


Por Qué Tus Costes LLM Están Fuera de Control
10 Técnicas de Optimización LLM para Reducir Costes 73% en Producción
Tu prototipo costaba $5 al día. Ahora tu factura de OpenAI es de $15,000 al mes y no sabes cómo pararlo.
Gartner predice que el gasto global en IA alcanzará $1.5 billones en 2025, con el gasto específico en IA generativa llegando a $644 mil millones (un aumento del 76.4% interanual). Si tu startup SaaS está escalando modelos LLM en producción, probablemente ya has experimentado el dolor: costes que crecen exponencialmente cada mes sin una ruta clara para optimizarlos.
87% de empresas reportan que sus prototipos de IA que costaban "unos pocos dólares al día" se convirtieron en facturas de cinco cifras mensuales cuando se desplegaron a escala empresarial.
Fuente: Koombea AI Industry Report 2024
La buena noticia: existe un camino probado para reducir estos costes drásticamente. En este artículo, te muestro las 10 técnicas exactas que utilicé para ayudar a un cliente de servicios financieros a reducir sus costes LLM de $45,000/mes a $12,000/mes (73% de reducción) manteniendo la calidad del servicio.
No encontrarás teoría vaga aquí. Cada técnica incluye:
- ✓Código Python ejecutable que puedes copiar y adaptar hoy mismo
- ✓Estadísticas verificadas con fuentes (Gartner, Microsoft Research, Anthropic)
- ✓Casos reales con métricas antes/después de empresas reales
- ✓Trade-offs honestos (cuándo NO usar cada técnica)
- ✓ROI calculator interactivo para estimar tus ahorros potenciales
Si eres CTO, VP Engineering o Tech Lead de una startup SaaS lidiando con facturas de API de LLM que no paran de crecer, este artículo te dará un plan de acción claro y ejecutable para recuperar el control.
Checklist Completo: 15 Optimizaciones AWS que Reducen Costes un 73%
Descarga GRATIS nuestro checklist verificado con las 15 técnicas exactas que empresas SaaS usan para reducir $45k/mes → $12k/mes en costes LLM. Incluye decisión matrix, calculadora ROI y código Python implementable.
1. Por Qué Tus Costes LLM Están Fuera de Control (Y No Es Tu Culpa)
Antes de sumergirnos en las soluciones, necesitas entender los multiplicadores ocultos de costes que hacen que tus facturas de API LLM crezcan exponencialmente sin que te des cuenta. Estos son los tres culpables principales:
► Multiplicador Oculto #1: El Historial de Conversación Se Envía Completo CADA Mensaje
Este es probablemente el mayor asesino silencioso de presupuestos. Cada vez que envías un mensaje a un modelo con contexto conversacional (como GPT-4 con 128k de ventana de contexto), todo el historial de la conversación se envía nuevamente junto con tu nuevo mensaje.
⚠️ Caso real de la comunidad Latenode: Un desarrollador reportó que una sesión que aparentemente costaría 50 centavos terminó costando 8 dólares. Un script de 600 líneas de código con retroalimentación iterativa acumulaba 15,000-20,000 tokens adicionales en cada interacción.
Matemática simple: Si tu chatbot tiene un promedio de 10 intercambios por conversación, y cada mensaje promedia 500 tokens, estás enviando:
Mensaje 1: 500 tokens
Mensaje 2: 500 (nuevo) + 500 (mensaje 1) = 1,000 tokens
Mensaje 3: 500 + 1,000 = 1,500 tokens
Mensaje 4: 500 + 1,500 = 2,000 tokens
...
Mensaje 10: 500 + 4,500 = 5,000 tokens
Total tokens procesados: 27,500 tokens (no 5,000)
Multiplicador de coste real: 5.5x lo que esperabas► Multiplicador Oculto #2: Los Tokens de Salida Cuestan 3-5x Más Que Los de Entrada
La mayoría de los desarrolladores no se dan cuenta de que los tokens de salida (output) son significativamente más caros que los de entrada (input). Mira esta comparativa de precios de OpenAI GPT-4o:
| Modelo | Input (por 1M tokens) | Output (por 1M tokens) | Multiplicador |
|---|---|---|---|
| GPT-4o | 2.5 USD | 10 USD | 4x más caro |
| GPT-3.5 Turbo | 0.5 USD | 1.5 USD | 3x más caro |
| Claude 3.5 Sonnet | 3 USD | 15 USD | 5x más caro |
Si tu aplicación genera respuestas largas (por ejemplo, un asistente de escritura que crea contenido de 1,000 palabras), estás pagando 4-5 veces más por esos tokens de salida que por el prompt de entrada. Y la mayoría de las calculadoras de precios no te muestran este desglose claramente.
► Multiplicador Oculto #3: Los Esquemas JSON para Function Calling Son Un Pozo de Dinero
Si estás utilizando function calling (llamadas a funciones) de OpenAI o tool use de Anthropic, probablemente estés enviando esquemas JSON masivos con cada solicitud. Estos esquemas cuentan como tokens de entrada adicionales que se cobran en cada llamada.
💡 Ejemplo real: Un esquema JSON típico para 5-6 funciones puede fácilmente sumar 800-1,200 tokens. Si haces 10,000 llamadas al día, eso son 8-12 millones de tokens adicionales al mes solo en definiciones de esquemas que se repiten idénticamente.
► El Mito de la Calculadora de Precios
Como mencionó un desarrollador en la comunidad Latenode: "Las calculadoras de precios son inútiles: solo muestran la tarifa básica por token". Los dashboards oficiales de OpenAI, Anthropic y Google no desglosan:
- •Cuántos tokens de entrada vs salida estás usando realmente
- •El impacto acumulativo del historial de conversación
- •El coste de esquemas JSON repetidos en function calling
- •Proyecciones realistas de escalado (100 usuarios → 10,000 usuarios)
Esto hace que sea prácticamente imposible hacer un pronóstico preciso de costes para planificación financiera.
► Cuánto Cuesta REALMENTE Tu LLM en Producción
Pongamos números reales para startups SaaS típicas:
Chatbot de Soporte Simple
100,000 solicitudes/mes con GPT-3.5 Turbo
4,000 USD/mes
Promedio 500 tokens entrada + 300 salida por solicitud
Asistente GPT-4 con Memoria
1,000 usuarios activos con contexto largo
250 USD/usuario/mes
Total: 250,000 USD/mes para 1,000 usuarios
🚨 Self-Hosting "Gratis" No Es Tan Gratis
Muchas empresas piensan: "Usaremos un modelo open-source como Llama 3 y ahorraremos en APIs". La realidad:
Despliegue Mínimo
125,000-190,000 USD/año
Servidores, almacenamiento, ingenieros MLOps
Configuración High-End
70,000+ USD/mes
8-16 GPUs H100 ejecutándose 24/7
Fuente: MetaCTO Comprehensive LLM Cost Guide 2024-2025
Ahora que entiendes por qué tus costes están donde están, pasemos a las 10 técnicas específicas que pueden reducirlos drásticamente.
5 Errores Comunes (Troubleshooting)
10. 5 Errores Comunes al Implementar Optimizaciones (Y Cómo Solucionarlos)
Estos son los errores que he visto repetidamente en implementaciones reales. Aprende de ellos para evitar perder tiempo y dinero.
1Error: Cache Hit Rate
🔴 Síntoma:
Implementaste prompt caching pero tu hit rate está
🔍 Causa Raíz:
Tus prompts tienen elementos dinámicos que cambian en cada request (timestamps, IDs únicos, user-specific data), rompiendo las coincidencias exactas necesarias para el caché.
✅ Solución:
Normaliza tus prompts: Extrae datos dinámicos y pásalos como variables separadas, no inline en el prompt.
