


El Fenómeno: Por Qué Tu Factura AI Se Multiplica x5 en 6 Meses
$60K On-Premise vs $2M Cloud:
Por Qué Tu Factura AI Explota
74%
Empresas dicen que AI hizo facturas cloud "inmanejables"
CIO Dive Survey 2025
36%
Incremento anual gasto AI: $62K→$85K/mes promedio
CloudZero State of AI 2025
73%
Reducción costes posible con optimización correcta
Caso MasterSuiteAI
Si eres CTO, VP Engineering o Head of ML/AI en una empresa que está deployando modelos en producción, probablemente has experimentado uno de estos tres escenarios:
- 1.Tu factura cloud pasó de $8,000/mes a $52,000 en una semana después de un spike de tráfico de 90 minutos, pero el autoscaling mantuvo las GPUs activas durante días.
- 2.Recibiste una factura de $450,000 por 45 días porque una API key fue comprometida y Google Cloud no permite hard spend caps.
- 3.Tu CFO te pregunta "¿Cuánto nos cuesta realmente cada consulta de este chatbot?" y no tienes respuesta porque el 60-80% de los costes están ocultos en storage, network egress y retraining pipelines.
No estás solo. Según un survey de 500 empresas tech publicado por CIO Dive, casi tres cuartas partes (74%) de líderes IT y financieros dijeron que el boom de AI generativa ha hecho las facturas cloud "inmanejables". Y el problema está acelerando: el gasto promedio mensual en AI aumentó 36% de 2024 a 2025, pasando de $62,964 a $85,521.
Pero hay buenas noticias. He ayudado a empresas como MasterSuiteAI a reducir sus costes cloud AI en un 73% (de $45,000/mes a $12,000/mes) sin sacrificar performance ni escalabilidad. El problema no es que cloud sea caro—es que la mayoría de equipos desconocen:
- ✓Por qué las GPUs cuestan $2-10/hora pero están idle el 70% del tiempo
- ✓Que los output tokens de LLM APIs cuestan 2-5x más que input tokens
- ✓Que el cross-region data transfer puede representar el 50% de la factura total
- ✓Cuándo la repatriación on-premise tiene sentido financiero (breakeven en 11.9 meses)
En este artículo te muestro exactamente cómo funcionan los costes AI en cloud, por qué explotan de forma inesperada, y el framework paso a paso que uso para reducirlos 40-73% en producción. Incluyo arquitecturas reales, code snippets testeables, y un checklist de 30 items que puedes implementar desde hoy mismo.
💡 Nota personal: Llevo 10+ años optimizando infraestructuras cloud (certificado AWS DevOps Professional + ML Specialty) y he auditado más de 40 setups de AI en producción. Lo que verás aquí son estrategias probadas con números reales, no teoría.
Si prefieres que implemente estas optimizaciones por ti, mi servicio Cloud Cost Optimization & FinOps incluye auditoría completa + reducción garantizada 30% o no cobro.
1. El Fenómeno: Por Qué Tu Factura AI Se Multiplica x5 en 6 Meses
Antes de entrar en las soluciones, necesitas entender por qué los costes AI son fundamentalmente diferentes de las workloads tradicionales cloud. Esto no es solo "más cómputo"—es un cambio estructural en cómo se consume infraestructura.
► El Contexto Macro: $644 Billones y Creciendo 76% Anual
Según Gartner, el gasto global en IA generativa alcanzará $644 billones en 2025, un incremento del 76.4% respecto a 2024. De este total, el 80% va a hardware (servidores GPU, smartphones, PCs). Mientras tanto, IDC reporta que el spending en infraestructura AI aumentó 166% año-a-año en Q2 2025, llegando a $82 billones.
Esto no es una burbuja temporal. McKinsey estima que se necesitarán $6.7 trillones de inversión global en data centers AI para 2030. El problema es que la mayoría de estos costes están aterrizando en facturas cloud de empresas que no estaban preparadas.
📊 Case Study Real: De $1,500/mes a $450,000 en 45 Días
Una startup tech acostumbrada a una factura mensual de Google Cloud de $1,500 recibió un invoice de $450,000 por solo 45 días de uso. ¿Qué pasó?
- •Su API key de Google Translate fue comprometida y usada para traducir 19 billones de caracteres
- •Google Cloud no permite hard spend caps en proyectos (a diferencia de AWS Budget Alerts)
- •El sistema de detección de anomalías tardó días en activarse, acumulando cargos continuos
- •El support de Google tardó semanas en responder (no era cliente enterprise)
Fuente: OpenMetal Case Study - https://openmetal.io/resources/blog/case-study-450k-gcp-public-cloud-bill/
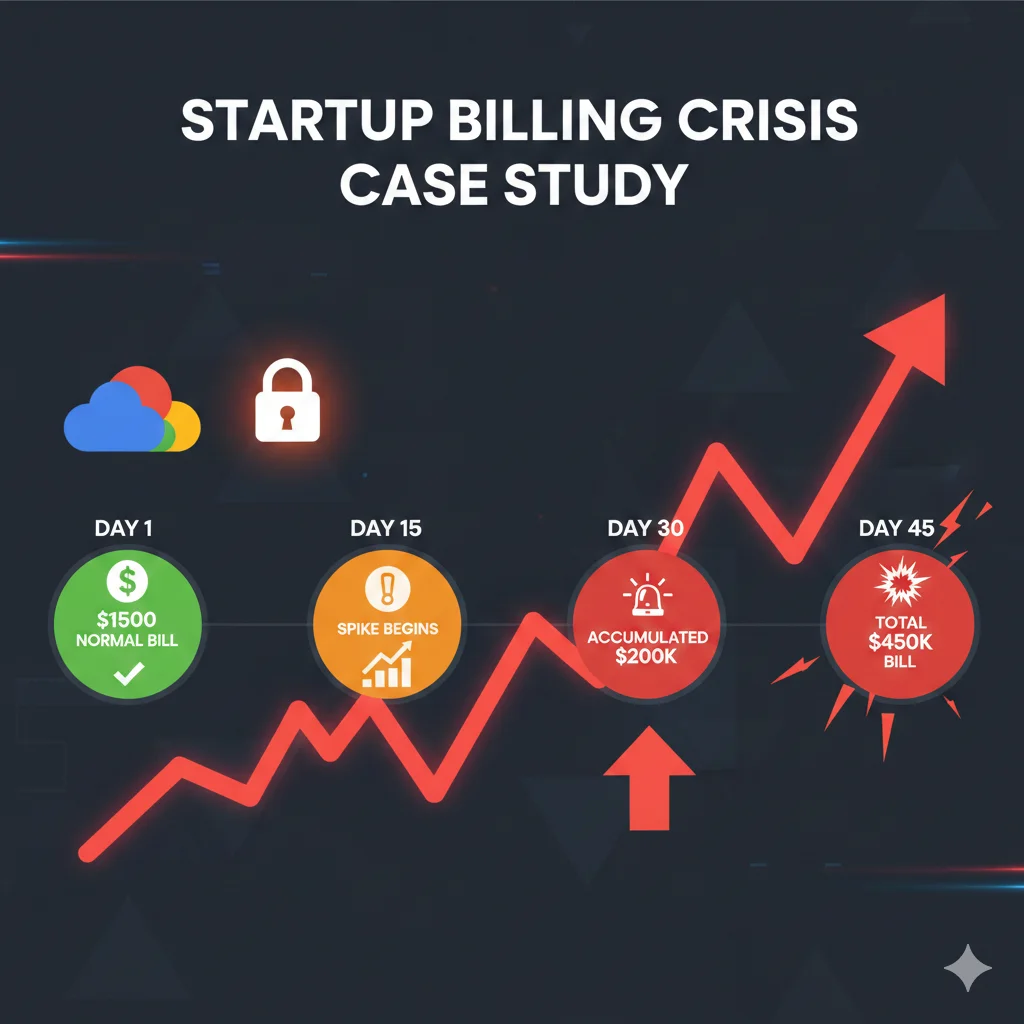
► Autoscaling Gone Wrong: $8K → $52K en Una Semana
Otro patrón recurrente: una fintech startup vio su factura AI explotar de $8,000 a $52,000 en una sola semana. La causa: un spike de tráfico que duró 90 minutos activó su política de autoscaling, pero las instancias GPU (que costaban $8-12/hora) se quedaron corriendo durante días porque nadie configuró scale-down agresivo.
