

Por Qué MLOps Está Muerto Para AI Agents: Las 5 Incompatibilidades Fatales
MLOps Está Muerto, AgentOps Es El Futuro: Por Qué Tu Pipeline de ML Es Obsoleto en 2026
Framework completo de migración production-ready para evitar el destino del 40% de proyectos agentic AI que serán cancelados antes de 2027.
de proyectos agentic AI serán cancelados antes de finales de 2027
Si eres CTO, VP of Engineering, o Tech Lead en una startup SaaS y estás implementando agentes autónomos de IA, probablemente estés usando las herramientas equivocadas sin saberlo.
Tu pipeline MLOps con MLflow, Kubeflow, o SageMaker funciona perfectamente para modelos tradicionales de ML. Entrenas un modelo de clasificación, lo despliegas como endpoint, monitorizas accuracy y latency, y todo está bajo control. Simple, predecible, reproducible.
Pero cuando intentas aplicar las mismas herramientas a agentes autónomos que razonan, planifican, usan herramientas externas, y toman decisiones en múltiples turnos conversacionales... todo se rompe.
El problema no eres tú. Es que MLOps fue diseñado para un paradigma completamente diferente. Agentes autónomos requieren un enfoque nuevo: AgentOps.
Por qué este artículo es diferente
No es teoría. Es el framework exacto que uso para migrar clientes de MLOps a AgentOps en proyectos de $12k-35k. Incluye:
- • Framework de migración de 30 puntos con timelines reales
- • Comparación técnica profunda de 5 herramientas AgentOps (AgentOps.ai, LangSmith, Langfuse, Datadog, Arize)
- • Código Python implementable para AgentOps.ai, LangSmith, y cost tracking
- • Análisis TCO completo: MLOps vs AgentOps con números reales
- • Checklist de 25 puntos para deployment production-ready
- • Case study real: reducción 92% debugging time, 69% cost reduction, 73% task completion improvement
Al final de este artículo, tendrás el roadmap completo para evaluar si necesitas AgentOps, qué herramientas usar, y cómo ejecutar la migración sin romper producción.
1. Por Qué MLOps Está Muerto Para AI Agents: Las 5 Incompatibilidades Fatales
MLOps se construyó sobre un paradigma simple: input → modelo → predicción. Entrenas un modelo con datos históricos, lo despliegas, y cada inferencia sigue el mismo flujo predecible. Pero los agentes autónomos operan de forma fundamentalmente diferente.
⚠️ La Realidad Brutal
MIT Research (2025) encontró que el 95% de pilotos de agentes autónomos fallan al intentar escalarse a producción. La razón principal: intentar usar herramientas MLOps tradicionales para gestionar workloads agentic.
► Incompatibilidad #1: Paradigma de Ejecución
| Dimensión | MLOps (Tradicional) | AgentOps (Agentic AI) |
|---|---|---|
| Paradigma | Input → Predicción (single-turn) | Razonamiento → Planificación → Acción → Reflexión (multi-turn) |
| Determinismo | Reproducible (mismo input = mismo output) | No determinista (LLM stochasticity + external tools) |
| Métricas | Accuracy, precision, recall, F1 | Task completion rate, tool usage correctness, reasoning quality |
| Debugging | Reproducible via inputs + model version | Requires full session replay (multi-turn context + tool calls) |
| Costo Inferencia | Lineal (1 input = 1 inferencia) | Exponencial multi-agente (1 query = 10-50 LLM calls) |
| Herramientas | MLflow, Kubeflow, SageMaker | AgentOps.ai, LangSmith, Langfuse, Datadog LLM Observability |
Observa la tabla. No son pequeñas diferencias de implementación. Son incompatibilidades fundamentales de arquitectura.
► Incompatibilidad #2: Métricas Inútiles
En MLOps tradicional, mides accuracy del modelo. Si tu clasificador de imágenes tiene 95% accuracy en el test set, sabes que funcionará bien en producción.
Pero ¿cómo mides el "accuracy" de un agente autónomo de customer support que:
- • Decide qué herramientas usar (search, database query, API call)
- • Razona sobre múltiples turnos conversacionales con contexto cambiante
- • Escala a humano cuando detecta incertidumbre
- • Toma decisiones basándose en información retrieved de una vector database
La respuesta: no puedes. Necesitas métricas completamente nuevas:
Métricas AgentOps Críticas:
Task Completion Rate
¿El agente resolvió completamente la tarea del usuario sin escalación?
Tool Usage Correctness
¿Llamó las herramientas correctas con parámetros válidos?
Reasoning Quality
¿El razonamiento step-by-step fue lógico y coherente?
Hallucination Rate
¿Inventó información no verificada?
Escalation Rate
¿Cuántas veces escaló a humano correctamente?
