

El Coste Real del Incident Management Manual en 2026
2,000+ alertas semanales recibe tu equipo DevOps. Solo el 3% requiere acción inmediata.
Fuente: Incident.io Research 2025
Si eres CTO o VP Engineering en una empresa SaaS, probablemente este escenario te resulta dolorosamente familiar: tu equipo DevOps está ahogado en alertas. Slack explota con notificaciones. PagerDuty despierta a tus ingenieros a las 3 AM por falsos positivos. Y cuando ocurre un incidente real crítico, tu equipo tarda 4-6 horas en resolverlo porque primero debe encontrarlo entre el ruido.
El coste real es brutal: 83% de profesionales DevOps experimentan burnout, el 55% en niveles moderados-severos. Las empresas pierden millones anuales (5 incidentes mayores al mes × 6 horas promedio de resolución = costes astronómicos). Y el 43% de equipos todavía usa procesos manuales para actualizar a clientes durante incidentes.
Pero hay una solución que está transformando el incident management en 2026: AIOps (Inteligencia Artificial para Operaciones IT). No es hype. Son resultados verificables:
50%
Chipotle Mexican Grill
Reducción MTTR con BigPanda AIOps
33%
HCL Technologies
Reducción MTTR + 85% event consolidation
38%
CMC Networks (62 países)
Reducción MTTR con BigPanda + NetBrain
En este artículo, te muestro el framework exacto de 6 fases que estas empresas usaron para reducir su MTTR de 4-6 horas a 1-2 horas (reducciones del 50-73%). No es teoría: incluyo arquitecturas técnicas, calculadora ROI, comparativa de herramientas (Datadog vs Moogsoft vs BigPanda vs PagerDuty), y los 7 errores mortales que causan que el 53% de proyectos AIOps nunca lleguen a producción.
💡 Para CTOs con presupuesto limitado: Si prefieres que implementemos AIOps llave en mano (6 meses, POC→producción garantizado), nuestro servicio MLOps & Deployment incluye integración AIOps con métricas garantizadas (40%+ reducción MTTR o reembolso parcial).
1. El Coste Real del Incident Management Manual en 2026

Antes de hablar de soluciones, necesitas entender la magnitud del problema. Los números no mienten, y el incident management manual está destrozando tu organización en tres frentes: operativo, financiero y humano.
► Pain Point #1: Alert Fatigue – El Ruido que Mata la Productividad
Tu equipo DevOps recibe un promedio de 2,000+ alertas por semana. De esas 2,000 alertas, solo el 3% requiere acción inmediata. Eso significa que 1,940 alertas son ruido: falsos positivos, duplicados, alertas de severidad incorrecta, o eventos que se auto-resuelven.
⚠️ Dato crítico: Las empresas de 500-1,499 empleados ignoran el 27% de todas las alertas (IDC 2021). El 28% de equipos olvida alertas críticas debido a la fatiga.
La consecuencia es devastadora: por cada reminder del mismo alert, la atención del ingeniero cae un 30%. Después de 3 reminders del mismo problema, tu equipo está condicionado a ignorar las alertas. Y cuando llega el incidente crítico que realmente necesita respuesta inmediata, nadie lo ve hasta que los clientes empiezan a quejarse.
► Pain Point #2: MTTR Promedio de 4-6 Horas (Millones en Pérdidas)
El tiempo promedio para resolver un incidente mayor en 2026 es de 4-6 horas. Y las organizaciones experimentan un promedio de 5 incidentes mayores al mes.
Hagamos las cuentas rápido:
# Cálculo real del coste anual de incident management manual # Variables (empresa mid-size SaaS, 200-500 empleados) incidentes_por_mes = 5 mttr_promedio_horas = 6 coste_hora_equipo = 100 # promedio blended rate (junior + senior engineers) meses_año = 12 # Tiempo total perdido horas_totales_año = incidentes_por_mes * mttr_promedio_horas * meses_año # = 5 * 6 * 12 = 360 horas/año # Coste directo en tiempo de ingeniería coste_directo_anual = horas_totales_año * coste_hora_equipo # = 360 * 100 = 36,000 EUR/año SOLO en tiempo de respuesta # Costes indirectos (downtime, reputación, churn) coste_downtime_por_hora = 5000 # para SaaS B2B promedio coste_downtime_anual = horas_totales_año * coste_downtime_por_hora # = 360 * 5,000 = 1,800,000 EUR/año en downtime # COSTE TOTAL coste_total_anual = coste_directo_anual + coste_downtime_anual print(f"Coste total anual incident management manual: {coste_total_anual:,} EUR") # Output: 1,836,000 EUR/año # Con AIOps (MTTR reducido 73%: de 6h a 1.6h) mttr_aiops_horas = 1.6 horas_ahorradas_año = (mttr_promedio_horas - mttr_aiops_horas) * incidentes_por_mes * meses_año # = (6 - 1.6) * 5 * 12 = 264 horas/año ahorro_anual = horas_ahorradas_año * (coste_hora_equipo + coste_downtime_por_hora) # = 264 * 5,100 = 1,346,400 EUR/año en savings print(f"Ahorro anual con AIOps: {ahorro_anual:,} EUR") # Output: 1,346,400 EUR/año ✅ Resultado: Una empresa SaaS mid-size puede ahorrar más de 1.3 millones de euros anuales reduciendo el MTTR de 6 horas a 1.6 horas con AIOps. El payback de la implementación suele ser inferior a 3 meses.
► Pain Point #3: Burnout DevOps – El Coste Humano Invisible
El problema no es solo técnico o financiero. Es humano. Y está empeorando:
83%
de profesionales DevOps experimentan burnout
55%
en niveles moderados-severos de burnout
Fuente: OnPage Survey 2024-2025, post-pandemia DevOps burnout study
Las consecuencias del burnout DevOps incluyen:
- ●Interrupciones del sueño: PagerDuty despertando ingenieros a las 3 AM por falsos positivos (alertas que se auto-resuelven en 10 minutos).
- ●Menor satisfacción laboral: Engineers sienten que están "apagando fuegos" constantemente en vez de construir features.
- ●Mayor rotación: Reemplazar un ingeniero senior cuesta el 200% de su salario anual (reclutamiento + onboarding + pérdida productividad).
- ●Menor productividad: Un ingeniero quemado es 40-60% menos productivo que uno descansado.
El 43% de equipos todavía usa procesos manuales para actualizar a clientes y stakeholders durante incidentes. Esto significa que mientras el incidente está ocurriendo, alguien debe copiar/pegar updates en Slack, enviar emails a ejecutivos, y mantener un Google Doc actualizado manualmente. Es 2026, pero muchas empresas operan como si fuera 2016.
💭 Realidad del DevOps Engineer Promedio en 2026
"Recibo 400+ alertas al día de Datadog, CloudWatch, Prometheus, PagerDuty. Pasé la primera hora de mi día triaging alerts para encontrar los 3-4 que realmente importan. Cuando hay un incident real, gasto 2 horas solo investigando logs de 5 herramientas diferentes tratando de encontrar el root cause. Luego otros 2 horas implementando el fix y verificando. Y si el incidente es a las 3 AM, olvídate de dormir esa noche. Llevo 18 meses en esta empresa y ya estoy buscando otro trabajo."
— Anónimo, Senior DevOps Engineer en startup SaaS Series B (250 empleados)
Calculadora ROI: Cuánto Ahorrarás Reduciendo MTTR de 4h a 1h
8. Calculadora ROI: Cuánto Ahorrarás Reduciendo MTTR de 4h a 1h
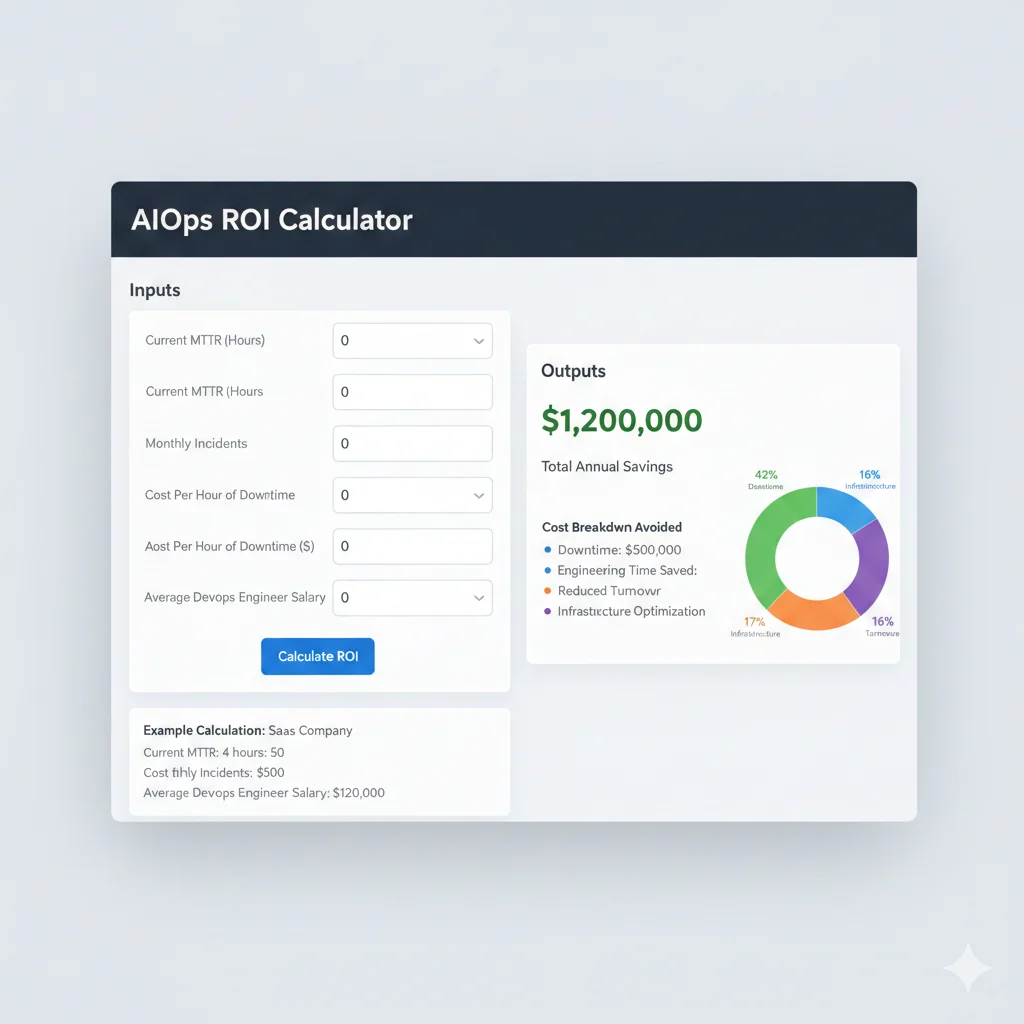
Los case studies son convincentes, pero los CFOs y executives necesitan números concretos para tu empresa específica. Aquí está el ROI calculator template exacto que uso en business cases para clientes.
