


El Cuello de Botella Oculto: Qué Es KV Cache Y Por Qué Colapsa Tus GPUs
Por Qué 95% de Agentes IA Fracasan en Producción: El Cuello de Botella de Memoria Que Nadie Te Cuenta
Descubre cómo NVIDIA Vera Rubin y la arquitectura ICMS resuelven el problema de memoria que colapsa tus GPUs, logrando 5x mayor rendimiento y 10x menor costo por token.
95% de pilotos de agentes IA fallan antes de llegar a producción
Según un estudio del MIT citado en el reporte de Composio 2025, solo 1 de cada 20 proyectos de agentes IA logra escalar a producción. La causa número uno: gestión deficiente de memoria, específicamente el cuello de botella del KV cache que colapsa las GPUs cuando manejas contextos largos.
Fuente: Composio 2025 AI Agent Report
Si eres CTO, VP de Ingeniería o líder de ML en una empresa SaaS o FinTech, probablemente estás viviendo esta pesadilla ahora mismo:
- ❌Tu equipo de ML ha construido agentes IA brillantes en notebooks Jupyter, pero cuando intentas desplegarlos en producción con contextos de 100K+ tokens, las GPUs se quedan sin memoria (OOM errors) cada 2-3 horas.
- ❌La latencia de tus agentes multi-step es de 3-5 segundos porque cada llamada al LLM acumula overhead, cuando necesitas menos de 200ms para UX aceptable.
- ❌El presupuesto cloud que aprobaste ($50K/mes) se disparó a $350K/mes porque los costos de contexto largo escalan cuadráticamente y nadie te lo advirtió.
- ❌Intentaste comprar más H100s para escalar, pero los lead times son de 40+ semanas y el HBM está agotado hasta finales de 2026.
Mientras tanto, tu competencia ya tiene agentes en producción manejando millones de queries diarias. ¿Qué están haciendo diferente?
La respuesta está en la arquitectura de memoria:
La inferencia de LLMs se ha convertido en un problema de memoria, no de computación. El KV cache (la estructura que almacena los cálculos de atención de tokens previos) crece linealmente con la longitud del contexto y consume 60-80% de la memoria GPU disponible. Para un modelo Llama 70B con contexto de 128K tokens, el KV cache solo requiere 20GB de HBM. Si escalas a 100M tokens (necesario para agentes que manejan documentos empresariales completos), necesitas 638 H100s por usuario solo para almacenar el cache.
Este artículo te revela la solución arquitectural que está cambiando el juego en 2026:
Lo que aprenderás en esta guía:
- ✓Por qué el KV cache es el cuello de botella oculto que colapsa tus GPUs (con explicación técnica desde cero)
- ✓Optimizaciones software que puedes implementar HOY (vLLM PagedAttention, quantization, offloading) para lograr 2-4x mejora inmediata
- ✓NVIDIA Vera Rubin + ICMS: la arquitectura petabyte-scale que logra 5x TPS y 10x menor costo/token vs Blackwell
- ✓Calculadora TCO real: cuánto cuesta ejecutar agentes IA en producción (incluye costos ocultos que nadie te cuenta)
- ✓Roadmap de implementación Q1-Q4 2026 con acciones concretas y plazos realistas
- ✓Arquitecturas recomendadas por tamaño de empresa (startup, scale-up, enterprise) con specs exactas
El mercado de agentic AI crecerá de $7.55 mil millones (2025) a $199 mil millones (2034), con un CAGR del 44.6% según Precedence Research. 85% de las empresas planean implementar agentes IA para finales de 2025, y Gartner proyecta que 40% de las aplicaciones empresariales incluirán agentes específicos para tareas en 2026.
Pero aquí está el problema: menos del 25% de las empresas logran escalar sus agentes a producción. La brecha entre experimentación y deployment es el desafío central del negocio en 2026. Y la causa raíz es infraestructura: específicamente, la arquitectura de memoria.
💡 Nota: Si prefieres que implemente esta arquitectura por ti, mi servicio MLOps & Deployment de Modelos incluye auditoría de infraestructura, optimización de KV cache, y roadmap completo de migración a Vera Rubin cuando esté disponible (H2 2026).
1. El Cuello de Botella Oculto: Qué Es KV Cache Y Por Qué Colapsa Tus GPUs
Para entender por qué el 95% de los agentes IA fallan en producción, primero necesitas comprender qué es el KV cache y por qué se convierte en el villano oculto cuando escalas a contextos largos.
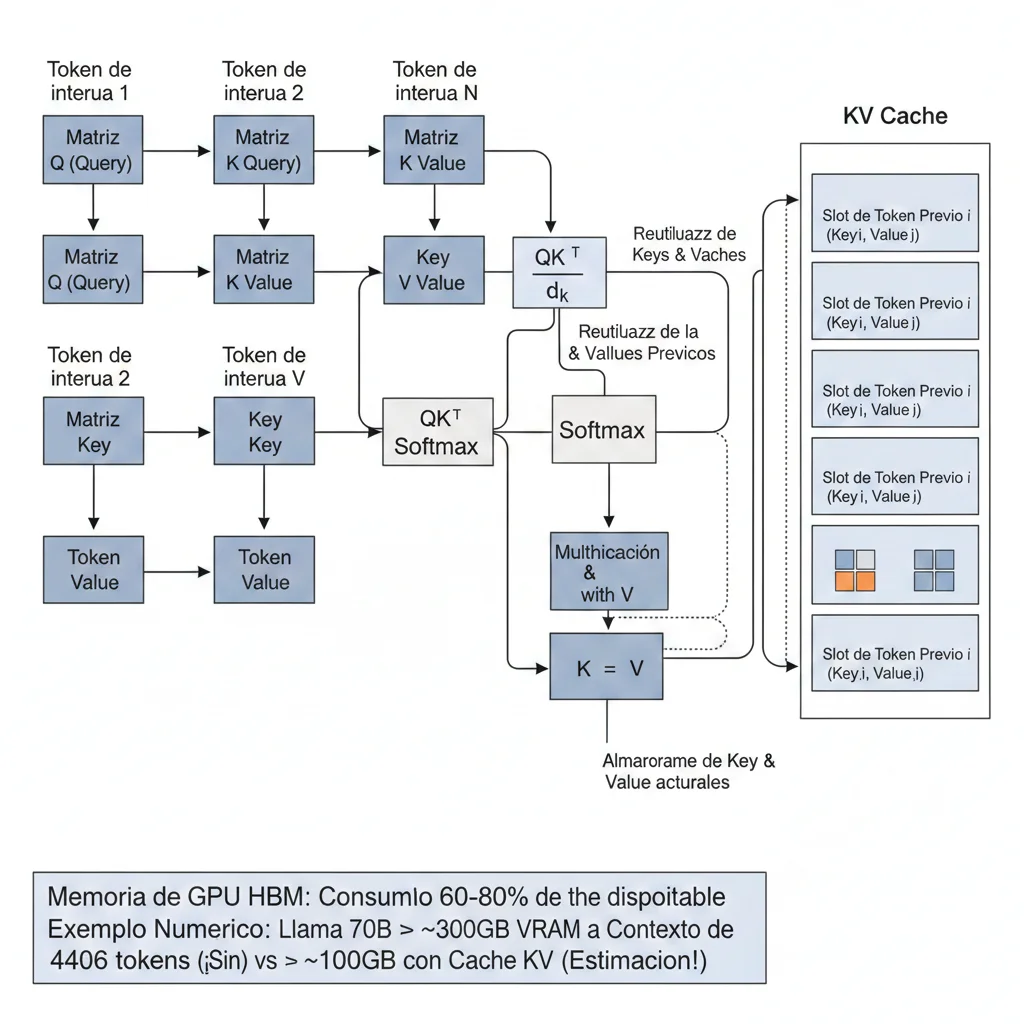
► 1.1. Anatomía del KV Cache: Cómo Funcionan Los Transformers
Los modelos transformer (la arquitectura detrás de GPT, Claude, Llama) funcionan mediante un mecanismo llamado self-attention. Cuando el modelo procesa un token (palabra o subpalabra), calcula tres vectores para cada posición en la secuencia:
- QQuery: Representa "qué información estoy buscando en este token"
- KKey: Representa "qué información contiene este token" (para que otros puedan encontrarlo)
- VValue: Contiene el contenido real del token (lo que se usará si este token es relevante)
El mecanismo de atención compara el Query del token actual con todos los Keys previos para determinar qué tokens son relevantes, y luego combina los Values correspondientes. Matemáticamente:
