MLOps & Model Deployment: ¿Inviertes en Entrenar Modelos MLque Nunca Llegan a Producción? - CI/CD Pipelines Automatizados
MLOps Production-Ready: 87% de modelos ML NUNCA se deployean (Forbes 2025). Implemento MLOps pipelines CI/CD para ML que escalan automáticamente. De Jupyter Notebook a production deployment en 4-6 semanas.
Revisamos tu stack actual • Roadmap despliegue • Sin compromiso
5 Señales de que tu Equipo ML Está Atascado
¿Te Suena Familiar? (Reconoces al Menos 3)

Modelos en Notebooks Hace 6+ Meses
Data Scientists entrenan modelos excelentes. Accuracy 95%+
Pero... todo está en .ipynb notebooks en sus laptops
Coste: Equipo DS completo sin output real en producción
Frustración + Vergüenza: "¿Por qué no deployamos?"
DevOps No Sabe Deployar ML
Dominan Docker, Kubernetes, CI/CD tradicional
Pero modelos ML: GPU, versioning, A/B testing = diferente
Coste: 9 meses intentos fallidos
Conflicto teams + Impotencia
Zero Visibilidad Performance
Deployaste 1 modelo hace 3 meses. ¿Accuracy ahora?
Sin monitoring drift, sin alertas cuando baja
Coste: Modelo degrada silenciosamente
Miedo: "¿Está roto y no lo sabemos?"
Re-training Manual
Nuevos datos → Re-train manual → Re-deploy manual
2 semanas proceso. Sin pipeline automático
Coste: 40 horas/mes DS perdidas
Tedio: "Debería haber forma mejor"
Impossible A/B Test
Quieres probar nuevo modelo vs actual
No hay infraestructura. Miedo a reemplazar viejo
Coste: Innovación paralizada
Stuck con modelo subóptimo
📊 El Coste Real de NO tener MLOps:
✗ Salarios team DS produciendo solo demos
✗ Infrastructure idle (GPUs sin usar producción)
✗ Oportunidades perdidas (features ML no deployed)
✗ Re-trabajo intentos despliegue manual
¿Cuánto llevas tú atascado?
Agenda Auditoría Gratuita →Implementación Pipelines MLOps: 4-6 Semanas de Notebooks a Producción
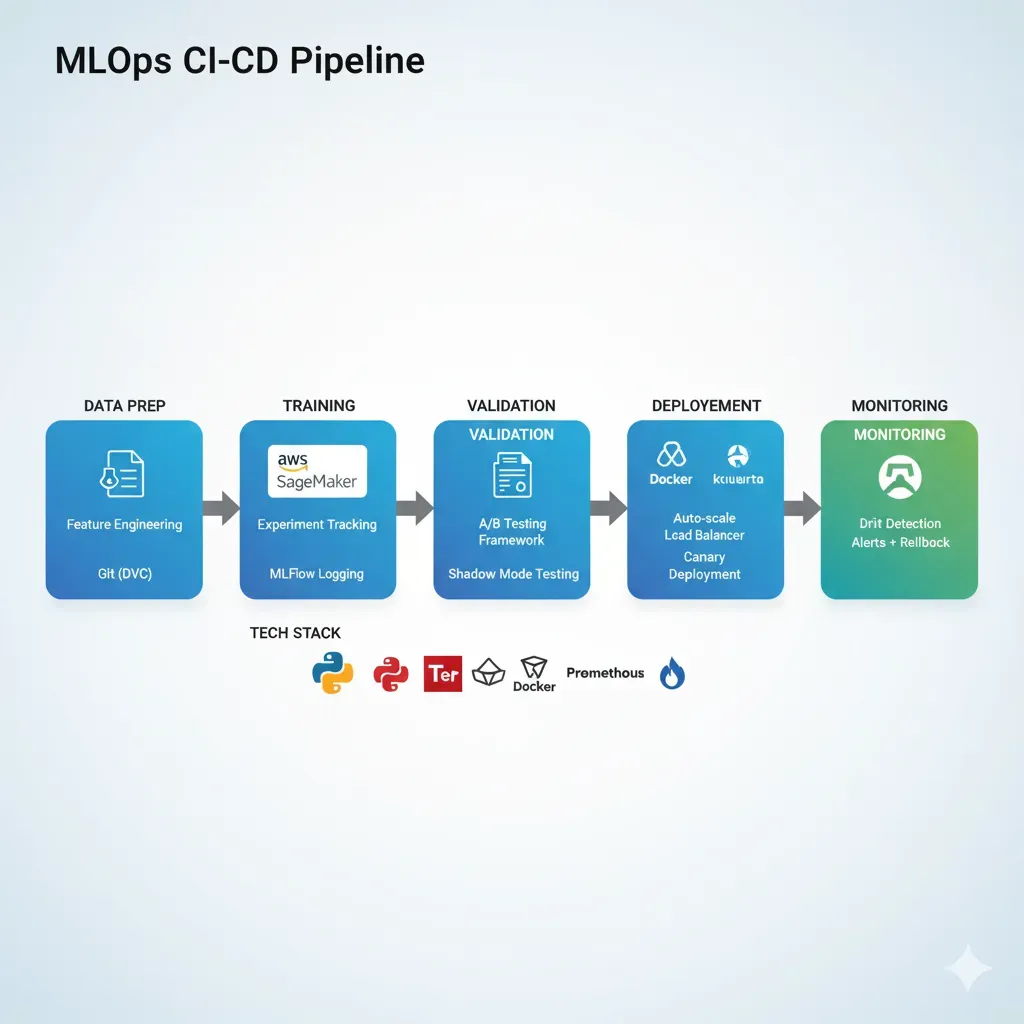
