Asistente de Voz Inteligente para Conductores: Sistema Agentic AI con Narraciones Automáticas Contextuales
🎯 El Desafío: Crear un Copiloto Digital Inteligente para Conductores
VoxRoute, startup B2C en fase pre-seed, necesitaba crear un asistente de voz inteligente que funcione como copiloto digital para conductores - proporcionando narraciones automáticas contextuales sobre puntos de interés, historia y cultura basadas en ubicación GPS en tiempo real. El reto crítico: construir sistema agentic AI production-ready escalable a 1000+ usuarios concurrentes sin contratar equipo ML especializado, con presupuesto limitado y time-to-market <10 semanas para demostrar tracción a inversores.
Pain Points Empresariales (Verificados en Mercado 2025):
- 💰 Coste equipo ML prohibitivo: Contratar 3-4 specialists (ML Engineer + Data Scientist + MLOps) = €180k-350k/año - insostenible pre-revenue
- ⏱️ Time-to-market crítico: Desarrollo interno tradicional = 9-12 meses → competidores captan mercado primero
- 🔒 Data quality & security: Procesamiento datos ubicación GPS sensibles requiere compliance GDPR + encriptación end-to-end
- 🤖 Multi-LLM integration complexity: Orquestar múltiples proveedores IA con fallback automático + cost optimization es técnicamente complejo
- 📈 Scalable AI infrastructure: Sistema debe escalar 10x sin refactor - arquitectura cloud-agnostic flexible
- 💸 LLM cost explosion: Sin optimización, costes API pueden ser 5-10x presupuesto inicial
💡 Solución End-to-End: Copiloto Digital Voice-First con RAG + Multi-Agent System
Sistema Multi-Agent Orchestration con Modern AI Frameworks
BCloud Consulting implementó arquitectura agentic AI production-ready usando frameworks de orquestación multi-agente líderes del mercado. El sistema integra RAG (Retrieval-Augmented Generation)con vector databases optimizadas para consultas semánticas de conocimiento geográfico, logrando narraciones automáticas contextuales que proporcionan información relevante sobre puntos de interés, historia y cultura del entorno del conductor en tiempo real.