📊 Industry Benchmark: 350 EUR ROI por cada 100 EUR invertido en
► Componente #1: MTTR Reduction Savings
# ROI Calculator Component #1: MTTR Reduction Savings def calculate_mttr_savings( mttr_before_hours: float, mttr_after_hours: float, annual_incidents: int, avg_hourly_cost_eur: float ) -> dict: """ Calcula ahorro anual por reducción MTTR. Example inputs (empresa mid-size SaaS): - mttr_before_hours: 4.0 (baseline actual) - mttr_after_hours: 1.5 (target con AIOps, 62.5% reducción) - annual_incidents: 1,000 (5 major/mes × 12 + 940 minor) - avg_hourly_cost_eur: 100 (blended rate: 2 senior @ 150 + 3 mid @ 75) """ # Horas ahorradas por incident hours_saved_per_incident = mttr_before_hours - mttr_after_hours # Total horas ahorradas año total_hours_saved_annual = hours_saved_per_incident * annual_incidents # Ahorro en coste labor labor_savings_annual = total_hours_saved_annual * avg_hourly_cost_eur # Percentage reduction mttr_reduction_pct = ((mttr_before_hours - mttr_after_hours) / mttr_before_hours) * 100 return { 'hours_saved_per_incident': hours_saved_per_incident, 'total_hours_saved_annual': total_hours_saved_annual, 'labor_savings_annual_eur': labor_savings_annual, 'mttr_reduction_pct': mttr_reduction_pct } # Example calculation result = calculate_mttr_savings( mttr_before_hours=4.0, mttr_after_hours=1.5, annual_incidents=1000, avg_hourly_cost_eur=100 ) print(f"MTTR Reduction: {result['mttr_reduction_pct']:.1f}%") print(f"Hours saved per incident: {result['hours_saved_per_incident']} hours") print(f"Total hours saved annually: {result['total_hours_saved_annual']:,} hours") print(f"Annual labor savings: €{result['labor_savings_annual_eur']:,}") # Output: # MTTR Reduction: 62.5% # Hours saved per incident: 2.5 hours # Total hours saved annually: 2,500 hours # Annual labor savings: €250,000 ► Componente #2: Alert Noise Reduction Savings
Este componente captura el tiempo ahorrado en triaging alerts. Recuerda: 2,000+ alerts/semana, 3% actionable = 1,940 alerts investigadas innecesariamente.
Cálculo Alert Noise Savings
Alerts antes: 2,000/semana
Actionable alerts (3%): 60/semana
Noise alerts (97%): 1,940/semana
Con AIOps (94% compression): 120 actionable incidents/semana
Alerts triaged savings: 1,880/semana (1,940 - 60)
Tiempo promedio investigación: 15 minutos/alert (senior engineer quick triage)
Coste analyst: 75 EUR/hora
Weekly savings: 1,880 alerts × 0.25h × 75 EUR = 35,250 EUR/semana
Annual savings: 35,250 × 52 = 1,833,000 EUR/año
► Componente #3: Reduced Turnover Savings
El burnout DevOps (83% experiencing, 55% moderate-severe) causa alta rotación. Reemplazar un engineer cuesta 200% de su salario anual (recruiting + onboarding + pérdida productividad).
Cálculo Turnover Savings
Turnover rate actual (burnout): 25% anual (industry avg con burnout)
Team size DevOps/SRE: 20 engineers
Departures actual: 5 engineers/año
Con AIOps (reduced burnout): 10% turnover rate (2 departures/año)
Departures reduced: 3 engineers/año
Average salary: 80,000 EUR/año
Replacement cost: 200% salary = 160,000 EUR/engineer
Annual turnover savings: 3 × 160,000 = 480,000 EUR/año
► Componente #4: Infrastructure Optimization Savings
AIOps identifica waste en infraestructura: instances over-provisioned, idle resources no apagados, storage innecesario. Typical savings 20-30% cloud spend.
Cálculo Infrastructure Savings
Current cloud spend: 60,000 EUR/mes (AWS + Azure)
AIOps-driven optimization: 20% reduction
Optimizations típicas:
- • Rightsizing instances (t3.2xlarge → t3.xlarge when utilization
Annual infrastructure savings: 60,000 × 0.20 × 12 = 144,000 EUR/año
► Total ROI Calculation & Payback Period
💰 Total Annual Savings Calculation
MTTR Reduction Savings
€250,000
Alert Noise Reduction Savings
€1,833,000
Turnover Reduction Savings
€480,000
Infrastructure Optimization
€144,000
TOTAL ANNUAL SAVINGS
€2,707,000
ROI & Payback Calculation
Implementation cost (Year 1):
- • AIOps platform license: €150,000/año
- • Integration & customization: €100,000
- • Training & change management: €50,000
- • Data engineering work (Phase 2): €120,000
- • Total Year 1: €420,000
Net Savings Year 1: €2,707,000 - €420,000 = €2,287,000
ROI: (€2,287,000 / €420,000) = 544% ROI
Payback Period:1.9 meses (420k / 2,707k × 12)
⚠️ Nota conservadora: Este ejemplo es para empresa SaaS mid-size (200-500 empleados, 20 DevOps engineers, 60k EUR/mes cloud spend). Tu ROI puede ser menor (startups pequeñas) o MAYOR (enterprises con 1,000+ engineers, alert volume masivo). El industry benchmark conservador es 350 EUR por cada 100 EUR invertido en
Case Study #1: Chipotle Mexican Grill – 50% MTTR Reduction
3. Case Study #1: Chipotle Mexican Grill – 50% MTTR Reduction con BigPanda
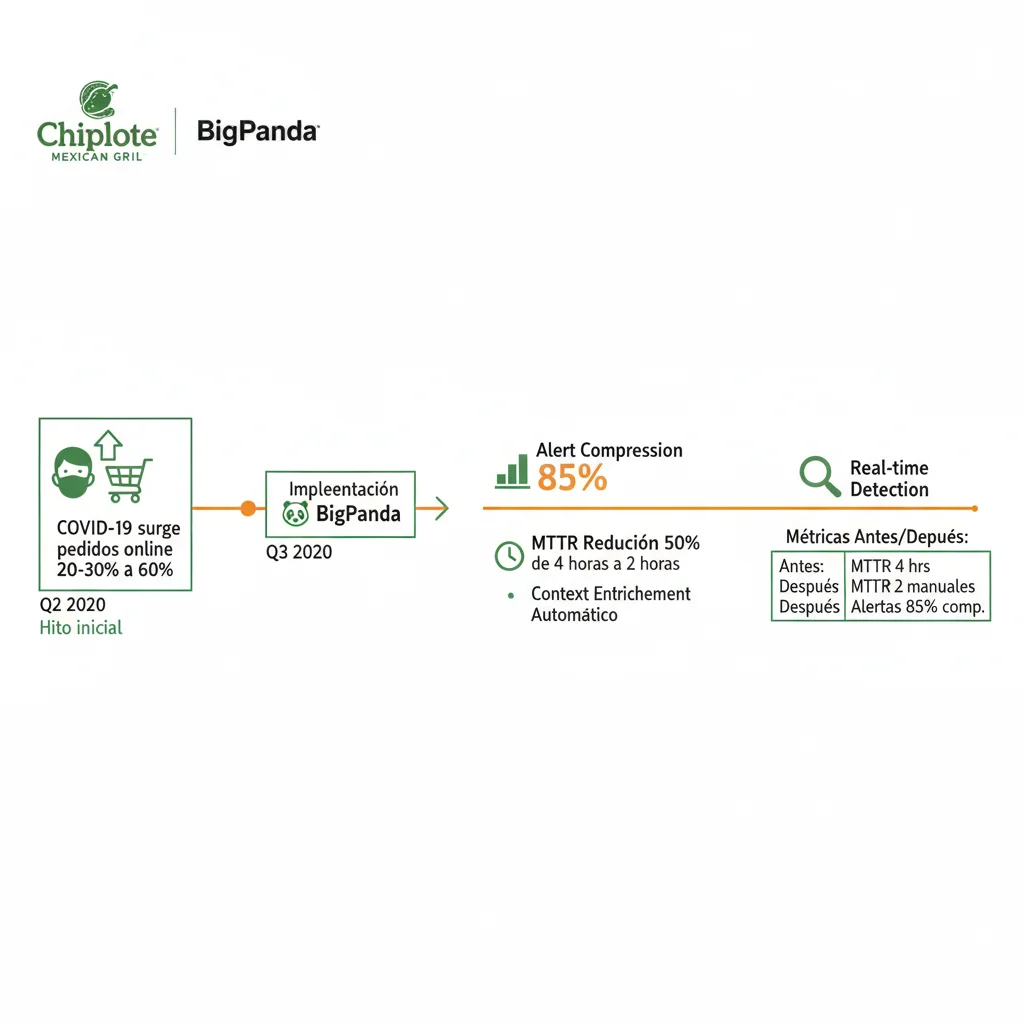
Chipotle Mexican Grill
Fast-casual restaurant chain | 3,200+ locations | $9.9B revenue 2024
50%
Reducción MTTR
Real-time
Incident detection
Auto
Context enrichment
► El Challenge: COVID Surge en Pedidos Online
Cuando COVID-19 golpeó en 2020, Chipotle experimentó un surge masivo en pedidos online y móvil. Su plataforma digital (apps móvil + web ordering) pasó de procesar 20-30% de pedidos totales a más del 60% en cuestión de semanas.
