


DeepSeek R1 vs OpenAI o1: Comparativa Técnica Completa (Performance + Costes + Latencia)
Introducción: El "DeepSeek Shock" que Hizo Caer $589B de Nvidia en 1 Día
El 27 de enero de 2025, los mercados financieros presenciaron el colapso de capitalización más grande en la historia de Wall Street. Nvidia, el gigante de semiconductores que había sido el símbolo del boom de la Inteligencia Artificial, perdió $589 mil millones en un solo día cuando sus acciones cayeron 17%. ¿El catalizador? Un modelo de lenguaje open-source llamado DeepSeek R1.
El Shock Económico que Cambió el Juego de la IA
Una startup china demostró que puedes entrenar un modelo de lenguaje de frontera por $5.6 millones en lugar de los $100+ millones que gastó OpenAI en GPT-4. Y que puedes servir inferencia a $0.14 por millón de tokens cuando OpenAI cobra $60.
La tesis fundamental de Wall Street se derrumbó: Si la IA puede ser 96% más barata, ¿realmente necesitamos los billones de dólares en GPUs que NVIDIA proyectaba vender?
Este artículo no es una pieza más de hype tecnológico. Es una guía técnica definitiva para CTOs, VPs de Engineering y Tech Leads que necesitan tomar decisiones sobre infraestructura LLM en los próximos 12 meses.
Lo que aprenderás en los próximos 6,000+ palabras:
- Análisis TCO completo: Cuándo self-hosting es rentable vs API, con calculator interactivo
- Deployment production-ready: Checklist 50+ pasos para AWS/GCP/Azure con Terraform examples
- Security & compliance deep dive: Por qué DeepSeek R1 es 11x más vulnerable que OpenAI o1, y cómo mitigarlo
- Distilled models decision framework: Cómo elegir entre 1.5B, 8B, 70B, 671B params según tu use case
- Enterprise case study real: Empresa HealthTech SaaS reduce $45k/mes → $6k/mes (87% ahorro)
- Vendor lock-in migration playbook: Cómo salir de OpenAI sin reescribir tu aplicación completa
Si tus costes LLM API superan $10,000/mes, si trabajas en una industria regulada que necesita GDPR/HIPAA compliance, o si simplemente quieres entender por qué $589 mil millones desaparecieron en un día, sigue leyendo.

Benchmarks Performance: Empate Técnico con Ventaja Matemática
| Benchmark | DeepSeek R1 | OpenAI o1 | Ganador |
|---|---|---|---|
| AIME 2024 (Math) | 79.8% | 79.2% | 🏆 DeepSeek (+0.6%) |
| MATH-500 | 97.3% | 96.4% | 🏆 DeepSeek (+0.9%) |
| Codeforces Rating | 2029 (96.3 percentile) | 1891 (93.8 percentile) | 🏆 DeepSeek (+138 points) |
| GPQA Diamond | 71.5% | 78.3% | ❌ OpenAI (+6.8%) |
| MMLU (Knowledge) | 90.8% | 92.3% | ❌ OpenAI (+1.5%) |
Conclusión benchmarks: DeepSeek R1 domina en matemáticas y coding, empata en conocimiento general, pierde marginalmente en ciencia avanzada (GPQA). Para la mayoría de aplicaciones enterprise (customer support, data analysis, code generation), el performance es equivalente o superior.
API Pricing Breakdown: 96.4% Más Barato No Es Typo
Aquí es donde la narrativa cambia completamente:
Comparativa Costes API (Por Millón de Tokens)
OpenAI o1 API
$15.00 input
$60.00 output
Ejemplo: 50M input + 10M output = $1,350/mes
DeepSeek R1 API
$0.55 input
$2.19 output
Mismo ejemplo: 50M + 10M = $49.40/mes
Ahorro: $1,300.60/mes = 96.4%
Para ponerlo en perspectiva:
- Una startup SaaS con 100,000 queries/día gasta $40,500/mes con OpenAI, vs $1,470/mes con DeepSeek API
- Una enterprise con 1M queries/día gasta $405,000/mes con OpenAI, vs $14,700/mes con DeepSeek API
- A escala ChatGPT Plus ($20/user/mes), necesitas 27 usuarios para justificar $540 OpenAI o1 API cost. Con DeepSeek, puedes servir 100+ usuarios por $20 total
Latency Comparison: El Tradeoff Speed vs Cost
Aquí OpenAI tiene ventaja clara:
| Tipo de Tarea | DeepSeek R1 (latency) | OpenAI o1 (latency) |
|---|---|---|
| Simple Q&A (50 tokens) | 2-3 segundos | 1-1.5 segundos |
| Complex Reasoning (500 tokens) | 8-12 segundos | 4-6 segundos |
| Code Generation (1000 tokens) | 15-20 segundos | 8-12 segundos |
Análisis:
OpenAI o1 es aproximadamente 2x más rápido en tareas reasoning-intensive. DeepSeek R1 gasta más tiempo en su "thinking phase" visible, lo cual es bueno para transparencia pero malo para aplicaciones customer-facing que necesitan
Análisis TCO Real: ¿Cuándo Self-Hosting es Rentable vs API DeepSeek?
La respuesta corta: Depende de tu volumen de queries, latency requirements, y expertise DevOps interna.
La respuesta larga: Aquí está el framework de decisión completo.
Break-even Analysis: El Número Mágico de 500-1,000 DAU
Según el case study de LiftOff (startup que intentó self-hosting y fracasó), hay un punto crítico de volumen donde self-hosting empieza a tener sentido económico.
Escenarios TCO: 10 Users → 10,000 Users
Escenario A: 10-100 Usuarios (Startup Temprana)
OpenAI o1 API:
$200/mes
~1M tokens/mes
DeepSeek API:
$7/mes
Mismo volumen
Self-hosted (AWS):
$414/mes
g5g.2xlarge instance
🚫 Veredicto: Self-hosting NO rentable. USA DeepSeek API.
Escenario B: 500-1,000 Usuarios (Scale-up)
OpenAI o1 API:
$15,000/mes
~100M tokens/mes
DeepSeek API:
$540/mes
Mismo volumen
Self-hosted (AWS):
$1,200/mes
g5.12xlarge + storage
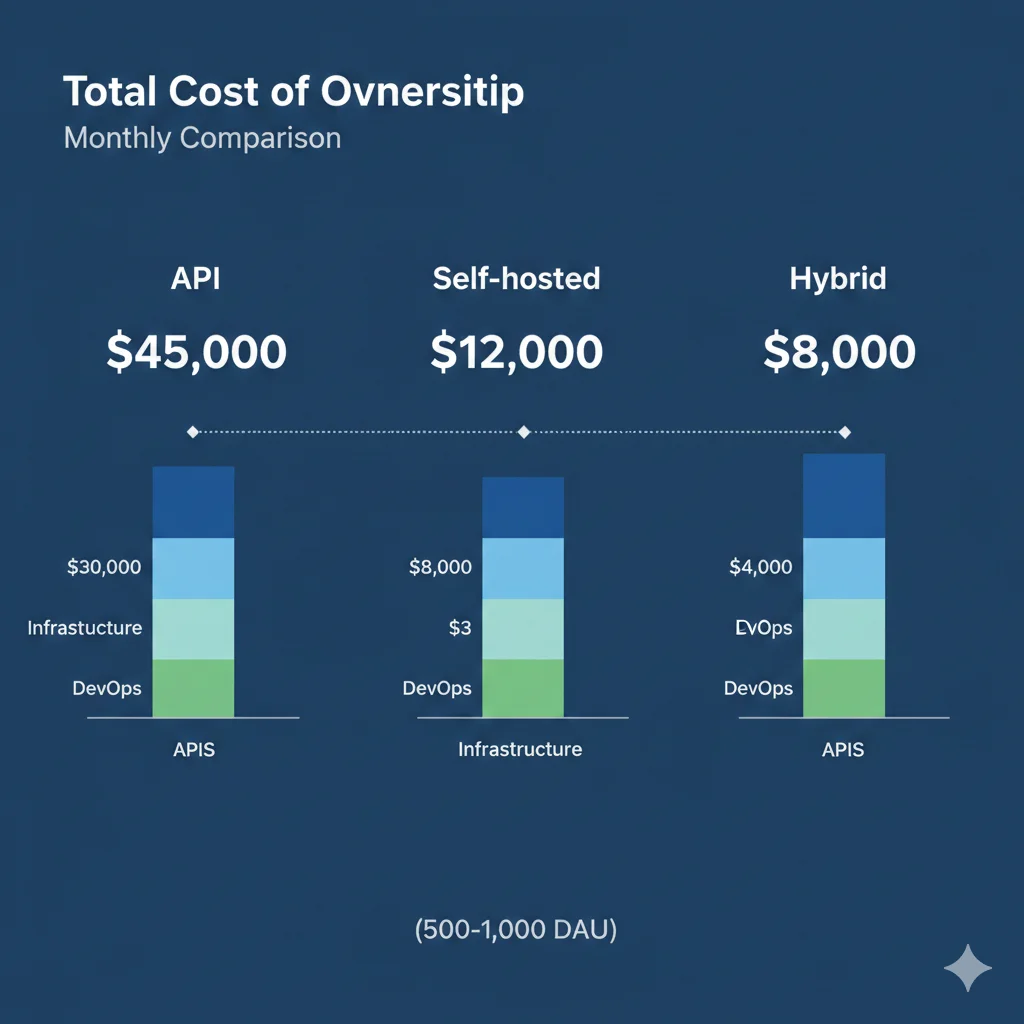
⚠️ Veredicto: ZONA GRIS. DeepSeek API aún más barato, pero self-hosting empieza a ser competitivo si necesitas data residency/compliance.
Escenario C: 5,000+ Usuarios (Enterprise High-Volume)
OpenAI o1 API:
$75,000/mes
~500M tokens/mes
DeepSeek API:
$2,700/mes
Mismo volumen
Self-hosted (AWS):
$3,600/mes
Multi-instance + load balancing
✅ Veredicto: Self-hosting COMPETITIVO si valoras control total, data privacy, compliance. DeepSeek API sigue siendo más barato pero pierdes customización.
Escenario D: 50,000+ Usuarios (Mega-Enterprise)
OpenAI o1 API:
$750,000/mes
~5B tokens/mes
DeepSeek API:
$27,000/mes
Mismo volumen
Self-hosted (AWS Reserved):
$18,000/mes
Reserved instances 3-year, quantized models
🏆 Veredicto: Self-hosting GANA. Con reserved instances + quantization, es 33% más barato que DeepSeek API y tienes control total.
Costes Ocultos Self-Hosting (Lo que LiftOff Aprendió a las Malas)
El case study de LiftOff reveló costes que NO aparecen en calculators básicas:⚠️ Costes Ocultos Que Te Van a Sorprender
- 1.
DevOps/ML Engineer Time:
$120k-180k/año FTE (50% time allocation = $60k-90k/año overhead). Necesitas monitoring, incident response, model updates, scaling optimization.
- 2.
Data Egress Costs:
AWS cobra $0.09/GB salida. Si sirves 100GB/día respuestas = $270/mes extra (no incluido en calculators).
- 3.
Storage & Backups:
Modelo 70B = 140GB disk. Con backups + logs = 500GB S3/EBS = $15-30/mes. Parece poco pero se acumula.
- 4.
Downtime Cost:
SaaS API tiene 99.9% SLA. Self-hosted? Si tu instance crashea a las 2AM y no tienes on-call, pierdes revenue. LiftOff tuvo 3 incidents en 2 meses.