Cost per Task
Total LLM API costs para completar una tarea específica
MLflow y Kubeflow no entienden estas métricas. No tienen conceptos de "tool calls", "multi-turn sessions", "reasoning chains". Intentar trackearlas manualmente es infierno.
► Incompatibilidad #3: Debugging No Determinista
En MLOps tradicional, debugging es relativamente simple. Si un modelo falla en una predicción específica:
- Identificas el input exacto que causó el error
- Reproduces la inferencia con el mismo model version + input
- Debuggeas con logging, profiling, etc.
Pero con agentes autónomos, esto no funciona. Un mismo query puede generar decisiones completamente diferentes debido a:
- ✗ LLM stochasticity (temperature > 0)
- ✗ External tool results cambiantes (APIs, databases)
- ✗ Context acumulado de turnos previos
- ✗ Retrieval results variando según embeddings/ranking
"Debugging Multi-Agent Hell: 4-Hour Sessions Hunting JSON"
Evil Martians Engineering Blog (2024) documenta el pain point #1 de developers trabajando con multi-agent systems: debugging sessions que toman 4+ horas porque no existe "git blame" para decisiones de agentes.
Necesitas session replay completo: cada LLM call, cada tool invocation, cada decision point, con timestamps y contexto. MLOps tools no fueron diseñados para esto.
► Incompatibilidad #4: Cost Model Exponencial
En MLOps tradicional, el coste de inferencia es lineal y predecible. Cada input genera 1 inferencia. Si tienes 10,000 requests/día y cada inferencia cuesta $0.001, tu coste diario es $10. Simple.
Agentes autónomos multi-agente tienen un cost model completamente diferente:
Cost Explosion Real: Single-Agent vs Multi-Agent
Single-Agent Simple (Chatbot RAG)
- • 1 user query
- • 1 embedding call (query)
- • 1 vector search
- • 1 LLM call (generation)
- = $0.05 - $0.10 por query
Multi-Agent Complex (Customer Support)
- • 1 user query
- • 1 supervisor agent LLM call (routing)
- • 5-10 tool agent LLM calls (execution + reasoning)
- • 2-3 retrieval agent calls (database queries)
- • 1 synthesis agent LLM call (final response)
- = $0.80 - $1.50 por query (15x)
Para 10,000 queries/día, esto significa:
Single-Agent
$1,500/mes
10k queries × $0.10 × 30 días
Multi-Agent (sin optimización)
$45,000/mes
10k queries × $1.50 × 30 días (30x más caro)
Sin herramientas de cost tracking específicas para agentes (que tracken cost per agent, per tool, per session), tu factura OpenAI/Anthropic explota sin que entiendas por qué.
► Incompatibilidad #5: Governance & Security
MLOps tradicional tiene governance relativamente simple: versionas modelos, trackeas experiments, controlas acceso a training data.
Agentes autónomos introducen riesgos de seguridad completamente nuevos:
Estadísticas de Seguridad Agentic AI 2025:
Necesitas governance para:
- • Qué herramientas puede invocar cada agente (RBAC granular)
- • Qué datos puede acceder (data masking)
- • Auditoría completa de decisiones (compliance)
- • Guardrails para prevenir prompt injection
MLflow y Kubeflow no tienen conceptos de "tool permissions" o "agent RBAC". Necesitas plataformas AgentOps específicas.
💡 Conclusión Sección 1
No es que MLOps sea "malo". Es que fue diseñado para un paradigma diferente. Intentar forzar agentes autónomos en herramientas MLOps es como intentar conducir un Tesla con herramientas de carruajes de caballos. Funcionalmente incompatible.
AgentOps Tool Ecosystem 2026: Deep Dive Comparison
4. AgentOps Tool Ecosystem 2026: Deep Dive Comparison
El mercado de herramientas AgentOps está explotando. AI Observability Market (foundation de AgentOps) pasó de $1.4B (2023) → $10.7B proyectado (2033), CAGR 22.5% (Precedence Research).
Voy a comparar las 5 plataformas principales que uso en proyectos production-ready de $12k-35k.
► Tool #1: AgentOps.ai
AgentOps.ai
Session Replay + Multi-Agent Observability Specialist
✅ Fortalezas:
- • Session replay visual más potente del mercado
- • 400+ integraciones (LangChain, LlamaIndex, CrewAI, AutoGen)
- • Overhead mínimo (~12% latency increase)
- • Dashboard intuitivo para no-developers
- • Pricing competitive (free tier generoso)
⚠️ Limitaciones:
- • No self-hosted (cloud-only)
- • Governance features básicas vs enterprise
- • Cost tracking menos granular que LangSmith
Pricing:
# Integración AgentOps.ai con LangChain
import agentops
from langchain.agents import initialize_agent, Tool
from langchain.llms import OpenAI
# Inicializar AgentOps con tu API key
agentops.init(api_key="tu_api_key_aqui")
# Configurar agent LangChain normal
llm = OpenAI(temperature=0)
tools = [
Tool(name="Search", func=search_function, description="Busca información"),
Tool(name="Calculator", func=calc_function, description="Calcula matemáticas")
]
agent = initialize_agent(
tools=tools,
llm=llm,
agent="zero-shot-react-description",
verbose=True
)
# Ejecutar con tracking automático AgentOps
# AgentOps captura TODOS los LLM calls, tool invocations, reasoning steps
result = agent.run("¿Cuál es la raíz cuadrada de 144 más información sobre Python?")