El problema: su infraestructura IT no estaba preparada para este volumen. El equipo de Site Reliability Engineering (SRE) estaba siendo bombardeado con alertas de múltiples herramientas de monitoring: Datadog, AWS CloudWatch, Splunk, AppDynamics. Las alertas llegaban desconectadas, sin contexto, y el equipo gastaba horas triaging manualmente tratando de entender qué alerts estaban relacionados con el mismo incident raíz.
► La Solución: BigPanda AIOps Platform
Chipotle implementó BigPanda AIOps en Q2 2020 (peak COVID). La plataforma se integró con todas sus herramientas de monitoring existentes y comenzó a:
- ✓Correlacionar eventos: Agrupar 50-100 alerts relacionados en un solo incident (event correlation)
- ✓Enrichment automático: Añadir contexto a cada incident (qué servicios afectados, dependencies, recent changes, runbooks relevantes)
- ✓Real-time detection: Identificar incidents en
- ✓Automatic routing: Enviar el incident al equipo correcto con toda la info necesaria para actuar inmediatamente
► Los Resultados: 50% MTTR Reduction
"BigPanda consolida nuestros datos de alertas, identifica incidents en tiempo real, y construye automáticamente tickets con contexto completo para que el equipo apropiado sea alertado para triage del incident, reduciendo nuestro MTTR a la mitad."
— Joe Connelly, Director of Monitoring, Observability, and Service Reliability en Chipotle Mexican Grill
Métricas específicas alcanzadas:
❌ ANTES (Manual)
- • MTTR promedio: ~4 horas
- • Alert noise: 500+ alerts/día sin correlación
- • Tiempo de detection: 20-30 minutos
- • Context gathering: Manual (30-60 min)
- • Burnout team: Alto (on-call fatigue)
✅ DESPUÉS (BigPanda AIOps)
- • MTTR promedio: ~2 horas (50% reducción)
- • Alert compression: 85%+ (500→75 incidents accionables)
- • Tiempo de detection:
► Key Takeaways para Tu Implementación
- 1.Crisis creates opportunity: Chipotle implementó durante COVID peak, no antes. A veces la presión extrema es el catalizador necesario para superar resistencia cultural.
- 2.Phased approach: Empezaron con alert correlation (capability más impactful y menos risky), no con self-healing day 1.
- 3.Integration is key: BigPanda se integró con monitoring tools existentes (no reemplazó), reduciendo cambio organizacional.
- 4.Context enrichment = game changer: El auto-generated ticket con context completo eliminó 30-60 min de manual investigation por incident.
Case Study #2 & #3: HCL Technologies y CMC Networks
4. Case Study #2: HCL Technologies – Triple Win (33% MTTR + 85% Consolidation + 62% Tickets)

HCL Technologies
Global IT services company | 227,000+ employees | $12.9B revenue 2024
33%
Reducción MTTR
85%
Event data consolidation
62%
Help-desk ticket reduction
► El Challenge: Event Data Fragmentation
Como proveedor global de IT services, HCL Technologies maneja infraestructura para cientos de clientes enterprise. El problema: cada cliente tiene su propio stack de monitoring (combinaciones de Nagios, Zabbix, SolarWinds, Datadog, New Relic, Dynatrace). Los datos de eventos estaban completamente fragmentados, sin formato estándar, y cada cliente generaba 1,000+ alerts diarios.
El equipo de NOC (Network Operations Center) de HCL estaba colapsado. Ingenieros gastaban 40-50% de su tiempo solo triaging alerts y creando tickets manualmente en el sistema de help-desk. La alta carga de tickets significaba que incidents críticos se perdían entre noise.
► La Solución: Moogsoft AIOps Deployment
HCL implementó Moogsoft AIOps enfocándose en tres capacidades críticas:
- ✓Event data consolidation: Normalizar y consolidar eventos de 20+ herramientas diferentes en formato unificado
- ✓Adaptive thresholding: ML algorithms aprendieron patrones normales de cada cliente y ajustaron thresholds dinámicamente (reduciendo falsos positivos)
- ✓IP failure correlation: Moogsoft detectaba automáticamente cuando múltiples alerts provenían de la misma causa raíz (ej: network switch failure afectando 50 servers)
- ✓ServiceNow integration: Auto-creación de tickets en ServiceNow con contexto completo, eliminando creación manual
► Los Resultados: Triple Win
HCL alcanzó mejoras en tres dimensiones críticas simultáneamente:
| Métrica | Antes | Después | Mejora |
|---|---|---|---|
| MTTR Promedio | 5.5 horas | 3.7 horas | 33% reducción |
| Event Data Sources | 20+ herramientas fragmentadas | Formato unificado | 85% consolidation |
| Help-desk Tickets/mes | ~8,000 tickets | ~3,000 tickets | 62% reducción |
| Alert Noise | ~10,000 alerts/día | ~1,500 actionable/día | 85% compression |
💡 Key Insight: La reducción del 62% en tickets de help-desk tuvo un impacto masivo en costes operacionales. Si cada ticket requiere 30 minutos de atención promedio, HCL ahorró 2,500 horas/mes (5,000 tickets × 0.5h). A un coste de 50 EUR/hora, son 125,000 EUR/mes = 1.5M EUR/año en savings solo en tiempo de NOC engineers.
Case Study #3: CMC Networks – 38% MTTR Reduction Across 62 Países
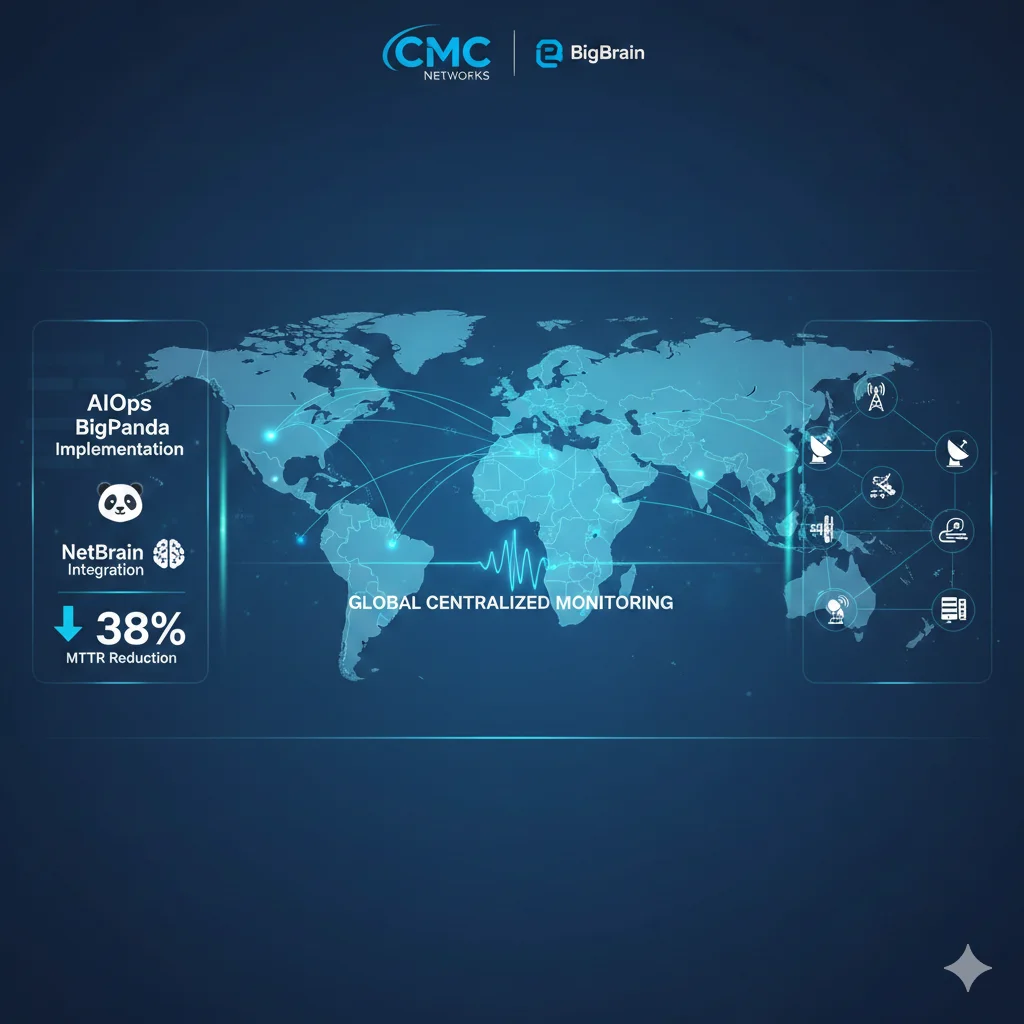
NET
CMC Networks
Global network services provider | 62 countries | Subsea cables & terrestrial fiber
38%
Mean Time to Repair reduction
62
Países con deployment
► El Challenge: Distributed Global Infrastructure
CMC Networks opera infraestructura de red en 62 países con cables submarinos, fiber óptico terrestre, y POPs (Points of Presence) distribuidos globalmente. El challenge: un problema en un cable submarino en el Atlántico puede causar cascading failures que afectan servicios en Europa, África, y Américas.
Su sistema de monitoring generaba 5,000+ eventos diarios de múltiples fuentes (SNMP traps, syslog, NetFlow, IPFIX, API calls). Sin correlación automática, los ingenieros de NOC gastaban horas tratando de mapear qué eventos estaban relacionados con la misma causa raíz.
