Intelligent Voice Assistant for Drivers: Agentic AI System with Contextual Automatic Narrations
🎯 The Challenge: Create an Intelligent Digital Copilot for Drivers
VoxRoute, a pre-seed B2C startup, needed to create an intelligent voice assistant functioning as a digital copilot for drivers - providing contextual automatic narrations about points of interest, history and culture based on real-time GPS location. The critical challenge: build a production-ready agentic AI system scalable to 1000+ concurrent users without hiring specialized ML team, with limited budget and time-to-market <10 weeks to demonstrate traction to investors.
Business Pain Points (Market Verified 2025):
- 💰 Prohibitive ML team cost: Hiring 3-4 specialists (ML Engineer + Data Scientist + MLOps) = €180k-350k/year - unsustainable pre-revenue
- ⏱️ Critical time-to-market: Traditional internal development = 9-12 months → competitors capture market first
- 🔒 Data quality & security: Sensitive GPS location data processing requires GDPR compliance + end-to-end encryption
- 🤖 Multi-LLM integration complexity: Orchestrating multiple AI providers with automatic fallback + cost optimization is technically complex
- 📈 Scalable AI infrastructure: System must scale 10x without refactor - flexible cloud-agnostic architecture
- 💸 LLM cost explosion: Without optimization, API costs can be 5-10x initial budget
💡 End-to-End Solution: Voice-First Digital Copilot with RAG + Multi-Agent System
Multi-Agent System Orchestration with Modern AI Frameworks
BCloud Solutions implemented production-ready agentic AI architecture using market-leading multi-agent orchestration frameworks. The system integrates RAG (Retrieval-Augmented Generation)with optimized vector databases for semantic queries of geographic knowledge, achieving contextual automatic narrations that provide relevant information about points of interest, history and local culture around the driver in real time.
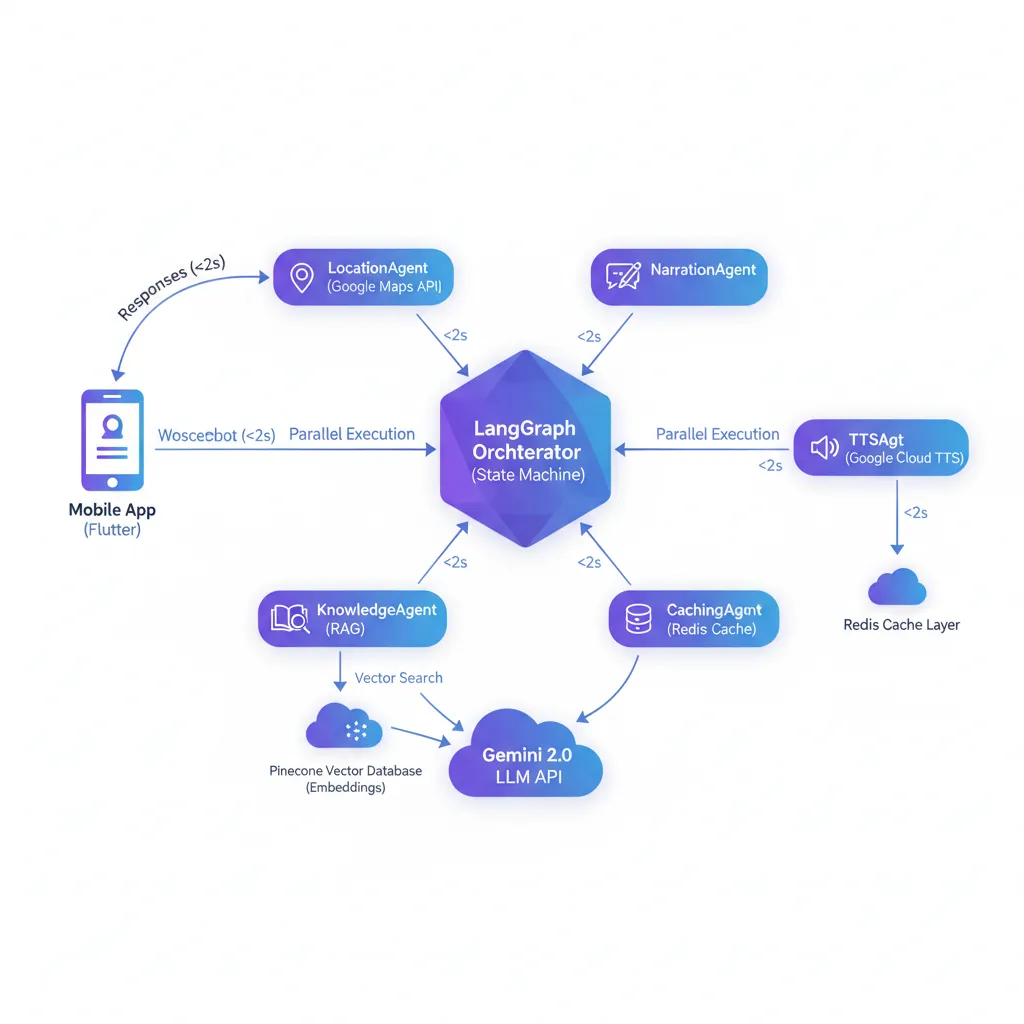
Architecture diagram: Multi-agent system orchestrating specialized agents with RAG, intelligent cache and multi-LLM integration. End-to-end latency <2s.
