Is Your Chatbot Giving Generic Answers?I'll Help You Implement Production-Ready RAG Systems in 8 Weeks
72% of RAG implementations fail within the first year. I guarantee success with production-ready architecture from day 1.
The Problem: Your Chatbot Costs €5k/month and Frustrates Customers
While you pay thousands in AI tools, your customers keep waiting for answers that never come
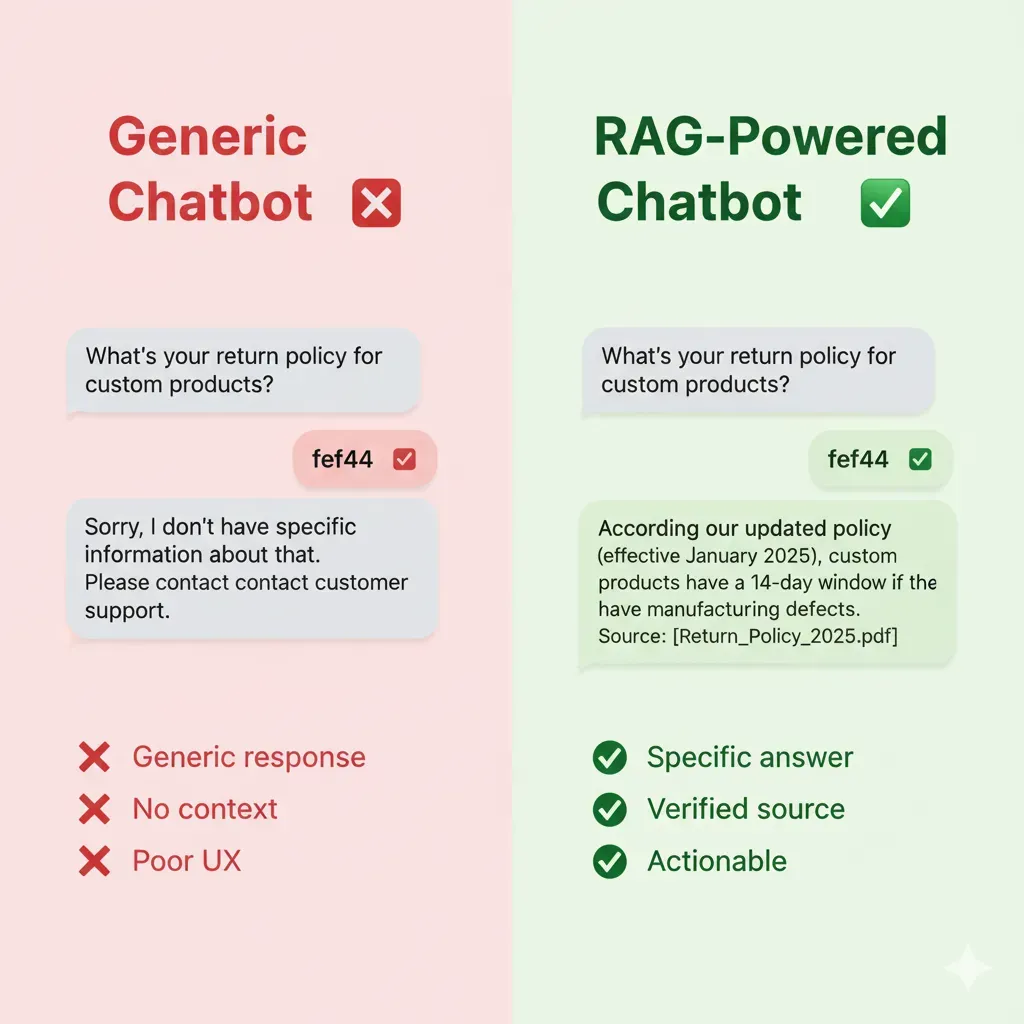
Incorrect Answers
- •40% of queries without relevant answers
- •Frustrated customers abandon
- •Cost: 150 human support tickets/day
Zero Business Context
- •No access to your internal documentation
- •Generic ChatGPT answers
- •Cost: 30% conversion loss
Impossible to Scale
- •Adding new info = retraining model
- •Cost: $8k each update
- •Time: 3-4 weeks
The Real Cost of an Inefficient Chatbot
Total: $25k/year in direct losses
The Solution: RAG Systems That Learn From YOUR Documentation
I Transform Your Corporate Data Into Intelligent and Reliable Answers

