


El Problema Multimillonario: Por Qué 72% Proyectos IA Fallan

El 19 de diciembre de 2025, Yann LeCun hizo lo impensable
Después de 12 años como Chief AI Scientist en Meta, dejó su puesto para fundar AMI Labs (Advanced Machine Intelligence). La apuesta: €500 millones de inversión inicial con una valuación de €3 mil millones... antes de lanzar producto.
¿Por qué el ganador del premio Turing (el "Nobel de la computación") y padre del Deep Learning moderno apostó su legado completo en una tecnología que la mayoría de CTOs ni siquiera conocen?
La respuesta está en una frase que LeCun pronunció en NVIDIA GTC 2025:
"Los LLMs son demasiado limitantes. Escalarlos no nos permitirá alcanzar la Inteligencia General Artificial."
— Yann LeCun, Chief AI Scientist Meta (2013-2025)
Esto no es un tweet provocador de un investigador frustrado. Es la declaración de guerra más grande en la historia de la IA moderna. LeCun está diciendo públicamente que OpenAI, Anthropic, Google, y todos los que apuestan por LLMs están equivocados.
Su alternativa tiene un nombre que suena a ciencia ficción: World Models (Modelos del Mundo). Y si tiene razón, tu startup de IA podría estar construyendo sobre la arquitectura equivocada.
LO QUE VAS A APRENDER EN ESTE ARTÍCULO:
- ✓ Por qué 72% de proyectos IA enterprise nunca llegan a producción
- ✓ Qué son World Models y cómo difieren arquitecturalmente de LLMs
- ✓ La carrera de $50 mil millones entre Meta, DeepMind, NVIDIA y World Labs
- ✓ 5 casos de uso reales con métricas verificadas (robotics, conducción autónoma, gaming)
- ✓ Checklist de 25 puntos para implementar World Models en producción
- ✓ Decisión framework: ¿Tu empresa necesita World Models o LLMs son suficientes?
Si eres CTO, VP Engineering, o Tech Lead en una startup SaaS evaluando arquitecturas de IA para 2026, este artículo podría ahorrarte millones de euros en inversiones equivocadas.
Porque mientras OpenAI sigue entrenando modelos de lenguaje cada vez más grandes (GPT-5, GPT-6...), LeCun está construyendo algo fundamentalmente diferente: IA que entiende cómo funciona el mundo físico.
1. El Problema Multimillonario: Por Qué 72% Proyectos IA Fallan
Antes de entender qué son World Models, necesitas entender por qué los LLMs actuales NO son suficientes para la mayoría de aplicaciones enterprise.
Proyectos IA enterprise nunca llegan a producción
Fuente: Gartner 2024
Modelos ML nunca se despliegan en producción
Fuente: VentureBeat ML Survey
Tasa promedio de alucinaciones en LLMs comerciales
Fuente: AI Hallucination Report 2026
Si trabajas en una startup SaaS o scale-up tecnológica, probablemente has visto este patrón:
► El Ciclo de Muerte de Proyectos IA Enterprise
- 1Fase Piloto (2-3 meses): Tu equipo de data scientists entrena modelo LLM que funciona increíble en notebooks. Accuracy 95%, demos impresionantes para stakeholders.
- 2Fase Staging (1-2 meses): Intentas deployar a staging. Latencia 8 segundos por query. Costes AWS $15k/mes para 100 usuarios concurrentes. El CFO empieza a hacer preguntas incómodas.
- 3Fase Producción (nunca llega): Los usuarios beta reportan 12-15% de respuestas completamente alucinadas. Healthcare compliance dice "absolutamente no". Legal bloquea el deploy. Proyecto cancelado.
Esta historia se repite en 72% de empresas que intentan llevar IA a producción. ¿Por qué?
► El Problema Fundamental: LLMs No Entienden el Mundo Real
Los LLMs (GPT-4, Claude, Gemini, Llama) son increíblemente buenos prediciendo la siguiente palabra en una secuencia de texto. Pero ese es exactamente el problema: solo entienden patrones estadísticos en texto, NO entienden física, causalidad, o cómo funciona el mundo real.
🔬 Experimento Harvard-MIT: El Test de Manhattan
Investigadores de Harvard y MIT entrenaron GPT-4 con mapas completos de Manhattan. El modelo podía dar direcciones perfectas, recomendar rutas, describir puntos de referencia.
Luego bloquearon solo el 1% de las calles aleatoriamente.
Resultado: El modelo colapsó completamente.
Fuente: "LLMs Learn Bags of Heuristics, Not Coherent World Models" - Quanta Magazine, Sept 2025
¿Por qué colapsó? Porque GPT-4 no tiene un modelo coherente de cómo funciona una ciudad. Solo memorizó patrones estadísticos de "si estás en X calle, normalmente vas por Y ruta". Cuando esos patrones se rompieron (1% de calles bloqueadas), no pudo razonar sobre alternativas.
Este problema se multiplica exponencialmente cuando intentas usar LLMs para:
Robótica
Un robot necesita entender gravedad, fricción, momentum. "Levanta la taza" requiere física, no estadísticas de texto.
Conducción Autónoma
Predecir trayectorias de peatones requiere entender momentum, intenciones, espacialidad 3D. LLMs fallan catastróficamente.
Gaming & Simulación
Generar entornos 3D coherentes donde objetos persisten, colisionan, interactúan según física. LLMs generan "soupy blobs" inconsistentes.
Industrial & Manufacturing
Simulación predictiva de fallos mecánicos, optimización de procesos físicos. Necesitas causalidad, no correlaciones.
El Coste Real de las Alucinaciones
Según el AI Hallucination Report 2026, trabajadores del conocimiento gastan en promedio 4.3 horas por semana verificando y corrigiendo outputs de IA alucinados.
Para un equipo de 10 ingenieros cobrando €75/hora:
4.3 horas/semana × 10 ingenieros × €75/hora × 52 semanas = €167,700/año
Solo en fact-checking. Sin contar proyectos bloqueados por compliance, reputación dañada, o usuarios perdidos.
Entonces, ¿cuál es la solución? Según Yann LeCun: World Models.
5 Casos de Uso Reales con Métricas Verificadas
4. 5 Casos de Uso Reales con Métricas Verificadas
Suficiente teoría. Veamos aplicaciones reales donde World Models ya están generando resultados medibles (y millones en ROI).
Caso #1: Robótica & Manipulación de Objetos
65-80% tasa de éxito en tareas zero-shot
❌ El Problema
Los robots tradicionales fallan estrepitosamente cuando encuentran objetos que nunca vieron antes durante entrenamiento. Si entrenaste tu robot para agarrar tazas rojas cilíndricas y ahora le pones una taza azul cuadrada, la tasa de éxito cae de 90% a menos de 40%.
Esto hace que robots warehouse/manufacturing sean extremadamente rígidos y requieran reentrenamiento constante (costoso).
✓ La Solución: Meta V-JEPA 2
Meta AI entrenó V-JEPA 2 (1.2 mil millones de parámetros) con:
- •1 millón de horas de video genérico (YouTube, internet)
- •1 millón de imágenes estáticas diversas
- •Fine-tuning con solo 62 horas de datos de robot (DROID dataset)
El modelo aprendió física intuitiva (gravedad, fricción, oclusión) del video genérico. Solo necesitó 62 horas de demos robot para transferir ese conocimiento a manipulación real.

