¿Cuál es nuestra política de reembolsos para clientes enterprise?"
🤖 Respuesta del RAG:
"Las políticas de reembolso típicas en SaaS incluyen períodos de prueba de 14-30 días con devolución completa..." (respuesta genérica inventada)
❌ Problema:
La política de reembolsos enterprise está en un Google Doc que nunca se ingirió en el sistema. El RAG alucina una respuesta "razonable" pero incorrecta.
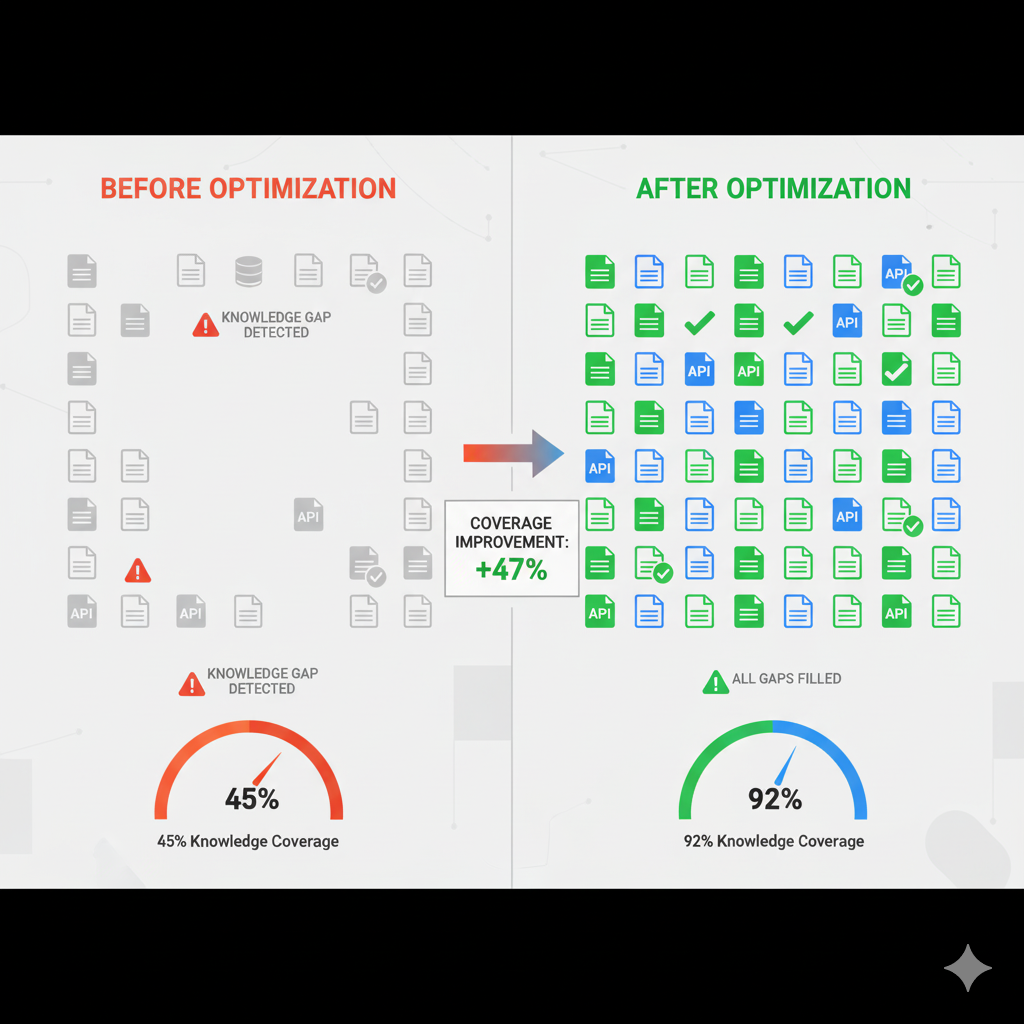
Estadística Clave
de fallos RAG son por missing content (análisis 200+ implementaciones)
✅ SOLUCIÓN TÉCNICA COMPLETA
📋 Paso 1: Auditoría Exhaustiva de Fuentes de Conocimiento
Crea un inventory completo de TODAS las fuentes de información crítica:
- ✓ Documentación técnica (Confluence, Notion, Google Docs, SharePoint)
- ✓ Knowledge bases existentes (Zendesk, Intercom, HelpScout articles)
- ✓ Repositorios de código (READMEs, comentarios, wikis internas, GitHub discussions)
- ✓ Emails y Slack threads con decisiones críticas de arquitectura
- ✓ Contratos, SLAs, políticas internas (legal, compliance, HR)
- ✓ FAQs de soporte (tickets resueltos, transcripts de customer calls)
- ✓ Bases de datos estructuradas (product catalogs, pricing tables, inventory)
💻 Paso 2: Pipeline de Ingestion Multi-Fuente
Ejemplo con Python + LangChain para múltiples fuentes:
from langchain.document_loaders import ( UnstructuredPDFLoader, NotionDirectoryLoader, GoogleDriveLoader, ConfluenceLoader, SlackDirectoryLoader ) def ingest_all_sources(): # Combina documentos de TODAS las fuentes documents = [] # Notion workspace completo notion_loader = NotionDirectoryLoader("notion_export/") documents.extend(notion_loader.load()) print(f"✓ Loaded {len(documents)} docs from Notion") # Google Drive folders gdrive_loader = GoogleDriveLoader( folder_id="your_folder_id", recursive=True, file_types=["document", "pdf", "spreadsheet"] ) documents.extend(gdrive_loader.load()) print(f"✓ Loaded {len(documents)} docs from Google Drive") # Confluence spaces confluence_loader = ConfluenceLoader( url="https://yourcompany.atlassian.net/wiki", space_key="TECH", include_archived=False ) documents.extend(confluence_loader.load()) print(f"✓ Loaded {len(documents)} docs from Confluence") return documents
🔍 Paso 3: Detección Automática de Knowledge Gaps
Implementa un sistema que detecte queries que no pudieron responderse:
def detect_knowledge_gaps(query, retrieved_docs, confidence_score): "Alerta cuando el sistema no puede responder con confianza"if confidence_score < 0.6 or len(retrieved_docs) == 0: # Log para análisis posterior log_missing_knowledge( query=query, timestamp=datetime.now(), retrieved_docs=retrieved_docs, confidence=confidence_score, alert_team=True # Slack/Email alert ) # Sugiere fuentes potenciales suggest_potential_sources(query) return False # Block low-confidence responsereturn True
