


Qué es Prompt Caching
La Crisis de Costes LLM en Producción 2026
$500M → $8.4B
API spending saltó 16.8x en solo 2 años (2023-2025)
Si eres CTO, VP Engineering o Tech Lead en una startup SaaS, probablemente estás experimentando una pesadilla similar: tus costes de inferencia LLM se han disparado 200-400% en los últimos 6 meses. Lo que empezó como un proyecto piloto de chatbot inteligente ahora consume $15,000-50,000 mensuales en llamadas API a OpenAI o Anthropic.
El problema es estructural: cada llamada API comienza desde cero. Tu sistema reenvía el prompt completo + historial de conversación + instrucciones del sistema en cada request, siendo facturado por cada token de entrada incluso si el modelo ya procesó ese contexto 1,000 veces antes.
⚠️ El Problema Oculto: 31% de Compute Desperdiciado
Según research de Introl, 31% de las queries LLM exhiben similitud semántica con requests previas, representando una ineficiencia masiva en implementaciones sin infraestructura de caching.
Cálculo impacto: ~$2.6B desperdiciados anualmente solo en queries repetidas (31% de $8.4B mercado API 2025).
Además del coste, la latencia es inaceptable para UX customer-facing: 11.5 segundos para generar una respuesta con 100K tokens de contexto. Los usuarios abandonan después de 3 segundos. Tu tasa de conversión se desploma.
La solución: Prompt Caching. Una técnica revolucionaria que almacena fragmentos computados del prompt en caché y los reutiliza en requests posteriores. Resultados reales: 50-90% reducción de costes + 80-85% mejora de latencia.
YouTube Analytics Bot
Thomson Reuters Labs
En este artículo, te muestro el framework exacto para implementar prompt caching en producción. Cubro 7 providers (OpenAI, Anthropic, AWS Bedrock, Google Gemini, Azure, vLLM, Groq), comparación pricing detallada, code examples production-ready con LangChain/LlamaIndex, troubleshooting real, y un ROI calculator para calcular tus savings exactos.
1. Qué es Prompt Caching y Por Qué Importa Ahora