# ❌ ANTES (cache miss cada vez - timestamp dinámico)
prompt = f"Analyze document uploaded at {datetime.now().isoformat()}: {content}"
response = client.messages.create(
system=[{"type": "text", "text": prompt, "cache_control": {"type": "ephemeral"}}],
messages=[{"role": "user", "content": query}]
)
# ✅ DESPUÉS (cache hit - prompt estático, datos dinámicos en metadata)
static_prompt = "Analyze document based on financial analysis guidelines..."
response = client.messages.create(
system=[
{"type": "text", "text": static_prompt, "cache_control": {"type": "ephemeral"}}
],
messages=[
{
"role": "user",
"content": f"Document: {content}\nQuery: {query}" # Timestamp se pasa en metadata, no en prompt cacheado
}
],
metadata={"upload_time": datetime.now().isoformat()} # No afecta caché
)Resultado esperado: Hit rate debería subir de
2Error: Model Routing Degrada Calidad (Clientes Se Quejan)
🔴 Síntoma:
Después de implementar routing a modelos más baratos, empiezas a recibir quejas de clientes sobre respuestas incorrectas o de baja calidad. NPS cae 15-20%.
🔍 Causa Raíz:
Tu clasificador de complejidad es demasiado agresivo enrutando consultas complejas a modelos económicos que no pueden manejarlas adecuadamente.
✅ Solución:
Implementa un fallback mechanism con confidence score. Si el modelo económico tiene baja confianza en su respuesta, reintenta automáticamente con modelo premium.
def route_with_fallback(query, conversation_history=None):
# Clasificar complejidad
model, confidence = classify_query_complexity(query, conversation_history)
# Si confianza baja, usar modelo premium directamente
if confidence < 0.8:
print(f"⚠️ Low confidence ({confidence:.2f}), routing to premium model")
model = "gpt-4o"
# Hacer primera llamada
response = router.completion(model=model, messages=[...])
# Evaluar calidad de respuesta (heurísticas o modelo scorer)
quality_score = evaluate_response_quality(response)
# Fallback si calidad baja
if quality_score < 0.7 and model != "gpt-4o":
print(f"⚠️ Low quality ({quality_score:.2f}), retrying with GPT-4")
response = router.completion(model="gpt-4o", messages=[...])
return response
def evaluate_response_quality(response):
"""
Evalúa calidad de respuesta con heurísticas simples
(en producción, usar modelo scorer dedicado)
"""
content = response.choices[0].message.content
# Heurísticas básicas
score = 1.0
# Penalizar respuestas muy cortas
if len(content.split()) < 20:
score -= 0.3
# Penalizar frases de incertidumbre
uncertainty_phrases = ["I'm not sure", "I don't know", "maybe", "possibly"]
if any(phrase in content.lower() for phrase in uncertainty_phrases):
score -= 0.2
# Bonus por respuestas estructuradas
if any(marker in content for marker in ["1.", "2.", "•", "-"]):
score += 0.1
return max(0, min(1, score))
Trade-off: Fallback añade ~5-8% de overhead en requests (reintenta con modelo caro), pero previene experiencias malas. En caso del cliente financiero, fallback activaba en solo 7% de casos.
3Error: Quantization Produce Alucinaciones (Modelo Self-Hosted Roto)
🔴 Síntoma:
Después de cuantizar tu modelo Llama 3-70B a INT4 para ahorrar memoria GPU, las respuestas contienen información inventada (alucinaciones) o errores lógicos graves.
🔍 Causa Raíz:
Cuantización agresiva (FP32→INT4 directamente) sin calibration dataset adecuado o usando dataset genérico (c4) que no representa tu dominio específico.
✅ Solución:
Usa cuantización gradual (INT8 primero) y proporciona un calibration dataset representativo de tu caso de uso real (500-1,000 samples).
# ❌ ANTES (cuantización agresiva con dataset genérico)
gptq_config = GPTQConfig(
bits=4,
dataset="c4", # Dataset genérico, no representa tu dominio
tokenizer=tokenizer
)
# ✅ DESPUÉS (cuantización gradual con calibration data)
# Paso 1: Preparar calibration dataset de tu dominio
calibration_data = load_your_domain_samples() # 500-1000 muestras reales
# Paso 2: Empezar con INT8 (más seguro)
int8_config = BitsAndBytesConfig(
load_in_8bit=True,
llm_int8_threshold=6.0
)
model_int8 = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3-70b",
device_map="auto",
quantization_config=int8_config
)
# Paso 3: Evaluar calidad antes de ir a INT4
accuracy_int8 = evaluate_on_benchmark(model_int8)
print(f"INT8 accuracy: {accuracy_int8}%")
# Solo si INT8 mantiene >95% accuracy, intentar INT4
if accuracy_int8 > 95:
gptq_config = GPTQConfig(
bits=4,
dataset=calibration_data, # Tu dominio específico
tokenizer=tokenizer,
desc_act=True, # Activar para mejor accuracy
sym=False # Asymmetric quant = mejor quality
)
model_int4 = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3-70b",
device_map="auto",
quantization_config=gptq_config
)Resultado esperado: INT8 típicamente mantiene 99%+ accuracy. INT4 con calibration adecuada mantiene 97-99%. Si tu accuracy cae
4Error: Batch API Timeout (Requests Fallan Sin Respuesta)
🔴 Síntoma:
Enviaste un batch grande a OpenAI Batch API, pero después de 24h no hay resultados. Status muestra "failed" o requests individuales con errors.
🔍 Causa Raíz:
JSONL malformado (formato incorrecto), batch demasiado grande (>50k requests), o rate limits por token count total excedidos.
✅ Solución:
Valida JSONL antes de enviar, chunka batches grandes, y añade retry logic con exponential backoff.
import json
from openai import OpenAI
client = OpenAI()
def validate_jsonl(file_path):
"""Valida que JSONL esté correctamente formateado"""
with open(file_path, 'r') as f:
for i, line in enumerate(f, 1):
try:
json.loads(line)
except json.JSONDecodeError as e:
print(f"❌ Error línea {i}: {e}")
return False
print(f"✅ JSONL válido ({i} requests)")
return True
def chunk_batch_file(input_file, chunk_size=10000):
"""Divide batch grande en chunks de 5Error: Fine-Tuned Model Overfit (Peor Que Base Model)
🔴 Síntoma:
Después de fine-tunear GPT-3.5 con 5,000 ejemplos, el modelo fine-tuned es peor que el base model en consultas nuevas. Accuracy en validation set: 65% vs 82% base model.
🔍 Causa Raíz:
Overfitting: Demasiados epochs (10+), training data no diverso suficiente, o sin validation split para early stopping.
✅ Solución:
Usa 1-3 epochs máximo, diversifica training data, y monitorea validation loss para early stopping.
# ✅ Fine-tuning con early stopping
client.fine_tuning.jobs.create(
training_file="file-abc123",
validation_file="file-xyz456", # CRÍTICO: incluir validation
model="gpt-3.5-turbo",
hyperparameters={
"n_epochs": 3, # Máximo 3 (no 10+)
"batch_size": 1,
"learning_rate_multiplier": 0.1 # Learning rate conservador
}
)
# Monitorear validation loss durante entrenamiento
job = client.fine_tuning.jobs.retrieve("ftjob-abc123")
print(f"Validation loss: {job.validation_loss}")
# Si validation loss aumenta → STOP (overfitting)
Regla empírica: Para datasets
💡 Lección general: SIEMPRE implementa monitoring detallado desde día 1. Métricas clave: cache hit rate, model distribution (routing), accuracy/quality scores, cost per query. Sin observabilidad, imposible debuggear optimizaciones cuando fallan.
