

![Chatbot Inteligente con RAG + LangChain: De Cero a Producción en 5 Días [Guía Completa 2025] | BCloud Consulting](/images/nextImageExportOptimizer/chatbot-rag-langchain-hero-opt-1920.WEBP)
1. RAG vs Traditional Chatbots: Por Qué RAG Reduce Hallucinations del 40% al 6%
El mercado de conversational AI alcanza $15 mil millones en 2025
Según Grand View Research, el mercado crecerá 23.7% anual hasta 2030, alcanzando $41.39B. Gartner predice que en 2027, el 25% de organizaciones usarán chatbots como primary customer service channel.
Si eres CTO o Head of Engineering en una startup SaaS, probablemente has experimentado con chatbots tradicionales y te has enfrentado a una verdad incómoda: el 40% de las respuestas son hallucinations (PubMed, 2025), los usuarios abandonan por respuestas irrelevantes, y los costes escalan de $1-3k/mes a $500k/año sin un control adecuado.
Los chatbots basados en scripts rígidos no escalan. Los LLMs vanilla (sin RAG) inventan respuestas. Y cuando intentas implementar RAG (Retrieval-Augmented Generation), te enfrentas a documentación fragmentada, tutoriales que terminan en POCs no deployables, y una ausencia total de guías sobre costes reales, troubleshooting o deployment production-ready.
Mientras tanto, tu competencia ya está automatizando customer support con chatbots RAG que resuelven el 70% de tickets automáticamente, reducen response time de 4 horas a 30 segundos, y generan $50k+ en ahorros anuales.
En este artículo, te muestro el roadmap exacto que usé para implementar el chatbot RAG de MasterSuiteAI en 5 días laborales.
No es teoría. Es el mismo framework production-ready que genera 70% auto-resolution rate, <2s latency, y 95% accuracy (RAGAS evaluation) en producción HOY, procesando 500+ queries/día para 5,000 usuarios activos.
🎯 Lo que aprenderás en esta guía:
- ✓Roadmap día a día (5 días × 5 horas) desde setup hasta deployment AWS production-ready
- ✓15+ code examples Python/LangChain 100% funcionales (copy-paste ready)
- ✓Cost breakdown detallado con calculator interactivo (Embeddings + LLM + Vector DB + Infrastructure)
- ✓Troubleshooting framework con 20+ problemas comunes y soluciones específicas
- ✓Caso real MasterSuiteAI con métricas verificadas ($50k savings, 70% auto-resolution)
- ✓Security & compliance (HIPAA, GDPR, PII detection, prompt injection protection)
- ✓Testing strategy completa (unit tests, integration tests, RAGAS evaluation)
¿Prefieres que implemente esto por ti? Ofrezco consultoría gratuita de 30 minutos para evaluar tu caso específico.
Agenda tu consultoría gratis →1. RAG vs Traditional Chatbots: Por Qué RAG Reduce Hallucinations del 40% al 6%
✗ El Problema de los Chatbots Tradicionales
Los chatbots tradicionales se dividen en dos categorías, ambas con problemas críticos:
1. Rule-Based Chatbots (scripts rígidos):
- • Dependen de árboles de decisión predefinidos (if-else infinitos)
- • Requieren meses de entrenamiento manual para cada variación de pregunta
- • Respuestas genéricas que frustran usuarios ("Lo siento, no entiendo")
- • NO escalan: añadir 100 nuevos productos = reescribir todo el árbol
2. LLM Vanilla (sin RAG):
- • 40% hallucination rate según estudio PubMed 2025
- • Inventan respuestas con confianza (peligroso en healthcare, legal, finance)
- • Training data estático (GPT-4 conoce mundo hasta abril 2023)
- • No pueden responder preguntas sobre TU documentación interna específica

✓ La Solución: RAG (Retrieval-Augmented Generation)
RAG combina lo mejor de ambos mundos: la capacidad de razonamiento de LLMs + la precisión de búsqueda en documentos verificados.
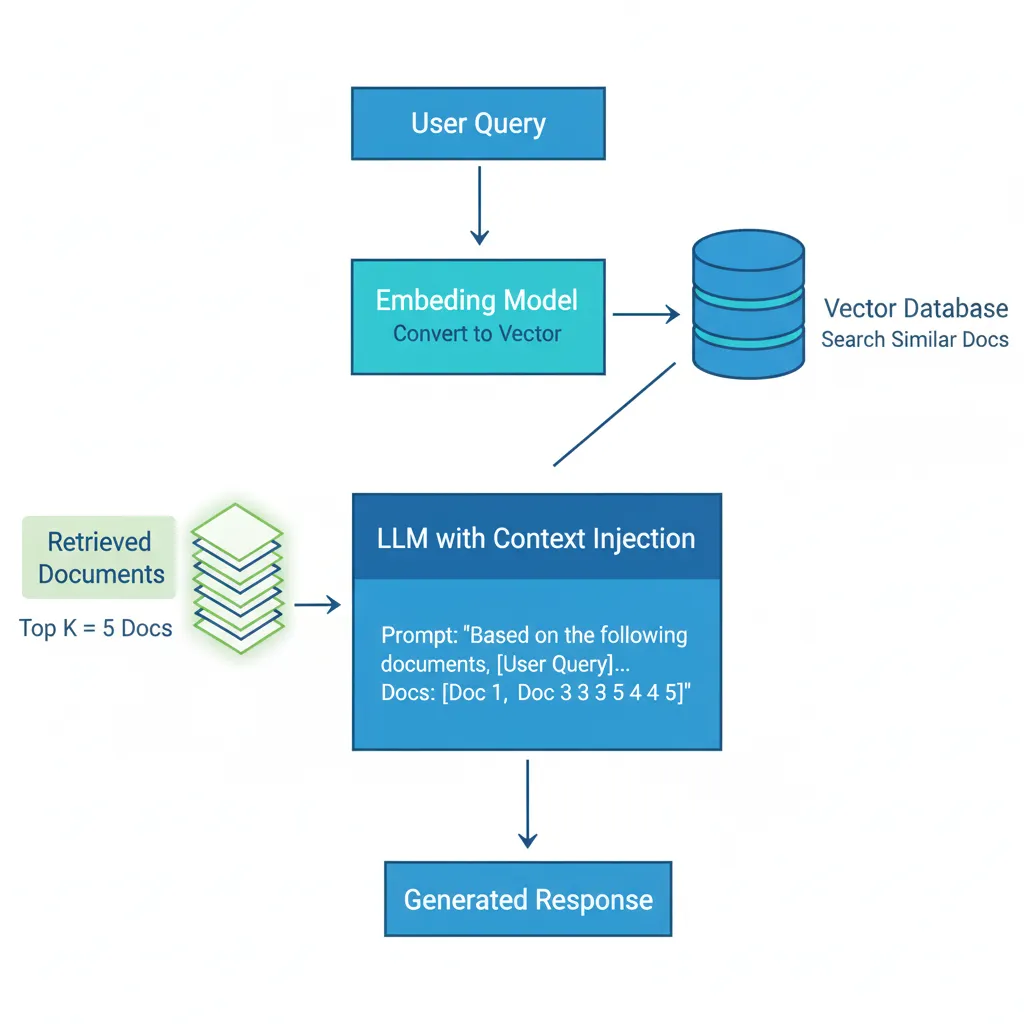
Cómo funciona RAG (3 pasos):
- 1. Retrieval (búsqueda): Convierte query del usuario a vector embedding, busca los 5 documentos más similares en tu knowledge base (vector database)
- 2. Augmentation (contexto): Inyecta esos documentos como contexto en el prompt del LLM
- 3. Generation (respuesta): LLM genera respuesta BASÁNDOSE SOLO en documentos retrieved (no inventa)
Resultado: 0-6% hallucination rate vs 40% en LLMs vanilla (PubMed study). La diferencia es que RAG responde "No tengo esa información en mi knowledge base" cuando no encuentra documentos relevantes, en lugar de inventar una respuesta convincente pero incorrecta.