# Session replay disponible en dashboard AgentOps.ai
# Visualizas: timeline completo, cada LLM call, cada tool invocation, costes
agentops.end_session("Success") # Marca sesión como exitosa ► Tool #2: LangSmith
LangSmith
LangChain Native Observability + Evaluation Platform
✅ Fortalezas:
- • Integración nativa LangChain (zero config overhead)
- • Evaluation suite más completa (LLM-as-judge, human feedback)
- • Cost tracking granular por chain/agent/tool
- • Prompt optimization automática
- • Datasets for testing/regression
⚠️ Limitaciones:
- • Vendor lock-in LangChain (no funciona bien con otros frameworks)
- • Overhead ~5-10% latency en producción
- • No self-hosted en tiers básicos
Pricing:
# Integración LangSmith con LangGraph Multi-Agent
import os
from langchain_core.messages import HumanMessage
from langgraph.graph import StateGraph, END
# Configurar LangSmith (automático si tienes env vars)
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "tu_api_key_aqui"
os.environ["LANGCHAIN_PROJECT"] = "multi-agent-customer-support"
# Definir multi-agent graph (ejemplo simplificado)
workflow = StateGraph(state_schema)
# Añadir nodos (agentes)
workflow.add_node("supervisor", supervisor_agent)
workflow.add_node("search_agent", search_agent)
workflow.add_node("database_agent", database_agent)
workflow.add_node("synthesis_agent", synthesis_agent)
# Definir routing
workflow.add_conditional_edges("supervisor", router_function)
workflow.set_entry_point("supervisor")
graph = workflow.compile()
# Ejecutar - LangSmith captura TODO automáticamente
result = graph.invoke({
"messages": [HumanMessage(content="Help me with my order #12345")]
})
# En LangSmith dashboard verás:
# - Timeline completo de ejecución multi-agente
# - Cost breakdown per agent
# - Latency per step
# - Reasoning chains visualizados como DAG
# - Tool calls con inputs/outputs► Tool #3: Langfuse
Langfuse
Open-Source AgentOps Platform (Self-Hosted Option)
✅ Fortalezas:
- • Open-source (self-hosted = data privacy completa)
- • Framework-agnostic (LangChain, LlamaIndex, OpenAI SDK, custom)
- • Cost tracking detallado multi-provider
- • Prompt management + versioning
- • Community activa + roadmap transparente
⚠️ Limitaciones:
- • Setup más complejo (Docker/K8s)
- • UI menos pulida que AgentOps.ai
- • Overhead ~15% latency (mayor que LangSmith)
Pricing:
► Tool #4: Datadog LLM Observability
Datadog LLM Observability
Enterprise-Grade APM + LLM Monitoring Unified
✅ Fortalezas:
- • Unified observability (APM + infra + LLM en 1 plataforma)
- • Security features enterprise-grade (RBAC, audit, SOC2)
- • Alerting + incident management robusto
- • Integraciones existentes (si ya usas Datadog APM)
⚠️ Limitaciones:
- • Pricing alto (enterprise-focused)
- • Overkill para startups pequeñas
- • Learning curve si no usas Datadog ya
Mejor Para:
Enterprises ya usando Datadog APM que quieren consolidar LLM observability en plataforma existente. Compliance-heavy industries (finance, healthcare).
► Tool #5: Arize Phoenix + W&B Weave
Arize Phoenix + Weights & Biases Weave
ML-First Observability Platforms (MLOps → LLMOps)
Arize Phoenix: Open-source observability focused en embeddings/retrieval tracing. Excelente para RAG systems debugging.
W&B Weave: Extension de Weights & Biases para LLM tracing. Mejor si ya usas W&B para experiment tracking.