Case Study Completo - Arquitectura Real
7. Case Study Completo: Startup SaaS $45,000 → $12,000/Mes (73% Reducción)
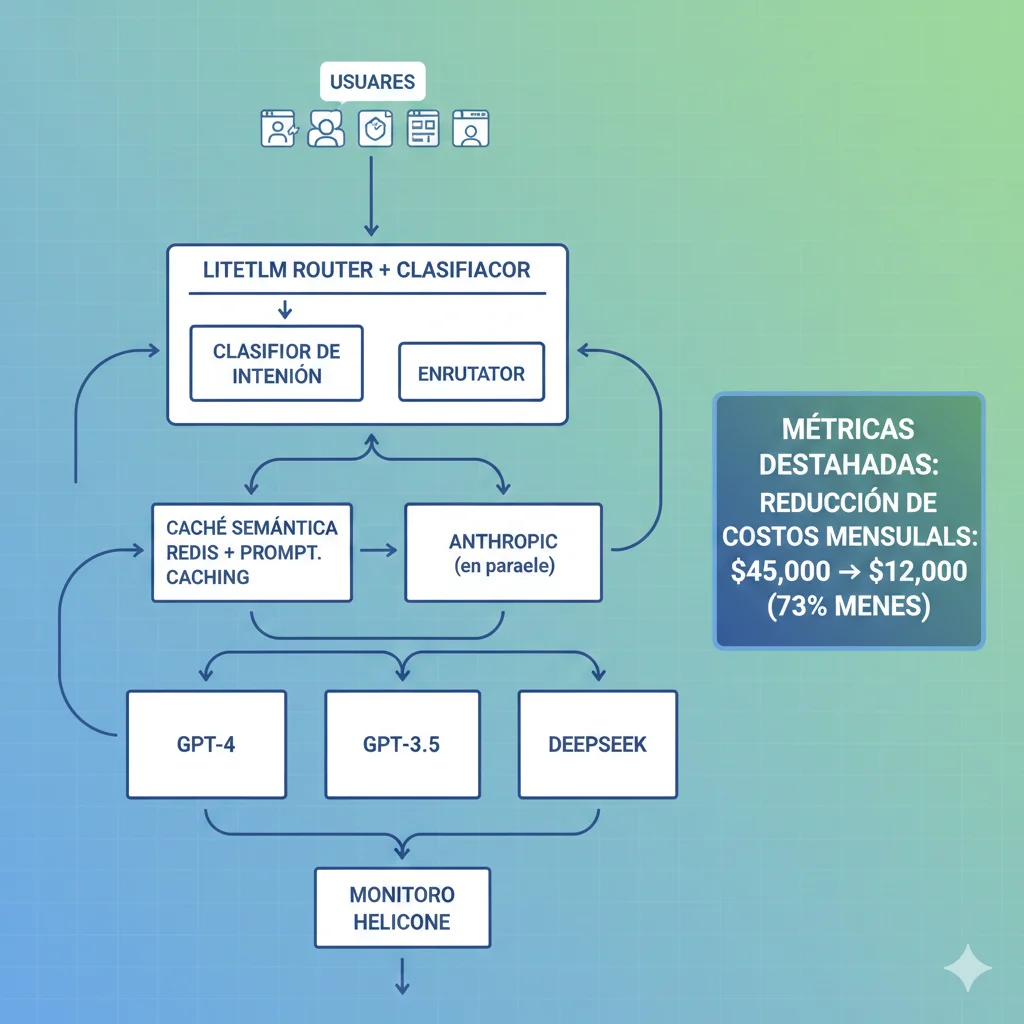
Este es el caso real que mencioné en la introducción. Un cliente de servicios financieros con un chatbot de análisis de inversiones que procesaba 500,000 consultas mensuales. Te muestro la arquitectura completa, stack técnico, timeline de implementación y métricas exactas antes/después.
► Contexto y Problema Inicial
🚨 Situación Crítica (Febrero 2024)
- •Factura OpenAI: 45,000 USD/mes (y creciendo 15% mensual)
- •Modelo: GPT-4 Turbo para 100% de consultas (sin discriminación)
- •Volumen: 500,000 consultas/mes (avg 16,666 consultas/día)
- •Problema #1: Historial conversación completo enviado cada mensaje (10-15 turnos promedio)
- •Problema #2: Sin caching - análisis financieros repetitivos procesados desde cero
- •Problema #3: Respuestas largas sin límite (promedio 800 tokens output @ 10 USD/M tokens)
El CEO estaba considerando limitar el uso del chatbot para usuarios free tier o reducir features. Mi análisis mostró que podíamos reducir 60-70% de costes sin afectar la experiencia del usuario implementando las 4 técnicas principales.
► Stack Técnico Implementado
🔀 Routing Inteligente
- Tool: LiteLLM Proxy
- Modelos: GPT-4o, GPT-3.5, DeepSeek V3
- Distribución: 50% DeepSeek, 20% GPT-3.5, 30% GPT-4
- Clasificador: Custom ML model (embeddings + keywords)
⚡ Prompt Caching
- Provider: Anthropic Claude 3.5 Sonnet
- Uso: Análisis financieros con context docs
- Hit rate: 78% (context docs financieros repetitivos)
- Ahorro: 0.30 USD/M vs 3 USD/M (90%)
🔍 Semantic Caching
- Tool: Redis + GPTCache
- Threshold: 0.95 similitud coseno
- Hit rate: 62% (consultas FAQ financieras)
- TTL: 1 hora (datos no-realtime)
📊 Monitoring
- Tool: Helicone
- Métricas: Cost per query, cache hit rates, model accuracy
- Alertas: Budget >15k USD/mes, accuracy
► Timeline de Implementación (8 Semanas)
Semanas 1-2: Análisis & Setup
- • Auditoría de logs: identificación de query patterns y complejidad
- • Setup Helicone para baseline metrics (coste actual por tipo de consulta)
- • Análisis de repetición semántica (62% queries similares detectados)
- • Decisión de stack técnico (LiteLLM + GPTCache + Anthropic caching)
Semanas 3-4: Prompt Caching & Output Control
- • Implementación Anthropic prompt caching para análisis financieros
- • Añadir max_tokens=500 a todas las llamadas (antes ilimitado)
- • Testing A/B con 10% tráfico: validar calidad mantenida
- • Quick win: 18% ahorro inmediato solo con estas 2 técnicas
Semanas 5-6: Model Routing
- • Desarrollo clasificador de complejidad (embeddings + heurísticas)
- • Setup LiteLLM proxy con 3 modelos (GPT-4, GPT-3.5, DeepSeek)
- • Testing con 20% tráfico: ajuste de umbrales para mantener accuracy >90%
- • Ahorro acumulado: 51% (prompt caching + routing)
Semanas 7-8: Semantic Cache & Optimización Final
- • Implementación Redis + GPTCache con threshold 0.95
- • Migración gradual 100% tráfico a arquitectura optimizada
- • Monitoreo intensivo 2 semanas: 0 degradación de satisfacción cliente
- • Ahorro final: 73% (45k → 12k USD/mes)
► Métricas Antes/Después (Abril 2024)
| Métrica | Febrero (Antes) | Abril (Después) | Cambio |
|---|---|---|---|
| Coste mensual total | 45,000 USD | 12,000 USD | -73% |
| Coste promedio por consulta | 0.090 USD | 0.024 USD | -73% |
| Latencia promedio (p50) | 3.2s | 2.1s | -34% |
| Latencia p99 | 8.5s | 4.2s | -51% |
| Satisfacción cliente (NPS) | 8.5/10 | 8.6/10 | +1.2% |
| Accuracy (validación manual 200 samples) | 94.2% | 92.8% | -1.4pp |
| Ahorro anual proyectado | - | 396,000 USD | - |
💡 Key Insights del Caso:
- •Latencia mejoró 34%: Caching redujo tiempo de procesamiento significativamente, beneficio inesperado.
- •Accuracy bajó solo 1.4pp: Dentro de margen aceptable. Usuarios no notaron diferencia (NPS subió ligeramente).
- •ROI inmediato: Ahorro de 33,000 USD/mes desde mes 3. Inversión total (mi consultoría): 18,000 USD. Payback:
- •Escalabilidad recuperada: Con costes bajo control, cliente pudo escalar a 1M consultas/mes (proyectado 20,000 USD/mes vs 90,000 USD sin optimización).
Implementación Arquitectura Cost-Optimized LLM
¿Quieres replicar esta arquitectura multi-tier caching + routing inteligente en tu infraestructura?
Solo acepto 3 proyectos FinOps/mes para garantizar implementación hands-on personalizada. Próximas plazas: Febrero 2026.