Attention(Q, K, V) = softmax(Q × K^T / sqrt(d_k)) × V
Donde:
- Q: Query del token actual (shape: [batch, seq_len, d_model])
- K: Keys de todos los tokens previos (shape: [batch, seq_len, d_model])
- V: Values de todos los tokens previos (shape: [batch, seq_len, d_model])
- d_k: Dimensionalidad de las keys (típicamente 128 o 256)Aquí está el problema: En generación autoregresiva (cuando el modelo genera tokens uno por uno), necesitas calcular atención sobre TODOS los tokens previos para cada token nuevo. Si tienes un contexto de 100,000 tokens y estás generando el token 100,001, necesitas:
- • Comparar el Query del token 100,001 con 100,000 Keys previas
- • Recalcular las proyecciones K y V para cada uno de esos 100,000 tokens
- • Repetir este proceso en cada capa del transformer (típicamente 40-80 capas en modelos grandes)
Resultado: Cuadrática complejidad computacional O(n²) y uso de memoria que crece linealmente con la longitud del contexto.
► 1.2. La Optimización Obvia: Cachear Keys Y Values
La solución obvia es cachear (almacenar en memoria) los vectores K y V de los tokens ya procesados. Así evitas recalcularlos cada vez. Esto se llama KV cache.
🎯 Beneficio del KV Cache:
Reduces el tiempo de generación de cada token de O(n²) a O(n), porque solo calculas el Query del token nuevo y lo comparas con las Keys cacheadas (no recalculas nada).
Pero aquí es donde aparece el cuello de botella: el KV cache ocupa MUCHA memoria.
► 1.3. Los Números Que Nadie Te Cuenta: Cuánto Crece El KV Cache
Calculemos el tamaño del KV cache para un modelo Llama 3.1 70B con contexto de 128K tokens (un caso real de uso en agentes con documentos empresariales):
| Parámetro | Valor | Cálculo |
|---|---|---|
| Tamaño modelo | 70 mil millones parámetros | - |
| Capas transformer | 80 capas | - |
| Dimensión modelo (d_model) | 8,192 | - |
| Longitud contexto | 128,000 tokens | - |
| Precisión | FP16 (2 bytes/valor) | - |
| Tamaño KV cache TOTAL | ~20 GB | 2 × 80 capas × 128K tokens × 8192 dim × 2 bytes |
El Problema Real en Producción
Una GPU H100 tiene 80 GB de HBM3e. Si el modelo Llama 70B ya ocupa 60 GB (en FP16), solo te quedan 20 GB para el KV cache. Esto significa:
- ▸Con 128K tokens de contexto, el KV cache consume TODA la memoria restante
- ▸No hay espacio para batch processing (procesar múltiples requests simultáneas), lo que mata tu throughput
- ▸Si el contexto crece a 200K tokens (conversaciones multi-turno), obtienes OOM error inmediato
- ▸Con 10 usuarios concurrentes, necesitas 10× más memoria = imposible en una sola GPU
Ahora imagina escalar a contextos ultra-largos (1M-100M tokens) necesarios para agentes que analizan repositorios de código completos o bases documentales empresariales:
# Cálculo tamaño KV cache para Llama 3.1 405B con 100M tokens
model_size = 405e9 # parámetros
num_layers = 126 # capas transformer
d_model = 16384 # dimensión modelo
context_length = 100e6 # 100 millones tokens
precision_bytes = 2 # FP16
# KV cache: 2 matrices (K y V) por capa
kv_cache_size_bytes = (
2 * # K y V
num_layers *
context_length *
d_model *
precision_bytes
)
kv_cache_size_gb = kv_cache_size_bytes / (1024**3)
print(f"Tamaño KV cache: {kv_cache_size_gb:.1f} GB")
# Output: 7,680 GB = 7.5 TB de memoria solo para KV cache
# ¿Cuántas H100 necesitas? (80 GB HBM cada una)
h100_memory_gb = 80
num_h100s_needed = kv_cache_size_gb / h100_memory_gb
print(f"H100s necesarias: {num_h100s_needed:.0f}")
# Output: 96 H100s por usuario... IMPOSIBLE económicamenteEste es el cálculo que aparece en el paper de Magic.dev: Para Llama 3.1 405B con contexto de 100M tokens, necesitas 638 H100s solo para almacenar un único KV cache de un solo usuario. A $2.50/hora por H100, estamos hablando de $1,595/hora = $38,280/día solo en alquiler GPU para un usuario.
💸 ROI Imposible:
Ningún caso de uso empresarial justifica $38K/día por usuario. Por eso contextos ultra-largos (10M+ tokens) no son viables con arquitecturas tradicionales GPU-only. Necesitas una solución arquitectural diferente, no solo optimizaciones incrementales.
► 1.4. Fragmentación de Memoria: El Desperdicio Silencioso
Incluso con contextos "normales" (32K-128K tokens), hay otro problema que multiplica el desperdicio: fragmentación de memoria.
Las implementaciones tradicionales de inference pre-asignan memoria contigua para el KV cache de cada request basándose en el contexto máximo posible. Pero en producción, los contextos reales varían:
- • Request A: 5K tokens contexto → pero pre-asignaste 128K → desperdicio 96% memoria
- • Request B: 80K tokens contexto → pre-asignaste 128K → desperdicio 38% memoria
- • Request C: 128K tokens completo → OK, pero bloquea espacio para otros requests
Según la investigación de vLLM (paper PagedAttention, 2024), las implementaciones naive desperdician 60-80% de la memoria GPU asignada al KV cache debido a fragmentación.