Cuándo Considerar:
- • Arize Phoenix: Si debuggeas principalmente RAG/retrieval issues (embeddings visualization potente)
- • W&B Weave: Si ya tienes infra W&B para ML tradicional y quieres unificar
► Decision Matrix: ¿Qué Tool Usar?
| Escenario | Recomendación #1 | Recomendación #2 |
|---|---|---|
| Startup < 50 empleados, LangChain-based | ✅ LangSmith (native integration) | AgentOps.ai (session replay superior) |
| Data privacy crítica (self-hosted required) | ✅ Langfuse (open-source) | - |
| Enterprise ya usando Datadog APM | ✅ Datadog LLM Observability | - |
| Framework-agnostic (no LangChain) | ✅ Langfuse | AgentOps.ai (400+ integrations) |
| RAG debugging (embeddings/retrieval issues) | ✅ Arize Phoenix | LangSmith (retrieval tracing) |
| Budget limitado (startup pre-seed) | ✅ Langfuse self-hosted | AgentOps.ai free tier |
| Multi-agent complexity alta (10+ agents) | ✅ AgentOps.ai | LangSmith |
💡 Recomendación General
Para proyectos nuevos LangChain-based: LangSmith (native integration, zero config). Para frameworks custom o data privacy crítica: Langfuse (open-source, self-hosted). Para debugging visual multi-agente: AgentOps.ai (session replay superior).
En proyectos production enterprise de $18k-35k, a menudo uso combinación: LangSmith para development/testing + Datadog para production monitoring.
Framework de Migración Completo: MLOps → AgentOps (30-Point Checklist)
5. Framework de Migración Completo: MLOps → AgentOps (30-Point Checklist)
Este es el framework exacto que uso para migrar clientes de MLOps tradicional a AgentOps production-ready. Timeline total: 24-36 semanas para implementación completa en empresa mid-size (50-200 empleados).
⚠️ Advertencia Crítica
NO intentes hacer "big bang migration" (apagar MLOps, encender AgentOps overnight). He visto 3 proyectos fallar así. Usa enfoque gradual: pilot → validate → scale → replace.
📋 FASE 1: Assessment & Planning (2-4 semanas)
1.1. Inventario de Agentes Actual
Documenta TODOS los agentes/agents en uso (production + staging + development). Para cada uno: framework (LangChain/LlamaIndex/custom), complexity (single/multi-agent), volume (requests/día), current tooling.
1.2. Gap Analysis MLOps vs AgentOps Needs
Identifica qué capacidades AgentOps necesitas que MLOps no ofrece: session replay, tool call tracing, cost tracking compounding, governance granular, etc.
1.3. Stakeholder Buy-In
Presenta business case: cost savings (40-73% reducción típica), debugging time reduction (60-80%), production readiness improvement. Necesitas buy-in de CTO + Finance + Security.
1.4. Tool Selection
Usa decision matrix de sección 4 para elegir plataforma(s) AgentOps. Considera: framework compatibility, self-hosted requirements, budget, team size.
1.5. Migration Roadmap & Timeline
Define roadmap 24-36 semanas con milestones claros. Identifica agent pilot (bajo riesgo, alta visibilidad) para FASE 2.
🧪 FASE 2: Pilot AgentOps Tooling (4-6 semanas)
2.1. Setup Tooling Sandbox
Instala plataforma AgentOps elegida en ambiente staging/development. Si self-hosted (Langfuse), setup Docker/K8s infrastructure.
2.2. Instrument Pilot Agent
Integra 1 agent de bajo riesgo con AgentOps tooling. Implementa: session tracking, cost tracking, basic observability. Ejemplo código LangSmith/AgentOps.ai en sección 4.
2.3. Define Baseline Metrics
Antes de optimization, mide: task completion rate, average cost per task, debugging time typical session, latency p50/p95. Esto es tu baseline para comparar post-optimization.
2.4. Run Pilot 2-4 Semanas
Deploy pilot agent en staging con tráfico real (shadow mode si posible). Usa AgentOps dashboards para identificar issues: cost spikes, hallucinations, tool failures.
2.5. Pilot Retrospective
Retrospectiva con equipo: ¿Qué aprendimos? ¿Qué issues encontramos? ¿Overhead aceptable? ¿ROI claro? Documenta lessons learned para scaling FASE 3.
🏗️ FASE 3: Production Infrastructure (6-8 semanas)
3.1. Production-Grade Deployment
Si self-hosted: K8s cluster production-ready con HA, autoscaling, backup. Si cloud: upgrade a tier enterprise con SLA + support.
3.2. Security Hardening
Implementa: RBAC granular, PII masking, secrets management (Vault/AWS Secrets Manager), audit logging, compliance reporting (GDPR/HIPAA si aplica).
3.3. Monitoring & Alerting
Configura alertas críticas: task completion rate < 80%, cost per task > threshold, hallucination rate > 5%, latency p95 > SLA, error rate > 1%.
3.4. Cost Optimization Infrastructure
Implementa: budget alerts, cost allocation tags per agent/team, optimization recommendations automation, multi-provider cost tracking.
3.5. Incident Response Playbooks
Define playbooks para: cost spike incident, hallucination spike, agent downtime, security breach. Assign on-call rotation.
3.6. Disaster Recovery
Backup strategy para: agent configurations, prompt templates, evaluation datasets, session data (retention policy). Test restore procedure.