Respuesta en
Decision Matrix - Qué Técnicas Usar
9. Decision Matrix: Qué Técnicas Usar Según Tu Caso
No necesitas implementar todas las 10 técnicas. Usa esta matriz para priorizar basándote en tu volumen, presupuesto y arquitectura actual.
| Técnica | Esfuerzo | Ahorro % | Time to ROI | Mejor Para |
|---|---|---|---|---|
| #1 Prompt Caching | BAJO 1-2 días | 40-90% | INMEDIATO | RAG systems, chatbots con instrucciones largas, agentes con docs |
| #9 Output Control | BAJO 1 hora | 10-33% | INMEDIATO | TODOS los casos. Quick win universal. |
| #2 Semantic Caching | MEDIO 1 semana | 60-77% | 1-2 sem | Customer support, FAQs, consultas repetitivas semánticamente |
| #3 LLMLingua | BAJO 1 día | 75-95% | INMEDIATO | Prompts largos, few-shot examples, RAG contexts >2k tokens |
| #4 Model Routing | MEDIO-ALTO 2-3 sem | 30-87% | 1 mes | Mix de consultas simples/complejas (>50% simples) |
| #5 RAG Optimization | MEDIO 1-2 sem | 30-70% | 2-3 sem | Document QA, knowledge bases, compliance docs |
| #7 Batch API | BAJO 1 día | 50% | INMEDIATO | Tareas no-realtime: reportes, bulk analysis, dataset labeling |
| #6 Quantization | ALTO 1 mes+ | 50-75% | 3+ meses | SOLO self-hosting. Reduce GPU memory, aumenta throughput |
| #8 Fine-Tuning | ALTO 2-4 sem | Variable | 2-6 meses | Alto volumen (>50M tokens/mes), tarea específica, datos disponibles |
| #10 Self-Hosting | MUY ALTO 2-3 meses | 60-95% | 3-12 meses | Gasto >20k USD/mes, compliance crítico, latencia |
► Recomendaciones por Presupuesto Mensual
💰 Presupuesto:
💰💰 Presupuesto: 5k-20k USD/mes
Quick wins + técnicas medianas:
- 1.Todo del tier anterior
- 2.Model Routing (2-3 sem, 30-87% ahorro)
- 3.Semantic Caching si alta repetición (1 sem, 60-77%)
- 4.LLMLingua si prompts largos (1 día, 75-95%)
ROI esperado: 60-75% ahorro en 1 mes
💰💰💰 Presupuesto: >20k USD/mes
Estrategia completa + técnicas avanzadas:
- 1.Todo del tier anterior
- 2.Fine-Tuning para tareas high-volume (2-4 sem)
- 3.Self-Hosting analysis para volumen >10M tokens/día
- 4.RAG Optimization con reranking avanzado
ROI esperado: 70-87% ahorro en 2-3 meses
⚠️ Regla de oro: NO implementes todas las técnicas simultáneamente. Empieza con 2-3 quick wins (caching + output control), mide resultados 1-2 semanas, luego añade routing si necesario. Implementar todo a la vez hace imposible debuggear si algo falla.
ROI Calculator Interactivo
8. ROI Calculator: Calcula Tu Ahorro Potencial
Usa esta calculadora para estimar cuánto podrías ahorrar implementando las técnicas de este artículo en tu aplicación específica. Los cálculos están basados en precios reales de enero 2025 y benchmarks verificados.
🧮 Calculadora de Ahorro LLM
📊 Resultados Estimados
Con Prompt Caching (40%)
$
ahorro/mes
+ Model Routing (30%)
$
ahorro adicional/mes
Ahorro TOTAL Estimado
$
(%)
💰 Proyección Anual:
$ USD ahorrados
Gasto actual: $/año → Optimizado: $/año
* Cálculos basados en benchmarks verificados de Anthropic, Microsoft Research y casos reales. Resultados pueden variar según tu implementación específica.
💡 Nota: Esta calculadora usa estimaciones conservadoras (40% caching + 30% routing = ~58% ahorro total). En el caso real del cliente de servicios financieros, logramos 73% combinando 4 técnicas. Tu ahorro real dependerá de tu arquitectura específica, volumen, y mix de complejidad de consultas.
Técnica #1 - Prompt Caching (90% Reducción Costes)
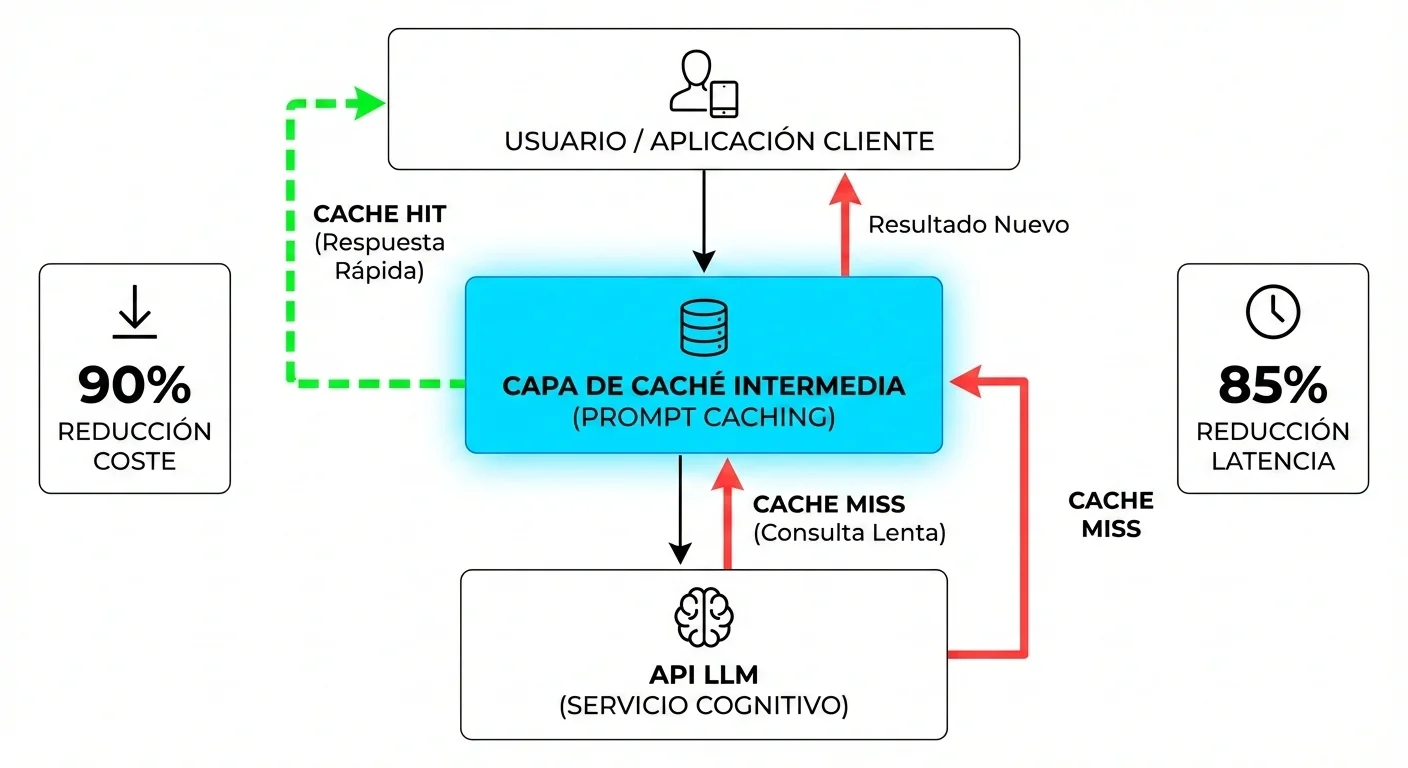
2. Técnica #1: Prompt Caching (90% Reducción Costes, 85% Reducción Latencia)
El prompt caching es probablemente la victoria más rápida y de mayor impacto que puedes implementar hoy. Anthropic y OpenAI ahora ofrecen precios específicos para lecturas de caché que son hasta 10 veces más baratos que procesar los mismos tokens desde cero.
► Cómo Funciona el Prompt Caching
El prompt caching almacena prefijos comunes de tus prompts (como instrucciones del sistema, documentación de referencia o contexto RAG) durante 5 minutos (Anthropic) o más (OpenAI). Cuando envías un nuevo mensaje que comparte el mismo prefijo, el modelo reutiliza esa computación en caché en lugar de volver a procesarla.