📊 Métricas Verificadas
65-80%
Tasa éxito pick-and-place
Objetos NUNCA vistos antes (zero-shot)
100x
Menos datos robot necesarios
62 horas vs 6,000+ horas tradicional
Caso Real: 1X Robotics (Humanoid Robots)
Antes: 40% tasa éxito con políticas hand-coded
Después: 70% tasa éxito con world model predictions
Inversión: $2M infraestructura + 6 meses desarrollo
ROI: 60% reducción testing físico = $500k ahorrados/año
Fuente: 1X World Model Challenge, Meta V-JEPA 2 benchmarks
Caso #2: Conducción Autónoma
10x más rápido iteración → 2 años a 6 meses
❌ El Problema
Entrenar sistemas de conducción autónoma requiere 10,000+ horas de conducción real-world para cubrir edge cases (peatones impredecibles, condiciones climáticas raras, construcciones inesperadas).
Esto significa años de testing físico costoso ($50-100M solo en flota de vehículos + conductores de seguridad).
✓ La Solución: Wayve GAIA-2 World Model
Wayve (startup británica conducción autónoma) desarrolló GAIA-2, un world model que:
- •Simula entornos de conducción realistas desde video
- •Genera edge cases sintéticos (peatón cruzando inesperadamente, ciclista cortando camino)
- •Permite 9,000 horas de entrenamiento simulado por cada 1,000 horas real
📊 Métricas Verificadas
10x
Faster iteration cycle
6 meses
Time to production (vs 2 años)
30%
Reducción maniobras inseguras
Comparación: Tesla vs Waymo Approaches
Tesla (end-to-end neural network):
Usa world model implícito dentro de red neuronal única. Entrena con millones de horas de fleet data real.
Waymo (foundation model + world model):
Integra Gemini (LLM) para razonamiento de alto nivel + world model para predicción trayectorias físicas.
Ambos convergen en necesidad de world models para entender física 3D del tráfico
Caso #3: Gaming & Generación Procedural
73% reducción costes desarrollo entornos
❌ El Problema
Crear un entorno 3D AAA game requiere:
- •50 artistas 3D trabajando 6 meses
- •$3 millones de coste por juego
- •Entornos estáticos (no adaptativos a jugador)
✓ La Solución: Microsoft World Model (Muse)
Microsoft Research entrenó world model con 7 años de footage Xbox (millones de horas gameplay).
El modelo aprendió cómo lucen y funcionan entornos de juegos (física, iluminación, interactividad). Ahora puede:
- ✓Generar base environments proceduralmente desde texto
- ✓Reducir trabajo artistas a refinement (no creación desde cero)
- ✓Adaptar dinámicamente a acciones jugador

📊 Métricas Verificadas
ANTES (Tradicional)
50 artistas × 6 meses = $3M
DESPUÉS (World Model + 10 artistas)
World model base + refinement = $800k
73% reducción costes
Herramientas Disponibles 2026
Genie 3 (DeepMind):
Genera entornos interactivos 3D en tiempo real. Ideal para prototyping rápido.
World Labs Marble:
Pricing freemium ($20-95/mes). Exporta a Unity/Unreal. Compatible VR.
NVIDIA Cosmos:
Open-source models (Nano/Super/Ultra). Para studios que quieren control completo.
Caso #4: Simulación Industrial & Digital Twins
90% reducción testing prototipos físicos
▶ Aplicación
Empresas como Amazon, Uber, y manufactureras usando NVIDIA Cosmos para simular operaciones warehouse/logística:
- •Amazon Robotics: Simular 1 millón escenarios warehouse antes deploy físico
- •Uber Eats bots: Entrenar navegación urbana en simulación (world model entiende aceras, escaleras, puertas)
- •Manufacturing: Predecir fallos mecánicos antes de que ocurran (mantenimiento predictivo)
Beneficio Clave
Testar 1 millón de escenarios en simulación (world model) vs 1,000 escenarios testing físico. Reduce tiempo desarrollo 6-12 meses y costes 90%.
Caso #5: Healthcare & Entrenamiento Quirúrgico VR
Simulación realista tejidos, sangrado, anatomía variable
▶ Aplicación
World models permiten entrenar cirujanos en VR con simulaciones que entienden física de tejidos, sangrado, interacción instrumental.
A diferencia de simuladores tradicionales (hard-coded physics), world models aprenden de video real de cirugías y generalizan a anatomías variables paciente-específicas.
Ventaja vs LLMs en Healthcare
LLMs alucina información médica (9.2% promedio, peor en dominios técnicos). World models anclados a física observable = cero riesgo compliance. Ideal para FDA approval.
El Lado Oscuro: 5 Desafíos Críticos Que Nadie Te Cuenta
5. El Lado Oscuro: 5 Desafíos Críticos Que Nadie Te Cuenta
World Models no son la solución mágica. Tienen problemas serios que necesitas conocer ANTES de invertir millones.
Desafío #1: Costes Computacionales Brutales
4-8x más caro que LLMs en inferencia
Comparación Real de Costes
| Concepto | LLMs | World Models |
|---|---|---|
| GPUs Inferencia | 1-8 GPUs por request | 8-32 GPUs por request |
| Training (small model) | $5k-50k (fine-tuning) | $50k-500k |
| Training (foundation) | $10M-100M | $2M-10M (menos datos texto) |
| Coste mensual inferencia 24/7 | $50k-100k (8 GPUs) | $280k-420k (16 GPUs H100) |
| Storage training data | $5k-20k/mes (100TB-1PB) | $50k-100k/mes (5-10 PB video) |
Cálculo Proyecto Completo
Hardware (GPU cluster): 8× H100 80GB = $200k
Networking: 400 Gbps InfiniBand = $50k
Storage: 10 PB NVMe = $100k-300k
Talent: 3 ingenieros × 6-12 meses ($150k-250k/año) = $225k-1.5M
Training compute: 6 meses GPU time = $50k-500k
Data collection/annotation: $50k-200k
TOTAL: $500k - $12M
Dependiendo escala y si es cloud vs on-premise
Comparación brutal: Fine-tuning un LLM cuesta $5k-50k. Un proyecto world model pequeño cuesta 100x más ($500k+).
⚠️ IMPORTANTE: Estos costes bajarán 10x en 2027-2028 cuando plataformas como NVIDIA Cosmos, World Labs Marble commoditicen la infraestructura. Pero en 2026, solo es viable para empresas con budget ML $1M+.
Desafío #2: Latencia Real-Time Imposible (Gaming)
40ms/frame vs
Requisitos Latencia por Aplicación
✅ VIABLE AHORA (2026)
- • Robotics: 100-200ms acceptable
- • Conducción AV: 50-100ms OK
- • Simulación industrial: 200-500ms
- • Content generation: Sin restricción
❌ NO VIABLE (necesita 2027-2028)
- • Gaming 60fps:
Estado Actual (Enero 2026)
- •Genie 3: 24 fps @ 720p = 41.6ms/frame (SOLO cinemático, NO gameplay)
- •HY-World 1.5: 40ms/frame @ 1080p (mejor del mercado, aún insuficiente 60fps)
- •V-JEPA 2: NO real-time (batch processing offline)
Implicación: World models NO listos para gaming competitivo hasta 2027-2028 cuando hardware mejore 3-4x.