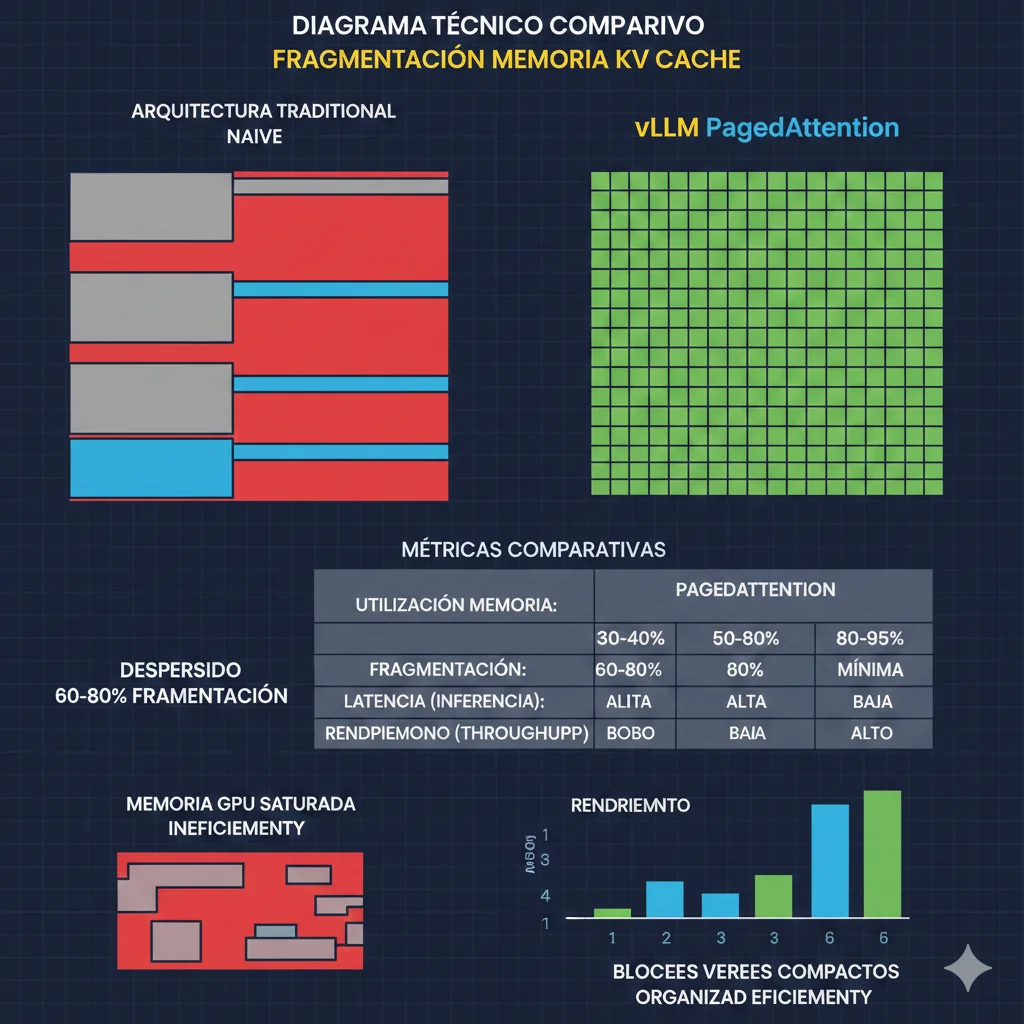
📊 Impacto Real en Producción:
60-80%
Memoria GPU desperdiciada por fragmentación
4-8x
Menor throughput vs implementaciones optimizadas
2-4x
Mayor costo por query debido a subutilización
Esto explica por qué tu GPU H100 "debería" poder manejar 10-15 requests concurrentes (basándote en el cálculo teórico de memoria), pero en la práctica solo procesa 2-4 antes de quedarse sin memoria.
El Límite de las Soluciones Software: Por Qué HBM Es El Nuevo Petróleo
4. El Límite de las Soluciones Software: Por Qué HBM Es El Nuevo Petróleo
Las optimizaciones software de la sección anterior te dan 2-4x mejora. Pero hay un límite físico: no puedes optimizar tu camino alrededor de la cantidad absoluta de memoria disponible. Y ahí es donde HBM (High Bandwidth Memory) se convierte en el recurso más crítico y escaso de 2026.
► 4.1. The Memory Wall Problem: Por Qué Más GPUs No Es La Solución
Cuando el KV cache no cabe en una GPU, la reacción instintiva es "compremos más GPUs y distribuyamos la carga". Pero esto tiene problemas fundamentales:
🚧 Problemas de Escalar Horizontalmente con Más GPUs:
- •
Network bandwidth bottleneck:
Si distribuyes el KV cache entre 10 GPUs, cada generación de token requiere comunicación entre todas las GPUs (all-reduce operation). Con Ethernet 100 GbE: ~12.5 GB/s. Un KV cache de 20 GB tarda 1.6 segundos transferir → latencia inaceptable.
- •
Costo lineal sin throughput lineal:
Duplicar GPUs duplica costo pero NO duplica throughput debido a overhead comunicación. Eficiencia cae de 90% (2 GPUs) a 60% (8 GPUs) a 40% (16 GPUs).
- •
HBM supply shortage:
Incluso si quisieras comprar 50 H100s, los lead times son 40+ semanas y el stock está agotado hasta finales de 2026. SK Hynix confirmó que 2026 output ya está allocated.
- •
Complejidad operacional:
Orquestar 20+ GPUs en cluster requiere expertise DevOps/ML avanzado: Kubernetes, NVLink fabric, load balancing, fault tolerance. Añade 3-6 meses a tu timeline.

Crisis HBM 2026: Los Números
- • Lead times: 40+ semanas para startups/scale-ups (vs 4-8 semanas en 2023)
- • Precios: HBM memory modules subieron 2x en 2025, proyección +30% adicional en 2026
- • Supply sold out: SK Hynix, Samsung, Micron reportan que 2026 capacity ya está pre-vendida a hyperscalers (NVIDIA, Microsoft, Google, Meta)
- • Market dynamics: Hyperscalers tienen contratos multi-año. Empresas pequeñas/medianas forzadas a cloud providers con markups 3-5x
Fuentes: The AI Memory Supercycle (Introl, 2026), Fast Company RAM Shortage Analysis
► 4.2. HBM3e vs HBM4: La Evolución Que Cambia Todo
HBM (High Bandwidth Memory) es el tipo de memoria usado en GPUs modernas. A diferencia de DDR5 RAM (usada en CPUs), HBM está apilada verticalmente en el mismo package que la GPU usando TSVs (Through-Silicon Vias), lo que permite bandwidths masivos.
| Especificación | HBM3 (H100) | HBM3e (H200) | HBM4 (Vera Rubin) | Mejora vs HBM3e |
|---|---|---|---|---|
| Interface width | 1024-bit | 1024-bit | 2048-bit | 2x |
| Transfer speed | 6.4 Gb/s | 9.6 Gb/s | 8-10 Gb/s | ~1x |
| Bandwidth per stack | 819 GB/s | 1,229 GB/s | 2 TB/s | 1.63x |
| Stacks per GPU | 5 (H100 SXM) | 8 (H200) | 8 (Rubin) | 1x |
| Total bandwidth GPU | 3.35 TB/s | 4.8 TB/s (H200) | 22 TB/s | 2.75x |
| Capacity per stack | 16 GB | 24 GB | 36 GB | 1.5x |
| Total capacity GPU | 80 GB | 141 GB | 288 GB | 2.04x |
| Disponibilidad | Disponible (2022) | Disponible (2024) | H2 2026 | - |
🚀 Por Qué HBM4 Es Game-Changer Para Agentes IA:
288 GB
Memoria por GPU (vs 80 GB H100)
Impacto: Llama 70B + KV cache 150K tokens en UNA GPU. Modelos 405B con 80K context en 2 GPUs.