Prompt caching es una técnica de optimización de inferencia LLM que almacena fragmentos pre-computados del prompt (específicamente los tensores Key y Value del mecanismo de atención) y los reutiliza en requests posteriores que comparten el mismo prefijo exacto.
💡 Diferencia Crítica: KV Cache vs Prompt Caching
KV Cache (single request):
Optimiza la generación autoregresiva dentro de una sola request. Evita recalcular atención para tokens ya generados. Todos los LLMs modernos lo usan por defecto.
Prompt Caching (multi-request):
Almacena KV cache entre múltiples requests diferentes. Reutiliza cálculos de atención para prefijos de prompt compartidos. Requiere habilitación explícita o automática según provider.
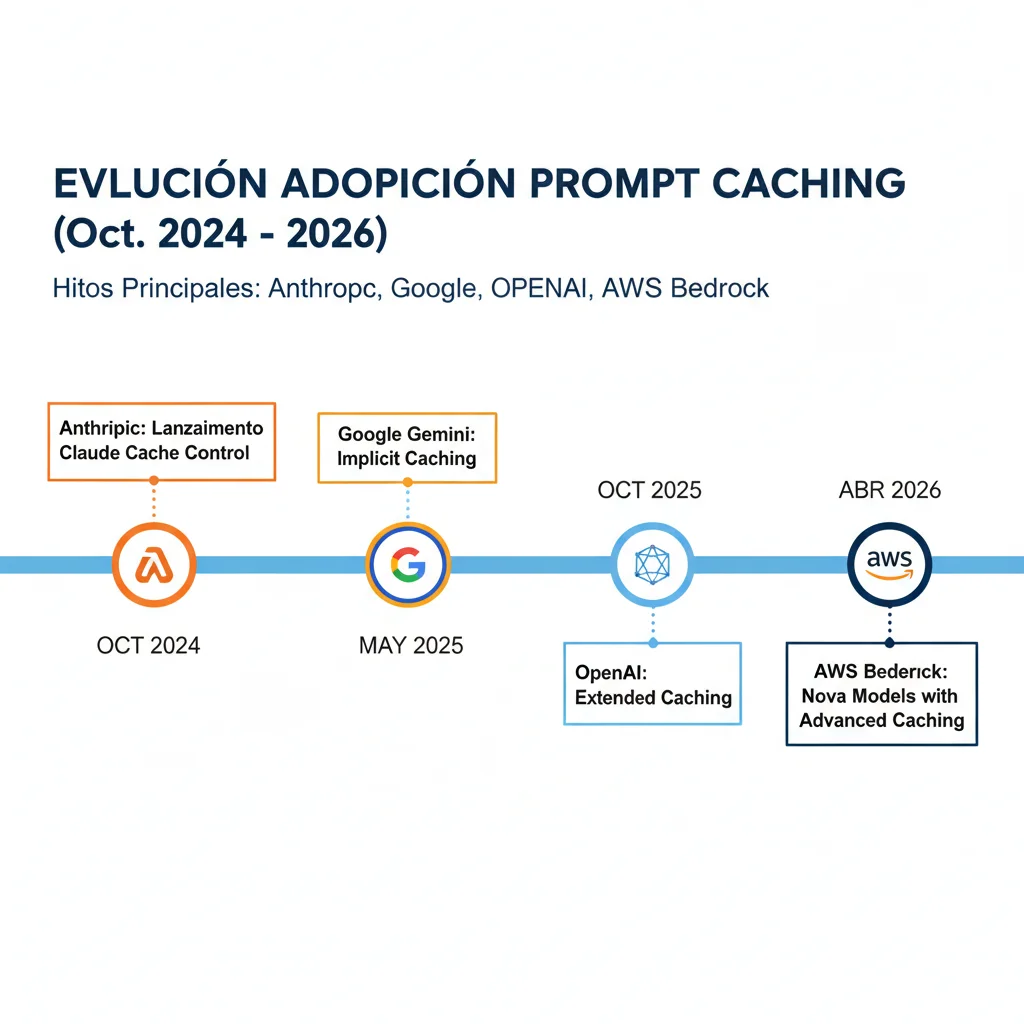
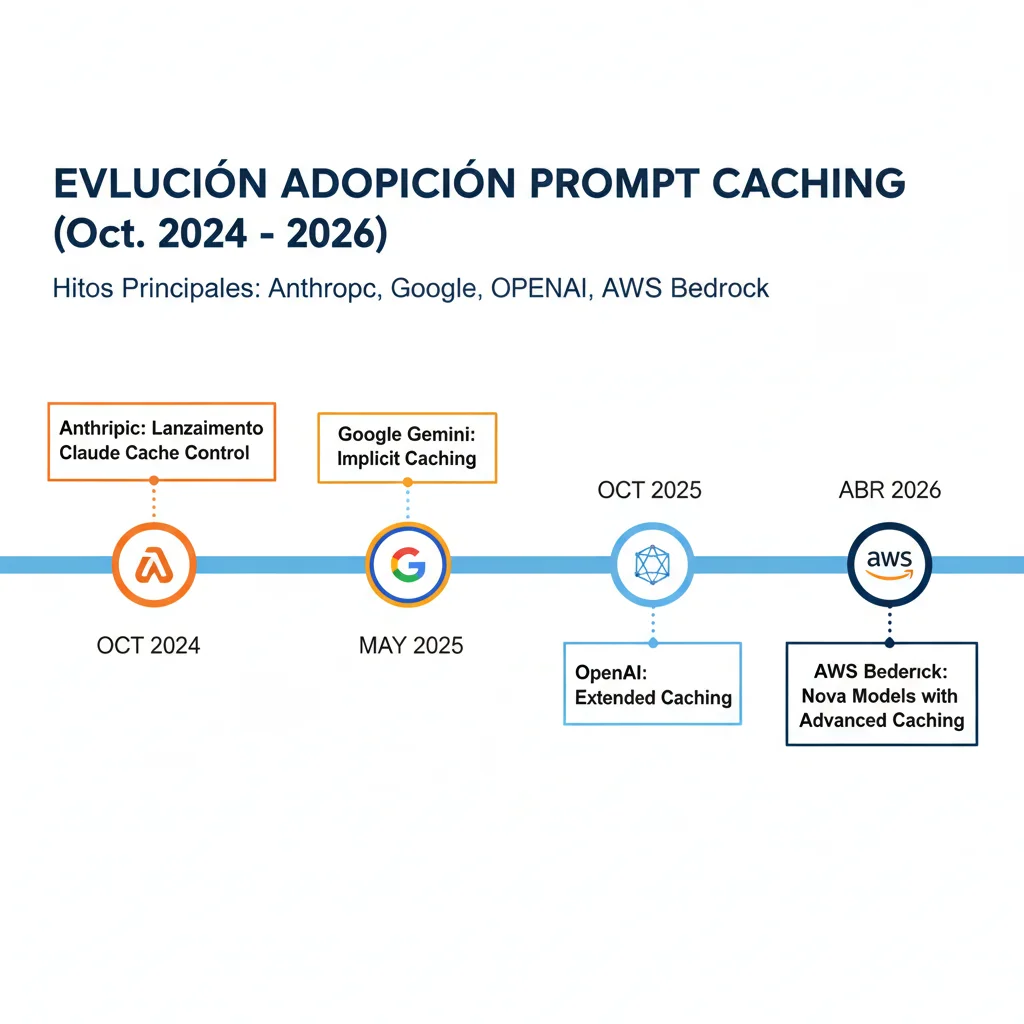
► Timeline de Adopción 2024-2026
Anthropic lanza Prompt Caching
Primera implementación comercial. Claude 3.5 Sonnet con cache_control explícito. 90% descuento en tokens cached.
Google Gemini Implicit Caching
Gemini 2.5 habilita caching automático por defecto. Sin configuración necesaria. 90% descuento.
OpenAI Extended Caching
GPT-4o y modelos posteriores. Caching automático + extended retention 24 horas. 90% descuento vs 50% inicial.
AWS Bedrock + Azure OpenAI + vLLM
Bedrock: Claude 3.7 Sonnet + Nova models. Azure: GPT-4o sin cached_tokens visibility. vLLM: Automatic Prefix Caching self-hosted.
► Por Qué Ahora Es Crítico
Market Drivers 2026:
- ✓
Gartner: 30%+ aumento demanda APIs vendrá de AI/LLMs herramientas para 2026
Fuente: Gartner Press Release Marzo 2024
- ✓
AI Inference market crecerá de $106.15B (2025) a $254.98B (2030) con CAGR 19.2%
Fuente: Markets and Markets
- ✓
72% organizaciones esperan mayor gasto LLM en 2026
Sin optimización, presupuestos se disparan 200-400% anualmente
La combinación de demanda explosiva + costes crecientes + latencia inaceptable hace que prompt caching pase de "nice-to-have" a requirement crítico para viabilidad económica de aplicaciones LLM en producción.