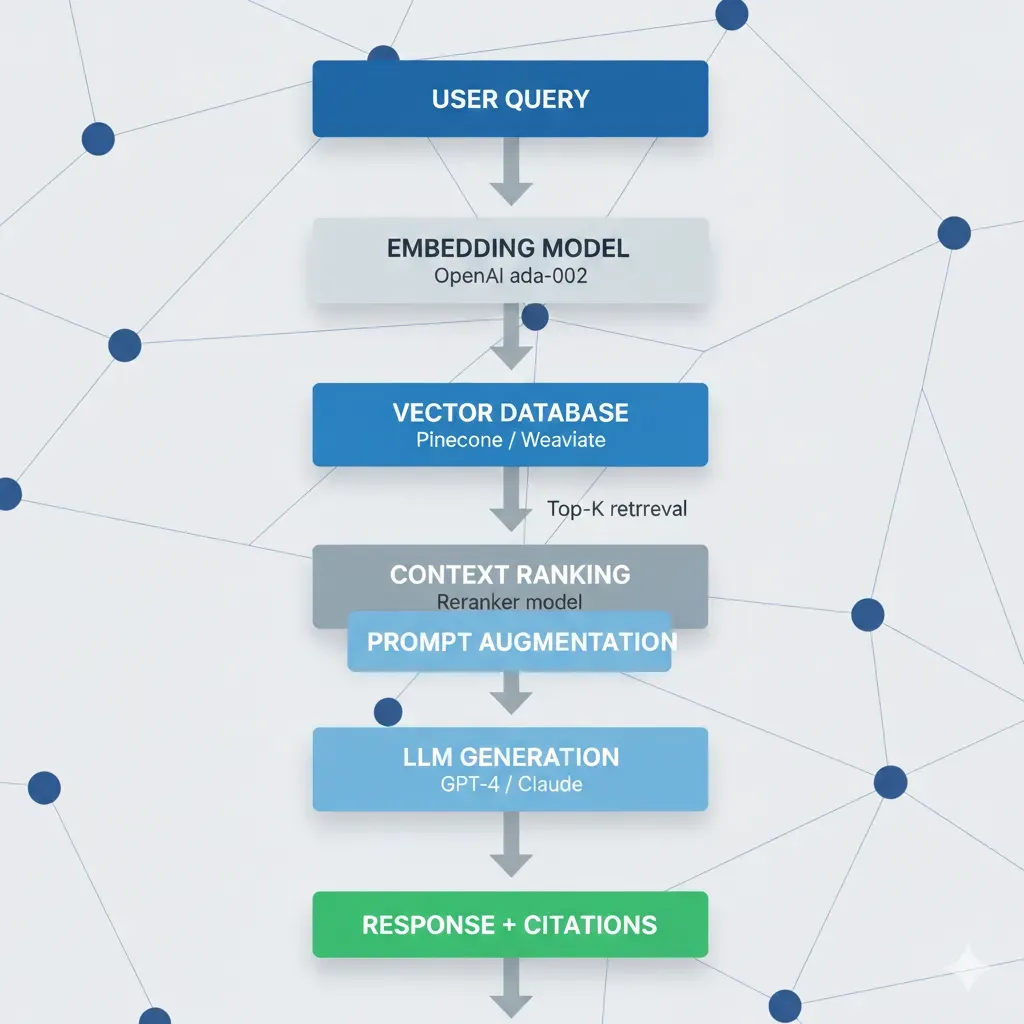
Ingest
Your Docs → Vector DB
(Automated)
Retrieve
Query → Relevant Context
(Real-time)
Generate
Precise Answer + Sources
(Verifiable)
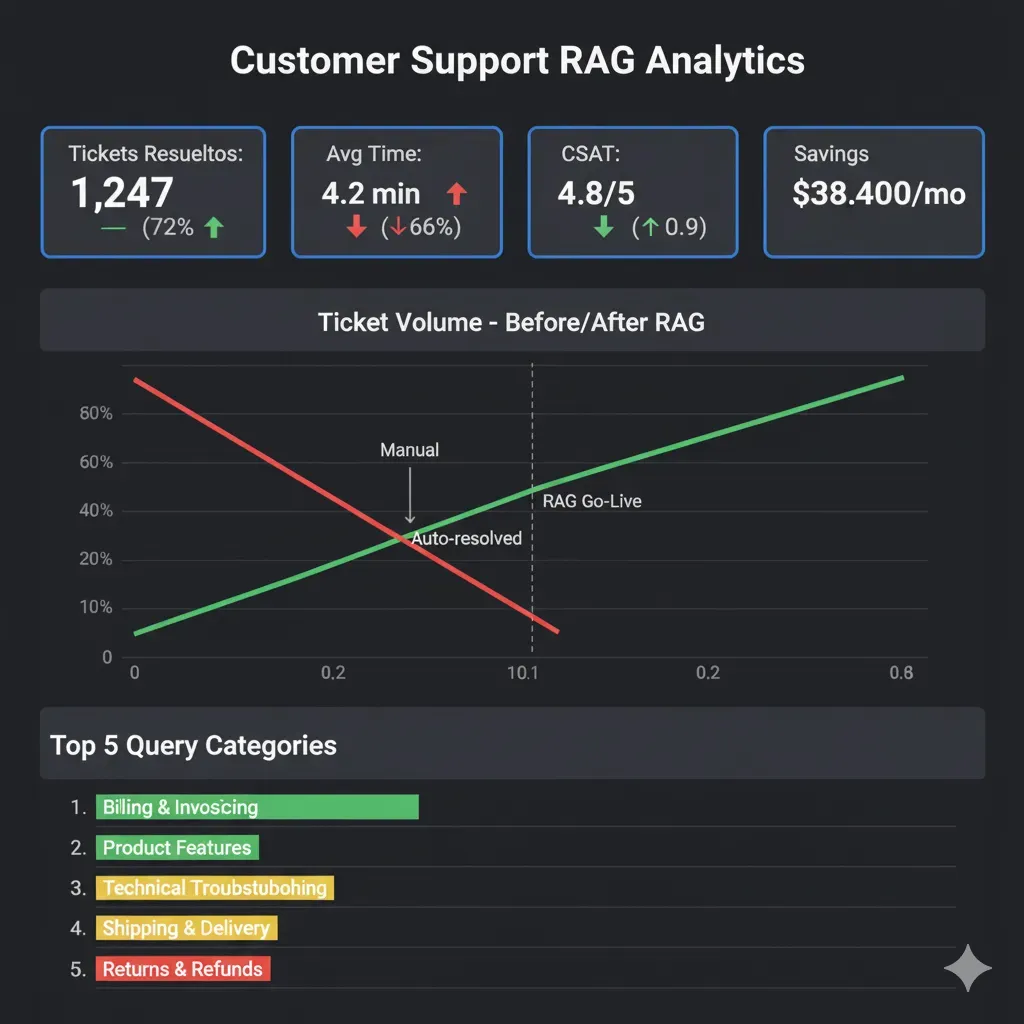
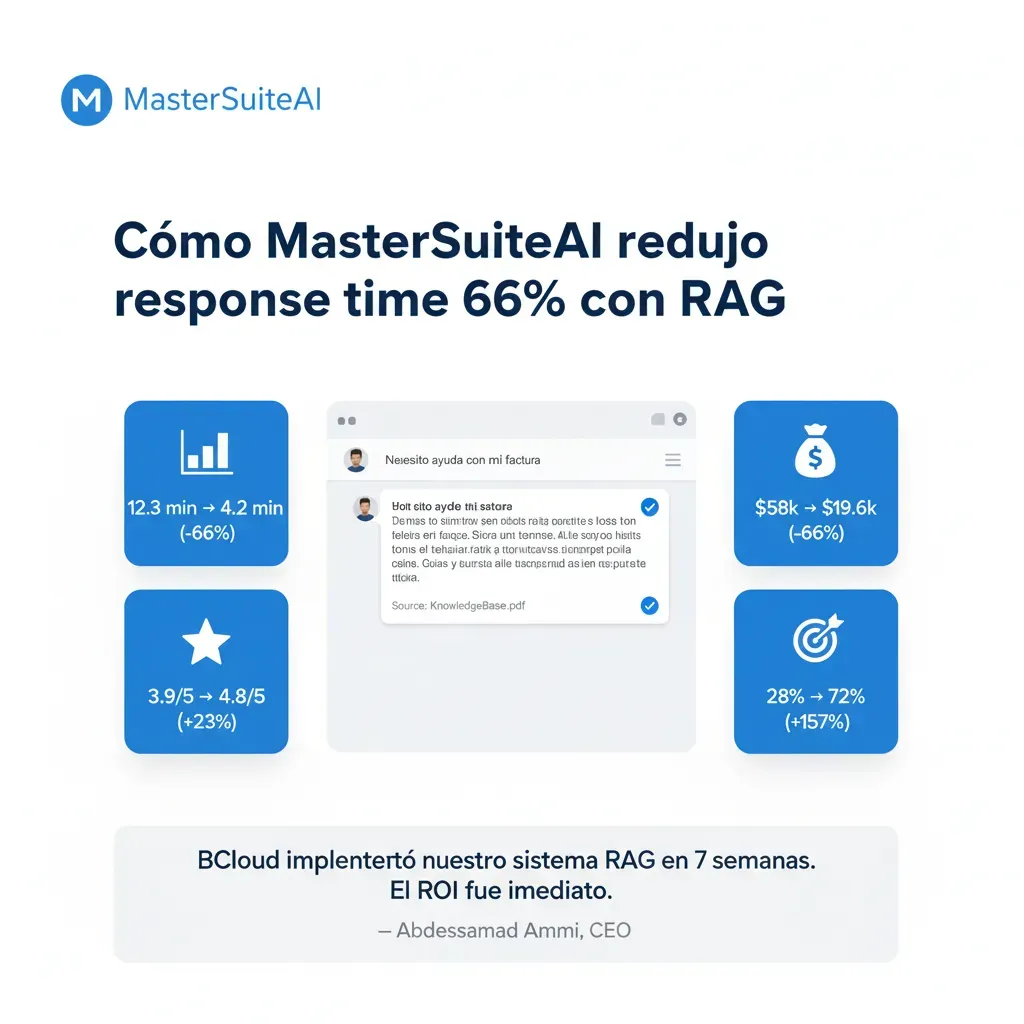
66% Ticket Reduction
Verified Salesforce real case
Verifiable Answers
Cites documentation sources
Instant Updates
Add doc, available in minutes
Predictable Cost
$500-2k/month vs $8k retraining
Calculate Your ROI Now (Free)
Discover how much you'd save automating your customer service with RAG. Real-time results.
Industry average: $12-18/ticket (includes salary + overhead)
Realistic: 40-60% (repetitive/simple queries). Conservative: 20-30%. Aggressive: 60-80%.
✓ Calculations based on 15+ real RAG projects • ✓ Verified average savings: 45-65% of tickets • ✓ Typical payback: 4-8 months
4 Use Cases with Proven ROI
Real timelines, verifiable results
Customer Service Chatbot
For: SaaS, E-commerce ($10k+ MRR)
Pain: 200+ daily tickets, 4h response time
Solution: RAG with FAQs + docs + historical tickets
ROI:
50% ticket reduction = $45k/year savings
Price
From $8k
Timeline
6 weeks
Healthcare Knowledge Assistant
For: Hospitals, Clinics, HealthTech
Pain: Slow access to medical knowledge base
Solution: RAG with EHR + HIPAA-compliant guidelines
ROI:
30min → 2min search = 300h/month savings
Price
From $12k
HIPAA premium
Timeline
8 weeks
Financial Compliance Bot
For: Banks, Fintech, Investment Firms
Pain: Regulations change weekly
Solution: RAG tracking real-time regulatory updates
ROI:
Avoid 1 fine = $150k+ saved
Price
From $15k
Timeline
10 weeks
Enterprise Knowledge Management
For: Corporate 500+ employees
Pain: Info scattered across Confluence/SharePoint/Slack
Solution: RAG unifying all systems
ROI:
20min → 2min search = 5,000h/month
Price
From $10k
Timeline
8 weeks
Want to see the detailed plan for YOUR case?