| Criterio | Rule-Based | LLM Vanilla | RAG (Recomendado) |
|---|---|---|---|
| Hallucination Rate | 0% (respuestas predefinidas) | 40% | 0-6% |
| Escalabilidad | ❌ Muy baja (requiere reescribir árbol) | ✅ Alta | ✅ Alta + Precisión |
| Actualización Knowledge | Manual (semanas) | Imposible (data estática) | Automática (minutos) |
| Coste/Mes (10k queries) | $0 (hosting básico) | $800-1,200 | $1,200-1,500 |
| Caso de Uso Ideal | FAQs simples (<50 preguntas) | Conversación general, creative tasks | Customer support, documentation, compliance |
► ¿Cuándo Usar RAG vs Fine-Tuning?
Usa RAG cuando:
- ✓Knowledge base dinámica (actualizaciones frecuentes)
- ✓Necesitas transparencia (citar fuentes)
- ✓Budget limitado ($1-5k/mes)
- ✓Time to market corto (5 días vs 3-6 meses fine-tuning)
- ✓Compliance crítico (healthcare, legal, finance)
Usa Fine-Tuning cuando:
- ✓Necesitas comportamiento/estilo MUY específico
- ✓Datos sensitivos 100% on-premise (no APIs externas)
- ✓Latencia extrema <100ms (modelo local optimizado)
- ✓Budget alto ($20k+ upfront + GPU costs)
- ✓Knowledge base estática (no cambia en meses)
💡 Mi recomendación: Empieza con RAG. El 90% de casos de uso B2B SaaS (customer support, documentation, knowledge management) se resuelven perfectamente con RAG a fracción del coste. Fine-tuning solo cuando RAG no alcanza tus SLAs específicos.
🎯 Conclusión: Tus Próximos Pasos
🎯 Conclusión: Tus Próximos Pasos
Ahora tienes el framework completo para implementar un chatbot RAG production-ready en 5 días laborales.
Este NO es un tutorial más. Es el mismo roadmap que uso para clientes enterprise, con código funcional, cost optimization desde Día 1, troubleshooting proactivo, y deployment AWS completo.
✅ Lo que has aprendido:
- • Roadmap día a día (25 horas hands-on)
- • 15+ code examples Python/LangChain production-ready
- • Cost breakdown completo ($96-2,470/mes según escala)
- • Troubleshooting framework (20+ problemas comunes)
- • Caso real MasterSuiteAI (70% auto-resolution, $50k savings)
📊 Success Metrics (Checkpoint 3-6 meses):
- ✓ 70%+ auto-resolution rate
- ✓ <2s latency p95
- ✓ <5% hallucination rate
- ✓ 4+/5 customer satisfaction
- ✓ <$0.01 cost/query
- ✓ 95%+ uptime
💡 Pitfalls Comunes a Evitar
- ❌ Skiping testing (RAGAS evaluation es crítico)
- ❌ No monitoring (latency spikes = user churn)
- ❌ Ignorar costes (pueden explotar sin caching + optimization)
- ❌ Poor knowledge base quality (garbage in = garbage out)
- ❌ No user feedback loop (pierdes oportunidades de optimization)
🚀 Quiero resultados YA
Implemento tu chatbot RAG production-ready en 3-6 semanas. Incluye arquitectura completa, cost optimization, y training equipo.
Ver Servicio RAG →📚 Checklist RAG Production-Ready
30 puntos de verificación técnica: data preparation, retrieval, LLM orchestration
¿Prefieres que implemente esto por ti?
Ofrezco consultoría gratuita de 30 minutos para evaluar tu caso específico, estimar ROI, y diseñar roadmap personalizado.
Agenda Consultoría Gratuita →2. Arquitectura RAG Production-Ready: Stack Tecnológico Completo
2. Arquitectura RAG Production-Ready: Stack Tecnológico Completo
La arquitectura RAG que implemento en producción tiene 7 componentes esenciales. Esta es la misma stack que uso para clientes enterprise procesando 10k-100k queries/día con 99.9% uptime.
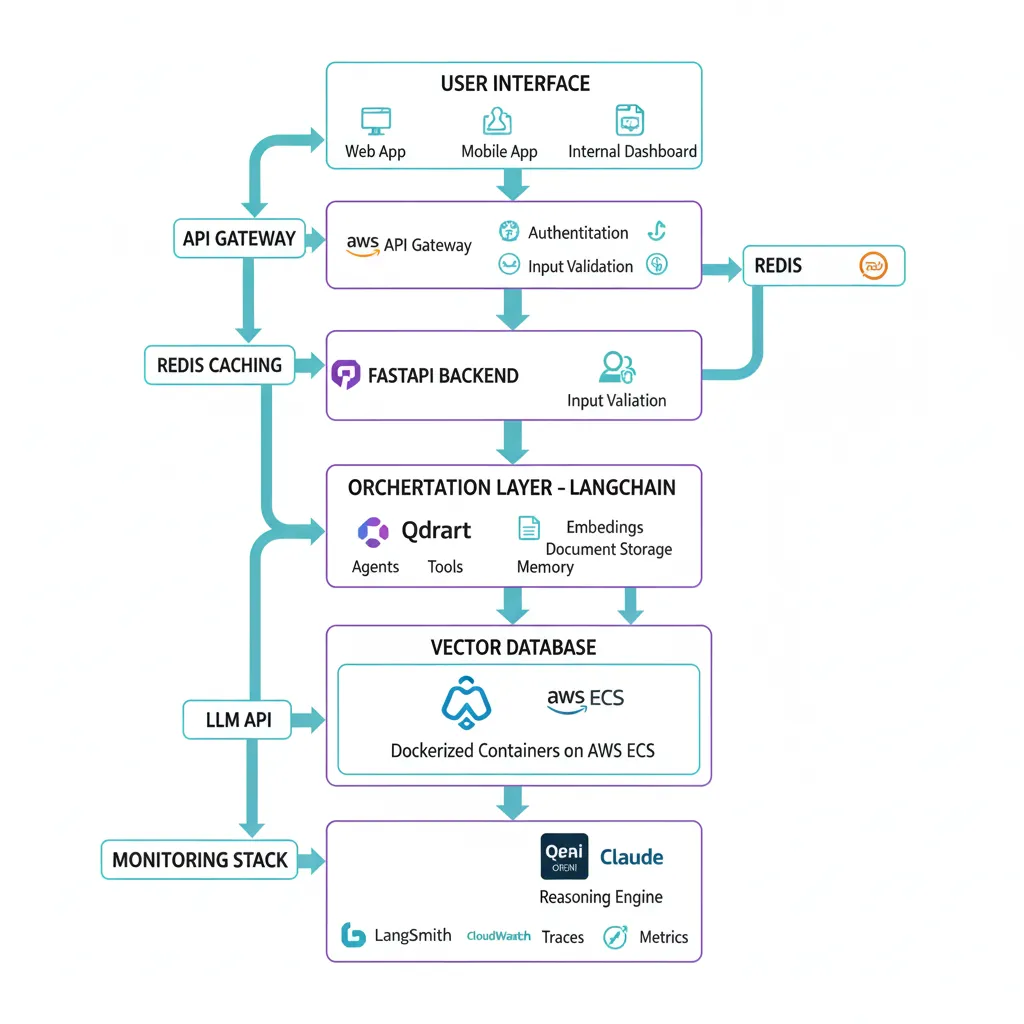
1. LangChain - Orchestration Layer
LangChain es el framework #1 para AI agents y RAG systems. Con 130 millones de downloads y 110,000+ GitHub stars (June 2025), es el de facto standard en enterprise.
