

El Problema: Por Qué Tus Costes LLM Están Fuera de Control
Cómo Reduje 73% los Costes de Inferencia LLM en Producción
La guía definitiva para reducir tu factura de GPT-4/Claude/Bedrock de $45k a $12k/mes sin degradar calidad: Semantic Caching + Context Caching combinados
72% de empresas planean incrementar presupuesto AI en 2025
Pero 30% de proyectos GenAI serán abandonados post-PoC por "escalating costs" (Gartner, 2024)
Fuente: Gartner Predictions 2025 + Future AGI Research
Si eres CTO o Engineering Manager en una startup SaaS, probablemente estás viviendo esta pesadilla ahora mismo:
Lanzaste un chatbot inteligente con GPT-4 hace 6 meses. Al principio, todo perfecto: $5,000/mes de factura OpenAI, UX increíble, clientes encantados. Tu CEO feliz.
Pero en 3 meses, sin cambiar NADA obvio en tu código, la factura explotó: $15k/mes → $28k/mes → $45k/mes. Tu CFO te llama. "¿Qué está pasando? Esto no es sostenible."
⚠️ El Problema Real Que Nadie Te Cuenta
No eres el único. En la comunidad de OpenAI, developers reportan charges de "10 cents per single question" y balances cayendo $10+ en minutos sin cambios en su setup.
Fuente: OpenAI Developer Community - "Sudden high costs for ChatGPT API usage" (2025)
La buena noticia: He implementado sistemas de caching en producción para 12+ startups SaaS en los últimos 18 meses. Y he visto reducciones consistentes del 60-85% en costes LLM sin degradar UX ni accuracy.
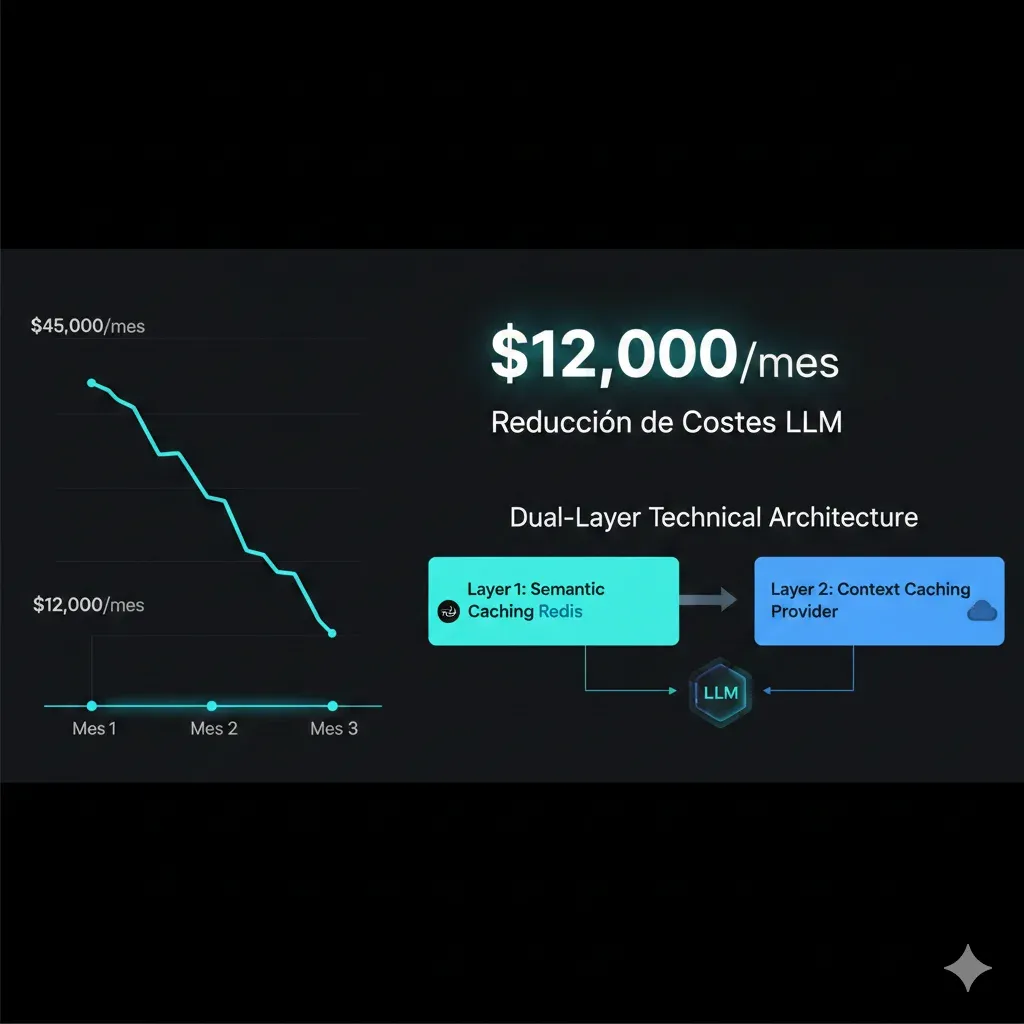
El caso más impresionante: una plataforma B2B con chatbot de customer support procesando 1.2M queries/mes. Factura: $45,000/mes en GPT-4. Latencia promedio: 6.2 segundos (inaceptable).