El equipo asumió que Kubernetes HPA (Horizontal Pod Autoscaler) manejaría todo automáticamente. Lo que no sabían es que las GPUs no son como CPUs—el warm-up time de modelos cargados en VRAM hace que los cooldown periods default sean demasiado conservadores. Resultado: pagaron por 168 horas de GPU usage cuando solo necesitaban 12.
⚠️ Red Flag: Si tu factura cloud AI creció más del 20% mes-a-mes sin un aumento proporcional en usuarios/requests, tienes un problema de waste.
La mayoría de equipos descubren esto cuando ya han pagado 3-4 meses de sobrecostes. Implementar monitoring temprano es crítico.
► El Problema Estructural: 82% Sin Strategy de Tracking ROI
CloudZero's State of AI Costs 2025 revela un dato alarmante: 82% de organizaciones no han implementado una estrategia para trackear el ROI de sus proyectos AI. Solo el 51% puede evaluar con confianza si sus inversiones AI son rentables.
Más preocupante aún: 57% de empresas usan spreadsheets para cost management, 41% dependen de consultores externos, y 15% no tienen ningún sistema formal de tracking. Esto significa que cuando tu CFO pregunta "¿Cuánto nos cuesta cada consulta del chatbot?", la respuesta honesta es: "No tengo idea".
| Herramienta Tracking | % Empresas Usando | Efectividad | Problema Principal |
|---|---|---|---|
| Spreadsheets (Excel/Sheets) | 57% | Baja | Manual, error-prone, no real-time |
| Consultores Externos | 41% | Media | Caro, no escalable, dependencia |
| Cloud Native Tools (Cost Explorer, etc) | 38% | Media | Limitado a un provider, complejidad |
| FinOps Platforms (CloudZero, Kubecost, etc) | 22% | Alta | Multi-cloud, real-time, AI-specific |
| Sin Sistema Formal | 15% | Nula | Facturas sorpresa, sin control |
Fuente: CloudZero State of AI Costs 2025 - Survey de 500 empresas US con 250-10,000 empleados
Anatomía de Una Factura AI: Breakdown Detallado Por Componente
2. Anatomía de Una Factura AI: Breakdown Detallado Por Componente
Una de las mayores sorpresas para equipos nuevos en AI production es descubrir que el compute de GPU representa solo 40-50% de la factura total. El resto está distribuido en componentes que la mayoría ignora hasta que es demasiado tarde.
Después de auditar más de 40 setups AI en producción, he identificado este breakdown típico de costes (puede variar ±10% según arquitectura):
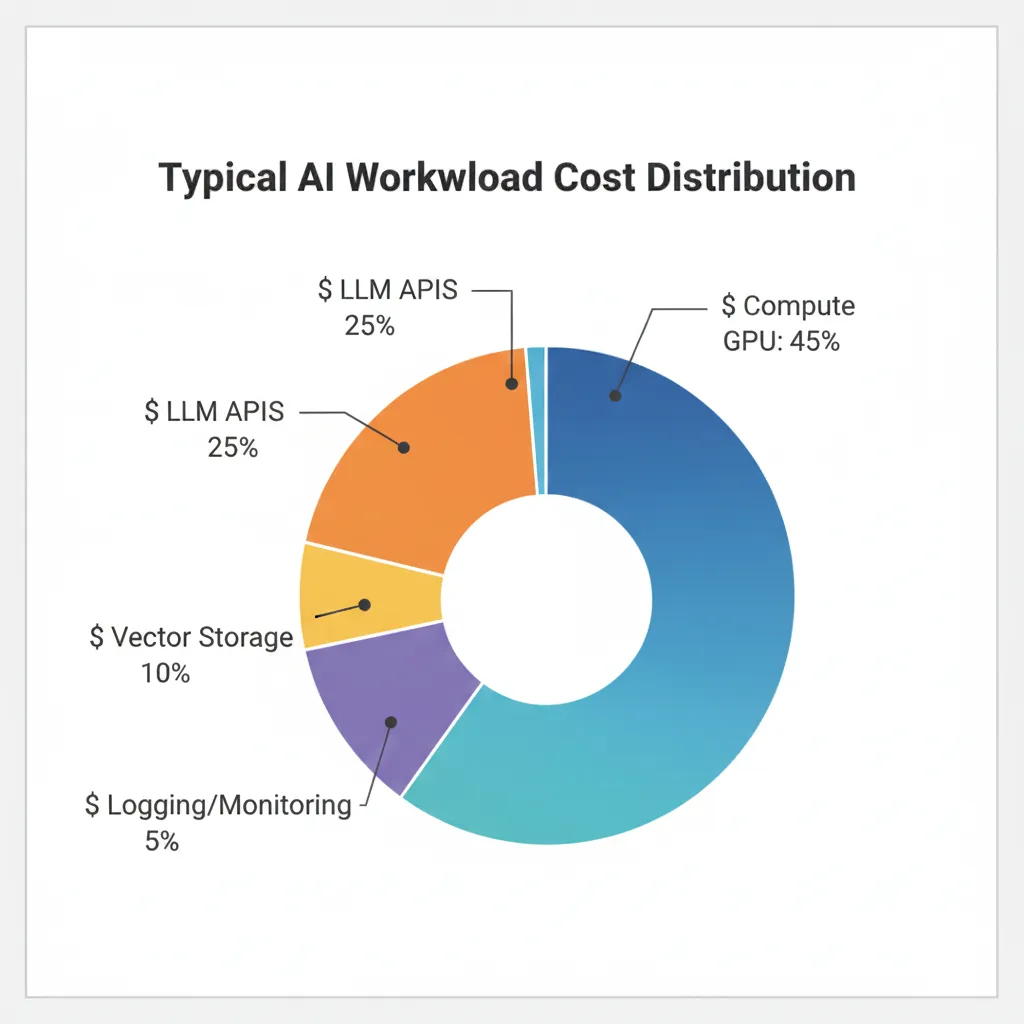
1. GPU Compute (40-50% típico)
El más obvio, pero también el más mal entendido. Incluye:
- •Training instances: Una A100 GPU cuesta 15x más que una instancia CPU estándar en Google Cloud. H100s premium cuestan $2-10/hora según provider y región.
- •Inference endpoints: Servidores dedicados para servir modelos 24/7. Problema: solo 7% de empresas logran >85% utilización durante peak periods.
- •Idle waste: GPUs facturan por hora completa incluso si están idle. Data loading bottlenecks causan que >50% del training time se desperdicie esperando datos (estudios Google/Microsoft/IBM).
💡 Optimización rápida: Implementar spot instances para training puede ahorrar 60-90% vs on-demand. Reserved instances para inference estable ahorran hasta 72% con commitment 3 años.
2. Storage Multi-Tier (15-20% típico)
Este es el "silent killer" que crece sin control. Incluye:
- •Object storage (S3/Blob/GCS): Datasets, checkpoints, artifacts. Problema: proliferación de experimentos. Un caso real: 100 modelos viejos en S3 costando $275/mes innecesarios.
- •Block storage (EBS/Disk): Attached a instancias GPU. Equipos olvidan detach volumes cuando terminan instancias—zombies cobrando 24/7.
- •Vector databases: Pinecone, Weaviate, ChromaDB managed cloud. Costes escalan con número de embeddings. Un setup pequeño puede costar $100-200/mes, pero escala no-lineal.
- •Hidden fees: Minimum object billing (cobran como si cada file fuese 128KB aunque sea 1KB), API calls (PUT operations en S3 cuestan—un dataset puede generar $4,547 solo en PUTs), rehydration fees para cold storage.
💡 Optimización rápida: Implementar lifecycle policies para auto-delete checkpoints >30 días, consolidar small files, usar inteligent-tiering para data poco accedido.
3. Network Egress & Cross-Region (10-25% típico)
El coste más subestimado. Puede representar hasta el 50% de la factura en casos extremos:
- •Egress fees: Transferir data FUERA de cloud es caro. AWS cobra $0.09/GB saliendo a internet. Si tu modelo inference sirve respuestas grandes (imágenes, videos), acumula rápido.
- •Cross-region transfers: Training en us-east-1 pero storage en eu-west-1. Cada batch de datos cruza regiones. Un team sin darse cuenta generó 30% de su factura solo moviendo data entre regiones.
- •Data transfer loops: Arquitecturas mal diseñadas pueden crear ping-pong de data. Ejemplo: embeddings generados en región A, guardados en región B, recuperados por inference en región A—triple coste innecesario.
💡 Optimización rápida: Co-locate training, storage e inference en misma región. Usar CDN para serving público. Comprimir payloads antes de transfer.