💡 WORKAROUND ACTUAL: Hybrid approach. Usar world models para generación procedural offline (crear niveles, NPCs behavior trees) + motores tradicionales para rendering real-time.
Desafío #3: Escasez Crítica de Talento
46% empresas reportan AI skill gaps
Implementar world models requiere expertise en 3 dominios simultáneamente:
1. Computer Vision (CV)
Video processing, spatial transformers, 3D reconstruction, optical flow
2. Reinforcement Learning (RL)
Action-conditioned prediction, policy optimization, world model planning
3. Systems Engineering
Distributed training (multi-GPU/multi-node), data pipelines PB-scale, inference optimization
Mercado Laboral Reality Check
- • Ingenieros CV+RL senior:
Coste anual talent: $450k-750k (3 ingenieros)
Alternativas Realistas
- 1.Consultorías especializadas (como BCloud Solutions 😉). Faster ramp-up, conocimiento ya adquirido.
- 2.Plataformas managed (NVIDIA Cosmos, World Labs Marble). Reducen necesidad expertise bajo nivel.
- 3.Partnerships académicos (universidades con labs CV/RL). Acceso talent junior trainable.
Desafío #4: Requisitos de Datos Masivos
20M horas video = 5-10 PB storage
NVIDIA Cosmos fue entrenado con 20 millones de horas de video real-world. ¿Qué significa esto en términos prácticos?
Breakdown de Costes Data
Alternativa: Datos Sintéticos
Generar video sintético con simuladores 3D (NVIDIA Omniverse, Unity, Unreal Engine). Ventajas:
- ✓Control perfecto sobre distribución data (generas edge cases a voluntad)
- ✓Cero costes annotation (labels automáticos desde simulator)
- ✓GDPR-friendly (no necesitas consentimiento grabaciones real-world)
Limitación: Domain gap (modelos entrenados solo con sintético fallan en real-world). Necesitas mix 70% sintético + 30% real para robustez.
Desafío #5: Integración Legacy Systems
60% AI leaders reportan esto como blocker #1
La mayoría de enterprises tienen infraestructura 10-15 años de antigüedad. World models requieren:
- •GPU clusters (legacy systems solo tienen CPUs)
- •Data pipelines video (legacy usa solo structured data SQL)
- •Real-time inference APIs (legacy batch processing nightly)
- •Monitoring especializado (legacy APM tools no entienden ML metrics)
Costes Típicos Migración
- • Cloud migration: $200k-500k (si on-premise legacy)
- • Data pipeline refactor: $100k-300k (6-12 meses)
- • API integration: $50k-150k
- • Change management (training equipos): $50k-100k
TOTAL MIGRACIÓN: $400k-1M + 6-12 meses timeline
⚠️ Realidad Check
Estos 5 desafíos NO son razón para NO usar world models. Son razón para:
- 1.Evaluar HONESTAMENTE si tu caso uso los necesita (sección siguiente)
- 2.Presupuestar REALÍSTICAMENTE (no subestimar costes 10x)
- 3.Planear timeline 6-12 meses (NO "2 sprints")
- 4.Considerar consultorías/plataformas para reducir riesgo
Guía Decisión: ¿Tu Caso de Uso NECESITA World Models?
6. Guía Decisión: ¿Tu Caso de Uso NECESITA World Models?
La pregunta de $1 millón: ¿Deberías invertir en World Models o LLMs son suficientes para tu caso?
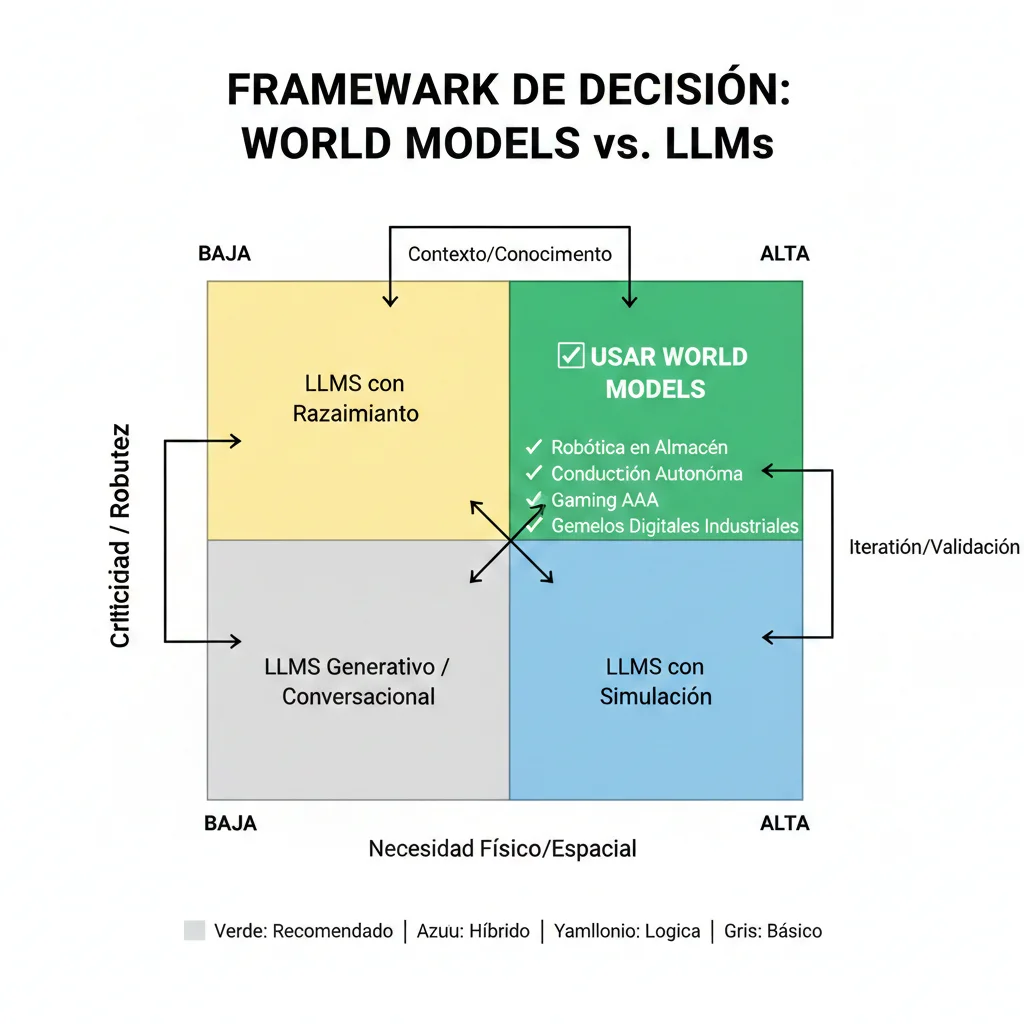
► Decision Framework: Matriz 2×2
USA World Models
SI cumples 3+ de estos criterios:
- ✓Necesitas entender física real (gravedad, colisiones, momentum)
- ✓Operas robots/AV/drones en mundo físico
- ✓Hallucinations LLM son riesgo crítico (healthcare, finance, legal)
- ✓Tienes budget $500k+ y timeline 6-12 meses
- ✓Robustness > Cost (safety-critical applications)
- ✓Necesitas simulación masiva (1M+ scenarios)
Ejemplos:
Robotics warehouse, conducción autónoma, gaming AAA, manufacturing digital twins
USA LLMs
SI cumples 3+ de estos criterios:
- ✓Caso uso principalmente texto/lenguaje
- ✓Budget
- ✓Necesitas deployment
- ✓Hallucinations tolerables con human-in-the-loop review
- ✓NO necesitas entender física/espacialidad 3D
- ✓Cost > Robustness (budget-constrained)
Ejemplos:
Chatbots customer service, generación contenido, code assistants, document analysis
► Checklist de 15 Preguntas
Responde SÍ/NO a cada pregunta. Si tienes 8+ respuestas SÍ, world models son altamente recomendables.