Implemented Agentic AI Architecture (Industry Best Practices 2025):
🎯 Multi-Agent System Specialization
We implemented architecture based on specialized agents where each component handles a specific responsibility:
- Geolocation Processing: Enriched geographic context extraction from real-time GPS coordinates
- RAG Engine (Retrieval-Augmented Generation): Semantic searches in knowledge base of geographic/historical information with 85%+ accuracy
- Generation Orchestrator: Natural conversational response synthesis via multiple LLMs with automatic failover
- Intelligent Cache System: Cost optimization through geographic strategic caching → 68% cache hit rate, -72% API costs
- Voice Synthesis: Multi-language Text-to-Speech with <800ms audio generation latency
🔧 Production-Ready Technical Capabilities:
- Multi-agent orchestration frameworks
- RAG architecture with vector databases
- Multi-LLM integration with automatic failover
- Semantic search optimized for geolocation
- Intelligent caching strategies
- Real-time WebSocket communication
- Async processing architecture
- Distributed caching system
- External APIs integration (Maps, TTS, Knowledge bases)
- Cloud-agnostic deployment
- Cross-platform iOS/Android
- Advanced state management
- Bidirectional real-time communication
- Optimized background GPS tracking
- Audio service integration
🔄 User Experience
Automatic conversational flow:
- Driver activates voice assistant while driving
- System processes GPS location and extracts relevant geographic context
- RAG engine searches historical/cultural information in specialized knowledge base
- AI generates natural conversational narration with enriched context
- Audio plays automatically with natural multi-language voice
- System optimizes costs through intelligent geolocation-based caching
Guaranteed total latency: <2s (p95), <1.2s with cache hit
Production-Ready Mobile App Interface