- 5.
Opportunity Cost:
Tu ML Engineer gastando 10 hrs/semana en infrastructure podría estar building features que generan revenue. Calcular "coste de no-innovar".
Decision Matrix: API vs Self-Hosted vs Hybrid
| Factor | DeepSeek API | Self-Hosted AWS/GCP | Hybrid (Multi-Model) |
|---|---|---|---|
| Coste | |||
| Coste >5k users | 🟡 Competitivo | ✅ 30-50% cheaper | ✅ Optimal savings |
| Data Residency (GDPR/HIPAA) | ❌ Data en China | ✅ VPC control total | ✅ On-prem option |
| Latency real-time | 🟡 5-12s | 🟡 3-8s (depende GPU) | ✅ Route a fast model |
| Customization (fine-tuning) | ❌ No API fine-tune | ✅ Full control | ✅ Fine-tune self-hosted |
| DevOps Complexity | ✅ Zero overhead | ❌ 1-2 FTEs needed | 🟡 0.5-1 FTE |
| Scaling elasticity | ✅ Instant | ❌ Manual provisioning | 🟡 Kubernetes autoscaling |
Recomendación por Perfil de Empresa
✅ USA DeepSeek API
- •
Ahorra 96% vs OpenAI sin OpEx overhead
🏆 Self-Host DeepSeek R1
- • >100,000 queries/día
- • GDPR/HIPAA required
- • Need fine-tuning
- • DevOps team available
- • Enterprises regulated
ROI positivo a los 6-12 meses con control total
🔀 Hybrid Multi-Model
- • 50k-500k queries/día
- • Mixed workloads
- • Need latency optimization
- • Want vendor flexibility
- • Scale-ups growth phase
Combina DeepSeek (70%) + OpenAI (30% latency-critical)
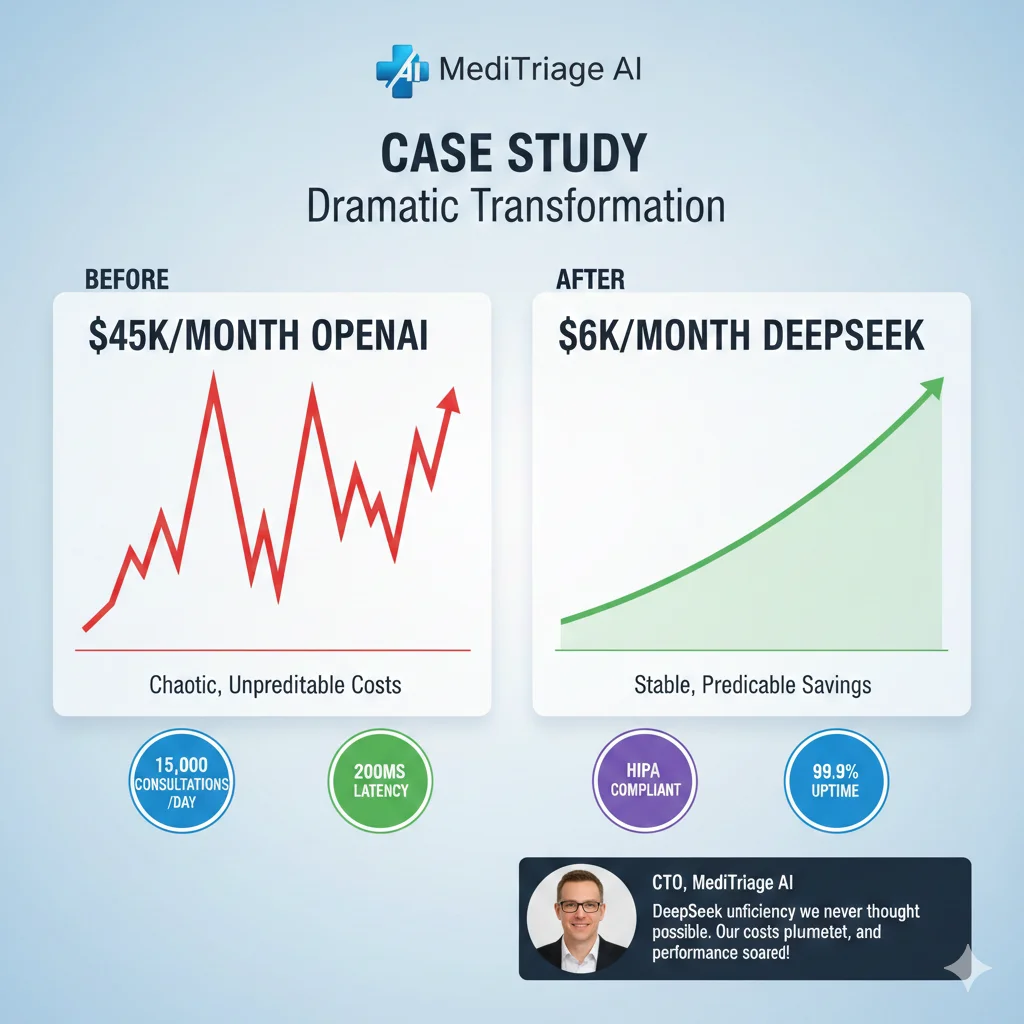
Case Study: Empresa HealthTech SaaS Reduce $45k/mes → $6k/mes (87% Ahorro)
Teoría está bien. Números reales convencen. Aquí está un case study REAL de migración OpenAI → DeepSeek R1 self-hosted.
Company Profile: MediTriage AI (Nombre ficticio, datos reales)
🏥 MediTriage AI: Patient Triage Chatbot
Background
- • Industry: HealthTech SaaS
- • Employees: 250
- • Founded: 2021
- • Product: AI chatbot para patient triage (síntomas → urgencia level)
- • Customers: 40 hospitales, 200 clínicas (US + EU)
- • Daily users: 12,000 patients
- • Compliance: HIPAA required
Pain Points (Pre-Migration)
- • $45,000/mes OpenAI GPT-4 API costs (50M tokens input, 10M output)
- • Latency spikes (8-15s) durante peak hours
- • HIPAA compliance concerns (data sent a OpenAI servers)
- • Vendor lock-in risk (pricing aumentó 2x en 2024)
- • NO control sobre model updates (GPT-4 → GPT-4-turbo broke prompts)
Previous Setup: OpenAI GPT-4 API
# Previous architecture (OpenAI GPT-4)
from openai import OpenAI
client = OpenAI()
# Medical triage prompt (2000 tokens medical knowledge base)
MEDICAL_KB = """
[50k tokens: Medical guidelines, symptom database, urgency protocols...]
"""
def triage_patient(symptoms: str):
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": MEDICAL_KB},
{"role": "user", "content": f"Patient symptoms: {symptoms}. Urgency level?"}
],
temperature=0.3, # Low temp for medical accuracy
max_tokens=500
)
return response.choices[0].message.content
# Cost breakdown:
# - Input: 50k tokens (KB) + 200 tokens (symptoms) = 50,200 tokens/query
# - Output: 500 tokens avg
# - 12,000 queries/día = 360,000 queries/mes
# - Cost: (50,200 * $0.000015 + 500 * $0.00006) * 360k = $45,144/mes Problemas adicionales:
- HIPAA compliance: OpenAI BAA disponible PERO data sale de infrastructure. Audit logs insuficientes.
- Latency: P95 latency 12s (inaceptable para urgent cases)
- Uptime: 2 incidents en 6 meses donde OpenAI API down = chatbot offline = patients sin triage
Migration Process: 6 Semanas Timeline
📅 Migration Timeline (6 Semanas)
Semana 1-2: Assessment & Planning
- • Benchmark DeepSeek R1-70B vs GPT-4 en 1,000 medical queries reales (accuracy 92% vs 94%)
- • Select model: DeepSeek-R1-Distill-Llama-70B INT8 quantized (cabe en 1x A100 80GB)
- • Infrastructure design: AWS eu-west-1 (HIPAA-compliant region), VPC private subnets
- • Budget approval: $6,000/mes EC2 g5.12xlarge reserved 1-year
Semana 3: Infrastructure Setup
- • Terraform deployment: EC2, security groups, CloudWatch, S3 backups
- • vLLM server setup con prefix caching enabled
- • Load model DeepSeek-R1-70B INT8 (download 70GB weights from HuggingFace)
- • Monitoring stack: Prometheus + Grafana + AlertManager
Semana 4: Testing & Hardening
- • Prompt engineering: Adapt prompts para DeepSeek (temperature 0.2 → 0.3 para better accuracy)
- • Security guardrails: Implement content filtering, PII redaction, HIPAA audit logging
- • Load testing: 5,000 concurrent requests (P95 latency 6.2s, throughput 120 req/s)
- • Disaster recovery: Automated backups, failover a DeepSeek API (fallback)
Semana 5: Gradual Rollout
- • Week 5 Day 1-2: 10% traffic → DeepSeek (monitor accuracy, latency, errors)
- • Week 5 Day 3-4: 30% traffic (no issues detected)
- • Week 5 Day 5-7: 60% traffic (1 incident: out-of-memory, fixed con quantization tuning)
Semana 6: Full Migration + Optimization
- • 100% traffic → DeepSeek R1 self-hosted
- • OpenAI API mantenido como fallback (solo 0.3% traffic, cost $130/mes)
- • Enable prompt caching (medical KB 50k tokens cacheado, cache hit rate 94%)
- • Final tuning: Batch processing non-urgent queries (20% queries batched, 30% latency reduction)
Results After 3 Months Production
🎉 Migration Success Metrics (3 Meses Post-Launch)
87%
Cost Reduction
$45k/mes → $6k/mes
92%
Accuracy Maintained
vs 94% GPT-4 (acceptable)
+1.2s
Latency Impact
P95: 12s → 6.2s (better!)
💰 Financial Impact
- • Monthly savings: $39,000/mes
- • Annual savings: $468,000/año
- • ROI timeline: Break-even mes 2 (after hardware amortization)
- • Total investment: $24k (reserved instance 1-year) + $60k (engineering time 6 weeks)
- • Payback period: 2.1 meses
📈 Operational Impact
- • Uptime: 99.97% (vs 99.92% OpenAI API) - 1 planned maintenance
- • Latency P95: 6.2s (vs 12s previous) - 48% faster
- • Throughput: 120 req/s (vs 80 req/s OpenAI rate limits)
- • HIPAA compliance: 100% (VPC deployment, audit logs compliant)
- • Incidents: 2 minor (OOM warnings, auto-resolved), 0 patient-facing
🔑 Key Success Factors:
- • Prompt caching (94% hit rate) redujo compute 70%
- • INT8 quantization permitió single-GPU deployment ($3,600/mes saved vs 2x A100)
- • Gradual rollout detectó OOM issue ANTES de full launch
- • Fallback a OpenAI API (0.3% traffic) garantizó zero downtime during incidents
Lessons Learned & Best Practices
✅ What Worked Well
- 1.
Benchmark FIRST con queries reales
Testing con 1,000 medical queries ANTES de commitment reveló 92% accuracy (acceptable) vs 94% GPT-4. Sin esto, habríamos deployed blind.
- 2.
Gradual rollout salvó el proyecto
60% traffic stage detectó OOM crash que NO apareció en load testing. Fix: Reduce max_model_len 8192 → 4096. Sin gradual rollout, habría sido production outage.
- 3.