1. ¿Tu aplicación necesita entender física real?
(Gravedad, colisiones, momentum, trayectorias)
2. ¿Operas robots, vehículos autónomos, o drones en mundo físico?
3. ¿Hallucinations LLM son riesgo de compliance crítico?
(Healthcare, finance, legal, regulated industries)
4. ¿Tienes acceso a 100k+ horas de video training data?
(O presupuesto para datos sintéticos)
5. ¿Puedes costear 8-32 GPUs corriendo 24/7?
($280k-420k/mes coste inferencia)
6. ¿Tu equipo tiene expertise computer vision + reinforcement learning?
7. ¿Robustness es más crítico que cost?
8. ¿Timeline proyecto >6 meses acceptable?
9. ¿Generalización a nuevos objetos/entornos es crítica?
10. ¿Latencia real-time
11. ¿Simulación puede sustituir testing real-world?
12. ¿Causalidad/counterfactuals son importantes?
(What-if scenarios, explainability)
13. ¿Multi-modal understanding necesario?
(Video + sensor data + audio simultaneamente)
14. ¿Persistent state tracking over time necesario?
15. ¿ROI justificable vs approach LLM?
Interpretación Resultados:
- • 12-15 SÍ: World models ALTAMENTE recomendado
- • 8-11 SÍ: Considerar seriamente (evaluar ROI caso por caso)
- • 4-7 SÍ: Híbrido LLM + World Model podría funcionar
- • 0-3 SÍ: LLMs probablemente suficientes
► Approach Híbrido: Lo Mejor de Ambos Mundos
🔀 LLM Frontend + World Model Backend
En muchos casos, NO es world models OR LLMs. Es world models AND LLMs trabajando juntos:
LLM (frontal):
Entiende lenguaje natural del usuario, genera explicaciones, hace razonamiento de alto nivel.
World Model (backend):
Predice física, simula trayectorias, valida feasibility de acciones propuestas.
Ejemplo: Robot Assistant
- Usuario: "Tráeme la taza azul de la mesa"
- LLM: Parsea intención → "agarrar objeto taza color azul ubicación mesa"
- World Model: Predice trayectoria brazo robótico, simula agarre, valida no hay colisiones
- Robot: Ejecuta acción validada
- LLM: Responde al usuario "Listo, aquí está tu taza"
Esta arquitectura combina fortalezas: lenguaje natural (LLM) + física robusta (World Model).
Implementación Production: Checklist 25 Puntos
7. Implementación Production: Checklist 25 Puntos
Si decidiste que world models son viables para tu caso, aquí está el checklist completo de infraestructura, software, datos, y compliance.
Infraestructura (10 puntos)
1. GPU Cluster
Mínimo 8× H100 80GB ($200k hardware) o equivalente cloud (AWS P5, Azure NDv5, GCP A3)
2. High-Bandwidth Networking
400 Gbps InfiniBand o RoCE para comunicación GPU-to-GPU ($50k hardware)
3. Storage Masivo
10 PB NVMe para training data ($100k-300k). Distributed file system (HDFS, Ceph, WekaFS)
4. Cooling Industrial
Liquid cooling para densidad GPU alta (8+ GPUs disipan 5-10kW cada uno)
5. Power Redundante
500kW+ supply redundant (dual power supplies). UPS para evitar pérdida checkpoints durante training
6. Cloud Alternative Evaluation
AWS P5 (H100), Azure NDv5 (H100), GCP A3 (H100). Comparar coste on-premise vs cloud 3 años
7. Cost Monitoring Real-Time
GPU utilization tracking (idle GPUs = dinero quemado). Alert cuando utilization
8. Backup & Redundancia
Redundant model checkpoints (S3 Glacier, Google Coldline). Policy: checkpoint cada 2 horas durante training
9. Low-Latency Interconnect
GPUs en mismo rack para minimizar latency comunicación. NUMA-aware deployment
10. Security & Access Control
VPN access only, encrypted storage (AES-256), IAM roles granular, audit logging
Software Stack (8 puntos)
11. Framework Deep Learning
PyTorch 2.0+ (preferido para research flexibility) o JAX (para TPUs Google Cloud)
12. Orchestration Distribuido
Kubernetes + Ray para distributed training multi-node. Alternatively: Slurm para HPC clusters
13. Monitoring & Observability
Weights & Biases (experiment tracking), TensorBoard (visualización), custom Prometheus metrics (GPU utilization, throughput)
14. Data Pipeline Video
FFmpeg (video decoding), PyAV (Python bindings), OpenCV (preprocessing). GPU-accelerated decoding (NVDEC)
15. Data Augmentation
Albumentations, custom temporal transforms (random crops, color jitter, temporal subsampling)
16. Quality Filtering
Blur detection (Laplacian variance), scene change detection (frame differencing), corrupted file removal
17. Version Control
DVC (Data Version Control) para datasets, MLflow para models, Git para código
18. CI/CD Pipeline
GitHub Actions, Jenkins, o GitLab CI para automated testing + deployment. Smoke tests antes de deploy production
Data Pipeline (4 puntos)
19. Data Collection Strategy
Web scraping (YouTube, internet archives), partnerships (data providers), synthetic generation (NVIDIA Omniverse, Unity)
20. Annotation (si necesario)
Scale AI, Appen para human-in-the-loop. Alternatively: self-supervised (JEPA no necesita labels explícitos)
21. Preprocessing Automatizado
Normalization (mean/std), resizing (consistent resolution), temporal alignment (frame rate standardization)
22. Storage Distribuido
Distributed file system (HDFS, Ceph). Replication factor 3 para fault tolerance
Compliance & Governance (3 puntos)
23. GDPR Compliance (video data)
Consent management para video training data. Anonymization pipelines (blur faces/license plates). Alternatively: datos sintéticos 100%
24. Bias Auditing
Demographic diversity checks en training data. Fairness metrics (demographic parity, equal opportunity). Periodic audits post-deployment
25. Explainability Tooling
Attention visualization (qué frames mira el modelo), saliency maps (qué regiones importan), counterfactual explanations ("si objeto estuviera aquí...")
💡 Pro Tip: Empezar Pequeño
NO necesitas implementar todos los 25 puntos el día 1. Approach incremental:
Fase 1 (Meses 1-2): Puntos 1-6, 11-14, 19-20 (infraestructura básica + data pipeline inicial)
Fase 2 (Meses 3-4): Puntos 7-10, 15-18, 21-22 (optimización + CI/CD)
Fase 3 (Meses 5-6): Puntos 23-25 (compliance para production launch)
La Carrera de los $50 Mil Millones: Quién Está Construyendo World Models
3. La Carrera de los $50 Mil Millones: Quién Está Construyendo World Models
La apuesta de LeCun no es solitaria. Cinco jugadores multimillonarios están en una carrera frenética para dominar World Models antes de 2027.