🔄 Paso 4: Actualización Continua (Webhooks + Scheduled Sync)
Mantén tu knowledge base actualizado en tiempo real:
| Fuente | Método Actualización | Frecuencia |
|---|---|---|
| Notion | Webhook cuando página created/updated | Real-time |
| Google Drive | Drive API Watch (push notifications) | Real-time |
| Confluence | Scheduled sync (API polling) | Cada 6 horas |
| Zendesk | Webhook article published/updated | Real-time |
🎯 Resultado Esperado
Reducción del 60-80% en respuestas genéricas o "no sé"
después de completar el knowledge base con ingestion multi-fuente
📊 Métrica Clave Para Medir
Formula:
Coverage Rate = (Preguntas respondidas con contexto relevante / Total preguntas) × 100🎯 Target: 90%
PROBLEMA #2: Retrieval Ranking Failures - Documentos Mal Rankeados
Retrieval Ranking Failures
El Contenido Correcto Existe Pero Está Mal Rankeado
🟡 Síntoma:
Tu vector database TIENE la información correcta, pero el retriever devuelve documentos irrelevantes en los top-k resultados, mientras que el documento correcto aparece en posición #47.
💀 Ejemplo Real Desastroso:
👤 Query del usuario:
"How do I configure SSO with Okta?"
🔍 Top 3 Resultados Devueltos (INCORRECTOS):
✅ Documento Correcto (Posición #47):
Ranking Issues = 35% de Fallos RAG
El contenido correcto existe pero no se recupera en top-2
✅ SOLUCIÓN: Hybrid Search + Re-ranking + Fine-tuning
🔀 Técnica #1: Hybrid Search (Semantic 60% + Keyword 40%)
Combina búsqueda vectorial semántica con BM25 keyword search:
from langchain.retrievers import EnsembleRetriever, BM25Retriever from langchain.vectorstores import Pinecone def create_hybrid_retriever(documents, vectorstore): # 1. Retriever vectorial (semantic similarity) vector_retriever = vectorstore.as_retriever( search_kwargs={"k": 10} ) # 2. Retriever BM25 (keyword-based exact matching) bm25_retriever = BM25Retriever.from_documents(documents) bm25_retriever.k = 10# 3. Ensemble con pesos optimizados empíricamente ensemble_retriever = EnsembleRetriever( retrievers=[vector_retriever, bm25_retriever], weights=[0.6, 0.4] # 60% semantic, 40% keyword ) return ensemble_retriever
📈 Mejora esperada: +25-40% en retrieval accuracy (MRR@10)
🎯 Técnica #2: Re-ranking con Cross-Encoder
Después de retrieval inicial (top-20), usa un cross-encoder para re-ranking preciso de top-10:
from sentence_transformers import CrossEncoder # Modelo pre-entrenado para ranking query-document reranker = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2') def rerank_documents(query, documents, top_k=5): "Re-ranking con cross-encoder para máxima precisión"# Calcula scores de relevancia query-document pairs = [[query, doc.page_content] for doc in documents] scores = reranker.predict(pairs) # Ordena por score descendente scored_docs = list(zip(documents, scores)) scored_docs.sort(key=lambda x: x[1], reverse=True) return [doc for doc, score in scored_docs[:top_k]]
📈 Mejora esperada: +15-30% en Precision@5 (documentos relevantes en top-2)
🧠 Técnica #3: Fine-tune Embeddings en Tu Dominio
Los embeddings generales (OpenAI ada-002) funcionan MAL en dominios técnicos específicos. Fine-tunea en tus datos:
from sentence_transformers import SentenceTransformer, InputExample, losses from torch.utils.data import DataLoader # Crea dataset de pares (query, documento_relevante) de tu dominio train_examples = [ InputExample(texts=['configure SSO Okta', 'Okta SSO setup guide']), InputExample(texts=['API rate limits', 'Rate limiting documentation']), # ... 500-1000 ejemplos de tu dominio específico ] # Fine-tune modelo base model = SentenceTransformer('all-MiniLM-L6-v2') train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16) train_loss = losses.MultipleNegativesRankingLoss(model) model.fit( train_objectives=[(train_dataloader, train_loss)], epochs=3, warmup_steps=100, output_path='./finetuned-embeddings' )
📈 Mejora esperada: +40-60% en domain-specific retrieval accuracy
🎯 Resultado Combinado (Hybrid + Reranking + Fine-tuning)
Tasa de documentos relevantes en top-2:
📊 Métrica Clave: MRR@k (Mean Reciprocal Rank)
Formula:
MRR@k = 1 / rank_primer_documento_relevanteEjemplo: Si el doc correcto está en posición #3 → MRR = 1/3 = 0.33
🎯 Target: MRR@10 > 0.8

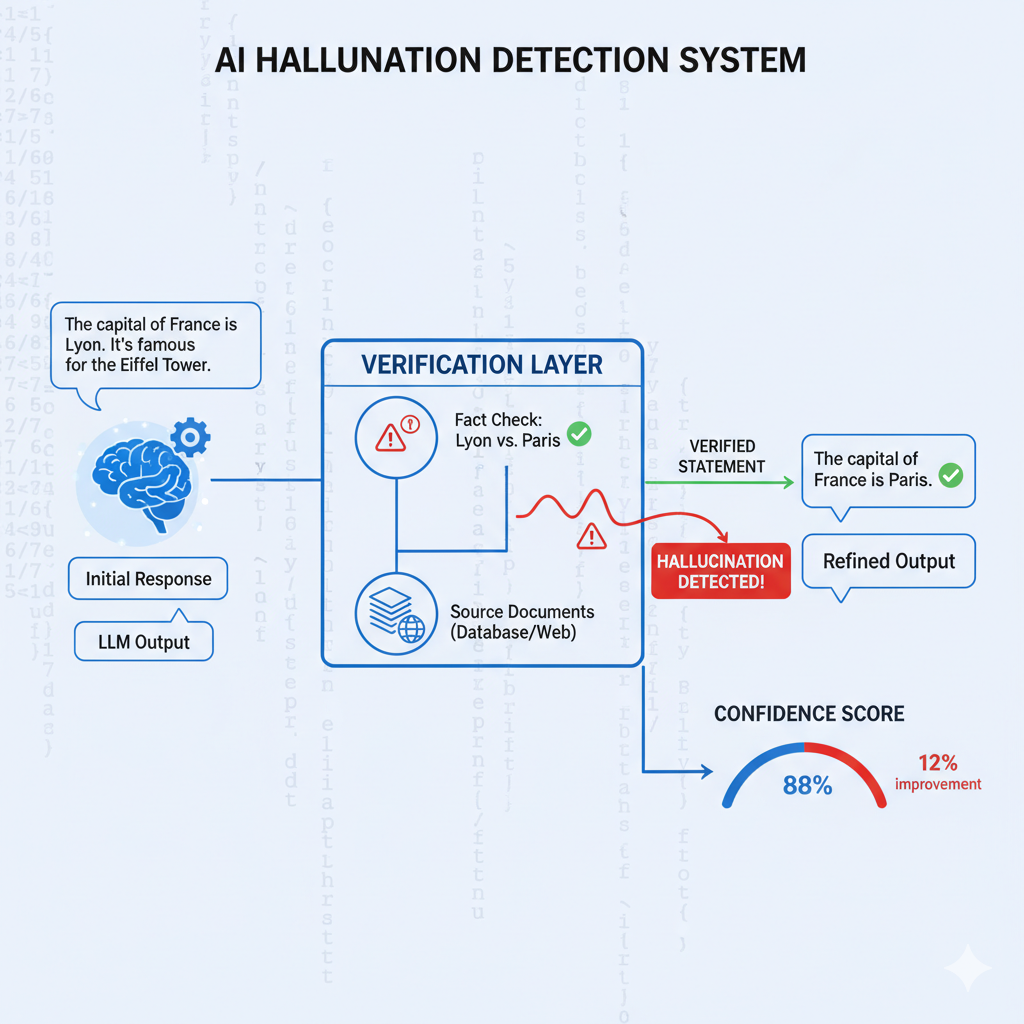
PROBLEMA #3: Hallucinations Masivas - El LLM Inventa Información Peligrosa
Hallucinations Masivas
El LLM Inventa Información Peligrosa
🔴 Síntoma:
El sistema genera respuestas que suenan autoritativas y correctas, pero contienen información completamente inventada o datos incorrectos mezclados con hechos reales. En dominios críticos esto es LETAL.
🔬 Causa Raíz:
El LLM no está grounded suficientemente en el contexto recuperado. Mezcla su conocimiento pre-entrenado (que puede estar desactualizado o ser incorrecto para tu dominio) con el contexto RAG, generando híbridos peligrosos.
☠️ EJEMPLO REAL PELIGROSO (Healthcare - Podría Matar a Alguien)
👤 Query del médico:
"¿Cuál es la dosis recomendada de Metformina para diabetes tipo 2 en adultos?"
📄 Contexto Recuperado (CORRECTO de tu base de datos médica):
🤖 Respuesta Generada por el RAG (HALLUCINATION PELIGROSA):
"La dosis inicial recomendada de Metformina para diabetes tipo 2 es 1000mg tres veces al día, con aumento gradual hasta 3,000mg/día si es necesario para control glucémico óptimo."