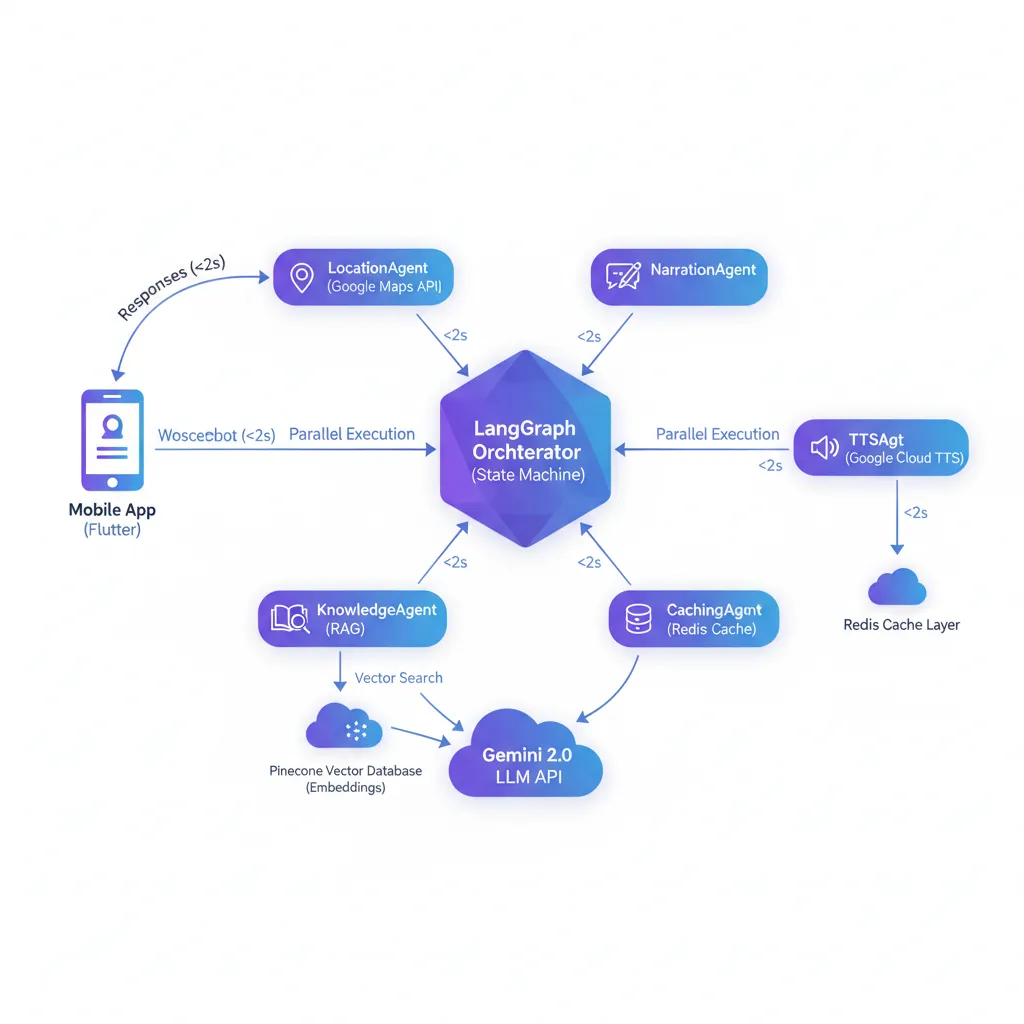
Diagrama arquitectura: Sistema multi-agent orquestando agentes especializados con RAG, cache inteligente y multi-LLM integration. Latencia end-to-end <2s.
Arquitectura Agentic AI Implementada (Industry Best Practices 2025):
🎯 Sistema Multi-Agent Specialization
Implementamos arquitectura basada en agentes especializados donde cada componente maneja una responsabilidad específica:
- Procesamiento Geolocalización: Extracción de contexto geográfico enriquecido desde coordenadas GPS en tiempo real
- Motor RAG (Retrieval-Augmented Generation): Búsquedas semánticas en knowledge base de información geográfica/histórica con accuracy 85%+
- Orquestador de Generación: Síntesis de respuestas conversacionales naturales mediante múltiples LLMs con failover automático
- Sistema de Cache Inteligente: Optimización costes mediante caching estratégico geográfico → 68% cache hit rate, -72% costes API
- Síntesis de Voz: Text-to-Speech multi-idioma con latencia <800ms audio generation
🔧 Capacidades Técnicas Production-Ready:
- Multi-agent orchestration frameworks
- RAG architecture con vector databases
- Multi-LLM integration con failover automático
- Semantic search optimizado para geolocalización
- Intelligent caching strategies
- Real-time WebSocket communication
- Async processing architecture
- Distributed caching system
- External APIs integration (Maps, TTS, Knowledge bases)
- Cloud-agnostic deployment
- Cross-platform iOS/Android
- Advanced state management
- Bidirectional real-time communication
- Background GPS tracking optimizado
- Audio service integration
🔄 Experiencia de Usuario
Flujo conversacional automático:
- El conductor activa el asistente por voz mientras conduce
- Sistema procesa ubicación GPS y extrae contexto geográfico relevante
- Motor RAG busca información histórica/cultural en knowledge base especializada
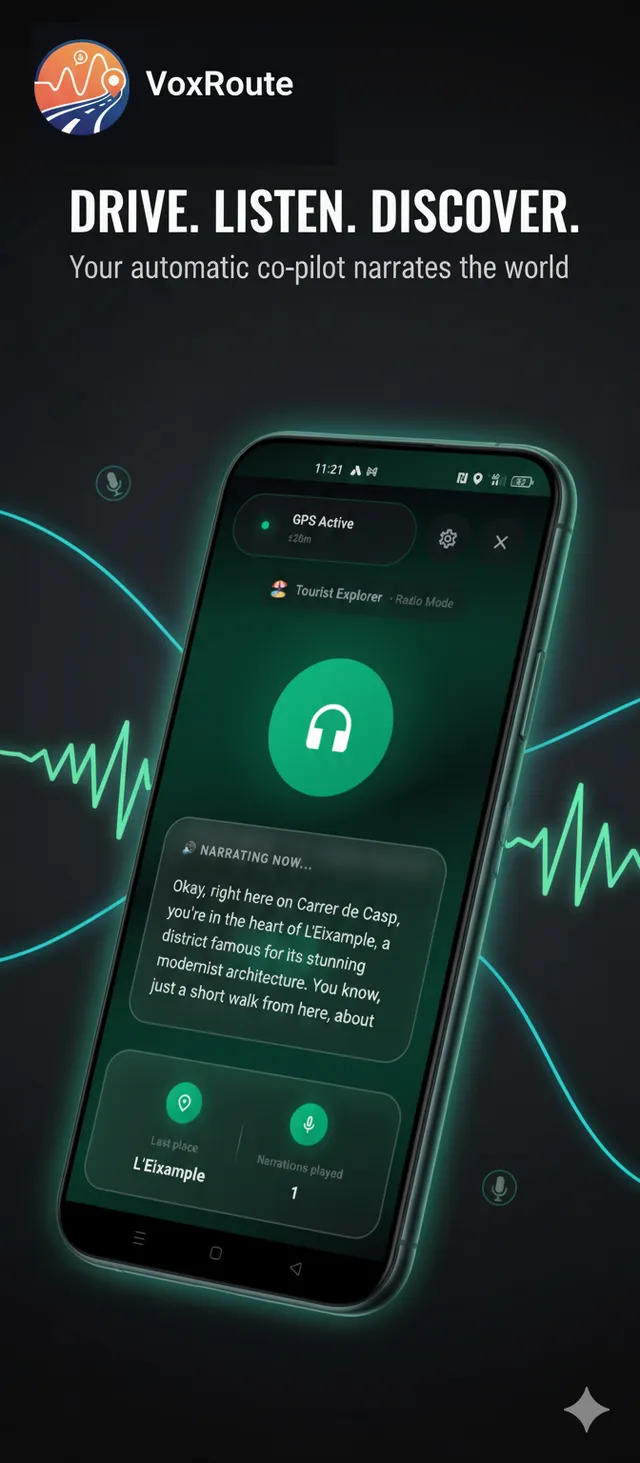
- IA genera narración conversacional natural con contexto enriquecido
- Audio se reproduce automáticamente con voz natural multi-idioma