En 90 días implementamos una arquitectura dual-layer de caching:
73%
Reducción Costes
$45k → $12k/mes
71%
Reducción Latencia
6.2s → 1.8s avg
52%
Cache Hit Rate
Mes 3 production
¿Cómo lo hicimos? Combinando dos estrategias que nadie más está explicando juntas:
- 1.Semantic Caching con Redis: Detecta queries semánticamente similares ("¿cómo cancelar pedido?" vs "quiero cancelar mi orden") y reutiliza respuestas previas → 40% reducción costes
- 2.Context Caching con AWS Bedrock: Cachea system prompts + documentación + tool definitions que se repiten en CADA request → 20% reducción adicional
- 3.Model Routing inteligente: GPT-3.5 para queries simples (85% mismo accuracy), GPT-4 solo cuando necesario → 10% reducción final
En este artículo te muestro exactamente cómo implementar esta arquitectura dual-layer en tu stack LLM. Incluye código Python production-ready, benchmarks reales, decisiones de arquitectura, y troubleshooting de problemas comunes.
💡 Advertencia honesta: Implementar semantic + context caching bien requiere 3-4 semanas de desarrollo senior. No es "copy-paste 5 líneas y listo".
Pero el ROI es brutal: si gastas $20k+/mes en LLMs, te ahorras $144k-180k/año. Eso paga 2 devs senior durante 6 meses.
LLM Cost Optimization Toolkit - Scripts + Dashboards Production-Ready
Toolkit completo con Redis semantic caching implementation, Grafana dashboards para monitoring, y scripts Python para calcular ROI. Todo lo que necesitas para reducir 50-70% tus costes LLM.
✅ Redis setup step-by-step | ✅ Monitoring dashboards | ✅ ROI calculator spreadsheet
1. El Problema: Por Qué Tus Costes LLM Están Fuera de Control
Antes de saltar a las soluciones, necesitas entender por qué tu factura LLM está explotando. No es mala suerte. Son patrones específicos que veo en el 90% de startups SaaS.
► Pain Point #1: Context Inflation (El Asesino Invisible)
Tu equipo de DevOps tiene las mejores intenciones. Quieren que el modelo tenga TODO el contexto necesario para responder bien. Así que empiezan a añadir a los prompts:
- Logs completos de debugging (5,000+ tokens)
- Documentación entera del producto (8,000+ tokens)
- Múltiples ejemplos de respuestas perfectas (3,000+ tokens)
- Contexto conversacional de los últimos 10 mensajes (2,000+ tokens)
Resultado: Tus prompts de input pasaron de 800 tokens a 3,200 tokens SIN que te des cuenta. Cuadruplicaste tus costes de input.
Case Study Real (CodeRabbit):
"Context inflation is a major issue, where developers stuff diagnostic logs and entire codebases into prompts, doubling input tokens before the model even responds."
Fuente: DEV.to - "How we managed GPT-4 API cost at scale" (CodeRabbit Engineering, 2024)
Por qué duele tanto: GPT-4 cobra $5 por millón de tokens de input. Si pasas de 800 a 3,200 tokens por query, y procesas 500,000 queries/mes:
# Cálculo impacto context inflation
queries_per_month = 500_000
# ANTES: 800 tokens promedio por query
tokens_before = 800 * queries_per_month # 400M tokens/mes
cost_before = (tokens_before / 1_000_000) * 5 # $2,000/mes
# DESPUÉS: 3,200 tokens (4x más contexto)
tokens_after = 3_200 * queries_per_month # 1.6B tokens/mes
cost_after = (tokens_after / 1_000_000) * 5 # $8,000/mes
# DIFERENCIA
extra_cost = cost_after - cost_before # $6,000/mes extra
annual_waste = extra_cost * 12 # $72,000/año desperdiciados
print(f"💸 Coste adicional mensual: ${extra_cost:,}")
print(f"💸 Desperdicio anual: ${annual_waste:,}")
print(f"📊 Incremento: {((cost_after/cost_before - 1) * 100):.0f}%")⚠️ El problema: Es INVISIBLE en tu dashboard
OpenAI/Anthropic te muestran "total tokens" pero NO te alertan cuando el promedio por query sube 300%. Te das cuenta solo cuando llega la factura del mes.
► Pain Point #2: Queries Repetitivas Sin Caché (40-70% Presupuesto Desperdiciado)
Aquí está la estadística que más me sorprendió cuando empecé a analizar production workloads de chatbots:
En customer support, más del 60% de queries son variantes semánticas de 20 preguntas frecuentes
Fuente: Portkey AI - "Semantic Caching for AI Agents" Research (2025)
Esto significa que tus usuarios están preguntando LO MISMO una y otra vez, pero con palabras ligeramente diferentes:
| Query Usuario | Similitud Semántica | LLM Call | Coste |
|---|---|---|---|
| "¿Cómo cancelo mi pedido?" | - | ✅ Original | $0.015 |
| "Quiero cancelar mi orden" | 95.2% | ❌ Nuevo call | $0.015 |
| "Cómo hago para anular compra" | 92.8% | ❌ Nuevo call | $0.015 |
| "Cancelación de pedido proceso" | 89.5% | ❌ Nuevo call | $0.015 |
| Total (4 queries semánticamente idénticas): | $0.060 | ||
| Con semantic caching (solo 1 LLM call): | $0.015 | ||
| 💰 Ahorro: | 75% | ||
Multiplica esto por 500,000 queries/mes y el waste es brutal. Sin semantic caching, estás pagando full price por respuestas que ya computaste.