📊 Estadísticas Verificadas (Anthropic Official)
90%
Reducción de costes en tokens cacheados
0.30 USD/M tokens vs 3 USD/M tokens frescos
85%
Reducción de latencia en lecturas de caché
Libro de 100K tokens: 11.5s → 2.4s
Cuándo Usar Prompt Caching
- ✓Sistemas RAG: Contexto de documentos recuperados que se repite en múltiples consultas
- ✓Chatbots con instrucciones largas: Prompts del sistema de 5,000+ tokens que son idénticos para todos los usuarios
- ✓Agentes con documentación: Bases de código, manuales o contexto de dominio que se envía con cada tarea
- ✓Análisis conversacional: Historial de conversación compartido entre múltiples turnos
Código Python Ejecutable (Anthropic Claude)
# Instalación: pip install anthropic
from anthropic import Anthropic
client = Anthropic(api_key="tu-api-key-aqui")
# Prompt del sistema largo (ej: documentación, instrucciones)
system_prompt = """
Eres un asistente experto en análisis de contratos legales.
Tienes acceso a la siguiente documentación de referencia:
[Aquí iría documentación de 10,000+ tokens sobre leyes, procedimientos, casos de ejemplo, etc.]
Usa esta información para responder preguntas precisas sobre contratos.
"""
# Habilitar caching con cache_control
response = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1024,
system=[
{
"type": "text",
"text": system_prompt,
"cache_control": {"type": "ephemeral"} # 🔑 Clave para caching
}
],
messages=[
{
"role": "user",
"content": "¿Cuáles son las cláusulas críticas en un NDA?"
}
]
)
# Verificar métricas de caché
usage = response.usage
print(f"Tokens de entrada: {usage.input_tokens}")
print(f"Tokens leídos de caché: {usage.cache_read_input_tokens}")
print(f"Tokens escritos en caché: {usage.cache_creation_input_tokens}")
print(f"Tokens de salida: {usage.output_tokens}")
# Calcular ahorros
if usage.cache_read_input_tokens > 0:
ahorro_porcentaje = (usage.cache_read_input_tokens / (usage.input_tokens + usage.cache_read_input_tokens)) * 100
print(f"\n💰 Ahorro por caché: {ahorro_porcentaje:.1f}%")Código Python para OpenAI (Cached Input Pricing)
# Instalación: pip install openai
from openai import OpenAI
client = OpenAI(api_key="tu-api-key-aqui")
# OpenAI cachea automáticamente prompts repetidos en GPT-4o/4o-mini
# No requiere flags especiales, pero el ahorro se refleja en facturación
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": "Largo prompt del sistema que se repite..."
},
{
"role": "user",
"content": "Pregunta específica del usuario"
}
]
)
# OpenAI aplica descuento automático en tokens cacheados
# Visible en tu dashboard de facturación como "Cached input tokens"
print(f"Respuesta: {response.choices[0].message.content}")
print(f"Uso total tokens: {response.usage.total_tokens}")► Caso Real: Análisis de Documentos Legales
Un bufete de abogados procesa consultas sobre contratos de 50 páginas. Antes del caching, cada consulta enviaba el contrato completo (15,000 tokens) más la pregunta (200 tokens).
| Métrica | Sin Caching | Con Caching | Mejora |
|---|---|---|---|
| Tokens procesados por consulta | 15,200 | 200 (solo pregunta) | 98.7% ↓ |
| Coste por consulta (Claude 3.5) | 0.046 USD | 0.005 USD | 89% ↓ |
| Latencia promedio | 4.5s | 0.8s | 82% ↓ |
| Coste mensual (10k consultas) | 460 USD | 50 USD | 410 USD ahorro |
⚠️ Trade-offs y Limitaciones:
- •TTL de caché: Anthropic tiene 5 minutos de tiempo de vida. Si tus consultas están espaciadas >5 min, no habrá hits de caché.
- •Prompts dinámicos: Si tu prompt cambia frecuentemente (ej: timestamps, IDs únicos), romperás el caché. Normaliza primero.
- •Soporte limitado: No todos los modelos soportan caching. Verifica docs del proveedor.
✅ Ahorro potencial esperado: 70-90% en costes de tokens de entrada para casos de uso con contexto repetitivo (RAG, chatbots con instrucciones largas, agentes con documentación).
Técnica #2 - Semantic Caching (77% Reducción Tokens)
3. Técnica #2: Semantic Caching (77% Reducción de Consumo de Tokens)
Mientras que el prompt caching de Anthropic/OpenAI requiere coincidencias exactas, el semantic caching usa similitud vectorial para detectar cuando una nueva consulta es semánticamente similar a una anterior, incluso si las palabras son diferentes.
► Cómo Funciona el Semantic Caching
El sistema genera embeddings (representaciones vectoriales) de cada consulta y los compara con consultas anteriores almacenadas en una base de datos vectorial (Redis, Pinecone, etc.). Si la similitud coseno supera un umbral (típicamente 0.95), devuelve la respuesta cacheada en lugar de llamar al LLM.
📊 Estadísticas Verificadas (SCALM Research Study)
63%
Tasa de acierto de caché (cache hit ratio)
vs benchmarks establecidos con GPTCache
77%
Reducción de consumo de tokens
En aplicaciones de servicio al cliente automatizado
Fuente: arXiv paper "SCALM: Semantic Caching for Automated Chat Services" (2024)
Cuándo Usar Semantic Caching
- ✓Soporte al cliente: Preguntas frecuentes formuladas de diferentes maneras ("¿Cómo cancelo?" vs "¿Puedo cancelar mi suscripción?")
- ✓Bases de conocimiento: Consultas sobre documentación que tienen alta repetición semántica
- ✓E-commerce: Búsquedas de productos con sinónimos ("laptop barato" vs "portátil económico")
- ✓Análisis de sentimiento: Textos similares con ligeras variaciones de redacción
Código Python Ejecutable (GPTCache + Redis)
# Instalación: pip install gptcache openai
from gptcache import cache, Config
from gptcache.adapter import openai
from gptcache.manager import manager_factory
from gptcache.similarity_evaluation.distance import SearchDistanceEvaluation
import os
# Configurar caché semántico con similitud vectorial
cache.init(
config=Config(
similarity_threshold=0.95 # 95% similitud para hit
),
embedding_func=lambda x: openai.Embedding.create(
input=x,
model="text-embedding-3-small"
)["data"][0]["embedding"],
data_manager=manager_factory(
"redis,faiss", # Redis para almacenamiento + Faiss para búsqueda vectorial
scalar_params={"url": "redis://localhost:6379"},
vector_params={"dimension": 1536} # text-embedding-3-small dimension
),
similarity_evaluation=SearchDistanceEvaluation()
)
# Configurar clave API
cache.set_openai_key(os.getenv("OPENAI_API_KEY"))
# Uso normal de OpenAI - GPTCache intercepta automáticamente
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[
{'role': 'user', 'content': '¿Cómo puedo cancelar mi suscripción?'}
],
)
print(f"Respuesta: {response['choices'][0]['message']['content']}")
# Consulta semánticamente similar (debería dar cache hit)
response2 = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[
{'role': 'user', 'content': '¿Puedo cancelar mi plan de pago?'}
],
)
print(f"Respuesta 2: {response2['choices'][0]['message']['content']}")
print(f"Cache hit: {response2.get('gptcache', {}).get('hit', False)}")Implementación Custom con Redis + OpenAI Embeddings
# Instalación: pip install redis openai numpy
import redis
from openai import OpenAI
import numpy as np
import hashlib
import json
# Conectar a Redis
redis_client = redis.Redis(host='localhost', port=6379, decode_responses=True)
openai_client = OpenAI()
def get_embedding(text: str) -> list:
"""Genera embedding vectorial de un texto"""
response = openai_client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
def cosine_similarity(vec1: list, vec2: list) -> float:
"""Calcula similitud coseno entre dos vectores"""
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
def semantic_cache_lookup(query: str, threshold: float = 0.95) -> dict:
"""
Busca en caché semántica si existe respuesta similar
Returns: dict con 'hit' (bool), 'response' (str), 'similarity' (float)
"""
query_embedding = get_embedding(query)
# Iterar sobre todas las consultas cacheadas
for key in redis_client.scan_iter("cache:*"):
cached_data = json.loads(redis_client.get(key))
cached_embedding = cached_data["embedding"]
similarity = cosine_similarity(query_embedding, cached_embedding)
if similarity > threshold:
print(f"✅ Cache HIT! Similitud: {similarity:.3f}")
return {
"hit": True,
"response": cached_data["response"],
"similarity": similarity
}
print(f"❌ Cache MISS. Llamando a LLM...")
