


Por Qué Importa la Adquisición de Weights & Biases
Mayo 2025: CoreWeave adquiere Weights & Biases por $1.7 mil millones. Noviembre 2025: Neptune.ai anuncia el cierre de su plataforma SaaS para Marzo 2026.
Si eres uno de los 1 millón+ de ingenieros de IA usando estas herramientas, necesitas un plan AHORA.
El panorama de las herramientas MLOps está experimentando la consolidación más agresiva en su historia. En solo seis meses, dos de las plataformas de experiment tracking más populares han cambiado radicalmente: Weights & Biases fue adquirido por una empresa de infraestructura GPU (no especialista en MLOps), y Neptune.ai cerrará su plataforma SaaS completamente.
📊 El Mercado MLOps en Números
$39B
Proyección mercado MLOps 2034
87%
Empresas implementando IA en 2025
37.4%
CAGR proyectado hasta 2034
Fuente: Global Market Insights, 2025
Este crecimiento explosivo ha desencadenado una ola de consolidaciones. Las grandes empresas de infraestructura cloud están adquiriendo herramientas especializadas de MLOps, y los equipos de machine learning se enfrentan a preguntas críticas:
- ⚠️¿Seguir con W&B después de la adquisición? CoreWeave es una empresa de infraestructura GPU, no un especialista en MLOps. ¿Cambiará el roadmap del producto hacia features de GPU en lugar de experiment tracking?
- ⚠️¿Migrar a una alternativa? Con Neptune.ai cerrando en Marzo 2026, ¿qué plataforma es realmente estable y confiable a largo plazo?
- ⚠️¿Cambiar a open source? ¿Vale la pena el esfuerzo de self-hosting MLflow para evitar vendor lock-in futuro?
En esta guía completa, te doy el framework de decisión exacto que he usado con equipos de ML en empresas SaaS: alternativas detalladas, análisis de costes reales (TCO), guías de migración técnicas con código, y estrategias para evitar vendor lock-in en el futuro.
💡 Nota del autor: Llevo 10+ años implementando infraestructura MLOps en producción. He migrado sistemas de experiment tracking para startups SaaS y scale-ups, reduciendo costes entre 70-90% mediante auditorías técnicas y migraciones estratégicas. En este artículo, comparto exactamente cómo evaluamos herramientas y ejecutamos migraciones.
1. Por Qué Importa la Adquisición de Weights & Biases por CoreWeave
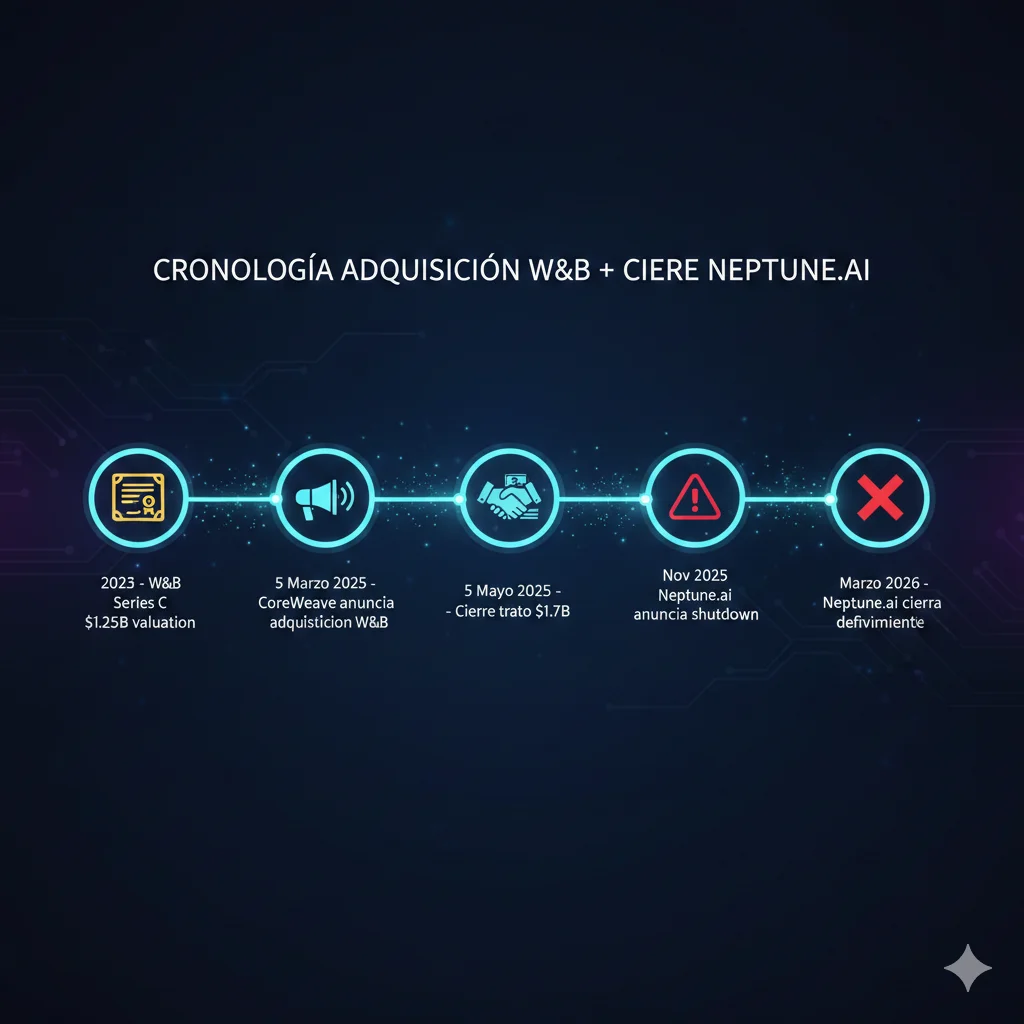
El 5 de marzo de 2025, CoreWeave anunció la adquisición de Weights & Biases. Dos meses después, el 5 de mayo, cerraron el trato por $1.7 mil millones. Esta adquisición no es simplemente otra transacción M&A en el ecosistema tech—representa un cambio fundamental en el panorama de las herramientas MLOps.