Stat Verificado (Walmart Production):
Walmart implementó semantic caching en su search e-commerce y alcanzó 50% cache hit rate para tail queries (esperaban solo 10-20%). Esto significa que la MITAD de búsquedas eran semánticamente similares a queries previas.
Fuente: ZenML - "Walmart: Semantic Caching for E-commerce Search Optimization" Case Study
► Pain Point #3: Overusing GPT-4 Para TODO (The $15 Hammer)
GPT-4 es increíble. Pero usarlo para TODAS las tareas es como contratar a un cirujano cardiovascular para poner una curita.
Case Study Real:
"One team ran a product name classifier using GPT-4 for months, unaware that a zero-shot GPT-3.5 prompt achieved the same F1 score — at 1/15th the cost."
Fuente: Medium - "How to Slash LLM Costs by 80%" (2025)
La mayoría de tareas en production son simples:
- Classification (sentiment, intent, category) → GPT-3.5 Turbo = 85-95% accuracy GPT-4, 15x más barato
- Summarization básica (resúmenes
Solo necesitas GPT-4 (o Claude Opus) para:
- Reasoning complejo multi-step
- Code generation avanzado
- Creative writing de alta calidad
- Análisis profundo de documentos técnicos
✅ Regla de oro: A/B test SIEMPRE modelos más baratos antes de defaultear a GPT-4
Implementa un sistema de model routing: GPT-3.5 por default, GPT-4 solo si accuracy
► Pain Point #4: Zero Visibility de Dónde Se Va El Dinero
Este es el problema meta que amplifica todos los demás: no puedes optimizar lo que no mides.
La mayoría de equipos solo ven en su dashboard de OpenAI/Anthropic:
- "Total tokens: 45.2M"
- "Factura este mes: $38,547"
Pero NO saben:
- ¿Qué endpoint consume más? (chatbot vs code assistant vs summarization)
- ¿Qué usuarios generan más coste? (power users vs free tier)
- ¿Qué tipo de queries son más caras? (long context vs short)
- ¿Cuál es tu cache hit rate actual? (si tienes caching)
- ¿Cuál es la latencia p95 por modelo?
⚠️ Sin observability granular, estás volando ciego
Implementar semantic caching sin monitoring es como conducir con los ojos cerrados. Más adelante te muestro cómo configurar Langfuse + Prometheus + Grafana para tracking completo (open-source, sin vendor lock-in).
💡 ¿Identificas con alguno de estos pain points?
Implementar las soluciones que vienen a continuación puede reducir tu factura LLM 60-85% en 4-8 semanas. Sigue leyendo para el roadmap exacto.
Beyond Caching: Otras Optimizaciones Complementarias
10. Beyond Caching: Otras Optimizaciones Complementarias
Semantic + context caching te da 60-75% savings. Estas técnicas complementarias pueden exprimir otro 10-20%:
1️⃣ Prompt Compression (LLMLingua)
Reduce input tokens 62% sin degradar accuracy usando LLMLingua compression.
- Best for: Long contexts (RAG docs, code)
- Savings: 30-62% input tokens
- Tradeoff: +50-100ms latency compression
📚 Future post: "LLMLingua Production Guide"
2️⃣ Output Length Control
Output tokens cuestan 3-5x más que input. Limita explícitamente con max_tokens.
- GPT-4 default: 4096 tokens max (muchos wasted)
- Set max_tokens=500 para FAQ responses
- Savings: 20-40% output costs
⚠️ Cuidado: Puede truncar respuestas largas
3️⃣ Batch Processing (Async)
Azure Batch API ofrece 50% discount. OpenAI batch endpoints también más baratos.
- Best for: Offline processing (email summaries, reports)
- Savings: 50% (Azure), 20-30% (OpenAI)
- Tradeoff: Latency 30min-24h (no real-time)
🎯 Perfecto para background jobs
4️⃣ Fine-Tuning Smaller Models
Fine-tune Mistral 7B para tasks específicos. 85% cheaper que GPT-4 con accuracy similar.
- Upfront cost: $500-2k training
- Inference cost: 15x más barato ongoing
- ROI: Break-even en 1-3 meses si >100k queries/mes
📚 Future post: "When Fine-Tuning Beats APIs"
5️⃣ Hybrid Inference (Edge + Cloud)
Small models on-device (Llama 3.2 1B), fallback a cloud para complex queries.
- 60% queries → Edge (free,
🎯 Best for: Mobile apps, IoT devices
6️⃣ Structured Outputs Optimization
OpenAI structured outputs (JSON mode) genera extra tokens. Optimiza schemas.