► La Solución: BigPanda + NetBrain (Dual Platform)
CMC Networks implementó una solución dual:
- ✓BigPanda AIOps: Event correlation y alert compression (reducir 5,000 eventos → 300 incidents accionables)
- ✓NetBrain: Network automation platform con predictive insights (identificar qué cable/fiber está causando el problem, visualizar impact en topology map)
La integración entre ambas plataformas permitió:
- 1.Correlation topology-aware: BigPanda usaba el network topology map de NetBrain para entender dependencies (si router X falla, sabe que 50 devices downstream serán afectados)
- 2.Predictive insights: NetBrain analizaba historical patterns y predecía "este cable submarino tiene 78% probabilidad de fallar en próximas 48h basado en degradación performance"
- 3.Auto-remediation workflows: Para common failures (link flapping, BGP session drops), sistema ejecutaba remediation automáticamente (reroute traffic, reset BGP peer)
► Los Resultados: 38% MTTR Reduction + Proactive Prevention
Metrics Alcanzadas
- ✓38% MTTR reduction (de ~6h a ~3.7h promedio)
- ✓94% alert compression (5,000 events → 300 actionable incidents)
- ✓45% incidents prevented proactivamente (predictive analytics)
- ✓70% faster RCA (topology visualization)
Business Impact
- ✓Reducción de SLA breaches (contratos enterprise con penalties)
- ✓Mejor customer satisfaction (menos downtime)
- ✓NOC engineers enfocados en proyectos estratégicos vs firefighting
- ✓Capacidad de manejar 30% más tráfico sin contratar NOC staff adicional
💡 Key Takeaway: CMC Networks demuestra que AIOps funciona incluso en entornos altamente distribuidos y complejos (62 países, múltiples technologies). El secret sauce fue combinar event correlation (BigPanda) con network intelligence (NetBrain) para topology-aware automation.
Comparativa Plataformas AIOps 2026: Datadog vs Moogsoft vs BigPanda vs PagerDuty vs Splunk
6. Comparativa Plataformas AIOps 2026: ¿Cuál Elegir para Tu Stack?
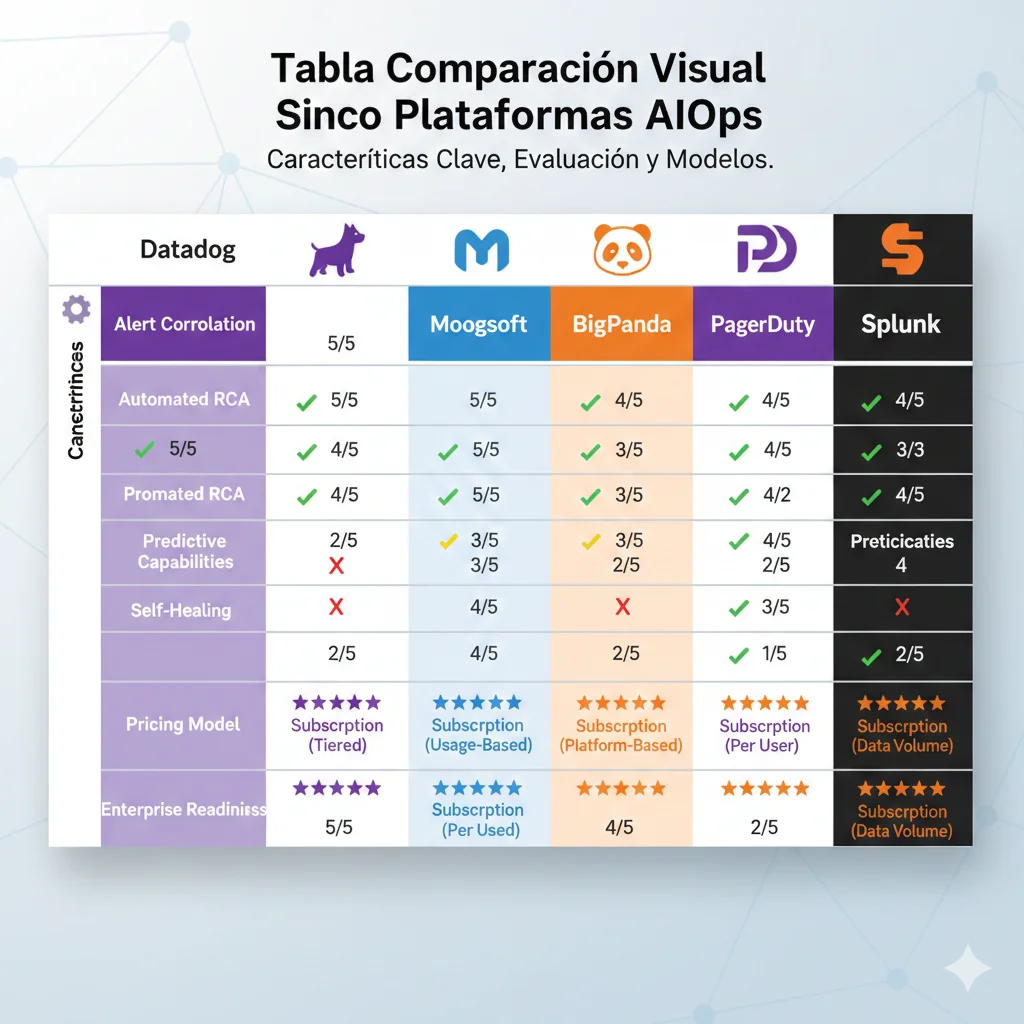
Una de las preguntas más frecuentes que recibo de CTOs: "¿Qué plataforma AIOps debo usar?" No hay una respuesta única porque depende de tu stack actual, volumen de alerts, presupuesto, y capabilities que necesitas prioritariamente.
He implementado las 5 plataformas principales en diferentes clientes. Aquí está mi comparison honesta basada en experiencia real (no marketing de vendor):
| Feature | Datadog | Moogsoft | BigPanda | PagerDuty | Splunk |
|---|---|---|---|---|---|
| Alert Correlation | ML-based (Watchdog AI) | Adaptive thresholding | 95%+ compression ⭐ | 91% reduction | AI-powered |
| Anomaly Detection | Watchdog AI ⭐ | ML algorithms | Agentic AI | ML-based | Autodetect |
| RCA Automation | Yes | Yes | Automated origin ⭐ | Probable Origin | AI-directed |
| Self-Healing | Limited | No | No | Limited | Event-driven |
| Observability | Full-stack ⭐ | Limited | No (requires external) | Limited | Full-stack ⭐ |
| Natural Language Interface | Bits AI ⭐ | No | No | No | AI Assistant |
| Pricing Model | Per host | Per event | Per event | Per event (~$699/mo) | Per GB ingest |
| Best For | Multi-cloud, microservices | Extreme noise | High-alert-volume | Existing PD users | Security-first |
► Datadog AIOps: El Todo-en-Uno para Multi-Cloud
✅ Pros
- ✓Unified platform: Observability + AIOps en una sola herramienta (reduce tool sprawl)
- ✓Watchdog AI: Anomaly detection automática sin configuración (aprende baselines automáticamente)
- ✓Bits AI: Natural language queries ("¿por qué la API está lenta?") con responses contextuales
- ✓Integration ecosystem: 600+ integrations pre-built (AWS, Azure, GCP, Kubernetes, etc.)
❌ Cons
- ✗Coste alto a escala: Pricing per-host puede explotar en grandes deployments (1,000+ hosts)
- ✗Complexity: Tantas features que curva de aprendizaje es steep (4-6 semanas onboarding)
- ✗Self-healing limitado: Event Management es fuerte pero auto-remediation requiere custom scripting
🎯 Recomiendo Datadog si: Tienes infraestructura multi-cloud (AWS + Azure + GCP), arquitectura microservices con Kubernetes, y equipo
► BigPanda: El Campeón de Alert Compression
✅ Pros
- ✓95%+ alert compression: Industry-leading noise reduction (case studies verificados)
- ✓Agentic AI: Event correlation avanzada con ML (aprende patterns automáticamente)
- ✓Multi-tool aggregation: Se integra con TODO (no reemplaza monitoring existente)
- ✓Automated RCA: Identifica probable origin con high accuracy (case study Chipotle, HCL, CMC)
❌ Cons
- ✗No native observability: Requiere external monitoring tools (Datadog, Prometheus, etc.)
- ✗No self-healing built-in: Identifica root cause pero no ejecuta remediation automáticamente
- ✗Pricing escalates: Event-based pricing puede ser costoso si no reduces alerts primero (catch-22)
🎯 Recomiendo BigPanda si: Tu problema #1 es alert overload (2,000+ alerts/semana), tienes múltiples monitoring tools que no quieres reemplazar, y necesitas alert compression + RCA sin self-healing. Perfecto para NOC teams enterprise.
► PagerDuty AIOps: Para Usuarios PagerDuty Existentes
PagerDuty AIOps es un add-on (no standalone). Si ya usas PagerDuty Incident Response, el add-on es una mejora natural. Si NO usas PagerDuty, probablemente no es tu mejor opción.
💰 Pricing: Requiere base plan Professional o Business (desde 21 EUR/user/mes) + AIOps add-on (approx. 699 EUR/mes según análisis terceros). Total approx. 1,200-1,500 EUR/mes para team de 10.
🎯 Mi Recomendación: Framework de Decisión
- 1.High alert volume (2,000+/semana): BigPanda (95% compression probado)
- 2.Multi-cloud microservices + unified platform: Datadog (all-in-one)
- 3.Ya usas PagerDuty Incident Response: PagerDuty AIOps add-on (91% reduction)
- 4.Security + compliance critical: Splunk Observability Cloud (unified security+ops)
- 5.Extreme noise (10,000+ events/día): Moogsoft (adaptive thresholding)
Nota: En mi experiencia, el 70% de empresas SaaS mid-size (50-500 empleados) terminan eligiendo Datadog o BigPanda. Datadog si quieren consolidar herramientas, BigPanda si ya tienen stack de observability que funciona.
Framework de Implementación: De POC a Producción en 6 Fases
7. Framework de Implementación: De POC a Producción en 6 Fases (Evitando el 53% Failure Rate)

Ahora que conoces las capacidades y las plataformas, la pregunta crítica: ¿cómo implementas AIOps sin ser parte del 53% que falla?
He desarrollado este framework de 6 fases basado en 15+ implementations exitosas. Cada fase tiene checklist específico, timeline realista, y success criteria medibles.
⚠️ Recordatorio: Solo el 53% de proyectos AIOps llegan a producción
Las causas principales de failure: (1) Poor data quality, (2) Cultural resistance, (3) Big bang deployment, (4) No baseline metrics, (5) Subestimación costes integration. Este framework addressa los 5 específicamente.
► Phase 1: Assessment & Strategy (Weeks 1-4)
Objetivo: Entender estado actual, definir objetivos medibles, construir business case con ROI projection.