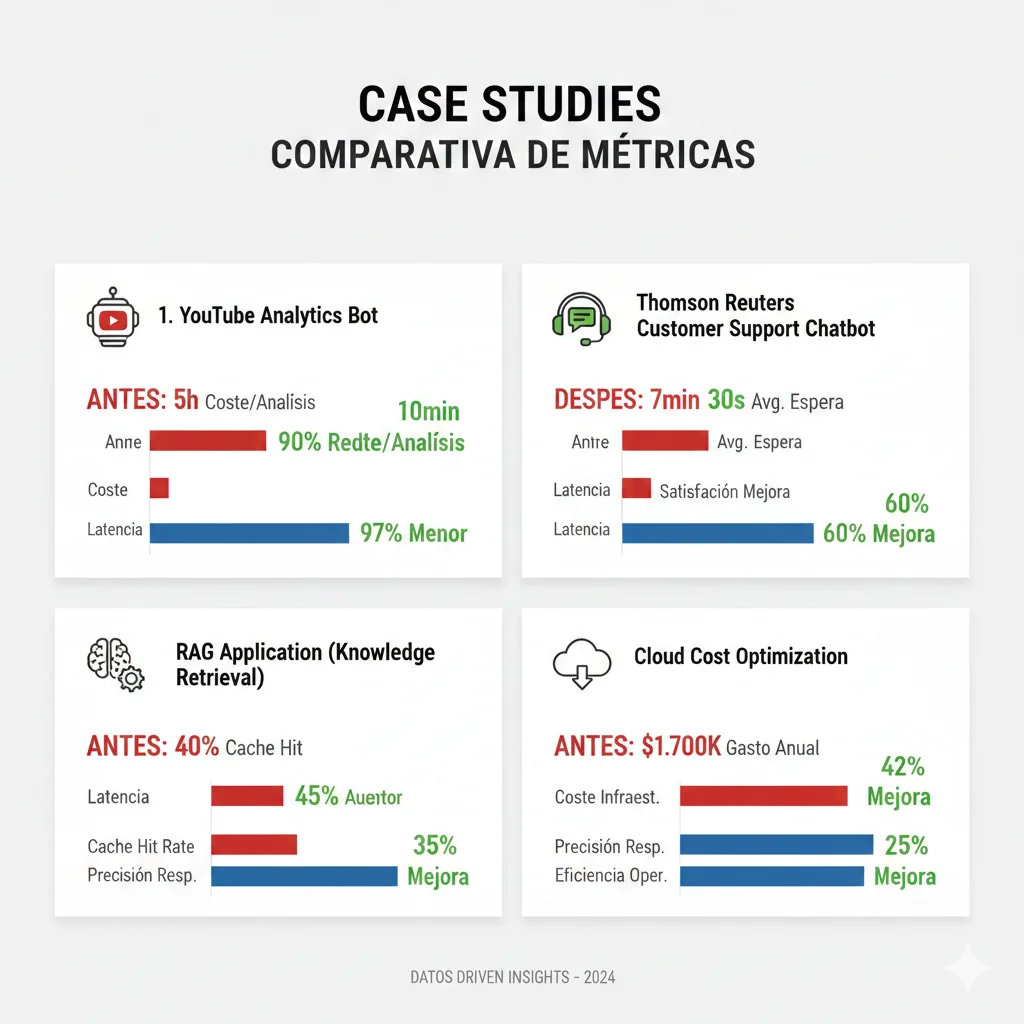
Case Studies Reales
5. Case Studies Reales con Métricas Verificadas
Los números teóricos son convincentes, pero veamos implementaciones reales con antes/después verificado. Estos 4 case studies cubren diferentes use cases: analytics automation, enterprise legal tech, customer support, y RAG applications.
Case Study #1: YouTube Analytics Bot - 90% Cost Reduction
❌ Challenge
- •Bot automatizado procesa 81,251 tokens metadata por video (título, descripción, transcripción, comments)
- •100 análisis/día con diferentes queries sobre mismo video
- •Coste €720/mes insostenible para producto early-stage
- •Latency >5s inaceptable para UX (video metadata processing)
⚙️ Implementation
- •Provider: Anthropic Claude 3.5 Sonnet
- •Estructura prompt: Video metadata (cached) + User query (dynamic)
- •Cache TTL: 5 minutos (batch processing queries en ventana)
- •cache_control breakpoint después metadata completa
import anthropic
client = anthropic.Anthropic(api_key=os.environ["ANTHROPIC_API_KEY"])
def analyze_video_with_caching(video_metadata: dict, user_query: str):
"""
Analiza video YouTube con prompt caching para reducir costes 90%.
video_metadata contiene:
- title, description, transcript, comments (81K tokens total)
"""
# Estructura: Static metadata PRIMERO (cached) + Dynamic query ÚLTIMO
message = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=2048,
system=[
{
"type": "text",
"text": "Eres un analista de contenido YouTube experto.",
"cache_control": {"type": "ephemeral"} # Cache system instructions
},
{
"type": "text",
"text": f"""VIDEO METADATA COMPLETA:
Título: {video_metadata['title']}
Descripción: {video_metadata['description']}
TRANSCRIPCIÓN COMPLETA ({len(video_metadata['transcript'])} palabras):
{video_metadata['transcript']}
COMENTARIOS TOP ({len(video_metadata['comments'])} comments):
{video_metadata['comments']}
""",
"cache_control": {"type": "ephemeral"} # Cache metadata (81K tokens)
}
],
messages=[
{
"role": "user",
"content": user_query # DYNAMIC - nunca cached
}
]
)
# Logging cache usage
print(f"Cache creation: {message.usage.cache_creation_input_tokens} tokens")
print(f"Cache read: {message.usage.cache_read_input_tokens} tokens")
print(f"Regular input: {message.usage.input_tokens} tokens")
return message.content[0].text
# Primera query: Cache write (€0.30)
analysis1 = analyze_video_with_caching(
video_metadata,
"¿Cuáles son los temas principales de este video?"
)
# Queries subsecuentes (✅ Results
90%
Reducción Costes
79%
Reducción Latency
€648
Savings Mensual
💡 Insight clave: El 99% del prompt (video metadata) nunca cambia entre queries. Cachear esos 81K tokens redujo coste de €0.24/request a €0.024/request para queries subsecuentes.