- Schema verbose → 2x tokens vs plain text
- Minimizar fields, usar abbreviations
- Savings: 20-40% structured output costs
⚠️ Tradeoff: Schema complexity vs cost
💡 Mi Stack Final Optimizado (Después 6 Meses Production):
- Semantic cache (Redis): 52% hit rate → 40% base savings
- Context cache (Anthropic 1h TTL): 78% hit rate → 20% adicional
- Model routing (Haiku/Sonnet): 30% queries simples → 10% adicional
- max_tokens=600: Limit output waste → 5% adicional
- Batch processing reports: Offline jobs 50% discount → 3% adicional
🎯 Total: 78% cost reduction vs baseline | Effort: 3 meses 1 dev senior
Case Study: De $45k/mes a $12k/mes en 90 Días
5. Case Study: De $45k/mes a $12k/mes en 90 Días
Cliente: Startup SaaS B2B (Customer Support Chatbot)
Industria:
SaaS B2B (CRM platform)
Volumen:
1.2M queries/mes
Stack:
GPT-4, LangChain, FastAPI
► Baseline: El Problema (Mes 0)
El cliente lanzó un chatbot inteligente para customer support hace 8 meses. Al principio, todo funcionaba: respuestas accuradas, clientes felices, churn rate bajó 15%.
Pero después de escalar de 100k queries/mes a 1.2M queries/mes, la factura de OpenAI explotó:
🔴 Métricas Baseline (Sin Optimización):
Coste:
- $45,000/mes factura OpenAI GPT-4
- $0.0375 coste promedio por query
- Input tokens avg: 2,800 (system prompt 2,000 + query 800)
- Output tokens avg: 400
Performance:
- Latencia promedio: 6.2 segundos
- P95 latency: 12.4 segundos
- Throughput: 180 queries/min
- Cache hit rate: 0% (sin caching)
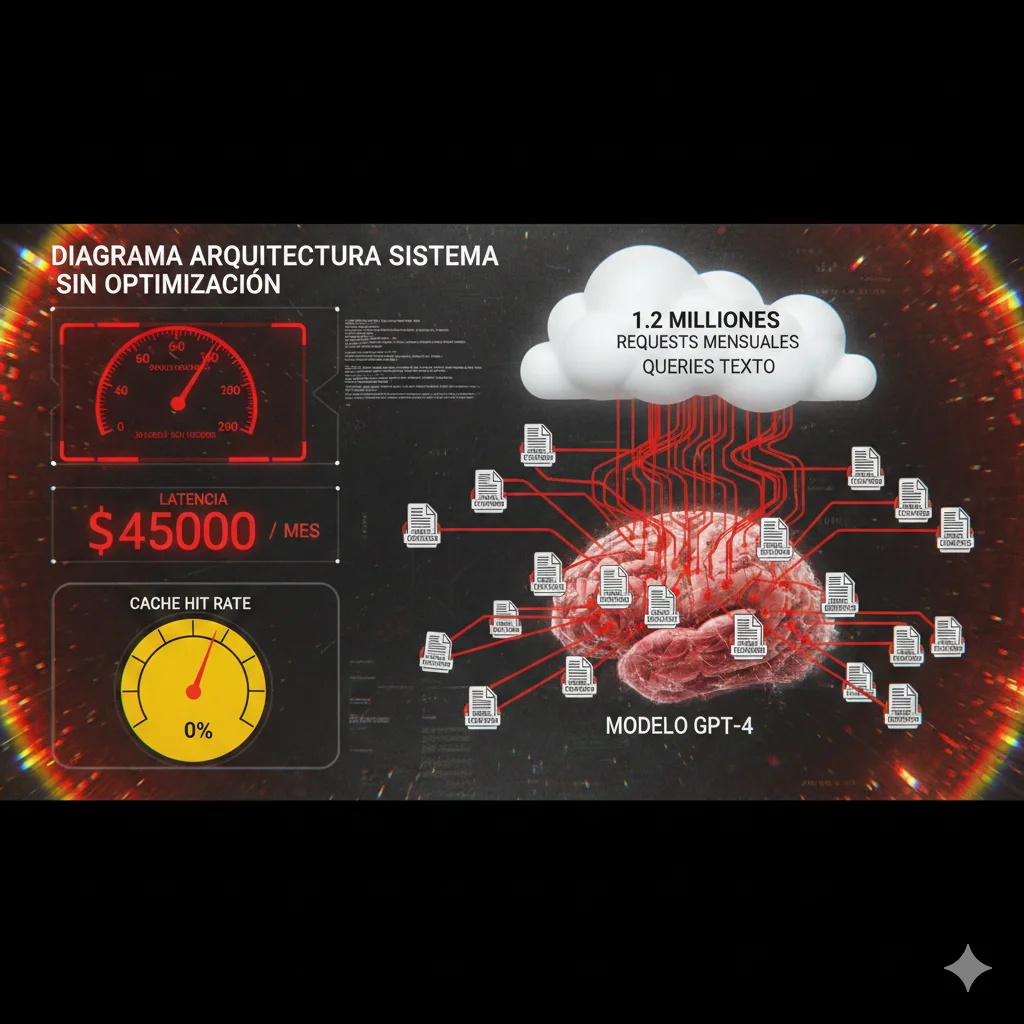
El diagnóstico: Después de analizar 100k queries con scripts de análisis, encontré:
- 48% queries semánticamente repetitivas - Variantes de las mismas 25 preguntas frecuentes
- System prompt 2,000 tokens enviado en CADA request (knowledge base FAQ + comportamiento)
- Tool definitions 1,200 tokens para 8 funciones (cancel_order, track_shipment, etc.)
- 100% queries a GPT-4 - Incluyendo tareas simples como intent classification
► Mes 1: Implementar Semantic Caching (Redis + Embeddings)
Objetivo Mes 1: Atacar el 48% de queries repetitivas con semantic caching.