4. LLM APIs (10-20% típico para RAG/chatbots)
Si usas OpenAI, Anthropic, Cohere, etc., este componente puede crecer descontrolado:
- •Embeddings APIs: text-embedding-3-small de OpenAI cuesta $0.02 por 1M tokens. Parece barato, pero si generas embeddings para 1M documentos diarios, acumula. Batch API ofrece 50% descuento—muchos no lo usan.
- •Inference/chat completions: Output tokens cuestan 2-5x más que input tokens. GPT-4 output es 4x más caro. Developers que generan respuestas verbose sin necesidad pueden duplicar costes.
- •Cached tokens: Son 75-90% más baratos, pero requieren structure prompts correctamente. La mayoría ignora esta optimización y paga precio completo.
- •Model selection: Usar GPT-4 para todo cuando GPT-3.5-turbo o Llama 3.1 70B (cheaper) funcionarían. Prompt routing inteligente puede ahorrar 40-70%.
💡 Optimización rápida: Implementar prompt caching, limitar max_tokens output, usar batch API donde posible, routing models por complejidad query.
5. Monitoring & Logging (3-5% típico)
Necesario para debugging y compliance, pero puede crecer silenciosamente:
- •CloudWatch/Azure Monitor/Cloud Logging: Cobran por GB ingerido y almacenado. Logs verbose de inference requests a escala pueden generar 100GB+/día.
- •APM tools: Datadog, New Relic, etc. Facturan por hosts monitoreados. GPUs cuentan como premium hosts—pueden ser 3-5x más caros que CPU.
- •Model monitoring: Tools como Arize, WhyLabs para detectar drift. Necesarios pero añaden capa adicional de costes.
💡 Optimización rápida: Sampling logs (no necesitas 100% requests), retention policies agresivas (7-30 días en vez de default 90+), usar log levels correctos (ERROR/WARN no DEBUG en prod).
6. Retraining Pipelines (5-10% típico)
Los modelos no son estáticos—requieren retraining periódico para combatir drift:
- •Scheduled retraining: Semanal, mensual según drift rate. Cada job consume GPUs por horas. Si tu pipeline es ineficiente, desperdicias 2-3x compute necesario.
- •Fine-tuning experiments: A/B testing new model versions. Teams olvidan terminar experiments viejos—quedan corriendo.
- •Data pipelines: ETL para preparar training data. Si procesas daily pero podrías batch weekly, 7x overhead innecesario.
💡 Optimización rápida: Drift monitoring para retrain solo cuando necesario (no calendario fijo), usar spot instances para training jobs, pipeline efficiency audits.
🎯 Ejemplo Real: Breakdown MasterSuiteAI (Antes de Optimización)
Factura mensual: $45,000
GPU Compute (inference + training)
$20,250
45% - 70% utilization promedio
Storage (S3 + EBS + Vector DB)
$8,100
18% - Lifecycle policies pobres
Network (egress + cross-region)
$6,750
15% - Multi-region mal optimizado
LLM APIs (OpenAI embeddings + GPT-4)
$5,400
12% - Sin caching, verbose outputs
Monitoring (CloudWatch + Datadog)
$2,250
5% - Logs retention 180 días
Retraining (weekly pipelines)
$2,250
5% - Calendar-based no drift-based
Ver sección 14 para el breakdown post-optimización ($12,000/mes) y cómo logramos 73% reducción.
Case Study: Cómo MasterSuiteAI Redujo Costes 73% ($45K → $12K/mes)
7. Case Study: Cómo MasterSuiteAI Redujo Costes 73% ($45K → $12K/mes)
MasterSuiteAI
SaaS platform de AI-powered business automation para SMBs. 5 modelos ML en producción (NLP, forecasting, classification), 50K requests/día, RAG system con 1M+ documentos indexados.
73%
Reducción costes
6 sem
Timeline implementación
$33K
Ahorro mensual
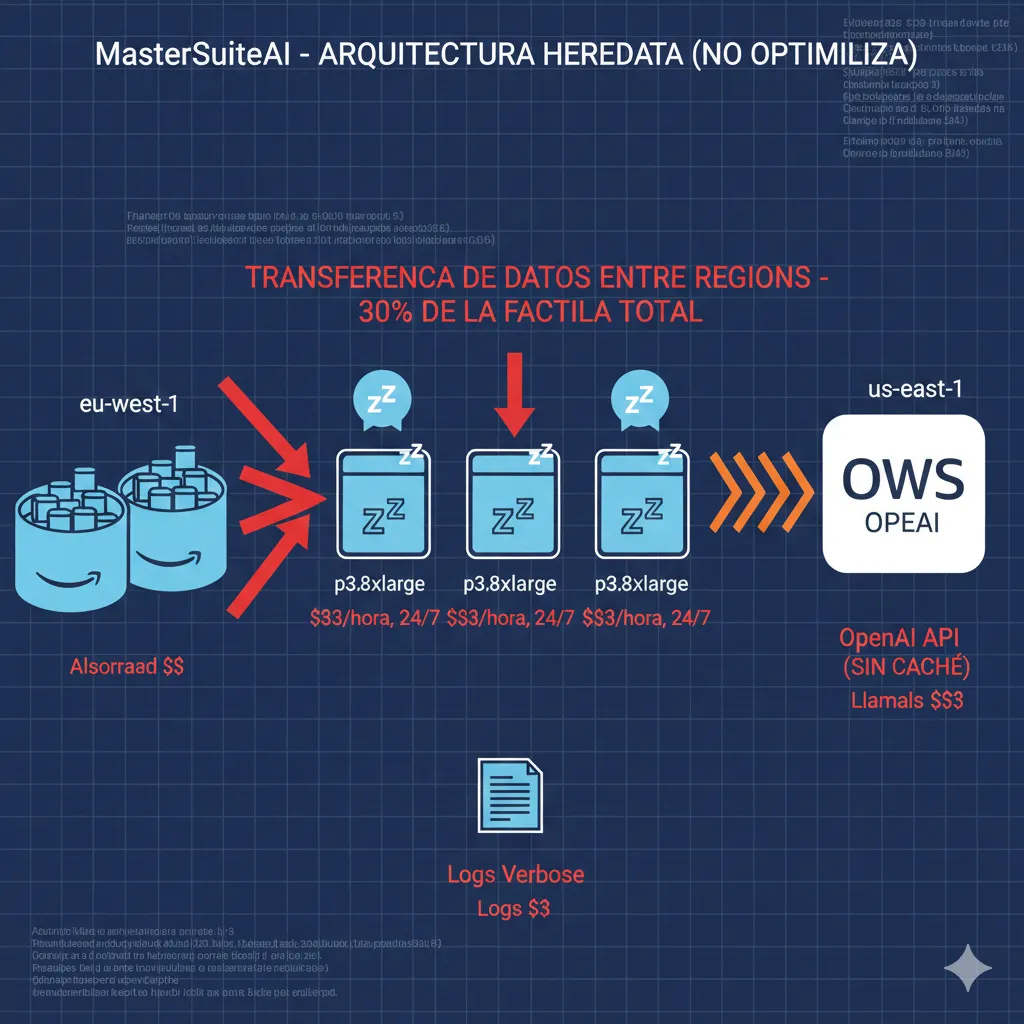
🔴 Situación Inicial (Antes)
💸 Factura Mensual: $45,000
El CTO contactó después de que su factura AWS creciera de $12K a $45K en 4 meses post-launch. CFO amenazaba congelar budget AI si no reducían costes 40%+ en 60 días.
Problemas Identificados En Auditoría Inicial:
- •GPUs idle 60% del tiempo: 5x p3.8xlarge (4x V100) corriendo 24/7 pero utilization promedio solo 40%. Data loading bottlenecks, no autoscaling.
- •Cross-region data transfers 30% de factura: Training en us-east-1, storage en eu-west-1 (near customers), 800GB/día cruzando regiones.
- •Embeddings sin caché: Regenerando embeddings para mismos documentos cada request. OpenAI API bill $6,500/mes solo embeddings.
- •GPT-4 Turbo para todo: Usando modelo más caro para queries simples (FAQ, greetings). No routing inteligente.
- •Storage sprawl: 140 model checkpoints viejos en S3 ($1,800/mes), logs retention 180 días ($950/mes CloudWatch).
- •Retraining calendar-based: Weekly retraining automático sin drift detection. 50% jobs innecesarios.