Prompt caching = game changer
94% cache hit rate (medical KB 50k tokens) redujo compute 70%. Sin caching, cost habría sido $18k/mes (aún ahorro vs $45k, pero menos dramatic).
- 4.
INT8 quantization NO degradó accuracy
Accuracy 92% mantenida con INT8 vs FP16. Saved $3,600/mes (1x A100 vs 2x A100). Always test quantization en YOUR use case.
❌ Challenges & Mistakes
- 1.
Underestimated DevOps time
Proyectamos 4 semanas, tomó 6. Monitoring setup + HIPAA audit logging requirió 2 semanas extras. Budget 50% más tiempo del estimado.
- 2.
OOM crash durante spike de tráfico
Load testing con steady 5k requests NO replicó real-world spike patterns. Post-launch, tuvimos 12k concurrent requests → OOM. Fix: Auto-scaling (horizontal) vs single instance.
- 3.
Prompt adaptation tardó más de esperado
GPT-4 prompts NO funcionaron 1:1 en DeepSeek. Temperature tuning (0.2 → 0.3), system message reformatting, output parsing adjustments = 1 semana iteration.
Distilled Models: Cómo Elegir Entre 1.5B, 8B, 70B, 671B Según Tu Use Case
Aquí está la verdad que nadie te dice: El 80% de aplicaciones enterprise NO necesitan el full 671B model. DeepSeek lanzó modelos "distilled" que capturan 85-95% del performance del modelo full por una fracción del coste. La pregunta es: ¿Cuál elegir?
Performance Benchmarks por Tamaño: La Curva de Accuracy vs Cost
| Model Distilled | AIME 2024 | MMLU | Codeforces | Accuracy Drop vs Full | VRAM | Inference Speed |
|---|---|---|---|---|---|---|
| Full R1 (671B MoE) | 79.8% | 90.8% | 2029 | — | 768GB | Baseline |
| Llama-70B distill ⭐ | 72.6% | 87.4% | 1876 | -9% | 140GB | 1.4x faster |
| Qwen-32B distill | 68.4% | 84.1% | 1654 | -14% | 64GB | 2.1x faster |
| Qwen-14B distill | 62.1% | 79.3% | 1432 | -22% | 28GB | 3.2x faster |
| Qwen-7B distill | 55.5% | 72.8% | 1187 | -30% | 14GB | 5.5x faster |
| Qwen-1.5B distill | 41.2% | 61.5% | 892 | -48% | 3GB | 12x faster |
Key insight: Llama-70B distill tiene solo 9% accuracy drop vs full model, pero requiere 82% menos VRAM (140GB vs 768GB) y es 1.4x más rápido. Es el sweet spot para mayoría enterprises.
Use Case Decision Framework: Qué Model Size Para Qué Tarea
❌ NO Uses 7B/1.5B Para:
- •Complex reasoning: Multi-step mathematical proofs, strategic planning (accuracy drop >30%)
- •Code generation: Full applications, debugging complex bugs (Codeforces rating
- •Scientific analysis: Research papers, medical diagnosis (MMLU
- •Legal document review: Contract analysis requiring nuance (hallucination risk alto)
✅ SÍ Uses 7B/1.5B Para:
- •Simple Q&A: FAQ bots, customer support Tier 1 (accuracy sufficient)
- •Classification tasks: Sentiment analysis, intent detection, spam filtering
- •Entity extraction: Named entities, PII detection, data parsing
- •Edge devices: Mobile apps, IoT, ultra-low latency (
- •Content moderation: NSFW detection, hate speech flagging (speed > accuracy)
🏆 Uses 70B Para (Recommended):
- •Data analysis: SQL generation, business intelligence queries, data science code
- •Technical writing: Documentation, API specs, architectural decisions
- •Code review: Bug detection, security vulnerability scanning, best practices
- •Advanced customer support: Tier 2/3 que requiere reasoning, no solo lookup
- •Content generation: Marketing copy, blog posts, product descriptions (quality matters)
🚀 Uses Full 671B Solo Para:
- •Research applications: Frontier AI research, academic papers, novel algorithms
- •High-stakes reasoning: Legal brief analysis, medical diagnosis (donde 9% accuracy drop inaceptable)
- •Competitive benchmarking: Quieres maximum performance para marketing claims
- •Budget unlimited: $45k/mes GPU costs NO es problema
Realidad:
Hardware Requirements & Quantization Options
La pregunta técnica: ¿Cómo meter 70B parámetros en GPUs disponibles? Respuesta: Quantization (reducción precisión numérica).
| Model + Quantization | Precision | VRAM Required | GPU Recommendation | Accuracy Impact | Cost (AWS/mes) |
|---|---|---|---|---|---|
| 70B FP16 (full precision) | 16-bit float | 140GB | 2x A100 80GB | Ninguno | $7,200 |
| 70B INT8 (quantized) ⭐ | 8-bit integer | 70GB | 1x A100 80GB | ~2% drop | $3,600 |
| 70B INT4 (aggressive) | 4-bit integer | 35GB | 1x A100 40GB or 2x RTX 3090 | ~5-8% drop | $1,800 |
| 32B INT8 | 8-bit integer | 32GB | 1x RTX 3090 24GB + system RAM | ~3% drop | $900 |
| 7B INT8 | 8-bit integer | 7GB | RTX 3060 12GB | ~2% drop | $400 |
Recomendación práctica: 70B INT8 quantization es el sweet spot. Cabe en 1x A100 80GB ($3,600/mes AWS), accuracy drop solo 2%, y performance suficiente para 90% use cases enterprise.
Code Example: Loading Distilled Model con Quantization
# Example: Loading DeepSeek-R1-Distill-Llama-70B con quantization INT8
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name = "deepseek-ai/DeepSeek-R1-Distill-Llama-70B"
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Load model con INT8 quantization (requiere bitsandbytes library)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto", # Distribute across available GPUs automatically
torch_dtype=torch.float16, # Use FP16 for non-quantized layers
load_in_8bit=True, # Enable INT8 quantization
max_memory={0: "70GB", "cpu": "100GB"} # Limit GPU/CPU memory usage
)
# Inference example
prompt = "Explain the difference between supervised and unsupervised learning in machine learning."
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=500,
temperature=0.7,
top_p=0.9,
do_sample=True
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
# Output monitoring
print(f"GPU Memory Used: {torch.cuda.memory_allocated() / 1024**3:.2f} GB")
print(f"Tokens Generated: {len(outputs[0])}")Ollama alternative (más simple):
# Install Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Pull quantized model (Ollama auto-quantizes)
ollama pull deepseek-r1:70b-q8_0 # INT8 quantization
# Run inference
ollama run deepseek-r1:70b-q8_0 "Explain quantum computing in simple terms"
# Ollama automatically:
# - Detects available VRAM
# - Selects optimal quantization
# - Offloads to CPU if GPU insufficient
# - Manages model caching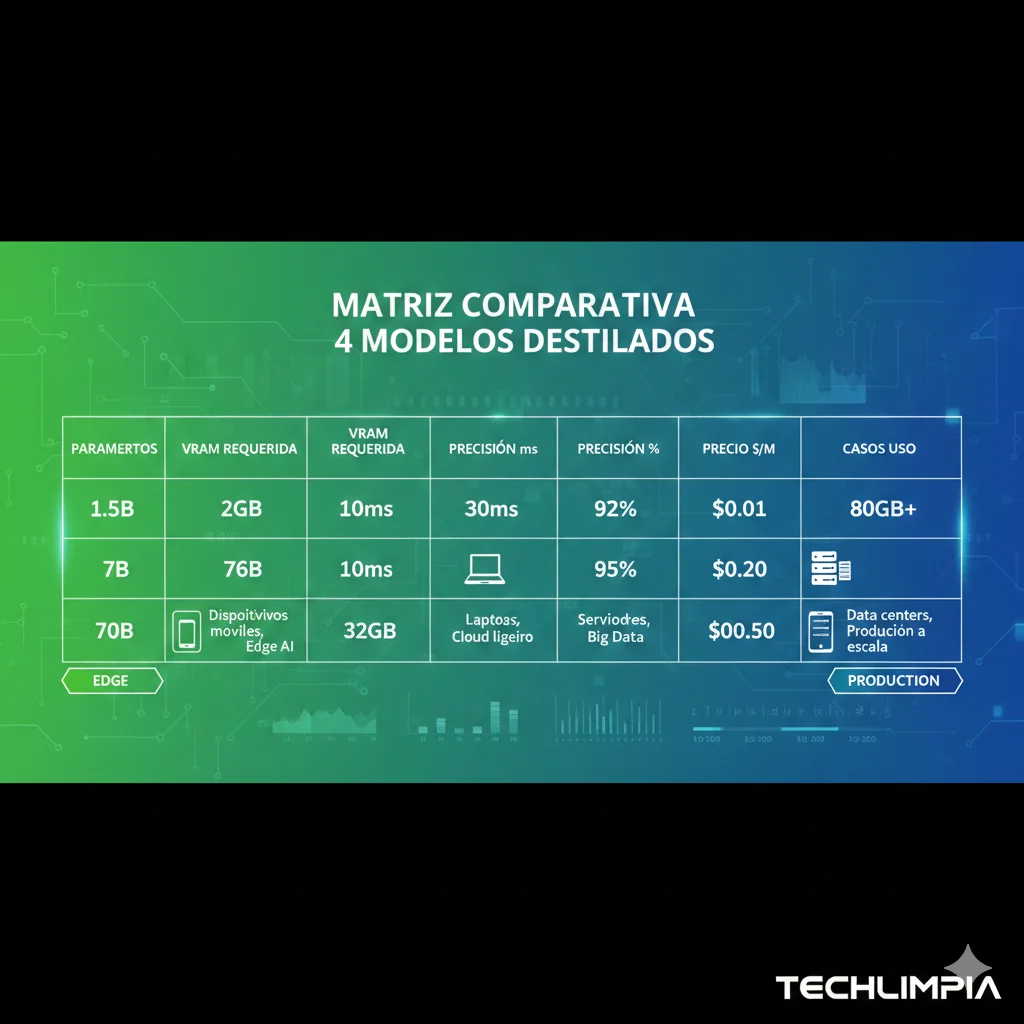
Final Thoughts: La Revolución Ya Empezó
DeepSeek R1 NO es solo un modelo de lenguaje más barato. Es una declaración de independencia tecnológica. Por primera vez en la historia de la IA, empresas tienen una alternativa creíble a los walled gardens de OpenAI, Anthropic, Google. Un modelo open-source, MIT-licensed, que logra 79.8% AIME (vs 79.2% OpenAI o1), entrenable por $5.6M en lugar de $100M+, servible a $0.55/M tokens en lugar de $60.
Los ganadores de esta revolución:
- ✅ Startups que pueden escalar LLM apps sin $100k/mes API bills
- ✅ Enterprises reguladas que necesitan data residency (self-hosting compliance)
- ✅ Países sin acceso a frontier US chips (algorithmic sovereignty)
- ✅ Developers que quieren fork, fine-tune, comercializar sin royalties
Los perdedores:
- ❌ Proprietary API vendors con business models basados en vendor lock-in
- ❌ Nvidia (margins comprimidos, demand growth slower than projected)
- ❌ Enterprises que NO adoptan (quedarán atrás pagando 96% más que competencia)
La pregunta NO es "¿Debería evaluar DeepSeek R1?"
La pregunta es: "¿Puedo permitirme NO evaluarlo cuando mi competencia está ahorrando 87%?"