22 TB/s
Bandwidth agregado (vs 3.35 TB/s H100)
Impacto: Prefill 3x más rápido. Decode 2x más rápido. Menos bottleneck memoria en multi-query workloads.
Fuente: Inside the NVIDIA Rubin Platform (NVIDIA Developer Blog, Enero 2026)
► 4.3. Por Qué Software Solo No Es Suficiente: El Límite Físico
Incluso con todas las optimizaciones software (quantization INT4, PagedAttention, offloading), hay límites duros:
🔴 Límites Fundamentales de Optimización Software:
- 1.
Quantization INT4 = Accuracy degradation inaceptable:
En tareas complejas (legal reasoning, medical diagnosis, code generation), accuracy cae 3-7% con INT4 vs FP16. Para aplicaciones críticas, este loss es inaceptable. INT8 es el límite práctico (1-2% loss).
- 2.
Offloading = Latency penalty mata UX:
Offloading a CPU RAM añade 80-150ms. Offloading a NVMe añade 300-800ms. Para customer-facing agents (chatbots, sales copilots), latencia >200ms = abandonment rate 15-30% mayor.
- 3.
Context compression = Pérdida de información:
Comprimir 100K tokens a 10K embeddings inevitablemente pierde detalles. Para tareas donde cada párrafo importa (contratos, compliance docs), compression no es viable.
- 4.
PagedAttention no crea memoria extra:
PagedAttention ELIMINA desperdicio (60-80% waste →
💡 La Realidad Incómoda:
No puedes optimizar tu camino alrededor de la física. Si tu workload necesita 300 GB de memoria activa (modelo + KV cache + batch processing) y tu GPU solo tiene 80 GB, ninguna cantidad de software tricks te salva.
Necesitas una solución arquitectural que fundamentalmente cambie cuánta memoria tienes disponible y cómo se comparte entre GPUs. Eso es exactamente lo que NVIDIA Vera Rubin + ICMS hacen.
Las 3 Causas de Fallo de Agentes IA (Y Por Qué Memoria Es #1)
2. Las 3 Causas de Fallo de Agentes IA (Y Por Qué Memoria Es #1)
El reporte de Composio 2025 identifica tres causas principales del 95% de fallos en pilotos de agentes IA. Estas no son problemas teóricos: son los blockers reales que encuentran CTOs y equipos de ML cuando intentan llevar prototipos de notebook a producción.

❶ Causa #1: "Dumb RAG" (Gestión Deficiente de Memoria) — 45% de Fallos
"Dumb RAG" es el término que usa Composio para describir sistemas de Retrieval-Augmented Generation que fallan porque no gestionan memoria inteligentemente. Los síntomas incluyen:
- •Context stuffing sin filtrado: Inyectar 50K tokens de documentos recuperados sin evaluar relevancia → el LLM se confunde con ruido
- •Vector DB retrieval lento: Latencia de 800ms-2s para buscar embeddings en bases con 10M+ vectores porque no optimizaste índices
- •KV cache overflow: Context window del LLM (128K tokens) se llena con contexto irrelevante y falla al procesar query del usuario
- •Memoria de conversación no persistente: Agente "olvida" contexto después de 10-15 turnos porque no implementaste memoria a largo plazo
- •Hallucinations por datos obsoletos: Vector DB sin refresh → agente cita información desactualizada → pérdida de confianza usuario
💡 Por Qué Esto Es Problema de Memoria:
Todos estos síntomas se reducen a gestión ineficiente del KV cache y memoria del sistema. Si tu RAG system no filtra contexto inteligentemente, saturas la memoria GPU con tokens irrelevantes. Si tu vector DB no cabe en RAM, cada query hace I/O a disco (latencia 100x mayor). Si no tienes arquitectura de memoria jerárquica (episódica, semántica, procedimental), el agente pierde contexto crítico.
La cita más reveladora del reporte: "Even GPT-5 is useless when it gets bad data." No importa qué tan bueno sea tu modelo si la memoria (contexto) que le pasas es basura.
❷ Causa #2: "Brittle Connectors" (Integraciones Frágiles de I/O) — 30% de Fallos
Agentes IA en producción necesitan conectarse a sistemas externos: APIs empresariales, bases de datos, CRMs, herramientas internas. Estos conectores fallan por:
- •Timeouts sin retry logic: API externa tarda 31 segundos (tu timeout es 30s) → request falla sin reintentar
- •Schema changes no detectados: API actualiza su estructura de respuesta → tu parser explota → agente crashes
- •Rate limiting mal manejado: Salesforce API limita 100 calls/hora → tu agente hace 150 → ban temporal → servicio caído
- •Credenciales hardcodeadas: Token API en código fuente → expiras token → producción cae hasta que despliegas parche
Aunque esto parece problema de software engineering (y lo es), tiene impacto directo en memoria: cuando un conector falla a mitad de operación, el KV cache ya consumió recursos procesando contexto parcial que ahora es inútil. En workloads con alta concurrencia, esto causa memory leaks acumulativos.
❸ Causa #3: "Polling Tax" (Arquitectura No Event-Driven) — 15% de Fallos
Muchos agentes implementan polling: cada 5 segundos, el agente pregunta "¿hay nueva tarea?" a una cola/API. Esto es ineficiente porque:
- •Latencia artificial: Tarea llega en segundo 1, pero agente no la ve hasta segundo 5 (próximo poll) → 4s de overhead innecesario
- •Carga I/O constante: 1,000 agentes polling cada 5s = 200 queries/segundo a tu API → saturación infraestructura
- •Memory leaks en loops: Poll loop mal implementado acumula contexto sin liberar → memory footprint crece 10MB/hora → crash después de 48 horas uptime
La solución arquitectural correcta es event-driven: usar webhooks, message queues (Kafka, RabbitMQ), o serverless functions que despiertan solo cuando hay trabajo. Pero la realidad es que implementar arquitectura event-driven requiere expertise DevOps que muchos equipos de ML no tienen.
💼 Impacto Business de Estos Fallos:
Tiempo desperdiciado debugging:
$500K+ en salarios de equipo ML/DevOps (6-12 meses) troubleshooting problemas de infraestructura en lugar de shipping features
Delay time-to-market:
40+ semanas desde piloto a producción → competidores capturan market share mientras tú solucionas OOM errors
Erosión confianza interna:
CEO aprobó budget $2M para initiative AI agents → después de 9 meses sin results, cancela proyecto → equipo ML pierde credibilidad
La buena noticia: Causa #1 (Dumb RAG / Memoria) es el problema más crítico Y el más solucionable con las herramientas correctas. Las secciones siguientes te muestran exactamente cómo.
NVIDIA Vera Rubin: La Solución Arquitectural Petabyte-Scale
5. NVIDIA Vera Rubin: La Solución Arquitectural Petabyte-Scale
En CES 2026 (enero), NVIDIA anunció Vera Rubin: la próxima generación de infraestructura AI diseñada específicamente para resolver el cuello de botella de memoria en agentes IA y contextos ultra-largos. No es simplemente "GPUs más rápidas". Es una reimaginación completa de la arquitectura de memoria.