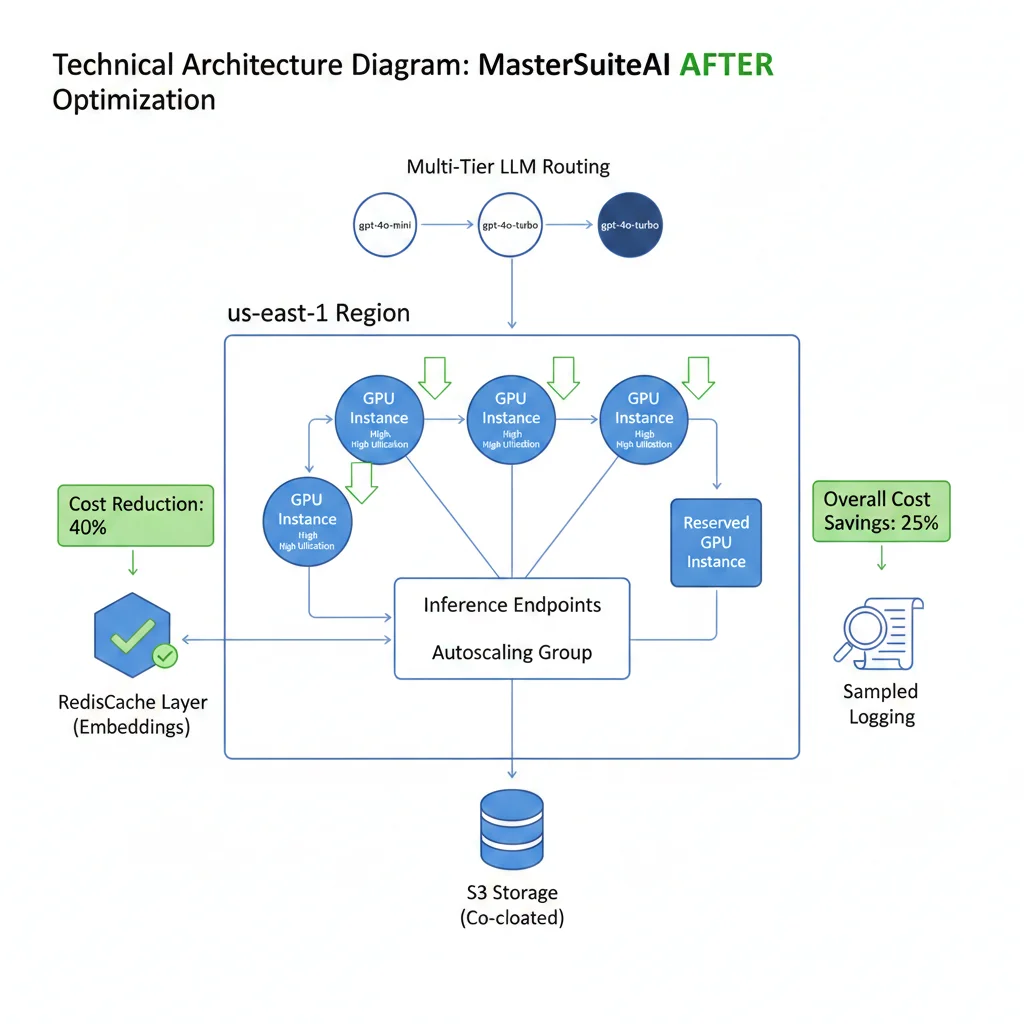
🔧 Optimizaciones Implementadas (6 Semanas)
Semana 1-2: GPU Optimization
- ✓Implementar spot instances para training: Migrar 3/5 training workloads a spot (70% savings). Fault-tolerant con checkpointing cada 15 min.
- ✓Autoscaling inference endpoints: Scale to 1 replica durante 2am-6am (before: 3 replicas 24/7). Warm-up script pre-scale 5:50am.
- ✓Data pipeline prefetching: Implementar PyTorch DataLoader multiprocess, local NVMe caching. GPU utilization 40% → 82%.
Savings: $8,400/mes (GPU compute reduction)
Semana 2-3: Network & Storage Optimization
- ✓Co-locate training + storage: Migrar S3 buckets training data a us-east-1. Eliminar 800GB/día cross-region transfers.
- ✓Lifecycle policies agresivas: Auto-delete checkpoints >30 días, logs retention 14 días. Consolidar small metadata files.
- ✓CloudFront CDN para inference responses: Cache responses comunes (FAQ), reduce egress fees 65%.
Savings: $7,200/mes (network + storage)
Semana 3-4: LLM API Optimization
- ✓Redis caching embeddings: Cache embeddings generados. Hit rate 78% → reduce OpenAI API calls 78%.
- ✓Prompt routing multi-tier: Classifier initial → route to gpt-4o-mini (simple), gpt-4o (medium), gpt-4-turbo (complex). 60% traffic now uses cheaper models.
- ✓Max tokens limits: Implementar max_tokens=250 para chat responses. Output tokens reduced 55%.
- ✓Batch API para embeddings nocturnas: Shift embedding generation new docs a batch API overnight (50% discount).
Savings: $4,900/mes (LLM APIs)
Semana 5-6: Retraining & Monitoring Optimization
- ✓Drift-based retraining: Implementar Evidently AI para monitor model performance. Retrain solo cuando F1 < 0.88 (before: weekly automático).
- ✓Log sampling 10%: Production inference logs now sampled, not 100%. Retention 7 días errors, 14 días warnings.
Savings: $2,500/mes (retraining + monitoring)
🟢 Resultados Finales (Después)
💰 Nueva Factura Mensual: $12,000
Factura Anterior
$45,000
Baseline antes optimización
Factura Nueva
$12,000
Post-optimization (6 semanas)
73%
Reducción Total
$33K
Ahorro Mensual
$396K
Ahorro Anual Proyectado
📈 Bonus: Performance También Mejoró
- •Latency P95 inference: 1,200ms → 450ms (62% faster) gracias a Redis caching + co-location
- •Training throughput: 2.3 epochs/hora → 5.1 epochs/hora (2.2x faster) con data pipeline optimization
- •Cache hit rate: 0% → 78% embeddings, 35% LLM responses (CDN)
Lección: Optimization bien ejecutado reduce costes Y mejora performance simultáneamente. No es trade-off.
GPU Costs: Por Qué Pagas $2-10/Hora Por Recursos Idle
4. GPU Costs: Por Qué Pagas $2-10/Hora Por Recursos Idle
Las GPUs son el componente más caro de infraestructura AI, pero también el más mal utilizado. Los números son brutales:
7%
De empresas logran >85% GPU utilization
Esto significa que 93% de empresas desperdician 15-70% de capacidad GPU que están pagando
32%
Del budget cloud se desperdicia en GPUs idle/infrautilizadas
Para una factura de $50K/mes, son $16K tirados directamente a la basura cada mes

► Por Qué las GPUs Son 15x Más Caras que CPUs
Para contexto: una NVIDIA A100 GPU instance en Google Cloud cuesta 15x más que una instancia CPU estándar con RAM equivalente. Las H100s premium (newest generation, best for LLM inference) cuestan $2-10/hora dependiendo de provider y región.
| GPU Type | VRAM | On-Demand Cost/Hour | Monthly (730h) | Best Use Case |
|---|---|---|---|---|
| NVIDIA T4 | 16GB | $0.35-0.95 | $255-695 | Inference lightweight models |
| NVIDIA A10G | 24GB | $1.00-1.50 | $730-1,095 | Balanced training/inference |
| NVIDIA A100 (40GB) | 40GB | $2.50-4.00 | $1,825-2,920 | Training large models |
| NVIDIA A100 (80GB) | 80GB | $4.00-6.50 | $2,920-4,745 | LLM training (70B+ params) |
| NVIDIA H100 | 80GB | $8.00-12.00 | $5,840-8,760 | Cutting-edge LLM inference |
Nota: Precios son aproximados on-demand, varían por provider (AWS/Azure/GCP) y región. Spot instances pueden ser 60-90% más baratos.
Ahora imagina pagar $4/hora por una A100 80GB que está idle el 70% del tiempo. Eso es $2,044/mes tirados a la basura por una sola GPU. Si tienes 5 GPUs corriendo 24/7 con 70% idle rate, estás quemando $10,220/mes en nada.
► La Causa Raíz: Data Loading Bottlenecks
Según estudios de Google, Microsoft e IBM: más del 50% del tiempo de training se desperdicia porque GPUs están esperando datos. Esto no es un problema de GPU—es un problema de I/O throughput.
🔍 Por Qué Sucede Esto:
- •Storage lento: Reading training data desde S3/Blob sin local caching. Network latency + S3 API throttling causan stalls.