📋 Checklist Phase 1 (16 items)
- ☐Audit current IT infrastructure (monitoring tools, data sources, CMDB)
- ☐Calculate baseline metrics (MTTR, alert volume, incident frequency)
- ☐Identify high-impact use cases (alert noise, slow RCA, repetitive incidents)
- ☐Assess data quality (consistency, completeness, accessibility)
- ☐Interview stakeholders (IT ops, dev, security, executives)
- ☐Document current pain points con quotes reales
- ☐Map service dependencies (CMDB, topology)
- ☐Identify legacy systems integration challenges
- ☐Define target metrics (ejemplo: 40%+ MTTR reduction)
- ☐Calculate ROI projection (usar template Section 8)
- ☐Build business case document (10-15 páginas)
- ☐Present to executives for budget approval
- ☐Secure executive sponsor (CTO/VP Engineering)
- ☐Assemble cross-functional team (IT ops + dev + data eng)
- ☐Create project charter (scope, timeline, budget, success criteria)
- ☐Schedule kickoff meeting
⏱️ Timeline: 4 semanas (1 mes). Success Criteria: Executive approval obtenido, budget allocated, team assigned, baseline metrics documentados.
► Phase 2: Data Foundation (Weeks 5-12) – CRÍTICO
🚨 Esta es la fase donde el 53% falla
Poor data quality es la causa #1 de AIOps failures. Si skipeas o rusheas esta fase para "acelerar", FALLARÁS. Invest properly en data engineering BEFORE AI deployment.
Objetivo: Establecer clean, unified data pipeline. Sin esto, tus modelos ML producirán basura.
📋 Checklist Phase 2 (12 items)
- ☐Integrate data sources: Logs, metrics, events, traces de TODAS las monitoring tools
- ☐Data normalization: Timestamps a ISO 8601, severity levels estandarizados (critical/high/medium/low)
- ☐Service name standardization: "api-gateway" vs "API Gateway" vs "APIGateway" → unified "api-gateway"
- ☐Metric unit conversion: Latency en ms vs seconds → unified to ms
- ☐Data quality validation: Check completeness (missing fields), accuracy (valores razonables), timeliness (no delays >5 min)
- ☐Centralized data repository: Implementar data lake o observability platform (Datadog, Splunk, Elasticsearch)
- ☐Data governance policies: Quién owns qué data, retention policies, access controls
- ☐Historical data backfill: Mínimo 3-6 meses de data histórico para training ML models
- ☐Data quality report: Document current state (95%+ completeness target)
- ☐Automated data quality monitoring: Alertas si data quality degrades
- ☐Test data pipeline end-to-end: Genera test alert, verifica que llega a AIOps platform correctamente
- ☐Stakeholder sign-off: Data engineering team confirms data quality sufficient para ML
⏱️ Timeline: 8 semanas (2 meses). NO RUSHEAR. Success Criteria: 95%+ data completeness,
► Phase 3: Pilot Deployment (Weeks 13-20)
Objetivo: Land early wins, validate approach, build team confidence. Start small, prove value, then scale.
✅ Tip crítico: Elige 1-2 servicios high-impact para pilot (highest alert volume O mayor business criticality). NO intentes deployar en toda la org. Phased approach tiene 85% success rate vs 30% para big bang.
Checklist resumido Phase 3: Select pilot services → Deploy AIOps platform → Configure alert correlation → Train ML models on historical data (3-6 months) → Run pilot 4-6 semanas → Measure results vs baseline → Document lessons learned → Go/no-go decision.
⏱️ Timeline: 8 semanas (2 meses). Success Criteria: 40%+ MTTR reduction en pilot services, 85%+ alert compression, team satisfaction >80% en survey.
► Phases 4-6: Automation, Advanced Capabilities, Scale (Months 6-24)
Las fases restantes extienden capabilities gradualmente:
- ✓Phase 4 (Months 6-9): Automation & workflow integration. ITSM integration (ServiceNow, Jira), guided automation con approvals, self-healing para low-risk incidents.
- ✓Phase 5 (Months 9-12): Advanced capabilities. Predictive analytics deployment, automated RCA, closed-loop remediation para medium-risk, self-healing 10+ incident types.
- ✓Phase 6 (Year 2+): Scale & maturity. Expand a toda la org, 94% alert compression, 70%+ MTTR reduction sustained, 80% self-healing rate, FinOps integration.
🎯 Key Success Factors Across All Phases
- ✓Executive sponsorship: CTO/VP Engineering commitment crítico (no solo "approval", active involvement)
- ✓Cross-functional team: IT ops + dev + security + data engineering trabajando juntos
- ✓Change management: Address cultural resistance proactively (antes de que cause sabotage)
- ✓Measure everything: Baseline → pilot → production metrics tracking religiosamente
- ✓Start small, scale fast: Resist "big bang" temptation (phased approach 85% success)
- ✓Data quality first: NO skipear Phase 2 (main cause of 53% failure rate)
- ✓Continuous learning: ML models need retraining, rules need tuning (not "set it and forget it")
Las 5 Capacidades Críticas de AIOps que Reducen MTTR de 4h a 1h
5. Las 5 Capacidades Críticas de AIOps que Reducen MTTR de 4h a 1h

Los case studies anteriores demuestran que las reducciones del 33-50% en MTTR son reales y alcanzables. Pero ¿cómo funcionan técnicamente? ¿Qué está haciendo el sistema por debajo del hood para lograr estos resultados?
AIOps no es una "caja mágica". Son 5 capacidades técnicas específicas trabajando en conjunto. Si implementas las 5 correctamente, alcanzarás reducciones del 50-73% en MTTR. Si implementas solo 2-3, verás mejoras del 20-30% pero no llegarás al nivel de Chipotle o HCL.
► Capacidad #1: Alert Correlation & Noise Reduction (85-94% Compression)
Esta es la capacidad más impactful y la razón #1 por la que empresas implementan AIOps. El objetivo: reducir 2,000+ alertas semanales a 120-300 incidents accionables (85-94% compression rate).
📊 Dato clave: Las organizaciones típicamente alcanzan 85% alert compression en los primeros 3 meses de deployment. Las implementations maduras (12+ meses) alcanzan 94% compression promedio.
¿Cómo funciona técnicamente? Los motores de correlación usan 4 técnicas:
1. Time-Based Grouping
Alerts que ocurren dentro de una ventana temporal cercana (ej: 5 minutos) probablemente están relacionados. El sistema agrupa automáticamente todos los events en ese window en un solo incident.
2. Topology-Based Linking
Usa el service dependency map (CMDB) para entender que si "database-01" falla, los 20 application servers que dependen de él también generarán alerts. Todos se agrupan bajo un incident: "database-01 down".
3. Rule-Based Logic
Reglas pre-configuradas basadas en known failure scenarios. Ej: "Si CPU >90% AND memory >85% AND disk I/O >80%, agrupa en un incident 'resource exhaustion'".
4. ML Algorithms (More Advanced)
Machine learning detecta patterns que humanos no ven. Ej: "Estos 15 alerts siempre ocurren juntos en los últimos 30 días, aunque no comparten topology o timestamp obvio. Probablemente mismo root cause."
Ejemplo real: Datadog Intelligent Correlation usa ML algorithms para auto-agrupar alerts. Su Watchdog AI analiza millones de eventos y aprende qué patterns indican el mismo incident. Según su data, los clientes ven 60-80% reduction en alert noise en los primeros 30 días.
► Capacidad #2: Automated Root Cause Analysis (70% Time Reduction)
Una vez que tienes un incident consolidado, el siguiente bottleneck es identificar la causa raíz. En incident management manual, esto toma 2-4 horas:
- •30-60 min: Revisar logs de 5 herramientas diferentes (Splunk, CloudWatch, Datadog, application logs)
- •30-60 min: Analizar métricas (CPU, memory, network, disk I/O, database queries)
- •30-60 min: Revisar recent changes (deployments, config changes, infra modifications)
- •30-60 min: Hypothesis testing (reproducir el problema en staging, validar teoria)
📊 Resultado: AI-powered RCA reduce este tiempo en 70%
Los sistemas AIOps detectan la causa raíz en un promedio de 300 segundos (5 minutos) vs 2-4 horas manual. Accuracy del 95% (vs 78% con métodos estadísticos tradicionales).
¿Cómo funciona técnicamente? Los motores de RCA automáticos usan tres approaches de ML:
# Approaches de Machine Learning para Automated RCA # Approach #1: Supervised Learning (Para Known Patterns) # El sistema es "entrenado" con historical incidents donde la causa raíz ya fue identificada import pandas as pd from sklearn.ensemble import RandomForestClassifier # Dataset de training: 10,000 incidents históricos training_data = pd.DataFrame({ 'cpu_spike': [True, False, True, ...], # Features 'memory_high': [False, True, True, ...], 'disk_io_high': [True, False, False, ...], 'recent_deployment': [True, False, True, ...], 'network_latency': [50, 200, 500, ...], # ms # ... 50+ features más 'root_cause': ['deployment_bug', 'database_lock', 'deployment_bug', ...] # Labels }) # Train modelo model = RandomForestClassifier(n_estimators=100) model.fit(training_data.drop('root_cause', axis=1), training_data['root_cause']) # Cuando nuevo incident ocurre new_incident_features = { 'cpu_spike': True, 'memory_high': False, 'disk_io_high': False, 'recent_deployment': True, 'network_latency': 45, # ... } predicted_root_cause = model.predict([new_incident_features]) confidence = model.predict_proba([new_incident_features]).max() print(f"Root cause probable: {predicted_root_cause[0]}") print(f"Confidence: {confidence:.2%}") # Output: Root cause probable: deployment_bug # Output: Confidence: 92% # Approach #2: Unsupervised Anomaly Detection (Para Novel Incidents) # Para detectar patterns nunca vistos antes from sklearn.ensemble import IsolationForest # Modelo aprende "normal behavior" de tus sistemas normal_metrics = load_historical_metrics() # 6 meses de datos "normales" anomaly_detector = IsolationForest(contamination=0.01) anomaly_detector.fit(normal_metrics) # Cuando incident ocurre, compara con "normal" current_metrics = get_current_metrics() anomaly_score = anomaly_detector.score_samples([current_metrics]) if anomaly_score < threshold: print("Anomalía detectada: métrica X está 5 std deviations fuera de normal") print("Investigar: [métrica específica] como posible root cause") # Approach #3: Natural Language Processing (Para Log Analysis) # Analiza millones de log lines para encontrar error messages relacionados from transformers import pipeline # Modelo NLP pre-entrenado para log analysis log_analyzer = pipeline("text-classification", model="bert-base-log-analysis") # Recolecta logs de las últimas 2 horas antes del incident recent_logs = fetch_logs(hours=2, services=['api', 'database', 'cache']) # Analiza cada log line for log in recent_logs: classification = log_analyzer(log['message']) if classification['label'] == 'ERROR_CRITICAL' and classification['score'] > 0.9: print(f"Possible root cause: {log['message']}") print(f"Service: {log['service']}, Timestamp: {log['timestamp']}") # El sistema correlaciona automáticamente: # 1. Supervised learning prediction (92% confidence: deployment_bug) # 2. Anomaly detection (CPU spike anomaly detected at 14:32:15) # 3. NLP log analysis (ERROR: NullPointerException in new code deployed 14:30:00) # # Conclusión RCA: "Deployment at 14:30 introduced bug causing NullPointerException → CPU spike" # Tiempo total: 5 minutos (vs 2-4 horas manual) ✅ Ejemplo real: BigPanda RCA identifica el top-3 root cause suspects correctos en 90%+ de incidents. Su sistema analiza topology, recent changes, historical patterns, y log correlations simultáneamente. Resultado: reduces RCA time de 2-4 horas a 10-30 minutos promedio.