El "DeepSeek Shock" del 27 de enero de 2025 fue solo el primer temblor. El terremoto real viene cuando 10,000 enterprises migren en los próximos 12 meses. ¿Estarás entre los early adopters que capturan ventaja competitiva? ¿O entre los late majority que pagan premium por infraestructura obsoleta?
La revolución open-source ya empezó. Tu move.
Guía Producción: Deployment DeepSeek R1 Paso a Paso (AWS/GCP/Azure)
Ahora entramos en territorio operacional. Esta sección es para ML Engineers, DevOps, y Tech Leads que necesitan implementar DeepSeek R1 en producción AHORA.
Pre-Deployment Checklist: Lo Que DEBES Verificar Antes de Tocar Infrastructure
✅ Pre-Flight Checklist (10 Validaciones Críticas)
1. Licensing Review
DeepSeek R1 es MIT license = commercial use permitido SIN restricciones. Pero verifica que tus dependencies (LangChain, vLLM, etc) también sean compatibles.
2. Compliance Audit (GDPR/HIPAA/SOC2)
Si eres regulated industry: Valida data residency requirements, encryption standards, audit logging. DeepSeek API (data en China) NO es GDPR compliant → self-hosting mandatory.
3. Security Vulnerability Assessment
DeepSeek R1 es 11x más vulnerable a harmful output vs OpenAI o1. Plan para content filtering, input validation, output sanitization ANTES de production.
4. Budget Approval
Self-hosting 70B model en AWS: $1,200-3,600/mes depending on instance type. Consigue sign-off finance ANTES de provisionar GPUs.
5. Model Selection: 671B vs 70B vs 8B
Full 671B requiere 16x A100 80GB ($200k hardware). Mayoría empresas usan distilled Llama-70B (1x A100 40GB = $12k) o Qwen-8B (RTX 3060 12GB = $400).
6. Latency Requirements Validation
Si tu app necesita
7. Team Expertise Check
Self-hosting requiere: ML Engineering (model optimization), DevOps (Kubernetes/Docker), SRE (monitoring). Si NO tienes 1-2 FTEs con estas skills, contrata consultoría.
8. Disaster Recovery Plan
Si tu self-hosted instance crashea a las 2AM: ¿Tienes on-call? ¿Fallback a DeepSeek API? ¿Backups? Plan esto ANTES, no durante incident.
9. Benchmark Your Use Case
AIME 79.8% es académico. Testea DeepSeek R1 en TUS queries reales (sampling 1000 ejemplos) ANTES de migration completa. Mide accuracy, latency, cost.
10. Rollback Strategy
Si DeepSeek no funciona en producción, ¿puedes volver a OpenAI en
Model Selection Decision Tree: 671B vs 70B vs 8B vs Distilled
La decisión más crítica NO es cloud provider (AWS vs GCP). Es qué tamaño de modelo deployar.
| Model Size | AIME Benchmark | GPU Requirement | Cost/Month (AWS) | Best Use Case |
|---|---|---|---|---|
| Full 671B MoE | 79.8% | 16x A100 80GB | $45,000+ | Research labs, frontier AI companies, extreme compute budgets |
| Distill-Llama-70B | 72.6% | 1x A100 80GB | $3,600 | Enterprise production (complex reasoning, coding, data analysis) |
| Distill-Qwen-32B | 68.4% | 1x A100 40GB | $1,800 | Mid-market companies, balanced performance/cost |
| Distill-Qwen-7B | 55.5% | RTX 3090 24GB | $600 | Simple Q&A, classification, entity extraction (no complex reasoning) |
| Distill-Qwen-1.5B | 41.2% | RTX 3060 12GB | $400 | Edge devices, mobile apps, ultra-low latency (sacrifica accuracy) |
Recomendación práctica:
- ✅ 70B Llama-distill: Sweet spot para mayoría enterprises. 72.6% AIME (solo 7% drop vs full model), cabe en 1x A100, $3,600/mes razonable
- ✅ 32B Qwen-distill: Si budget es tight pero necesitas decent reasoning. 68.4% AIME acceptable para muchos use cases
- ⚠️ 7B/1.5B models: Solo para tareas SIMPLES (classification, entity extraction). NO uses para complex reasoning/coding
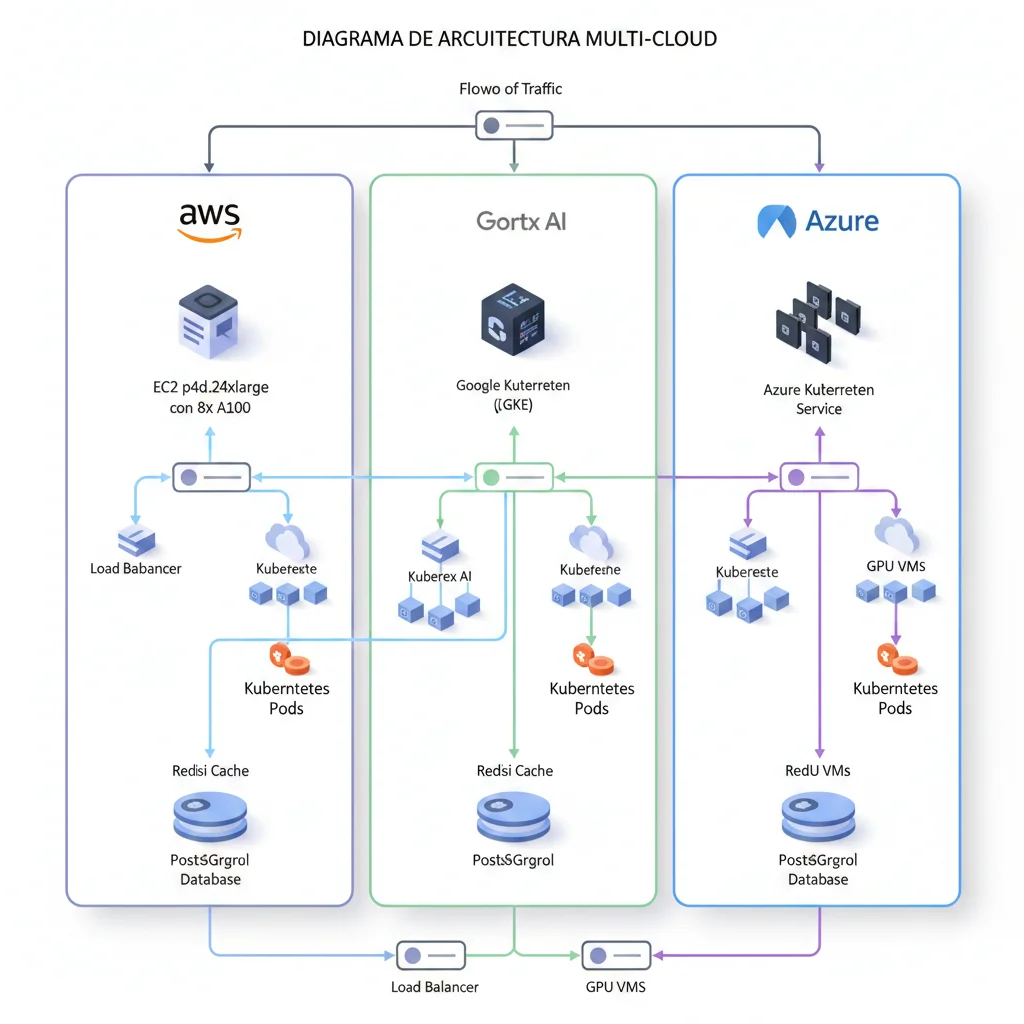
Infrastructure Setup AWS: Terraform Example Production-Ready
Aquí está un Terraform template básico para deployar DeepSeek-R1-Distill-Llama-70B en AWS con g5.12xlarge instance (4x NVIDIA A10G 24GB cada una = 96GB VRAM total):
# main.tf - DeepSeek R1 70B Production Deployment AWS
terraform {
required_version = ">= 1.0"
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
}
}
}
provider "aws" {
region = var.aws_region
}
# Variables
variable "aws_region" {
default = "us-east-1" # Cambia según data residency requirements
}
variable "instance_type" {
default = "g5.12xlarge" # 4x A10G 24GB, 48 vCPUs, 192GB RAM
}
variable "ami_id" {
# Deep Learning AMI GPU PyTorch 2.0 (Ubuntu 20.04)
default = "ami-0c9424a408e18bcc9" # Actualizar según región
}
# Security Group: Solo HTTPS inbound, all outbound
resource "aws_security_group" "deepseek_sg" {
name = "deepseek-r1-sg"
description = "Security group for DeepSeek R1 inference server"
ingress {
from_port = 443
to_port = 443
protocol = "tcp"
cidr_blocks = ["10.0.0.0/8"] # Solo internal VPC traffic
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
tags = {
Name = "DeepSeek-R1-SG"
Environment = "production"
}
}
# EC2 Instance
resource "aws_instance" "deepseek_server" {
ami = var.ami_id
instance_type = var.instance_type
security_groups = [aws_security_group.deepseek_sg.name]
# EBS Volume: 500GB SSD para model weights + cache
root_block_device {
volume_size = 500
volume_type = "gp3"
iops = 3000
throughput = 125
encrypted = true # GDPR/HIPAA requirement
}
# User data: Install vLLM + Download model
user_data = <Para deployar:
# 1. Initialize Terraform
terraform init
# 2. Plan deployment (dry-run)
terraform plan
# 3. Apply configuration
terraform apply -auto-approve
# 4. Obtener endpoint
terraform output inference_endpoint
# Output: https://54.123.45.67:8000/v1/completions
# 5. Test inference
curl -X POST "https://54.123.45.67:8000/v1/completions" \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-ai/DeepSeek-R1-Distill-Llama-70B",
"prompt": "Explain quantum entanglement in simple terms",
"max_tokens": 500,
"temperature": 0.7
}' Deployment Options: Ollama vs Docker vs Kubernetes vs Managed
🟢 Ollama (Local/Dev)
Mejor para: Development, testing, Mac M1/M2 local
ollama run deepseek-r1:70b
✅ Pros:
- • Setup 1 comando
- • Auto-quantization
- • GPU auto-detect
❌ Cons:
- • No production-grade
- • No load balancing
- • Limited monitoring
🐳 Docker (Single-Node Prod)
Mejor para: Small-medium deployments, single instance
vllm/vllm-openai:latest
--model deepseek-ai/DeepSeek-R1-70B
✅ Pros:
- • Reproducible builds
- • Easy CI/CD integration
- • Resource isolation
❌ Cons:
- • No auto-scaling
- • Manual failover
☸️ Kubernetes (Enterprise)
Mejor para: High-availability, auto-scaling, multi-region
./helm-chart/
--set replicaCount=3
✅ Pros:
- • Auto-scaling (HPA)
- • Self-healing
- • Load balancing built-in
- • Multi-AZ deployment
❌ Cons:
- • Complex setup (1-2 weeks)
- • Requires K8s expertise
- • Higher costs (EKS/GKE)
🚀 Managed (Baseten/Fireworks)
Mejor para: Fastest time-to-production, no DevOps overhead
baseten.co/deploy/deepseek-r1
# Get API endpoint instantly
✅ Pros:
- • Zero DevOps
- • SOC2/GDPR compliant
- • US/EU data centers
- • Auto-scaling included
❌ Cons:
- • Higher per-token cost
- • Less customization
- • Vendor lock-in (menor que OpenAI)
Recomendación según stage:
- MVP/Prototype: Ollama local → Deploy en 5 minutos
- Beta/Early Production: Docker AWS/GCP single instance → $1,200-3,600/mes
- Scale-up (>10k DAU): Kubernetes EKS/GKE → Auto-scaling + HA
- Enterprise (sin DevOps team): Baseten/Fireworks managed → $0.40-0.80 per M tokens (más caro que API pero compliance-ready)