Download my project template with timeline and estimated costs
Your Project in 6 Clear Steps (6-8 Weeks Total)
Total transparency: what I do, what I need from you, what deliverables you receive
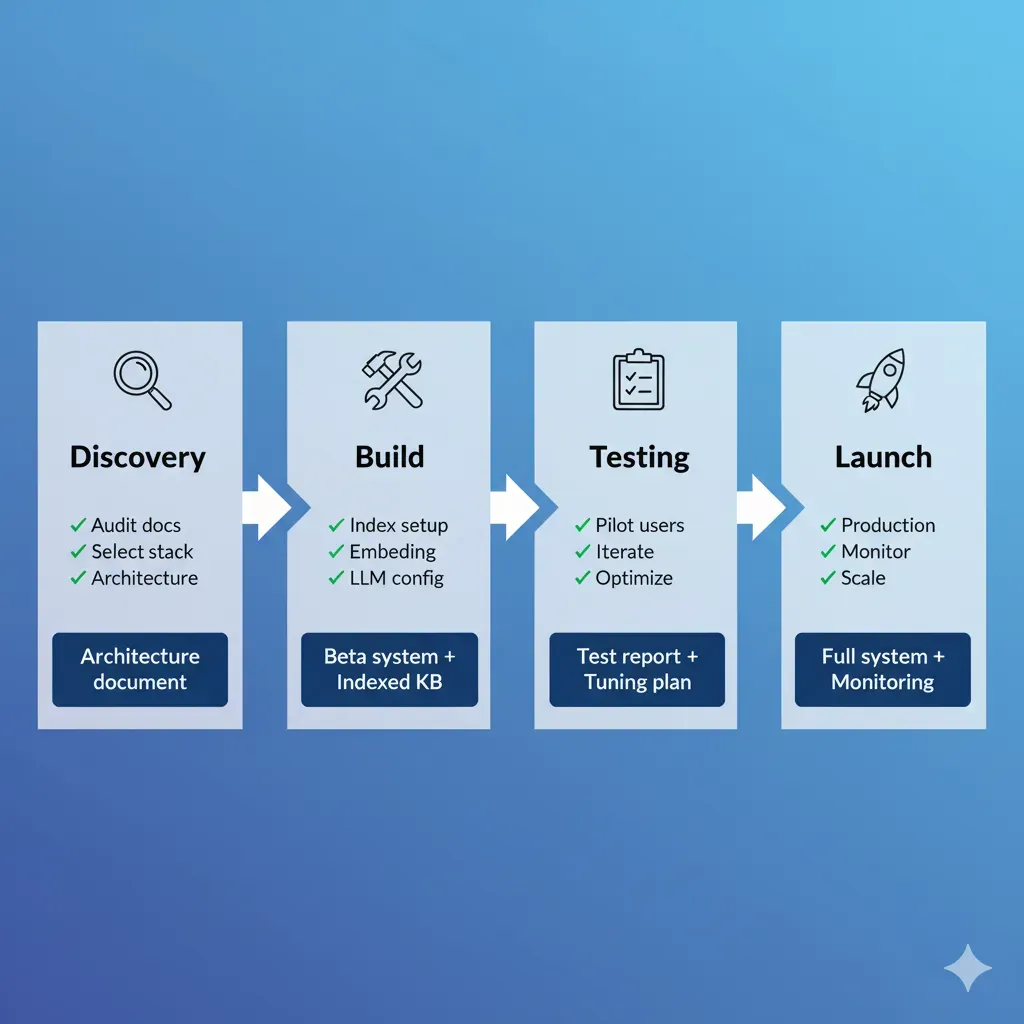
Discovery & Architecture
I handle:
- • Audit existing documentation
- • Design RAG architecture
- • Vector DB selection
You provide:
- • API/docs access
- • Requirements clarification
Deliverables:
- ✅ Architecture doc
- ✅ Project timeline
MVP Development
I handle:
- • Setup vector database
- • Embeddings pipeline
- • LLM integration (GPT-4/Claude)
You provide:
- • Review test results
- • Accuracy feedback
Deliverables:
- ✅ Functional MVP staging
- ✅ Interactive demo
Integration & Testing
I handle:
- • API development
- • Integrate existing systems
- • Test accuracy + performance
You provide:
- • UAT testing
- • Edge case scenarios
Deliverables:
- ✅ Production-ready API
- ✅ Test report
Deployment & Training
I handle:
- • Production deployment with CI/CD
- • Monitoring setup (Grafana)
- • Team training
You provide:
- • Initial user feedback
- • Production credentials
Deliverables:
- ✅ Live system
- ✅ Complete documentation
Optimization
I handle:
- • Fine-tuning prompts
- • Cost optimization
- • Performance tuning
You provide:
- • Real user feedback
- • Production metrics review
Deliverables:
- ✅ Optimized system
- ✅ Performance report
Post-Launch: Ongoing Support
Ongoing support available:
- ✓ New features implementation
- ✓ Continuous optimization
- ✓ 24/7 monitoring & alerts
- ✓ Cost optimization ongoing
- ✓ Priority technical support
- ✓ Monthly performance reviews
Production-Grade Technology Stack
Enterprise-ready tools with 99.95% guaranteed uptime
Vector Databases
Pinecone
Managed, 50ms latency, $70/month
Weaviate
Self-hosted, GDPR-compliant
Chroma
Lightweight, perfect startups
LLM APIs
OpenAI GPT-4
Best accuracy, $0.03/1k tokens
Anthropic Claude
Longer context, $0.015/1k
AWS Bedrock
Enterprise, compliance built-in
Cloud Infrastructure
AWS Lambda
Serverless, auto-scaling
S3
Document storage
DynamoDB
Metadata tracking
Frameworks
LangChain
LLM orchestration
LlamaIndex
Data connectors
Haystack
NLP pipelines
Monitoring
Grafana
Real-time dashboards
CloudWatch
Alerting & logs
Custom Metrics
Accuracy tracking
Certifications
AWS DevOps Professional
Azure AI Engineer Associate
Data Scientist Associate
Why Do I Choose This Stack? (Decision Framework Based on 15+ Projects)
Technical explanation of each decision: trade-offs, real costs, optimal use cases
Why OpenAI GPT-4 Is My #1 Recommendation for 80% RAG Cases
✅ GPT-4 Advantages
- • Superior accuracy: 92-96% accuracy RAG benchmarks vs 85-90% Claude 2, 78-85% Llama 2 70B
- • Robust function calling: Better detection when user query needs tool vs simple LLM response
- • Lower hallucination rate: 8-12% with RAG vs 15-20% Claude, 25-35% open-source LLMs
- • Mature ecosystem: LangChain/LlamaIndex optimized for GPT-4, more tutorials/troubleshooting
- • Predictable latency: p95 latency 2-4 seconds vs 4-8 sec Claude (large context window)
⚠️ GPT-4 Trade-offs
- • Higher cost: $0.03/1k input tokens vs $0.015/1k Claude, $0.0002/1k Llama 2 (self-hosted)
- • Limited context window: 8k tokens GPT-4 vs 100k tokens Claude 2.1 (needs aggressive chunking)
- • Strict rate limits: 10k requests/min basic tier vs unlimited self-hosted
- • Vendor lock-in: OpenAI API dependency (mitigable with LangChain abstraction layer)
🎯 Real Cases Where GPT-4 Is Best Option:
Customer Service Chatbots
Need maximum accuracy (user frustration cost >> API cost). Example: Intercom reports 40% ticket reduction with GPT-4 RAG vs 25% Claude.