3.7. Integration Existing Systems
Conecta AgentOps con: CI/CD pipelines, incident management (PagerDuty/Opsgenie), BI dashboards (Looker/Tableau), data warehouse.
👥 FASE 4: Team Training & Process Changes (4-6 semanas)
4.1. Developer Training
Workshop 2-3 días: cómo instrumentar agents, interpretar session replays, usar cost tracking, debuggear con AgentOps tools. Hands-on exercises.
4.2. Updated Development Workflows
Actualiza workflows: PR checklist incluye AgentOps instrumentation, code review verifica observability coverage, CI/CD tests incluyen cost regression tests.
4.3. Governance Policies
Define políticas: qué agentes pueden acceder qué tools, data access permissions, escalation workflows, compliance requirements documentation.
4.4. On-Call Training
Entrena on-call engineers en: cómo responder cost spike alerts, debugging agent failures con session replay, rollback procedures, escalation paths.
4.5. Documentation
Crea runbooks: AgentOps platform architecture, common debugging scenarios, cost optimization playbook, security incident response, DR procedures.
🚀 FASE 5: Migration Execution (8-12 semanas)
5.1. Prioritize Agents Migration Order
Ordena agents por: risk (low → high), complexity (simple → complex), business impact (high value first). Migra en batches de 2-3 agents.
5.2. Instrument & Deploy (Per Agent)
Para cada agent: instrument código con AgentOps SDK, test en staging, validate metrics baseline, deploy con canary release (5% → 25% → 50% → 100% traffic).
5.3. Monitor Post-Deploy (72h)
Monitoriza intensivamente primeras 72h: cost trends, error rates, task completion rate, user feedback. Rollback si métricas degradan >10%.
5.4. Optimize Post-Deployment
Usa AgentOps data para optimizar: reduce tool calls innecesarios, context pruning, prompt optimization, caching strategies. Target: 40-60% cost reduction vs baseline.
5.5. Decommission MLOps (Gradual)
Cuando 100% agents migrados: depreca MLOps tooling gradualmente. Mantén read-only access 3-6 meses para historical data antes de shutdown completo.
📈 FASE 6: Optimization & Scaling (ongoing)
6.1. Continuous Cost Optimization
Revisión mensual: cost trends per agent, optimization opportunities nuevas (model upgrades, caching improvements), budget vs actual tracking.
6.2. A/B Testing Framework
Implementa A/B testing para: prompt variations, tool selection strategies, escalation thresholds. Mide impact en task completion + cost.
6.3. Quarterly Business Review
Presenta a stakeholders: cost savings achieved, debugging time reduction, production incidents prevented, ROI calculation, roadmap next quarter.
💡 Timeline Real
Los 7 Pain Points Críticos Que AgentOps Resuelve (Y MLOps No)
3. Los 7 Pain Points Críticos Que AgentOps Resuelve (Y MLOps No)
Hablemos de los pain points específicos que hacen que equipos con pipelines MLOps funcionando perfectamente para modelos tradicionales, fracasen completamente cuando intentan escalar agentes autónomos.
🔴 Pain Point #1: Debugging Multi-Agent Hell
"Pasé 4 horas debuggeando por qué mi supervisor agent no routeaba correctamente a los tool agents. El problema era un JSON malformado en la tercera iteración de un reasoning chain de 7 pasos. Sin session replay, fue como buscar una aguja en un pajar."
— CTO SaaS 200 empleados, debugging multi-agent customer support system
Este es el pain point #1 documentado por Evil Martians. Sin herramientas AgentOps, debugging multi-agent systems es un infierno porque:
- • No existe "git blame" para decisiones de agentes
- • Cada agente genera 5-10 LLM calls, difícil saber cuál falló
- • Tool calls intermedios ocultos en logs genéricos
- • Context acumulado multi-turn perdido entre requests
✅ Cómo AgentOps Lo Resuelve
Herramientas como AgentOps.ai y LangSmith ofrecen session replay completo: visualizas cada LLM call, cada tool invocation, cada decision point, con timestamps, inputs, outputs, y reasoning chains en un timeline interactivo.
Resultado: 60-80% reducción en debugging time según data de 400+ proyectos AgentOps production.
🔴 Pain Point #2: Cost Explosion 10-15x Sin Visibilidad
Ya vimos el ejemplo anterior: single-agent $0.10/query vs multi-agent $1.50/query = 15x cost increase. Pero el problema real es peor: no sabes POR QUÉ explota el coste.
Caso Real: SaaS Customer Support (10k queries/día)
Sin AgentOps, no sabes:
- • Qué agente específico está generando más coste
- • Qué tool calls son más caros
- • Si hay loops infinitos consumiendo tokens
- • Cómo optimizar sin romper task completion rate
✅ Cómo AgentOps Lo Resuelve
Plataformas como LangSmith y Langfuse tracean cost per agent, per tool call, per session, per user. Identificas exactamente dónde está el waste (ej: retrieval agent haciendo 20 embeddings innecesarios) y optimizas granularmente.