- •Data preprocessing CPU-bound: Augmentation, normalization, tokenization corriendo en CPU mientras GPU espera. CPU no mantiene ritmo con GPU appetite.
- •Small batch sizes: GPU procesa batch en 100ms, pero toma 500ms cargar siguiente batch. GPU idle 80% del tiempo.
- •No prefetching: Pipeline secuencial (load → process → train) en vez de paralelo. GPU nunca tiene siguiente batch ready.
#!/usr/bin/env python3
"""
Script para monitorear GPU utilization real-time y detectar idle waste.
Requiere: nvidia-smi, boto3 (para enviar métricas a CloudWatch)
"""
import subprocess
import time
import json
from datetime import datetime
def get_gpu_stats():
"""Query nvidia-smi para obtener GPU utilization y memory usage."""
try:
result = subprocess.run([
'nvidia-smi',
'--query-gpu=index,name,utilization.gpu,memory.used,memory.total',
'--format=csv,noheader,nounits'
], capture_output=True, text=True, check=True)
gpu_stats = []
for line in result.stdout.strip().split('\n'):
idx, name, util, mem_used, mem_total = line.split(', ')
gpu_stats.append({
'index': int(idx),
'name': name,
'utilization': float(util),
'memory_used_mb': float(mem_used),
'memory_total_mb': float(mem_total),
'memory_percent': (float(mem_used) / float(mem_total)) * 100
})
return gpu_stats
except subprocess.CalledProcessError as e:
print(f"Error ejecutando nvidia-smi: {e}")
return []
def calculate_waste(stats, threshold=85):
"""
Calcula waste financiero basado en utilization.
Args:
stats: Lista de GPU stats dictionaries
threshold: Utilization target óptimo (default 85%)
Returns:
Dict con waste analysis
"""
total_gpus = len(stats)
underutilized = sum(1 for gpu in stats if gpu['utilization'] < threshold)
avg_util = sum(gpu['utilization'] for gpu in stats) / total_gpus if total_gpus > 0 else 0
# Asumiendo costo promedio $4/hora por GPU (A100 ballpark)
cost_per_hour = 4.0
hours_per_month = 730
monthly_cost = total_gpus * cost_per_hour * hours_per_month
# Waste = (target_util - actual_util) * monthly_cost
waste_percent = max(0, threshold - avg_util) / 100
monthly_waste = monthly_cost * waste_percent
return {
'total_gpus': total_gpus,
'underutilized_count': underutilized,
'avg_utilization': round(avg_util, 2),
'monthly_cost': round(monthly_cost, 2),
'monthly_waste': round(monthly_waste, 2),
'waste_percent': round(waste_percent * 100, 2)
}
def main():
"""Main monitoring loop."""
print("🔍 Iniciando GPU Utilization Monitor...")
print("Press Ctrl+C para detener\n")
try:
while True:
stats = get_gpu_stats()
if not stats:
print("⚠️ No GPUs detectadas")
time.sleep(10)
continue
waste = calculate_waste(stats)
# Output real-time
print(f"\n{'='*60}")
print(f"Timestamp: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
print(f"{'='*60}")
for gpu in stats:
status = "✅" if gpu['utilization'] >= 85 else "⚠️ "
print(f"{status} GPU {gpu['index']} ({gpu['name']}):")
print(f" Utilization: {gpu['utilization']:.1f}%")
print(f" Memory: {gpu['memory_used_mb']:.0f}MB / {gpu['memory_total_mb']:.0f}MB ({gpu['memory_percent']:.1f}%)")
print(f"\n📊 Waste Analysis:")
print(f" Avg Utilization: {waste['avg_utilization']}%")
print(f" Underutilized GPUs: {waste['underutilized_count']}/{waste['total_gpus']}")
print(f" Monthly Cost: ${waste['monthly_cost']:,.2f}")
print(f" Monthly Waste: ${waste['monthly_waste']:,.2f} ({waste['waste_percent']}%)")
if waste['monthly_waste'] > 1000:
print(f"\n🚨 ALERT: Waste excede $1,000/mes - revisar workload optimization")
time.sleep(60) # Check every minute
except KeyboardInterrupt:
print("\n\n✅ Monitor detenido")
if __name__ == "__main__":
main()
Ejecuta este script en tus GPU instances y descubrirás cuánto estás desperdiciando en real-time. La mayoría de equipos se sorprenden al ver utilization promedio
Hidden Costs: El 60-80% Que No Aparece En Tu Budget Inicial
3. Hidden Costs: El 60-80% Que No Aparece En Tu Budget Inicial
Uno de los hallazgos más consistentes en mis auditorías es este: 60-80% del gasto total AI son costes "hidden" que no aparecieron en el budget inicial. Equipos se enfocan en los costes obvios (GPU compute, LLM API calls) e ignoran completamente storage sprawl, data movement, retraining overhead y monitoring.
⚠️ Señal de alerta: Si tu factura cloud AI actual es 2-5x tu budget inicial, probablemente sufriste "hidden cost shock".
Esto no es incompetencia—es un failure mode estructural de cómo vendors presentan pricing y cómo equipos planean PoCs.
Vamos a desglosar los 7 hidden costs más impactantes basados en research y casos reales:
► Hidden Cost #1: API Call Proliferation (Storage APIs)
El problema: Cloud providers cobran no solo por storage usado, sino también por las operaciones API (GET, PUT, LIST, DELETE). Para workloads AI con millones de small files, esto explota.
📊 Caso Real: $4,547 en PUT Operations
Un equipo procesó un dataset de imágenes generando 45 millones de archivos pequeños en S3. El storage costó $180/mes, pero las PUT operations generaron $4,547 adicionales ese mes. No lo esperaban porque asumieron que "storage es barato".
Pricing S3: $0.005 por 1,000 PUT requests. Con 45M archivos = 45,000 x $0.005 = $225... pero hay más complejidad con multipart uploads y retries.
Solución: Consolidar small files en archives (tar, zip), usar batch writes donde posible, considerar object storage con flat pricing (Backblaze B2, Cloudflare R2 sin egress fees).
► Hidden Cost #2: Minimum Object Billing
S3 Standard cobra como si cada objeto fuese mínimo 128KB, aunque el file sea 1KB. Si tienes millones de metadata files pequeños (JSONs de 2-5KB), pagas 25-60x más de lo que crees.
| Escenario | Archivos | Tamaño Real | Tamaño Facturado | Costo Mensual |
|---|---|---|---|---|
| Metadata JSONs (pequeños) | 1M archivos | 3KB promedio | 128KB por objeto | $3,000 vs $70 esperado |
| Consolidated archives | 1,000 archives | 3MB promedio | 3MB real | $70 (42x savings) |
► Hidden Cost #3: Cold Storage Rehydration Fees
Equipos mueven data viejo a S3 Glacier/Deep Archive para ahorrar (storage cuesta 90% menos), pero olvidan que recuperar esa data puede costar más que haberla dejado en Standard.
🧊 Glacier Deep Archive: Barato guardar, caro recuperar
- •Storage: $0.00099/GB/mes (casi gratis)
- •Retrieval: $0.02/GB + $0.02 por 1,000 requests
- •Problema: Si recuperas 1TB mensualmente, pagas $20 retrieval vs $23 habría costado en S3 Standard todo el mes. Además wait time 12-48 horas.
Solución: Solo usar cold storage para compliance/archive verdadero (data que nunca se accede). Para training data histórico que se usa ocasionalmente, S3 Intelligent-Tiering auto-optimiza sin retrieval fees.
► Hidden Cost #4: Cross-Region Data Transfer Loops
Este es el que más sorprende. Un equipo puede diseñar arquitectura "lógica" pero geográficamente desastrosa:
🌍 Ejemplo: Arquitectura Multi-Region Ineficiente
- Raw data storage: eu-west-1 (Europa, near data sources)
- Training GPUs: us-east-1 (AWS tiene más GPU availability)
- Model artifacts: Guardados de vuelta en eu-west-1 (near production users)
- Inference endpoints: us-east-1 (aprovechan GPUs baratas)
- User requests: Europa → cruzan Atlántico a us-east-1 → recuperan embeddings de eu-west-1
Resultado: 30% de la factura total eran data transfer fees. Cross-region transfer AWS/Azure cuesta $0.02/GB (puede llegar a $0.09 según regiones).
Solución: Co-locate todo en misma región siempre que sea posible. Si multi-region es necesario (latency, compliance), usar regional inference replicas en vez de centralizar.
► Hidden Cost #5: Continuous Model Retraining Overhead
Modelos sufren drift y necesitan retraining periódico. El problema: equipos implementan calendar-based retraining (cada semana, cada mes) sin medir si es realmente necesario.