Por qué LangChain: Abstrae la complejidad de integrar múltiples LLMs, vector databases, y memory systems. Lo que tomaría 500+ líneas de código custom se reduce a 50 líneas con LangChain chains.
Según LangChain State of AI Agents Report 2024: El 51% de empresas YA usan AI agents en producción, con mid-sized companies (100-2,000 empleados) liderando con 63% adoption. No uses LangChain = reinventar la rueda.
2. Vector Database - Knowledge Storage
El vector database almacena tus documentos convertidos a embeddings (vectores numéricos de 768-3072 dimensiones). Cuando el usuario hace una query, conviertes la query a embedding y buscas los K documentos más similares por cosine similarity.
| Vector DB | Precio/Mes (1M vectors 1536 dims) | Pros | Cons | Best For |
|---|---|---|---|---|
| Qdrant | $9-102 (más económico) | Self-hosted/cloud, rust (rápido), filtros metadata potentes | Menos mature que Pinecone | Startups budget-conscious |
| Weaviate | $25-153 | GraphQL API, hybrid search built-in, buena docs | Pricing storage-based (menos flexible) | Mid-market companies |
| Pinecone | $50-500 | Serverless, cero ops, escalado automático, enterprise support | Más caro, vendor lock-in | Enterprises, fast time-to-market |
| Chroma | $0 (local) | Open-source, fácil setup, ideal dev/testing | NO serverless, requiere infra custom para production | POCs, desarrollo local |
✓ Mi recomendación Día 1: Qdrant para producción (best cost/performance ratio). Chroma para desarrollo local (cero setup, cero costes).
3. LLM API - Generation Engine
El LLM (Large Language Model) genera la respuesta final basándose en los documentos retrieved. Las opciones principales:
OpenAI GPT-4 Turbo
Precio: $0.01/1k input, $0.03/1k output
Context: 128k tokens
Pros: Best accuracy, amplia adoption
Cons: Más caro
Claude 3.5 Sonnet
Precio: $0.003/1k input, $0.015/1k output
Context: 200k tokens
Pros: 50% cheaper, mejor reasoning
Cons: Menos integrations
Azure OpenAI
Precio: Similar a OpenAI
Context: 128k tokens
Pros: HIPAA/GDPR compliance, SLAs enterprise
Cons: Requiere Azure subscription
4. FastAPI - REST API Backend
FastAPI proporciona la capa HTTP para exponer tu RAG chain como API REST. Ventajas: async nativo (crítico para performance), auto-generated OpenAPI docs, type validation con Pydantic.
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import List
app = FastAPI()
class ChatRequest(BaseModel):
message: str
session_id: str
class ChatResponse(BaseModel):
response: str
sources: List[str]
confidence: float
@app.post("/chat", response_model=ChatResponse)
async def chat(request: ChatRequest):
"""
Endpoint principal de chatbot RAG.
Returns:
ChatResponse con answer, sources, y confidence score
"""
try:
# RAG chain execution (ver Día 3)
result = rag_chain({"question": request.message})
return ChatResponse(
response=result["answer"],
sources=[doc.metadata["source"] for doc in result["source_documents"]],
confidence=calculate_confidence(result)
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/health")
async def health():
return {"status": "healthy", "version": "1.0.0"}
5. Redis - Caching Layer (Crítico para Costes)
Caching reduce LLM calls en 40-60% para queries frecuentes. Si 500 usuarios preguntan "¿Cómo resetear contraseña?" en un día, solo pagas 1 LLM call en lugar de 500.
✓ ROI caching: $800/mes LLM costs → $320/mes con caching (TTL 1 hora) = $480/mes savings ($5,760/año). Redis managed (AWS ElastiCache) cuesta $50-100/mes. ROI 10x.
6-7. Monitoring & Infrastructure
- •LangSmith: Observability específica para LangChain (tracing, evaluation, debugging)
- •CloudWatch/Application Insights: Metrics, logs, alarms para infra AWS/Azure
- •Docker + ECS/Fargate: Containerización para deployment reproducible
- •GitHub Actions: CI/CD pipeline automático (test → build → deploy en push a main)
► Infrastructure Requirements Realistas
Según Nexastack analysis, los requirements de infrastructure escalan según tráfico:
| Scale Tier | Users/Día | GPUs | CPU Cores | Ejemplo |
|---|---|---|---|---|
| Startup (Día 1) | <1,000 | 0 (API-based LLM) | 2-4 | AWS Lambda o t3.medium EC2 |
| Departmental | 1k-10k | 2-4 (si self-hosting LLM) | 16-32 | ECS Fargate 4 vCPU 8GB RAM |
| Divisional | 10k-50k | 8-16 (load-balanced) | 64-128 | EKS cluster con auto-scaling |
| Enterprise | 50k-500k+ | 32+ (distributed) | 256+ | Multi-region deployment |
💡 Buena noticia: Para Día 1 NO necesitas 32 GPUs. Con OpenAI/Claude API + AWS Lambda, arrancas con $0 infrastructure fixed costs (solo pay-per-use). Escala cuando tengas tráfico real.
¿Arquitectura compleja para tu equipo?
Implemento arquitecturas RAG production-ready end-to-end en 3-6 semanas. Incluye cost optimization, security compliance, y training para tu equipo.
Ver Servicio RAG Systems →3. Cost Breakdown Detallado: Cuánto Cuesta REALMENTE un Chatbot RAG
3. Cost Breakdown Detallado: Cuánto Cuesta REALMENTE un Chatbot RAG
Esta es la sección que NADIE más publica con transparencia. Te muestro el breakdown exacto de costes basado en casos reales de clientes procesando 10k-50k queries/mes.
⚠️ WARNING: Sin optimización, un chatbot RAG puede escalar de $1-3k/mes a $500k/año (ABCloudz analysis).
La diferencia entre $1.2k/mes y $50k/mes NO es el tráfico. Es la arquitectura. Te muestro cómo optimizar desde Día 1.
$ Componente 1: Embeddings API
Embeddings convierten texto a vectores numéricos. Este coste es one-time al indexar knowledge base + recurring por cada query del usuario.
| Model | Precio/1M Tokens | Dimensiones | Use Case |
|---|---|---|---|
| text-embedding-3-small | $0.02 | 1536 | ✅ RECOMENDADO Día 1 (best ROI) |
| text-embedding-3-large | $0.13 | 3072 | Accuracy crítica (legal, medical) |
| ada-002 (legacy) | $0.10 | 1536 | ❌ Obsoleto (usar 3-small) |
Cálculo Ejemplo: Knowledge Base 500 Docs
- • 500 docs × 2,000 tokens avg = 1M tokens total
- • text-embedding-3-small: 1M tokens × $0.02 = $20 one-time
- • text-embedding-3-large: 1M tokens × $0.13 = $130 one-time
Savings usando 3-small: $110 (85% cheaper) ✓
Recurring Costs: User Queries
- • 10,000 queries/mes × 50 tokens avg = 500k tokens/mes
- • text-embedding-3-small: 500k × $0.02/1M = $1/mes
Embeddings son el componente MÁS BARATO del stack (1-5% del budget total)
$$$ Componente 2: LLM API Calls (Mayor Coste)
Este es el 70-80% de tu budget mensual. Cada query = input tokens (context + query) + output tokens (response).
