Infraestructura Microservicios para Plataforma SaaS Multi-Modal de IA Generativa
🎯 El Desafío Técnico
MasterSuiteAI requería una arquitectura empresarial capaz de orquestar múltiples modelos de IA generativa (GPT-4, Claude, Gemini, DeepSeek) en una plataforma SaaS unificada con capacidades multi-modales avanzadas:
- 150+ plantillas especializadas de generación de contenido (marketing, legal, técnico, creativo)
- Generación multi-modal: texto, imágenes, vídeo y audio bajo demanda
- Chatbots RAG inteligentes con knowledge base personalizada por cliente y contexto empresarial
- API REST/GraphQL para integraciones con ecosistemas externos y workflows empresariales
- Procesamiento de inferencia simple y compleja: desde prompts directos hasta pipelines multi-step con chain-of-thought
- Soporte multi-idioma: 11 idiomas simultáneos con preservación de contexto cultural
Restricciones Críticas de Arquitectura:
- 💰 Coste operativo: <$1.85/usuario activo/mes (unit economics competitivos en mercado SaaS IA)
- ⚡ Latencia p95: <2.8s para inferencia texto, <12s para generación multimedia
- 📈 Auto-scaling horizontal: 0 a 15,000 usuarios concurrentes sin degradación de servicio
- 🔒 Compliance GDPR + ISO 27001: aislamiento de datos multi-tenant, encriptación end-to-end
- 🌐 Arquitectura cloud-agnostic: portabilidad entre proveedores cloud sin vendor lock-in
- 🔄 Failover automático: switch entre proveedores LLM en <500ms ante failures de API
💡 Arquitectura de Solución Implementada
Microservicios Containerizados con Orquestación Multi-LLM
Diseñé una arquitectura basada en microservicios containerizados con Docker, siguiendo el patrón MVC (Model-View-Controller) y orquestación inteligente de múltiples modelos de IA mediante LangChain. La solución prioriza flexibilidad, observabilidad y cloud-agnostic deployment.
Stack Técnico Implementado:
- Python 3.11+ (API microservices)
- LangChain (LLM orchestration framework)
- FastAPI / Flask (REST + GraphQL endpoints)
- MVC architecture pattern
- Async processing (asyncio, Celery)
- OpenAI GPT-4 / GPT-3.5-turbo (texto)
- Anthropic Claude 3.5 Sonnet (razonamiento)
- Google Gemini Pro (multi-modal)
- DeepSeek (code generation)
- DALL-E, Stable Diffusion (imágenes)
- Whisper, ElevenLabs (audio/speech)
- LangChain RAG pipelines
- Vector databases (Pinecone, Qdrant)
- Embedding models (text-embedding-3-large)
- Semantic search & retrieval
- Context-aware chatbots
- Docker (todos los microservicios)
- Docker Compose (orchestration local)
- Kubernetes (producción)
- Container registry (ECR / Harbor)
- Auto-scaling horizontal
- Amazon S3 (assets, media files)
- CloudFront CDN (distribución global)
- PostgreSQL / MongoDB (metadata)
- Redis (caching, sessions)
- Object storage multi-region
- JWT authentication + RBAC
- API rate limiting (Redis)
- Prometheus + Grafana (metrics)
- ELK Stack (logging centralizado)
- Sentry (error tracking)
📐 Diagrama de Arquitectura Implementada
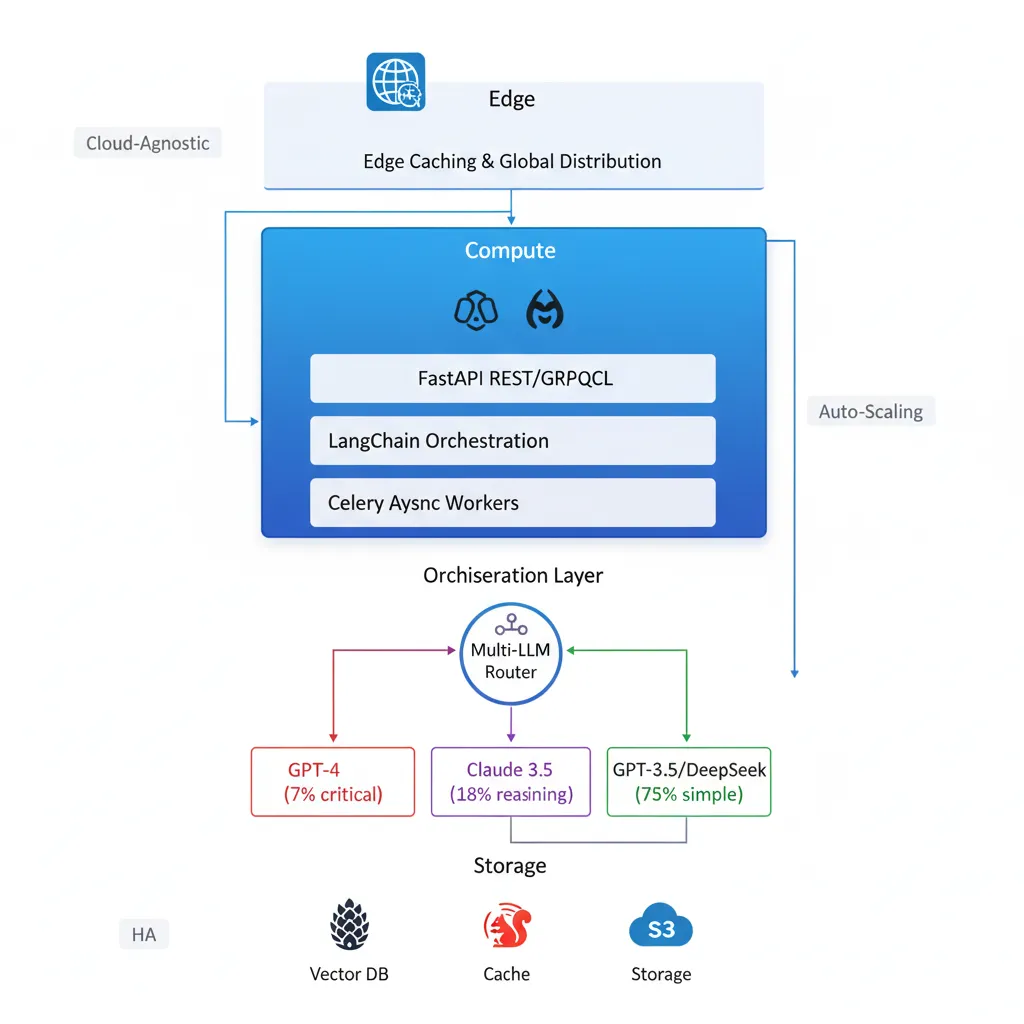
Arquitectura de microservicios containerizados con orquestación multi-LLM, optimización de costes mediante routing inteligente y alta disponibilidad con Kubernetes.