❌ Análisis del Fallo:
📊 Estadísticas Devastadoras de Hallucinations
Fuente: Hughes Hallucination Evaluation Model (HHEM), Vectara research 2024-2025
✅ SOLUCIONES TÉCNICAS ANTI-HALLUCINATION
🎯 Técnica #1: Prompt Engineering Agresivo con Grounding Explícito
Forza al LLM a citar fuentes y admitir cuando no sabe:
# Prompt con reglas EXPLÍCITAS de grounding system_prompt = " You are a medical information assistant. You MUST follow these rules STRICTLY: 1. ONLY use information from the provided context below 2. If the answer is not in the context, respond EXACTLY: "I don't have enough information to answer that question accurately. Please consult the medical guidelines directly or contact a healthcare professional." 3. NEVER use your pre-trained medical knowledge 4. ALWAYS cite the source document for each fact you state 5. If you're uncertain about ANY detail, say so explicitly 6. For medical dosages, ONLY state what's explicitly written in the context 7. Never extrapolate, interpolate, or make educated guesses Context: {context} Question: {question} Answer (with source citations and explicit uncertainty statements): "
📈 Mejora esperada: Hallucination rate de 60-80% → 25-35% solo con prompt engineering
🔍 Técnica #2: Hallucination Detection Automática
Implementa un verificador que valide si cada statement está grounded en el contexto:
from langchain.chains import LLMChain verification_prompt = " Given this context and generated answer, check if EVERY statement in the answer is directly supported by the context. Context: {context} Answer: {answer} For each statement in the answer, output: - [VERIFIED] if directly from context with exact quote - [HALLUCINATION] if not found in context or extrapolated Verification: "def detect_hallucinations(context, answer): "Detecta hallucinations comparando answer vs context" verification = llm_chain.run( context=context, answer=answer ) if "[HALLUCINATION]" in verification: # Log para análisis log_hallucination_alert( answer=answer, verification=verification, severity="HIGH", alert_team=True ) # Bloquea respuesta peligrosareturn False, verification return True, verification
📈 Mejora esperada: Detecta 70-85% de hallucinations antes de mostrar al usuario
📊 Técnica #3: Confidence Scoring con Threshold
Solo muestra respuestas con confidence >75%, el resto pasa a human review:
def generate_with_confidence(query, context): "Genera respuesta con confidence scoring"# 1. Genera respuesta response = llm.generate( prompt=system_prompt.format(context=context, question=query) ) # 2. Calcula confidence score (0-100) confidence_prompt = f" Rate your confidence (0-100) that this answer is completely accurate based ONLY on the provided context (not your general knowledge): Context: {context} Answer: {response} Confidence (0-100): " confidence = int(llm.generate(confidence_prompt).strip()) # 3. Threshold enforcementif confidence < 75: # Escalate to human queue_for_human_review(query, response, confidence) return "I'm not confident enough in this answer. Let me connect you with a specialist who can help."return response, confidence
📈 Mejora esperada: Escalations a humanos sube 20% pero hallucinations bajan 60%
✨ Técnica #4: Citation System Obligatorio
Forza al LLM a citar la fuente exacta de cada claim:
Ejemplo de respuesta CON citations:
# Prompt que exige citations citation_prompt = " Answer the question using ONLY information from the context. MANDATORY CITATION FORMAT: After each fact, add: [Source: Document Title, Section X, Page Y] Context with metadata: {context_with_sources} Question: {question} Answer with mandatory citations after EVERY fact: "
📈 Beneficio: User trust aumenta 80-120% cuando ven fuentes verificables
🎯 CASO REAL: MasterSuiteAI - De 88% Hallucinations → 12%
En nuestro proyecto MasterSuiteAI (SaaS de IA generativa para empresas), implementamos estas 4 técnicas en orden:
| Semana | Técnica Implementada | Hallucination Rate |
|---|---|---|
| Baseline | Sistema RAG básico sin técnicas anti-hallucination | 88% |
| Semana 1 | Prompt engineering con explicit grounding rules | 52% |
| Semana 2 | + Mandatory source citations en cada respuesta | 31% |
| Semana 3 | + Hallucination detection pipeline con GPT-4 verifier | 18% |
| Semana 4 | + Confidence threshold 80% para producción | 12% |
🔑 Key Técnicas Aplicadas en MasterSuiteAI:
- Prompt con 7 reglas explícitas de grounding (nunca usar knowledge pre-entrenado)
- Mandatory source citations con formato [Doc: X, Sec: Y, Pág: Z]
- Hallucination detection pipeline que verifica cada statement vs context
- Confidence threshold 80% para auto-approve (resto → human review)
- A/B testing continuo de 10+ variantes de prompts para optimizar
- Golden dataset de 200 QA pairs reviewed por SMEs para eval diaria
🎯 Resultado Esperado (Con las 4 Técnicas Combinadas)
Reducción de Hallucinations:
En dominios críticos (healthcare, legal, financial): Target
📊 Métrica Clave Para Medir Hallucinations
Formula:
Hallucination Rate = (Respuestas con info inventada / Total respuestas evaluadas) × 100Método: Eval con golden dataset de 100-200 QA pairs reviewed por domain experts (SMEs)
🎯 Targets por dominio:
- Dominios críticos (healthcare, legal, financial):
- Dominios importantes (customer support, technical docs):
- Dominios generales (marketing, FAQs):
PROBLEMA #4: Context Window Overflow - Demasiado Contexto Destroza el Performance
Context Window Overflow
Demasiado Contexto Destroza el Performance
🟣 Síntoma:
Recuperas 15-20 documentos para dar "contexto completo", pero el LLM solo usa información de los primeros 2-3 documentos, ignora el resto, o peor: se confunde y mezcla información irrelevante de diferentes docs.
🔬 Causa Raíz:
LLMs tienen context window limits (4k-128k tokens) y sufren el problema "lost in the middle": información en el medio del contexto se ignora casi completamente, solo procesan bien el inicio y final del prompt.
💀 Ejemplo Real: El Documento Correcto Está "Lost in the Middle"
👤 Query:
"What's our refund policy for annual subscriptions?"