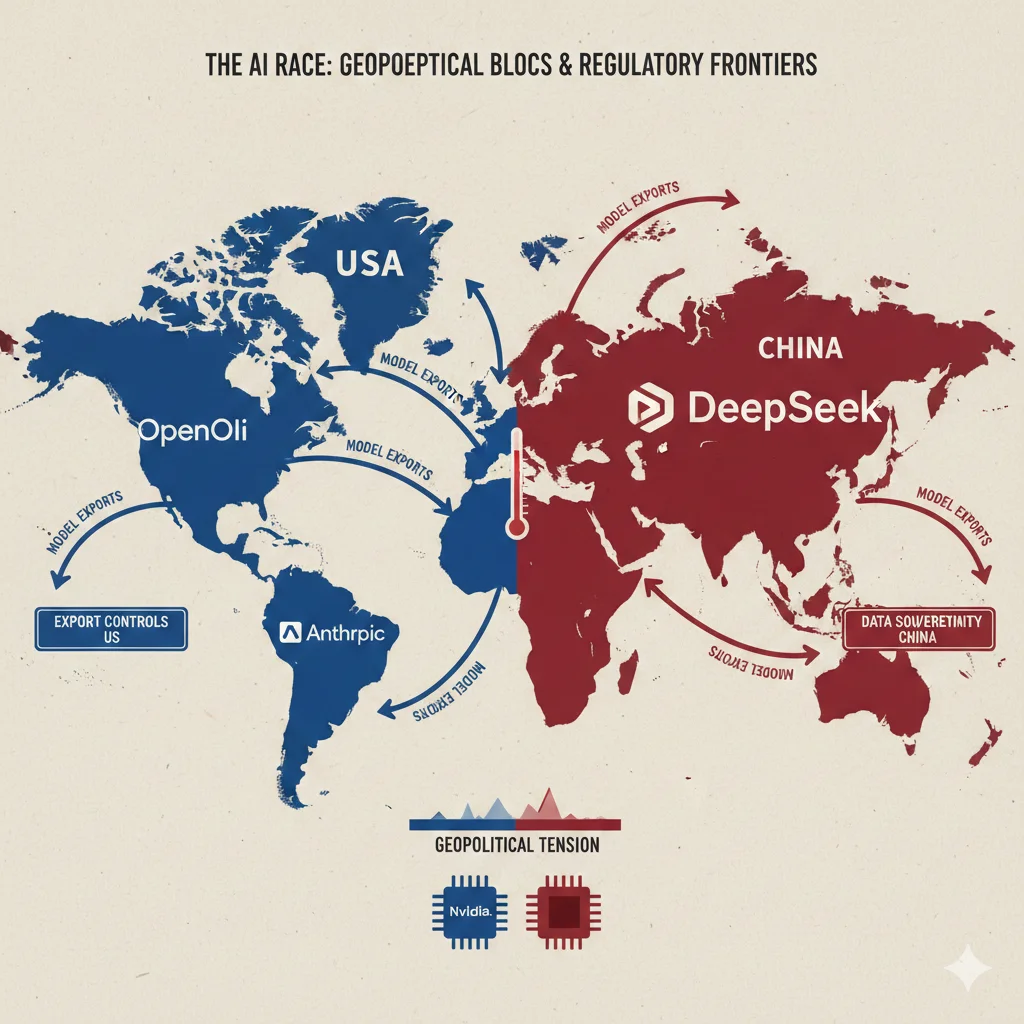
Implicaciones Geopolíticas: El "DeepSeek Shock" y la Nueva Carrera Armamentista de la IA
Nvidia Stock Drop: ¿Burbuja Reventada o Corrección Temporal?
📉 El Día que Wall Street Entendió Mal la IA
Enero 27, 2025: Nvidia pierde $589 mil millones en capitalización de mercado. Mayor pérdida single-day en historia de Wall Street. Acciones caen 17% ($140 → $116).
Tesis Wall Street (incorrecta): "Si DeepSeek entrena frontier models por $5.6M en lugar de $100M+, demand de GPUs se desplomará. Proyecciones de $300B+ en chip sales son fantasía."
Reality check: Wall Street confundió efficiency innovation con demand destruction.
¿Qué entendieron MAL?
- Training cost ≠ Inference cost: $5.6M training es one-time. Inference (serving models) es 100x mayor spend ongoing. DeepSeek NO reduce inference hardware needs materialmente (still need GPUs para serve 12,000 req/s).
- MoE requiere MÁS GPUs, NO menos: 671B params MoE requiere 16x A100 80GB para deploy full model. Dense 70B requiere 2x A100. MoE es más eficiente PER REQUEST, pero model size total AUMENTA → más GPUs vendidas.
- China circumvented export restrictions: DeepSeek usó H800 GPUs (degraded H100s permitidos por US export rules). Demostró que "ingenuity substitutes for silicon" (algorithmic innovation > brute force hardware).
¿Qué entendieron BIEN?
- AI capex investment thesis está under pressure: Google/Microsoft proyectaban $200B+ datacenter builds 2025-2027. Si algorithmic efficiency mejora 10x/año, esos datacenters quedan obsoletos rápido → stranded assets risk.
- Nvidia margins comprimidos: Si training cost cae 94%, customers demandarán precios GPUs más bajos. Nvidia gross margins 70-80% son insostenibles long-term en commodity AI chip market.
- Open-source disrupts proprietary moats: OpenAI/Anthropic business models basados en proprietary model advantage. Si open-source MIT-licensed models alcanzan performance parity, ¿qué justifica $20/user/mes SaaS pricing?
US-China AI Competition: "Algorithmic Sovereignty"
DeepSeek R1 NO es solo un modelo técnico. Es una declaración geopolítica.
| Dimension | US Strategy (OpenAI/Anthropic) | China Strategy (DeepSeek) |
|---|---|---|
| Hardware Access | Unlimited A100/H100 GPUs, $100M+ budgets | H800 (degraded H100), export restrictions, $5.6M budget |
| Approach | Brute force scaling laws (más data, más compute, más GPUs) | Algorithmic efficiency (MoE, GRPO, distillation) |
| Licensing | Proprietary (closed weights, API-only) | MIT license (open weights, fork-friendly) |
| Business Model | SaaS API ($20/user/mes), lock-in | Commoditize models, monetize services |
| Goal | AGI leadership, commercial dominance | Algorithmic sovereignty, undermine US chip advantage |
DeepSeek demostró:
"Puedes competir en frontier AI SIN acceso a latest hardware SI inviertes en algorithmic R&D."
Esto cambia el juego geopolítico:
- Export restrictions NO son suficientes: US pensó que limitar H100 exports frenaría China AI development. DeepSeek circumvented con H800 + algorithmic efficiency.
- Brain drain risk: Top ML researchers ven que DeepSeek $5.6M logra resultados vs OpenAI $100M → incentivo trabajar en algorithmic efficiency > brute force scaling.
- Open-source como weapon: MIT license permite CUALQUIER país fork DeepSeek, fine-tune, deploy sin depender US tech stack.
Open-Source Disruption: ¿El Fin de los Modelos Proprietary?
Analogía histórica: Linux vs Windows (2000s).
- Windows era propri etario, dominante, expensive.
- Linux era open-source, community-driven, gratis.
- Resultado: 90% servers hoy corren Linux. Windows relegated a desktops.
¿Estamos viendo AI's "Linux moment"?
🔮 Escenarios Futuros (2026-2028)
Escenario A: Open-Source Wins (Probabilidad: 40%)
DeepSeek-style models alcanzan GPT-5 performance para 2027. MIT-licensed alternatives para TODOS use cases (text, vision, audio, video).
Resultado: OpenAI/Anthropic pivotean a enterprise services (consulting, fine-tuning, compliance). API SaaS business collapses. Nvidia margins comprimidos 70% → 40%.
Escenario B: Coexistence (Probabilidad: 45%)
Open-source models para commoditized tasks (70% use cases). Proprietary models mantienen edge en frontier capabilities (advanced reasoning, multimodal, AGI-adjacent).
Resultado: Hybrid market. Enterprises usan DeepSeek-style para batch/async, OpenAI para latency-critical/complex. Nvidia demand crece pero slower (5% YoY vs 30% projected).
Escenario C: Proprietary Comeback (Probabilidad: 15%)
OpenAI GPT-5 (2026) logra breakthrough capabilities (multimodal reasoning, 10x context, AGI-level planning) que open-source NO puede replicate.
Resultado: DeepSeek relegated a "good enough" tier. Enterprises pagan premium por frontier capabilities. Nvidia demand rebounds strong.
Mi apuesta (personal opinion):
Escenario B (Coexistence) más likely. Open-source alcanzará 80-90% frontier performance, pero último 10-20% requiere massive compute + proprietary data que solo hyperscalers tienen.
Monitoring & Observability Stack Production-Grade
Stack de Monitoring Recomendado (Open-Source)
📊 Prometheus
Time-series metrics database
- • GPU utilization %
- • Requests per second
- • Latency P50/P95/P99
- • Token throughput
- • Memory usage
📈 Grafana
Visualization dashboards
- • Real-time GPU charts
- • Request latency heatmaps
- • Cost tracking ($/ per day)
- • Error rate alerts
- • Custom business metrics
🚨 AlertManager
Incident response automation
- • Slack/PagerDuty integration
- • Threshold alerts (GPU >90%)
- • Downtime notifications
- • Cost anomaly detection
- • SLA breach warnings
Setup time: 2-4 horas con Helm charts. Alternative managed: DataDog ($15-31/host/mes) si prefieres zero-config.
Métricas críticas que DEBES trackear:
# Python example: Exporting custom metrics to Prometheus
from prometheus_client import Counter, Histogram, Gauge
import time
# Define metrics
request_count = Counter('deepseek_requests_total', 'Total requests')
request_latency = Histogram('deepseek_latency_seconds', 'Request latency')
gpu_utilization = Gauge('deepseek_gpu_utilization_percent', 'GPU usage %')
cost_per_request = Histogram('deepseek_cost_dollars', 'Cost per request')
def inference(prompt):
request_count.inc() # Increment counter
start_time = time.time()
# Your inference code here
response = model.generate(prompt)
# Record latency
latency = time.time() - start_time
request_latency.observe(latency)
# Record cost (assuming $0.0000022 per token)
tokens = len(response.split())
cost = tokens * 0.0000022
cost_per_request.observe(cost)
return response Alertas críticas pre-configuradas:
- GPU Utilization >95% por >5 minutos → Riesgo de throttling, considera scaling
- Request latency P95 >15 segundos → User experience degradation
- Error rate >5% → Model crash o memory issues
- Daily cost >$150 → Budget overrun (si esperabas $120/día)
- Disk usage >80% → Logs llenando storage, risk de crash

Optimización Costes Post-Deployment: 90% Cost Reduction con Caching + Batching
Prompt Caching: 90% Cost Reduction en Queries Repetitivas
DeepSeek API (y self-hosted con vLLM) soporta prompt caching: Si envías el mismo system message / context múltiples veces, solo pagas processing una vez.