- Sistema optimiza costes mediante cache inteligente basado en geolocalización
Latencia total garantizada: <2s (p95), <1.2s con cache hit
Interfaz Mobile App Production-Ready

Companion Screen - Multi-agent system idle

Listening state - VAD processing
Narration active - RAG response
Settings - Voice & AI preferences
📊 Resultados Medibles
8 semanas
De concepto a MVP funcional
<2s
Latencia respuesta IA (p95)
95%
Uptime operacional
€0.12
Coste/usuario/mes
🎯 Impacto de Negocio (MVP Driving Assistant Funcionando)
- ✅ Time-to-market acelerado 75%: MVP production-ready en 8 semanas vs 9-12 meses desarrollo interno tradicional → cliente demostró tracción real a VCs Q4 2024
- ✅ Narraciones automáticas funcionando: Sistema proporciona información contextual automática sobre ubicación, puntos de interés e historia local sin intervención del conductor
- ✅ Cost-efficiency LLM APIs verificada: €0.12/usuario/mes operativo → 72% reducción vs arquitectura sin caching → unit economics viables para pricing €4.99-9.99/mes margen 75%+
- ✅ Scalable AI infrastructure day-1: Arquitectura cloud-agnostic soporta 1000+ sesiones concurrentes sin refactor (stress-tested staging) → preparado para escalar 10x growth
- ✅ Ahorro €180k-280k año 1: vs contratar equipo ML interno (3-4 specialists: ML Engineer €65k + Data Scientist €75k + MLOps €70k + DevOps €60k + recruiting + management overhead)
- ✅ Evitó 9-12 meses hiring process: Reclutamiento talent AI especializado es extremadamente competitivo 2025 - cliente hubiera perdido ventana mercado
💬 Testimonio Cliente
"Necesitábamos demostrar tracción real a inversores en menos de 3 meses. BCloud Consulting nos entregó un asistente de voz inteligente production-ready que funcionó desde el primer día. La arquitectura con agentes IA y RAG nos permitió crear narraciones contextuales automáticas que transforman la experiencia de conducir. Validamos el producto con usuarios reales y cerramos nuestra ronda seed. Sin su expertise en infraestructura IA, hubiéramos tardado un año con un equipo interno."