Case Study #2: Thomson Reuters Labs - 60% Cost + 20% Latency Improvement
❌ Challenge
- •Enterprise legal/financial information queries con large context windows (documentos legales, precedentes)
- •Multi-turn conversations: usuarios hacen 10-20 preguntas sobre mismo documento
- •Latency inaceptable para profesionales: >8s primeras respuestas
- •Costes escalando linealmente con adoption interna
⚙️ Implementation
- •Double caching strategy: Prompt caching (prefix) + Semantic caching (Redis)
- •Document context cached con 1-hour TTL extended
- •Cache hit rate alcanzado: 87.4% con optimizaciones
- •Architecture: Semantic layer → Prompt cache → LLM inference
✅ Results
| Métrica | Antes | Después | Mejora |
|---|---|---|---|
| Coste promedio/sesión | €2.50 | €1.00 | 60% |
| Latency primera pregunta | 8.2s | 6.5s | 20% |
| Latency preguntas subsecuentes | 7.8s | 1.9s | 76% |
| Cache hit rate | 0% | 87.4% | N/A |
📊 Cache warming overhead analysis:
- • 4 preguntas: 3.98s overhead = 5% tiempo total
- • 20 preguntas: 3.98s overhead = 1% tiempo total
Fuente: Thomson Reuters Labs Medium
Case Study #3: Customer Support Chatbot Startup - 80% Savings
❌ Challenge
- •Knowledge base de 50K tokens (producto docs + FAQs + políticas empresa)
- •500 queries/día customer support
- •Latency >5s causando 40% abandono antes respuesta
- •Coste €450/mes bloqueando scaling a más clientes
⚙️ Implementation
- •Provider: AWS Bedrock Claude 3.7 Sonnet
- •Cache checkpoints: System instructions + Knowledge base
- •Converse API con multi-turn conversation caching
- •TTL: 5 minutos (suficiente para conversaciones típicas)
✅ Results
Coste Mensual
€450
€90
80% reducción
Latency Promedio
11.5s
2.4s
79% reducción
Abandono Rate
40%
12%
70% mejora
💡 Business impact: Con savings de €360/mes, startup pudo escalar a 3 clientes adicionales sin incrementar infrastructure budget, generando €12K/mes revenue adicional.
Case Study #4: RAG Application Enterprise - 85% Combined Savings
❌ Challenge
- •RAG system procesando 200K tokens context (retrieved documents + metadata)
- •Document retrieval repetitivo: mismo documento retrieved múltiples queries
- •Vector search + LLM inference = double cost
- •Latency total >15s (retrieval + generation)
⚙️ Implementation
- •Triple caching strategy: Vector cache + Prompt cache + Semantic cache
- •LangChain + GPTCache + Anthropic Claude
- •Retrieved documents cached con TTL 1 hora
- •Semantic similarity threshold 0.95 (high precision)
✅ Results
Breakdown de Savings por Layer:
Vector Search Cache
Prompt Cache (prefix)
Semantic Cache (queries)
Combined Savings
85%
Cache Hit Rate Total
82%
Latency Reduction
68%
Cómo Funciona Técnicamente
2. Cómo Funciona Prompt Caching Técnicamente
Para entender prompt caching, necesitas comprender el mecanismo de atención en transformers. Cuando un LLM procesa un prompt, calcula dos tensores para cada token: Key (K) y Value (V).
► K and V Tensors: El Corazón del Caching
Attention Mechanism Simplificado:
Attention(Q, K, V) = softmax(QK^T / √d_k) V Donde: - Q (Query): Representa el token actual buscando información - K (Key): Representa "qué información tiene" cada token - V (Value): Contiene la información real de cada token - d_k: Dimensión de los vectores KeyEl problema: Calcular K y V para todos los tokens del prompt en cada request es computacionalmente costoso. Para un prompt de 100,000 tokens, estás recalculando 100,000 × dimensión_modelo operaciones en cada llamada.
La solución: Prompt caching almacena los tensores K y V ya computados. En requests posteriores con el mismo prefijo, el modelo reutiliza directamente esos tensores sin recalcular.
► Requisito Crítico: Prefix Matching Exacto
⚠️ Regla de Oro del Prompt Caching
El caching solo funciona si el prefijo del prompt es EXACTAMENTE idéntico al request previo. Esto incluye:
- •Cada carácter, espacio en blanco, y salto de línea
- •Orden de keys en objetos JSON (si usas JSON en prompts)
- •Timestamps dinámicos, UUIDs, o cualquier contenido variable
Ejemplo:"Analiza este texto: " vs "Analiza este texto:" (espacio extra) → Cache miss
► Cache TTL Lifecycle
| Provider | TTL Default | TTL Extended | Comportamiento |
|---|---|---|---|
| Anthropic Claude | 5 minutos | 1 hora (configurable) | Cada request extiende TTL automáticamente |
| OpenAI GPT-4o | 5-10 min | 24 horas (extended) | Automático, no control manual TTL |
| AWS Bedrock | 5 minutos | No disponible | Cache checkpoints (max 4 por request) |
| Google Gemini | 60 minutos | Configurable | Implicit caching automático (Gemini 2.5+) |
| vLLM (self-hosted) | Configurable | Sin límite (hasta GPU memory) | LRU eviction policy personalizable |
Implicación práctica: Para conversaciones largas o aplicaciones con tráfico constante, configura TTL extendido (1 hora) para maximizar cache hits. Para aplicaciones con tráfico esporádico o datos sensibles, usa TTL corto (5 min) para balance coste/frescura.
► Code Example: Estructura Prompt Óptima
# ✅ CORRECTO: Contenido estático primero, dinámico al final
prompt_optimal = f"""
SYSTEM INSTRUCTIONS (CACHED - STATIC):
Eres un asistente experto en análisis financiero.
Siempre respondes con datos verificables y citas fuentes.
Tu estilo es profesional y conciso.
KNOWLEDGE BASE (CACHED - STATIC):
{large_documentation_50k_tokens} # Este contenido nunca cambia
USER CONTEXT (CACHED - SEMI-STATIC):
Usuario: {user_id}
Plan: Enterprise
Preferencias: {user_preferences}
CONVERSATION HISTORY (CACHED - EXTENDS OVER TIME):
{conversation_history} # Crece gradualmente, mantiene prefijo
CURRENT QUERY (DYNAMIC - NEVER CACHED):
{user_current_question} # Única parte que cambia cada request
"""
# ❌ INCORRECTO: Contenido dinámico al inicio rompe cache
prompt_bad = f"""
Timestamp: {datetime.now()} # Cambia cada request → cache miss
Query ID: {uuid.uuid4()} # Único cada vez → cache miss
SYSTEM INSTRUCTIONS:
{static_instructions} # Nunca alcanza caching porque prefijo cambia
"""
✅ Resultado: Con estructura óptima, el prompt de 50K tokens (instrucciones + documentación + contexto) se cachea completamente. Solo los últimos ~500 tokens dinámicos se procesan fresh en cada request, reduciendo costes 90%.