Companion Screen - Multi-agent system idle

Listening state - VAD processing
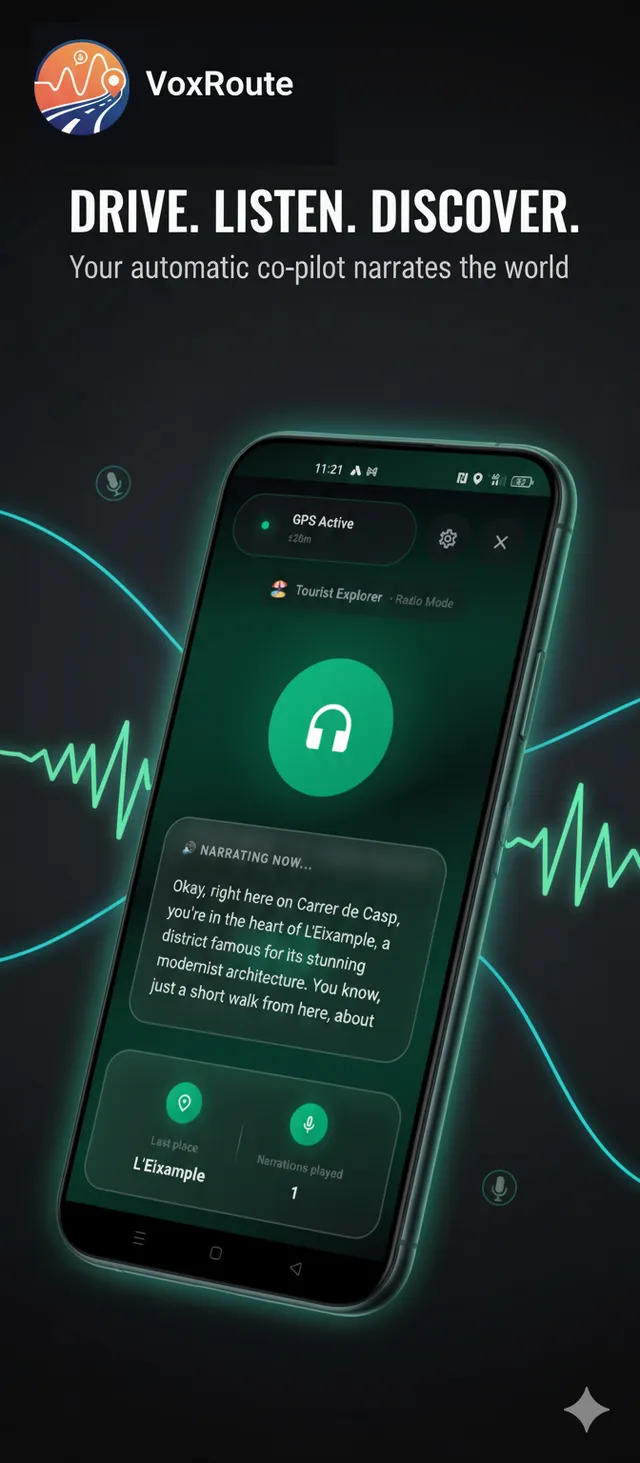
Narration active - RAG response
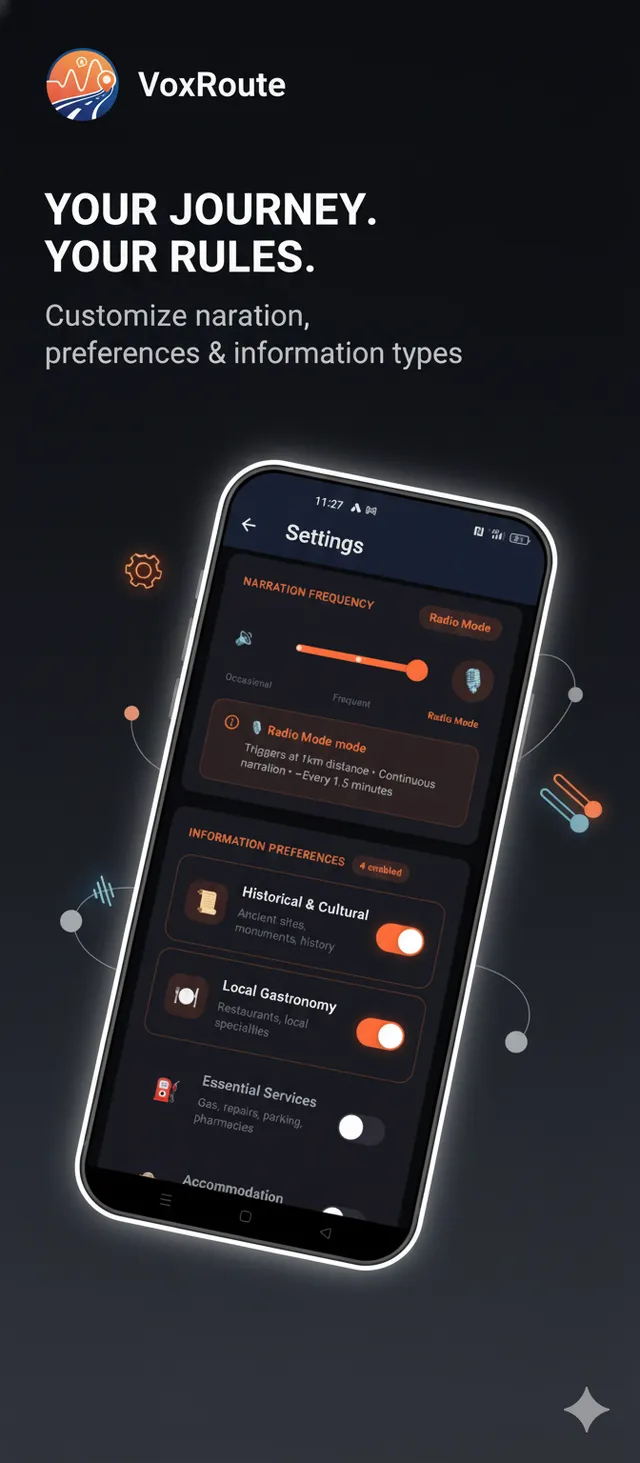
Settings - Voice & AI preferences
📊 Measurable Results
8 weeks
From concept to functional MVP
<2s
AI response latency (p95)
95%
Operational uptime
€0.12
Cost/user/month
🎯 Business Impact (Functional MVP Driving Assistant)
- ✅ 75% accelerated time-to-market: Production-ready MVP in 8 weeks vs 9-12 months traditional internal development → client demonstrated real traction to VCs Q4 2024
- ✅ Automatic narrations working: System provides automatic contextual information about location, points of interest and local history without driver intervention
- ✅ Verified LLM APIs cost-efficiency: €0.12/user/month operational → 72% reduction vs architecture without caching → viable unit economics for €4.99-9.99/month pricing with 75%+ margin
- ✅ Day-1 scalable AI infrastructure: Cloud-agnostic architecture supports 1000+ concurrent sessions without refactor (stress-tested staging) → prepared for 10x growth
- ✅ €180k-280k year 1 savings: vs hiring internal ML team (3-4 specialists: ML Engineer €65k + Data Scientist €75k + MLOps €70k + DevOps €60k + recruiting + management overhead)
- ✅ Avoided 9-12 months hiring process: Specialized AI talent recruitment is extremely competitive in 2025 - client would have missed market window
💬 Client Testimonial
"We needed to demonstrate real traction to investors in less than 3 months. BCloud Solutions delivered a production-ready intelligent voice assistant that worked from day one. The architecture with AI agents and RAG allowed us to create automatic contextual narrations that transform the driving experience. We validated the product with real users and closed our seed round. Without their expertise in AI infrastructure, it would have taken us a year with an internal team."