El Mercado de Physical AI
$5.23B
2025
$49.73B
2033
CAGR 32.53% — Crecimiento explosivo
Fuente: SNS Insider, Physical AI Market Report 2025
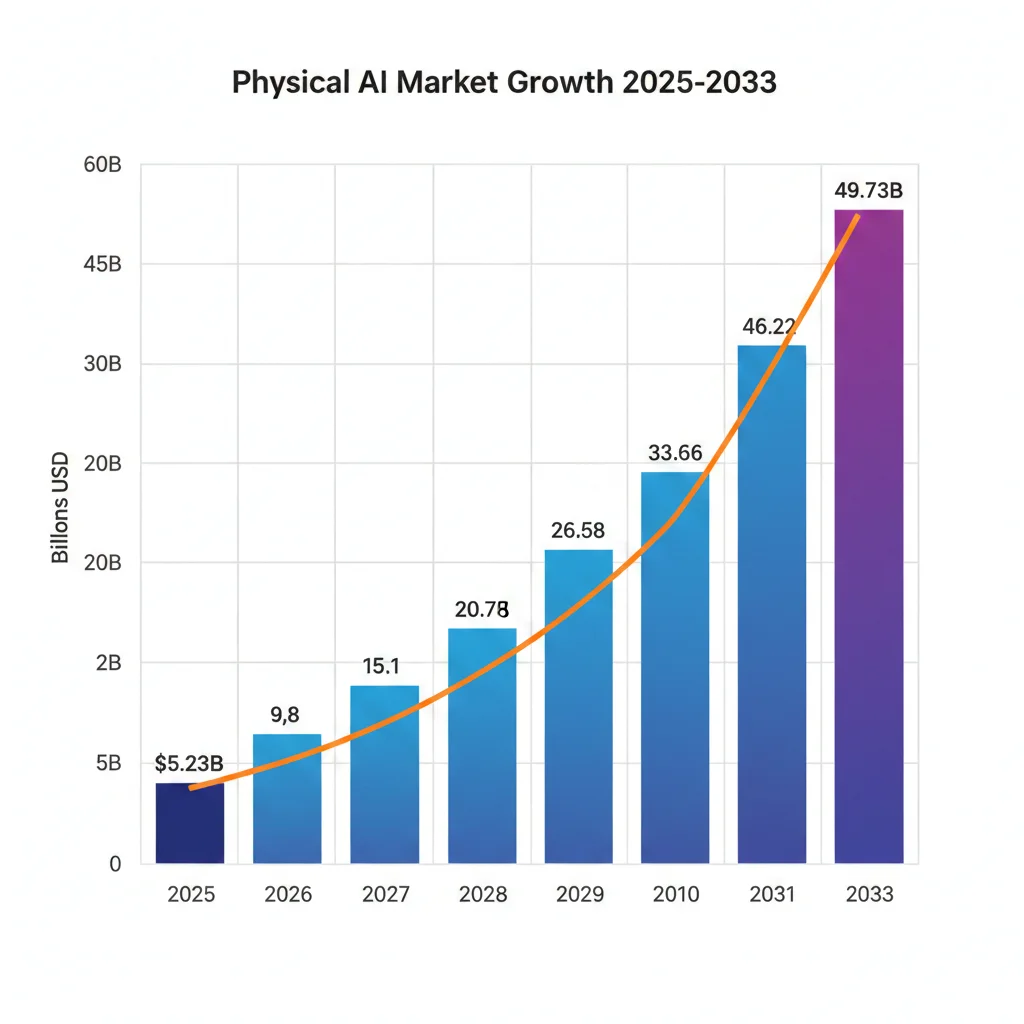
► Los 5 Jugadores Principales
Yann LeCun — AMI Labs (Advanced Machine Intelligence)
Fundación: Diciembre 2025, París (Francia)
CEO: Alexandre Lebrun (ex-fundador Nabla, adquirida por IBM)
Enfoque: JEPA architecture (non-generative). Apuesta filosófica que predecir representaciones abstractas > generar pixels.
Target inicial: Robótica industrial, simulación física, agentes autónomos.
"La apuesta más grande de LeCun: si JEPA falla, su legado completo está en riesgo. Si funciona, cambia la industria IA para siempre."
Google DeepMind — Genie 3
Hito técnico: Primer world model generativo interactivo en tiempo real.
Specs: Genera entornos 3D a 24 fps, resolución 720p, memoria visual ~1 minuto, latencia milisegundos.
Uso actual: Research preview limitado. Solo acceso académico (no comercial aún).
Aplicación: Gaming (generación procedural), simulación, entrenamiento agentes RL.
"Genie 3 demuestra que real-time world models SON posibles. El problema ahora es reducir costes de inferencia 10x para hacerlo viable comercialmente."
Meta AI — V-JEPA 2 (Video Joint Embedding)
Training: Pre-entrenado en 1M horas video + 1M imágenes. Fine-tuned con solo 62 horas de datos robot (DROID dataset).
Performance robotics: 65-80% tasa éxito en tareas pick-and-place zero-shot (objetos nunca vistos antes).
Benchmarks nuevos: IntPhys 2 (física intuitiva), MVPBench (video prediction), CausalVQA (razonamiento causal).
Aplicación: Planificación robótica sin necesidad de simuladores 3D detallados. Aprende física del mundo real observando video.
"V-JEPA 2 prueba que solo necesitas 62 horas de datos robot para fine-tuning si pre-entrenas con suficiente video genérico. Esto reduce costes de datos 100x."
Fei-Fei Li — World Labs (Marble)
Fundadora: Fei-Fei Li (ex-directora AI Lab Stanford, pionera ImageNet).
Lanzamiento: Agosto 2024 funding, Noviembre 2025 producto comercial (primer world model comercial del mercado).
Features: Genera entornos 3D persistentes desde texto/imágenes. Compatible VR. Exporta a game engines.
Pricing freemium: Gratis (4 generaciones/mes) → $20/mes → $35/mes → $95/mes (enterprise).
Target market: Gaming studios, arquitectura/diseño, creadores contenido AR/VR.
"Marble es prueba que world models pueden monetizarse YA (no solo research). Pricing freemium similar a Midjourney demuestra market-fit."
NVIDIA — Cosmos Platform
Lanzamiento: CES 2025 (Enero). 2 millones de descargas en 30 días (adopción masiva).
Training data: 20 millones de horas de video real-world (dataset más grande del mercado).
Tiers: Nano (edge devices), Super (baseline quality), Ultra (máxima calidad). Modelos pre-entrenados descargables.
Clientes enterprise: 1X (robots humanoides), Agility Robotics, Figure AI, Waabi (AV), XPENG, Uber (delivery bots).
Estrategia: NVIDIA apuesta por democratizar world models (como hizo con LLMs). Proveer infraestructura (GPUs H100/B200) + software (Cosmos) = lock-in ecosistema.
"Cosmos es el 'NVIDIA CUDA de world models'. Quien controla la plataforma controla el mercado. 2M descargas en 30 días señala adopción exponencial."