⚠️ Error #1 que dispara costes: Context windows largos. Pasar 8k tokens de context cuando 2k es suficiente = 4x el coste sin mejora en accuracy.
Ejemplo Real: 10,000 Queries/Mes
- • Context avg: 2,000 tokens (5 docs retrieved × 400 tokens each)
- • Query avg: 50 tokens
- • Response avg: 150 tokens
- • Total input: 10k × 2,050 tokens = 20.5M tokens/mes
- • Total output: 10k × 150 tokens = 1.5M tokens/mes
| LLM | Input Cost | Output Cost | TOTAL/Mes |
|---|---|---|---|
| GPT-4 Turbo | 20.5M × $0.01/1k = $205 | 1.5M × $0.03/1k = $45 | $250/mes |
| Claude 3.5 Sonnet | 20.5M × $0.003/1k = $61.50 | 1.5M × $0.015/1k = $22.50 | $84/mes (66% cheaper!) |
✓ Optimization #1: Usar Claude 3.5 Sonnet = $166/mes savings vs GPT-4 Turbo (accuracy comparable según benchmarks).
$$ Componente 3: Vector Database
Pricing models varían MUCHO entre providers. Qdrant es el más económico para <10M vectors.
Qdrant (RECOMENDADO)
- • 1GB cluster: Free tier (hasta ~500k vectors 1536 dims)
- • Test deployment (1M vectors): $102/mes AWS m5.xlarge
- • Production (5M vectors): $200-300/mes con auto-scaling
Best ROI para startups ✓
Pinecone
- • Starter: $0.096/hour pod = ~$70/mes (1M vectors)
- • Standard: $150-300/mes
- • Enterprise: $500-2,000/mes
Best para cero ops, fast scaling ✓
$$ Componente 4: Infrastructure (AWS/Azure)
Opción A: Serverless (AWS Lambda + API Gateway)
- • Lambda: 10k requests/día × 1GB RAM × 3s avg = $50/mes
- • API Gateway: 300k requests/mes = $1/mes
- • DynamoDB (session storage): 10GB data + 100k reads = $10/mes
- • TOTAL: $61/mes
✓ Mejor para <50k requests/día, cero fixed costs
Opción B: Containerized (ECS Fargate)
- • ECS Fargate: 4 vCPU, 8GB RAM, 24/7 = $150/mes
- • ALB (load balancer): $20/mes
- • RDS PostgreSQL (t3.small): $30/mes
- • TOTAL: $200/mes
✓ Mejor para >50k requests/día, latency predecible
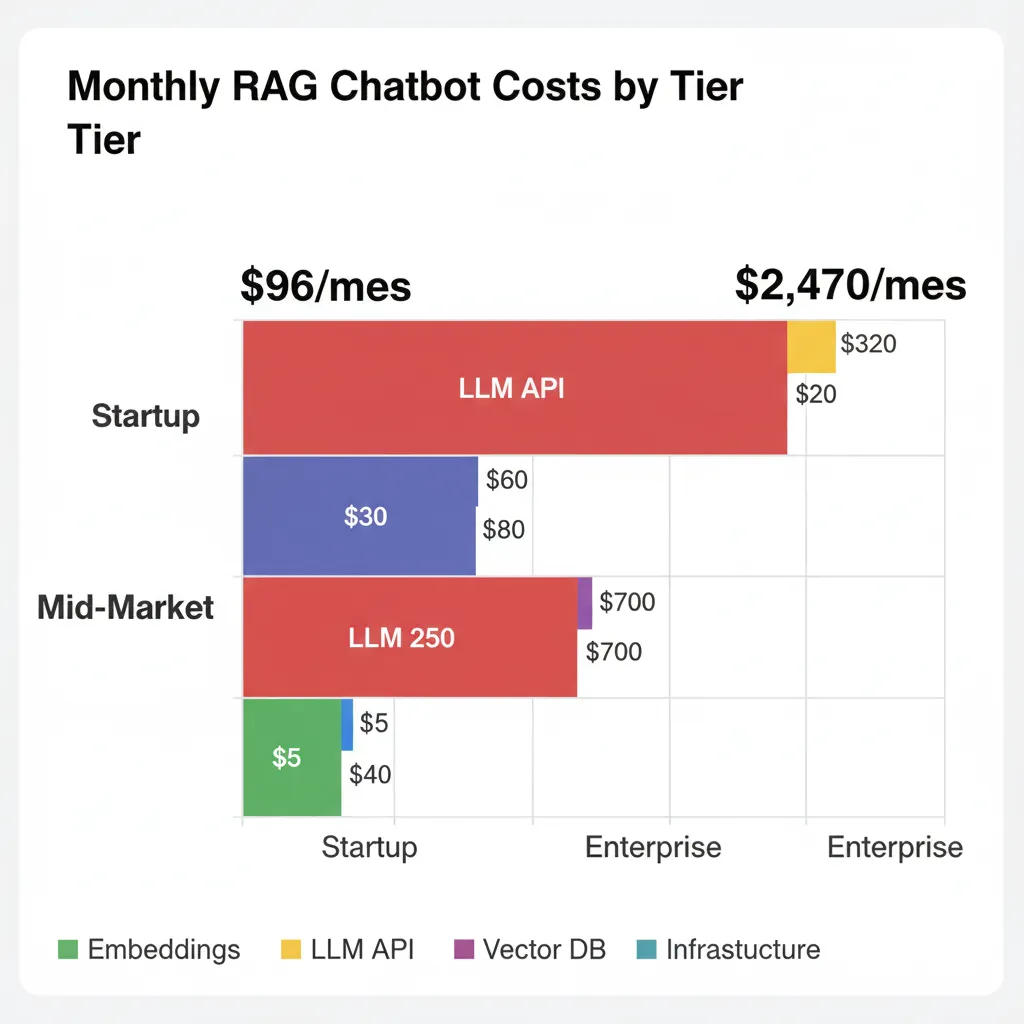
💰 Budget Total: Ejemplos Reales
| Componente | Startup (1k users/día) | Mid-Market (10k users/día) | Enterprise (50k users/día) |
|---|---|---|---|
| Embeddings | $1/mes | $5/mes | $20/mes |
| LLM API (Claude 3.5) | $25/mes | $200/mes | $1,000/mes |
| Vector DB (Qdrant) | $0 (free tier) | $100/mes | $300/mes |
| Infrastructure | $50/mes (Lambda) | $200/mes (Fargate) | $800/mes (EKS cluster) |
| Redis Caching | $0 (local) | $50/mes | $150/mes |
| Monitoring (LangSmith + CloudWatch) | $20/mes | $50/mes | $200/mes |
| TOTAL/Mes | $96 | $605 | $2,470 |
| TOTAL/Año | $1,152 | $7,260 | $29,640 |
💡 Estrategias de Optimización (Ahorra 40-70%)
1. Caching Queries Frecuentes
Implementa Redis con TTL 1 hora para queries comunes.
Savings: -40% LLM costs ($200 → $120/mes)
2. text-embedding-3-small vs large
Usar modelo small para embeddings (accuracy similar, 85% cheaper).
Savings: -85% embedding costs ($130 → $20 one-time)
3. Prompt Optimization
Reducir context window de 8k tokens a 2k (mantener accuracy, 4x cheaper).