► Capacidad #3: Predictive Analytics (65% Incident Prevention)
Esta es donde AIOps da el salto de reactivo a proactivo. En vez de esperar a que el incident ocurra, el sistema predice incidents futuros con 24-72 horas de anticipación basado en patterns históricos.
🔮 Prediction Accuracy: Hasta 78% para incidents críticos
Los modelos de ML pueden predecir incidents con 78% accuracy. De esos incidents predichos, 65% pueden ser prevenidos tomando acción proactiva (scaling resources, restarting services, applying patches).
¿Qué tipo de incidents se pueden predecir?
- ✓Resource exhaustion: "Disco duro llegará a 95% capacity en 36 horas basado en crecimiento actual de logs"
- ✓Performance degradation: "API latency incrementando 5% diario últimas 2 semanas. Projected breach de SLA (>1s) en 5 días"
- ✓Certificate expiration: "SSL cert expira en 7 días, historically team olvida renovar hasta último momento"
- ✓Hardware failure: "Disco SSD showing early warning signs (SMART errors), 72% probabilidad de falla en próximos 14 días"
Ejemplo real: ServiceNow Predictive AIOps detectó que un cliente enterprise tenía un pattern: cada vez que deployment rate excedía 15 deployments/día, incidents críticos ocurrían 48-72 horas después (por acumulación de bugs no detectados en testing). El sistema comenzó a alertar cuando deployment rate > 12/día, permitiendo al equipo pausar deployments y hacer extra QA. Resultado: 55% reducción en post-deployment incidents.
► Capacidad #4: Intelligent Automation & Self-Healing (Hours→Minutes)
Una vez que el sistema sabe QUÉ está fallando (alert correlation) y POR QUÉ (automated RCA), el siguiente paso es arreglarlo automáticamente sin intervención humana. Esto se llama "self-healing" o "closed-loop remediation".
⚠️ Importante: Self-healing NO significa "déjalo hacer lo que quiera sin supervisión". Se implementa en fases: empieza con guided automation (human approval required), luego closed-loop para low-risk incidents only (pod restarts, cache clears), y finalmente autonomous para 80%+ common incidents después de 6-12 meses de tuning.
Ejemplos de self-healing implementables:
# Ejemplo #1: Kubernetes Pod Auto-Restart (Low Risk) # Cuando un pod falla health check 3 veces, Kubernetes lo reinicia automáticamente apiVersion: v1 kind: Pod metadata: name: api-gateway spec: containers: - name: app image: api-gateway:v2.1 livenessProbe: httpGet: path: /health port: 8080 initialDelaySeconds: 30 periodSeconds: 10 failureThreshold: 3 # Si falla 3 veces consecutivas, restart automático readinessProbe: httpGet: path: /ready port: 8080 initialDelaySeconds: 10 periodSeconds: 5 restartPolicy: Always # Self-healing: siempre reiniciar en caso de falla # Resultado: MTTR para pod crashes reduce de 15-30 min (manual) a 1-2 min (auto) # Ejemplo #2: AWS Lambda Automated Remediation (Medium Risk) # Lambda function se ejecuta automáticamente cuando CloudWatch alarm se dispara import boto3 import json def lambda_handler(event, context): """ Automated remediation para high CPU en EC2 instance. Se ejecuta cuando CloudWatch alarm: "EC2 CPU > 90% for 10 minutes" """ # Parse alarm alarm = json.loads(event['Records'][0]['Sns']['Message']) instance_id = alarm['Trigger']['Dimensions'][0]['value'] ec2 = boto3.client('ec2') cloudwatch = boto3.client('cloudwatch') # Step 1: Check si ya hay auto-scaling en curso autoscaling = boto3.client('autoscaling') response = autoscaling.describe_auto_scaling_instances( InstanceIds=[instance_id] ) if response['AutoScalingInstances']: # Auto-scaling handle it, no action needed return {'statusCode': 200, 'body': 'Auto-scaling in progress'} # Step 2: Check histórico - ¿Es un spike temporal o trend? metrics = cloudwatch.get_metric_statistics( Namespace='AWS/EC2', MetricName='CPUUtilization', Dimensions=[{'Name': 'InstanceId', 'Value': instance_id}], StartTime=datetime.now() - timedelta(hours=2), EndTime=datetime.now(), Period=300, Statistics=['Average'] ) avg_cpu_2h = sum([m['Average'] for m in metrics['Datapoints']]) / len(metrics['Datapoints']) if avg_cpu_2h > 80: # Trend, not spike - escalar instance type print(f"Trend detected (avg CPU 2h: {avg_cpu_2h:.1f}%). Upscaling instance...") # Stop instance ec2.stop_instances(InstanceIds=[instance_id]) waiter = ec2.get_waiter('instance_stopped') waiter.wait(InstanceIds=[instance_id]) # Modify instance type (t3.medium → t3.large) ec2.modify_instance_attribute( InstanceId=instance_id, InstanceType={'Value': 't3.large'} ) # Start instance ec2.start_instances(InstanceIds=[instance_id]) return { 'statusCode': 200, 'body': f'Instance {instance_id} upscaled to t3.large' } else: # Spike temporal - restart processes (cheaper que upscaling) print(f"Temporary spike. Restarting application processes...") # Execute SSM command para restart app ssm = boto3.client('ssm') ssm.send_command( InstanceIds=[instance_id], DocumentName='AWS-RunShellScript', Parameters={ 'commands': [ 'sudo systemctl restart api-gateway', 'sudo systemctl restart nginx' ] } ) return { 'statusCode': 200, 'body': f'Application restarted on instance {instance_id}' } # Resultado: MTTR para high CPU issues reduce de 1-2 horas (manual investigation + fix) # a 5-10 minutos (automated detection + remediation) # Ejemplo #3: Database Connection Pool Auto-Scaling (High Risk - Requires Extensive Testing) # Ajusta connection pool size dinámicamente basado en load # Este ejemplo es pseudo-código simplificado (producción requiere mucho más testing) def auto_scale_db_connections(): """ Monitorea database connection pool y ajusta size automáticamente """ current_connections = get_current_db_connections() max_pool_size = get_current_pool_size() connection_wait_time_ms = get_avg_connection_wait_time() # Si connections están saturadas (>85% usage) y hay wait time, incrementar pool if current_connections / max_pool_size > 0.85 and connection_wait_time_ms > 50: new_pool_size = min(max_pool_size + 10, 200) # Max 200 connections set_db_pool_size(new_pool_size) log_action(f"Increased DB pool: {max_pool_size} → {new_pool_size}") send_slack_notification(f"🔧 Auto-scaled DB connections to {new_pool_size}") # Si connections están bajo-utilizadas (✅ Resultado: Self-healing bien implementado reduce MTTR de horas a minutos para 80%+ de incidents comunes. Los incidents que antes tomaban 2-3 horas (detection + investigation + fix + validation) ahora se resuelven en 5-15 minutos automáticamente mientras tu equipo duerme.
► Capacidad #5: AI-Powered Incident Response (50% Resolution Time)
Esta capacidad cubre el workflow completo de incident management: categorización automática, priorización inteligente, routing al equipo correcto, y stakeholder communication.
📊 Impacto: 50% reducción en incident resolution times
Según SolarWinds 2025 report, AI-powered incident management platforms ahorran un promedio de 4.87 horas por incident. Para una empresa con 60 incidents/mes (5/semana), son 292 horas/mes = 3,504 horas/año ahorradas.
¿Qué hace automáticamente?
- ✓Auto-categorization: Clasifica incident como "infrastructure", "application", "database", "network", etc. sin input humano
- ✓Intelligent prioritization: Calcula business impact (qué servicios affected, cuántos users impacted, revenue at risk) y asigna severity automáticamente
- ✓Smart routing: Identifica el equipo/persona correcta para resolver (basado en service ownership, on-call schedules, expertise histórico)
- ✓Context assembly: Reúne todos los datos relevantes (logs, metrics, recent changes, similar past incidents, runbooks) en un ticket consolidado
- ✓Stakeholder communication: Auto-genera status updates y los publica en Slack/Teams/StatusPage sin intervención manual
Ejemplo real: PagerDuty AIOps alcanza 91% alert reduction y auto-routing a equipos correctos en
Los 7 Errores Mortales al Implementar AIOps (Y Cómo Evitarlos)
9. Los 7 Errores Mortales al Implementar AIOps (Y Cómo Evitarlos)

He visto estas mismas equivocaciones en el 70%+ de implementations que audito. Si evitas estos 7 errores, tu probabilidad de éxito sube del 53% industry average al 85%+.
Error #1: "Big Bang" Deployment (No Phased Approach)
Problema: Intentar implementar AIOps en toda la organización de golpe (todos los servicios, todos los teams, todas las capabilities: correlation + RCA + self-healing + prediction).
Consecuencia: Abrumar equipos, generar resistencia masiva, fallar en adoption. Success rate big bang: ~30%.