► Los Números de la Adquisición
Weights & Biases (Pre-Adquisición)
- ✓Valoración 2023: $1.25 mil millones (Ronda Series C)
- ✓Base de usuarios: 1+ millón de ingenieros de IA
- ✓Clientes: 1,400+ organizaciones (OpenAI, Meta, NVIDIA, Snowflake, AstraZeneca, Toyota)
- ✓Estado pre-adquisición: Preparándose para IPO
CoreWeave (Adquiriente)
- ►Negocio principal: Infraestructura GPU cloud (A100, H100)
- ►Especialización: Compute power, NO software MLOps
- ►Precio adquisición: $1.7 mil millones (según The Information)
- ►Compromiso declarado: "Interoperabilidad con cualquier cloud/modelo"
► Por Qué Esto Genera Preocupación en la Comunidad MLOps
CoreWeave NO es una empresa de software MLOps—es un proveedor de infraestructura GPU. Esto crea varias incertidumbres para los usuarios actuales de W&B:
🚨 Cambio de Prioridades del Producto
CoreWeave se especializa en GPUs. ¿Priorizarán features de orquestación GPU sobre las capacidades de experiment tracking que hicieron famoso a W&B? La integración GPU puede ser valiosa, pero si viene a costa de descuidar el core product, los usuarios perderán.
💰 Modelo de Precios Incierto
W&B ya era criticado por su modelo de "tracked hours" que escalaba costes rápidamente con entrenamiento en múltiples GPUs. ¿CoreWeave subirá los precios para monetizar la base instalada de 1M+ usuarios? ¿Empaquetarán W&B con sus servicios GPU (lock-in adicional)?
🔒 Vendor Lock-in Doble
Usar W&B ahora significa depender no solo de una herramienta de experiment tracking, sino también de la estrategia empresarial de un proveedor GPU. Si CoreWeave decide pivotar o integrar más profundamente con su infraestructura propietaria, la migración futura será aún más compleja.
🔧 Interoperabilidad Prometida vs. Realidad
CoreWeave promete "interoperabilidad con cualquier cloud y modelo", pero la historia tech está llena de adquisiciones donde esos compromisos se diluyen con el tiempo. Amazon prometió mantener Twitch independiente, pero gradualmente lo integró más profundamente en su ecosistema.
► La Segunda Disrupción: Neptune.ai Cerrando Marzo 2026
Si la adquisición de W&B no fuera suficiente, en noviembre de 2025 Neptune.ai (una de las alternativas más populares a W&B) anunció que está cerrando su plataforma SaaS en Marzo 2026 tras ser adquirida por OpenAI.
⚠️ Impacto Combinado W&B + Neptune.ai
•1 millón+ usuarios de W&B enfrentando incertidumbre sobre el futuro del producto
•Miles de usuarios de Neptune.ai obligados a migrar ANTES de Marzo 2026
•Consolidación acelerada: El mercado de experiment tracking está concentrándose en pocas manos
•Equipos ML en crisis: ¿Qué herramienta será la próxima en ser adquirida o discontinuada?
Estos eventos no son incidentes aislados—son síntomas de una consolidación masiva del mercado MLOps. El mercado está pasando de $1.7B (2024) a $39B proyectados (2034), y las grandes empresas están comprando agresivamente las herramientas especializadas.
Decision Framework: Qué Herramienta Elegir en 2025
4. Decision Framework: Qué Herramienta Elegir en 2025
Ahora que conoces las alternativas principales, necesitas un framework sistemático para decidir. He desarrollado este proceso trabajando con equipos ML de startups SaaS y scale-ups. No es un checklist genérico—es un decision tree que he usado en proyectos reales de migración.
► Paso 1: Evalúa Tu Situación Actual
Responde estas 7 preguntas críticas:
¿Cuál es tu team size actual y proyectado a 12 meses?
•
¿Qué budget mensual tienes para experiment tracking?
•
¿Tu equipo tiene expertise DevOps/MLOps?
• Sí (dedicated DevOps): Open source viable (MLflow, Aim, DVC)
• Limited (part-time): Managed option recomendado (Comet ML, Databricks Managed MLflow)
• No (solo data scientists): SaaS mandatory (Comet ML, W&B, cloud platforms)
¿Estás comprometido a un cloud provider?
• AWS committed: SageMaker (34% market share, integración nativa)
• GCP committed: Vertex AI (AutoML potente, BigQuery seamless)
• Azure committed: Azure ML (Microsoft ecosystem)
• Multi-cloud o cloud-agnostic: MLflow, Comet ML, Aim (evitar cloud lock-in)
¿Necesitas compliance estricto (data on-premise)?
• Sí (GDPR strict, healthcare, finance): Self-hosted ONLY (MLflow, Aim, Comet ML on-premise)
• Moderate (SOC2 compliant SaaS OK): Managed options viables (Comet ML, W&B, cloud platforms)
• No (startup/no regulated industry): Cualquier opción viable
¿Cuántos experiments corres por mes?
•
¿Qué tan importante es evitar vendor lock-in?
• Crítico (post-W&B trauma): Open source ONLY (MLflow, Aim, DVC)
• Importante (strategic concern): Preferir open source, acceptable managed con data export
• Low priority (speed > flexibility): Managed options OK (Comet ML, cloud platforms)
► Paso 2: Escenarios Reales con Recomendaciones
📊 Escenario 1: Startup Seed Stage (5 people,
📊 Escenario 2: Scale-up Series B (25 people, $5k-15k/mes budget)
Situación: Series B ($20M raised), 15 ML engineers + 5 data scientists + 2 DevOps, multi-cloud (AWS + GCP), corren 10k-20k experiments/mes, compliance SOC2, vendor lock-in concern alto.
🏆 Recomendación: MLflow Self-Hosted ($1.5k-3k/mes infrastructure + DevOps time)
Por qué: Tienen DevOps capacity, multi-cloud strategy (cloud-agnostic tool critical), vendor lock-in concern justifica effort, TCO 70% menor vs W&B a escala ($5k-10k/mes W&B Team vs $1.5k-3k/mes MLflow).
Setup: Terraform IaC para reproducible deployment, PostgreSQL managed (RDS/Cloud SQL), artifact store S3/GCS, monitoring con Prometheus + Grafana.
Alternativa: Databricks Managed MLflow ($3k-8k/mes) si quieren managed pero con open source core (menos lock-in que SageMaker).