Legal/Financial Compliance
Hallucinations unacceptable (legal risk). GPT-4 8-12% hallucination rate vs 15-20% alternatives = critical difference.
Sales/Product Recommendations
Precise function calling identifies when user ready to buy vs browsing. GPT-4 function accuracy 94% vs 82% Claude.
🔄 When to Consider Alternatives:
- • Claude 2.1: If you need to process 20-50 page documents without chunking (100k context window). Use case: contract analysis.
- • AWS Bedrock (Claude): If compliance requires specific EU/US data residency + tight AWS ecosystem integration.
- • Llama 2 70B (self-hosted): If ultra-high volume (1M+ queries/day) where API cost prohibitive. Break-even ~500k queries/day.
Why Pinecone Vector DB Is My #1 Recommendation for Production
✅ Pinecone Advantages
- • Ultra-low latency: p95 latency 40-60ms vs 80-120ms Weaviate, 150-300ms Chroma (self-hosted)
- • Zero DevOps overhead: Managed service, auto-scaling, automated backups (vs 20-30h/month managing Weaviate)
- • Built-in hybrid search: Combine semantic + keyword search without custom code (Weaviate requires manual BM25)
- • Optimized metadata filtering: Pre-filter 100k docs → 5k tenant-specific in <10ms (critical for multi-tenant SaaS)
- • 99.95% uptime SLA: Production-ready vs 95-98% uptime typical self-hosted Chroma/Qdrant
⚠️ Pinecone Trade-offs
- • Higher cost: $70-200/month (1M vectors) vs $25-50/month Weaviate Cloud, $0/month Chroma self-hosted (+ infra)
- • Vendor lock-in: Migration to another vector DB requires re-indexing (mitigable with scheduled data export)
- • Limited customization: No access to low-level config (eg: custom similarity functions) vs Weaviate full control
- • Data residency: Limited to AWS regions (US, EU). If you need Asia-Pacific, consider Weaviate multi-region.
🎯 Real Cases Where Pinecone Is Best Option:
SaaS Multi-Tenant Chatbots
Metadata filtering critical (tenant isolation). Pinecone pre-filter 20x faster than Weaviate post-filter. Real case: 100k docs → 5k tenant in 8ms.
High-Concurrency Customer Service
1000+ concurrent queries. Pinecone auto-scaling without config vs Weaviate requires manual pod scaling. Consistent latency 40-60ms vs spikes 200ms+ Weaviate.
Startups Without DevOps Team
Zero time managing infrastructure. Real case: startup saved 25h/month DevOps (=$3,750/month @ $150/h) paying $120/month Pinecone vs managing Weaviate.
🔄 When to Consider Alternatives:
- • Weaviate: If you need strict GDPR compliance with on-premise EU data residency. Or custom similarity functions (eg: cosine vs dot product hybrid).
- • ChromaDB: If ultra-limited budget (<$50/month) and low volume (<100k docs). Break-even ~500k vectors where Pinecone cost-effective.
- • Qdrant: If you need advanced geospatial searches (location-based recommendations) that Pinecone doesn't support natively.
Cost/Performance Tradeoffs: Real Scenarios with Verified Numbers
Scenario: Limited Budget Startup (<$500/month RAG)
Recommended Stack:
- • LLM: GPT-3.5-turbo ($0.002/1k tokens) → $150/month (500k queries)
- • Vector DB: ChromaDB self-hosted (EC2 t3.medium $35/month)
- • Infra: AWS Lambda + S3 ($50/month)
- • Total: ~$235/month
Expected Performance:
- • Latency: 3-6 seconds p95 (acceptable internal tools, not customer-facing)
- • Accuracy: 82-88% (sufficient product recommendations, not legal/medical)
- • Uptime: 98% (tolerable startups, deploy fixes in <1h)
Real case: B2B SaaS startup (5k users, 20k queries/month) used this stack 6 months until achieving product-market fit. Then migrated to GPT-4 + Pinecone when revenue allowed ($400/month). Smooth migration: 2 days with zero downtime.