De Notebooks a Producción Sistemáticamente
Training Pipeline
MLflow tracking
Testing Automated
Validation gates
Deployment CI/CD
Canary/Blue-Green
Monitoring 24/7
Drift detection
9 meses → 4 semanas
Startup Fintech deployó 3 modelos en 6 semanas
ROI: €80k saved vs 9 meses idle
Monitoring Automático
Dashboard en tiempo real: precisión, latencia, detección de deriva
CTO duerme tranquilo, DS saben estado
A/B Testing Built-In
Deploy nuevo modelo 10% traffic, comparar, rollback auto
Innovación sin miedo, mejora continua
Multi-Platform Support
SageMaker, Azure ML, Vertex AI, Databricks, híbrido local
Tu stack actual, no vendor lock-in
¿Quieres ver el pipeline específico para TU stack?
Demo Técnica 30 min →MLOps Quickstart: 5 Pasos para Deployar tu Primer Modelo
Guía práctica para equipos que quieren pasar de notebooks a producción sistemáticamente
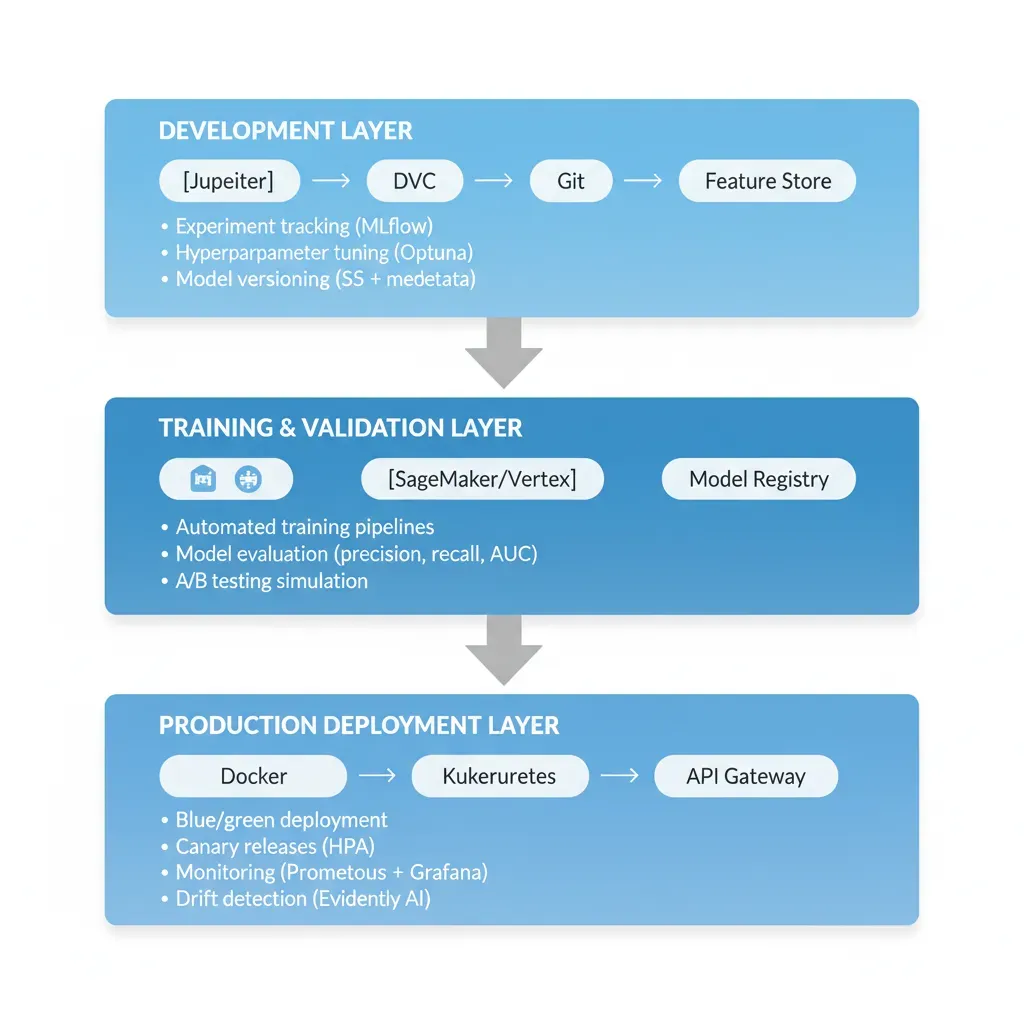
Auditoría Stack Actual (Día 1-2)
Acción: Inventariar modelos existentes (notebooks, scripts, accuracy metrics) y stack técnico actual (AWS/Azure/GCP, frameworks ML usados). Identificar el modelo con mayor impact business como candidato piloto. Verificar requisitos deployment: latencia target (<100ms real-time vs batch overnight OK), volumen predictions/día, compliance (HIPAA/SOC2).
Herramientas: Spreadsheet tracking (modelo, accuracy, última actualización, owner).Outcome: Top 3 modelos priorizados por ROI.
Seleccionar Plataforma MLOps (Semana 1)
Decisión crítica: Elegir entre AWS SageMaker (mejor para startups AWS-native, spot instances -70% cost), Google Vertex AI (óptimo para BigQuery workflows + TensorFlow), Azure ML (empresas Microsoft-heavy + compliance HIPAA). Si necesitas cloud-agnostic: stack portable con MLflow + Docker + Kubernetes funciona anywhere (85% código reutilizable entre clouds). Para ayudarte a decidir, lee nuestro análisis comparativo detallado de costes SageMaker vs Vertex AI vs Azure ML.