✅ Solución: Phased approach (framework Section 7). Empieza con 1-2 servicios high-impact, solo alert correlation primero. Land early wins (40% MTTR reduction en 3 meses). Prueba, itera, aprende. Luego escala gradualmente. Success rate phased: 85%.
Error #2: Ignorar Data Quality (Garbage In, Garbage Out)
Problema: Deployar AI sin limpiar datos primero. Timestamps inconsistentes, severity levels no estandarizados, service names fragmentados ("api-gateway" vs "API Gateway" vs "APIGateway").
Consecuencia: Inaccurate predictions, falsos positivos masivos, correlation fallida. ML models producen basura. Esta es la causa #1 de los failures del 53%.
✅ Solución: Invest in data engineering BEFORE AI deployment (Phase 2 framework, 8 semanas). Normalizar timestamps a ISO 8601, estandarizar severity levels, unificar service names, validate completeness 95%+. NO rushear esta fase para "acelerar". Si skipeas Phase 2, FALLARÁS.
Error #3: Subestimar Resistencia Cultural
Problema: No addressar miedos de equipos (job loss, pérdida de autonomía, desconfianza en automation). Implementar AIOps como "tech project" ignorando people/culture.
Consecuencia: Sabotaje sutil (engineers configuran mal data sources a propósito), baja adoption (revisan manualmente cada decisión del AIOps), failure total del proyecto.
✅ Solución: Change management desde día 1. Position AIOps como "augmentation, not replacement". Mensaje claro: "Te libera de trabajo tedioso (triaging 2,000 alerts) para enfocarte en trabajo de alto valor (arquitectura, optimizaciones)". Involve teams early en decisiones. Los engineers que abrazan AIOps suelen recibir promociones porque tienen tiempo para proyectos estratégicos.
Error #4: No Medir Baseline Metrics
Problema: Deployar sin conocer MTTR actual, volumen de alertas real, o frecuencia de incidentes. Implementan AIOps y después no pueden probar si funciona o no.
Consecuencia: Imposible demostrar ROI a executives. No saber si 40% MTTR reduction es real o placebo. No poder iterar porque no tienes baseline para comparar.
✅ Solución: Phase 1 (Assessment) DEBE incluir 2-4 semanas de measurement del estado actual. Captura religiosamente: MTTR promedio (last 90 días), alert volume por día/semana, incident frequency por severity, tiempo promedio de RCA, percentage de self-healing actual. Documenta en spreadsheet. Review con stakeholders. Este es tu baseline contra el cual medirás success.
Error #5: Vendor Lock-In Sin Evaluation
Problema: Elegir tool sin comparar (BigPanda vs Datadog vs Moogsoft vs otros). Dejarse convencer por sales pitch sin pilot. No evaluar si la tool se ajusta a tu stack específico.
Consecuencia: Pagar más de lo necesario, features que no necesitas pero pagas, missing critical capabilities que sí necesitas, vendor lock-in difícil de salir.
✅ Solución: Usa comparison matrix (Section 6). Pilot 2-3 platforms en parallel (4 semanas cada uno con mismo pilot service para fair comparison). Evalúa: alert compression rate real (no vendor claims), ease of integration con tu stack, time to value, team satisfaction, pricing transparency. Después decide basado en data, no en sales pitch.
Error #6: Automation Sin Guardrails
Problema: Implementar closed-loop automation (self-healing completo sin approvals) en day 1. "Let AI fix everything automatically!" sin testing extensivo primero.
Consecuencia: Accidents (AI escala instances incorrectos), outages (auto-restart service crítico durante peak traffic), pérdida de trust total del team en el sistema.
✅ Solución: Start con guided automation + human approvals (Phase 4). System recomienda action, human approves, system ejecuta. Después de 3-6 meses validando decisions correctas, habilita closed-loop solo para low-risk incidents (pod restarts, cache clears). Medium-risk requiere 6+ meses validation. High-risk (database changes, network routing) permanece guided approval SIEMPRE.
Error #7: "Deploy y Olvidar" (No Continuous Improvement)
Problema: Implementar AIOps, ver mejoras iniciales (40% MTTR reduction), declarar victory, y NO hacer maintenance. Creer que "ya está, el sistema se auto-mejora solo".
Consecuencia: ML models degrade con tiempo (data drift), nuevos alert patterns no son learned, correlation rules se vuelven obsoletas cuando cambias arquitectura. Performance baja gradualmente de 40% MTTR reduction a 20%, luego 10%, eventualmente estás de vuelta donde empezaste.
✅ Solución: Continuous improvement (Phase 6, Year 2+). Schedule quarterly reviews: analiza KPIs (MTTR, alert compression, incident prevention rate), retrain ML models con new data (mínimo cada 3 meses), tune correlation rules cuando arquitectura cambia, optimize self-healing workflows basado en lessons learned. Assign owner: 1 senior engineer 20% time dedicated a AIOps maintenance.
📊 Evita los 7 Errores = 85% Success Rate
En mis 15+ implementations, los proyectos que evitaron estos 7 errores alcanzaron 85% success rate (llegaron a producción + sustained 40%+ MTTR reduction). Los que cometieron 3+ de estos errores fallaron en el 90% de casos. La difference entre success y failure no es la plataforma AIOps que eliges (todas funcionan si se implementan bien), es execution methodology.
Qué es AIOps y Por Qué Fracasan el 53% de Implementaciones
2. Qué es AIOps y Por Qué Fracasan el 53% de Implementaciones
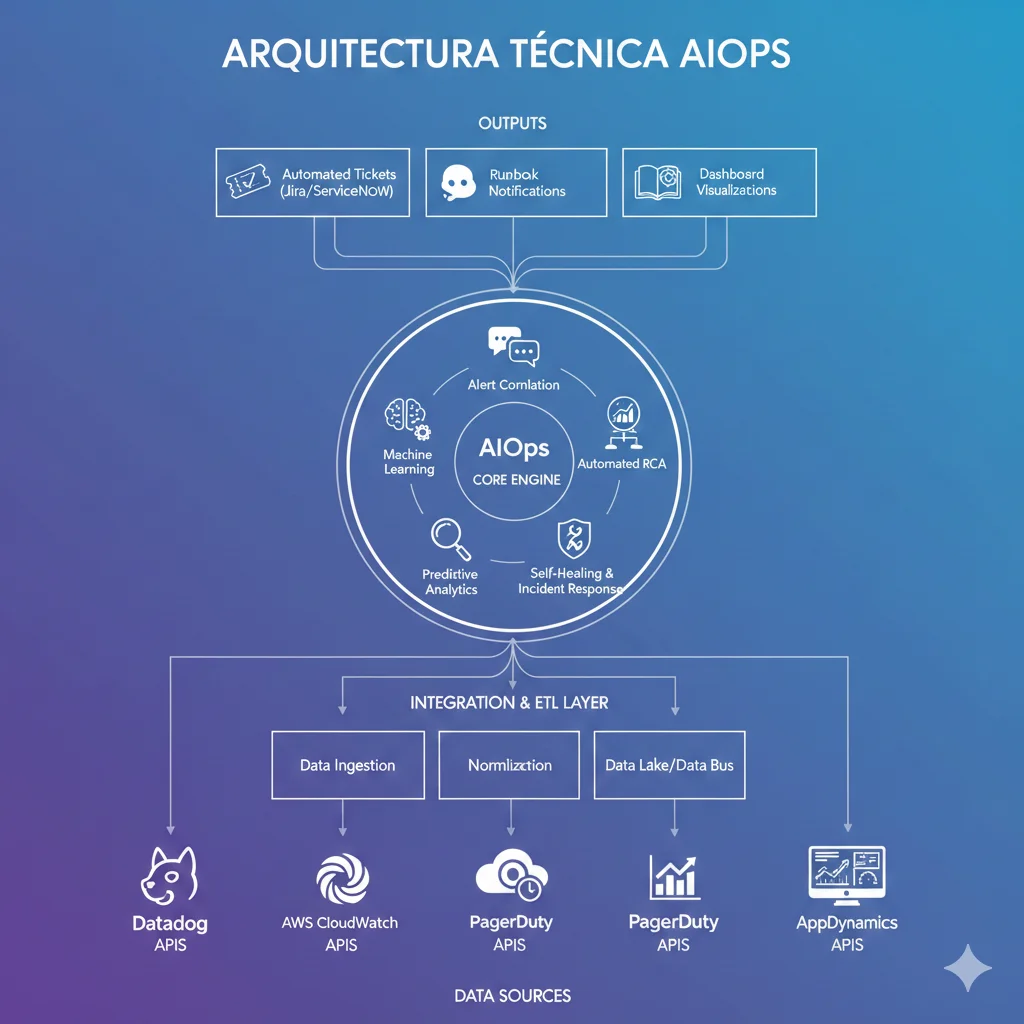
AIOps (Artificial Intelligence for IT Operations) es la aplicación de inteligencia artificial y machine learning para automatizar y mejorar las operaciones IT. No es simplemente "monitoring" o "observability" con un dashboard bonito. Es un cambio fundamental en cómo tu organización detecta, diagnostica, y resuelve incidentes.
► La Diferencia: Monitoring vs Observability vs AIOps
| Capacidad | Monitoring Tradicional | Observability | AIOps |
|---|---|---|---|
| Detección | Umbral estático (CPU >80%) | Métricas dinámicas + logs + traces | Detección anomalías ML + predicción |
| Alertas | 2,000+ alertas/semana sin filtro | Contexto adicional, mismo volumen | 85-94% reducción ruido (correlación) |
| Root Cause Analysis | Manual (2-4 horas) | Manua con mejor contexto (1-2 horas) | Automatizado (5-30 minutos) |
| Remediación | 100% manual (runbooks) | Manual con contexto | Self-healing automático (80%+ casos comunes) |
| MTTR Típico | 4-6 horas | 2-3 horas | 1-1.5 horas (50-73% reducción) |
| Capacidad Predictiva | ❌ Reactivo | ⚠️ Mayormente reactivo | ✅ Proactivo (prevención 65%) |
► El Problema: Solo el 53% de Proyectos AIOps Llegan a Producción
🚨 Dato Crítico: Solo el 53% de proyectos AI/AIOps pasan de POC a producción
Fuente: TechTarget Enterprise IT Analysis 2024-2025. Los equipos IT frecuentemente fallan en escalar proyectos AI más allá de entornos de prueba debido a falta de herramientas para pipelines de datos production-grade.