► Gaming AI: El Mercado de $37.89 Mil Millones
Además del mercado Physical AI ($50B), hay otro mercado explosivo donde world models tendrán impacto masivo: Gaming & Entretenimiento.
AI in Gaming Market
$1.2B
2023
$37.89B
2034
CAGR 20-36% según firma
Fuente: Precedence Research, Grand View Research 2025
Drivers de crecimiento:
- ✓Generación procedural de mundos 3D (world models eliminan necesidad engines tradicionales)
- ✓NPCs con comportamiento realista (physics-aware AI)
- ✓AR/VR experiences (73% del mercado AI gaming en 2030)
- ✓Reducción costes desarrollo (Microsoft: 73% reducción con world models vs artists manuales)
Con €500M + $230M + inversiones multimillonarias de Google/Meta/NVIDIA, está claro: World Models NO son hype. Son la próxima frontera de IA.
Qué Son World Models: IA que Entiende Física (No Solo Texto)
2. Qué Son World Models: IA que Entiende Física (No Solo Texto)
Imagina una IA que no solo predice palabras, sino que entiende cómo objetos caen, colisionan, se mueven, e interactúan en el espacio 3D. Eso es un World Model.
🌍 Definición Técnica Accesible
Un World Model es una red neuronal entrenada para predecir estados futuros de un sistema físico o entorno, basándose en observaciones visuales (video) y acciones tomadas.
En lugar de predecir "la siguiente palabra", predice "el siguiente frame de video" o "cómo se moverá este objeto si aplico esta fuerza". Aprende física implícitamente observando millones de horas de video del mundo real.
► LLMs vs World Models: Comparación Arquitectural
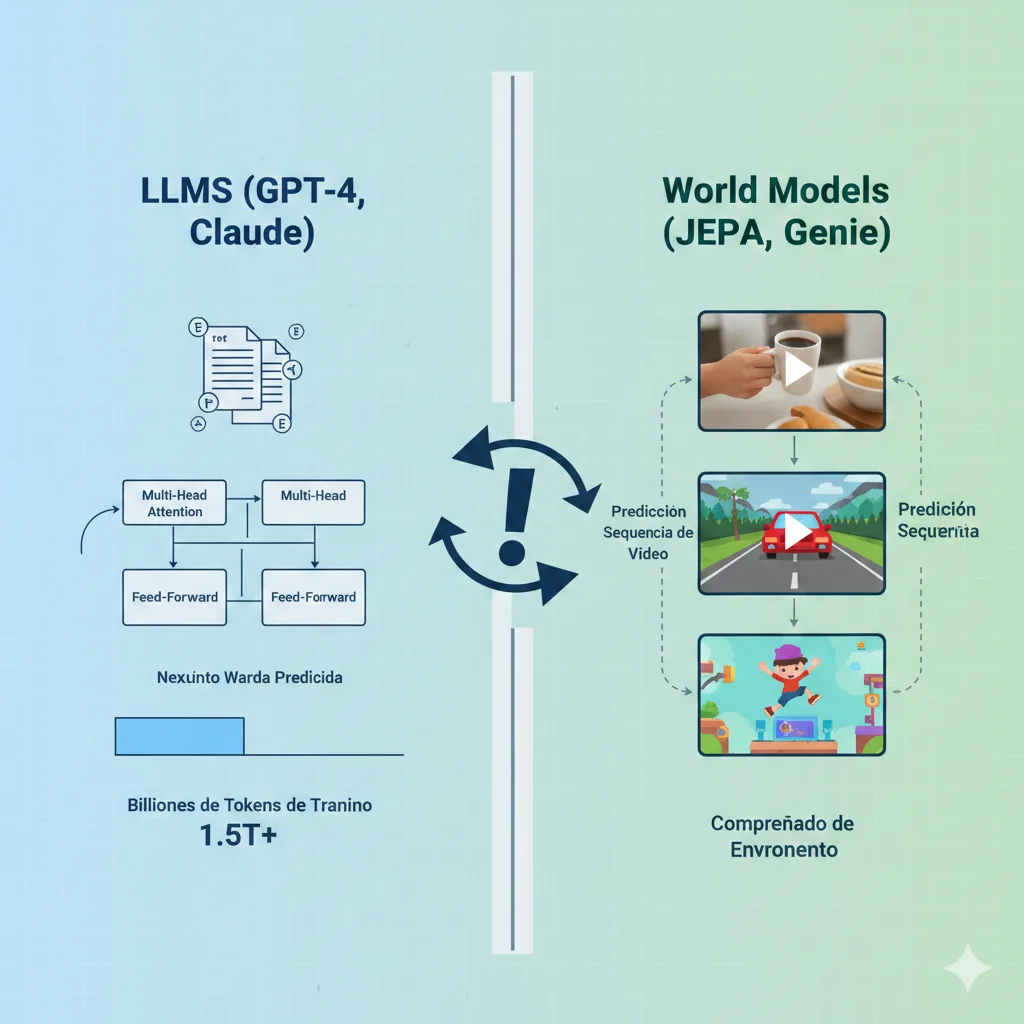
| Dimensión | LLMs (GPT-4, Claude) | World Models (JEPA, Genie) |
|---|---|---|
| Datos Entrenamiento | Texto (billones de tokens web, libros, código) | Video + imágenes + datos sensoriales (millones de horas) |
| Qué Entiende | Patrones estadísticos en lenguaje natural | Dinámica física, causalidad, espacialidad 3D |
| Predicción | Siguiente palabra en secuencia | Siguiente estado/frame basado en acción |
| Robustez | Frágil (1% perturbación → colapso) | Robusto (generaliza a nuevos objetos/entornos) |
| Mejor Para | Chatbots, generación texto, code completion | Robótica, conducción autónoma, gaming, simulación |
| Coste Entrenamiento | $5k-50k (fine-tuning), $10M-100M (foundation) | $50k-500k (pequeño), $2M-10M (foundation) |
| GPUs Inferencia | 1-8 GPUs por request | 8-32 GPUs por request (4-8x más caro) |
| Alucinaciones | 9.2% promedio, crítico en compliance | Mínimas (anclado a física observable) |
► Arquitectura JEPA: La Visión de Yann LeCun
La arquitectura que LeCun está apostando €500M se llama JEPA (Joint Embedding Predictive Architecture). A diferencia de transformers generativos (GPT), JEPA es no-generativo.