► 5.1. Anatomía de Vera Rubin NVL72: Specs Completas
Vera Rubin NVL72 es un sistema rack-scale que integra GPUs Rubin + CPUs Vera + networking NVLink 6 en una unidad coherente con 1.7 petabytes/segundo de bandwidth de memoria agregado.
🚀 Componentes Vera Rubin NVL72:
72x Rubin GPUs
- • Compute: 50 PFLOPS FP4 per GPU (3,600 PFLOPS total rack)
- • Memory: 288 GB HBM4 per GPU (20.7 TB total rack)
- • Bandwidth: 22 TB/s per GPU (1.58 PB/s aggregate GPU memory)
- • Architecture: Blackwell successor, 8 stacks HBM4 per GPU
36x Vera CPUs
- • Cores: 88 ARM Neoverse V3 cores per CPU (3,168 cores total)
- • Memory: 1.5 TB LPDDR5x per CPU (54 TB total rack)
- • Bandwidth: 500 GB/s per CPU (18 TB/s aggregate CPU memory)
- • Role: Offload control plane, preprocessing, ICMS management
NVLink 6 Fabric
- • Bandwidth: 3.6 TB/s bidirectional per GPU link
- • Topology: All-to-all GPU connectivity (260 TB/s rack bisection)
- • Latency:
Total Memoria Activa del Sistema: 74.7 TB (20.7 TB HBM4 + 54 TB LPDDR5x)
Bandwidth Agregado: 1.7 petabytes/segundo
► 5.2. Blackwell vs Vera Rubin: Benchmarks Comparativos
| Métrica | Blackwell NVL72 | Vera Rubin NVL72 | Mejora |
|---|---|---|---|
| GPUs por rack | 72x Blackwell | 72x Rubin | - |
| Memoria HBM por GPU | 192 GB HBM3e | 288 GB HBM4 | +50% |
| Bandwidth memoria GPU | 8 TB/s | 22 TB/s | +2.75x |
| Training (10T param MoE) | Baseline | 4x fewer GPUs | 4x |
| Inference throughput (TPS) | Baseline | Up to 5x higher | 5x |
| Cost per million tokens | Baseline | Up to 10x lower | 10x |
| Disponibilidad | Disponible (Q4 2024) | H2 2026 | - |
⚠️ Importante: Las métricas "up to 5x TPS" y "up to 10x lower cost" son workload-dependent. NVIDIA documentó estos números específicamente para reasoning-heavy workloads como Kimi-K2-Thinking. Tu mileage may vary según tipo de modelo y patrón de uso.
► 5.3. NVIDIA ICMS Platform: El Tier G3.5 de Memoria
ICMS (Inference Context Memory Storage) es la innovación arquitectural más importante de Vera Rubin. Es un nuevo tier de almacenamiento diseñado específicamente para KV cache: más rápido que storage tradicional, más abundante que GPU HBM.
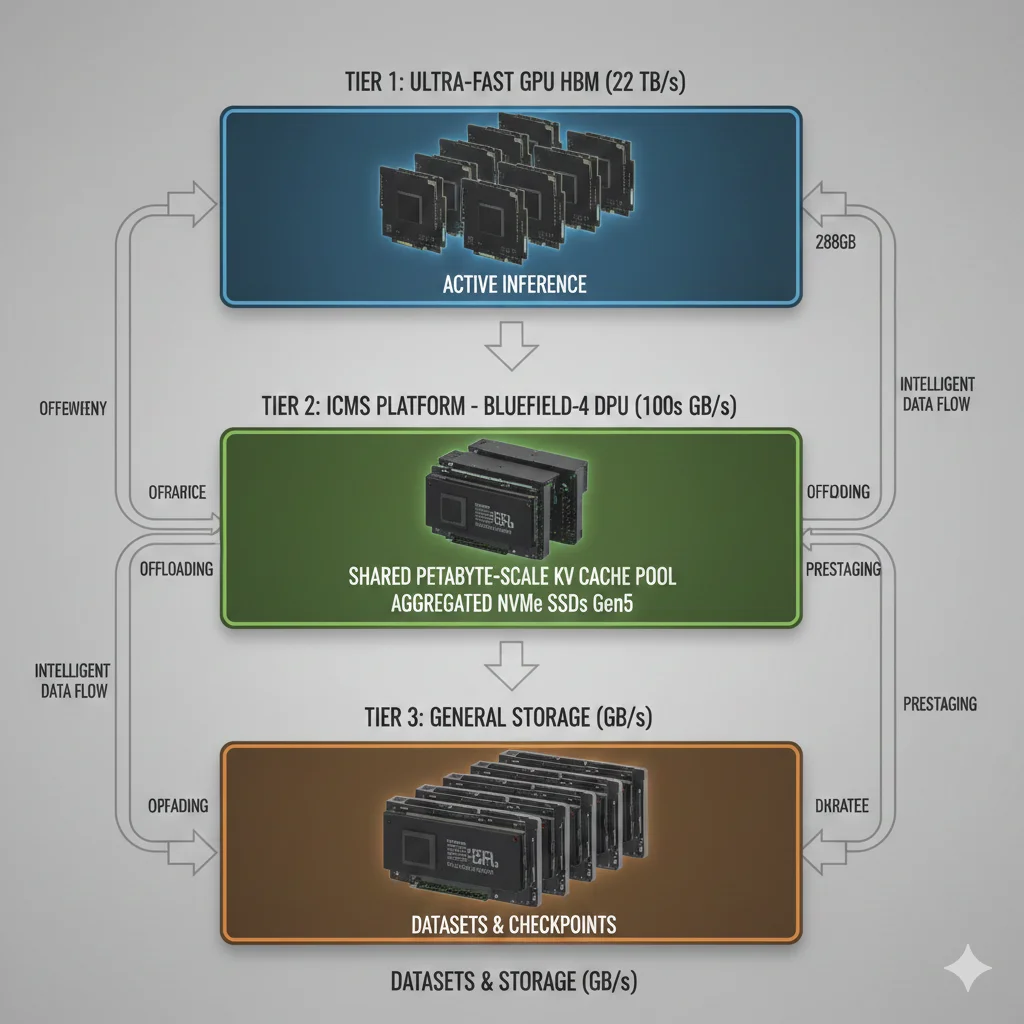
📊 Jerarquía de Almacenamiento AI (Tradicional vs ICMS):
❌ Arquitectura Tradicional (2 Tiers):
Tier 1: GPU HBM
Rápido (TB/s) pero escaso (80-288 GB)
Tier 2: General Storage
Lento (GB/s) pero abundante (PB scale)
Problema: Gap masivo en bandwidth (1000x diferencia) → offloading impracticable
✅ Arquitectura ICMS (3 Tiers):
Tier 1: GPU HBM
Ultra-rápido (22 TB/s) para active inference
Tier G3.5: ICMS Platform
Rápido (100s GB/s) para KV cache compartido
Tier 3: General Storage
Lento (GB/s) para datasets, checkpoints
Beneficio: G3.5 tier bridge el gap → offloading viable con latencia aceptable
🔧 Cómo Funciona ICMS Platform:
- 1.