Criterios decisión: Stack actual (¿ya usas AWS?), presupuesto GPU training, compliance requirements.Tip: 80% startups empiezan SageMaker pay-per-use, optimizan Reserved Instances mes 3-4.
Setup Pipeline Training Automático (Semana 2-3)
Implementar: (a) Tracking experimentos con MLflow (métricas, hyperparameters, model artifacts versioned), (b) Containerización con Docker (requirements.txt → imagen reproducible), (c) CI trigger: git push → training automático con validation gates (si accuracy < threshold → block deployment). Data Scientists solo añaden 3-5 líneas logging MLflow a código existente. NO rewrite modelo completo.
Stack típico: GitHub Actions/GitLab CI + SageMaker Training Job + MLflow Tracking Server.Tiempo DS: 4-6 horas adaptación código (minimal).
Deploy Modelo Producción con Canary (Semana 4)
Estrategia segura: Deploy nuevo modelo routing solo 10% tráfico real, comparar métricas (accuracy, latency) vs modelo actual 90% durante 48-72h. Si performance OK → gradualy increase 10%→25%→50%→100%. Si degrada → rollback automático en 30 segundos. Implementar health checks: endpoint /predict debe responder <200ms con dummy input.
Infraestructura: SageMaker Endpoint (auto-scaling 1-10 instances) o Kubernetes deployment (HPA based CPU/requests).Garantía: Zero-downtime deployment.
Monitoring & Drift Detection 24/7 (Semana 5-6)
Dashboard crítico: Grafana/CloudWatch mostrando (1) Model accuracy tiempo real, (2) Prediction latency P95/P99, (3) Input feature distribution (detectar data drift cuando features nuevas divergen >15% vs training data), (4) Error rate & anomaly alerts. Setup alertas: si accuracy baja <threshold o latency spike >500ms → Slack/PagerDuty automático. Re-training trigger: si drift detectado consistente 7+ días → re-train automático con nuevos datos.