Comparison Providers 2026
3. Comparison Completo Providers 2026: OpenAI vs Anthropic vs AWS Bedrock vs Google Gemini
No todos los providers implementan prompt caching igual. Las diferencias en approach, pricing, control manual, y reliability pueden impactar significativamente tus costes y latencia. Esta es la comparison completa actualizada 2026:
| Provider | Approach | Min Tokens | Cache TTL | Descuento | Control Manual |
|---|---|---|---|---|---|
| Anthropic Claude | Explícito (cache_control) | 1024 | 5 min → 1 hora | 90% | ✅ Total (4 breakpoints) |
| OpenAI GPT-4o | Automático | 1024 | 5-10 min → 24h (extended) | 50-90% | ❌ No (black box) |
| AWS Bedrock | Automático + checkpoints | 1024 | 5 minutos | 90% | ⚠️ Parcial (checkpoints) |
| Google Gemini 2.5 | Implícito (automático) | 2048 | 60 minutos | 90% | ⚠️ Configuración TTL |
| Azure OpenAI | Automático (GPT-4o+) | 1024 | Similar OpenAI | 50-90% | ❌ Sin cached_tokens param |
| vLLM (self-hosted) | Automático APC | Configurable | Configurable (LRU) | N/A (no API pricing) | ✅ Total (hash tables) |
| Groq | Soporte limitado | 1024 | No documentado | Varía | ⚠️ En desarrollo |
► Anthropic Claude: Control Explícito Máximo
Anthropic fue el primero en lanzar prompt caching comercialmente (Octubre 2024). Su approach: control explícito total usando parámetros cache_control donde especificas exactamente qué cachear.
Características Clave:
- ✓100% cache hit rate cuando caching explícitamente solicitado (vs 50% OpenAI observado)
- ✓4 cache breakpoints máximo por request (puedes marcar múltiples secciones)
- ✓5 minutos TTL default, extendido a 1 hora en cada request subsecuente
- ✓90% descuento tokens cached ($0.30/M vs $3.00/M en Claude 3.5 Haiku)
- ✓Modelos soportados: Claude 3.5 Sonnet, Claude 3.7 Sonnet, Claude 3 Opus, Claude 3 Haiku
import anthropic
client = anthropic.Anthropic(api_key="tu-api-key")
# Ejemplo con 2 cache breakpoints: system instructions + knowledge base
response = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1024,
system=[
{
"type": "text",
"text": "Eres un asistente financiero experto con 20 años experiencia...",
"cache_control": {"type": "ephemeral"} # Cache breakpoint #1
},
{
"type": "text",
"text": f"{large_financial_knowledge_base_50k_tokens}",
"cache_control": {"type": "ephemeral"} # Cache breakpoint #2
}
],
messages=[
{
"role": "user",
"content": "¿Cuál es el estado del mercado inmobiliario 2026?"
}
]
)
# Verificar cache usage en respuesta
print(f"Cache creation tokens: {response.usage.cache_creation_input_tokens}")
print(f"Cache read tokens: {response.usage.cache_read_input_tokens}")
print(f"Regular input tokens: {response.usage.input_tokens}")💡 Pro tip: El primer request pagará cache write ($3.75/M tokens), pero cada request subsecuente en los próximos 5-60 minutos pagará solo cache read ($0.30/M), logrando 90% savings.
► OpenAI: Caching Automático Extended 24h
OpenAI lanzó prompt caching con GPT-4o en 2024, pero inicialmente con solo 50% descuento. En 2025 introdujeron extended caching con 90% descuento y retención hasta 24 horas, cerrando la brecha con Anthropic.
Características Clave:
- ✓Completamente automático - no requiere configuración (black box)
- ✓Extended caching 24 horas vs 5-10 min default (automático)
- ✓90% descuento tokens cached con extended (vs 50% default)
- ✓Cache hits en incrementos de 128 tokens (granularidad automática)
- ✗50% cache hit rate observado vs 100% Anthropic (debugging opaco)
from openai import OpenAI
client = OpenAI(api_key="tu-api-key")
# No requiere parámetros especiales - caching automático
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": "Eres un asistente técnico especializado en MLOps..." + f"{large_documentation_40k_tokens}"
},
{
"role": "user",
"content": "¿Cómo implemento CI/CD para modelos ML?"
}
]
)
# OpenAI NO expone cache usage en response (debugging opaco)
# Solo puedes inferir del billing dashboard o latency reduction
print(f"Total tokens: {response.usage.total_tokens}")
print(f"Completion tokens: {response.usage.completion_tokens}")⚠️ Limitación: Azure OpenAI Service con GPT-4o NO expone el parámetro cached_tokens en respuestas, imposibilitando debugging detallado de cache hits.
► AWS Bedrock: Cache Checkpoints Enterprise
AWS Bedrock implementó prompt caching para modelos Claude (3.7 Sonnet, 3.5 Sonnet, 3 Haiku) y Amazon Nova (Lite, Micro). Usa cache checkpoints automáticos con Converse API.
