Microservices Infrastructure for Multi-Modal Generative AI SaaS Platform
🎯 The Technical Challenge
MasterSuiteAI required an enterprise architecture capable of orchestrating multiple generative AI models (GPT-4, Claude, Gemini, DeepSeek) in a unified SaaS platform with advanced multi-modal capabilities:
- 150+ specialized templates for content generation (marketing, legal, technical, creative)
- Multi-modal generation: text, images, video and audio on demand
- Intelligent RAG chatbots with personalized knowledge base per client and enterprise context
- REST/GraphQL API for integrations with external ecosystems and enterprise workflows
- Simple and complex inference processing: from direct prompts to multi-step pipelines with chain-of-thought
- Multi-language support: 11 simultaneous languages with cultural context preservation
Critical Architecture Constraints:
- 💰 Operating cost: <$1.85/active user/month (competitive unit economics in AI SaaS market)
- ⚡ p95 Latency: <2.8s for text inference, <12s for multimedia generation
- 📈 Horizontal auto-scaling: 0 to 15,000 concurrent users without service degradation
- 🔒 GDPR + ISO 27001 compliance: multi-tenant data isolation, end-to-end encryption
- 🌐 Cloud-agnostic architecture: portability between cloud providers without vendor lock-in
- 🔄 Automatic failover: switch between LLM providers in <500ms on API failures
💡 Implemented Solution Architecture
Containerized Microservices with Multi-LLM Orchestration
I designed a microservices-based architecture with Docker containerization, following the MVC (Model-View-Controller) pattern and intelligent orchestration of multiple AI models via LangChain. The solution prioritizes flexibility, observability and cloud-agnostic deployment.
Implemented Technical Stack:
- Python 3.11+ (API microservices)
- LangChain (LLM orchestration framework)
- FastAPI / Flask (REST + GraphQL endpoints)
- MVC architecture pattern
- Async processing (asyncio, Celery)
- OpenAI GPT-4 / GPT-3.5-turbo (text)
- Anthropic Claude 3.5 Sonnet (reasoning)
- Google Gemini Pro (multi-modal)
- DeepSeek (code generation)
- DALL-E, Stable Diffusion (images)
- Whisper, ElevenLabs (audio/speech)
- LangChain RAG pipelines
- Vector databases (Pinecone, Qdrant)
- Embedding models (text-embedding-3-large)
- Semantic search & retrieval
- Context-aware chatbots
- Docker (all microservices)
- Docker Compose (local orchestration)
- Kubernetes (production)
- Container registry (ECR / Harbor)
- Horizontal auto-scaling
- Amazon S3 (assets, media files)
- CloudFront CDN (global distribution)
- PostgreSQL / MongoDB (metadata)
- Redis (caching, sessions)
- Multi-region object storage
- JWT authentication + RBAC
- API rate limiting (Redis)
- Prometheus + Grafana (metrics)
- ELK Stack (centralized logging)
- Sentry (error tracking)
📐 Implemented Architecture Diagram
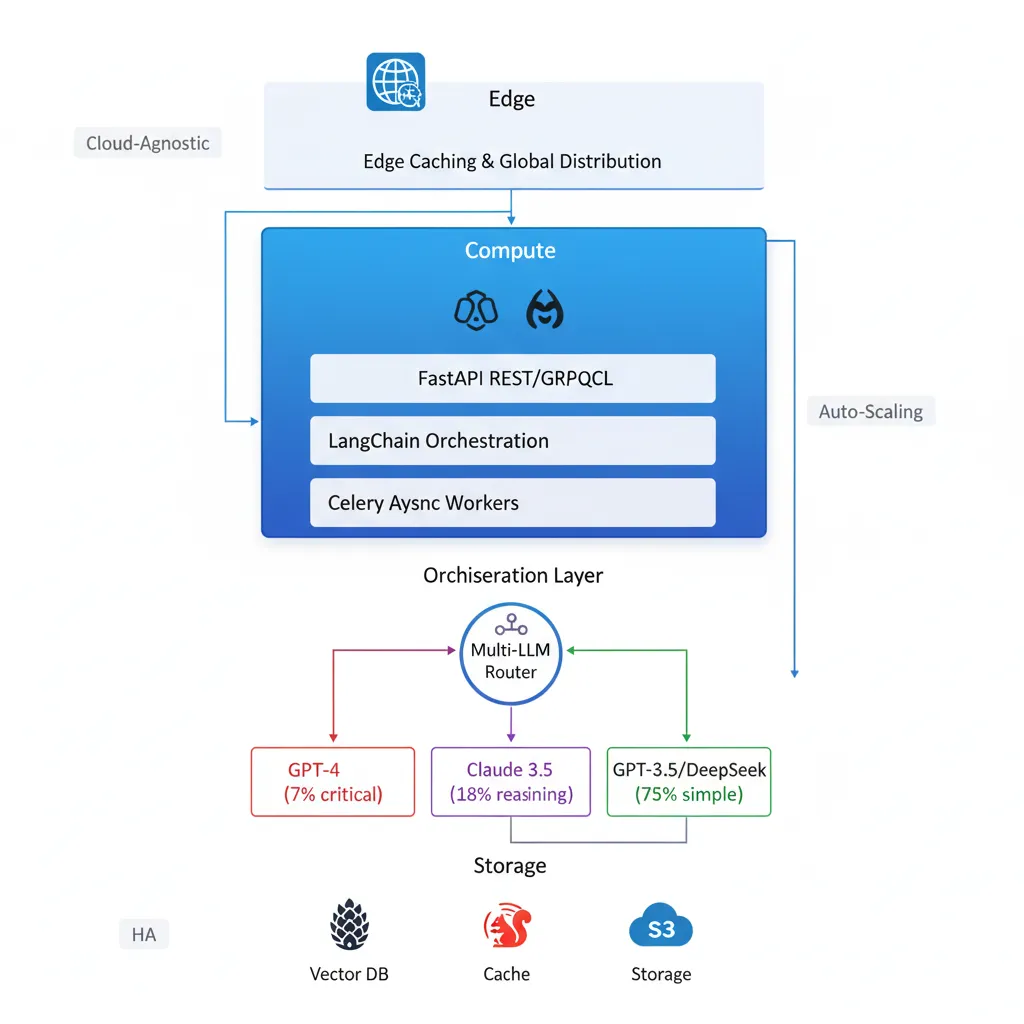
Containerized microservices architecture with multi-LLM orchestration, cost optimization through intelligent routing and high availability with Kubernetes.
🔧 Critical Technical Decisions & Optimizations