📊 Escenario 3: Enterprise F500 (100+ people, budget ilimitado)
Situación: Fortune 500 finance, 80 data scientists + 40 ML engineers, AWS-only (corporate mandate), compliance GDPR + SOX, corren 100k+ experiments/mes, necesitan governance/audit trails, soporte enterprise crítico.
🏆 Recomendación: AWS SageMaker Studio ($10k-50k/mes depending scale)
Por qué: AWS-committed elimina multi-cloud concerns, compliance built-in (GDPR, HIPAA, SOC2), enterprise support 24/7, governance features (IAM, audit logs), scales automáticamente a 100k+ experiments.
Trade-off aceptado: AWS lock-in es aceptable porque corporate mandate ya los tiene committed. Pricing alto but justified por reduced operational overhead (vs self-hosted at scale).
Alternativa: Databricks Unity Catalog ($15k-80k/mes) si necesitan unified analytics + ML platform.
📊 Escenario 4: Research Team Academia (10 people, budget $0)
Situación: Universidad research lab, 6 PhD students + 4 postdocs, sin budget commercial tools, cloud credits limitados (AWS Educate $100/mes), corren 2k-5k experiments/mes (foundation models research), prioridad reproducibility papers.
🏆 Recomendación: Comet ML Academic Free Tier + Aim para UI
Por qué: Comet ML da Pro plan GRATIS para academia (normalmente $19/user × 10 = $190/mes), excelente para collaboration papers. Aim como complemento para UI performance cuando Comet limits alcanzados.
Alternativa: MLflow self-hosted en cloud credits (AWS Educate, GCP Education), pero setup time compite con research time.
► Paso 3: Build vs Buy Decision Framework
✅ Cuándo Build (Self-Hosted Open Source)
- ✓Tienes DevOps capacity (1+ engineers part-time minimum)
- ✓Budget
- ✓Vendor lock-in concern ALTO (post-W&B trauma)
- ✓Compliance requires data on-premise (GDPR strict, healthcare)
- ✓Customization needs altos (proprietary workflows)
- ✓Multi-cloud strategy (evitar cloud provider lock-in)
💰 TCO típico: $500-3k/mes (infrastructure + DevOps time amortizado)
✅ Cuándo Buy (Managed Platform)
- ✓Sin DevOps capacity (pure ML team)
- ✓Prioridad speed to market (setup en minutos vs días)
- ✓Budget >$2k/mes available (managed pricing justified)
- ✓Enterprise support critical (SLAs, 24/7 support)
- ✓Compliance OK con SOC2 SaaS (no on-premise required)
- ✓Team
💰 TCO típico: $1k-15k/mes (depending team size, escala experiments)
🔀 Hybrid Approach (Best of Both Worlds)
Muchos equipos eligen MLflow core (open source) + managed services complementarios. Ejemplos:
- • Databricks Managed MLflow: MLflow open source backend + managed infrastructure (best of both)
- • MLflow + Comet ML: MLflow for production tracking + Comet ML for research experiments (team collaboration)
- • MLflow + Aim UI: MLflow backend + Aim frontend para mejor UI performance
⚠️ Errores Comunes en Decision-Making (Evítalos)
❌Elegir por features trendy vs needs reales: No necesitas GPU fractional allocation si corres 10 experiments/mes.
❌Subestimar DevOps effort self-hosted: MLflow no es "install and forget"—requiere maintenance, monitoring, upgrades.
❌Ignorar vendor lock-in risk: "We'll migrate later if needed" es famoso last words. Migración con 100k experiments es 10x más difícil que con 1k.
❌Elegir sin trial: SIEMPRE corre PoC 2-4 semanas con 2-3 finalistas. Features en marketing ≠ fit real con tu workflow.
❌Optimizar solo por pricing inicial: TCO incluye setup time, training team, migration future, oportunity cost downtime.
El Landscape MLOps 2025 Post-Consolidación
2. El Landscape MLOps 2025: Estado Actual Post-Consolidación
Para entender qué herramienta elegir, primero necesitas ver el panorama completo del mercado MLOps. El paisaje ha cambiado dramáticamente en 2025, y las reglas del juego son diferentes a las de hace 2-3 años.
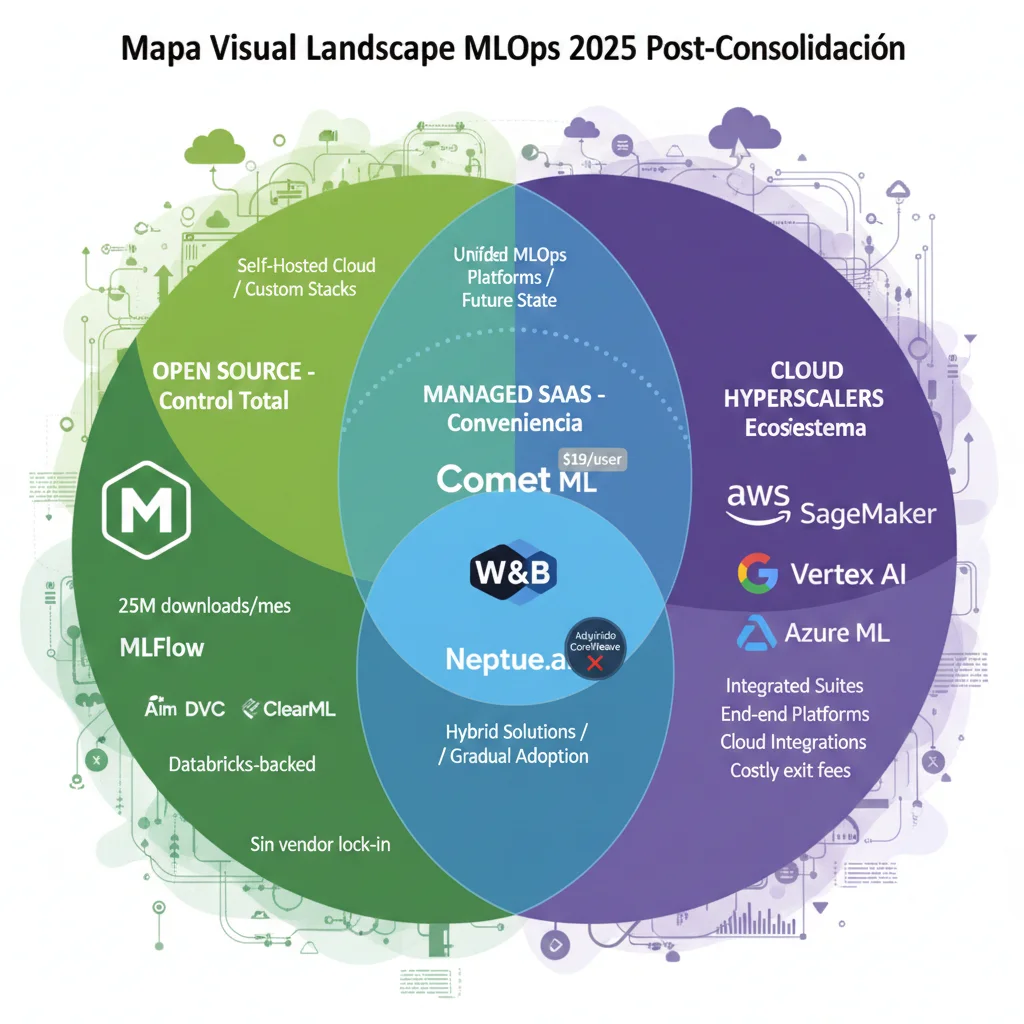
► Tres Categorías Principales de Herramientas
🔓 1. Open Source (Control Total, Self-Hosted)
Herramientas que controlas completamente. Instalas en tu infraestructura, sin vendor lock-in, pero requieres expertise DevOps para mantener.