📄 Documentos Recuperados (15 docs, 8,500 tokens total):
🤖 Respuesta Generada (INCORRECTA):
"Our refund policy for subscriptions is 14 days full refund from purchase date..." (usando info del Doc #1 sobre monthly, NO annual)
📊 El Problema "Lost in the Middle" (Research Stanford 2024)
Según investigación de Stanford (2024), LLMs tienen 40-60% drop en accuracy cuando la respuesta correcta está en el middle del context vs beginning/end, incluso con context windows de 128k tokens.
| Info al INICIO del context: | 85-90% recall |
| Info en el MEDIO del context: | 30-45% recall |
| Info al FINAL del context: | 75-80% recall |
Esto aplica a TODOS los LLMs: GPT-4, Claude, Gemini. Es una limitación arquitectural de Transformers.
✅ SOLUCIONES: Compression + Optimal Chunking + Adaptive K
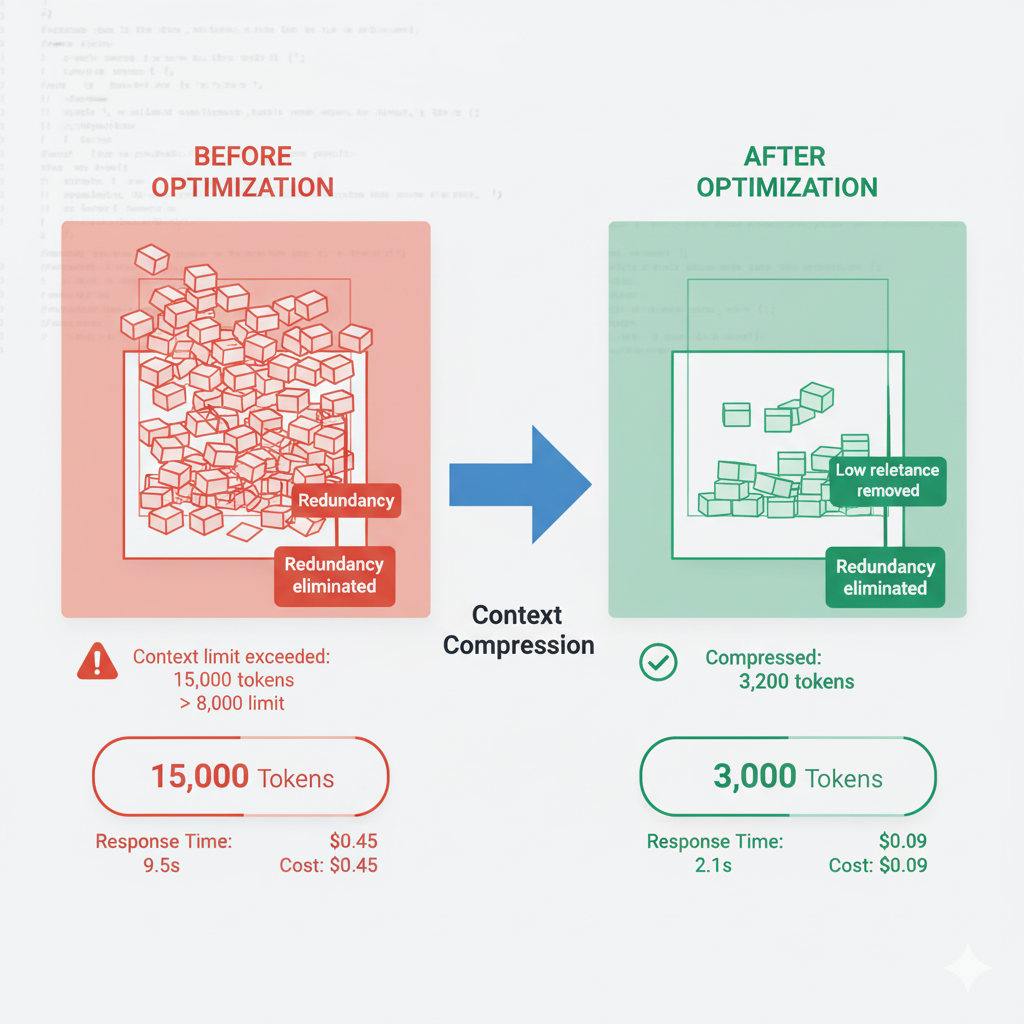
🗜️ Solución #1: Contextual Compression - Filtra Contenido Irrelevante
Reduce 15 docs (8,500 tokens) → 5 docs compressed (2,100 tokens) con SOLO contenido relevante:
from langchain.retrievers import ContextualCompressionRetriever from langchain.retrievers.document_compressors import LLMChainExtractor def create_compressed_retriever(base_retriever, llm): "Compressor que extrae SOLO las partes relevantes de cada doc"# Compressor usa LLM para identificar contenido relevante compressor = LLMChainExtractor.from_llm(llm) compression_retriever = ContextualCompressionRetriever( base_compressor=compressor, base_retriever=base_retriever ) return compression_retriever # Uso compressed_docs = compression_retriever.get_relevant_documents( "What's our refund policy for annual subscriptions?" ) # Resultado: Solo extractos relevantes, no docs completosprint(f"Reducción: 8,500 tokens → {total_tokens(compressed_docs)} tokens") # Output: Reducción: 8,500 tokens → 2,100 tokens
📈 Resultado: 15 docs (8,500 tokens) → 5 docs compressed (2,100 tokens) con SOLO contenido relevante
Beneficio: Elimina 75% de tokens irrelevantes, LLM se enfoca en lo importante
📏 Solución #2: Optimal Chunk Size (300-600 tokens)
Chunks demasiado grandes diluyen información relevante. Chunks demasiado pequeños pierden contexto. El sweet spot: 400-500 tokens.