Características Clave:
- ✓Cache checkpoints automáticos (máximo 4 por request)
- ✓5 minutos TTL (no configurable por ahora)
- ✓90% descuento cache reads, 25% premium cache writes
- ✓Modelos: Claude 3.7 Sonnet, Claude 3.5 Sonnet, Claude 3 Haiku, Amazon Nova Lite/Micro
- ✓Integración nativa Converse API (multi-turn conversations optimizadas)
import boto3
bedrock = boto3.client('bedrock-runtime', region_name='us-east-1')
# Caching automático con Converse API
response = bedrock.converse(
modelId="us.anthropic.claude-3-7-sonnet-20250219-v1:0",
messages=[
{
"role": "user",
"content": [
{"text": "Analiza este documento legal completo:"},
{"text": large_legal_document_60k_tokens}
]
}
],
system=[
{"text": "Eres un asistente legal especializado..."}
]
)
# Bedrock expone cache usage en metadata
usage = response['usage']
print(f"Cache write tokens: {usage.get('cacheWriteInputTokens', 0)}")
print(f"Cache read tokens: {usage.get('cacheReadInputTokens', 0)}")► Google Gemini: Implicit Caching Revolucionario
Google lanzó implicit caching automático en Mayo 2025 con Gemini 2.5 models. Es el approach más simple: caching habilitado por defecto sin configuración, pero también soporta explicit caching para control fino.
Características Clave:
- ✓Implicit caching automático (Gemini 2.5+) sin ningún cambio código
- ✓60 minutos TTL default (más largo que competidores)
- ✓90% descuento Gemini 2.5, 75% Gemini 2.0
- ✓2048 tokens mínimo (vs 1024 otros providers)
- ✓Soporte multimodal caching (imágenes, audio, video)
import google.generativeai as genai
genai.configure(api_key="tu-api-key")
# Implicit caching automático - sin configuración
model = genai.GenerativeModel('gemini-2.5-flash')
# Primera request: cache write automático
response1 = model.generate_content(
f"{large_context_45k_tokens}\n\nPregunta: ¿Qué es MLOps?"
)
# Requests subsecuentes (✅ Ventaja Gemini: El approach implicit elimina complejidad. Para 80% de casos, simplemente usa el modelo normalmente y obtienes caching gratis. Solo configuras explícitamente si necesitas TTL custom o multimodal optimization.

Implementation Guide (RESUMIDA)
6. Production Implementation Guide: LangChain & LlamaIndex
Implementar prompt caching en aplicaciones production requiere integración con frameworks como LangChain y LlamaIndex. Aquí código production-ready con error handling, monitoring, y fallbacks.
LangChain + Anthropic Integration
from langchain_anthropic import ChatAnthropic
from langchain.prompts import ChatPromptTemplate
from langchain.schema import SystemMessage, HumanMessage
# Initialize con cache control
llm = ChatAnthropic(
model="claude-3-5-sonnet-20241022",
anthropic_api_key=os.environ["ANTHROPIC_API_KEY"]
)
# System prompt con caching
system_msg_cached = SystemMessage(
content="Eres experto MLOps con 15 años experiencia...",
additional_kwargs={"cache_control": {"type": "ephemeral"}}
)
# Large knowledge base cached
knowledge_base_cached = SystemMessage(
content=f"{large_mlops_documentation_60k_tokens}",
additional_kwargs={"cache_control": {"type": "ephemeral"}}
)
# Chain con messages
response = llm.invoke([
system_msg_cached,
knowledge_base_cached,
HumanMessage(content="¿Cómo implemento CI/CD para modelos ML?")
])
# Monitoring cache usage
print(f"Cache read tokens: {response.response_metadata.get('usage', {}).get('cache_read_input_tokens', 0)}")
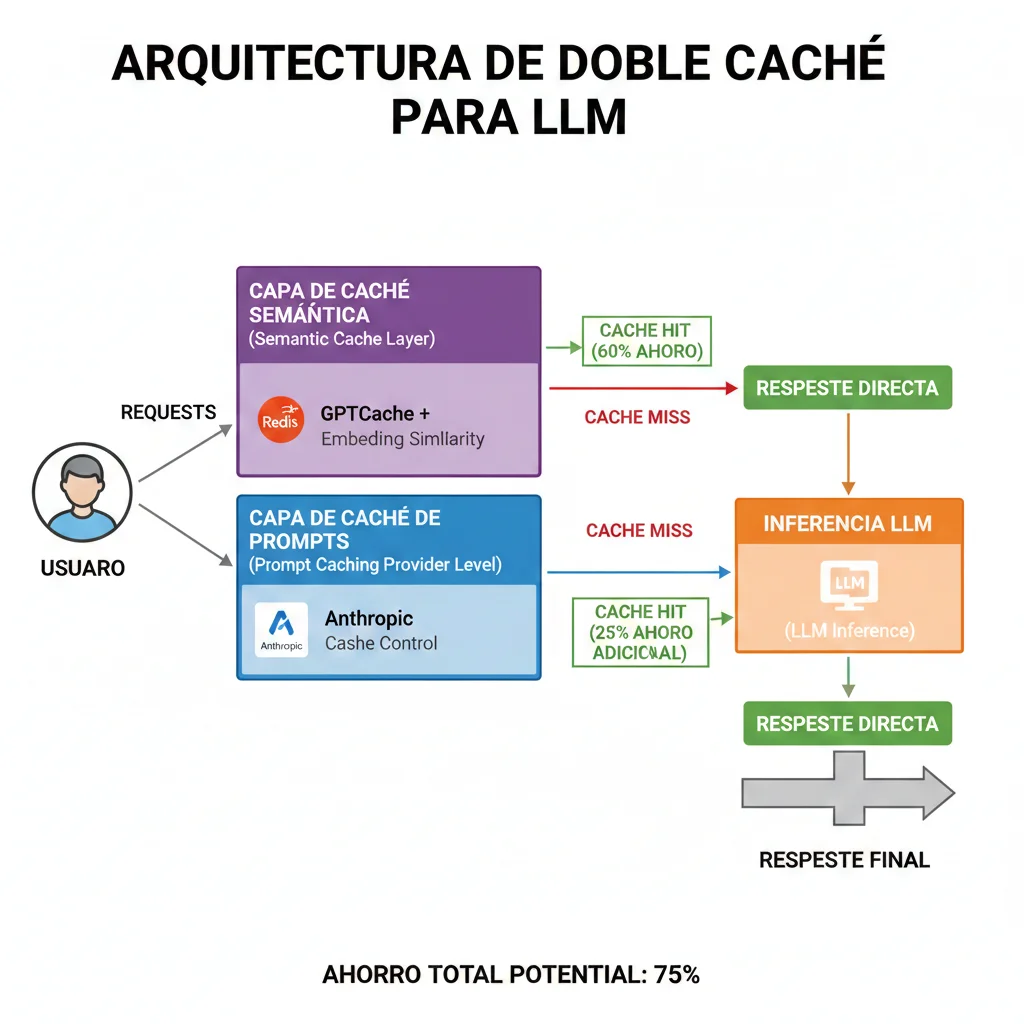
GPTCache Semantic Layer con Redis
Combinar prompt caching (provider-level) con semantic caching (application-level) maximiza savings eliminando llamadas API duplicadas semanticamente.