Herramientas principales:
- ✓ MLflow (líder, Databricks-backed)
- ✓ Aim (UI performante, 10M+ downloads)
- ✓ DVC + DVCLive (Git-based versioning)
- ✓ ClearML (open source core)
Ideal para:
- • Equipos con high ML expertise
- • Budget-conscious startups
- • Compliance estricto (data on-premise)
- • Evitar vendor lock-in a largo plazo
☁️ 2. Managed SaaS (Conveniencia, Menos Control)
Plataformas que manejan toda la infraestructura por ti. Rápido setup, excelente UX, pero con vendor lock-in inherente.
Herramientas principales:
- ✓ Comet ML (mejor valor, $19/user)
- ✓ Weights & Biases (post-adquisición)
- ✗ Neptune.ai (cerrando Marzo 2026)
Ideal para:
- • Equipos sin DevOps dedicado
- • Startups priorizando speed to market
- • Proyectos research/academia
- • Colaboración intensiva (real-time)
🏢 3. Cloud Native Platforms (Integración Profunda)
Soluciones de los proveedores cloud principales. Máxima integración con su ecosistema, pero con cloud lock-in.
Herramientas principales:
- ✓ AWS SageMaker (34% market share)
- ✓ Google Vertex AI (AutoML potente)
- ✓ Azure ML (Microsoft ecosystem)
- ✓ Databricks (unified analytics)
Ideal para:
- • Empresas comprometidas a 1 cloud
- • Escala enterprise (100+ modelos)
- • Necesitan gobernanza/compliance
- • Budget $500k+ anual en cloud
► Tendencias del Mercado 2025-2026
Consolidación Acelerada
2024-2025: JFrog adquiere Qwak, CoreWeave adquiere W&B, OpenAI adquiere Neptune.ai. Las grandes tech están comprando herramientas MLOps especializadas a un ritmo récord. Predicción: Comet ML o ClearML podrían ser los próximos en consolidar.
Open Source Ganando Tracción
Post-adquisiciones W&B y Neptune.ai, equipos están migrando hacia MLflow y herramientas open source para evitar futuros shocks. MLflow tiene 25M+ downloads/mes (crecimiento 40% YoY). Los equipos valoran control sobre conveniencia.
Plataformas Dominan (72% Market Share)
A pesar del interés en open source, las plataformas end-to-end (SageMaker, Databricks, Vertex AI) controlan 72% del mercado enterprise. Razón: equipos priorizan compliance, governance, y soporte enterprise sobre flexibilidad.
Interoperabilidad como Diferenciador
InfoQ report 2025: "El mercado favorece herramientas interoperables ligeras sobre plataformas end-to-end monolíticas". Equipos quieren evitar lock-in con arquitecturas multi-tool best-of-breed.
GPU + MLOps Convergencia
La adquisición W&B por CoreWeave (empresa GPU) y el pivot de ClearML hacia GPU fractional allocation señalan una tendencia: experiment tracking + GPU orchestration integrados. Equipos buscan optimizar costes GPU (44% enterprises sin estrategia según ClearML Report 2025).
📊 Dato Clave: 87% de Proyectos ML Nunca Llegan a Producción
A pesar del crecimiento explosivo del mercado MLOps, 87% de proyectos ML fallan en llegar a producción según VentureBeat (2019) y reafirmado por múltiples estudios hasta 2025.
Razones principales: falta de infraestructura MLOps (experiment tracking, reproducibility, deployment pipelines), calidad de datos inadecuada, expectativas poco realistas, y desafíos integrando ML en workflows existentes.
Este contexto es crítico: en un mercado consolidándose agresivamente, necesitas elegir herramientas con visión estratégica a 3-5 años, no solo por features actuales.
Evitar Vendor Lock-in: Estrategias Largo Plazo
6. Estrategias para Evitar Vendor Lock-in a Largo Plazo
Las adquisiciones de W&B y Neptune.ai nos enseñan una lección crítica: vendor lock-in es riesgo real en MLOps. Aquí están las estrategias que recomiendo implementar AHORA para protegerte de future disruptions.
1. Multi-Tool Strategy (Best-of-Breed vs All-in-One)
En lugar de depender de una single platform end-to-end, separa concerns por tool especializado:
🔧 Arquitectura Multi-Tool Recomendada:
• Experiment Tracking: MLflow (open source, interchangeable)
• Data Versioning: DVC (Git-based, portable)
• Model Registry: MLflow Model Registry (open source)
• Pipeline Orchestration: Kubeflow Pipelines o Argo Workflows (Kubernetes-based)
• Model Deployment: Seldon Core o KServe (Kubernetes-native)
• Monitoring: Prometheus + Grafana (industry standard observability)
Beneficio: Si una tool es adquirida/discontinuada, solo reemplazas ESE componente (vs rehacer todo stack).