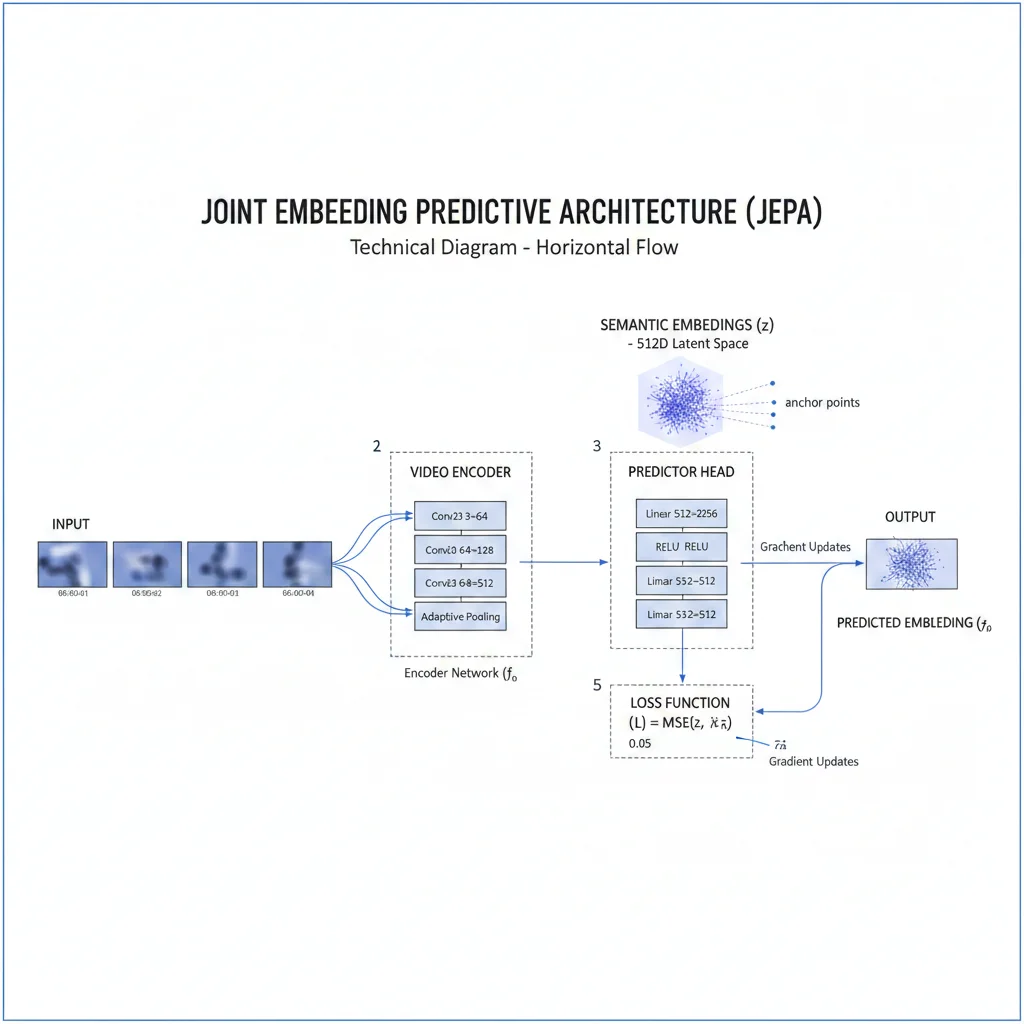
🔧 Componentes JEPA Simplificados
Encoder (Codificador)
Toma frames de video como entrada y los comprime en embeddings semánticos (representaciones abstractas del estado del mundo). Por ejemplo, en lugar de guardar cada pixel, guarda "hay una taza azul en posición X con orientación Y".
Predictor (Predictor)
Toma los embeddings del pasado + una acción (ej: "empujar taza a la izquierda") y predice el embedding del futuro. NO predice pixels exactos, predice representaciones abstractas del estado futuro.
Ventaja Clave
Al predecir representaciones abstractas en lugar de pixels, JEPA evita "modelar incertidumbre irrelevante" (como texturas exactas, sombras, reflejos). Se enfoca en información estructural: posiciones, movimientos, relaciones espaciales.
"La clave es NO generar pixels. Generar pixels es una tarea de muy alta dimensión con mucha incertidumbre irrelevante. Mejor predecir representaciones abstractas."
— Yann LeCun, explicando JEPA en NVIDIA GTC 2025
► Código Conceptual: Cómo Luce JEPA
Aquí un ejemplo simplificado en PyTorch para ilustrar la arquitectura (esto es conceptual, no production-ready):
# Arquitectura JEPA simplificada para World Models import torch import torch.nn as nn class VideoEncoder(nn.Module): """ Encoder: Video frames → embeddings semánticos Comprime información visual en representaciones abstractas """ def __init__(self, embed_dim=512): super().__init__() # CNN para procesar frames (simplificado) self.conv_layers = nn.Sequential( nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1), nn.ReLU(), nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1), nn.ReLU(), nn.Conv2d(128, embed_dim, kernel_size=3, stride=2, padding=1), nn.AdaptiveAvgPool2d(1) ) def forward(self, frames): # frames: (batch, channels, height, width) embeddings = self.conv_layers(frames) return embeddings.squeeze(-1).squeeze(-1) # (batch, embed_dim) class Predictor(nn.Module): """ Predictor: embeddings pasado + acción → embeddings futuro Aprende dinámica del mundo sin generar pixels """ def __init__(self, embed_dim=512, action_dim=4): super().__init__() self.fc = nn.Sequential( nn.Linear(embed_dim + action_dim, 1024), nn.ReLU(), nn.Linear(1024, 1024), nn.ReLU(), nn.Linear(1024, embed_dim) ) def forward(self, past_embedding, action): # Concatena estado pasado + acción x = torch.cat([past_embedding, action], dim=-1) future_embedding = self.fc(x) return future_embedding class WorldModelJEPA(nn.Module): """ World Model completo usando JEPA NO genera pixels, solo predice representaciones abstractas """ def __init__(self, embed_dim=512, action_dim=4): super().__init__() self.encoder = VideoEncoder(embed_dim) self.predictor = Predictor(embed_dim, action_dim) def forward(self, past_frames, action=None): # Encode: Video → representaciones abstractas past_emb = self.encoder(past_frames) if action is not None: # Predict: ¿Cómo cambiará el mundo si tomo esta acción? future_emb = self.predictor(past_emb, action) return future_emb else: # Solo encoding (pre-training sin acciones) return past_emb # Ejemplo de uso model = WorldModelJEPA(embed_dim=512, action_dim=4) # Entrenamiento sin acciones (pre-training en video) past_frames = torch.randn(32, 3, 224, 224) # batch de 32 frames embeddings = model(past_frames) print(f"Embeddings shape: {embeddings.shape}") # (32, 512) # Predicción con acción (fine-tuning con robot data) action = torch.randn(32, 4) # 4D: [dx, dy, dz, gripper] predicted_future = model(past_frames, action) print(f"Predicted future shape: {predicted_future.shape}") # (32, 512) DIFERENCIA CLAVE VS GENERATIVE MODELS
Modelos generativos (Sora, Runway) predicen pixels exactos del siguiente frame. JEPA predice embeddings abstractos. Esto lo hace 10-100x más eficiente computacionalmente y evita aprender ruido irrelevante (texturas, iluminación).
Ahora que entiendes qué son World Models arquitecturalmente, veamos quién está invirtiendo miles de millones en construirlos.
Timeline & Roadmap 2026-2030
8. Timeline & Roadmap: ¿Cuándo Estará Listo Para TU Empresa?
La pregunta que todo CTO/CFO hace: "¿Cuándo world models serán mainstream y accesibles para mid-market?"

AHORA: Early Adopters + Research Labs
Maturity: 60% (functional pero expensive)
Quién Adopta
- • Robotics research labs (Meta AI, DeepMind)
- • Autonomous vehicle companies (Waymo, Tesla, Wayve)
- • AAA gaming studios (Microsoft, Ubisoft)
- • Enterprises con budget ML $1M+ anual
Costes Típicos
- • Training pequeño: $50k-500k
- • Training foundation: $2M-10M
- • Inferencia 24/7: $280k-420k/mes
- • Team talent: $450k-750k/año
Hitos Clave 2026
- •Q2 2026: AMI Labs product launch (¿cumplirá promesas de LeCun?)