Herramientas: Prometheus + Grafana (open-source) o SageMaker Model Monitor (managed).Benefit: CTO duerme tranquilo, equipo DS notificado proactivamente antes de que clientes reporten issues.
✅ Resultado Final: Pipeline MLOps Completo en 4-6 Semanas
Git push → Training → Tests → Production
Semanal/mensual automático con nuevos datos
Drift detection + performance monitoring 24/7
¿Necesitas ayuda implementando estos 5 pasos? Hago el trabajo pesado por ti.
📅 Agendar Auditoría Gratuita →3 Casos Reales: De Notebooks a Producción
4-6 Semanas Verificadas
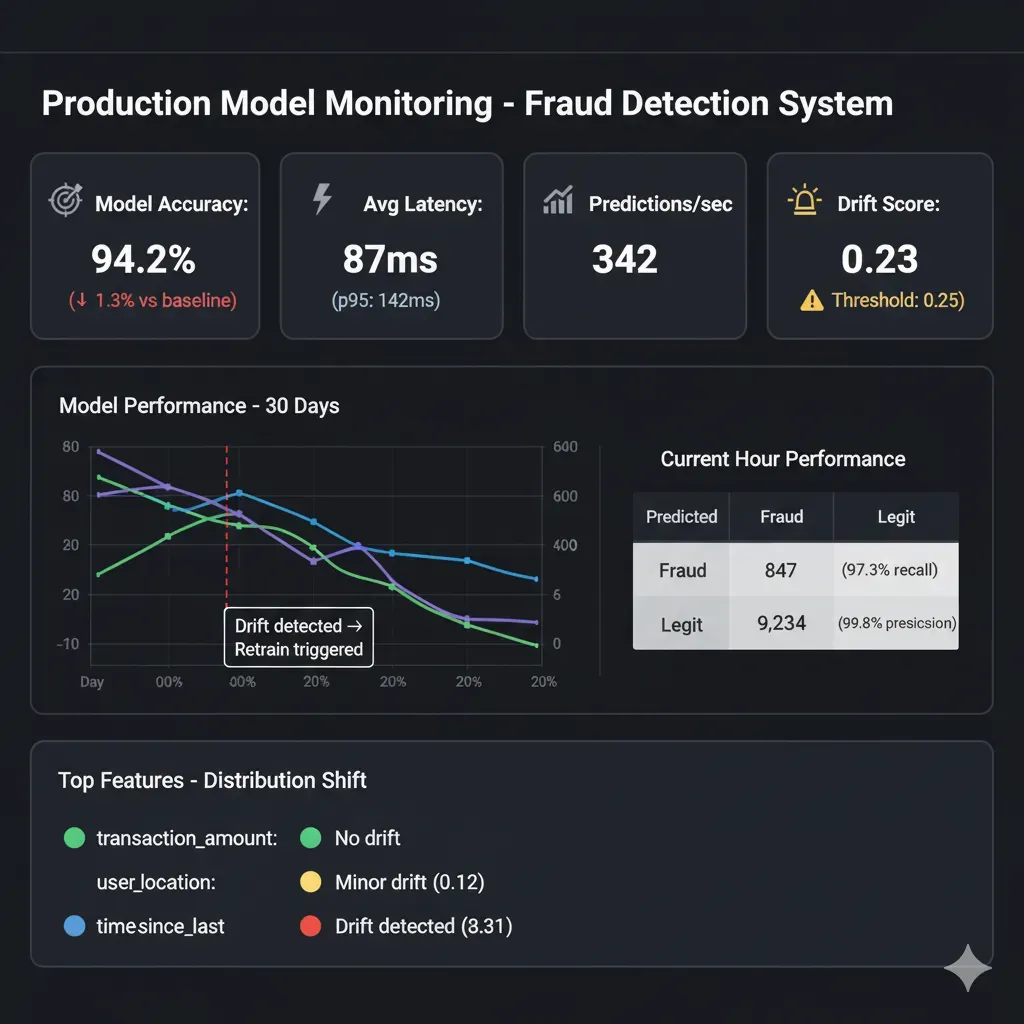

FinTech Startup
Fraud Detection (Series A)
Model 95% accuracy, 6 meses stuck staging. DevOps no sabe deployar
Results:
- • Latencia: 24h batch → <50ms tiempo real
- • False positives: -40%
- • €450k fraud prevented año 1
"Modelos en notebooks a API producción en 5 semanas. Ahora iteramos semanalmente."