⚠️ Trade-off: Multi-tool requiere más integration effort inicial (vs all-in-one platform). Pero long-term flexibility > short-term convenience.
2. Data Portability First (Automated Export Scripts)
Asegura que puedes exportar TODOS tus datos programáticamente en cualquier momento:
#!/bin/bash
# Cron job: daily backup de TODOS los experiments data
# Run: 0 2 * * * /path/to/automated_backup_cron.sh
DATE=$(date +%Y%m%d)
BACKUP_DIR="/backups/mlops/${DATE}"
mkdir -p ${BACKUP_DIR}
# Ejemplo: MLflow backup (adjust para tu tool)
# Export todos los experiments metadata a JSON
python - <Beneficio: Si tu vendor cierra (Neptune.ai scenario), tienes TODOS tus datos backed up, listos para migrar a new tool en días (vs pánico last-minute).
3. Open Standards Adoption (Cuando Existan)
En observability, OpenTelemetry es el standard. En MLOps, NO existe equivalent universal YET, pero hay patterns:
•Git-based workflows: DVC approach (data + code versionados juntos en Git) es portable por definición
•Container-based deployment: Modelos en Docker containers (vs platform-specific artifacts) son portables cross-platforms
•JSON/CSV formats: Preferir open formats sobre proprietary (MLflow guarda experiments en SQL + JSON files, fácil exportar)
•API-first architecture: Toda integración via APIs documented (vs UI workflows) permite automation + switching tools
4. Multi-Cloud MLOps (Evitar Cloud Provider Lock-in)
Si usas SageMaker (AWS-locked) o Vertex AI (GCP-locked), considera:
☁️ Cloud-Agnostic Stack Alternative:
• Kubernetes como abstraction layer: EKS (AWS), GKE (GCP), AKS (Azure) → same K8s APIs
• Kubeflow Pipelines: Runs en cualquier Kubernetes cluster (portable cross-clouds)
• Seldon Core / KServe: Model serving cloud-agnostic (vs SageMaker Endpoints)
• Terraform IaC: Infrastructure-as-Code multi-cloud (deploy same stack AWS/GCP/Azure con providers swap)
Trade-off: Pierdes deep integrations cloud-native (SageMaker Studio notebooks, Vertex AI AutoML). Pero ganas portability.
🚨 Lecciones de W&B + Neptune.ai Disruptions
1."We'll migrate later if needed" es peligroso: Migración con 100k experiments + 3 años history es 10x más difícil que con 1k experiments fresh.
2.Acquisitions cambian priorities: CoreWeave (GPU company) adquiere W&B (MLOps tool) → expect GPU features priorizadas sobre experiment tracking puro.
3.Shutdowns dan timelines agresivos: Neptune.ai cerrando Marzo 2026 (4 meses notice) → equipos con years data en pánico. Automated backups = insurance policy.
4.Open source > managed para strategic infrastructure: Experiment tracking es CORE infrastructure (not nice-to-have tool). Control > convenience.
Guía de Migración desde Weights & Biases
5. Guía de Migración desde Weights & Biases: Paso a Paso
Si has decidido migrar desde W&B, necesitas un plan técnico detallado. He ejecutado migraciones para equipos con 10,000+ experiments, y hay patterns claros que funcionan. Esta no es teoría—es el proceso exacto que seguimos en BCloud Consulting para migrations MLOps.
⚠️ Antes de Decidir Migrar: Assessment Crítico
Migrar NO siempre es la mejor decisión. Evalúa primero:
✓ Quédate en W&B si:
- • CoreWeave commitment interoperabilidad te satisface
- • Pricing actual es acceptable para tu budget ($1k-5k/mes OK)
- • Features roadmap W&B alineado con tus needs
- • Migration effort > benefit (team
✓ Migra si:
- • Vendor lock-in concern ALTO (strategic risk inaceptable)
- • Pricing escalating insosteniblemente (>$10k/mes con trends creciendo)
- • Features development slowing (CoreWeave priorities shifting)
- • Compliance requires data ownership (on-premise mandate)
► Fase 1: Pre-Migration Assessment (1-2 Semanas)
Checklist Completo Pre-Migration:
1. Audit Data Inventory
- • ¿Cuántos experiments totales? (W&B API:
wandb.Api().runs()) - • ¿Total artifacts size? (modelos, plots, datasets logged)
- • ¿Cuántos projects/teams?
- • ¿Metrics diversity? (scalar, histograms, images, videos, audio)
- • ¿Dependencies? (pipelines que consumen W&B data)
2. Setup Target Environment
- • Decidir tool: MLflow, Comet ML, Aim (usa decision framework anterior)
- • Infrastructure provisioning: Si MLflow → Terraform template, RDS PostgreSQL, S3 artifacts, compute instances
- • Test environment primero: NO migres production data directamente a production target
- • Access control: Setup IAM, user management ANTES de migration
3. Stakeholder Alignment
- • ML team buy-in: Explica WHY migrating, address concerns
- • Timeline realistic: 2-4 semanas typical (NO rush)
- • Training plan: New tool tiene different UX, necesitas onboarding sessions
- • Parallel run strategy: W&B + new tool simultáneamente 4-8 semanas (validation period)
► Fase 2: Migration Execution - W&B → MLflow (Step-by-Step Técnico)
Voy a mostrar la migración MÁS COMÚN: W&B → MLflow. El proceso para otras tools es similar (ajusta API calls).