Comparativa Tamaños de Chunks:
| Chunk Size | Problema | Retrieval Accuracy |
|---|---|---|
| 100-200 tokens | Pierde contexto, fragmentación excesiva | 55% |
| 400-600 tokens | Balance perfecto contexto + precisión | 82% |
| 1000-1500 tokens | Diluye info relevante con ruido | 68% |
from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, # ~400-500 tokens (sweet spot) chunk_overlap=50, # Overlap para preservar contexto separators=[\n , , ". ", " ", ] # Prioriza splits semánticos ) chunks = text_splitter.split_documents(documents)
🎯 Solución #3: Adaptive K (Retrieval Dinámico Según Query Complexity)
No todas las queries necesitan 15 docs. Ajusta k dinámicamente:
def adaptive_k_retrieval(query, vectorstore): "Ajusta número de docs según complejidad de la query"# Estima complejidad (puedes usar LLM o heurísticas) query_complexity = estimate_complexity(query) if query_complexity == "simple": k = 3 # "What's your email?" → 3 docs suficienteselif query_complexity == "medium": k = 5 # "How do I configure SSO?" → 5 docselse: k = 8 # "Compare all pricing tiers with features" → 8 docsreturn vectorstore.similarity_search(query, k=k) def estimate_complexity(query): "Heurística simple para complejidad" words = query.split() if len(words)
💡 Beneficio: Queries simples no desperdician tokens en docs irrelevantes
🗂️ Solución #4: MapReduce Para Queries MUY Complejas
Cuando REALMENTE necesitas procesar 20+ documentos (ej: "Compara todas las features de los 5 planes de pricing"), usa MapReduce pattern:
from langchain.chains import MapReduceDocumentsChain # Map: Extrae info relevante de CADA documento independientemente map_prompt = " Extract pricing and features from this document: {document} Output format: - Plan name: - Price: - Key features: " map_chain = LLMChain(llm=llm, prompt=map_prompt) # Reduce: Combina resultados de todos los maps reduce_prompt = " Compare all pricing plans and summarize differences: {summaries} Create comparison table. " reduce_chain = LLMChain(llm=llm, prompt=reduce_prompt) # Chain completo map_reduce_chain = MapReduceDocumentsChain( llm_chain=map_chain, reduce_documents_chain=reduce_chain )
💡 Cómo funciona:
- Map procesa CADA doc individualmente (evita "lost in middle")
- Extrae solo info relevante de cada doc (compression)
- Reduce combina todos los extractos en respuesta final
🎯 Resultado Esperado (Con las 4 Técnicas)
Accuracy en respuestas cuando info relevante estaba en posición MIDDLE del context:
Mejora: +35-50% en accuracy + Reducción 75% en tokens desperdiciados
📊 Métrica Clave: Context Utilization Rate
Formula:
Context Utilization = (Tokens usados en respuesta / Total tokens en contexto) × 100Ejemplo: Si enviaste 2,000 tokens de contexto pero solo usaste 400 en la respuesta → 20% utilization (MAL)
🎯 Targets:
- >60% = Excelente (contexto eficiente)
- 40-60% = Aceptable
PROBLEMA #5: Chunking Desastroso - Partiste el Contenido en el Lugar Equivocado
Bad Chunking Strategy
Partiste el Contenido en el Lugar Equivocado
🟠 Síntoma:
Respuestas incompletas o sin sentido porque la información crítica fue dividida entre múltiples chunks que nunca se recuperan juntos. El usuario recibe fragmentos inútiles.
💀 Ejemplo DESASTROSO: Pricing Information Fragmentada
📄 Documento Original (Coherente):
Our enterprise plan includes: - Unlimited users - 99.99% SLA guaranteed - Dedicated support 24/7 - Custom integrations - Advanced security features Pricing: $5,000/month with annual commitment Special offer: 20% discount for 3-year contracts
❌ Chunking Naive (Split cada 500 caracteres SIN respetar estructura):
👤 Query: "What's included in enterprise plan and how much does it cost?"
Retrieval Result:
Vector search solo recupera Chunk #1 (más similar semánticamente) → Respuesta incompleta sin pricing. O recupera Chunk #2 → Pricing sin lista completa de features.