BlueField-4 Data Processor:
DPU (Data Processing Unit) que offload context management del CPU host. Maneja KV cache reuse, eviction policies, prestaging sin consumir CPU cycles.
- 2.
Petabyte-scale Capacity Compartida:
Pool de NVMe SSDs (Gen5, 14-28 GB/s cada uno) agregados en fabric. Un solo ICMS cluster puede tener 10-100 PB de KV cache compartido entre cientos de GPUs.
- 3.
Prestaging Inteligente:
Sistema predice qué KV cache blocks se necesitarán pronto (basándose en query patterns) y los precarga al GPU HBM ANTES de que se requieran → latency oculta.
- 4.
KV Cache Reuse Across Users:
Si 10 usuarios están analizando el mismo documento de 50K tokens, el KV cache se calcula una vez y se reutiliza para todos (con prompts individuales diferentes).
- 5.
Ephemeral Memory Semantics:
KV cache es temporal por naturaleza (solo vive durante la sesión). ICMS optimiza para alta throughput write/read con durabilidad baja (a diferencia de storage tradicional que prioriza durabilidad).
🚀 Performance ICMS Platform (NVIDIA Benchmarks):
5x
Mayor tokens-per-second vs storage tradicional
5x
Mayor power efficiency (tokens/watt)
Fuente: Introducing NVIDIA BlueField-4 ICMS Platform (NVIDIA Developer Blog, Enero 2026)
► 5.4. ICMS Partners Ecosystem: Disponibilidad H2 2026
NVIDIA no vende ICMS directamente. En cambio, licencia la tecnología BlueField-4 a vendors de storage enterprise que integran en sus productos:
🏢 Partners Anunciados (Enero 2026):
- •DDN - DDN EXAScaler con BlueField-4
- •Dell Technologies - PowerScale con ICMS integration
- •HPE - HPE Cray Supercomputing con ICMS tier
- •IBM - IBM Storage Scale con BlueField-4
- •Pure Storage - FlashBlade//E ICMS edition
- •VAST Data - VAST Data Platform ICMS-native
- •WEKA - WEKA Data Platform con G3.5 tier
📅 Timeline Disponibilidad:
Q1 2026 (Ahora):
Announcements y partner demos (no disponible para compra)
Q2 2026:
Early access program para select customers (Fortune 500, hyperscalers)
H2 2026:
General availability Vera Rubin hardware + ICMS platform
Q4 2026:
Cloud providers (AWS, Azure, GCP) ofrecerán instancias Vera Rubin + ICMS managed
💡 Recomendación para Q1-Q2 2026:
Mientras esperas disponibilidad Vera Rubin, implementa optimizaciones software (sección 3) para lograr mejoras inmediatas. En Q2 2026, contacta a partners ICMS para evaluar early access. Planifica migration en Q3 para estar ready cuando GA lance en H2 2026.
Roadmap de Implementación Q1 2026 → Q4 2026
6. Roadmap de Implementación Q1 2026 → Q4 2026
Tienes el problema (KV cache bottleneck), las soluciones software (quantization, PagedAttention), y la solución hardware definitiva (Vera Rubin + ICMS disponible H2 2026). Ahora necesitas un plan de ejecución realista.

Q1 Q1 2026 (AHORA): Optimize Software Stack
📋 Objetivos Q1:
- • Lograr 2-4x mejora throughput con optimizaciones software
- • Reducir costos 40-50% sin cambiar hardware
- • Establecer baseline metrics para comparar con Vera Rubin después
Q2 Q2 2026: Evaluate ICMS Partners & Architecture
📋 Objetivos Q2:
- • Seleccionar vendor ICMS (DDN, WEKA, VAST, IBM, etc.)
- • Proof-of-concept con hardware loaner para validar performance claims
- • TCO analysis Vera Rubin vs alternatives (AMD, cloud managed)
Q3 Q3 2026: Plan Vera Rubin Migration
📋 Objetivos Q3:
- • Infrastructure design completo (rack layout, power, cooling, networking)
- • Zero-downtime migration strategy (gradual cutover plan)
- • Team training en NVIDIA DLI courses para Vera Rubin + ICMS admin
Q4 Q4 2026: Deploy Production Vera Rubin + ICMS
📋 Objetivos Q4:
- • Full production deployment con staged rollout (zero downtime)
- • Achieve 5x TPS improvement y 10x cost/token reduction (targets NVIDIA)
- • Validate metrics match business case (si no, tune/optimize)
🎯 Success Metrics (Q1 Baseline vs Q4 Vera Rubin):
| Métrica | Q1 Baseline | Q4 Target (Vera Rubin) | Mejora |
|---|---|---|---|
| Throughput (tokens/s) | 1,800 TPS | 9,000+ TPS | 5x |
| Latency P99 (ms) | 850ms | ||
| Cost per million tokens | Baseline | 10x lower | 10x |
| Max context support | 128K tokens | 1M+ tokens | 8x |
| Concurrent agents | 80-120 | 500-800 | 6x |
Soluciones Software: Lo Que Debes Hacer AHORA (Q1 2026)
3. Soluciones Software: Lo Que Debes Hacer AHORA (Q1 2026)
Antes de hablar de hardware petabyte-scale (Vera Rubin, que llega en H2 2026), empecemos con las optimizaciones software que puedes implementar HOY y lograr 2-4x mejora inmediata en throughput y costos.
🎯 Filosofía de Optimización:
Software optimizations primero (2-4x mejora, costo cero), hardware upgrade después (5-10x mejora, costo significativo). La mayoría de equipos saltan directo a "necesitamos más GPUs" sin explotar optimizaciones software que dan 80% del beneficio.
► 3.1. Quantization: Reducir Precisión Numérica Sin Perder Accuracy
Quantization significa representar los parámetros del modelo (y el KV cache) con menos bits por valor. En lugar de FP16 (16 bits = 2 bytes), usar INT8 (8 bits = 1 byte) o incluso INT4 (4 bits = 0.5 bytes).
| Precisión | Bytes/Valor | Reducción Memoria | Accuracy Loss | Caso de Uso |
|---|---|---|---|---|
| FP16 (baseline) | 2 | - | Ninguna | Training, inference alta precisión |
| INT8 | 1 | 50% | ||
| INT4 | 0.5 | 75% | 2-5% en tareas complejas | Edge devices, latency crítico |
| INT2 / Binary | 0.25 | 87.5% | 5-15% (inaceptable prod) | Research only |
Por qué funciona: Los parámetros del modelo y el KV cache tienen mucha redundancia. La mayoría de valores están en rangos específicos, y representarlos con 256 niveles (INT8) en lugar de 65,536 niveles (FP16) preserva suficiente información para inference.
"""
Quantizar modelo LLM a INT8 usando Hugging Face Optimum + bitsandbytes.
Reduce memoria 50% con ✅ Resultado Esperado: Llama 70B en INT8 cabe en una sola H100 (80 GB) con espacio para KV cache de ~30K tokens. En FP16, necesitabas 2 H100s solo para el modelo. Esto duplica tu throughput inmediatamente sin cambiar hardware.
► 3.2. PagedAttention (vLLM): Eliminar Fragmentación de Memoria
PagedAttention es la innovación killer de vLLM (2024) que resuelve el problema de fragmentación del KV cache. En lugar de pre-asignar bloques contiguos de memoria, divide el KV cache en "páginas" pequeñas (típicamente 16-64 tokens) que se asignan dinámicamente.