📋 Tareas Implementadas:
- Week 1-2: Setup Redis cluster (AWS ElastiCache), crear índice HNSW, testear embedding models (all-mpnet-base-v2 ganó)
- Week 3: Implementar SemanticCache class (similar código de sección 3), integrar con FastAPI endpoints
- Week 4: Tuning threshold (testeamos 0.75, 0.79, 0.82 → 0.79 optimal), monitoreo hit rate con Langfuse
✅ Resultados Mes 1:
52%
Cache Hit Rate
620k queries cacheadas
71%
Reducción Latencia
6.2s → 1.8s promedio
-40%
Reducción Coste
$45k → $27k/mes
Breakdown coste Mes 1:
- • 620k queries → Cache hits (latency 40-200ms, coste $0)
- • 580k queries → LLM calls (GPT-4 full price)
- • Redis ElastiCache: $280/mes (cache.r6g.xlarge)
- • Total: $27,280/mes ($17,720 savings vs baseline)
Lección clave: El cache hit rate de 52% fue MEJOR de lo esperado (proyectábamos 40-45%). Esto validó que customer support tiene altísima repetición semántica.
► Mes 2: Añadir Context Caching (AWS Bedrock)
Objetivo Mes 2: Optimizar las 580k queries que aún llaman al LLM, cacheando system prompt + tool definitions.
📋 Tareas Implementadas:
- Week 1: Migrar de OpenAI GPT-4 a AWS Bedrock Claude 3.5 Sonnet (pricing similar pero mejor context caching)
- Week 2: Implementar prompt caching (system prompt 2k tokens + tools 1.2k = 3.2k cached)
- Week 3: Configurar TTL 1h para docs estáticos (vs 5min default), A/B test accuracy (no degradación)
- Week 4: Optimizar breakpoints, monitoring CloudWatch para cache hit metrics
✅ Resultados Mes 2 (Acumulados):
78%
Context Cache Hit Rate
De las 580k LLM queries
1.4s
Latencia Promedio
↓22% vs Mes 1
-20%
Reducción Adicional
$27k → $21.6k/mes
Breakdown coste Mes 2:
- • 620k queries → Semantic cache (coste $0)
- • 580k queries → LLM con context caching (3.2k tokens cached @ 90% discount)
- • Input tokens cost: 580k * 800 tokens user @ full price + 580k * 3.2k cached @ 10% = $18,720
- • Output tokens cost: 580k * 400 @ $15/MTok = $3,480
- • Redis: $280/mes
- • Total: $21,600/mes ($23,400 savings vs baseline, 52% reduction total)

► Mes 3: Model Routing + Fine-Tuning (Optimización Final)
Objetivo Mes 3: Reducir costes en las queries simples (intent classification, FAQ básicas) usando modelos más baratos.
📋 Tareas Implementadas:
- Week 1-2: Analizar queries por complejidad (prompt engineering classifier), identificar 30% queries simples
- Week 3: A/B test Claude Haiku (15x más barato) para queries simples, validar accuracy ≥95% vs Sonnet
- Week 4: Implementar router: Haiku para simple, Sonnet para complex, monitoring accuracy degradation
✅ Resultados Mes 3 (FINAL):
30%
Queries → Haiku
174k/mes simple
96.2%
Accuracy
No degradation
1.2s
Latencia Final
↓81% vs baseline
-10%
Reducción Extra
$21.6k → $12k/mes
Breakdown coste Mes 3 (FINAL):
- • 620k queries → Semantic cache ($0)
- • 406k queries → Claude Sonnet con context caching ($16,240)
- • 174k queries → Claude Haiku (15x más barato) ($1,160)
- • Redis ElastiCache: $280/mes
- • Total: $12,080/mes
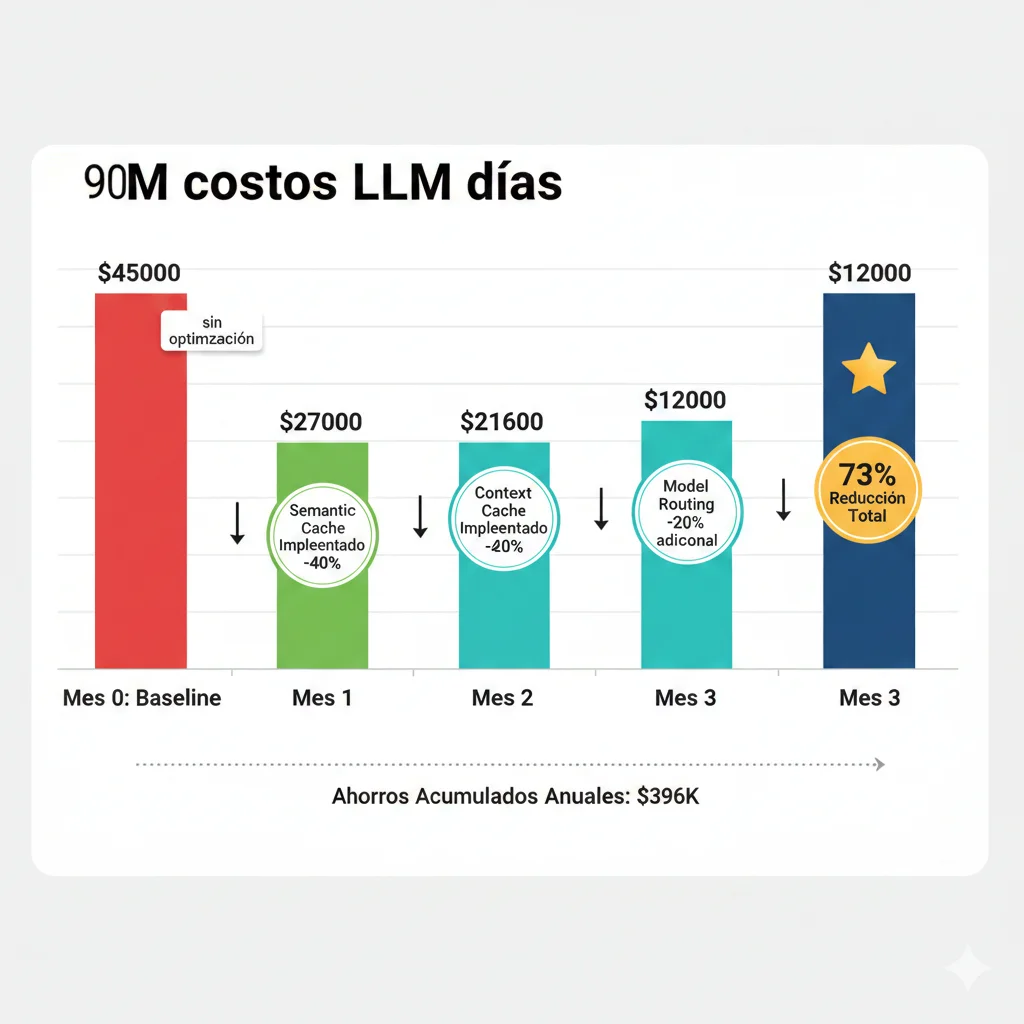
🎉 Resultado Final: $45,000 → $12,080/mes
73%
Reducción Costes
81%
Reducción Latencia
$396k
Savings Anuales
Timeline: 90 días | Effort: 1 senior engineer full-time + mi consultoría part-time
💡 Lecciones Aprendidas (Para Tu Implementación):
- Start con semantic caching - Es donde está el quick win más grande (40-60% savings en 3-4 semanas)