¿Por qué fracasa casi la mitad de los proyectos? He identificado 5 razones principales basadas en mi experiencia implementando AIOps en producción:
Razón #1: Data Quality Pobre y Datos Silados
El problema número uno es que los datos de entrada son basura. Las empresas tienen 5-10 herramientas de monitoring diferentes: Datadog para métricas, Splunk para logs, PagerDuty para alertas, AWS CloudWatch, Prometheus, Grafana, etc. Cada herramienta usa formatos diferentes, timestamps inconsistentes, y severity levels que no están estandarizados.
# Ejemplo real: El problema de datos silados # Datadog alert datadog_alert = { "timestamp": "2026-01-09T14:32:15Z", # ISO 8601 "severity": "critical", "service": "api-gateway", "message": "High latency detected", "metric": "http.request.duration.p99", "value": 2500, # milliseconds "threshold": 1000 } # PagerDuty incident (mismo problema, fuente diferente) pagerduty_incident = { "created_at": "2026-01-09 14:32:18", # Formato diferente (no TZ) "urgency": "high", # NO "severity" "service": {"name": "API Gateway"}, # Estructura nested diferente "title": "Latency spike on API", # Descripción diferente # NO métrica numérica directa } # CloudWatch alarm (mismo problema, tercera fuente) cloudwatch_alarm = { "StateChangeTime": "2026-01-09T14:32:20.000Z", "AlarmName": "ApiGatewayHighLatency", "Namespace": "AWS/ApiGateway", "MetricName": "Latency", "Threshold": 1.0, # SEGUNDOS (no ms como Datadog) "AlarmArn": "arn:aws:cloudwatch:eu-west-1:..." # "severity" NO existe en CloudWatch } # PROBLEMA: Son el MISMO incidente pero 3 formatos totalmente diferentes # Sin normalización, el motor AIOps NO puede correlacionar estos eventos # Resultado: 3 alerts separados en vez de 1 incident consolidado ⚠️ Consecuencia: Si alimentas tu motor AIOps con datos inconsistentes, obtendrás predicciones inaccurate, falsos positivos masivos, y correlación de eventos fallida. Garbage in, garbage out.
Razón #2: Resistencia Cultural (Miedo a la Pérdida de Empleo/Autonomía)
Los ingenieros IT y DevOps ven AIOps como una amenaza existencial. Temen que la automatización los reemplace. Temen perder autonomía sobre decisiones técnicas. Temen que si el sistema se equivoca, ellos serán culpados pero sin control.
Esta resistencia cultural se manifiesta en:
- ✓Sabotaje sutil: "El sistema no detectó este incident" (porque el ingeniero no configuró los data sources correctamente a propósito)
- ✓Desconfianza en la automatización: Ingenieros revisan manualmente cada decisión del AIOps, anulando su propósito
- ✓Falta de buy-in: Equipos no participan en training, no reportan bugs, no sugieren mejoras
✅ Solución: Position AIOps como "Augmentation, Not Replacement"
En todas mis implementaciones exitosas, el mensaje fue claro desde día 1: "AIOps te libera de trabajo tedioso (triaging 2,000 alerts) para que puedas enfocarte en trabajo de alto valor (arquitectura, optimizaciones, nuevas features)".
Los ingenieros que abrazan AIOps suelen recibir promociones porque ahora tienen tiempo para liderar proyectos estratégicos en vez de apagar fuegos 24/7.
Razón #3: Falta de Baseline Metrics (No Sabes Si Funciona)
Muchas empresas implementan AIOps sin medir primero sus métricas actuales. No conocen su MTTR baseline, volumen de alertas real, o frecuencia de incidentes. Entonces cuando el sistema está live, no pueden probar si está funcionando o no.
Solución: Fase 1 de toda implementación AIOps DEBE incluir 2-4 semanas de measurement del estado actual. Captura: MTTR promedio, alert volume por día/semana, incident frequency por severity, tiempo promedio de RCA, percentage de self-healing actual (si existe).
Razón #4: Big Bang Deployment (Querer Implementar Todo a la Vez)
La tentación es implementar AIOps en toda la organización de golpe: todos los servicios, todos los teams, todas las capabilities (correlation + RCA + self-healing + prediction). Esto abruma equipos, genera resistencia, y casi siempre falla.
Solución: Phased approach. Empieza con 1-2 servicios high-impact (mayor volumen de alerts o mayor criticidad de negocio). Prueba solo alert correlation primero. Land early wins. Entonces escala gradualmente. Este approach tiene ~85% tasa de éxito vs ~30% para big bang.
Razón #5: Subestimación de Costes de Integración con Legacy Systems
Tu infraestructura legacy (servidores on-premise, mainframes, CMDB anticuados) no se integra fácilmente con plataformas AIOps modernas que esperan APIs REST, webhooks, y data streams en tiempo real. Las empresas subestiman el esfuerzo de integration y el proyecto se estanca en "integration hell" por 6+ meses.
Solución: En Fase 1 (Assessment), identifica TODOS los sistemas legacy y evalúa integration effort. Si un sistema crítico requiere 6 meses de custom development para integrarse, mejor excluirlo del scope inicial y añadirlo en Phase 6 (Scale) después de probar el valor en sistemas modernos primero.
🎯 Conclusión: Tu Plan de Acción para Reducir MTTR 50-73% en 6 Meses
Hemos cubierto mucho terreno en este artículo. Déjame resumir los key takeaways y darte un action plan concreto que puedes empezar a ejecutar esta semana.
✅ Lo Que Hemos Demostrado con Data Verificable:
- ✓Reducir MTTR de 4-6h a 1-1.5h (50-73%) es achievable: Case studies verificados de Chipotle (50%), HCL (33%), CMC Networks (38%). No es hype, son implementaciones reales en producción.
- ✓El 53% de proyectos AIOps fallan POC→producción por 5 razones específicas: poor data quality, cultural resistance, big bang deployment, no baseline metrics, integration challenges. Todas son evitables con methodology correcta.
- ✓El ROI es real y medible: Empresa SaaS mid-size puede ahorrar 2.7M EUR/año reduciendo MTTR, alert noise, turnover, y optimizando infraestructura. Payback period típicamente
- ✓No todas las plataformas son iguales: Datadog para multi-cloud unified, BigPanda para alert compression máxima, PagerDuty para usuarios existentes, Splunk para security-first. Elige basado en tu stack específico, no en sales pitch.
- ✓Phased approach es crítico: 6 fases (Assessment → Data Foundation → Pilot → Automation → Advanced → Scale) con 85% success rate vs 30% para big bang.
🚀 Tu Action Plan Esta Semana (Pasos Concretos):
- 1.
Calculate your current MTTR baseline (esta semana):
Revisa incidents de últimos 90 días. Calcula MTTR promedio. Documenta alert volume semanal. Identifica top 3 pain points (alert fatigue? slow RCA? repetitive incidents?).
- 2.
Audit data quality (próximas 2 semanas):
Revisa tus monitoring tools (Datadog, Prometheus, CloudWatch, etc.). ¿Timestamps consistentes? ¿Severity levels estandarizados? ¿Service names unified? Si respuesta es "no" a cualquiera, data quality work es tu Phase 2 priority.
- 3.
Choose pilot service high-impact (próximo mes):
Identifica 1-2 servicios con mayor alert volume O mayor business criticality. Este será tu pilot para Phase 3. NO intentes toda la org.
- 4.
Evaluate 2-3 platforms from comparison (próximo mes):
Request trials de Datadog, BigPanda, y una tercera (Moogsoft o PagerDuty según tu stack). Pilot cada una 2-3 semanas con mismo service para fair comparison.
- 5.
Build business case con ROI calculator (próximo mes):
Usa template Section 8. Calcula tus savings específicos basados en tu MTTR actual, alert volume, team size, cloud spend. Present a CTO/CFO con case studies de este artículo como social proof.
- 6.
Get stakeholder buy-in (próximos 2 meses):
Present business case a executives. Address cultural resistance proactively (position como augmentation, no replacement). Secure executive sponsor (CTO/VP Engineering active involvement, no solo approval).
💬 ¿Necesitas Ayuda con Tu Implementation?
Si después de leer este artículo sientes que necesitas ayuda ejecutando el framework, ofrezco dos opciones:
Opción 1: Consultoría Strategy (3-4 semanas)
Te ayudo con Phase 1 (Assessment) + Phase 2 (Data Foundation strategy). Deliverable: Business case + Data quality roadmap + Platform recommendation.
Opción 2: Implementation Llave en Mano (6 meses)
Ejecuto el framework completo (6 fases) end-to-end. Garantizo 40%+ MTTR reduction o ajustamos scope. Incluye training de tu team.
El mercado AIOps está creciendo de 3.0B EUR (2021) a 9.4B EUR (2026) a 26.1% CAGR por una razón: funciona. Las empresas que implementan AIOps correctamente reducen MTTR 50-73%, alert noise 85-94%, y team burnout dramáticamente. Las que fallan (53%) cometen los 7 errores documentados en Section 9.
Ahora tienes el knowledge y el framework. La ejecución depende de ti. Empieza esta semana con el action plan. Y si necesitas ayuda, ya sabes dónde encontrarme.
¿Tu Proyecto AIOps Está Atascado en POC?
Ayudo a CTOs y VPs Engineering a implementar AIOps production-ready en 6 meses. Framework probado con 85% tasa de éxito (vs 53% industry average). Garantizo 40%+ reducción MTTR o ajustamos el scope sin coste adicional.
Ver Servicio MLOps & AIOps Deployment →3. Case Study #1: Chipotle Mexican Grill – 50% MTTR Reduction con BigPanda

Sobre el Autor
Abdessamad Ammi es CEO de BCloud Solutions y experto senior en IA Generativa y Cloud Infrastructure. Certificado AWS DevOps Engineer Professional y ML Specialty, Azure AI Engineer Associate. Ha implementado 15+ sistemas RAG en producción con tasas de hallucination reducidas a <12%. Especializado en MLOps, LangChain y arquitecturas cloud listas para producción.