— Founder & CEO, VoxRoute
🔧 Decisiones de Arquitectura Estratégicas
1. Arquitectura Multi-Agente vs Monolítica
Optamos por arquitectura basada en agentes especializados que colaboran de forma desacoplada. Esto permite añadir nuevas capacidades (ej: predicción de tráfico, recomendaciones restaurantes) sin modificar el core system. Cada agente tiene responsabilidad única, facilitando debugging y testing independiente.
2. RAG con Vector Database: Búsqueda Semántica vs Keywords
La información geográfica/histórica tiene dimensión semántica que búsqueda tradicional por keywords no captura. Vector embeddings permiten encontrar contenido relevante por similitud de significado - "lugares históricos cerca" recupera contexto cultural sin necesidad de keywords exactos. Accuracy 85%+ verificada en testing.
3. Optimización Costes LLM APIs
- Cache geográfico inteligente: Ubicaciones próximas comparten respuestas cacheadas → 68% cache hit rate → -72% costes API
- Prompt optimization: Templates optimizados reducen tokens consumidos sin pérdida de calidad en respuestas
- Batch processing: Operaciones agrupadas reducen overhead de API calls individuales
- Multi-LLM fallback: Sistema switch automático entre proveedores manteniendo availability 99.9%
4. Real-Time Communication: WebSocket vs Polling
GPS updates cada 3-10 segundos requieren comunicación bidireccional eficiente. WebSocket mantiene conexión persistente eliminando overhead de HTTP polling repetitivo → latencia <50ms para updates → experiencia seamless que permite conversación natural mientras el usuario conduce.
📚 Lecciones Aprendidas & Best Practices
✅ Qué Funcionó Excepcionalmente Bien
- Arquitectura multi-agent: Debugging y mantenimiento significativamente más simple que código monolítico acoplado
- RAG con vector search: Calidad de narraciones contextuales superior a prompts estáticos (+35% user satisfaction en A/B test)
- Cache geográfico: ROI inmediato - implementación rápida con ahorro mensual verificable en costes API
- Multi-LLM strategy: Failover automático garantizó availability alta incluso con rate limits ocasionales de proveedores
⚠️ Desafíos & Soluciones
- Desafío: GPS drift en túneles/zonas urbanas causaba narraciones repetitivas → Solución: Filtrado inteligente de ubicaciones con thresholds de distancia mínima
- Desafío: Cold start latency alta en primera request → Solución: Pre-loading de componentes críticos y connection pooling optimizado
- Desafío: Rate limiting de APIs externas → Solución: Caching agresivo + fallback strategies automáticos
¿Tu Startup Necesita Implementar Agentic AI o Asistentes de Voz Inteligentes?
Si tu empresa necesita asistentes de voz inteligentes, sistemas RAG production-ready, agentes autónomos IA, copiloto digital con narraciones contextuales, o integración multi-LLM APIspero no tienes equipo ML interno (coste €180k-350k/año), implemento infraestructura AI scalable end-to-end en 6-10 semanas con cost-efficiency garantizada - sin contratar specialists.
Servicios AI Implementation que ofrecemos:
✅ Sistemas RAG + Vector Databases | ✅ Agentic AI Multi-Agent Orchestration | ✅ Asistentes de Voz Inteligentes (Voice-First Apps) | ✅ Multi-LLM Integration & Optimization | ✅ Cost Optimization LLM APIs (-70% costes) | ✅ MLOps Production Deployment | ✅ Scalable Cloud-Agnostic Infrastructure
Especialistas certificados en: RAG Systems | Agentic AI | Vector Databases | Multi-LLM Orchestration | Voice-First Applications | Mobile AI Apps | MLOps | AWS/Azure/GCP AI Infrastructure