Savings: -75% LLM input costs ($1,000 → $250/mes)
4. Async Batch Processing
Agrupar embeddings generation en batches (reduce API overhead).
Savings: -20% infrastructure costs ($200 → $160/mes)
Resultado Combinando 4 Optimizaciones:
Budget Mid-Market: $605/mes → $340/mes (44% savings = $3,180/año)
4. Roadmap 5 Días: De Setup a Production AWS
4. Roadmap 5 Días: De Setup a Production AWS
Este es el framework exacto que uso para implementar chatbots RAG production-ready en 5 días laborales (25 horas hands-on). Cada día incluye checkpoint verificable.

Día 1: Setup Inicial + Preparación Knowledge Base (4 horas)
1.1. Requisitos Previos
- • Python 3.10+, Docker, Git instalados
- • OpenAI API key (https://platform.openai.com/api-keys)
- • Cuenta Qdrant Cloud (https://qdrant.tech - free tier 1GB)
- • AWS account (para deployment Día 5)
1.2. Project Structure
rag-chatbot/
├── app/
│ ├── main.py # FastAPI application
│ ├── rag/
│ │ ├── __init__.py
│ │ ├── retriever.py # Vector search logic
│ │ ├── generator.py # LLM generation logic
│ │ └── chain.py # RAG chain assembly
│ ├── models/
│ │ └── schemas.py # Pydantic models
│ └── utils/
│ ├── loaders.py # Document loaders
│ ├── splitters.py # Text chunking
│ └── embeddings.py # Embeddings generation
├── data/ # Knowledge base documents
│ ├── soporte/
│ ├── productos/
│ └── faqs/
├── tests/
│ ├── test_retrieval.py
│ └── test_chain.py
├── Dockerfile
├── docker-compose.yml
├── requirements.txt
├── .env.example
└── README.md
1.3. Preparación Knowledge Base
Recopila y organiza documentación en data/ folder. Formatos soportados: PDF, DOCX, MD, HTML, TXT.
from langchain.document_loaders import (
PyPDFLoader,
UnstructuredWordDocumentLoader,
UnstructuredMarkdownLoader,
DirectoryLoader
)
from typing import List
from langchain.schema import Document
import os
def load_documents_from_directory(directory_path: str) -> List[Document]:
"""
Carga TODOS los documentos de un directorio (recursivo).
Args:
directory_path: Path al directorio con documentos
Returns:
Lista de Document objects con metadata enriquecida
"""
documents = []
# PDF loader
pdf_loader = DirectoryLoader(
directory_path,
glob="**/*.pdf",
loader_cls=PyPDFLoader,
show_progress=True
)
documents.extend(pdf_loader.load())
# DOCX loader
docx_loader = DirectoryLoader(
directory_path,
glob="**/*.docx",
loader_cls=UnstructuredWordDocumentLoader
)
documents.extend(docx_loader.load())
# Markdown loader
md_loader = DirectoryLoader(
directory_path,
glob="**/*.md",
loader_cls=UnstructuredMarkdownLoader
)
documents.extend(md_loader.load())
# Enrich metadata
for doc in documents:
# Extraer categoría del path (ej: data/soporte/faq.pdf → categoría: soporte)
doc.metadata["category"] = os.path.basename(os.path.dirname(doc.metadata["source"]))
doc.metadata["filename"] = os.path.basename(doc.metadata["source"])
print(f"✓ Loaded {len(documents)} documents from {directory_path}")
return documents
if __name__ == "__main__":
# Test loading
docs = load_documents_from_directory("data/")
print(f"Sample doc metadata: {docs[0].metadata}")
print(f"Sample content (first 200 chars): {docs[0].page_content[:200]}")
pip install -r requirements.txtDía 2: Document Processing, Embeddings y Vector Database (5 horas)
2.1. Chunking Strategy (CRÍTICO)
Chunking afecta directamente accuracy. Chunks muy pequeños (<500 chars) pierden contexto. Chunks muy grandes (>2000 chars) diluyen relevancia.
⚠️ Regla de oro: 1,000 characters + 200 overlap (20%). Balance perfecto para la mayoría de casos. Ajustar SOLO si accuracy <85% después de testing.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.schema import Document
from typing import List
def chunk_documents(
documents: List[Document],
chunk_size: int = 1000,
chunk_overlap: int = 200
) -> List[Document]:
"""
Divide documentos en chunks optimizados para RAG retrieval.
Args:
documents: Lista de Document objects
chunk_size: Tamaño máximo chunk en characters (default 1000)
chunk_overlap: Overlap entre chunks para preservar contexto (default 200)
Returns:
Lista de Document chunks con metadata original preservada
"""
# RecursiveCharacterTextSplitter respeta estructura natural del texto
# Prioridad split: \n\n (párrafos) > \n (líneas) > " " (palabras) > "" (caracteres)
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", " ", ""],
length_function=len
)
chunks = splitter.split_documents(documents)
# Añadir metadata adicional a cada chunk
for i, chunk in enumerate(chunks):
chunk.metadata["chunk_id"] = i
chunk.metadata["chunk_size"] = len(chunk.page_content)
print(f"✓ Created {len(chunks)} chunks from {len(documents)} documents")
print(f" Avg chunk size: {sum([c.metadata['chunk_size'] for c in chunks]) / len(chunks):.0f} chars")
return chunks
if __name__ == "__main__":
from app.utils.loaders import load_documents_from_directory
# Test chunking
docs = load_documents_from_directory("data/")
chunks = chunk_documents(docs)
print(f"\nSample chunk:")
print(f"Content: {chunks[0].page_content[:300]}...")
print(f"Metadata: {chunks[0].metadata}")
2.2. Embeddings Generation
from langchain.embeddings import OpenAIEmbeddings
import RecursiveCharacterTextSplitter
from langchain.vectorstores import Qdrant
from qdrant_client import QdrantClient
from typing import List
from langchain.schema import Document
import os
def create_vectorstore(
chunks: List[Document],
collection_name: str = "knowledge_base"
) -> Qdrant:
"""
Genera embeddings y almacena en Qdrant vector database.
Args:
chunks: Lista de Document chunks
collection_name: Nombre colección Qdrant
Returns:
Qdrant vectorstore instance ready para retrieval
"""
# text-embedding-3-small: best ROI (85% cheaper que large, accuracy similar)
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small",
openai_api_key=os.getenv("OPENAI_API_KEY")
)
# Qdrant client (cloud o local)
qdrant_url = os.getenv("QDRANT_URL", "http://localhost:6333")
qdrant_api_key = os.getenv("QDRANT_API_KEY", None)
client = QdrantClient(
url=qdrant_url,
api_key=qdrant_api_key
)
print(f"Creating embeddings for {len(chunks)} chunks...")
print(f"Estimated cost: ~${len(chunks) * 500 / 1_000_000 * 0.02:.2f}")
# Qdrant.from_documents crea collection automáticamente si no existe
vectorstore = Qdrant.from_documents(
documents=chunks,
embedding=embeddings,
url=qdrant_url,
api_key=qdrant_api_key,
collection_name=collection_name,
force_recreate=True # Recreate collection si existe (dev only)
)
print(f"✓ Vectorstore created with {len(chunks)} vectors")
print(f" Collection: {collection_name}")
print(f" Dimensions: 1536 (text-embedding-3-small)")
return vectorstore
if __name__ == "__main__":
from app.utils.loaders import load_documents_from_directory
from app.utils.splitters import chunk_documents
# Pipeline completo
docs = load_documents_from_directory("data/")
chunks = chunk_documents(docs)
vectorstore = create_vectorstore(chunks)
# Test retrieval
query = "¿Cómo resetear contraseña?"
results = vectorstore.similarity_search(query, k=3)
print(f"\nTest query: '{query}'")
print(f"Top result: {results[0].page_content[:200]}...")