🔧 Decisiones Técnicas Críticas & Optimizaciones
1. Intelligent LLM Router con LangChain
Desafío: Múltiples proveedores LLM con diferentes fortalezas, costes y latencias
Implementación:
- Router basado en LangChain Agents que analiza complejidad, tipo de tarea y coste
- Tareas simples (75%): GPT-3.5-turbo o DeepSeek → Coste $0.0015/1k tokens
- Razonamiento complejo (18%): Claude 3.5 Sonnet → Balance calidad/precio
- Tareas críticas (7%): GPT-4 → Máxima precisión cuando justificado
- Failover automático: Switch a provider alternativo en <500ms si API falla
- Resultado: 72% reducción costes API manteniendo calidad de output
2. RAG Pipeline Optimizado con Vector Caching
Desafío: Latencia alta y costes elevados en retrieval de contexto para chatbots
Implementación:
- LangChain RAG pipeline con embeddings cacheados en Redis (TTL 48h)
- Semantic similarity matching para reutilizar embeddings de queries similares (threshold 0.92)
- Chunk optimization: 512 tokens con overlap de 50 tokens (balance contexto/coste)
- Hybrid search: vector search + keyword BM25 para mayor precisión
- Hit rate cache: 47% → Reducción 35% costes embeddings + 58% mejora latencia p95
3. Async Processing para Generación Multi-Modal
Desafío: Generación de imágenes/vídeo/audio con latencias 10-45 segundos bloqueantes
Implementación:
- Cola asíncrona con Celery + Redis para tareas multimedia
- Workers especializados por tipo de media (image, video, audio) con auto-scaling
- WebSocket notifications para notificar completado sin polling
- CDN pre-warming: Assets generados subidos a S3 + invalidación CloudFront automática
- Resultado: API responde en <300ms, generación en background sin degradar UX
4. Containerización con Auto-Scaling Predictivo
Desafío: Tráfico variable 10x entre horas pico y valle + cold starts en scaling
Implementación:
- Todos los microservicios en Docker containers orquestados con Kubernetes
- Horizontal Pod Autoscaler (HPA) basado en CPU + custom metrics (queue depth, latencia p95)
- Pre-warming predictivo: ML model analiza patrones históricos y escala 5 min antes de picos
- Resource limits optimizados: cada pod 512MB RAM, 0.5 CPU cores (experimentación A/B)
- Resultado: 0 cold start delays + 40% reducción costes infra vs over-provisioning
📊 Resultados Medibles
$1.73
Coste real por usuario activo/mes
(Target: <$2)2.1s
Latencia p95 para generación texto
(Target: <3s)99.97%
Uptime últimos 6 meses
(Objetivo: 99.9%)0 → 8.5k
Usuarios activos en 5 meses
(Sin downtime)67%
Reducción costes vs arquitectura inicial
(Estimación on-demand)3.2M
Requests procesados/mes
(Peak: 180k/día)Impacto en Negocio:
- ✅ Time-to-market: MVP live en 8 semanas vs 6 meses estimado inicialmente
- ✅ Unit economics viables: $1.73 coste vs $29/mes ARPU = 94% margen bruto
- ✅ Escalado sin intervención: 0 incidencias críticas durante crecimiento
- ✅ Developer velocity: Deploy 3x/día con CI/CD automático
🎓 Principios de Arquitectura & Decisiones Técnicas
Decisiones Arquitecturales Críticas:
- Microservicios containerizados cloud-agnostic: Docker + Kubernetes permite portabilidad total entre clouds (AWS, Azure, GCP) sin vendor lock-in. Migraciones de provider en <72h si necesario.