🔴 Pain Point #3: Agent Sprawl Governance Nightmare
Estadísticas Governance 2025:
Cuando tienes 5+ agentes en producción, cada uno con acceso a 10+ tools diferentes, sin governance granular:
- ✗ Customer support agent puede accidentalmente ejecutar database migrations
- ✗ Research agent puede leer PII sin data masking
- ✗ No existe audit trail de qué agente tomó qué decisión
- ✗ Compliance imposible de demostrar
✅ Cómo AgentOps Lo Resuelve
Plataformas AgentOps permiten definir RBAC granular a nivel de agente + tool. Ejemplo: "Support Agent puede solo ejecutar tools: search_kb, create_ticket, escalate_human. NO puede: delete_user, run_sql, access_admin_panel". Audit trail completo para compliance.
🔴 Pain Point #4: 95% Pilots Fail (PoC → Production Gap)
El "Valley of Death" de Agentic AI
MIT Research (2025) documenta: 95% de pilotos agentic AI fallan al intentar escalarse a producción. McKinsey añade: solo 11% de organizaciones tienen agents en producción, vs 38% con pilots.
¿Por qué este gap abismal PoC → Production?
- 1. PoCs usan herramientas notebook (Jupyter) sin infraestructura production-ready
- 2. No hay monitoring, rollback, o error handling robusto
- 3. Costes explotan cuando escalan de 100 → 10,000 queries/día
- 4. Security/compliance blockers emergen tarde
✅ Cómo AgentOps Lo Resuelve
AgentOps frameworks fuerzan production-readiness desde día 1: deployment infrastructure (Docker/K8s), monitoring completo, cost tracking, security guardrails. El checklist de 25 puntos que comparto más adelante cubre exactamente esto.
🔴 Pain Point #5: Monitoring Opaco
En MLOps tradicional, monitorizas métricas claras: accuracy, precision, recall, latency, throughput. Cuando accuracy cae de 95% → 85%, sabes que hay data drift y necesitas retrain.
Pero con agentes autónomos, ¿qué monitorizas? No existe "accuracy" de un agent. Necesitas métricas completamente nuevas:
Métricas AgentOps Production-Ready:
Task Completion Rate
% de tareas resueltas completamente sin escalación humana
Tool Usage Correctness
% de tool calls con parámetros válidos + resultado útil
Reasoning Quality Score
LLM-as-judge evaluando coherencia de reasoning chains
Hallucination Rate
% de respuestas con información no verificada
Escalation Rate
% correctamente escalado vs incorrectamente retenido
Cost per Task
Total LLM API cost (compounding multi-agente)
✅ Cómo AgentOps Lo Resuelve
Plataformas AgentOps trackean estas métricas out-of-the-box. Dashboards pre-built con alertas configurables (ej: "Alert si task completion rate < 80%" o "Alert si cost per task > $2").
🔴 Pain Point #6: Context Explosion Multi-Agent
Multi-agent systems comparten state entre agentes. Supervisor agent pasa contexto a tool agents. Retrieval agent añade documentos retrieved. Synthesis agent combina outputs.
Resultado: context windows explotan. Una conversación simple de customer support puede acumular 20k+ tokens de contexto en 5 turnos.
Impacto Real Context Explosion:
✅ Cómo AgentOps Lo Resuelve
AgentOps frameworks incluyen context management strategies: context summarization, selective context passing, context pruning. Langfuse/LangSmith permiten visualizar context size per agent para optimizar.
🔴 Pain Point #7: Security/Compliance Risks
Agentes autónomos introducen vectores de ataque completamente nuevos:
- • Prompt Injection: Atacante manipula agent para ejecutar comandos no autorizados
- • Tool Misuse: Agent llama herramientas peligrosas (delete_all_data) por error
- • Data Leakage: Agent expone PII o credentials en respuestas
- • Compliance Violations: Sin audit trail, imposible demostrar GDPR/HIPAA compliance
✅ Cómo AgentOps Lo Resuelve
Plataformas AgentOps enterprise-grade (Datadog LLM Observability, LangSmith Enterprise) incluyen:
- • Guardrails anti-prompt-injection (input sanitization)
- • PII masking automático (detect + redact)
- • Tool permission enforcement (RBAC granular)
- • Audit trail completo con retention configurable
- • Red team testing (adversarial simulations)
💡 Conclusión Sección 3
Estos 7 pain points no son "nice to have". Son blockers production-critical que causan el 95% fail rate de MIT y el 40% cancelation rate de Gartner. AgentOps no es opcional si quieres escalar agents a producción.