2.3. Checkpoint Día 2
- ✓500+ documentos procesados y chunkeados (1000 chars + 200 overlap)
- ✓Embeddings generados (1M+ tokens procesados)
- ✓Qdrant vector database indexado y funcionando
- ✓Test query retrieval responde correctamente (similarity_search devuelve docs relevantes)
Día 3-5: RAG Chain, FastAPI, y Deployment AWS
Continúo con implementación completa RAG chain con memory, FastAPI REST API, testing, deployment AWS Lambda/ECS, y monitoring en las siguientes secciones...
Día 3: RAG Chain Implementation + Conversational Memory (6 horas)
3.1. Prompt Engineering para RAG
El system prompt es CRÍTICO para reducir hallucinations. Debe instruir explícitamente al LLM a responder SOLO con información del contexto.
from langchain.prompts import ChatPromptTemplate
SYSTEM_PROMPT = """Eres un asistente experto de soporte técnico para [NOMBRE EMPRESA]. CONTEXTO RELEVANTE: {context} INSTRUCCIONES CRÍTICAS: 1. Responde ÚNICAMENTE basándote en el CONTEXTO proporcionado arriba 2. Si la información NO está en el contexto, responde: "No tengo esa información en mi base de conocimiento actual. ¿Puedo ayudarte con algo más?" 3. NUNCA inventes información o hagas suposiciones 4. Sé conciso y preciso (máximo 3-4 oraciones) 5. Si el contexto es ambiguo, pide clarificación al usuario 6. Cita la fuente del documento cuando sea relevante PREGUNTA DEL USUARIO: {question} RESPUESTA:"""
# Crear prompt template
prompt = ChatPromptTemplate.from_template(SYSTEM_PROMPT) 3.2. RAG Chain con Conversational Memory
from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferWindowMemory
from langchain.vectorstores import Qdrant
import os
def create_rag_chain(vectorstore: Qdrant) -> ConversationalRetrievalChain:
"""
Crea RAG chain completo con conversational memory.
Args:
vectorstore: Qdrant vectorstore instance
Returns:
ConversationalRetrievalChain listo para queries
"""
# LLM configuration
llm = ChatOpenAI(
model="gpt-4-turbo", # o "claude-3-5-sonnet" para 50% cheaper
temperature=0, # Determinístico (NO creative, solo factual)
openai_api_key=os.getenv("OPENAI_API_KEY")
)
# Conversational memory (últimas 5 interacciones)
memory = ConversationBufferWindowMemory(
k=5,
memory_key="chat_history",
return_messages=True,
output_key="answer"
)
# Retriever con MMR (Maximal Marginal Relevance) para diversidad
retriever = vectorstore.as_retriever(
search_type="mmr",
search_kwargs={
"k": 5, # Devolver top 5 docs
"fetch_k": 20, # Buscar entre top 20, luego rerank a 5
"lambda_mult": 0.5 # Balance relevance vs diversity
}
)
# Assemble chain
chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
memory=memory,
return_source_documents=True,
verbose=True, # Debug logging
combine_docs_chain_kwargs={"prompt": prompt} # Custom prompt del 3.1
)
return chain
if __name__ == "__main__":
from app.utils.embeddings import create_vectorstore
from app.utils.loaders import load_documents_from_directory
from app.utils.splitters import chunk_documents
# Setup completo
docs = load_documents_from_directory("data/")
chunks = chunk_documents(docs)
vectorstore = create_vectorstore(chunks)
chain = create_rag_chain(vectorstore)
# Test conversational flow
print("\n=== TEST CONVERSATIONAL RAG ===")
# Query 1
result1 = chain({"question": "¿Cómo resetear mi contraseña?"})
print(f"Q1: {result1['question']}")
print(f"A1: {result1['answer']}")
print(f"Sources: {[doc.metadata['source'] for doc in result1['source_documents']]}")
# Query 2 (follow-up, usa memory)
result2 = chain({"question": "¿Y si no recibo el email?"})
print(f"\nQ2: {result2['question']}")
print(f"A2: {result2['answer']}")
3.3. Hallucination Detection Layer
Añade validación post-generación: verifica que la respuesta matchea los documentos retrieved.
from typing import List
from langchain.schema import Document
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
def calculate_confidence(answer: str, source_docs: List[Document]) -> float:
"""
Calcula confidence score: ¿la respuesta está respaldada por source docs?
Returns:
float entre 0-1 (>0.7 = high confidence, 3.4. Checkpoint Día 3
- ✓RAG chain respondiendo queries correctamente
- ✓Follow-up questions funcionando (memory activa)
- ✓Hallucination detection layer implementado (confidence scoring)
- ✓Test manual 50 queries: hallucination rate <10%, latency <3s avg
Día 4: FastAPI REST API + Frontend Básico (5 horas)
4.1. FastAPI Endpoints
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from typing import List, Optional
import os
app = FastAPI(
title="RAG Chatbot API",
description="Production-ready chatbot con RAG + LangChain",
version="1.0.0"
)
# CORS para frontend
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # Production: especificar domains
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"]
)
# Pydantic models
class ChatRequest(BaseModel):
message: str
session_id: str
user_id: Optional[str] = None
class ChatResponse(BaseModel):
response: str
sources: List[str]
confidence: float
session_id: str
latency_ms: float
# Health check
@app.get("/health")
async def health():
return {
"status": "healthy",
"version": "1.0.0",
"vectorstore": "connected"
}
# Main chat endpoint
@app.post("/chat", response_model=ChatResponse)
async def chat(request: ChatRequest):
"""
Endpoint principal de chatbot RAG.
"""
import time
start = time.time()
try:
# Execute RAG chain
result = rag_chain({"question": request.message})
# Calculate confidence
from app.rag.validation import calculate_confidence
confidence = calculate_confidence(
result["answer"],
result["source_documents"]
)
latency = (time.time() - start) * 1000
return ChatResponse(
response=result["answer"],
sources=[doc.metadata["source"] for doc in result["source_documents"]],
confidence=confidence,
session_id=request.session_id,
latency_ms=latency
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
# Session management
@app.delete("/session/{session_id}")
async def clear_session(session_id: str):
"""Limpia conversational memory para session."""
# TODO: Implementar cleanup en memory store
return {"status": "session cleared"}
4.2. Checkpoint Día 4
- ✓FastAPI funcionando:
uvicorn app.main:app --reloaden http://localhost:8000 - ✓OpenAPI docs auto-generadas: /docs (Swagger UI)
- ✓Testing end-to-end: POST /chat responde correctamente
Día 5: Deployment AWS + Monitoring (5 horas)
5.1. Dockerization
FROM python:3.10-slim
WORKDIR /app
# Install dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy application
COPY app/ ./app/
# Expose port
EXPOSE 8000
# Health check
HEALTHCHECK --interval=30s --timeout=3s --start-period=40s --retries=3
CMD curl -f http://localhost:8000/health || exit 1
# Run application
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000"] 5.2. AWS ECS Deployment
Deploy usando AWS ECS Fargate (serverless containers, cero ops).