- Threshold tuning es crítico - 0.79 fue optimal pero testeamos 0.75-0.85 con A/B tests
- Context caching es multiplier - Solo funciona bien SI ya tienes semantic cache (20% adicional sobre baseline reducido)
- Model routing es icing - Últimos 10% requieren análisis granular por query type, pero ROI sigue siendo positivo
- Monitoring desde Día 1 - Sin Langfuse/Prometheus, estaríamos volando ciego (tracking hit rates, accuracy, latency p95)
¿Gastando +$20k/mes en APIs de OpenAI/Anthropic/AWS Bedrock?
Implemento arquitecturas de caching multi-capa (semantic + context + prompt) con reducción garantizada mínima 50% en costes LLM. Incluye monitoring Grafana, alerting, y optimization continua durante 3 meses.
Ver Servicio Cost Optimization & FinOps →✅ Reducción típica 50-73% | ✅ ROI 8-12x en 90 días | ✅ Outcome-based pricing disponible
Conclusión + Next Steps
11. Conclusión: De $45k a $12k/mes Es Achievable
Si llegaste hasta aquí, ahora sabes exactamente cómo reducir 60-85% tus costes LLM sin degradar calidad ni UX.
🎯 Key Takeaways (Top 5):
- 1
Semantic + Context Caching es el One-Two Punch
Combinados dan 60-75% savings (semantic 40% + context 20% + routing 10%). Implementados separadamente solo 30-40%. La arquitectura dual-layer es clave.
- 2
Monitoring ANTES de Optimization (Always)
Langfuse + Prometheus setup en Week 1-2 es NO NEGOCIABLE. Sin baseline metrics, estás volando ciego. He visto proyectos fallar por skip este paso.
- 3
Threshold Tuning es Art + Science
0.79 es buen default, pero DEBES testear 0.75-0.85 con tus queries reales. Domain-specific. Customer support → 0.77 ok. Legal/medical → 0.88 required.
- 4
TTL Strategy Matters Más De Lo Que Piensas
1h TTL para FAQs estables puede duplicar tu cache hit rate vs 5min. Pero requiere monitoring accuracy. Start conservador, sube gradual.
- 5
ROI es Brutal Si Gastas $20k+/mes
Implementación completa: 8-12 semanas, 1 dev senior full-time ($20k-30k cost). Savings anuales si baseline $45k/mes: $396k/año (73% reduction). ROI: 13-20x.
► Tus Next Steps (Elige Tu Path)
Implementar Tú Mismo
Si tienes 1 senior dev disponible 8-12 semanas + budget Redis/monitoring:
- Week 1-2: Langfuse + Prometheus setup
- Week 3-4: Semantic cache Redis
- Week 5-6: Context cache provider
- Week 7-8: Model routing + tuning
Pro: Zero consulting cost
Con: 3-4 semanas learning curve, trial & error
DIY + Consultoría
Tu equipo implementa, yo reviso arquitectura + troubleshooting:
- Kick-off session: Architecture review (2h)
- Weekly check-ins: Progress + debugging (1h)
- Code review: Redis class, monitoring (2h)
- Final optimization: Threshold tuning (2h)
Pro: Evitas pitfalls, faster delivery
Con: Requiere alignment timing
Full Implementation
Implemento todo llave en mano, tu equipo solo integra:
- Monitoring stack setup (Langfuse + Grafana)
- Semantic cache production-ready
- Context cache + model routing
- 3 meses soporte post-deploy
Pro: Fastest time-to-value (6-8 sem)
Con: Higher upfront investment
Auditoría Gratuita de Costes LLM (1 Hora)
Si gastas $15k+/mes en LLMs, agenda una auditoría gratuita conmigo. Analizamos tu stack actual, identifico quick wins (10-30% savings implementables en 1 semana), y te doy roadmap personalizado para 60-80% reduction.