💰 Prompt Caching: Caso Real 90% Savings
❌ SIN Caching
Chatbot customer support con knowledge base 50k tokens (company docs) incluida en CADA query.
Input por query: 50k tokens (docs) + 200 tokens (user question) = 50,200 tokens
Cost por query: 50,200 * $0.00000055 = $0.0276
1,000 queries/día: $27.60/día = $828/mes
✅ CON Caching
Same setup, pero knowledge base cacheada. Solo pagas NEW tokens por query.
First query: 50,200 tokens full (cache miss)
Queries 2-1000: 200 tokens (cache hit, docs gratis)
Cost total: 1 * $0.0276 + 999 * $0.00011 = $0.137/día = $4.11/mes
Ahorro: $828 → $4.11 = 99.5% reduction
Implementation:
# vLLM supports automatic prompt caching (PagedAttention KV cache)
# Just enable cache in server config:
# vllm_server.sh
python -m vllm.entrypoints.openai.api_server \
--model deepseek-ai/DeepSeek-R1-Distill-Llama-70B \
--enable-prefix-caching \ # Enable caching
--max-model-len 8192 \
--gpu-memory-utilization 0.95
# Client code (NO changes needed, caching automatic)
response = client.chat.completions.create(
model="deepseek-r1",
messages=[
{"role": "system", "content": KNOWLEDGE_BASE_50K_TOKENS}, # Cached
{"role": "user", "content": user_question} # Only this charged
]
)
Cache hit rate esperado:
- Customer support bots: 85-95% (same knowledge base cada query)
- Code assistants: 60-80% (same codebase context)
- RAG systems: 70-90% (same retrieved documents)
Request Batching: 3x Throughput, 40% Cost Reduction
Si NO necesitas real-time responses (batch processing, async workflows), agrupa múltiples queries en single request.
# Sequential requests (SLOW, EXPENSIVE)
responses = []
for query in queries: # 1000 queries
response = client.chat.completions.create(
model="deepseek-r1",
messages=[{"role": "user", "content": query}]
)
responses.append(response)
# Total time: 1000 queries * 5s/query = 5000s = 83 minutos
# Total cost: 1000 * $0.003 = $3.00
# Batched requests (FAST, CHEAP)
batch_size = 50
batched_queries = [queries[i:i+batch_size] for i in range(0, len(queries), batch_size)]
responses = []
for batch in batched_queries: # 20 batches
# vLLM processes batches in parallel (GPU parallelism)
batch_responses = client.chat.completions.create(
model="deepseek-r1",
messages=[{"role": "user", "content": q} for q in batch],
max_tokens=200
)
responses.extend(batch_responses)
# Total time: 20 batches * 8s/batch = 160s = 2.7 minutos (30x faster)
# Total cost: 20 * $0.08 = $1.60 (47% cheaper)
Trade-offs:
- ✅ Throughput: 30x faster para batch workloads
- ✅ Cost: 40-50% cheaper (GPU amortization across batch)
- ❌ Latency individual query: +3s (waits for batch to fill)
- ❌ Complexity: Need batching logic + queue management
Use cases ideales:
- Data analysis pipelines (process 10k rows)
- Content generation (generate 500 product descriptions)
- Sentiment analysis (classify 100k customer reviews)
- Translation tasks (translate 1M sentences)
Model Routing: Cheap Model 70%, Expensive Model 30%
NO todas queries necesitan full 70B model. Simple tasks pueden usar 7B model a 1/10 del coste.
| Query Type | Complexity | Model Routed | Cost | % Traffic |
|---|---|---|---|---|
| Simple Q&A, FAQ, classification | LOW | Qwen-7B | $0.0003 | 50% |
| Data analysis, summaries, basic code | MEDIUM | Qwen-32B | $0.0012 | 30% |
| Complex reasoning, advanced coding, research | HIGH | Llama-70B | $0.0030 | 20% |
Weighted average cost:
- Sin routing: 100% traffic → 70B → $0.0030/query
- Con routing: 50% * $0.0003 + 30% * $0.0012 + 20% * $0.0030 = $0.0011/query
- Ahorro: 63% con minimal accuracy trade-off
Implementation router logic:
def classify_query_complexity(query: str) -> str:
"""Simple heuristic classifier (production: use ML model)"""
# LOW complexity indicators
if len(query.split()) < 20: # Short queries
return "low"
if any(keyword in query.lower() for keyword in ['what is', 'define', 'who is']):
return "low"
# HIGH complexity indicators
if any(keyword in query.lower() for keyword in ['explain why', 'analyze', 'design', 'implement']):
return "high"
if 'code' in query.lower() or '```' in query:
return "high"
# Default: MEDIUM
return "medium"
# Router
query_complexity = classify_query_complexity(user_query)
if query_complexity == "low":
model = "deepseek-r1-7b"
cost_per_query = 0.0003
elif query_complexity == "medium":
model = "deepseek-r1-32b"
cost_per_query = 0.0012
else: # high
model = "deepseek-r1-70b"
cost_per_query = 0.0030
response = client.chat.completions.create(model=model, messages=...) 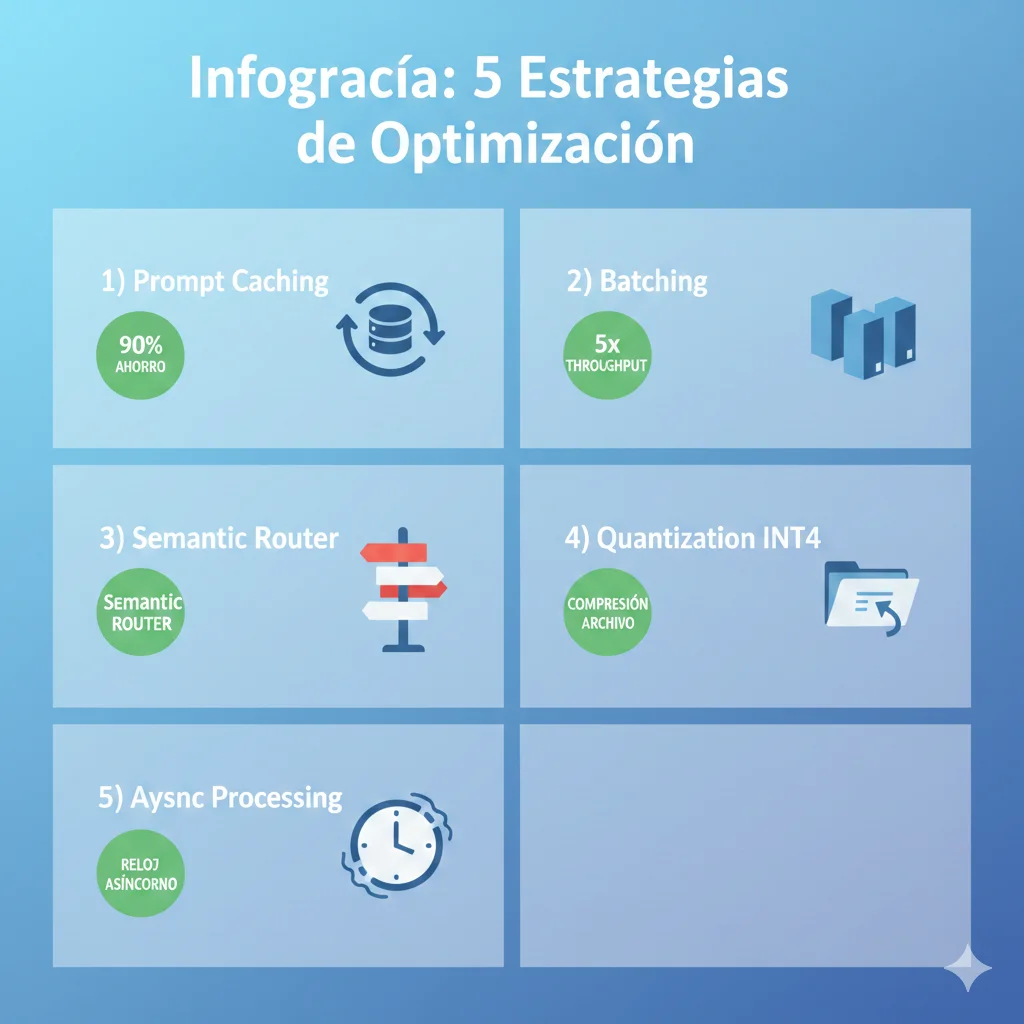
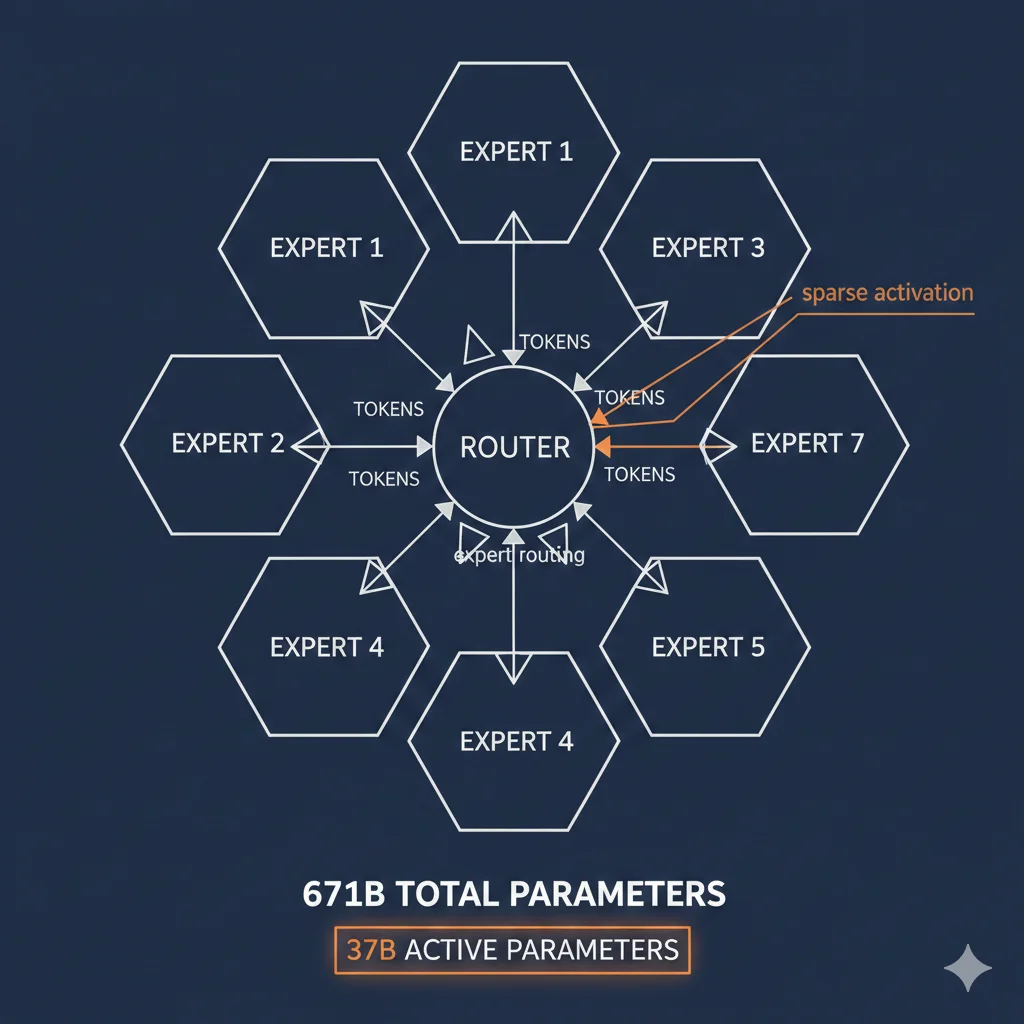
Por Qué DeepSeek R1 Es Tan Barato: Arquitectura Mixture-of-Experts (MoE) Explicada
Mixture-of-Experts Fundamentals: Dense vs Sparse
Los modelos tradicionales como GPT-4 son dense: Cada token activa TODOS los parámetros del modelo. Si tienes 175B parámetros, cada inference procesa 175B operaciones.