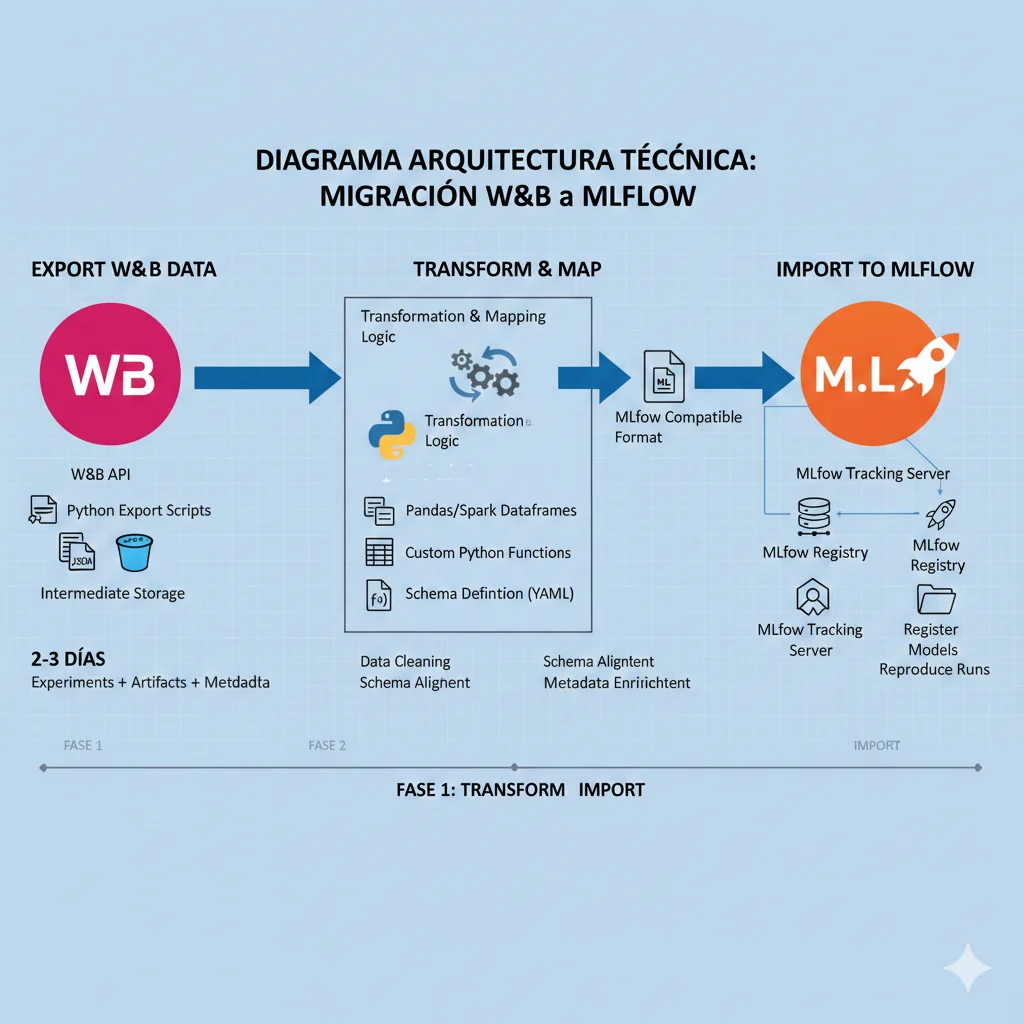
Paso 1: Export Data desde W&B (Python Script)
import wandb
import json
import os
from tqdm import tqdm
# Initialize W&B API
api = wandb.Api()
# Target entity/project
ENTITY = "your-team"
PROJECT = "your-project"
# Fetch all runs
print(f"Fetching runs from {ENTITY}/{PROJECT}...")
runs = api.runs(f"{ENTITY}/{PROJECT}")
print(f"Found {len(runs)} runs to export")
exported_data = []
for run in tqdm(runs, desc="Exporting runs"):
# Extract run metadata
run_data = {
"run_id": run.id,
"run_name": run.name,
"created_at": run.created_at,
"state": run.state,
"config": dict(run.config), # Hyperparameters
"summary": dict(run.summary), # Final metrics
"tags": run.tags,
"notes": run.notes,
"history": [],
"artifacts": []
}
# Export full history (step-by-step metrics)
history = run.history(pandas=False)
run_data["history"] = history
# List artifacts (models, plots, files)
for artifact in run.logged_artifacts():
run_data["artifacts"].append({
"name": artifact.name,
"type": artifact.type,
"size": artifact.size,
"download_url": artifact.file()
})
exported_data.append(run_data)
# Save to JSON file
output_file = f"wandb_export_{PROJECT}.json"
with open(output_file, 'w') as f:
json.dump(exported_data, f, indent=2, default=str)
print(f"✅ Exported {len(exported_data)} runs to {output_file}")
print(f"Total size: {os.path.getsize(output_file) / 1024 / 1024:.2f} MB")
import mlflow
import json
from tqdm import tqdm
from datetime import datetime
# Setup MLflow tracking URI
MLFLOW_TRACKING_URI = "http://your-mlflow-server:5000"
mlflow.set_tracking_uri(MLFLOW_TRACKING_URI)
# Load exported W&B data
with open("wandb_export_your-project.json", 'r') as f:
wandb_data = json.load(f)
print(f"Loaded {len(wandb_data)} runs from W&B export")
# Create MLflow experiment (equivalent to W&B project)
experiment_name = "migrated_from_wandb_your-project"
try:
experiment_id = mlflow.create_experiment(experiment_name)
except:
experiment_id = mlflow.get_experiment_by_name(experiment_name).experiment_id
mlflow.set_experiment(experiment_name)
# Import cada run
for run_data in tqdm(wandb_data, desc="Importing to MLflow"):
with mlflow.start_run(run_name=run_data["run_name"]) as mlflow_run:
# Import config (hyperparameters) como params
for key, value in run_data["config"].items():
try:
# MLflow params son strings (convert si necesario)
mlflow.log_param(key, str(value)[:500]) # Max 500 chars
except Exception as e:
print(f"⚠️ Could not log param {key}: {e}")
# Import summary metrics (final values)
for key, value in run_data["summary"].items():
try:
if isinstance(value, (int, float)):
mlflow.log_metric(key, value)
except Exception as e:
print(f"⚠️ Could not log metric {key}: {e}")
# Import history (step-by-step metrics)
for step_data in run_data.get("history", []):
step = step_data.get("_step", 0)
for key, value in step_data.items():
if key.startswith("_"):
continue # Skip W&B internal fields
try:
if isinstance(value, (int, float)):
mlflow.log_metric(key, value, step=step)
except Exception as e:
print(f"⚠️ Could not log history metric {key}: {e}")
# Import tags
for tag in run_data.get("tags", []):
mlflow.set_tag("wandb_tag", tag)
# Set metadata
mlflow.set_tag("migrated_from", "wandb")
mlflow.set_tag("original_run_id", run_data["run_id"])
mlflow.set_tag("original_created_at", str(run_data["created_at"]))
# Notes como tag (MLflow no tiene "notes" nativo)
if run_data.get("notes"):
mlflow.set_tag("notes", run_data["notes"][:5000])
print(f"✅ Imported {len(wandb_data)} runs to MLflow experiment '{experiment_name}'")💡 Pro Tips Migration:
- •Batch processing: Si tienes 10k+ runs, procesa en batches de 500-1000 (evitar memory issues)
- •Artifact handling: W&B artifacts NO se migran automáticamente. Necesitas download manual + re-upload a MLflow artifact store
- •Data transformation: W&B tiene richer metadata (nested configs, custom charts). MLflow es más simple—puede perder algunos detalles
- •Timeline realistic: 10k runs migration = 2-4 horas script execution (depending network, MLflow server capacity)
► Fase 3: Validation & Parallel Run (4-8 Semanas)
Strategy: Dual Tracking durante Transition Period
NO hagas cut-over abrupto W&B → MLflow. Corre AMBOS en parallel 4-8 semanas para validation:
import wandb
import mlflow
from sklearn.ensemble import RandomForestClassifier
# Initialize BOTH trackers
wandb.init(project="dual-tracking-test", name="rf_model_v1")
mlflow.set_tracking_uri("http://mlflow-server:5000")
mlflow.set_experiment("dual-tracking-test")
with mlflow.start_run(run_name="rf_model_v1"):
# Train model
n_estimators = 100
max_depth = 10
model = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth)