— CTO FinTech
Stack: AWS SageMaker, MLflow, TensorFlow
Pricing: Desde €12k
ROI: €430k neto año 1
E-commerce
Product Recommendations
Re-training manual mensual, 2 semanas proceso, sin A/B testing
Results:
- • Re-training: Monthly → Weekly auto
- • CTR recommendations: Mejora significativa
- • Revenue: Incremento sustancial verificado
"Deployar nuevo modelo era nightmare. Ahora commit code y en 2h está live con canary."
— VP Engineering
Stack: Vertex AI, Kubeflow, PyTorch
Pricing: Desde €10k
ROI: €310k neto año 1
HealthTech
Predictive Diagnostics (HIPAA)
Modelo on-prem, cumplimiento HIPAA bloqueando despliegue cloud
Results:
- • Latency: Reducción drástica con cloud auto-scaling
- • Availability: 98.5% → 99.95%
- • Revenue: Crecimiento sustancial verificado
"Miedo cloud por HIPAA. BCloud implementó Azure ML compliant. Game changer."
— CTO HealthTech
Stack: Azure ML, MLflow, HIPAA
Pricing: Desde €18k
ROI: €362k neto año 1
Comparación Plataformas MLOps: SageMaker vs Vertex AI vs Azure ML
Seleccionamos la plataforma óptima según tu stack actual, presupuesto y requisitos de escalado. 40% de nuestros proyectos usan AWS SageMaker, 25% Google Vertex AI, 20% Azure ML.
| Característica | AWS SageMaker | Google Vertex AI | Azure ML |
|---|---|---|---|
| 🎯 Mejor Para | Startups AWS-native, alta escalabilidad, integración Lambda/ECS | Empresas GCP, BigQuery workflows, modelos TensorFlow/JAX | Empresas Microsoft, integración .NET/Office365, compliance |
| 💰 Pricing Model | Pay-per-use, spot instances (-70% cost), reserved capacity | Pay-per-use, committed use discounts (-55%), preemptible GPUs | Pay-as-you-go, reserved instances (-72%), low-priority compute |
| 🔧 Training Automation | SageMaker Pipelines, hyperparameter tuning automático, spot training | Vertex AI Pipelines (Kubeflow), AutoML integration, distributed training | Azure ML Pipelines, automated ML, parallel hyperparameter optimization |
| 📊 Model Monitoring | SageMaker Model Monitor, drift detection, CloudWatch integration | Vertex AI Model Monitoring, feature skew detection, Cloud Monitoring | Azure ML monitoring, data drift alerts, Application Insights integration |
| 🚀 Deployment Options | Real-time endpoints, batch transform, multi-model endpoints, edge (IoT) | Online prediction, batch prediction, private endpoints, edge TPU | Real-time inference, batch endpoints, managed online endpoints, IoT Edge |
| 🔗 MLOps Integrations | MLflow, Kubeflow, DVC, CodePipeline, Lambda triggers | MLflow, TFX, DVC, Cloud Build, Cloud Functions, Dataflow | MLflow, Kubeflow, DVC, Azure DevOps, Logic Apps, Data Factory |
| ✅ Nuestra Recomendación | ⭐ Startups escalando rápido, necesitan spot instances para cost optimization | ⭐ Empresas con BigQuery/GCP, modelos TensorFlow complejos | ⭐ Empresas Microsoft-heavy, necesitan compliance (HIPAA/SOC2) |
💡 Decisión Platform-Agnostic: Diseñamos pipelines portables con MLflow + Docker + Kubernetes que funcionan en cualquier plataforma. Si tu empresa migra de AWS SageMaker a Google Vertex AI, tu pipeline se mueve en 2-3 días vs reescribir todo (4-6 semanas). ~85% del código reutilizable entre plataformas.

Garantías Técnicas: Si No Deployamos, No Pagas
25+ proyectos MLOps. NUNCA he fallado deadline.
First Model Production in 6 Weeks
Si tu primer modelo no está en producción en 6 semanas, trabajo gratis hasta lograrlo.
Historial: Los proyectos se completan consistentemente dentro del timeline acordado
Knowledge Transfer Completo
Documentación exhaustiva + training. Tu equipo autónomo post-project.
Deliverables: Runbook 80-100 pgs, video tutorials, source code.
Preguntas Frecuentes Técnicas
¿Funciona con nuestro stack actual (SageMaker/Vertex/Azure/Databricks)?