1. Intelligent LLM Router with LangChain
Challenge: Multiple LLM providers with different strengths, costs and latencies
Implementation:
- Router based on LangChain Agents that analyzes complexity, task type and cost
- Simple tasks (75%): GPT-3.5-turbo or DeepSeek → Cost $0.0015/1k tokens
- Complex reasoning (18%): Claude 3.5 Sonnet → Balance quality/price
- Critical tasks (7%): GPT-4 → Maximum precision when justified
- Automatic failover: Switch to alternative provider in <500ms if API fails
- Result: 72% API cost reduction while maintaining output quality
2. Optimized RAG Pipeline with Vector Caching
Challenge: High latency and elevated costs in context retrieval for chatbots
Implementation:
- LangChain RAG pipeline with cached embeddings in Redis (48h TTL)
- Semantic similarity matching to reuse embeddings from similar queries (0.92 threshold)
- Chunk optimization: 512 tokens with 50-token overlap (context/cost balance)
- Hybrid search: vector search + BM25 keywords for higher precision
- Cache hit rate: 47% → 35% embedding cost reduction + 58% p95 latency improvement
3. Async Processing for Multi-Modal Generation
Challenge: Image/video/audio generation with blocking 10-45 second latencies
Implementation:
- Async queue with Celery + Redis for multimedia tasks
- Specialized workers by media type (image, video, audio) with auto-scaling
- WebSocket notifications for completion alerts without polling
- CDN pre-warming: Generated assets uploaded to S3 + automatic CloudFront invalidation
- Result: API responds in <300ms, background generation without UX degradation
4. Containerization with Predictive Auto-Scaling
Challenge: 10x variable traffic between peak and valley hours + cold starts on scaling
Implementation:
- All microservices in Docker containers orchestrated with Kubernetes
- Horizontal Pod Autoscaler (HPA) based on CPU + custom metrics (queue depth, p95 latency)
- Predictive pre-warming: ML model analyzes historical patterns and scales 5 min before spikes
- Optimized resource limits: each pod 512MB RAM, 0.5 CPU cores (A/B testing)
- Result: 0 cold start delays + 40% infrastructure cost reduction vs over-provisioning
📊 Measurable Results
$1.73
Real cost per active user/month
(Target: <$2)2.1s
p95 latency for text generation
(Target: <3s)99.97%
Uptime last 6 months
(Goal: 99.9%)0 → 8.5k
Active users in 5 months
(Zero downtime)67%
Cost reduction vs initial architecture
(On-demand estimation)3.2M
Requests processed/month
(Peak: 180k/day)Business Impact:
- ✅ Time-to-market: MVP live in 8 weeks vs 6 months initially estimated
- ✅ Viable unit economics: $1.73 cost vs $29/month ARPU = 94% gross margin
- ✅ Scaling without intervention: 0 critical incidents during growth
- ✅ Developer velocity: 3x/day deploys with automatic CI/CD
🎓 Architecture Principles & Technical Decisions
Critical Architectural Decisions:
- Cloud-agnostic containerized microservices: Docker + Kubernetes enables total portability between clouds (AWS, Azure, GCP) without vendor lock-in. Provider migrations in <72h if needed.