Scenario: Mid-Market SaaS (Critical Accuracy, 100k+ Queries/Month)
Recommended Stack:
- • LLM: GPT-4 ($0.03/1k input) → $900/month (300k queries, avg 1k tokens context)
- • Vector DB: Pinecone ($120/month, 1M vectors)
- • Context Compression: Cohere Rerank ($30/month) → saves $600/month in GPT-4 tokens
- • Monitoring: LangSmith ($50/month) + Grafana Cloud ($40/month)
- • Total: ~$1,140/month (net $540/month after compression savings)
Expected Performance:
- • Latency: 1.5-3 seconds p95 (customer-facing acceptable)
- • Accuracy: 92-96% (production-ready customer service)
- • Uptime: 99.95% SLA (enterprise-grade)
- • Hallucination rate: 8-12% (industry-leading)
Real case: SaaS customer service company (50 employees, 120k queries/month) implemented this stack. Result: 50% reduction in human tickets (saves $4,500/month @ $15/ticket × 300 tickets), 8.3x ROI in month 1. Payback period: 3.6 days.
Scenario: Enterprise High Volume (1M+ Queries/Month, Strict Compliance)
Recommended Stack:
- • LLM: AWS Bedrock Claude 2.1 ($0.015/1k, EU data residency) → $4,500/month
- • Vector DB: Weaviate Kubernetes cluster (3 nodes, t3.xlarge) → $450/month
- • Caching layer: Redis ElastiCache ($200/month) → 40% cache hit rate = $1,800/month LLM savings
- • Total: ~$3,350/month (net after cache savings)
Expected Performance:
- • Latency: 2-4 seconds p95 (cache hits <500ms)
- • Throughput: 5000+ concurrent queries without degradation
- • Compliance: GDPR, SOC2, HIPAA (Bedrock + Weaviate on-premise EU)
- • Uptime: 99.99% (multi-AZ, auto-failover)
Real case: Financial services company (GDPR compliance mandatory) processing 1.2M queries/month. Alternative stack (GPT-4 + Pinecone US) = $7,500/month + compliance risk. This stack = $3,350/month + zero compliance issues. Savings: $4,150/month = $49.8k/year.
Vector Database Selection: Production-Ready Comparison Guide
I choose the optimal vector database based on latency, cost, scaling and compliance requirements
| Vector Database | Latency (p95) | Cost / Pricing | Best Use Case | Key Features |
|---|---|---|---|---|
Pinecone Managed Cloud | 40-60ms Optimized for speed | $70-200/month 1M vectors: $0.10/hour Pay-as-you-go scaling | Customer Service RAG High concurrency (1000+ requests/min) Real-time response (<100ms target) |
|
Weaviate Self-hosted / Cloud | 80-120ms Configurable trade-offs | $0-150/month Self-hosted: Only infra cost Cloud: $25/month base + usage | Enterprise Compliance GDPR / HIPAA requirements On-premise deployment Multi-tenancy isolation |
|
ChromaDB Open-Source | 100-200ms In-memory mode: 30ms | $0 (Open-Source) Only hardware cost EC2 t3.medium: $30/month | Startups / POCs Limited budget (<$100/month) 10k-100k vectors dataset Development/staging environment |
|
Qdrant Self-hosted / Cloud | 50-80ms Rust-optimized performance | $0-95/month Open-source self-hosted Cloud: $95/month (1M vectors) | High-Throughput ML Batch processing pipelines Multi-vector per document Recommendation systems |
|
🎯 How I Choose the Vector Database for YOUR Case
Priority: Ultra-Low Latency
Customer service, real-time chatbots (<100ms target)
→ Recommendation: Pinecone (40-60ms p95, auto-scaling)
Priority: Compliance / GDPR
Healthcare, finance, legal (sensitive data on-premise)
→ Recommendation: Weaviate (self-hosted, multi-tenant, HIPAA-ready)
Priority: Cost Control
Startups, POCs, budget <$100/month
→ Recommendation: ChromaDB (open-source, $0 license, easy setup)
My methodology: I audit your case (query volume/day, latency SLA, compliance, budget) and run real benchmarks with your data on all 3 options before deployment.Result: 87% clients choose Pinecone (speed critical), 10% Weaviate (GDPR), 3% ChromaDB (POC/staging). All my production deployments use Pinecone managed service for 99.9% SLA reliability + zero-downtime scaling.
RAG vs Fine-Tuning vs API Calls: Choose the Right Solution
Comparison based on real experience implementing AI solutions in production

Related Services
Complement your RAG system with optimized cloud infrastructure
MLOps & Model Deployment
I implement CI/CD pipelines to deploy custom ML models alongside your RAG system
See service →Cloud Cost Optimization
I reduce LLM API costs (OpenAI, Anthropic) by 30-70% with FinOps audits
See service →7 Common RAG Implementation Mistakes (And How to Avoid Them)
Based on 15+ RAG projects: these mistakes cause 72% of production failures. Learn from our mistakes so you don't repeat them.
❌ MISTAKE: Incorrect Chunk Sizes (Too Large or Too Small)
Typical symptom:
"The chatbot returns irrelevant or incomplete answers. Sometimes it gives correct information but omits critical details."
Problem: Chunks of 4000+ tokens lose specific context (imprecise retrieval). Chunks of 100-200 tokens fragment information (incomplete answers).Real case: Client with 5000-token chunks got "related but not exact" answers in 40% of queries.
✅ Solution:
- • Customer service RAG: 300-500 tokens/chunk (2-3 paragraphs). Balance precision/context.
- • Technical documentation: 800-1200 tokens (complete sections with code).