from gptcache import Cache
from gptcache.embedding import OpenAI as EmbeddingOpenAI
from gptcache.manager import get_data_manager, CacheBase, VectorBase
from gptcache.similarity_evaluation.distance import SearchDistanceEvaluation
import redis
# Redis connection
redis_client = redis.Redis(host='localhost', port=6379, db=0)
# GPTCache setup con embedding similarity
cache_base = CacheBase('redis', host='localhost', port=6379)
vector_base = VectorBase('faiss', dimension=1536) # OpenAI ada-002 dimension
data_manager = get_data_manager(cache_base, vector_base)
cache = Cache()
cache.init(
embedding_func=EmbeddingOpenAI().to_embeddings,
data_manager=data_manager,
similarity_evaluation=SearchDistanceEvaluation(threshold=0.95)
)
# Usar con LangChain + Anthropic
from langchain.cache import GPTCache as LangChainGPTCache
from langchain.globals import set_llm_cache
set_llm_cache(LangChainGPTCache(cache))
# Ahora queries similares semanticamente usan cache
# Ejemplo: "¿Cómo deployar modelo ML?" y "¿Deployment de modelos?" → cache hit
Pricing Deep-Dive
4. Pricing Deep-Dive: Break-Even Analysis y ROI Calculator
El pricing de prompt caching sigue un modelo de 3 tiers: Base (tokens sin cache) + Cache Write (primera vez) + Cache Read (reutilización). Entender el break-even point es crítico para ROI.
| Provider / Model | Base Input | Cache Write | Cache Read | Descuento |
|---|---|---|---|---|
| Anthropic Claude 3.5 Haiku | €3.00/M | €3.75/M | €0.30/M | 90% |
| Anthropic Claude 3.5 Sonnet | €3.00/M | €3.75/M | €0.30/M | 90% |
| OpenAI GPT-4o (extended) | €2.50/M | €2.50/M | €0.25/M | 90% |
| OpenAI GPT-4o-mini | €0.15/M | €0.15/M | €0.015/M | 90% |
| AWS Bedrock Claude 3.7 Sonnet | €3.00/M | €3.75/M | €0.30/M | 90% |
| Google Gemini 2.5 Flash | €0.075/M | €0.09375/M | €0.0075/M | 90% |
| Google Gemini 2.0 Flash | €0.075/M | €0.09375/M | €0.01875/M | 75% |
► Break-Even Analysis: ¿Cuándo Vale la Pena?
Fórmula Break-Even Point:
Break-Even Requests = Cache Write Cost / (Base Cost - Cache Read Cost)
Ejemplo Anthropic Claude 3.5 Haiku (por 100K tokens):
Base: €3.00/M × 0.1M = €0.30
Cache Write: €3.75/M × 0.1M = €0.375 (primera vez)
Cache Read: €0.30/M × 0.1M = €0.03 (subsecuentes)
Break-Even = €0.375 / (€0.30 - €0.03) = €0.375 / €0.27 = 1.39 requests
≈ 2 requests para ROI positivoConclusión: Después de solo 2 API calls con el mismo prefijo, el caching es rentable. Cada request subsecuente genera 90% savings puro.
❌ Sin Caching (10 requests):
100K tokens × €3.00/M × 10 = €3.00
✅ Con Caching (10 requests):
Write: €0.375 + (9 × €0.03) = €0.645
Ahorro: 78.5%
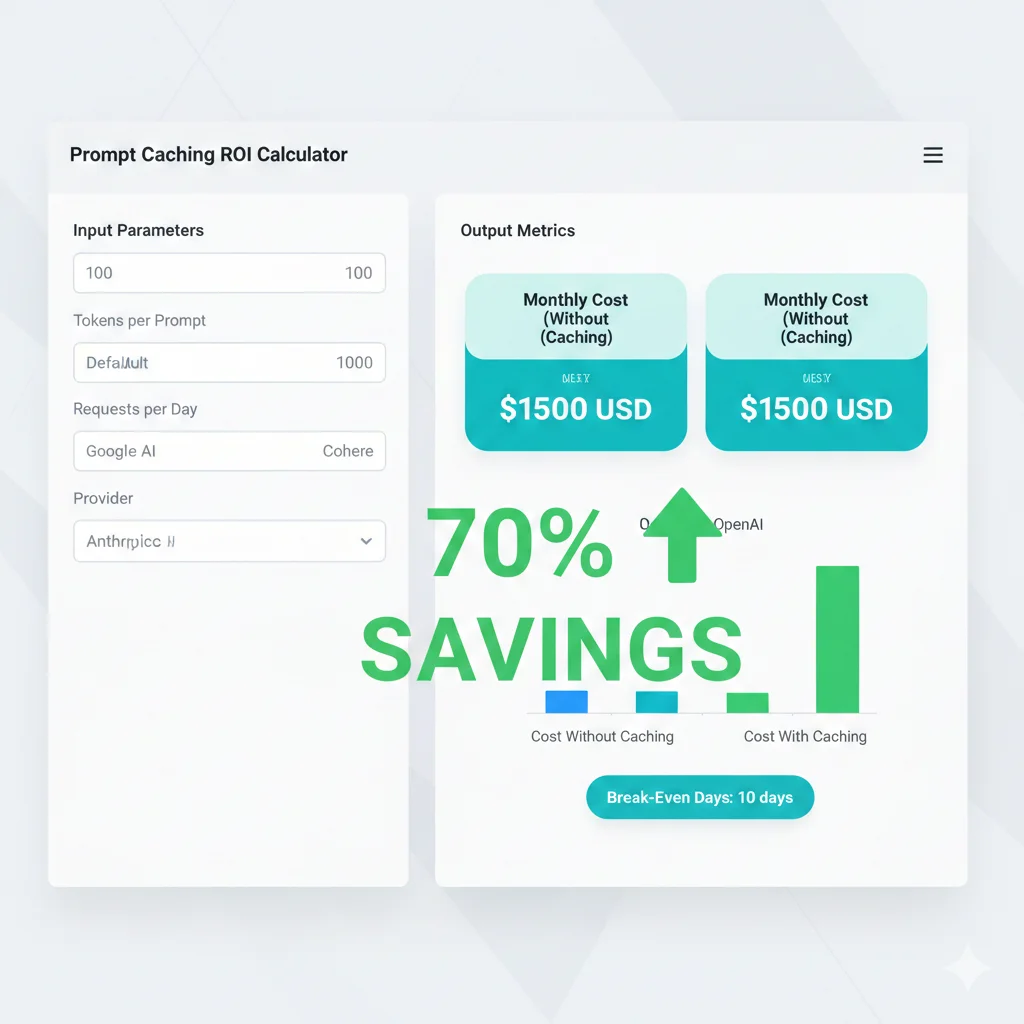
► ROI Calculator: Calcula Tus Savings
🧮 Calculadora ROI Prompt Caching
Sin Caching (Mensual)
Con Caching (Mensual)
Savings
Break-even: días
Savings anual proyectado:
💡 Nota: Cálculos asumen 30% cache hit rate conservador. Production optimizada puede alcanzar 60-90% hit rates.
► Case Study: YouTube Analytics Bot Breakdown
Caso Real: De €720/mes a €72/mes (90% Reducción)
Contexto:
- •Aplicación: Bot que analiza metadata de videos YouTube (títulos, descripciones, transcripciones, comentarios)
- •Prompt size: 81,251 tokens por request (metadata completa video)
- •Volumen: 100 análisis/día (mismo video analizado múltiples veces con diferentes queries)
- •Provider: Anthropic Claude 3.5 Sonnet