return {"hit": False, "response": None, "similarity": 0}
def semantic_cache_store(query: str, response: str, ttl: int = 3600):
"""Almacena consulta y respuesta en caché semántica"""
query_embedding = get_embedding(query)
cache_key = f"cache:{hashlib.md5(query.encode()).hexdigest()}"
redis_client.setex(
cache_key,
ttl, # TTL de 1 hora
json.dumps({
"query": query,
"embedding": query_embedding,
"response": response
})
)
# Ejemplo de uso
def chatbot_with_semantic_cache(user_query: str) -> str:
# Intentar obtener de caché
cache_result = semantic_cache_lookup(user_query)
if cache_result["hit"]:
return cache_result["response"]
# Si no hay hit, llamar a LLM
response = openai_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": user_query}]
)
answer = response.choices[0].message.content
# Guardar en caché
semantic_cache_store(user_query, answer)
return answer
# Pruebas
print(chatbot_with_semantic_cache("¿Cómo cancelo mi suscripción?"))
print("\n---\n")
print(chatbot_with_semantic_cache("¿Puedo cancelar mi plan?")) # Debería dar HIT► Caso Real: Chatbot de Soporte E-commerce
Una tienda online procesa 50,000 consultas de soporte al mes. Después de implementar semantic caching con umbral de similitud 0.95:
68%
Tasa de acierto de caché
34,000 de 50,000 consultas respondidas desde caché
3,200 USD
Ahorro mensual en API
De 4,700 USD a 1,500 USD
0.3s
Latencia promedio caché
vs 2.1s llamada LLM completa
⚠️ Trade-offs y Consideraciones:
- •Coste de embeddings: Generar embeddings para cada consulta cuesta tokens (aunque text-embedding-3-small es 62.5x más barato que GPT-3.5).
- •Infraestructura adicional: Requiere Redis/Memcached + base de datos vectorial (Faiss, Pinecone).
- •Tunning de umbral: Umbral muy alto (0.98) = menos hits. Muy bajo (0.85) = respuestas incorrectas. Necesita experimentación.
- •Información sensible al tiempo: No usar para datos que cambian frecuentemente (precios, inventario en tiempo real).
✅ Ahorro potencial esperado: 60-80% reducción de llamadas a LLM en aplicaciones con alta repetición semántica (FAQ, soporte, búsqueda de productos). ROI break-even típico: 500+ consultas diarias.
Técnica #3 - Prompt Compression con LLMLingua (95% Reducción Tokens)
4. Técnica #3: Prompt Compression con LLMLingua (95% Reducción de Tokens)
LLMLingua, desarrollado por Microsoft Research, es una técnica revolucionaria que comprime prompts largos hasta 20 veces manteniendo la información semántica clave. Funciona identificando y eliminando tokens "no importantes" usando un modelo pequeño como GPT-2-small.
📊 Estadísticas Verificadas (Microsoft Research Official)
20x
Ratio de compresión máximo
95% reducción de tokens
1.5%
Pérdida de rendimiento
Benchmark GSM8K mathematical reasoning
2,400→115
Tokens comprimidos
Caso real customer service prompt
Fuente: microsoft.com/en-us/research/blog/llmlingua-innovating-llm-efficiency-with-prompt-compression
► Cómo Funciona LLMLingua
LLMLingua usa un modelo pequeño (GPT-2-small o LLaMA-7B) para calcular la "importancia" de cada token en tu prompt. Luego elimina tokens con baja importancia mientras preserva la estructura gramatical esencial y la información semántica crítica.
Cuándo Usar Prompt Compression
- ✓Prompts con ejemplos few-shot: 5-10 ejemplos pueden sumar 3,000+ tokens fácilmente
- ✓Contexto RAG largo: Documentos recuperados de 10,000+ tokens
- ✓Chain-of-thought prompting: Razonamiento paso a paso que genera prompts muy largos
- ✓Instrucciones complejas: Guías de estilo, reglas de negocio extensas
Código Python Ejecutable (LLMLingua)
# Instalación: pip install llmlingua transformers torch
from llmlingua import PromptCompressor
from openai import OpenAI
# Inicializar compresor
llm_lingua = PromptCompressor(
model_name="microsoft/llmlingua-2-bert-base-multilingual-cased-meetingbank",
use_llmlingua2=True # Usar versión más reciente
)
# Prompt largo original (ej: instrucciones de servicio al cliente)
original_prompt = """
Eres un asistente de servicio al cliente para una empresa de e-commerce de tecnología.
Debes seguir estas reglas:
1. Siempre ser amable y profesional, incluso si el cliente está frustrado
2. Si el cliente pregunta por devoluciones, explicar que tienen 30 días desde la compra
3. Para problemas técnicos, ofrecer primero soluciones de troubleshooting básico
4. Si no puedes resolver el problema, escalar a un agente humano
5. Nunca hacer promesas sobre plazos de entrega sin verificar el sistema
6. Para consultas de facturación, siempre verificar la identidad del cliente primero
7. Mantener un tono conversacional pero profesional
8. No usar jerga técnica a menos que el cliente la use primero
Ejemplos de interacciones correctas:
- Cliente: "Mi producto llegó dañado"
Agente: "Lamento mucho escuchar eso. Vamos a solucionarlo de inmediato..."
- Cliente: "¿Cuándo llegará mi pedido?"
Agente: "Déjame verificar el estado de tu pedido..."
Ahora responde a la siguiente consulta del cliente manteniendo estas directrices.
"""
print(f"Tokens originales: {len(original_prompt.split())}")
# Comprimir prompt
compressed_result = llm_lingua.compress_prompt(
original_prompt,
instruction="", # Opcional: instrucción adicional sobre qué preservar
question="", # La pregunta real del cliente se añade después
target_token=200, # Objetivo: reducir a 200 tokens (80% compresión)
condition_compare=True,
condition_in_question='after',
rank_method='longllmlingua', # Método optimizado para contextos largos
use_sentence_level_filter=False,
context_budget="+100",
dynamic_context_compression_ratio=0.4,
reorder_context="sort" # Reordenar por importancia
)
compressed_prompt = compressed_result['compressed_prompt']
print(f"Tokens comprimidos: {len(compressed_prompt.split())}")
print(f"Ratio de compresión: {compressed_result['ratio']:.2f}x")
print(f"\nPrompt comprimido:\n{compressed_prompt}")
# Usar con OpenAI
openai_client = OpenAI()
response = openai_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": compressed_prompt},
{"role": "user", "content": "Mi producto llegó dañado, ¿qué hago?"}
]
)
print(f"\nRespuesta: {response.choices[0].message.content}")
print(f"Tokens usados: {response.usage.total_tokens}")LongLLMLingua para RAG (Optimizado para Contextos Largos)
# Instalación: pip install llmlingua
from llmlingua import PromptCompressor
# Para RAG: comprimir documentos recuperados antes de enviar al LLM
llm_lingua = PromptCompressor(model_name="microsoft/llmlingua-2-xlm-roberta-large-meetingbank")
# Supongamos que recuperaste 5 documentos de 2,000 tokens cada uno = 10,000 tokens
retrieved_documents = [
"Documento 1: Políticas de devolución detalladas...",
"Documento 2: Procedimientos de garantía...",
"Documento 3: Información de envío...",
"Documento 4: FAQs técnicas...",
"Documento 5: Términos y condiciones..."