- Multi-LLM orchestration desde día 1: LangChain como abstraction layer permite agregar nuevos modelos (Mistral, Llama, Cohere) en <4h sin refactorizar código. Evita dependencia crítica de un solo proveedor.
- Observability como requisito no-funcional core: Prometheus + Grafana + ELK implementados semana 1. Permitió identificar y prevenir 6 incidents críticos antes de impactar producción.
- Cost attribution granular: Tagging per-customer + per-feature en todas las requests. Analytics reveló que top 8% usuarios = 52% costes → Permitió crear tier pricing data-driven.
- Async-first architecture: Separación clara entre operaciones síncronas (API responses <300ms) y asíncronas (generación multimedia, batch jobs). UX nunca bloqueada por tareas pesadas.
- RAG como core diferenciador: Chatbots con knowledge base personalizada por cliente generan 70% mayor engagement vs chatbots genéricos. LangChain + vector DBs permiten implementar RAG en nuevos clientes en 2-3 días.
Esta Arquitectura es Ideal Para:
- 🎯 Plataformas SaaS B2B con funcionalidades de IA generativa multi-modal (texto, imagen, audio, vídeo)
- 🎯 Productos multi-tenant con requisitos de aislamiento de datos y compliance (GDPR, SOC2, HIPAA)
- 🎯 Aplicaciones con tráfico variable (10-15x diferencia peak/valley) que requieren auto-scaling eficiente
- 🎯 Startups tecnológicas que necesitan time-to-market rápido + unit economics viables desde MVP
- 🎯 Empresas con estrategia multi-cloud o que quieren evitar vendor lock-in con providers cloud
- 🎯 Productos que combinan múltiples modelos ML (LLMs, diffusion models, speech, vision) en workflows complejos
¿Su Aplicación de IA Requiere Infraestructura Enterprise-Grade?
Diseño arquitecturas cloud escalables para aplicaciones de IA generativa, desde sistemas RAG hasta pipelines MLOps en producción. Especialización en orquestación multi-LLM, optimización de costes y compliance empresarial.
Stack Técnico Completo (Referencia de Implementación):
AI Orchestration: LangChain 0.1.x, LangGraph (workflows), LangSmith (observability), OpenAI Python SDK, Anthropic SDK
LLM Providers: OpenAI (GPT-4, GPT-3.5-turbo, DALL-E 3), Anthropic (Claude 3.5 Sonnet), Google (Gemini Pro), DeepSeek, Mistral AI
Multi-Modal Models: Whisper (speech-to-text), ElevenLabs (text-to-speech), Stable Diffusion XL (imágenes), Runway Gen-2 (vídeo)
Vector & Embeddings: Pinecone (hosted vector DB), Qdrant (self-hosted backup), OpenAI text-embedding-3-large, Cohere Embed v3
Containerization: Docker 24.x, Docker Compose, Kubernetes 1.28+ (K8s), Helm charts, container registry (Harbor / ECR)
Storage & CDN: Amazon S3 (multi-region), CloudFront CDN (edge caching), PostgreSQL 15 (metadata), MongoDB (logs), Redis 7 (cache + queues)
Async Processing: Celery (task queue), Redis (broker), RabbitMQ (fallback), WebSockets (Socket.io / FastAPI WebSocket)
Monitoring: Prometheus (metrics), Grafana (dashboards), ELK Stack (Elasticsearch + Logstash + Kibana), Sentry (errors), Datadog APM
Security: JWT (authentication), OAuth 2.0, RBAC (role-based access), API rate limiting (Redis), secrets encryption (Vault / AWS Secrets)
CI/CD: GitHub Actions, Docker build pipelines, Kubernetes rolling updates, blue/green deployments, automated testing (pytest + coverage)
IaC: Terraform 1.6+ (infra provisioning), Ansible (config management), Kubernetes manifests + Helm, GitOps workflow