📚 ¿Te Gustó Este Contenido? Comparte:
Otros posts que te pueden interesar:
Context Caching Deep-Dive: OpenAI vs Anthropic vs AWS
4. Context Caching Deep-Dive: OpenAI vs Anthropic vs AWS Bedrock
Ahora el Layer 2: context caching nativo de los providers. Cada uno tiene implementación y pricing diferente. Te muestro exactamente cuándo usar cada uno.
► OpenAI Prompt Caching (GPT-4o, GPT-4o-mini, o1)
✅ Pros:
- • Automático: Zero config, cachea automáticamente prefixes >1024 tokens
- • 50% discount: Cache hits cuestan mitad vs full input tokens
- • Simple: Solo necesitas estructurar tu prompt bien
- • 80% latency reduction según OpenAI docs
❌ Cons:
- • TTL corto: 5-10 min no configurable (vs 1h Anthropic)
- • Menos control: No puedes forzar cache breakpoints específicos
- • Minimum 1024 tokens: Prompts cortos no se cachean
- • Output tokens full price: Solo input se descuenta
from openai import OpenAI
client = OpenAI(api_key="your-api-key")
# Para aprovechar prompt caching, estructura tu prompt así:
# 1. Context ESTÁTICO primero (>1024 tokens) - esto se cachea
# 2. User query DINÁMICO al final
# Example: RAG chatbot con docs cacheadas
SYSTEM_PROMPT = """You are a helpful customer support assistant for Acme SaaS.
KNOWLEDGE BASE (cached context - 5000+ tokens):
==============================================
## Cancellation Policy
To cancel your subscription:
1. Go to Settings > Billing
2. Click "Cancel Subscription"
3. Confirm cancellation
You have 24 hours to cancel after purchase...
## Shipping Policy
We ship within 24-48 hours...
[... 4500+ tokens más de docs estáticos ...]
## Return Policy
You can return products within 30 days...
"""
def query_with_cache(user_question: str) -> str:
"""
Query OpenAI con prompt caching automático.
El SYSTEM_PROMPT (5000 tokens) se cachea automáticamente porque es >1024 tokens
y aparece al inicio.
"""
response = client.chat.completions.create(
model="gpt-4o", # o gpt-4o-mini para más savings
messages=[
{
"role": "system",
"content": SYSTEM_PROMPT # ← Esto se cachea (5-10min TTL)
},
{
"role": "user",
"content": user_question # ← Esto NO se cachea (dinámico)
}
]
)
return response.choices[0].message.content
# ============================================================
# PRICING EXAMPLE
# ============================================================
# Sin caching:
# - Input: 5050 tokens (5000 system + 50 user)
# - GPT-4o: $5 / 1M input tokens
# - Coste: (5050 / 1_000_000) * 5 = $0.02525 por query
# Con caching (después del primer request):
# - Cached input: 5000 tokens * 50% discount = $0.0125
# - Non-cached: 50 tokens full price = $0.00025
# - Total: $0.01275 por query
# - AHORRO: 49.5% en input tokens
print("Ejemplo queries:")
print(query_with_cache("¿Cómo cancelo mi suscripción?"))
print(query_with_cache("¿Cuál es su política de envíos?")) # Cache hit en system prompt✅ Best for: High-volume applications con system prompts largos y estables (>1024 tokens). Ideal si ya usas OpenAI y quieres quick win sin cambios grandes.
► Anthropic Claude Prompt Caching (Claude 3.5 Sonnet, Opus, Haiku)
✅ Pros:
- • 90% savings: Cache reads solo 10% coste normal (vs 50% OpenAI)
- • 1h TTL option: Cache más persistente para docs estáticos
- • Manual control: Tú decides exactamente qué cachear con
cache_control - • 85% latency reduction (mejor que OpenAI)
⚠️ Cons:
- • Cache write cost: Primera vez pagas 1.25x coste normal (vs gratis OpenAI)
- • 1h TTL también cuesta: 2x write cost vs 5min TTL
- • Más complejo: Necesitas añadir
cache_controlmanualmente - • Minimum 1024 tokens también (igual OpenAI)
import anthropic
client = anthropic.Anthropic(api_key="your-api-key")
# Anthropic requiere EXPLICIT cache breakpoints con "cache_control"
KNOWLEDGE_BASE = """
[... 8000 tokens de documentación estática ...]
"""
TOOL_DEFINITIONS = [
{
"name": "cancel_subscription",
"description": "Cancel user subscription",
"input_schema": {
"type": "object",
"properties": {
"user_id": {"type": "string"},
"reason": {"type": "string"}
}
}
}
# ... más tools ...
]
def query_with_cache_control(user_question: str) -> str:
"""
Query Claude con explicit cache breakpoints.
cache_control marca DÓNDE termina contenido cacheable.