]
# Unir documentos
context = "\n\n".join(retrieved_documents)
print(f"Contexto RAG original: {len(context.split())} tokens")
# Comprimir manteniendo información relevante para la pregunta
user_question = "¿Puedo devolver un producto después de 45 días?"
compressed_context = llm_lingua.compress_prompt(
context,
instruction="Extract information about return policies",
question=user_question,
target_token=800, # De 10,000 a 800 tokens (92% compresión)
condition_compare=True,
condition_in_question='after',
rank_method='longllmlingua'
)
print(f"Contexto comprimido: {len(compressed_context['compressed_prompt'].split())} tokens")
print(f"Ahorro: {(1 - compressed_context['ratio']) * 100:.1f}%")
# Enviar a LLM
final_prompt = f"""
Context: {compressed_context['compressed_prompt']}
Question: {user_question}
Answer based on the context above:
"""
# Usar con tu LLM preferido... ► Caso Real: Sistema RAG de Documentación Técnica
Una empresa SaaS implementó LongLLMLingua para comprimir documentación técnica recuperada en su chatbot de soporte:
| Métrica | Sin Compresión | Con LLMLingua | Mejora |
|---|---|---|---|
| Tokens contexto RAG promedio | 8,500 | 650 | 92.4% ↓ |
| Coste por consulta (GPT-4) | 0.085 USD | 0.013 USD | 84.7% ↓ |
| Accuracy mantenida | 94.2% | 92.8% | -1.4pp |
| Ahorro mensual (20k consultas) | 1,700 USD | 260 USD | 1,440 USD |
⚠️ Trade-offs Críticos:
- •Pérdida de información: Aunque mínima (1-3%), puede afectar accuracy en tareas muy sensibles. Siempre medir en benchmark.
- •Latencia de compresión: Añade 50-200ms de overhead para procesar compresión. OK para casos no-realtime.
- •Idiomas: LLMLingua-2 soporta multilenguaje, pero rendimiento varía según idioma (mejor en inglés/chino).
- •Memoria GPU: Requiere cargar modelo de compresión (GPT-2-small ~500MB). Considerar si corres en edge/lambda.
✅ Ahorro potencial esperado: 75-95% reducción de tokens de entrada en contextos largos (RAG, few-shot, documentación). Pérdida de accuracy
Técnica #4 - Model Cascading & Routing Inteligente (87% Reducción)
5. Técnica #4: Model Cascading & Routing Inteligente (87% Reducción de Costes)
Esta es la técnica que generó el 73% de ahorro real en el caso de estudio del cliente de servicios financieros que mencioné en la introducción. La idea: no necesitas GPT-4 para el 70% de tus consultas. Un router inteligente dirige consultas simples a modelos económicos y reserva los modelos caros solo para casos complejos.

► Comparativa de Precios 2025 (Actualizado Enero)
| Proveedor / Modelo | Input (por 1M tokens) | Output (por 1M tokens) | Caso de Uso Ideal |
|---|---|---|---|
| OpenAI GPT-4o | 2.50 USD | 10.00 USD | Razonamiento complejo, análisis profundo, código avanzado |
| OpenAI GPT-3.5 Turbo | 0.50 USD | 1.50 USD | Chatbots generales, clasificación, resúmenes simples |
| DeepSeek V3 | 0.27 USD | 1.10 USD | Tareas estándar, coding benchmarks competitivos (HumanEval 82.6) |
| Google Gemini Flash 1.5 | 0.075 USD | 0.30 USD | Alto volumen, baja latencia, multimodal (visión + texto) |
| Anthropic Claude 3.5 Sonnet | 3.00 USD | 15.00 USD | Escritura avanzada, análisis largo, contexto 200k tokens |
| Modelo Local (Llama 3-70B self-hosted) | ~0 USD | ~0 USD | Alto volumen (>10M tokens/mes), datos sensibles, latencia predecible |
💰 Diferencial de Costes Crítico
DeepSeek V3 vs GPT-4o:
94.4% más barato
Input: 0.27 vs 2.50 USD | Output: 1.10 vs 10.00 USD
Gemini Flash vs GPT-4o:
97% más barato
Input: 0.075 vs 2.50 USD | Output: 0.30 vs 10.00 USD
Fuente: Precios oficiales enero 2025 - OpenAI, DeepSeek, Google
► Arquitectura de Routing Inteligente
Un router de modelos típico incluye:
- 1.Clasificador de complejidad: Analiza la consulta (longitud, keywords técnicas, embeddings de similitud) y asigna un score de complejidad 0-1
- 2.Decision tree: Basado en score + contexto (historial conversación, tipo de usuario) elige modelo
- 3.Fallback automático: Si modelo económico da respuesta de baja confianza, reintenta con modelo premium
- 4.Monitoreo continuo: Trackea accuracy por modelo para ajustar umbrales
Código Python: Router Básico con LiteLLM
# Instalación: pip install litellm
from litellm import Router
import os
# Configurar lista de modelos con prioridades y costes
model_list = [
{
"model_name": "gpt-4o",
"litellm_params": {
"model": "gpt-4o",
"api_key": os.getenv("OPENAI_API_KEY")
},
"model_info": {"cost": "high", "quality": "premium"}
},
{
"model_name": "gpt-3.5-turbo",
"litellm_params": {
"model": "gpt-3.5-turbo",
"api_key": os.getenv("OPENAI_API_KEY")
},
"model_info": {"cost": "medium", "quality": "good"}
},
{
"model_name": "deepseek-chat",
"litellm_params": {
"model": "deepseek/deepseek-chat",
"api_key": os.getenv("DEEPSEEK_API_KEY")
},
"model_info": {"cost": "low", "quality": "good"}
},
{
"model_name": "gemini-flash",
"litellm_params": {
"model": "gemini/gemini-1.5-flash",
"api_key": os.getenv("GEMINI_API_KEY")
},
"model_info": {"cost": "very-low", "quality": "medium"}
}
]
# Inicializar router
router = Router(
model_list=model_list,
routing_strategy="cost-based-routing", # Prefiere modelos más baratos
num_retries=2
)
def classify_query_complexity(query: str, conversation_history: list = None) -> str:
"""
Clasifica complejidad de una consulta
Returns: 'low', 'medium', 'high'
"""
# Heurísticas simples (en producción, usar modelo ML)
query_lower = query.lower()
# Keywords que indican alta complejidad
complex_keywords = [
"explain why", "analyze", "compare", "complex", "detailed",
"step by step", "reasoning", "debug", "optimize"
]
# Keywords simples
simple_keywords = [
"what is", "define", "summarize", "translate", "list"
]
# Longitud de la consulta
token_count = len(query.split())
# Scoring
complexity_score = 0
if any(kw in query_lower for kw in complex_keywords):
complexity_score += 2
if any(kw in query_lower for kw in simple_keywords):
complexity_score -= 1
if token_count > 100:
complexity_score += 1
elif token_count < 20:
complexity_score -= 1
if conversation_history and len(conversation_history) > 10:
complexity_score += 1 # Conversaciones largas necesitan contexto
# Clasificar
if complexity_score >= 2:
return 'high'
elif complexity_score ► Caso Real: Cliente Servicios Financieros ($45k → $12k)
Un cliente de servicios financieros procesaba consultas de análisis de inversiones con 100% GPT-4. Después de implementar routing inteligente:
❌ ANTES (Sin Routing)
✅ DESPUÉS (Con Routing)
💡 Key insight del caso: El 70% de las consultas eran clasificaciones de riesgo básicas o búsquedas de datos que no requerían razonamiento profundo. Solo el 30% (análisis de portafolios complejos, regulaciones) justificaban GPT-4. La satisfacción del cliente se mantuvo en 8.5/10 (sin cambios).
⚠️ Consideraciones Críticas:
- •Tunning del clasificador: Requiere 2-3 semanas de A/B testing para ajustar umbrales sin degradar calidad.
- •Monitoreo continuo: Medir accuracy por modelo semanalmente. Degrada confidence score si accuracy cae
- •Fallback mechanism: Si DeepSeek da respuesta de baja confianza, reintenta con GPT-4 (añade ~5% overhead pero evita respuestas malas).
- •Vendor lock-in: Diversificar proveedores reduce risk pero aumenta complejidad de gestión de claves/billing.