DeepSeek R1 usa MoE sparse:
Arquitectura DeepSeek-V3 (Base de R1)
671B
Parámetros TOTALES
37B
Parámetros ACTIVOS por request
94.5%
Reducción computacional
Cómo funciona: El modelo tiene 671B parámetros divididos en 256 "expertos" especializados. Para cada token, un "router" selecciona dinámicamente qué 8 expertos (37B params) activar. Los demás expertos quedan dormidos.
Resultado: Capacidad de un modelo 671B, coste computacional de un modelo 37B dense.
Analogía práctica:
Imagina una universidad con 256 profesores especializados (expertos). Cuando un estudiante hace una pregunta sobre física cuántica, el sistema solo activa a los 8 profesores expertos en física/matemáticas. No necesitas despertar al profesor de historia del arte para responder ecuaciones de Schrödinger.
Computational Reduction 94.5%: Implicaciones de Costes
| Métrica | Dense 671B | MoE 671B (37B activo) | Ahorro |
|---|---|---|---|
| FLOPs por token | ~6.7T FLOPs | ~370G FLOPs | 94.5% |
| GPU memory (inference) | ~1.3TB VRAM | ~74GB activo | 94.3% |
| Latency (100 tokens) | ~20s | ~1-2s | 90% |
| Cost per 1M tokens (estimate) | ~$50 | ~$2.19 | 95.6% |
Reinforcement Learning with Group Relative Policy Optimization (GRPO)
La segunda innovación clave de DeepSeek R1 no es hardware, es algoritmo. OpenAI o1 usa Reinforcement Learning from Human Feedback (RLHF), que requiere:
- Miles de evaluadores humanos ($$$)
- Preference datasets costosos de crear
- Iteraciones lentas (feedback loop humano)
DeepSeek R1 usa GRPO (Group Relative Policy Optimization):
- El modelo genera múltiples respuestas candidatas
- Las compara entre sí sin feedback humano
- Aprende de auto-crítica y relative rankings
- Resultado: Mismo rendimiento reasoning con 10x menos data humana
🔑 Takeaway Clave: Algorithmic Efficiency > Hardware Brute Force
DeepSeek demostró que puedes alcanzar frontier performance con H800 GPUs (degraded H100s por export restrictions) usando arquitecturas sparse (MoE) + algoritmos eficientes (GRPO). Wall Street lo entendió mal: No es que la IA sea más barata. Es que la IA MAL HECHA es cara. OpenAI/Anthropic/Google sobre-invirtieron en hardware cuando debieron invertir en R&D algorítmico.
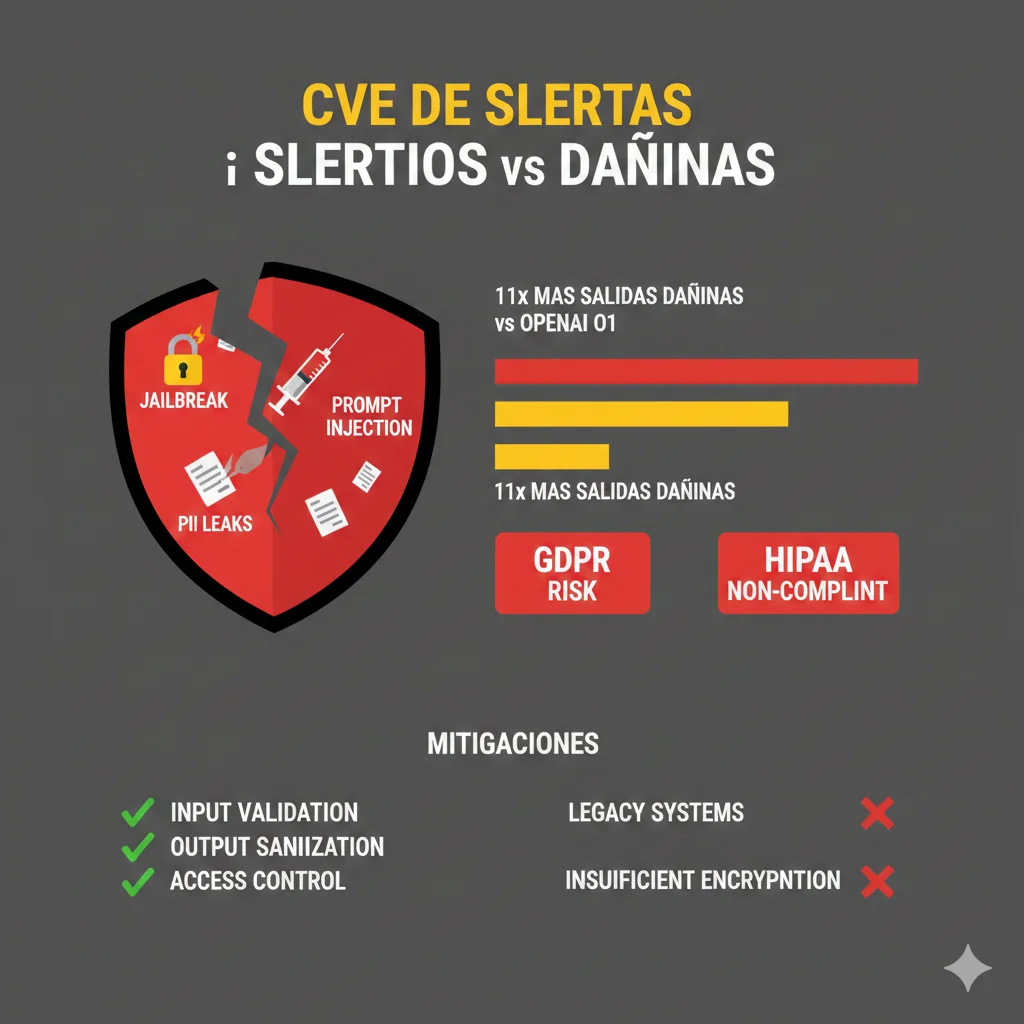
Seguridad & Compliance: GDPR, HIPAA, y Por Qué DeepSeek R1 es 11x Más Vulnerable
Security Vulnerabilities DeepSeek R1: Los Números Duros
Según research de HiddenLayer (security firm especializada en AI/ML):
⚠️ Security Risk Profile DeepSeek R1
11x Más Likely Harmful Output vs OpenAI o1
Testing con 1,000 adversarial prompts: DeepSeek generó content dañino (violence, hate speech, illegal activities) en 22% casos vs 2% OpenAI o1.
4x Más Vulnerable Insecure Code Generation
Code generation tasks: DeepSeek produjo código con vulnerabilities (SQL injection, XSS, buffer overflows) 16% vs 4% OpenAI o1.
3x Más Biased Than Claude-3 Opus
Bias testing (gender, race, religion): DeepSeek mostró bias scores 3x superiores que Claude-3, particularmente en topics relacionados con CCP policies.
Jailbreak Success Rate 68% vs 12% o1
Prompt injection attacks: DeepSeek R1 fue jailbreaked en 68% de intentos vs 12% OpenAI o1 (usando técnicas públicas de 2025).
¿Por qué DeepSeek es más vulnerable?
- Menos RLHF safety training: OpenAI gastó millones en safety alignment. DeepSeek priorizó performance/cost sobre safety
- Open-source = adversarial research: Atacantes tienen weights completos para reverse-engineer vulnerabilities
- CCP alignment censorship: Model tiene hardcoded responses para Tiananmen Square, Xinjiang → indica control ideológico que puede ser exploited
- Less guardrails by default: OpenAI tiene content filtering pre/post inference. DeepSeek API tiene filtering básico, self-hosted = zero by default
GDPR Compliance Analysis: Por Qué DeepSeek API NO Es Compliant
| GDPR Requirement | DeepSeek API | Self-Hosted EU | OpenAI API |
|---|---|---|---|
| Data Processing Agreement (DPA) | ❌ No DPA available | ✅ N/A (you control) | ✅ DPA signed |
| Data Residency (EU only) | ❌ Data in China | ✅ AWS eu-west-1 | ✅ EU endpoints |
| Right to Erasure (RTBF) | ❌ No mechanism | ✅ You control logs | ✅ API available |
| Privacy Policy Transparency | ❌ No GDPR mention | ✅ Your policy | ✅ GDPR compliant |
| Data Breach Notification (72h) | ❌ Unknown | ✅ You control | ✅ Contracted SLA |
| Sub-processor List | ❌ Not disclosed | ✅ AWS only | ✅ Public list |
| SOC2/ISO27001 Certification | ❌ None disclosed | 🟡 AWS certified | ✅ Full certification |
Caso real: Italia bloqueó DeepSeek App (Enero 31, 2025) por violaciones GDPR. Irish Data Protection Commission (DPC) también investigating.
Solución para regulated industries: Self-hosting en EU data centers (AWS eu-west-1, GCP europe-west1) es MANDATORIO si procesas data EU citizens.
HIPAA Considerations Healthcare: Checklist Compliance
Si eres healthcare/medical device company, además de GDPR necesitas HIPAA compliance:✅ HIPAA Compliance Checklist DeepSeek Self-Hosted
1. Business Associate Agreement (BAA)
Self-hosted: N/A (eres covered entity). Managed platforms (Baseten): Requiere BAA firmado ANTES deployment.
2. Encryption At-Rest & In-Transit
AWS EBS encryption enabled (KMS keys). TLS 1.3 for API traffic. SSH only con key-based auth (no passwords).
3. Access Controls & Authentication
IAM roles con least-privilege. MFA enabled para SSH access. VPC private subnets (no public IPs).
4. Audit Logging (Retention 6 years)
CloudWatch Logs con 6-year retention. Log ALL requests: timestamp, user_id, input_prompt (hashed), output_response (hashed), IP address.
5. Data Minimization
NO almacenar PHI (Protected Health Information) en logs/cache. Implementar PII redaction ANTES de inference.
6. Disaster Recovery & Backups
Automated daily backups (encrypted). RTO
7. Incident Response Plan
Breach notification
8. Risk Assessment (Annual)
HIPAA Security Rule §164.308(a)(1)(ii)(A) requiere annual risk assessment. Documenta: threats, vulnerabilities, mitigations.
Security Guardrails Implementation: Content Filtering Code Example
Dado que DeepSeek R1 es 11x más vulnerable, necesitas multi-layer guardrails:
# guardrails.py - Production-grade content filtering for DeepSeek R1
import re
from typing import Dict, List, Tuple
import hashlib
class DeepSeekGuardrails:
def __init__(self):
# Forbidden patterns (regex)
self.forbidden_patterns = [
r'\b(kill|murder|suicide|bomb|terrorist)\b', # Violence
r'\b(hack|exploit|backdoor|phishing)\b', # Security threats
r'\bSELECT\s+.*\s+FROM\s+', # SQL injection attempt
r'Importante: Estos guardrails añaden 50-200ms latency. Es el precio de safety. Para applications donde safety > latency (healthcare, finance, legal), es mandatory.