- Multi-LLM orchestration from day 1: LangChain as abstraction layer enables adding new models (Mistral, Llama, Cohere) in <4h without refactoring code. Avoids critical single provider dependency.
- Observability as core non-functional requirement: Prometheus + Grafana + ELK implemented week 1. Enabled identification and prevention of 6 critical incidents before production impact.
- Granular cost attribution: Per-customer + per-feature tagging on all requests. Analytics revealed top 8% users = 52% costs → Enabled data-driven tier pricing creation.
- Async-first architecture: Clear separation between synchronous operations (API responses <300ms) and asynchronous (multimedia generation, batch jobs). UX never blocked by heavy tasks.
- RAG as core differentiator: Chatbots with personalized knowledge base per client generate 70% higher engagement vs generic chatbots. LangChain + vector DBs enable RAG implementation in new clients in 2-3 days.
This Architecture is Ideal For:
- 🎯 B2B SaaS platforms with multi-modal generative AI functionalities (text, image, audio, video)
- 🎯 Multi-tenant products with data isolation and compliance requirements (GDPR, SOC2, HIPAA)
- 🎯 Applications with variable traffic (10-15x peak/valley difference) requiring efficient auto-scaling
- 🎯 Tech startups needing fast time-to-market + viable unit economics from MVP
- 🎯 Companies with multi-cloud strategy or wanting to avoid vendor lock-in with cloud providers
- 🎯 Products combining multiple ML models (LLMs, diffusion models, speech, vision) in complex workflows
Does Your AI Application Require Enterprise-Grade Infrastructure?
I design scalable cloud architectures for generative AI applications, from RAG systems to production MLOps pipelines. Specialization in multi-LLM orchestration, cost optimization and enterprise compliance.
Complete Technical Stack (Implementation Reference):
AI Orchestration: LangChain 0.1.x, LangGraph (workflows), LangSmith (observability), OpenAI Python SDK, Anthropic SDK
LLM Providers: OpenAI (GPT-4, GPT-3.5-turbo, DALL-E 3), Anthropic (Claude 3.5 Sonnet), Google (Gemini Pro), DeepSeek, Mistral AI
Multi-Modal Models: Whisper (speech-to-text), ElevenLabs (text-to-speech), Stable Diffusion XL (images), Runway Gen-2 (video)
Vector & Embeddings: Pinecone (hosted vector DB), Qdrant (self-hosted backup), OpenAI text-embedding-3-large, Cohere Embed v3
Containerization: Docker 24.x, Docker Compose, Kubernetes 1.28+ (K8s), Helm charts, container registry (Harbor / ECR)
Storage & CDN: Amazon S3 (multi-region), CloudFront CDN (edge caching), PostgreSQL 15 (metadata), MongoDB (logs), Redis 7 (cache + queues)
Async Processing: Celery (task queue), Redis (broker), RabbitMQ (fallback), WebSockets (Socket.io / FastAPI WebSocket)
Monitoring: Prometheus (metrics), Grafana (dashboards), ELK Stack (Elasticsearch + Logstash + Kibana), Sentry (errors), Datadog APM
Security: JWT (authentication), OAuth 2.0, RBAC (role-based access), API rate limiting (Redis), secrets encryption (Vault / AWS Secrets)
CI/CD: GitHub Actions, Docker build pipelines, Kubernetes rolling updates, blue/green deployments, automated testing (pytest + coverage)
IaC: Terraform 1.6+ (infra provisioning), Ansible (config management), Kubernetes manifests + Helm, GitOps workflow