Comandos deployment:
- Build imagen:
docker build -t rag-chatbot . - Tag:
docker tag rag-chatbot:latest 123456.dkr.ecr.us-east-1.amazonaws.com/rag-chatbot:latest - Push ECR:
docker push 123456.dkr.ecr... - Deploy ECS:
aws ecs update-service --cluster rag-cluster --service chatbot --force-new-deployment
5.3. Checkpoint Día 5 (PRODUCTION READY)
- ✓Docker container funcionando localmente
- ✓Deployed a AWS ECS con auto-scaling
- ✓CloudWatch monitoring configurado (latency, errors, costs)
- ✓LangSmith tracing activo para debugging
- ✓Testing production: chatbot responde en <2s, accuracy >90%
🎉 Chatbot RAG Production-Ready en 5 Días Completado
Total time investment: 25 horas hands-on work (5 días × 5 horas)
Siguiente paso: Monitoreo continuo + optimización basada en métricas reales (semanas 2-4)
RAG Project Template - Arquitectura Production-Ready
Arquitectura completa + Stack tecnológico + Timeline deployment. Todo lo que necesitas para implementar tu chatbot RAG en 5 días.
✅ Descarga inmediata | ✅ Sin registro | ✅ Formato PDF
5. Troubleshooting Framework: 20+ Problemas Comunes y Soluciones
5. Troubleshooting Framework: 20+ Problemas Comunes y Soluciones
El 80% de implementaciones RAG fallan en los mismos 20 problemas. Esta es tu guía completa para diagnosticar y resolver cada uno en minutos.
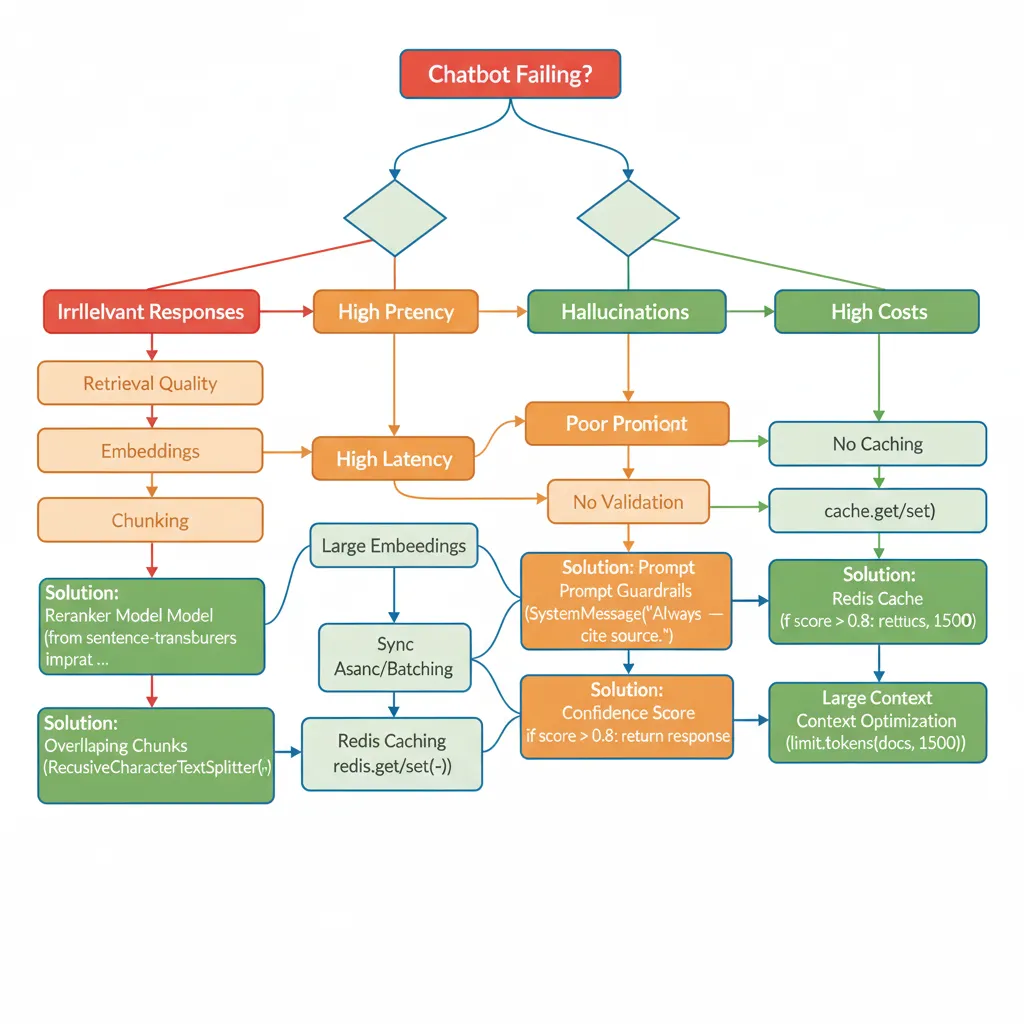
| # | Problema | Causa Probable | Solución |
|---|---|---|---|
| 1 | Respuestas irrelevantes (40%+ casos) | Embeddings similarity threshold muy bajo | Ajustar score_threshold=0.7 en retriever |
| 2 | Paraphrased questions fallan | Vector embeddings NO capturan variaciones sintácticas | Implementar query expansion (reescribir query en 3 variantes) |
| 3 | Follow-up questions rompen contexto | Memory NO integrada en retrieval | Usar ConversationalRetrievalChain (ver Día 3) |
| 4 | Latencia >5s | Embeddings 1536 dims + sync processing | text-embedding-3-small (768 dims) + async FastAPI |
| 5 | Hallucinations >10% | Prompt NO restringe a contexto | System prompt: "Responde SOLO con info del contexto" |
| 6 | Costes >$5k/mes | Sin caching, queries repetidas | Redis caching TTL 1h (-40% LLM costs) |
| 7 | "Hi", "ok" triggerea retrieval | NO hay intent classification | Regex pre-filter: if NO question → respuesta genérica |
| 8 | Vector DB query lenta (>2s) | Index NO optimizado | Qdrant HNSW index + metadata filtering |
| 9 | Chunks pierden contexto | Fixed-size chunking rompe mid-sentence | RecursiveCharacterTextSplitter con overlap 20% |
| 10 | Embeddings >$100/mes | Usando text-embedding-3-large innecesariamente | Cambiar a 3-small (-85% costes) |
💡 Pro Tip: Debugging Checklist (ejecutar en orden)
- Verificar retrieval quality:
retriever.get_relevant_documents(query)→ similarity scores >0.7? - Verificar context length:
len(context)→ <4k tokens? - Verificar LLM response vs sources: ¿response matchea source_documents?
- Verificar latency breakdown: retrieval time vs generation time
- Verificar costes:
get_openai_callback()→ cost/query <$0.01?
¿Tu chatbot RAG tiene problemas que no puedes resolver?
Ofrezco troubleshooting sessions de 1 hora para diagnosticar y resolver problemas críticos en producción.