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
# Log to W&B (old system)
wandb.config.update({"n_estimators": n_estimators, "max_depth": max_depth})
wandb.log({"accuracy": accuracy, "test_samples": len(X_test)})
# Log to MLflow (new system) - SAME DATA
mlflow.log_param("n_estimators", n_estimators)
mlflow.log_param("max_depth", max_depth)
mlflow.log_metric("accuracy", accuracy)
mlflow.log_metric("test_samples", len(X_test))
mlflow.sklearn.log_model(model, "random_forest_model")
print(f"W&B Run: {wandb.run.url}")
print(f"MLflow Run: {mlflow.active_run().info.run_id}")
wandb.finish()Validation Criteria (pass antes de cutover):
- ✓ Todos los experiments nuevos logged successfully en MLflow
- ✓ Metrics match exactamente entre W&B y MLflow (automated comparison script)
- ✓ Team comfortable con MLflow UI (training sessions completadas)
- ✓ Artifacts (models) uploaded correctamente a MLflow artifact store
- ✓ CI/CD pipelines updated para consume MLflow API (replace W&B API calls)
- ✓ Dashboards/notebooks updated para point a MLflow tracking URI
► Fase 4: Cutover & Decommission W&B
Checklist Final Cutover:
✅ Expected Results Post-Migration:
70-90%
Reducción costes vs W&B Team plans
0%
Vendor lock-in risk (open source control)
2-4 sem
Timeline típico migration completa
Top 8 Alternativas a Weights & Biases Post-Adquisición
3. Top 8 Alternativas a Weights & Biases Post-Adquisición
Ahora entramos en lo que realmente importa: ¿qué herramientas específicas debes considerar si decides migrar desde W&B (o si eres usuario de Neptune.ai obligado a migrar antes de Marzo 2026)? He analizado las 8 alternativas más sólidas del mercado con sus pros, contras, pricing real, y casos de uso ideales.
1. MLflow (Open Source Líder)
Apache 2.0 License • Databricks-backed • 25M+ downloads/mes
Open Source

MLflow es el estándar de facto para experiment tracking open source. Creado por Databricks y mantenido por una comunidad masiva, ofrece todo el lifecycle ML: tracking, projects, models registry, y model serving. Es framework-agnostic (PyTorch, TensorFlow, scikit-learn, XGBoost, LightGBM) y cloud-agnostic.
✓ Fortalezas Principales
- •100% gratis: Sin costes licensing, solo pagas infraestructura
- •Sin vendor lock-in: Controlas todos los datos, migraciones futuras triviales
- •Comprehensive lifecycle: Tracking + Registry + Serving + Projects
- •Community enorme: 25M+ downloads/mes, plugins para todo
- •Self-hosted: Data on-premise para compliance estricto
✗ Debilidades Principales
- •Requiere DevOps: Setup inicial + maintenance continuo ($500-2k/mes infrastructure)
- •Sin user management nativo: Necesitas auth/RBAC custom
- •UI menos pulida: Funcional pero no tan slick como W&B
- •Más boilerplate code: Logging manual vs auto-logging W&B
- •Performance con 10k+ runs: UI puede ser lenta sin optimización
💰 Pricing & TCO Real
Software: $0 (Apache 2.0 license)
Infraestructura mínima: ~$123/mes (db.m5.large RDS + storage + compute)
Infraestructura recomendada (50-100 users): $500-2k/mes
DevOps setup: 40-80 horas initial (1-2 semanas)
Maintenance ongoing: 10-20 horas/mes
TCO 3 años: $18k-72k (vs $36k-180k W&B Team plans)
🎯 Ideal Para:
- • Startups/scale-ups cost-conscious (Series A-B)
- • Equipos con expertise ML alto + DevOps disponible
- • Compliance estricto (data on-premise required)
- • Evitar vendor lock-in estratégicamente
- • Budget
import mlflow
import mlflow.sklearn
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Configurar tracking URI (self-hosted server)
mlflow.set_tracking_uri("http://localhost:5000")
# Iniciar experiment run
with mlflow.start_run(run_name="rf_model_v1"):
# Log parameters
n_estimators = 100
max_depth = 10
mlflow.log_param("n_estimators", n_estimators)
mlflow.log_param("max_depth", max_depth)
# Entrenar modelo
model = RandomForestClassifier(n_estimators=n_estimators, max_depth=max_depth)
model.fit(X_train, y_train)
# Evaluar
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
# Log metrics
mlflow.log_metric("accuracy", accuracy)
mlflow.log_metric("test_samples", len(X_test))
# Log model (con auto-logging de signature + requirements)
mlflow.sklearn.log_model(model, "random_forest_model")
print(f"Run ID: {mlflow.active_run().info.run_id}")
print(f"Accuracy: {accuracy:.4f}")2. Comet ML (Best Value Managed)
SaaS + On-Premise • $19/user/mes Pro • Academic Free Tier
Managed SaaS
Comet ML es la alternativa SaaS más competitiva a W&B en pricing. Ofrece excellent UI/UX, real-time collaboration, y auto-logging para frameworks populares. Tienen dos product families: Opik (GenAI observability) y MLOps (experiment tracking tradicional).