📅 Calendar-Based vs Drift-Based Retraining
❌ Calendar-Based (wasteful)
- • Retrain every Sunday, sin importar drift
- • 52 retraining jobs/año
- • Muchos innecesarios (modelo aún performant)
- • Costo: $2,250/mes promedio
✅ Drift-Based (optimized)
- • Monitor accuracy/F1 continuo
- • Retrain cuando performance < threshold
- • 18-24 retraining jobs/año típico
- • Costo: $850/mes (62% saving)
Solución: Implementar monitoring de model performance en producción. Trigger retraining solo cuando accuracy degrada >X% o F1 score cae. Tools como Arize, WhyLabs, o custom scripts con MLflow.
► Hidden Cost #6: Zombie Resources (Forgotten Infrastructure)
Esto pasa en 100% de empresas que audito. Recursos lanzados para experimentos, PoCs, debugging... y nunca terminados.
| Tipo Zombie | Frecuencia | Costo Típico/Mes | Cómo Detectar |
|---|---|---|---|
| EBS volumes detached | Muy Común | $50-500 | AWS CLI: `aws ec2 describe-volumes --filters Name=status,Values=available` |
| Old model checkpoints (S3) | Universal | $100-1,000 | Lifecycle policies + age analysis |
| Load balancers sin targets | Común | $18-50 | AWS: `aws elbv2 describe-load-balancers` + check target health |
| Elastic IPs no attached | Ocasional | $3-10 | AWS: `aws ec2 describe-addresses --query 'Addresses[?InstanceId==null]'` |
| EC2 instances stopped (pero EBS charged) | Común | $50-300 | AWS: `aws ec2 describe-instances --filters Name=instance-state-name,Values=stopped` |
En una auditoría reciente encontré $1,200/mes en zombie resources en una empresa mediana (50 empleados tech). El CTO no tenía idea—nadie revisaba resources orphaned.
#!/bin/bash
#
# Script para detectar recursos zombie en AWS
# Ejecutar con: ./zombie-detection.sh
echo "🔍 Buscando Zombie Resources en AWS..."
echo ""
# 1. EBS volumes no attached
echo "1️⃣ EBS Volumes Detached:"
aws ec2 describe-volumes \
--filters Name=status,Values=available \
--query 'Volumes[*].[VolumeId,Size,CreateTime]' \
--output table
# 2. Elastic IPs no asociadas
echo ""
echo "2️⃣ Elastic IPs No Attached:"
aws ec2 describe-addresses \
--query 'Addresses[?InstanceId==`null`].[PublicIp,AllocationId]' \
--output table
# 3. Load Balancers sin targets activos
echo ""
echo "3️⃣ Load Balancers Sin Targets:"
for lb in $(aws elbv2 describe-load-balancers --query 'LoadBalancers[*].LoadBalancerArn' --output text); do
targets=$(aws elbv2 describe-target-health \
--target-group-arn $(aws elbv2 describe-target-groups \
--load-balancer-arn $lb \
--query 'TargetGroups[0].TargetGroupArn' \
--output text) 2>/dev/null | grep -c "healthy")
if [ "$targets" -eq 0 ]; then
echo "⚠️ LB sin targets: $lb"
fi
done
# 4. EC2 instances stopped (aún cobrando EBS)
echo ""
echo "4️⃣ EC2 Instances Stopped (cobrando storage):"
aws ec2 describe-instances \
--filters Name=instance-state-name,Values=stopped \
--query 'Reservations[*].Instances[*].[InstanceId,InstanceType,LaunchTime]' \
--output table
echo ""
echo "✅ Scan completado. Revisa output y termina recursos innecesarios."Solución: Ejecutar scripts de detección mensualmente, implementar tagging obligatorio (owner, project, expiry_date), usar tools como AWS Cost Anomaly Detection o Azure Advisor.
► Hidden Cost #7: Verbose Logging & Monitoring Sprawl
Engineers adoran logs detallados para debugging. El problema: en producción a escala, esto genera terabytes de logs que cuestan almacenar e indexar.
📊 Ejemplo: Inference Endpoint con 1M requests/día
- •Log level DEBUG: 2KB por request → 2GB/día → 60GB/mes → CloudWatch $30/mes ingest + $15/mes storage = $45
- •Log level ERROR only + 10% sampling: 0.2KB por request → 200MB/día → 6GB/mes → $3/mes total
- •Savings: 93% reducción ($42/mes este endpoint solo)
Ahora multiplica por 10 microservices, 5 environments (dev, staging, prod, etc.), y tienes $2,000-5,000/mes solo en logs innecesarios.
Solución: Log sampling (sample 1-10% requests en prod, 100% errors), retention policies agresivas (7-14 días no 90+), usar log levels correctos (INFO/WARN/ERROR no DEBUG en production), structured logging para queries eficientes.
LLM Inference Costs: La Buena y Mala Noticia
5. LLM Inference Costs: La Buena y Mala Noticia
Si estás construyendo aplicaciones con RAG, chatbots o cualquier sistema que use LLM APIs (OpenAI, Anthropic, Cohere, etc.), necesitas entender la dinámica de costes inference. Hay buenas noticias... y malas noticias.
✓ La Buena Noticia: Precios Cayeron 1000x en 3 Años
Según a16z, los costes de LLM inference han caído 1000x en solo 3 años, con precios decreciendo 10x cada año para performance equivalente. Cuando GPT-3 se hizo público en noviembre 2021, costaba $60 por millón de tokens. Hoy, el modelo más barato que logra el mismo score cuesta $0.06 por millón de tokens.
| Modelo | Input ($/1M tokens) | Output ($/1M tokens) | Context Window | Best For |
|---|---|---|---|---|
| GPT-4o mini | $0.15 | $0.60 | 128K | Cheap general purpose |
| GPT-3.5 Turbo | $0.50 | $1.50 | 16K | Fast, cost-effective |
| GPT-4o | $2.50 | $10.00 | 128K | Balanced performance |
| GPT-4 Turbo | $10.00 | $30.00 | 128K | Complex reasoning only |
| Claude 3.5 Sonnet | $3.00 | $15.00 | 200K | Long context tasks |
| Llama 3.1 70B (hosted) | $0.35 | $0.40 | 128K | Open source, self-host option |
Pricing actualizado Nov 2025. Output tokens típicamente cuestan 2-5x más que input tokens—factor crítico que muchos ignoran.
✗ La Mala Noticia: Inference Overtakes Training En 3-6 Meses
El gran shock para equipos en producción: dentro de 3-6 meses de deployment, inference overtakes training como driver dominante de costes. Entrenar un modelo es one-time o periódico (retraining mensual). Inference es continuo—cada consulta de usuario, cada request de chatbot, 24/7/365.
📊 Ejemplo Real: Chatbot Customer Support
- •Embedding generation: 10,000 documentos iniciales → text-embedding-3-small → 50M tokens → $1 one-time
- •Chat inference: 50,000 conversaciones/mes, 10 mensajes promedio → GPT-4o (2.5K tokens input + 500 output) → 150M input + 25M output tokens
- •Costo mensual inference: (150M × $2.50) + (25M × $10) = $375 + $250 = $625/mes
- •Costo anual: $625 × 12 = $7,500/año vs $1 embeddings one-time
En 6 meses, inference costó 3,750x más que el training inicial. Y esto asume volumen moderado—chatbots high-traffic pueden ser 10-50x más.