Sí. Soportamos AWS SageMaker (40% proyectos), Google Vertex AI (25%), Azure ML (20%), Databricks (15%). También Kubernetes personalizado (Kubeflow), GPUs locales + cloud híbrido. Auditoría día 1 identifica mejor opción TU caso.
¿Necesitamos cambiar nuestro código Data Science existente?
Mínimo. Cambios típicos: añadir MLflow logging (3-5 líneas), parametrizar training script, Dockerfile. NO requiere: rewrite modelo, cambiar framework (TensorFlow→PyTorch), refactor codebase. Tiempo adaptation: 4-8 horas Data Scientist.
¿Cuánto tiempo mi equipo necesita dedicar durante implementation?
Mínimo. Total: ~25-30 horas over 4-6 semanas. Breakdown: Kick-off 4h, Reviews 12h, Training 10h, Ad-hoc 4h. TOTAL: 30h over 6 semanas = 5h/semana average (1h/día team). Yo hago el heavy lifting.
Casos de Éxito Reales
Pipelines MLOps implementados en producción con resultados medibles
Servicios Relacionados
Completa tu infraestructura IA/ML con estos servicios especializados
Sistemas RAG & IA Generativa
Implementa sistemas RAG production-ready con LangChain. Reduce hallucinations y mejora accuracy de tus aplicaciones LLM.
Ver servicio RAG Systems →Optimización Costes Cloud & FinOps
Reduce tu factura AWS/Azure hasta 50% con auditorías FinOps. Especialmente útil para workloads ML (GPUs, LLM APIs).
Ver servicio FinOps →Agentes Autónomos IA
Automatiza procesos complejos que chatbots y RPA no pueden. Multi-agent orchestration con LangChain/LangGraph.
Ver servicio Agentes IA →¿Listo para Deployar tu Primer Modelo en 6 Semanas?
Track record de implementaciones exitosas en semanas, sin incidents críticos en producción.
Demo Técnica 30 min
- ✅ Revisamos tu stack actual
- ✅ Architecture proposal específica
- ✅ Timeline & pricing estimate
WhatsApp Directo
- ✅ Respuesta <4h laborables
- ✅ +34 631 360 378
- ✅ Consulta técnica gratuita
Descarga Gratis
"MLOps Readiness Assessment (25 pts)"
- ✅ Checklist: ¿Tu equipo ready MLOps?
- ✅ Stack comparison (SageMaker vs Vertex)
- ✅ ROI calculator deployment
Track Record Verificable:
Cada mes sin MLOps = €10k desperdiciado (equipo DS idle). ¿Cuántos meses más?
Artículos Relacionados sobre MLOps & Deployment de Modelos
Aprende más sobre deployment de modelos ML en producción, SageMaker y MLOps
Desafíos Kubernetes MLOps: Simplificar con Terraform & Helm
Guía práctica para desplegar modelos ML en Kubernetes usando Terraform + Helm. Evita los 5 errores más comunes.
Leer más →AWS SageMaker vs Azure ML vs Vertex AI: Costes Reales 2025
Comparativa exhaustiva de costes MLOps: SageMaker, Azure ML y Vertex AI con casos reales y TCO completo.
Leer más →Vulnerabilidades MLOps: 87% Fallan - Checklist Seguridad
Checklist completo de seguridad MLOps: model poisoning, data leakage, pipeline security y compliance.
Leer más →Kubernetes 1.33 MLOps: DRA GPU Scheduling Revolución
Nueva arquitectura Dynamic Resource Allocation en K8s 1.33 para GPUs: benchmarks y migración práctica.
Leer más →LLMOps vs MLOps: Framework de Transición y Migración
Diferencias críticas entre MLOps y LLMOps: evaluations, monitoring, deployment patterns y migración paso a paso.
Leer más →Por Qué Empresas No Ven ROI en IA Generativa: McKinsey
Análisis McKinsey 2025: razones por las que proyectos IA no generan ROI y framework para solucionarlo.
Leer más →Servicios Relacionados
Complementa tu infraestructura con nuestros servicios especializados en IA/ML
Sistemas RAG & IA Generativa
Implemento sistemas RAG listos para producción que conectan LLMs con tu documentación interna
Ver servicio →Optimización Costes Cloud & FinOps
Reduzco costes cloud 30-70% con auditorías técnicas y optimización de LLM APIs
Ver servicio →Agentes Autónomos IA
Desarrollo agentes multi-step con LangGraph que ejecutan acciones automáticas
Ver servicio →