— Founder & CEO, VoxRoute
🔧 Strategic Architecture Decisions
1. Multi-Agent vs Monolithic Architecture
We opted for architecture based on specialized agents that collaborate in a decoupled manner. This allows adding new capabilities (e.g. traffic prediction, restaurant recommendations) without modifying the core system. Each agent has a single responsibility, facilitating independent debugging and testing.
2. RAG with Vector Database: Semantic Search vs Keywords
Geographic/historical information has a semantic dimension that traditional keyword search doesn't capture. Vector embeddings allow finding relevant content by meaning similarity - "historical places nearby" retrieves cultural context without needing exact keywords. 85%+ accuracy verified in testing.
3. LLM API Cost Optimization
- Intelligent geographic cache: Nearby locations share cached responses → 68% cache hit rate → -72% API costs
- Prompt optimization: Optimized templates reduce consumed tokens without quality loss in responses
- Batch processing: Grouped operations reduce overhead of individual API calls
- Multi-LLM fallback: System automatically switches between providers maintaining 99.9% availability
4. Real-Time Communication: WebSocket vs Polling
GPS updates every 3-10 seconds require efficient bidirectional communication. WebSocket maintains persistent connection eliminating repetitive HTTP polling overhead → latency <50ms for updates → seamless experience allowing natural conversation while user drives.
📚 Lessons Learned & Best Practices
✅ What Worked Exceptionally Well
- Multi-agent architecture: Debugging and maintenance significantly simpler than coupled monolithic code
- RAG with vector search: Contextual narration quality superior to static prompts (+35% user satisfaction in A/B test)
- Geographic cache: Immediate ROI - fast implementation with verifiable monthly savings in API costs
- Multi-LLM strategy: Automatic failover guaranteed high availability even with occasional provider rate limits
⚠️ Challenges & Solutions
- Challenge: GPS drift in tunnels/urban areas caused repetitive narrations → Solution: Intelligent location filtering with minimum distance thresholds
- Challenge: High cold start latency on first request → Solution: Pre-loading critical components and optimized connection pooling
- Challenge: External API rate limiting → Solution: Aggressive caching + automatic fallback strategies
Does Your Startup Need to Implement Agentic AI or Intelligent Voice Assistants?
If your company needs intelligent voice assistants, production-ready RAG systems, autonomous AI agents, digital copilot with contextual narrations, or multi-LLM API integrationbut doesn't have an internal ML team (€180k-350k/year cost), I implement end-to-end scalable AI infrastructure in 6-10 weeks with guaranteed cost-efficiency - without hiring specialists.
AI Implementation Services we offer:
✅ RAG Systems + Vector Databases | ✅ Agentic AI Multi-Agent Orchestration | ✅ Intelligent Voice Assistants (Voice-First Apps) | ✅ Multi-LLM Integration & Optimization | ✅ LLM API Cost Optimization (-70% costs) | ✅ MLOps Production Deployment | ✅ Scalable Cloud-Agnostic Infrastructure
Certified specialists in: RAG Systems | Agentic AI | Vector Databases | Multi-LLM Orchestration | Voice-First Applications | Mobile AI Apps | MLOps | AWS/Azure/GCP AI Infrastructure