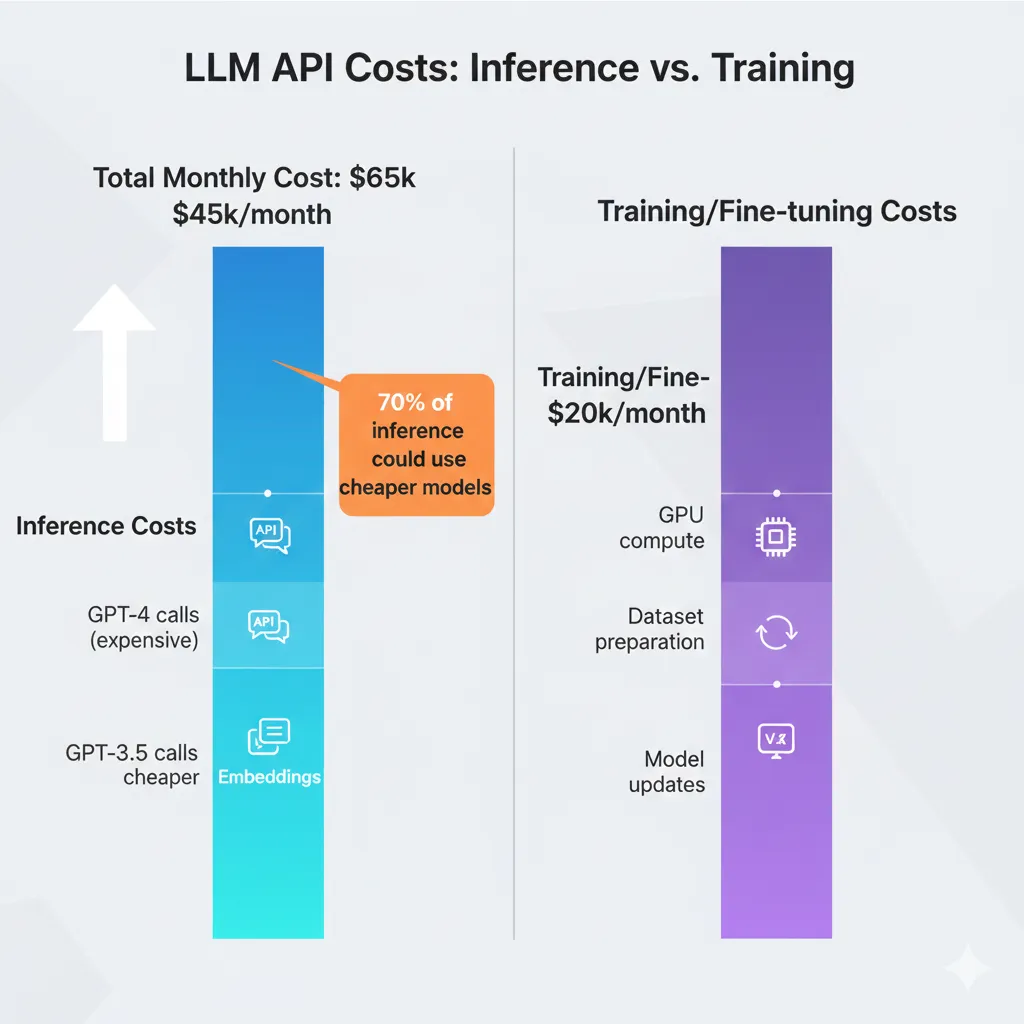
► El Hidden Cost: Output Tokens Cuestan 2-5x Input Tokens
Este es el que sorprende a developers nuevos en LLM APIs. Output tokens cuestan significativamente más que input tokens—típicamente 2-5x dependiendo del modelo. Para GPT-4 Turbo, output cuesta exactamente 3x más ($30 vs $10 por millón).
¿Por qué? Generar tokens es computacionalmente más caro que procesarlos. El modelo debe ejecutar forward pass completo para cada token generado, mientras que input processing es batch parallelizable.
💸 Impacto Financiero de Outputs Verbose
Imagina un chatbot configurado para generar respuestas "helpful y detalladas" sin límite max_tokens:
❌ Sin Limit (verbose)
- • Avg output: 800 tokens
- • 50K conversations/mes
- • Total output: 40M tokens
- • Costo: 40M × $10 = $400/mes
✅ Con max_tokens=300
- • Avg output: 280 tokens
- • 50K conversations/mes
- • Total output: 14M tokens
- • Costo: 14M × $10 = $140/mes
Savings: $260/mes (65% reducción) solo limitando output length. Esto NO degrada user experience—la mayoría de respuestas verbose tienen fluff innecesario.
► 5 Optimizaciones LLM Inference Que Reducen Costes 30-70%
1. Prompt Engineering Para Brevity (30-50% savings)
Prompts concisos y específicos reducen tanto input como output tokens dramáticamente:
❌ Verbose Prompt (450 tokens):
"You are a helpful customer support agent. The user has asked a question about our product. Please analyze their question carefully, consider all possible interpretations, and provide a comprehensive, detailed answer that addresses every aspect of their concern. Make sure to be friendly, professional, and thorough in your response..."
✅ Concise Prompt (120 tokens):
"Answer this customer question concisely using docs context. Max 2 paragraphs."
Savings: 73% input reduction. Multiply por millones de requests → $$$
2. Context Caching (75-90% cheaper cached tokens)
OpenAI, Anthropic y otros ofrecen prompt caching donde porción estática del prompt (system message, docs context) se cachea y reutiliza. Cached tokens cuestan 75-90% menos.
Estructura Prompt Cache-Friendly:
# Cacheable prefix (doesn't change) SYSTEM: You are a support agent. Docs: [10,000 tokens of product documentation] # Dynamic suffix (changes per request) USER QUESTION: [specific user query]ROI: Si 10K tokens docs se reusan en cada request, pagas precio completo 1x, luego 10-25% por request subsecuente. Para high-volume apps, esto es 50-70% total savings.
3. Prompt Routing (40-70% savings multi-model)
No uses GPT-4 Turbo para TODO. Implementa routing inteligente basado en complejidad query:
- •Simple queries: GPT-4o mini ($0.15 input) - FAQ, greetings, basic info
- •Medium queries: GPT-4o ($2.50 input) - Product questions, troubleshooting
- •Complex reasoning: GPT-4 Turbo ($10 input) - Technical analysis, multi-step problems
FinOps for AI guide: Routing efectivo reduce costes inference 40-70%. Classifier inicial (cheap model) determina complexity → routes to appropriate model tier.
4. Batch API Donde Posible (50% savings)
OpenAI Batch API ofrece 50% descuento para requests asíncronos (24h SLA). Perfecto para:
- •Embedding generation de documentos (no real-time)
- •Data analysis/classification jobs (overnight processing)
- •Summarization de logs/reports (daily/weekly)
5. Self-Hosted Open Source Models (6x cost reduction)
Para high-volume applications, self-hosting Llama 3.1 70B, Mixtral 8x7B u otros open source puede ser 6x más barato que APIs.
Breakeven Analysis:
- • API cost: Llama 3.1 70B hosted @ $0.35/1M input tokens
- • Self-hosted: 2x A100 80GB @ $2,920/mes = $35,040/año
- • Breakeven: ~100 billion tokens/año (8.3B tokens/mes)
- • For apps doing 10B+ tokens/mes → self-host is 6x cheaper
Consideration: Requires ML engineering effort (deployment, scaling, monitoring). Solo tiene sentido para high-volume sustained workloads.
#!/usr/bin/env python3
"""
LLM Cost Optimization Wrapper
Implementa caching, routing, y token limits automáticos
"""
from openai import OpenAI
from functools import lru_cache
import hashlib
import tiktoken
client = OpenAI()
encoder = tiktoken.encoding_for_model("gpt-4")
# Configuration
MAX_OUTPUT_TOKENS = 300
CACHE_SIZE = 1000
MODEL_TIERS = {
"simple": "gpt-4o-mini", # $0.15/1M input
"medium": "gpt-4o", # $2.50/1M input
"complex": "gpt-4-turbo" # $10.00/1M input
}
@lru_cache(maxsize=CACHE_SIZE)
def cached_completion(prompt_hash, model, max_tokens):
"""
Cache completions para prompts idénticos.
Usa hash del prompt como key para evitar duplicates.
"""
# Note: In production, deshacer hash para obtener prompt real
# Aquí es simplified example
return None # Placeholder
def estimate_tokens(text):
"""Estimate token count para cost calculation."""
return len(encoder.encode(text))
def classify_complexity(prompt):
"""
Classify query complexity para routing.