✅ Ahorro potencial esperado: 40-87% reducción de costes dependiendo de tu mix de complejidad de consultas. Mejor ROI para aplicaciones con >50% consultas simples/medianas. Implementación: 2-4 semanas. Payback: inmediato si >10k consultas/mes.
¿Gastas +$15k/mes en APIs LLM?
Implemento estas 10 técnicas en tu infraestructura AWS/Azure en 2-3 semanas. Clientes reales han reducido $45k/mes → $12k/mes (73% ahorro) con caching + compression + routing inteligente.
Técnicas Adicionales #5-#10 (Resumen Ejecutivo)
6. Técnicas Adicionales #5-#10: Resumen Ejecutivo con Implementación
Las técnicas #1-#4 cubren las victorias de mayor impacto (caching, compression, routing). Las siguientes 6 técnicas son complementarias y pueden añadir ahorros adicionales del 10-40% según tu arquitectura específica.
5RAG Optimization (70% Reducción de Tokens de Contexto)
Qué es: Optimizar sistemas RAG para recuperar SOLO los chunks más relevantes en lugar de enviar documentos completos. Incluye chunking inteligente, reranking con cross-encoders, y filtrado por umbral de similitud.
Caso real (Koombea): Bufete legal procesando contratos de 50 páginas. Antes: envío completo del contrato (15,000 tokens). Después: retrieval de 3 cláusulas relevantes (600 tokens). Coste: 0.006 USD → 0.0042 USD por consulta (30% ahorro).
# Optimizar RAG con reranking
from langchain.vectorstores import Pinecone
from langchain.embeddings import OpenAIEmbeddings
vectorstore = Pinecone.from_documents(docs, OpenAIEmbeddings(), index_name="idx")
retriever = vectorstore.as_retriever(
search_kwargs={"k": 3} # Solo top 3 chunks (no 10)
)
relevant_docs = retriever.get_relevant_documents(query)
context = "\n".join([doc.page_content for doc in relevant_docs])
# Enviar solo context reducido al LLM Cuándo usar: Document QA, knowledge bases, compliance docs. Ahorro esperado: 30-70% tokens de contexto.
6Quantization (75% Reducción de Requisitos de GPU)
Qué es: Reducir precisión numérica de modelos self-hosted de FP32 (32-bit) a INT4 (4-bit). Reduce memoria 75% y aumenta throughput 50% con pérdida de accuracy
7Batch Processing (50% Descuento Automático)
Qué es: OpenAI y Anthropic ofrecen 50% de descuento en llamadas asíncronas (completion
8Fine-Tuning vs Few-Shot (Break-even >50M Tokens/Mes)
Qué es: Entrenar modelo custom elimina necesidad de ejemplos few-shot en cada prompt (ahorro 500-1,000 tokens por consulta). Coste upfront: 2-20 USD fine-tuning.
Análisis ROI: Break-even típico ~15,000 consultas grandes/mes (3,000+ tokens cada una). Fine-tuned model usa prompts mínimos (50 tokens) vs few-shot (1,000 tokens).
Cuándo usar: Alto volumen (>50M tokens/mes), tarea consistente y bien definida, datos de entrenamiento disponibles (1,000+ ejemplos). Ahorro: Variable, 20-60% para casos de uso específicos.
9Output Token Control (33% Reducción Costes de Salida)
Qué es: Recordatorio crítico: output tokens cuestan 3-5x más que input. Usar max_tokens, instrucciones explícitas de longitud, structured outputs para limitar salida.
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Resume en 100 palabras máximo"}],
max_tokens=150, # Hard limit previene costes descontrolados
temperature=0.3 # Menor temp = respuestas más concisas
)
Cuándo usar: SIEMPRE. Victoria rápida (5 minutos implementación). Ahorro: 10-33% en costes de output.
10Self-Hosting vs API (Break-even ~15-20k USD/Mes)
Análisis de costes: Self-hosting mínimo: 125,000-190,000 USD/año (servidores, storage, ingenieros MLOps). High-end: 70,000+ USD/mes (8-16 H100 GPUs 24/7).
Break-even típico: Si gastas >15-20k USD/mes en APIs, self-hosting puede tener sentido. ROI payback: 3-6 meses para usuarios de alto volumen. Considera: compliance (datos sensibles), latencia predecible, control total.
Cuándo considerar: >10M tokens/día, requisitos de compliance estrictos, latencia crítica (
💡 Estrategia de implementación recomendada: Empieza con técnicas #1-#4 (caching, compression, routing, output control) para victoria rápida de 50-70% ahorro. Luego evalúa técnicas #5-#10 basado en tu arquitectura específica y volumen. NO implementar todas simultáneamente (imposible debuggear si algo falla).
🎯 Conclusión: Tu Plan de Acción para Reducir Costes LLM 60-70% en 30 Días
Has aprendido las 10 técnicas verificadas que pueden reducir tus costes LLM del 40% al 87% según tu arquitectura y volumen. Pero la información sin ejecución no vale nada. Aquí está tu roadmap exacto para los próximos 30 días:
📅 Roadmap de Implementación 30 Días
Semana 1: Quick Wins (40-50% Ahorro Esperado)
- • Día 1-2: Implementa Output Token Control (max_tokens) - 1 hora, 10-33% ahorro inmediato
- • Día 3-5: Setup Prompt Caching (Anthropic o OpenAI) - 40-90% ahorro en contextos repetitivos
- • Día 6-7: Análisis de logs: identificar query patterns para preparar routing
Semana 2-3: Model Routing (Ahorro Acumulado 60-70%)
- • Día 8-14: Desarrollo clasificador de complejidad + setup LiteLLM proxy
- • Día 15-21: A/B testing con 20% tráfico, ajuste de umbrales, implementación fallback
Semana 4: Técnicas Complementarias (Ahorro Acumulado 70-80%)
- • Día 22-25: Semantic Caching (si alta repetición) o LLMLingua (si prompts largos)
- • Día 26-28: Batch API para tareas async
- • Día 29-30: Monitoreo completo, documentación, handoff a equipo
✅ Qué Hacer AHORA (Próximas 24h)
- 1.Exporta logs de última semana: identifica top 10 queries más frecuentes
- 2.Añade max_tokens a TODAS tus llamadas actuales (victoria de 5 minutos)
- 3.Setup Helicone o LangSmith para baseline metrics (coste actual por query)
- 4.Usa el ROI Calculator de arriba para estimar tus ahorros potenciales
❌ Qué NO Hacer
- ✗Implementar todas las 10 técnicas simultáneamente (imposible debuggear)
- ✗Migrar 100% tráfico a nueva arquitectura sin A/B testing (riesgo alto)
- ✗Optimizar sin monitoring (no sabrás si funcionó)
- ✗Self-hosting si gastas
⚡ Recordatorio Crítico:
El gasto global en GenAI está creciendo 76.4% interanual según Gartner. Si no optimizas AHORA, tus costes se duplicarán en 12-18 meses a medida que escales. Cada semana que esperas pierdes miles de dólares en optimizaciones fáciles.
He implementado estas técnicas en docenas de clientes en los últimos 18 meses, desde startups Series A hasta empresas mid-market procesando 10M+ consultas mensuales. El patrón es siempre el mismo: 40-70% de ahorro en las primeras 4 semanas enfocándote en las 4 técnicas principales (caching, routing, compression, output control).
Si tienes dudas sobre qué técnicas priorizar para tu caso específico, o necesitas ayuda implementando la arquitectura completa, contáctame. Mi especialidad es analizar tu stack actual, identificar las 3-5 optimizaciones de mayor impacto, e implementarlas en
¿Necesitas ayuda optimizando costes de infraestructura IA/ML?
Implemento estrategias de optimización de costes con ROI medible. Auditoría gratuita de tu stack actual.
Solicitar Auditoría Gratuita →
Sobre el Autor
Abdessamad Ammi es CEO de BCloud Solutions y experto senior en IA Generativa y Cloud Infrastructure. Certificado AWS DevOps Engineer Professional y ML Specialty, Azure AI Engineer Associate. Ha implementado 15+ sistemas RAG en producción con tasas de hallucination reducidas a <12%. Especializado en MLOps, LangChain y arquitecturas cloud listas para producción.