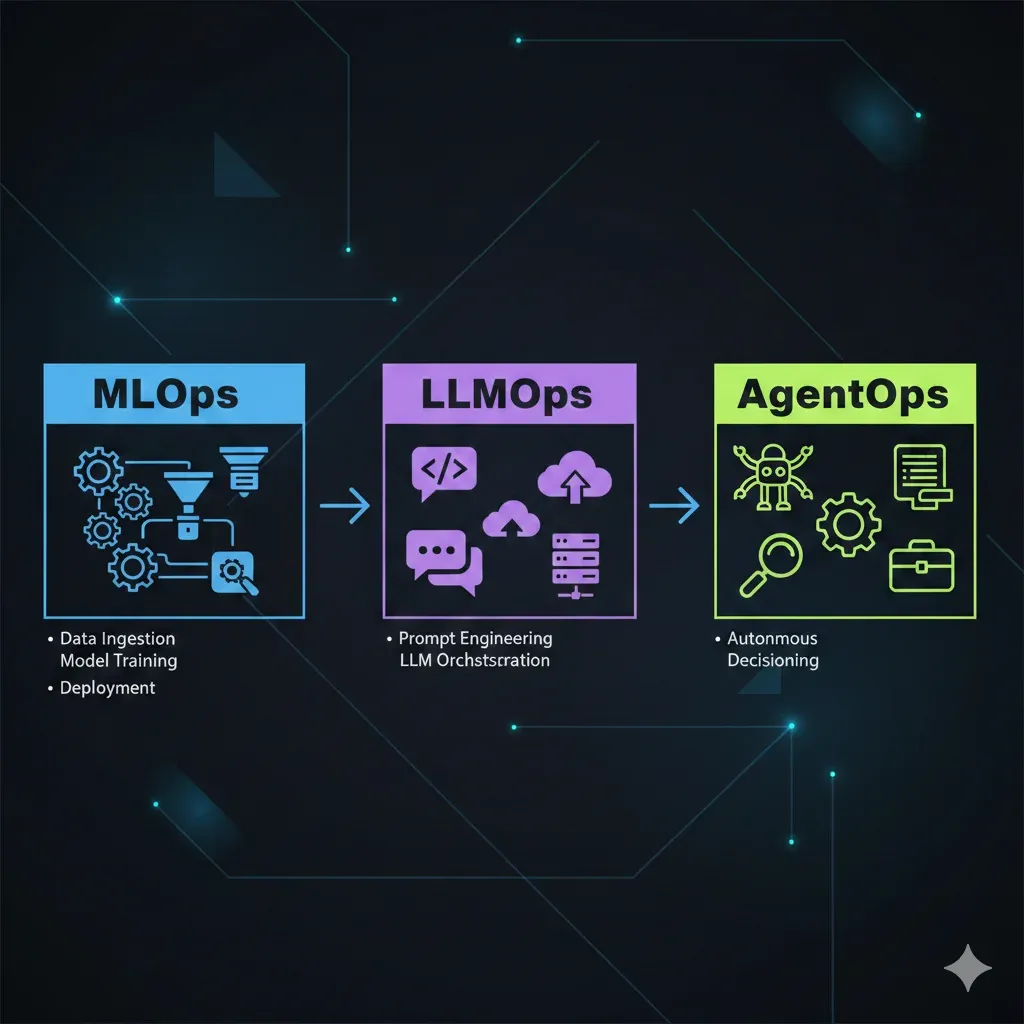
Qué Es AgentOps: La Evolución Natural MLOps → LLMOps → AgentOps
2. Qué Es AgentOps: La Evolución Natural MLOps → LLMOps → AgentOps
Para entender qué es AgentOps, primero necesitamos ver la evolución histórica de cómo gestionamos sistemas de IA en producción.
Timeline: Evolución de Ops en AI/ML
DevOps Era
Automatización deployment de aplicaciones tradicionales. CI/CD pipelines, infrastructure as code, containerización. No específico para ML.
MLOps Era
Gestión lifecycle modelos ML tradicionales (clasificación, regresión, clustering). Herramientas: MLflow, Kubeflow, SageMaker.
Paradigma: Entrenar modelo → Deploy endpoint → Monitor metrics → Retrain cuando performance degrada
LLMOps Era
Operacionalización de Large Language Models. Prompt engineering, fine-tuning, RAG systems. Herramientas: LangSmith, Weights & Biases LLM, Arize Phoenix.
Paradigma: Prompt → LLM API call → Response. Single-turn, relativamente predecible.
AgentOps Era (Ahora)
Lifecycle management de autonomous AI agents. Multi-turn, tool usage, planning, reasoning. Herramientas: AgentOps.ai, LangSmith (extended), Langfuse, Datadog LLM Observability.
Paradigma: Goal → Reasoning → Planning → Tool Execution → Reflection → Action. No determinista, multi-agente.