Returns:
"simple" | "medium" | "complex"
"""
token_count = estimate_tokens(prompt)
# Simple rules (mejorar con ML classifier si necesario)
keywords_complex = ["analyze", "compare", "explain why", "multi-step"]
keywords_simple = ["what is", "define", "list", "hello"]
prompt_lower = prompt.lower()
if any(kw in prompt_lower for kw in keywords_simple):
return "simple"
elif any(kw in prompt_lower for kw in keywords_complex):
return "complex"
elif token_count > 500:
return "complex"
else:
return "medium"
def optimized_completion(prompt, system_msg="", force_model=None):
"""
Main wrapper con todas las optimizaciones:
- Prompt caching
- Model routing
- Token limits
- Cost tracking
"""
# 1. Check cache
prompt_hash = hashlib.md5(f"{system_msg}{prompt}".encode()).hexdigest()
cached = cached_completion(prompt_hash, "gpt-4o", MAX_OUTPUT_TOKENS)
if cached:
print("✅ Cache hit - $0 cost")
return cached
# 2. Determine model tier
if force_model:
model = force_model
else:
complexity = classify_complexity(prompt)
model = MODEL_TIERS[complexity]
print(f"🎯 Routed to {model} (complexity: {complexity})")
# 3. Call API con limits
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_msg},
{"role": "user", "content": prompt}
],
max_tokens=MAX_OUTPUT_TOKENS,
temperature=0.7
)
# 4. Track cost (simplified)
input_tokens = response.usage.prompt_tokens
output_tokens = response.usage.completion_tokens
# Pricing (approximate)
pricing = {
"gpt-4o-mini": {"input": 0.15, "output": 0.60},
"gpt-4o": {"input": 2.50, "output": 10.00},
"gpt-4-turbo": {"input": 10.00, "output": 30.00}
}
cost = (
input_tokens / 1_000_000 * pricing[model]["input"] +
output_tokens / 1_000_000 * pricing[model]["output"]
)
print(f"💰 Cost: ${cost:.4f} ({input_tokens} in + {output_tokens} out tokens)")
return response.choices[0].message.content
# Example usage
if __name__ == "__main__":
# Simple query → routes to gpt-4o-mini
result1 = optimized_completion("What is your return policy?")
# Complex query → routes to gpt-4-turbo
result2 = optimized_completion(
"Analyze the trade-offs between microservices and monolith architectures "
"for a fintech startup with 50 engineers, considering scaling, costs, and "
"team cognitive load."
)
On-Premise vs Cloud: Cuándo La Repatriación Tiene Sentido Financiero
6. On-Premise vs Cloud: Cuándo La Repatriación Tiene Sentido Financiero
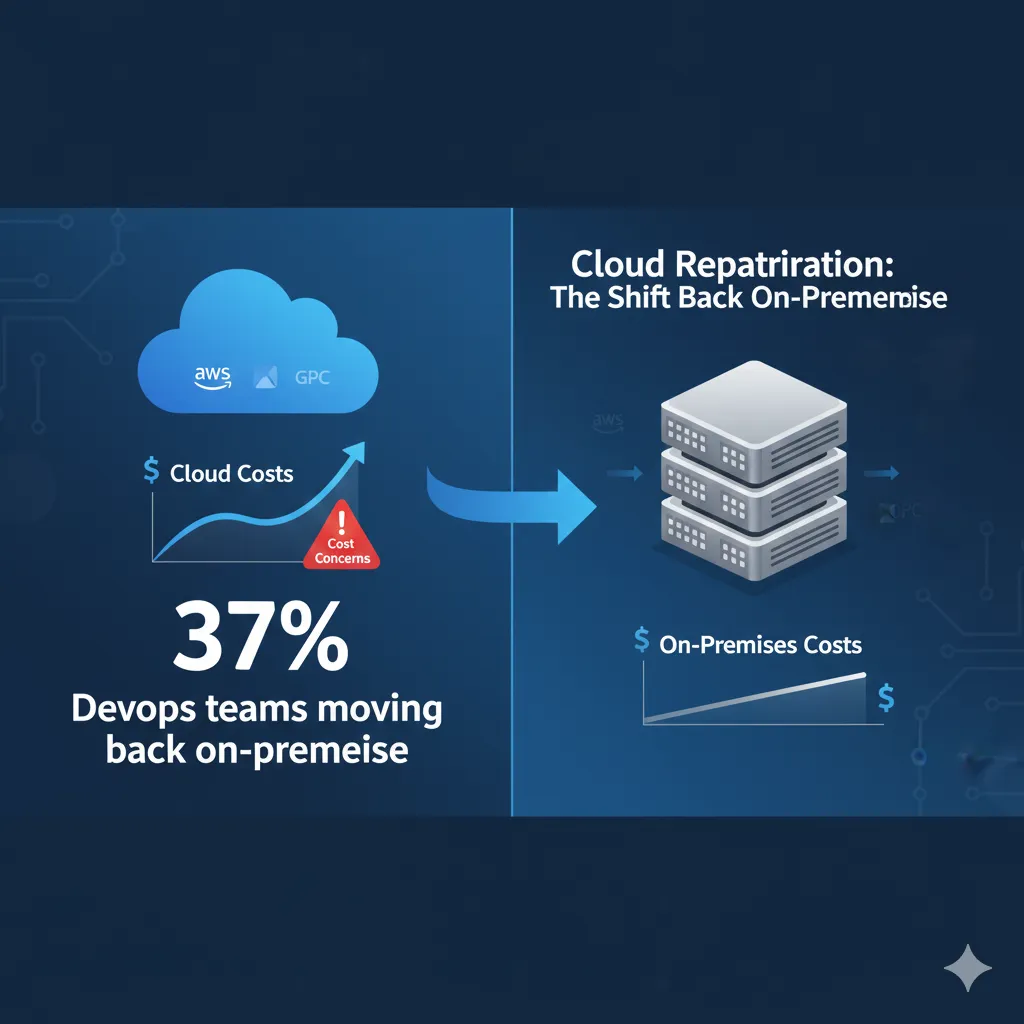
Uno de los trends más interesantes de 2025: 83% de CTOs enterprise planean repatriar al menos algunos workloads de cloud a on-premise. Gartner predice que más del 50% de empresas que movieron workloads a public cloud buscarán repatriar debido a cost overruns y performance issues.
83%
CTOs planean repatriation en 2025
Motivación principal: costes cloud excediendo 150% de alternativas on-premise
11.9
Meses de breakeven promedio
Reserved instances cloud vs CAPEX on-premise para AI workloads estables
► Case Study: Dropbox Ahorró $75M En 2 Años
Dropbox inicialmente dependía completamente de AWS S3 para storage. Al crecer, descubrieron que los costes cloud long-term eran insostenibles. Decidieron repatriar core storage workloads a infraestructura on-premise, manteniendo cloud solo para operations no-críticas.
Resultado: Ahorraron $75 millones durante dos años. Sí, tuvieron CAPEX inicial significativo (data centers, hardware), pero el ROI se materializó en
🎯 Tus Próximos Pasos
Ahora tienes el framework completo para entender por qué tu factura AI cloud explota y exactamente qué hacer al respecto. El problema no es falta de información—es la ejecución.
La mayoría de equipos tardan 3-6 meses en implementar optimizaciones significativas porque:
- •No tienen visibilidad clara de dónde están los waste hotspots (82% sin AI ROI tracking)
- •Usan spreadsheets en vez de tooling real (57% de empresas)
- •No tienen bandwidth dedicado para cost optimization (team enfocado en features)
- •Temen romper production haciendo cambios de infra
Con el approach correcto y expertise adecuado, puedes reducir costes 40-73% en 4-8 semanas sin sacrificar performance ni escalabilidad. Así es como:
🚀 Auditoría Gratuita
Agenda una auditoría gratuita de 30 minutos donde analizo tu factura AWS/Azure/GCP actual, identifico tus top 5 waste hotspots, y te doy un savings estimate personalizado.
Solicitar Auditoría →Garantía: Si no encuentro al menos 20% waste, la consulta es gratis.
📚 Recursos Gratuitos
Descarga mi checklist técnica de 40 puntos de optimización AWS (Compute, Storage, Databases, Networking). Ahorros verificables sin vendehumo.
Email gate. Incluye tutorial video 10 minutos.
🔧 Servicio FinOps
Mi servicio Cloud Cost Optimization incluye auditoría completa, roadmap priorizado, e implementación hands-on. Outcome-based pricing: solo cobro si ahorro >30%.
Ver Servicio →Casos reales: 40-73% reducción típica en 6-8 semanas.
📧 Contáctame Directamente
Soy Abdessamad Ammi, certificado AWS ML Specialty + DevOps Professional con 10+ años optimizando infraestructuras cloud. Si tienes preguntas específicas sobre tu setup, escríbeme directamente.
¿Listo Para Reducir Tu Factura AI 40-70%?
He ayudado a más de 40 empresas SaaS a optimizar sus costes cloud AI. El ahorro promedio: 52% en 6-8 semanas.
Solicitar Auditoría Gratuita Ahora →Respuesta en

Sobre el Autor
Abdessamad Ammi es CEO de BCloud Consulting y experto senior en IA Generativa y Cloud Infrastructure. Certificado AWS DevOps Engineer Professional y ML Specialty, Azure AI Engineer Associate. Ha implementado 15+ sistemas RAG en producción con tasas de hallucination reducidas a <12%. Especializado en MLOps, LangChain y arquitecturas cloud production-ready.