- •Q3 2026: NVIDIA Cosmos v1.5 con 2x mejor inferencia latency
- •Q4 2026: OpenAI Sora 3 incorpora capacidades world model (rumor)
⚠️ RECOMENDACIÓN 2026: Piloto small-scale SI tienes budget $500k+ y timeline 12 meses. NO esperes ROI rápido. Es inversión estratégica.
2028
Mid-Market Adoption
Maturity: 75% (productionized pero still niche)
Quién Adopta
- • Manufacturing mid-size (digital twins)
- • Logistics optimization (Amazon, Uber clones)
- • AR/VR content creators
- • Scale-ups tech con budget $100k-500k
Costes (10x Reducción)
- • Training pequeño: $10k-100k
- • Plataformas managed: $20-95/mes (World Labs)
- • Inferencia 24/7: $50k-100k/mes (optimización HW)
- • Consultorías accessible: $50k-200k projects
Hitos Clave 2027-2028
- •2027: Apple integra world models en iOS (AR use cases para Vision Pro v2)
- •2027: NVIDIA Cosmos v2 con 10x lower inference cost (nuevos GPUs B200/B300)
- •2028: Gaming 60fps viable (latency
- •2028: Major robotics company (Tesla Bot?) production deployment masivo
✅ RECOMENDACIÓN 2027-2028: Production deployment viable para mid-market. Plataformas managed reducen barreras entrada. Budget $100k-500k acceptable ROI.
2030
Mainstream & Commodity
Maturity: 90% (como LLMs hoy en 2026)
Quién Adopta
- • Consumer apps mainstream
- • SMB automation (pequeñas empresas)
- • Personal assistants físicos (robots hogar)
- • Cualquier empresa con budget ML $10k+
Costes (100x Reducción)
- • APIs cloud: $0.01-0.10 por request
- • No-code platforms: $10-50/mes SaaS
- • Inference edge devices: Free (on-device)
- • Consultorías commoditizadas: $10k-50k
Hitos Clave 2029-2030
- •2029: AWS lanza "World Model as a Service" API (similar a Bedrock para LLMs)
- •2029: Meta integra world models en Quest VR headsets (on-device inference)
- •2030: Smartphones flagship incluyen world model chips dedicated (NPU)
- •2030: No-code platforms permiten crear apps world model sin programar
🚀 RECOMENDACIÓN 2029-2030: Adopción universal. World models tan accesibles como LLMs son hoy (2026). Empresas SIN world models quedarán obsoletas.
⏰ ¿Cuándo Deberías Empezar?
SI eres robotics/AV/gaming: Empieza piloto AHORA (2026). Ventaja competitiva early mover.
SI eres enterprise con compliance concerns: Evalúa en 2026, deploy en 2027 cuando plataformas maduras.
SI eres SMB/startup cost-constrained: Espera 2028-2029. Costes bajarán 10x, plataformas no-code disponibles.
🎯 Conclusión: La Apuesta Existencial de LeCun (Y Qué Significa Para Tu Empresa)
Volvamos al principio: ¿Por qué Yann LeCun, uno de los científicos de IA más respetados del planeta, apostó €500 millones y su legado completo en World Models?
Porque después de 40+ años investigando IA, LeCun llegó a una conclusión fundamental:
"Los LLMs aprenden estadísticas de texto. Los humanos aprenden física del mundo observando. Para alcanzar inteligencia general, la IA debe entender cómo funciona el mundo real, no solo cómo suena el lenguaje."
— Yann LeCun, parafraseo de múltiples entrevistas 2024-2025
Esta NO es una apuesta sobre tecnología. Es una apuesta sobre la naturaleza fundamental de la inteligencia.
► La Evidencia Acumulada
✓ Market Validation
- • €500M AMI Labs (LeCun)
- • $230M World Labs (Fei-Fei Li)
- • Billions Google DeepMind Genie
- • Billions Meta V-JEPA research
- • 2M downloads NVIDIA Cosmos (30 días)
✓ Technical Results
- • 65-80% success robotics zero-shot
- • 10x faster iteration AV development
- • 73% reducción costes gaming environments
- • Real-time 24fps @ 720p alcanzado (Genie 3)
- • Physical AI market $5.23B→$49.73B
Esto NO es hype. Los números no mienten.
► Para Tu Empresa: 3 Escenarios
🟢 Escenario 1: Necesitas World Models AHORA
SI operas: Robotics, conducción autónoma, gaming AAA, manufacturing digital twins, simulación física crítica.
ACCIÓN: Empieza piloto Q1 2026. Budget $500k-1M. Timeline 6-12 meses. Ventaja competitiva early mover.
🟡 Escenario 2: Evalúa World Models 2027
SI tienes: Compliance concerns (healthcare, finance, legal), hallucinations LLM son problema, o mid-market con budget $100k-500k.
ACCIÓN: Monitor developments 2026. Deploy cuando plataformas maduras (Q4 2026 - Q2 2027). Costes bajarán 5-10x.
🔵 Escenario 3: LLMs Suficientes (Por Ahora)
SI tu caso uso: Principalmente text/lenguaje, chatbots, content generation, code assistants, budget
⚠️ El Riesgo de Esperar Demasiado
Recuerda 2017: Transformers (GPT) fueron publicados. La mayoría de empresas dijeron "interesante pero no práctico".
5 años después (2022): ChatGPT lanza. Las empresas que NO invirtieron early están 3-5 años atrás intentando catch up.
World Models en 2026 = Transformers en 2017. Las empresas que ignoren esto repetirán el mismo error.
► Próximos Pasos Accionables
- 1
Evalúa tu caso uso con checklist 15 preguntas (sección 6)
¿Tienes 8+ respuestas SÍ? World models altamente recomendables.
- 2
Piloto small-scale $50k-100k (3 meses)
Valida feasibility técnica sin explotar budget completo. Prueba concepto con datos sintéticos.
- 3
Consulta con especialista (hint: BCloud Solutions 😉)
Si careces expertise CV+RL+Systems, trabajar con consultancy reduce riesgo 80%.
- 4
Monitor developments (AMI Labs, NVIDIA Cosmos, World Labs)
Suscríbete a newsletters, sigue a LeCun en X/Twitter, asiste NVIDIA GTC 2026.
El Pensamiento Final
"World Models NO son el futuro de la IA. Son el presente de la IA para quienes necesitan entender el mundo físico."
La pregunta ya NO es "¿Funcionan world models?" (respuesta: SÍ, lo demostraron).
La pregunta AHORA es: "¿Cuándo tu empresa los adoptará?"

Sobre el Autor
Abdessamad Ammi es CEO de BCloud Solutions y experto senior en IA Generativa y Cloud Infrastructure. Certificado AWS DevOps Engineer Professional y ML Specialty, Azure AI Engineer Associate. Ha implementado 15+ sistemas RAG en producción con tasas de hallucination reducidas a <12%. Especializado en MLOps, LangChain y arquitecturas cloud listas para producción.