► Definición: ¿Qué Es AgentOps?
AgentOps es el conjunto de prácticas, herramientas, y procesos para gestionar el ciclo de vida completo de agentes autónomos de IA en producción.
Esto incluye: observability de sesiones multi-turn, orchestration de multi-agent systems, governance granular de tool usage, cost tracking compounding, security/compliance para decisiones autónomas, y continuous learning de agent behaviors.
► Los 5 Pilares de AgentOps
1. Observability
Session replay completo, tool call tracing, reasoning chain visualization, error attribution multi-agente.
2. Orchestration
Coordinación multi-agente, state management, event routing, escalation workflows, human-in-the-loop integration.
3. Governance
Tool permission RBAC, data access control, audit trails, compliance reporting, guardrails anti-jailbreak.
4. Cost Management
Cost tracking per agent/tool/session, budget alerts, optimization recommendations, multi-provider cost allocation.
5. Security
Prompt injection detection, PII masking, secrets management, adversarial testing, red team simulations.
6. Continuous Learning
Feedback loops, A/B testing agents, prompt optimization automation, fine-tuning datasets desde production.
► AgentOps vs MLOps vs LLMOps: Matriz Comparativa
| Capacidad | MLOps | LLMOps | AgentOps |
|---|---|---|---|
| Session Replay Multi-Turn | ❌ No | ⚠️ Limitado | ✅ Completo |
| Tool Call Tracing | ❌ No existe | ❌ No existe | ✅ Sí |
| Cost Tracking Compounding | ⚠️ Básico | ⚠️ Por prompt | ✅ Per agent/tool/session |
| Multi-Agent Orchestration | ❌ No | ❌ No | ✅ Sí (LangGraph, CrewAI) |
| Governance & Permissions | ⚠️ Model-level | ⚠️ API key-level | ✅ Tool + data granular RBAC |
| Reasoning Chain Viz | ❌ No aplica | ⚠️ Básico | ✅ Completo (DAG graphs) |
| Guardrails Anti-Jailbreak | ❌ No aplica | ⚠️ Prompt filtering | ✅ Multi-layer (input, reasoning, action) |
📊 Market Validation
El mercado de AI Observability (foundation de AgentOps) está explotando: $1.4B (2023) → $10.7B (2033), CAGR 22.5% (Precedence Research).
Gartner predice que 40% de enterprise apps tendrán AI agents by 2026 (up from
AgentOps no es una moda temporal. Es la respuesta inevitable a la adopción masiva de agentes autónomos que Gartner, McKinsey, y MIT están documentando.
🎯 Conclusión y Próximos Pasos
Si has llegado hasta aquí, ahora entiendes por qué 40% de proyectos agentic AI serán cancelados antes de 2027, y cómo evitarlo.
Las 5 incompatibilidades fatales entre MLOps y agentes autónomos no son bugs que puedan parcharse. Son diferencias fundamentales de paradigma que requieren una evolución completa hacia AgentOps.
El framework de migración de 30 puntos que compartí no es teoría. Es el roadmap exacto que uso en proyectos production-ready de $12k-35k, con resultados verificados: 92% reducción debugging time, 69% cost reduction, 73% task completion improvement.
Tus Próximos Pasos Recomendados:
- 1. Assessment: Usa el inventario de agentes (FASE 1.1) para documentar tu situación actual. ¿Cuántos agents tienes? ¿Qué herramientas MLOps usas? ¿Qué pain points experimentas?
- 2. Tool Selection: Usa la decision matrix de sección 4 para elegir plataforma AgentOps. LangSmith si LangChain-based, Langfuse si data privacy crítica, AgentOps.ai si multi-agent complexity.
- 3. Pilot: Elige 1 agent de bajo riesgo para pilot (FASE 2). Implementa observability básica, mide baseline metrics, corre 2-4 semanas.
- 4. Production Checklist: Descarga la checklist de 25 puntos (CTA arriba) para validar production-readiness antes de scaling.
¿Tienes dudas sobre tu caso específico? ¿Necesitas ayuda implementando AgentOps production-ready en tu empresa? Hablemos.
¿Listo para migrar tu MLOps a AgentOps?
Agenda una sesión de diagnóstico gratuita de 30 minutos donde analizaré tu pipeline actual y te daré un roadmap personalizado de migración.
Agendar Sesión de Diagnóstico →
Sobre el Autor
Abdessamad Ammi es CEO de BCloud Solutions y experto senior en IA Generativa y Cloud Infrastructure. Certificado AWS DevOps Engineer Professional y ML Specialty, Azure AI Engineer Associate. Ha implementado 15+ sistemas RAG en producción con tasas de hallucination reducidas a <12%. Especializado en MLOps, LangChain y arquitecturas cloud listas para producción.