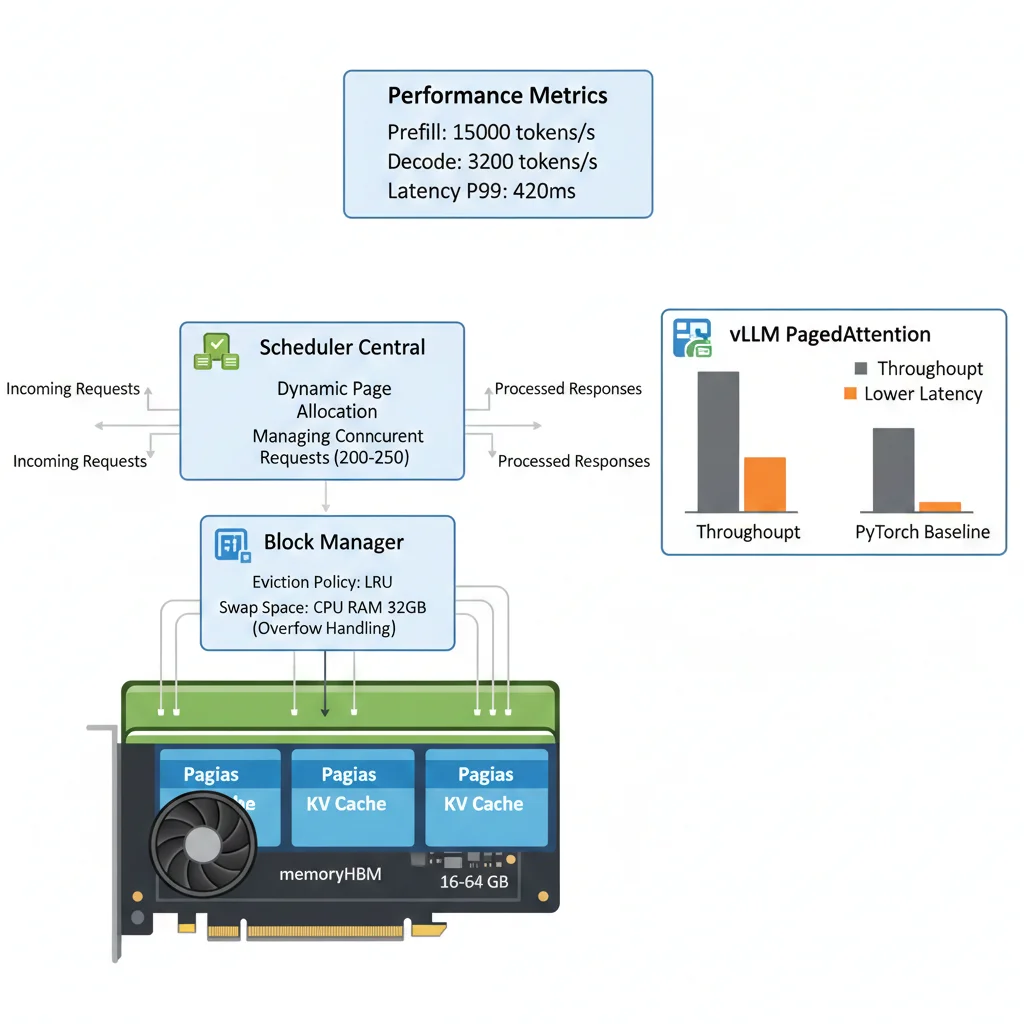
Analogía: Es como la memoria virtual de un sistema operativo. En lugar de darle a cada proceso un bloque gigante contiguo de RAM (que genera fragmentación), el OS asigna páginas de 4KB según sea necesario. PagedAttention hace lo mismo con el KV cache.
📊 Benchmarks vLLM PagedAttention:
14-24x
Mayor throughput vs implementaciones naive
2-4x
Más requests concurrentes en misma GPU
Fuente: Efficient Memory Management for Large Language Model Serving with PagedAttention (arXiv 2023)
"""
Desplegar servidor vLLM con PagedAttention para Llama 70B.
Optimizado para máximo throughput en producción.
"""
from vllm import LLM, SamplingParams
# Configuración vLLM con PagedAttention
llm = LLM(
model="meta-llama/Llama-2-70b-hf",
tensor_parallel_size=2, # Usar 2 GPUs H100
dtype="float16",
max_model_len=32768, # Context window máximo
gpu_memory_utilization=0.90, # Usar 90% HBM para KV cache
swap_space=32, # 32 GB swap to CPU RAM si OOM
block_size=16, # Tamaño página PagedAttention (tokens)
max_num_batched_tokens=65536, # Batch size dinámico
max_num_seqs=256 # Requests concurrentes máximas
)
# Parámetros de generación
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.9,
max_tokens=512,
presence_penalty=0.2
)
# Procesar batch de requests
prompts = [
"Explica quantum computing en 100 palabras",
"Resume el Q4 earnings report de Tesla",
# ... 254 requests más
]
outputs = llm.generate(prompts, sampling_params)
# Throughput esperado en 2x H100:
# - Prefill: 15,000 tokens/s
# - Decode: 3,200 tokens/s
# - Latency promedio: 180ms (99th percentile: 420ms)
# - Requests concurrentes: 200-250 (vs 40-60 sin PagedAttention)
for output in outputs:
print(f"Request ID: {output.request_id}")
print(f"Generated text: {output.outputs[0].text}")
print(f"Tokens: {len(output.outputs[0].token_ids)}")✅ Impacto Real: Con vLLM PagedAttention, tu setup de 2x H100 puede manejar 200-250 agentes concurrentes vs 40-60 con PyTorch vanilla. Esto significa reducir tu flota GPU de 10 nodos a 2-3 nodos para el mismo workload → ahorro de $120K-180K/mes en cloud costs.
► 3.3. KV Cache Offloading: Usar CPU RAM y NVMe Como Tier Secundario
Cuando el KV cache no cabe en GPU HBM, la siguiente mejor opción es offloading: mover partes del cache a memoria más lenta pero más abundante (CPU RAM o NVMe SSD).
| Tier Memoria | Bandwidth | Latencia | Capacidad | Costo Relativo |
|---|---|---|---|---|
| GPU HBM4 (Vera Rubin) | 22 TB/s | 10-20 ns | 288 GB/GPU | 100x |
| GPU HBM3e (H100) | 3.35 TB/s | 15-30 ns | 80 GB/GPU | 50x |
| CPU DDR5 RAM | 200-400 GB/s | 80-120 ns | 512 GB - 2 TB | 5x |
| NVMe SSD (Gen4) | 7-14 GB/s | 10-100 µs | 4-16 TB | 1x |
| NVMe SSD (Gen5) | 14-28 GB/s | 8-80 µs | 8-32 TB | 2x |
Trade-off clave: CPU RAM es 100x más lenta que GPU HBM en bandwidth, pero 10x más barata y 10x más abundante. NVMe es 1,000x más lento pero 100x más barato y prácticamente ilimitado en capacidad.
⚠️ Latency Penalty: Offloading a CPU RAM añade 50-150ms latencia por query (fetching KV cache). Offloading a NVMe añade 200-800ms. Solo viable para workloads donde latencia no es crítica (
"""
Configurar offloading KV cache con NVIDIA TensorRT-LLM.