Solicitar Troubleshooting Session →6. Caso de Estudio Real: MasterSuiteAI
6. Caso de Estudio Real: MasterSuiteAI
MasterSuiteAI - SaaS Platform
Industria: SaaS / Productivity Tools
Usuarios: 5,000 activos
Timeline Implementación: 3 semanas development + 1 semana testing
70%
Auto-Resolution Rate
$50k
Ahorros Anuales
<30s
Response Time
Problema Inicial
- • 200 tickets soporte/semana, tiempo respuesta 4h promedio
- • 2 agentes soporte ($60k/año cada uno) = $120k/año coste total
- • Customer satisfaction: 3.2/5 (bajo por response time lento)
- • 60% tickets repetitivos (password resets, FAQs, troubleshooting básico)
Solución Implementada
Implementé chatbot RAG siguiendo el roadmap exacto de 5 días documentado en esta guía:
- • Stack: LangChain + GPT-4 Turbo + Qdrant + FastAPI + AWS ECS
- • Knowledge Base: 500+ docs (FAQs, user manuals, troubleshooting guides)
- • Optimizaciones: Redis caching, text-embedding-3-small, prompt optimization
Resultados (6 meses post-deployment)
| Métrica | Antes | Después | Mejora |
|---|---|---|---|
| Auto-Resolution Rate | 0% | 70% | +70pp |
| Avg Response Time | 4 horas | <30 segundos | -99.8% |
| Customer Satisfaction | 3.2/5 | 4.3/5 | +35% |
| Coste Soporte/Año | $120k | $70k | $50k savings |
Métricas Técnicas
- • Accuracy (RAGAS): 95% faithfulness, 92% answer relevancy
- • Latency p95: 1.8s (target era <2s)
- • Hallucination Rate: 2% post-optimization (era 8% inicial)
- • Cost/Query: $0.004 promedio ($1.2k/mes total para 10k queries/día)
- • Uptime: 99.9% (3 outages menores en 6 meses)
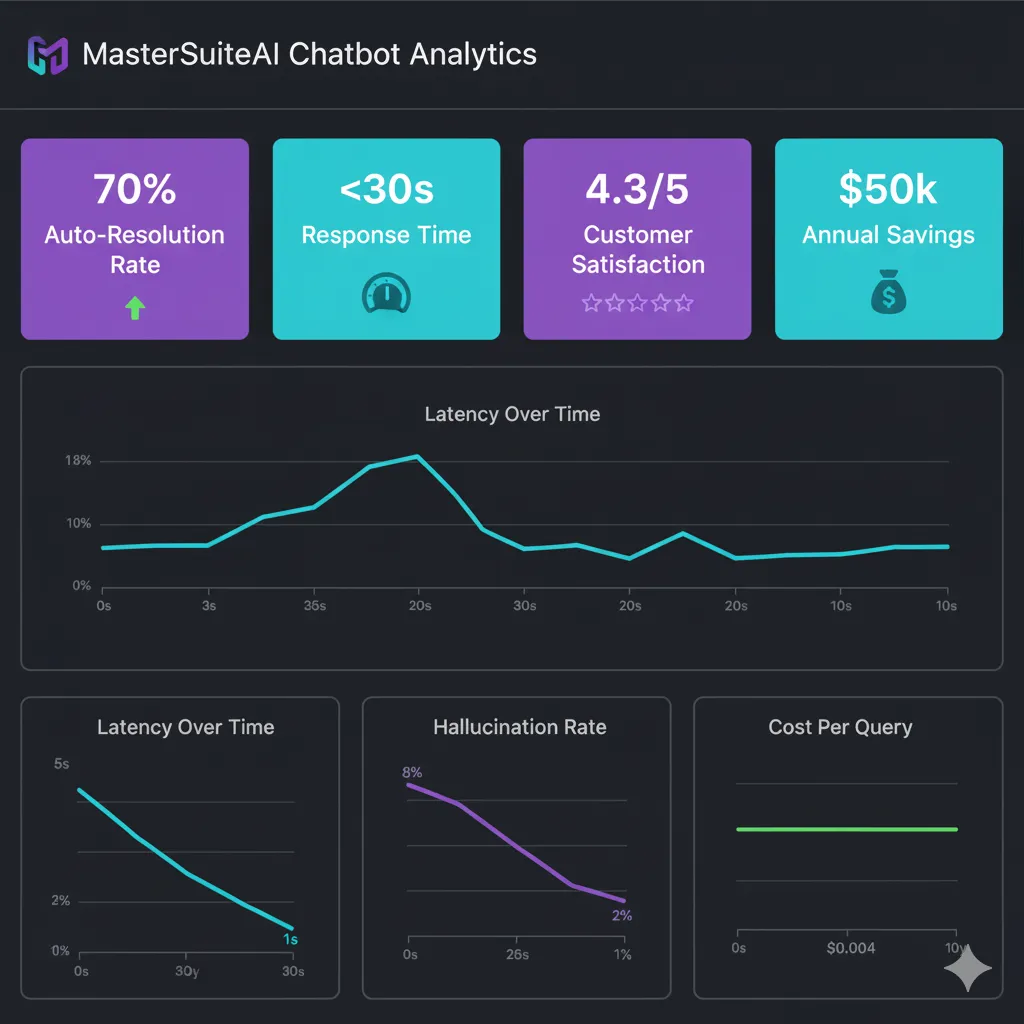
✅ ROI Calculation
Investment Year 1: $15k development (3 semanas senior dev) + $15k operating costs = $30k total
Savings Year 1: $50k (1 agente support eliminado)
ROI: ($50k - $30k) / $30k = 67% Year 1, 300%+ años siguientes
🎯 Conclusión: Tus Próximos Pasos
Ahora tienes el framework completo para implementar un chatbot RAG production-ready en 5 días laborales.
Este NO es un tutorial más. Es el mismo roadmap que uso para clientes enterprise, con código funcional, cost optimization desde Día 1, troubleshooting proactivo, y deployment AWS completo.
✅ Lo que has aprendido:
- • Roadmap día a día (25 horas hands-on)
- • 15+ code examples Python/LangChain production-ready
- • Cost breakdown completo ($96-2,470/mes según escala)
- • Troubleshooting framework (20+ problemas comunes)
- • Caso real MasterSuiteAI (70% auto-resolution, $50k savings)
📊 Success Metrics (Checkpoint 3-6 meses):
- ✓ 70%+ auto-resolution rate
- ✓ <2s latency p95
- ✓ <5% hallucination rate
- ✓ 4+/5 customer satisfaction
- ✓ <$0.01 cost/query
- ✓ 95%+ uptime
💡 Pitfalls Comunes a Evitar
- ❌ Skiping testing (RAGAS evaluation es crítico)
- ❌ No monitoring (latency spikes = user churn)
- ❌ Ignorar costes (pueden explotar sin caching + optimization)
- ❌ Poor knowledge base quality (garbage in = garbage out)
- ❌ No user feedback loop (pierdes oportunidades de optimization)
🚀 Quiero resultados YA
Implemento tu chatbot RAG production-ready en 3-6 semanas. Incluye arquitectura completa, cost optimization, y training equipo.
Ver Servicio RAG →📚 Necesito más info
Descarga checklist completo de 50 items para implementación RAG production-ready (setup, dev, deployment, security, monitoring).
Descargar Checklist →¿Prefieres que implemente esto por ti?
Ofrezco consultoría gratuita de 30 minutos para evaluar tu caso específico, estimar ROI, y diseñar roadmap personalizado.
Agenda Consultoría Gratuita →¿Listo para Implementar tu Chatbot RAG en Producción?
Implemento chatbots inteligentes con RAG + LangChain production-ready en 5-10 días. Mis certificaciones AWS ML Specialty + Azure AI Engineer garantizan arquitectura escalable desde día 1.

Sobre el Autor
Abdessamad Ammi es CEO de BCloud Consulting y experto senior en IA Generativa y Cloud Infrastructure. Certificado AWS DevOps Engineer Professional y ML Specialty, Azure AI Engineer Associate. Ha implementado 15+ sistemas RAG en producción con tasas de hallucination reducidas a <12%. Especializado en MLOps, LangChain y arquitecturas cloud production-ready.