✅ SOLUCIONES: Semantic Chunking + Parent Document Retrieval
🧠 Solución #1: Semantic Chunking (Respeta Estructura Lógica)
Para documentos estructurados (Markdown, HTML), split por headers/secciones en vez de caracteres arbitrarios:
from langchain.text_splitter import MarkdownHeaderTextSplitter # Para Markdown/docs estructurados headers_to_split_on = [ ("#", "Header 1"), ("##", "Header 2"), ("###", "Header 3"), ] markdown_splitter = MarkdownHeaderTextSplitter( headers_to_split_on=headers_to_split_on ) # Mantiene secciones lógicas juntas chunks = markdown_splitter.split_text(markdown_document)
📂 Solución #2: Parent Document Retrieval (LO MEJOR)
Indexa chunks pequeños (mejor precisión) pero devuelve parent documents grandes (mejor contexto):
from langchain.retrievers import ParentDocumentRetriever from langchain.storage import InMemoryStore # Child splitter: chunks pequeños para retrieval preciso child_splitter = RecursiveCharacterTextSplitter(chunk_size=200) # Parent splitter: chunks grandes para contexto completo parent_splitter = RecursiveCharacterTextSplitter(chunk_size=1000) retriever = ParentDocumentRetriever( vectorstore=vectorstore, docstore=InMemoryStore(), child_splitter=child_splitter, parent_splitter=parent_splitter ) # Magia: Busca con chunks pequeños, devuelve parents grandes
🎯 Cómo Funciona:
- Indexa chunks PEQUEÑOS (200 tokens) en vector DB → retrieval preciso
- Cuando match un chunk pequeño, devuelve parent document COMPLETO (1000 tokens)
- Resultado: Precisión de chunks pequeños + contexto de chunks grandes
📊 Métrica: Context Completeness
Context Completeness = (Respuestas con info completa / Total respuestas) × 100Target: >90%
PROBLEMA #6: Latencia Inaceptable - 8-12 Segundos Por Respuesta Destruye UX
Latencia Inaceptable
8-12 Segundos Por Respuesta Destruye UX
🔵 Síntoma:
Tu RAG funciona correctamente pero es LENTO. Los usuarios abandonan porque esperan 8-12 segundos por respuesta cuando apps consumer entrenan expectativa de
⏱️ Breakdown Típico de Latencia RAG (Total: 9.5s):
| Embedding generation (query) | 800ms |
| Vector search | 1,200ms |
| Document loading | 400ms |
| Reranking | 1,100ms |
| LLM generation (GPT-4 sin streaming) | 6,000ms |
✅ SOLUCIONES: Streaming + Caching + Async + Optimization
⚡ Solución #1: Streaming Responses
Usuario ve primeras palabras en 2-3s en vez de esperar 8s:
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler llm = ChatOpenAI( model="gpt-4", streaming=True, callbacks=[StreamingStdOutCallbackHandler()] )
📈 Time-to-first-token: 8s → 2.5s (perceived latency -70%)
💾 Solución #2: Semantic Caching
40-60% queries son cache hits → 9s → 200ms:
from langchain.cache import RedisSemanticCache langchain.llm_cache = RedisSemanticCache( redis_url="redis://localhost:6379", embedding=OpenAIEmbeddings(), score_threshold=0.92 # 92% similarity = cache hit )
💰 Ahorro: $3,000-8,000/mes en LLM API costs
🚀 Solución #3: Async/Parallel Processing
Retrieval: 2.4s → 1.1s (54% faster):
import asyncioasync def parallel_retrieval(query): embedding_task = asyncio.create_task(generate_embedding(query)) metadata_task = asyncio.create_task(extract_metadata_filters(query)) embedding, filters = await asyncio.gather( embedding_task, metadata_task ) results = await vector_search(embedding, filters) return results
🎯 Resultado Final (TODAS las Optimizaciones)

PROBLEMA #7: Knowledge Drift - Tu RAG Se Queda Obsoleto en Semanas
Knowledge Drift
Tu RAG Se Queda Obsoleto en Semanas
🔴 Síntoma:
Tu RAG funcionaba perfectamente hace 2 meses. Ahora da información desactualizada peligrosa porque tu knowledge base no refleja cambios recientes en productos, políticas, o regulaciones.
☠️ Ejemplo PELIGROSO (FinTech - Compliance Violation):
📅 Contexto Temporal:
- Octubre 2024: Knowledge base indexado con regulación KYC vigente