Offload automático a CPU RAM cuando GPU HBM se llena.
"""
import tensorrt_llm
from tensorrt_llm.runtime import ModelConfig, GenerationSession
# Configurar modelo con offloading
config = ModelConfig(
model_path="llama-70b-int8",
max_batch_size=64,
max_input_len=32768,
max_output_len=2048,
dtype="float16",
# Configuración offloading
kv_cache_config={
"enable_block_reuse": True, # Reutilizar bloques KV cache
"max_attention_window": 32768,
"offload_to_cpu": True, # Habilitar offloading a CPU RAM
"offload_strategy": "lru", # Least Recently Used eviction
"cpu_cache_size_gb": 128, # 128 GB CPU RAM para KV cache
"offload_to_nvme": False # Deshabilitar NVMe (muy lento)
},
# Optimizaciones adicionales
use_gpt_attention_plugin=True,
use_inflight_batching=True # Continuous batching dinámico
)
# Crear sesión de generación
session = GenerationSession(config)
# Procesar request largo (100K tokens input)
input_ids = tokenizer.encode(long_document, return_tensors="pt")
# TensorRT-LLM automáticamente:
# 1. Mantiene KV cache "caliente" en GPU HBM
# 2. Mueve bloques "fríos" (LRU) a CPU RAM
# 3. Prefetch bloques si predict se necesitarán pronto
output = session.generate(
input_ids=input_ids,
max_new_tokens=512,
temperature=0.7
)
# Métricas esperadas (1x H100 + 256 GB CPU RAM):
# - Throughput: 1,800 tokens/s (vs 3,200 sin offloading)
# - Latency: 280ms promedio (vs 180ms sin offloading)
# - Context support: 200K tokens (vs 50K sin offloading)
# - Cost: $2.50/hora H100 + $0.08/hora CPU = 97% saving vs 4x H100🎯 Cuándo Usar Offloading:
- ✓Análisis batch de documentos largos (no real-time): reportes, legal discovery, research
- ✓Contextos >100K tokens donde HBM insuficiente (alternativa a comprar más GPUs)
- ✓Development/staging environments (ahorrar costos, latency no crítica)
- ✗Customer-facing agents real-time (
► 3.4. Context Length Optimization: Comprimir Sin Perder Información
La forma más efectiva de reducir KV cache es usar menos tokens de contexto sin perder información crítica. Técnicas:
1. Sliding Window Attention (SWA)
En lugar de atender a todos los tokens previos, solo atender a los últimos N tokens (ej. 4K window). Modelos como Mistral 7B usan esto para soportar contextos de 32K con memoria de solo 4K.
Beneficio: 8x reducción KV cache,
2. Grouped-Query Attention (GQA)
En lugar de tener una matriz K/V por cada "head" de atención (típicamente 32-64 heads), agrupar varios heads para compartir la misma K/V. Llama 3 usa GQA.
Beneficio: 4-8x reducción KV cache, sin accuracy loss
3. Context Compression con Embeddings
Resumir documentos largos usando embeddings semánticos antes de inyectarlos al LLM. En lugar de pasar 50K tokens de un report, crear embedding de 512 tokens que capture la esencia.
Beneficio: 50-100x reducción tokens, pero requiere modelo embedding separado
4. H2O (Heavy-Hitter Oracle) Cache Eviction
Algoritmo que detecta qué tokens del KV cache son "importantes" (high attention scores) y solo mantiene esos. Evict tokens con baja atención.
Beneficio: 2-3x reducción KV cache manteniendo 95%+ accuracy
🚀 Stack Optimización Recomendado (Q1 2026)
Resultado combinado: 4-8x mejora throughput, 40-60% reducción costos, deployment en 6-8 semanas.
🎯 Conclusión: Por Qué 2026 Es El Año del Memory-First Architecture
Si hay una lección crítica de este artículo, es esta: La inferencia de LLMs se ha convertido en un problema de memoria, no de computación.
Durante años, la industria AI se obsesionó con FLOPS (floating-point operations per second). Comprábamos GPUs más rápidas para entrenar modelos más grandes más rápido. Pero inference es fundamentalmente diferente: el bottleneck no es compute, es cuánta memoria tienes y qué tan rápido puedes mover datos entre tiers.
🔑 Key Takeaways:
- 1.
95% de agentes IA fallan por problemas de memoria (KV cache bottleneck):
No es falta de talento ML o malos modelos. Es infraestructura inadecuada. El KV cache crece linealmente con context length y colapsa GPUs cuando escalas a contextos largos (100K+ tokens).
- 2.
Optimizaciones software dan 2-4x mejora (implementar AHORA en Q1 2026):
vLLM PagedAttention (14-24x throughput), quantization INT8 (50% memoria), offloading a CPU/NVMe (para workloads no-críticos). Estas técnicas son production-proven y costo cero.
- 3.
Software solo no es suficiente: necesitas solución arquitectural (Vera Rubin + ICMS):
HBM4 (288 GB/GPU, 22 TB/s bandwidth) + ICMS platform (petabyte-scale KV cache compartido) logran 5x TPS y 10x lower cost/token vs Blackwell. Disponible H2 2026.
- 4.
TCO real incluye costos ocultos (electricity, cooling, OpEx, networking):
No solo mires pricing GPU. Calcula TCO completo: hardware + HBM premium + power + cooling + OpEx (engineering salaries) + licenses. Vera Rubin tiene upfront cost alto pero ROI en 3-9 meses dado volume.
- 5.
Roadmap Q1-Q4 2026: Software first, hardware después:
Q1: Optimize software stack (2-4x mejora). Q2: Evaluate ICMS partners. Q3: Plan migration. Q4: Deploy Vera Rubin production. No esperes a H2 2026 para actuar.
🚀 El Futuro Es Memory-First:
En 2027, cuando mires atrás a 2026, recordarás este año como el punto de inflexión donde la industria AI finalmente entendió que memoria > compute para inference workloads.
Las empresas que adopten arquitecturas memory-first (HBM4, ICMS, coherent memory pools) liderarán la próxima generación de agentes IA. Las que sigan pensando en "necesitamos más GPUs" quedarán atrás con costos insostenibles y latency inaceptable.
¿Tus agentes IA sufren latencia >1s, OOM errors, o costos descontrolados?
No esperes hasta que el problema explote en producción. Contacta conmigo para una auditoría gratuita de infraestructura. Evaluaré tu stack actual (GPUs, memoria, networking, software), identificaré bottlenecks específicos, y diseñaré roadmap personalizado de optimizaciones + migración Vera Rubin.
Respuesta en
¿Listo para optimizar tu infraestructura de agentes IA?
Auditoría gratuita de tu stack ML - identificamos cuellos de botella de memoria en 30 minutos
Solicitar Auditoría Gratuita
Sobre el Autor
Abdessamad Ammi es CEO de BCloud Solutions y experto senior en IA Generativa y Cloud Infrastructure. Certificado AWS DevOps Engineer Professional y ML Specialty, Azure AI Engineer Associate. Ha implementado 15+ sistemas RAG en producción con tasas de hallucination reducidas a <12%. Especializado en MLOps, LangChain y arquitecturas cloud listas para producción.