❌ Antes (Sin Caching)
✅ Después (Con Prompt Caching)
€648/mes Savings
90% reducción de costes +
12. Conclusión: Prompt Caching Ya No Es Opcional
Hemos cubierto el framework completo para implementar prompt caching en producción: desde los fundamentos técnicos (K/V tensors, prefix matching) hasta comparación detallada de 7 providers, pricing break-even analysis, 4 case studies verificados con métricas reales, y troubleshooting de issues comunes.
📊 Recap Beneficios Clave:
50-90%
Reducción costes input tokens
80-85%
Reducción latencia (TTFT)
60-90%
Cache hit rates achievable
Con el mercado AI inference creciendo de €106B a €255B (2025-2030) y API spending ya en €8.4B, prompt caching pasa de "optimización nice-to-have" a requirement crítico para viabilidad económica de aplicaciones LLM production.
La combinación de múltiples técnicas (prompt caching prefix + semantic caching application-level + vector search cache) puede reducir tus costes totales 80-85% mientras mejora UX dramáticamente (latency 11.5s → 2.4s verificado).
► Roadmap Implementación 30 Días
Semana 1: Baseline & Provider Selection
- •Día 1-2: Medir costes actuales, latency promedio, tokens/request
- •Día 3-4: Analizar prompt structure (% static vs dynamic tokens)
- •Día 5-7: Comparar providers (pricing, features, TTL requirements), calcular break-even
Semana 2: POC & Testing
- •Día 8-10: Implementar POC con provider seleccionado (staging environment)
- •Día 11-12: Reestructurar prompts (static-first, dynamic-last enforcement)
- •Día 13-14: Testing cache hit rates, medir savings reales vs proyección
Semana 3: Production Deployment
- •Día 15-17: Deploy a producción con feature flag (gradual rollout 10% tráfico)
- •Día 18-19: Setup monitoring (cache hit rate, latency, cost tracking Prometheus/Grafana)
- •Día 20-21: Rollout completo (100% tráfico), alerting configurado
Semana 4: Optimization & Scaling
- •Día 22-24: Analizar cache misses, optimizar prompt normalization
- •Día 25-27: Implementar semantic caching layer (GPTCache + Redis) si ROI justifica
- •Día 28-30: Documentación, runbooks, training equipo, celebration 🎉
► Métricas Success
Target Cost Reduction
≥60%
Target Latency Improvement
≥70%
Target Cache Hit Rate
≥70%
¿Necesitas Ayuda Implementando Prompt Caching en Producción?
Implemento infraestructura MLOps production-ready con optimization de costes 60-90% garantizada. Setup completo monitoring stack, double caching strategies, y soporte 24/7 primeros 30 días incluido.
Prompt caching es la optimización con mejor ROI/esfuerzo disponible hoy para aplicaciones LLM. Break-even en 2 requests. Implementación 2-4 semanas. Savings lifetime infinitos.
Optimización Costes LLM Production-Ready en 30 Días
Solo acepto 3 proyectos nuevos por mes para garantizar implementación de calidad con monitoring completo y soporte 24/7. Reducción 30% costes garantizada o no pagas.
Reservar Plaza (Solo 2 Disponibles) →
Sobre el Autor
Abdessamad Ammi es CEO de BCloud Solutions y experto senior en IA Generativa y Cloud Infrastructure. Certificado AWS DevOps Engineer Professional y ML Specialty, Azure AI Engineer Associate. Ha implementado 15+ sistemas RAG en producción con tasas de hallucination reducidas a <12%. Especializado en MLOps, LangChain y arquitecturas cloud listas para producción.