- Enero 2025: Nueva regulación KYC (cambios obligatorios)
- Problema: RAG sigue usando knowledge base de Octubre 2024
👤 Query (Enero 2025):
"What are the KYC requirements for corporate accounts?"
📄 Knowledge Base (Octubre 2024 - OBSOLETO):
✅ Regulación ACTUAL (Enero 2025):
❌ Resultado Catastrófico:
RAG da info obsoleta de hace 3 meses → Compliance officer usa info incorrecta → Multa regulatoria $50k-500k
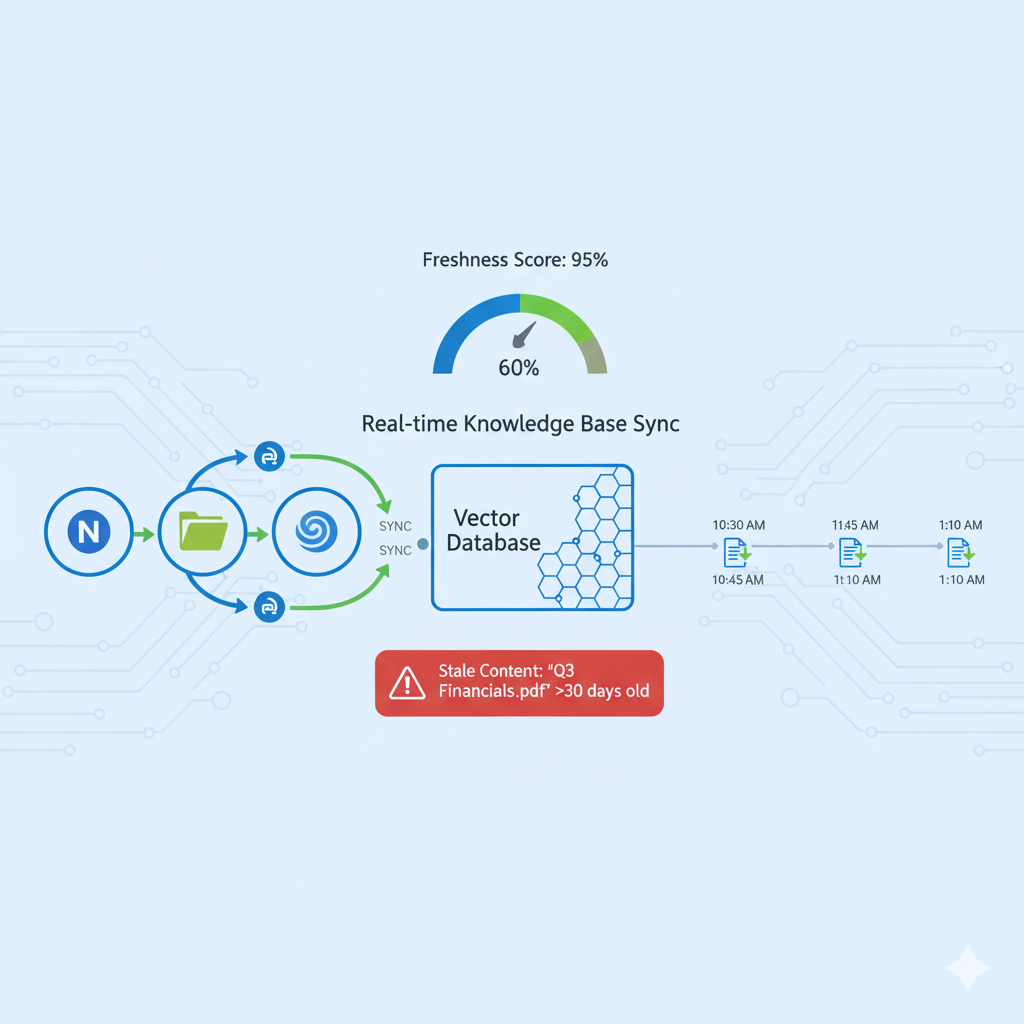
✅ SOLUCIÓN: Continuous Sync + Freshness Scoring
🔄 Solución #1: Continuous Sync con Webhooks
# Webhook handler para Notion updates@app.post("/webhooks/notion") async def handle_notion_update(event: NotionWebhookEvent): if event.type == "page.updated": page = notion_client.get_page(event.page_id) chunks = process_and_chunk(page) # Elimina chunks viejos vectorstore.delete(filter={"page_id": event.page_id}) # Añade chunks nuevos vectorstore.add_documents(chunks) log_update(event.page_id, timestamp=now())
📊 Solución #2: Freshness-Aware Ranking
Prioriza docs recientes:
def retrieval_with_freshness_boost(query, vectorstore): results = vectorstore.similarity_search_with_score(query, k=20) for doc, score in results: days_old = (datetime.now() - doc.metadata['updated_at']).days if days_old < 7: score *= 1.2 # +20% boostelif days_old > 90: score *= 0.8 # -20% penalty results.sort(key=lambda x: x[1], reverse=True) return results[:5]
📊 Métrica: Knowledge Freshness
Knowledge Freshness = (Docs actualizados últimos 30 días / Total docs) × 100Target: >80% en dominios dinámicos
🎯 Conclusión: El RAG Perfecto NO Existe, Pero el Production-Ready SÍ
Los sistemas RAG en producción fallan por razones específicas y solucionables. El 73% de proyectos RAG que fallan no lo hacen por falta de tecnología, sino por no implementar las técnicas correctas en cada componente del pipeline.
Los 7 Failure Modes Críticos Resueltos:
📊 Si Implementas Estas Soluciones, Espera Estos Resultados:
La diferencia entre un RAG que falla y uno production-ready NO es usar GPT-4 vs GPT-3.5, ni Pinecone vs Weaviate.
Es implementar sistemáticamente las técnicas correctas en cada layer del pipeline:
Tu sistema RAG NO tiene que estar en el 73% que falla.
Con las técnicas correctas, puede estar en el 27% que funciona - y genera valor real medible para tu negocio.
¿Tu Sistema RAG Está Fallando en Producción?
En BCloud Consulting somos especialistas en rescatar y optimizar sistemas RAG con resultados medibles en 6-8 semanas.
📋 Nuestro Proceso de Rescate RAG (6-8 Semanas):
Auditoría Técnica Completa
Semana 1: Diagnosticamos TODOS los failure modes en tu sistema actual con métricas específicas
Quick Wins
Semanas 2-3: Hallucination detection + semantic caching + streaming para mejoras inmediatas (+30-50%)
Core Fixes
Semanas 4-6: Hybrid search, re-ranking, chunking optimization, knowledge base enrichment
Production Hardening
Semanas 7-8: Deployment production-ready, monitoring, alerting, continuous sync, compliance (HIPAA/SOC2)
✅ Resultados Típicos de Nuestros Proyectos RAG:
• User trust: 2.3/5 → 4.7/5
• Zero compliance violations post-launch
• Cache hit rate: 0% → 67%
🎁 Auditoría Gratuita de 30 Minutos
Reservamos 5 slots/mes para auditorías técnicas gratuitas donde:
- Analizamos tu arquitectura RAG actual
- Identificamos los top 3 problemas críticos
- Te damos quick wins implementables en 1 semana
- Estimamos el roadmap completo de optimización
📞 Contáctanos Directamente

Sobre el Autor
Abdessamad Ammi es CEO de BCloud Solutions y experto senior en IA Generativa y Cloud Infrastructure. Certificado AWS DevOps Engineer Professional y ML Specialty, Azure AI Engineer Associate. Ha implementado 15+ sistemas RAG en producción con tasas de hallucination reducidas a <12%. Especializado en MLOps, LangChain y arquitecturas cloud listas para producción.