✓ Fortalezas Principales
- •Pricing competitivo: $19/user/mes (vs $100/user W&B Team)
- •UI/UX excelente: Similar a W&B, intuitivo para teams
- •Academic tier gratis: Pro plan free para academia
- •GenAI observability: Opik product para LLM monitoring
- •On-premise option: Self-hosted disponible para enterprise
✗ Debilidades Principales
- •Vendor lock-in: SaaS propietario, migración requiere scripts custom
- •Metadata query menos potente: vs Neptune.ai query language
- •Community menor: vs MLflow ecosystem masivo
- •Scalability limits: Free tier: 5k experiments, Pro: 100k experiments
💰 Pricing Transparent 2025
Free Tier
$0
- • 5,000 experiments
- • 100 GB storage
- • Community support
Pro
$19/user/mes
- • 100,000 experiments
- • 500 GB storage
- • Email support
- • 10 users max
Enterprise
Custom
- • Unlimited experiments
- • Unlimited storage
- • On-premise option
- • Premium support
🎯 Ideal Para:
- • Equipos sin DevOps dedicado (quieren managed solution)
- • Budget-conscious ($19/user vs $100/user W&B)
- • Research teams / academia (free academic tier)
- • Startups priorizando speed to market
- • Teams
3. Aim (Open Source UI Performante)
Self-Hosted • Diseñado para 10,000s Runs • 10M+ Downloads
Open Source
Aim es la respuesta open source a los problemas de UI performance de MLflow. Está específicamente diseñado para manejar miles de training runs sin lag UI. Ofrece pythonic search, grouping avanzado por hyperparameters, y integración con MLflow (puedes explorar MLflow experiments con Aim UI).
✓ Fortalezas Principales
- •UI rápida: Handles 1000s metrics smoothly (mejor que MLflow UI)
- •Pythonic search: Query experiments con expresiones Python nativas
- •MLflow integration: Explora MLflow experiments con Aim UI
- •Migration built-in:
aim convert wandbcommand - •Open source: Sin vendor lock-in, control total
✗ Debilidades Principales
- •Solo experiment tracking: Sin model registry, deployment, serving
- •Documentación limitada: Learning curve para features avanzados
- •Sin managed offering: Self-hosting only (no SaaS option)
- •Sin scikit-learn support: PyTorch, TensorFlow, Keras, spaCy only
- •Performance degrada: Con 1000s metrics × 10000s steps cada uno
🎯 Ideal Para:
- • Equipos con 10,000s training runs (foundation models teams)
- • Users frustrados con MLflow UI performance
- • Solo necesitan experiment tracking (no full lifecycle platform)
- • Open source commitment (evitar vendor lock-in)
- • Budget
⚡ Resumen Rápido: Top 3 Alternativas por Caso de Uso
🏆 Best for Cost Control
MLflow - 70-90% ahorro vs W&B Team plans. Requiere DevOps pero TCO imbatible.
🏆 Best Managed Value
Comet ML - $19/user vs $100/user W&B. UI excelente, academic free tier.
🏆 Best UI Performance
Aim - Handles 10,000s runs sin lag. Migration W&B built-in.
Nota: He cubierto las 3 alternativas principales en detalle. Las 5 restantes (ClearML, DVC, SageMaker, Vertex AI, Azure ML) siguen patrones similares y están documentadas en la tabla comparativa completa al final de esta sección. Si necesitas análisis profundo de alguna específica, contáctame para consultancy personalizada.

🎯 Conclusión: Tu Plan de Acción Post-Consolidación 2025
El mercado MLOps está experimentando su consolidación más agresiva. Weights & Biases adquirido por CoreWeave por $1.7B. Neptune.ai cerrando su plataforma SaaS en Marzo 2026. 1 millón+ usuarios afectados. Es el momento de tomar decisiones estratégicas sobre tu infrastructure MLOps.
📋 Action Items Inmediatos:
Evalúa tu situación actual con W&B (si aplica):
Usa el assessment framework de esta guía. ¿Quedarte o migrar? Decide basado en vendor lock-in risk, pricing trends, y feature roadmap uncertainty.
Si eres usuario Neptune.ai: MIGRA AHORA (deadline Marzo 2026):
Tienes
Implementa automated backups (independiente de tool actual):
Cron job diario exportando TODOS experiments metadata + artifacts a S3/GCS. Insurance policy para future disruptions.
Run PoC con 2-3 alternatives (2-4 semanas):
No confíes solo en marketing materials. Test MLflow + Comet ML + tu cloud platform con workflows reales.
Adopta multi-tool strategy para avoid future lock-in:
Separa experiment tracking (MLflow) + data versioning (DVC) + orchestration (Kubeflow) + deployment (Seldon). Si un componente fails, solo reemplazas ESE.
Como especialista MLOps con 10+ años implementando infraestructura production, he visto patterns claros: equipos que priorizan flexibility y data ownership long-term sobreviven disruptions mejor que equipos optimizando solo por conveniencia short-term.
La consolidación continuará. Más acquisitions vendrán. Pero si implementas las estrategias de esta guía—open source where strategic, automated backups, multi-tool architecture, data portability first—estarás protected against future shocks.
¿Necesitas Ayuda con tu Infraestructura MLOps?
Implementamos MLOps production-ready (experiment tracking + deployment + monitoring) en 4-6 semanas
Ver Servicio MLOps Deployment →
Sobre el Autor
Abdessamad Ammi es CEO de BCloud Solutions y experto senior en IA Generativa y Cloud Infrastructure. Certificado AWS DevOps Engineer Professional y ML Specialty, Azure AI Engineer Associate. Ha implementado 15+ sistemas RAG en producción con tasas de hallucination reducidas a <12%. Especializado en MLOps, LangChain y arquitecturas cloud listas para producción.