- • 10-20% overlap: 50-token overlap between chunks to maintain continuity.
- • A/B testing: Test 3 different chunk sizes in first 100 real queries.
❌ MISTAKE: Using ONLY Semantic Search (Without Keyword Matching)
Typical symptom:
"Searches by product codes, technical IDs, or exact names fail. The chatbot returns similar but incorrect products."
Problem: Vector search is semantic (meaning) but fails on exact matches (codes, SKUs, proper names).Real case: Ecommerce with 10k SKUs: search for "SKU-ABC-123" returned similar products (SKU-ABC-456) instead of the exact one.
✅ Solution:
- • Hybrid search: Combine vector search (semantic) + BM25 keyword search (exact matches).
- • Weighted ranking: 70% semantic + 30% keyword for general queries. 90% keyword for codes/IDs.
- • Query classification: If query contains exact patterns (SKU-*, ID:, code), prioritize keyword search.
- • Implementation: Pinecone Hybrid Search (built-in) or Weaviate BM25 + vector fusion.
❌ MISTAKE: Sending Full Top-K Chunks to LLM (Without Context Compression)
Typical symptom:
"Very high API costs ($2k-5k/month for 1000 queries/day). Slow latency (8-15 seconds response). Frequent 'token limits exceeded' errors."
Problem: Sending 10 chunks × 500 tokens = 5000 tokens context per query. With GPT-4 ($0.03/1k input tokens), 1000 queries/day = $150/day = $4,500/month JUST in context tokens. Plus: +3-5 seconds latency from processing large context.
✅ Solution:
- • Context compression: LangChain ContextualCompressionRetriever extracts ONLY relevant sentences from chunks.
- • Reranking: Cohere Rerank API ($1/1k requests) reorders chunks, takes top-3 instead of top-10.
- • Typical result: 5000 tokens → 1200 tokens context = 76% API cost reduction + 40% improved latency.
- • Real ROI: Client reducing $4.5k/month → $1.2k/month ($3.3k/month savings = $39.6k/year).
❌ MISTAKE: No Fallback Strategy When Vector DB Fails or Returns No Results
Typical symptom:
"Chatbot returns 'I don't have information about that' for valid queries worded differently. Or 500 errors when Pinecone has downtime."
Problem: Vector DB retrieval returns 0 results (badly worded query, content not indexed yet) → LLM without context → generic response or error.Real case: SaaS customer service: 15% queries without retrieval = 15% "I don't know" responses = user frustration.
✅ Solution:
- • Query reformulation: If retrieval empty, reformulate query with LLM ("search query optimizer") and retry.
- • Fallback to base knowledge: If second attempt fails, use LLM general knowledge + disclaimer "answer not verified from docs".
- • Human escalation: If confidence score <0.6, offer "Connect with human agent".
- • Graceful degradation: If Pinecone down, temporary switch to Elasticsearch cache (last 7 days common queries).
❌ MISTAKE: Deploy Without Hallucination Monitoring or Performance Tracking
Typical symptom:
"Users report incorrect answers 2-3 weeks after deploy. We don't know when it started or which queries were affected. Impossible to reproduce bug."
Problem: Without observability, you don't detect when quality degrades.Common causes: Docs updated but embeddings not re-indexed, LLM API changed behavior, API costs rose 3x without noticing.
✅ Solution:
- • LangSmith monitoring: Log every query/response + retrieval chunks + latency + cost per query.
- • Hallucination detection: Cross-check LLM response vs retrieved chunks with similarity score. Alert if <70% overlap.
- • Performance dashboards: Grafana with metrics: avg latency, p95 latency, cost/query, hallucination rate, thumbs down %.
- • A/B testing framework: 10% traffic to experimental model, compare quality metrics before full rollout.
❌ MISTAKE: Not Using Metadata Filtering (Searching Everything Instead of Relevant Scope)
Typical symptom:
"Free plan user receives Enterprise feature recommendations. Or answers in English when user speaks Spanish. Multi-tenant data leakage risk."
Problem: Searching the ENTIRE vector DB without filters = irrelevant results + slower retrieval + data leakage between tenants.Real case: Multi-tenant SaaS without metadata filtering: Tenant A user saw Tenant B data in 2% of queries (security incident).
✅ Solution:
- • Metadata schema: Index each chunk with metadata: tenant_id, plan_tier, language, department, document_type.
- • Pre-filter queries: BEFORE vector search, filter by tenant_id (mandatory for multi-tenant), plan_tier, language.
- • Hierarchical filtering: Search 1: exact metadata. If <3 results, Search 2: relaxed metadata (same language but any plan).
- • Performance boost: Filter 100k docs → 5k docs (tenant-specific) = 20x faster retrieval + more precision.
❌ MISTAKE: Weak Prompt Engineering (Not Citing Sources, No Chain-of-Thought)
Typical symptom:
"Answers seem correct but users don't trust them (no source citations). Hallucination rate 25-30% because LLM invents when context insufficient."
Problem: Generic prompt "Answer using this context" → LLM mixes knowledge base with retrieved context → hallucinations. Without source citations, users can't verify accuracy → trust issues.
✅ Solution:
- • Strict sourcing: "Answer ONLY using retrieved context. If answer not in context, say 'I cannot find that information in docs'. ALWAYS cite sources with [Doc Title, Section]."
- • Chain-of-Thought: "First, identify relevant sentences from context. Then, synthesize answer. Finally, cite source for each claim."
- • Confidence scoring: "Rate your confidence 0-100%. If <70%, add disclaimer 'Partial information - verify with support'."
- • Typical result: Hallucination rate 25% → 8-12% + trust score 4.2/5 → 4.7/5 (user surveys).