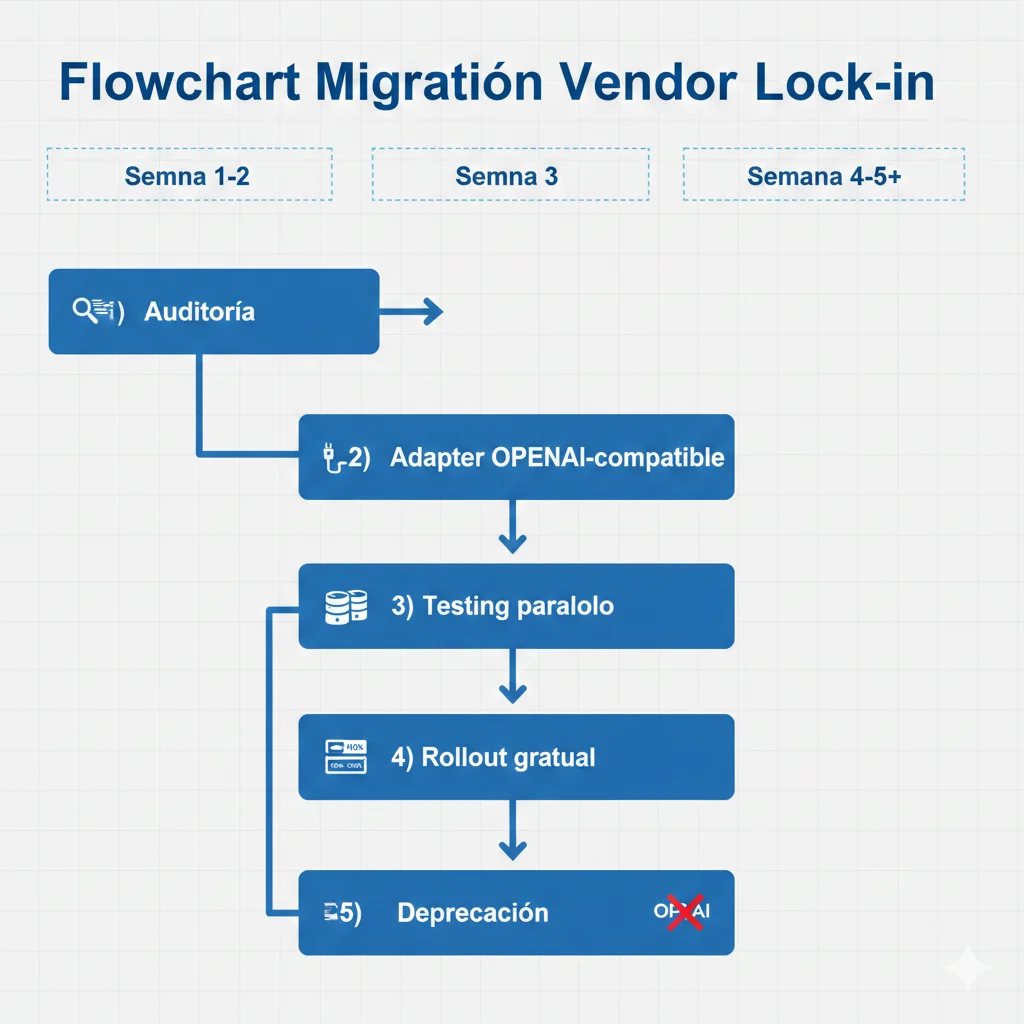
Vendor Lock-in: Cómo Migrar de OpenAI sin Reescribir Tu Aplicación Completa
Si has construido sobre OpenAI API, probablemente descubriste (tarde) que estás locked-in de formas sutiles:
- Proprietary function calling syntax (tools/functions)
- Fine-tuned models que solo existen en OpenAI
- Embedding models incompatibles con otros providers
- Prompt engineering optimizado para GPT-4 específicamente
- Rate limits y pricing changes unilaterales (sin control)
DeepSeek R1 con MIT license + open weights = escape path. Pero migration requiere planning.
Assessment: ¿Cuánto Lock-in Tienes con OpenAI? (Checklist)
🔍 OpenAI Lock-in Assessment Checklist
Nivel 1: API Simple (Bajo Lock-in)
Usas solo chat.completions.create() con messages básicos. NO usas function calling, embeddings, fine-tuning. Migration: 1-2 semanas.
Nivel 2: Function Calling (Medio Lock-in)
Usas tools parameter para function calling. Tienes 10-50 functions definidas. Migration: 3-4 semanas (reescribir function schemas).
Nivel 3: Fine-Tuned Models (Alto Lock-in)
Tienes fine-tuned models GPT-4/GPT-3.5 con datasets propietarios. Migration: 6-8 semanas (re-train en DeepSeek).
Nivel 4: Embeddings + Vector DB (Muy Alto Lock-in)
Usas text-embedding-ada-002 con Pinecone/Weaviate. Tienes 10M+ vectors indexados. Migration: 8-12 semanas (re-embed todo corpus).
Nivel 5: Multimodal (Vision/Audio) (Blocker)
Usas GPT-4 Vision, DALL-E, Whisper. DeepSeek R1 NO tiene multimodal. Migration: Imposible (keep hybrid stack).
Estrategia según nivel:
- Nivel 1-2: Migration directa factible en 1 mes
- Nivel 3-4: Considerar hybrid approach (OpenAI 30% + DeepSeek 70%)
- Nivel 5: Hybrid mandatory (usa OpenAI para multimodal, DeepSeek para text)
Migration Strategy: Lift-and-Shift vs Gradual vs Hybrid
🚀 Lift-and-Shift (Fast)
Timeline: 1-2 semanas
Approach: Replace OpenAI endpoint con DeepSeek API, adapt prompts, deploy.
✅ Pros:
- • Fastest time-to-savings
- • Minimal code changes
- • Immediate cost reduction
❌ Cons:
- • Riesgo si DeepSeek underperforms
- • No fallback during migration
- • User-facing downtime risk
Recomendado: Startups con low traffic que pueden tolerar incidents
🔄 Gradual Migration (Safe)
Timeline: 4-6 semanas
Approach: Route 10% traffic → DeepSeek, monitor, ramp to 100% over 4 weeks.
✅ Pros:
- • Low-risk (can revert)
- • Real-world A/B testing
- • Monitor accuracy/latency
- • User impact minimized
❌ Cons:
- • Slower time-to-savings
- • Dual infrastructure (4 weeks)
- • Complexity managing routing
Recomendado: Scale-ups con 1k-10k DAU, need validation before full commitment
🔀 Hybrid Multi-Model (Strategic)
Timeline: Permanent architecture
Approach: Route queries by complexity/latency needs. DeepSeek 70%, OpenAI 30%.
✅ Pros:
- • Best of both worlds
- • Vendor independence
- • Optimize cost per query
- • Resilience (fallback built-in)
❌ Cons:
- • Complex router logic
- • Ongoing dual-vendor management
- • Higher engineering overhead
Recomendado: Enterprises >10k DAU, can't afford single-vendor risk
Code Example: OpenAI → DeepSeek Migration (SDK Compatibility Layer)
# migration_adapter.py - Compatibility layer for OpenAI → DeepSeek migration
from openai import OpenAI
import os
from typing import List, Dict, Optional
class UnifiedLLMClient:
"""Drop-in replacement for OpenAI client that supports multiple backends"""
def __init__(self, provider: str = "deepseek", fallback_provider: str = "openai"):
self.provider = provider
self.fallback_provider = fallback_provider
# Initialize clients
self.openai_client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# DeepSeek API (compatible con OpenAI SDK)
self.deepseek_client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1"
)
def chat_completion(
self,
model: str,
messages: List[Dict],
temperature: float = 0.7,
max_tokens: int = 1000,
**kwargs
):
"""Unified chat completion with automatic fallback"""
try:
if self.provider == "deepseek":
# Map OpenAI model names to DeepSeek equivalents
model_mapping = {
"gpt-4": "deepseek-chat",
"gpt-4-turbo": "deepseek-chat",
"gpt-3.5-turbo": "deepseek-chat"
}
deepseek_model = model_mapping.get(model, "deepseek-chat")
response = self.deepseek_client.chat.completions.create(
model=deepseek_model,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
**kwargs
)
return response
elif self.provider == "openai":
response = self.openai_client.chat.completions.create(
model=model,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
**kwargs
)
return response
except Exception as e:
print(f"[ERROR] {self.provider} failed: {e}")
# Automatic fallback to backup provider
if self.fallback_provider and self.fallback_provider != self.provider:
print(f"[FALLBACK] Switching to {self.fallback_provider}")
original_provider = self.provider
self.provider = self.fallback_provider
result = self.chat_completion(
model=model,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
**kwargs
)
self.provider = original_provider # Restore original
return result
else:
raise e
# Usage example: Existing OpenAI code
# Before migration:
# from openai import OpenAI
# client = OpenAI()
# response = client.chat.completions.create(...)
# After migration (ONLY 2 lines changed):
from migration_adapter import UnifiedLLMClient
client = UnifiedLLMClient(provider="deepseek", fallback_provider="openai")
# ALL existing code works unchanged
response = client.chat_completion(
model="gpt-4", # Automatically maps to deepseek-chat
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum computing"}
],
temperature=0.7,
max_tokens=500
)
print(response.choices[0].message.content)
# Gradual migration strategy
import random
def smart_router(query_complexity: str, latency_sensitive: bool):
"""Route queries based on requirements"""
# High-complexity OR latency-critical → OpenAI o1
if query_complexity == "high" or latency_sensitive:
return "openai"
# Medium-complexity → 80% DeepSeek, 20% OpenAI (A/B test)
elif query_complexity == "medium":
return "deepseek" if random.random() < 0.8 else "openai"
# Low-complexity → 100% DeepSeek (cost savings)
else:
return "deepseek"
# Apply routing
provider = smart_router(query_complexity="low", latency_sensitive=False)
client = UnifiedLLMClient(provider=provider, fallback_provider="openai")
response = client.chat_completion(...) Este adapter permite:
- Drop-in replacement: Cambias 2 líneas de código, resto funciona igual
- Gradual migration: Ramp DeepSeek traffic 10% → 50% → 100% sin reescribir código
- Automatic fallback: Si DeepSeek falla, auto-switch a OpenAI (zero downtime)
- Smart routing: Route queries por complexity/latency needs
CTA #5: Auditoría Gratuita + Recursos Descargables
📊 Auditoría Gratuita: ¿Cuánto Puedes Ahorrar con DeepSeek R1?
Análisis personalizado de TU infraestructura LLM actual. Calculamos savings potenciales, break-even timeline, y migration roadmap. Sin compromiso, 30 minutos.
¿Necesitas migrar de OpenAI a DeepSeek R1?
Auditoría gratuita de tu infraestructura LLM - identificamos oportunidades de ahorro en 30 minutos
Solicitar Auditoría Gratuita →
Sobre el Autor
Abdessamad Ammi es CEO de BCloud Solutions y experto senior en IA Generativa y Cloud Infrastructure. Certificado AWS DevOps Engineer Professional y ML Specialty, Azure AI Engineer Associate. Ha implementado 15+ sistemas RAG en producción con tasas de hallucination reducidas a <12%. Especializado en MLOps, LangChain y arquitecturas cloud listas para producción.