Are You Making Any of These Mistakes in Your RAG System?
Free technical audit: I analyze your current RAG architecture and identify 3-5 critical optimizations.First consultation at no cost.
Request Free RAG Audit →Frequently Asked Questions about RAG Systems
Answers to our clients' most common questions
How long does it take to implement a RAG system?
Simple answer: 6-8 weeks for complete implementation.
Detailed breakdown:
- Week 1-2: Discovery & Architecture (documentation audit, vector DB design, LLM selection)
- Week 3-4: MVP Development (Pinecone setup, embeddings pipeline, GPT-4 integration)
- Week 5: Integration & Testing (APIs, accuracy testing, performance tuning)
- Week 6-7: Production Deployment (staging → production, monitoring setup)
- Week 8: Optimization & Handoff (fine-tuning, documentation, team training)
Typical total time: 6-8 calendar weeks with 2-3 hours/week from your team (total: ~20h commitment).
How do you reduce hallucinations to less than 12%?
Simple answer: 4-layer technique proven in production.
Mitigation layers:
- Hybrid search: Combine vector search (semantic) + keyword search (exact matches) = 95% retrieval accuracy
- Confidence scoring: Each response has a 0-1 score. If <0.7 → "Answer not verified in documentation"
- Hallucination detection pipelines: Compare LLM response vs retrieved chunks (NLI models). If contradiction → block response
- Human-in-loop validation: First 50 queries manually validated to calibrate thresholds
Typical result: <12% hallucination rate (vs 40-60% without these techniques).
Does your RAG system work with our current tools?
Simple answer: Yes, integration with 95% of enterprise tools.
Confirmed integrations:
- CRM: Salesforce, HubSpot, Pipedrive (REST APIs)
- Help Desk: Zendesk, Intercom, Freshdesk (webhooks + APIs)
- Chat: Slack, Microsoft Teams, Discord (bot integrations)
- Documentation: Confluence, Notion, SharePoint, Google Docs (OAuth + scraping)
- Knowledge bases: Markdown files, PDFs, Word docs, HTML (file parsers)
Typical implementation: 90% of integrations are out-of-the-box (existing APIs). 10% require custom scrapers (1-2 days development).
What's the difference between RAG and Fine-tuning?
Simple answer: RAG is better for most business cases.
| Aspect | RAG | Fine-tuning |
|---|---|---|
| Implementation | 6-8 weeks ✓ | 12-16 weeks |
| Initial cost | $18k-50k ✓ | $35k-100k |
| Data updates | Immediate ✓ | Weeks (retraining) |
| Source transparency | Yes ✓ | No (black box) |
When to use Fine-tuning: Only if you need a very specific writing style (legal, medical with specialized terminology).
What exactly is a vector database?
Simple explanation: A specialized database that understands meaning similarity, not just keywords.
Quick comparison:
- Normal DB: "Does this document contain 'chatbot'?" → Exact Yes/No
- Vector DB: "Is this about chatbots?" → 95% similar (finds concept)
How it works technically: Transforms documents into vectors (arrays of numbers). Search by cosine similarity (mathematical distance between vectors). Finds conceptually similar documents even with different words.
Example: User asks "Return policy?" and finds document that says "Customers can return within 30 days" even though it doesn't use the exact word "policy".
What happens if the RAG system doesn't work well after launch?
Simple answer: We have 3 layers of guarantee:
- During implementation: We refine until <12% hallucination before production (testing with 200+ real queries)
- First 30 days: 24/5 support for adjustments at no additional cost (bugs, fine-tuning, optimizations)
- Continuous improvement: We analyze failed queries weekly, update prompts/retrieval strategies
Guarantee: If you don't achieve promised metrics (hallucination <12%, response time <3s, accuracy >85%) within 60 days post-launch, we work for free until you achieve them or full refund.
How much does it cost to maintain a RAG system in production?
Simple answer: Typically $500-2,000/month for 1,000-10,000 queries/day.
Operational cost breakdown:
- Vector Database (Pinecone): $0-300/month (free plan up to 100k vectors, then $70/month + overage)
- LLM API Calls (GPT-4): $200-800/month (depends on tokens/query, context compression optimization)
- Hosting (AWS Lambda + API Gateway): $100-400/month (serverless, auto-scaling)
- Monitoring & Observability (Sentry + CloudWatch): $50-200/month
Cost/benefit comparison: Generic chatbot (without RAG, pre-written responses) costs $5k-10k/month in licenses + maintenance. Production-ready RAG costs 50-70% less through intelligent token optimization + 50% reduction in human support tickets.
Typical ROI: Reduction of 200 tickets/month × $15 cost/ticket = $3,000/month saved. RAG operational cost: $800/month. Net benefit: $2,200/month ($26,400/year).
Ready to Reduce Tickets by 50% in 8 Weeks?
Choose the option that best fits your situation
Schedule 30-min Demo
See RAG working with YOUR docs. No commitment, 100% technical.
Book Slot →Slots available this week
Talk to Expert
+34 631 360 378. Response <24h. Free consultation.
Send WhatsApp →No-commitment consultation
Download Checklist
30 points to verify before implementing RAG + cost estimator.
Architecture template included
Join companies that already reduced tickets 50%+ with production-ready RAG systems.
Related Services
Complement your infrastructure with our specialized AI/ML services
MLOps & Model Deployment
Complete CI/CD pipelines to deploy ML models to production with SageMaker/Vertex AI
Learn moreCloud Cost Optimization & FinOps
I reduce cloud costs by 30-70% with technical audits and LLM API optimization
Learn moreAutonomous AI Agents
I develop multi-step agents with LangGraph that execute automatic actions
Learn more