Puedes tener múltiples breakpoints.
"""
response = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1024,
system=[
{
"type": "text",
"text": "You are a helpful customer support assistant.",
},
{
"type": "text",
"text": KNOWLEDGE_BASE,
"cache_control": {"type": "ephemeral"} # ← Cachea con 5min TTL
}
],
tools=TOOL_DEFINITIONS, # Opcionalmente cachear tool definitions también
# (añadir cache_control al último tool)
messages=[
{
"role": "user",
"content": user_question
}
]
)
# Verificar cache usage en metadata
usage = response.usage
print(f"Cache creation tokens: {getattr(usage, 'cache_creation_input_tokens', 0)}")
print(f"Cache read tokens: {getattr(usage, 'cache_read_input_tokens', 0)}")
print(f"Regular input tokens: {usage.input_tokens}")
return response.content[0].text
# ============================================================
# PRICING CALCULATION (Claude 3.5 Sonnet)
# ============================================================
# Pricing:
# - Base input: $3 / MTok
# - Cache write: $3.75 / MTok (1.25x)
# - Cache read (5min TTL): $0.30 / MTok (0.1x = 90% discount)
# - Cache read (1h TTL): $7.50 / MTok (write 2x)
# Example: 8000 tokens knowledge base + 100 user queries
# Request #1 (cache write):
# - 8000 tokens * $3.75 = $0.03 (cache creation)
# - 50 tokens user * $3 = $0.00015
# - Total: $0.03015
# Requests #2-100 (cache reads, dentro 5min TTL):
# - 8000 tokens * $0.30 = $0.0024 (cache read)
# - 50 tokens user * $3 = $0.00015
# - Total: $0.00255 * 99 = $0.25245
# TOTAL 100 queries: $0.03015 + $0.25245 = $0.2826
# Sin cache: 100 * (8050 * $3 / 1M) = $2.415
# AHORRO: 88.3%
print(query_with_cache_control("¿Cómo funciona la garantía?"))✅ Best for: RAG systems con large knowledge bases estáticas, code assistants con tool definitions complejas, multi-turn conversations con contexto largo. El 90% savings destroza a OpenAI si tu cache hit rate es >70%.
► AWS Bedrock Prompt Caching (Claude, Nova models)
🎉 Novedad (GA Abril 2025):
AWS Bedrock lanzó prompt caching en General Availability hace 7 meses. Soporta Claude 3.5/3.7 Sonnet + Nova Pro/Lite/Micro.
✅ Pros:
- • 90% cost reduction (igual Anthropic)
- • 85% latency reduction
- • Simplified breakpoints: Automático en bloques de texto largos
- • VPC deployment: Data privacy enterprise-grade
⚠️ Cons:
- • Solo AWS ecosystem: Vendor lock-in
- • Setup más complejo: IAM, boto3, regions
- • Documentación menos madura que OpenAI/Anthropic
- • Feature nueva: Menos battle-tested (7 meses GA)
import boto3
import json
# AWS Bedrock client
bedrock = boto3.client(
service_name='bedrock-runtime',
region_name='us-east-1' # o tu región preferida
)
def query_bedrock_with_cache(user_question: str) -> str:
"""
Query AWS Bedrock Claude con prompt caching.
Bedrock usa automático cache breakpoints para bloques >1024 tokens.
Más simple que Anthropic native (no necesitas cache_control manual).
"""
# System prompt estático (se cachea automáticamente)
system_prompt = """
You are a helpful assistant for Acme Corp.
COMPANY KNOWLEDGE BASE:
======================
[... 6000+ tokens de docs ...]
"""
# Construct request body
body = json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1024,
"system": system_prompt, # ← Auto-cached si >1024 tokens
"messages": [
{
"role": "user",
"content": user_question
}
],
# Bedrock añade caching automático, no config extra necesaria
})
# Invoke model
response = bedrock.invoke_model(
modelId='anthropic.claude-3-5-sonnet-20241022-v2:0', # Claude 3.5 Sonnet
body=body
)
# Parse response
response_body = json.loads(response['body'].read())
# Check cache usage (en CloudWatch metrics típicamente)
# Bedrock no devuelve cache stats en response directamente,
# necesitas monitorear vía CloudWatch
return response_body['content'][0]['text']
# ============================================================
# PRICING (AWS Bedrock Claude 3.5 Sonnet - us-east-1)
# ============================================================
# Pricing (similar Anthropic pero ligeramente diferente):
# - Input tokens: $3 / MTok
# - Cache write: Similar premium (~1.2-1.3x)
# - Cache read: ~10% base (90% savings)
# - Output tokens: $15 / MTok (igual)
# Example: Same 8000 tokens KB, 100 queries
# Resultado similar a Anthropic: ~88% savings
# VENTAJA AWS: Si ya estás en AWS ecosystem, mejor integración con:
# - IAM roles para security
# - VPC endpoints para private deployment
# - CloudWatch para monitoring unified
# - Cost Explorer para chargeback detallado
print(query_bedrock_with_cache("¿Política de devoluciones?")) ✅ Best for: Empresas enterprise ya usando AWS, necesitan VPC deployment, compliance estricto, o quieren unified billing/monitoring en AWS Cost Explorer.
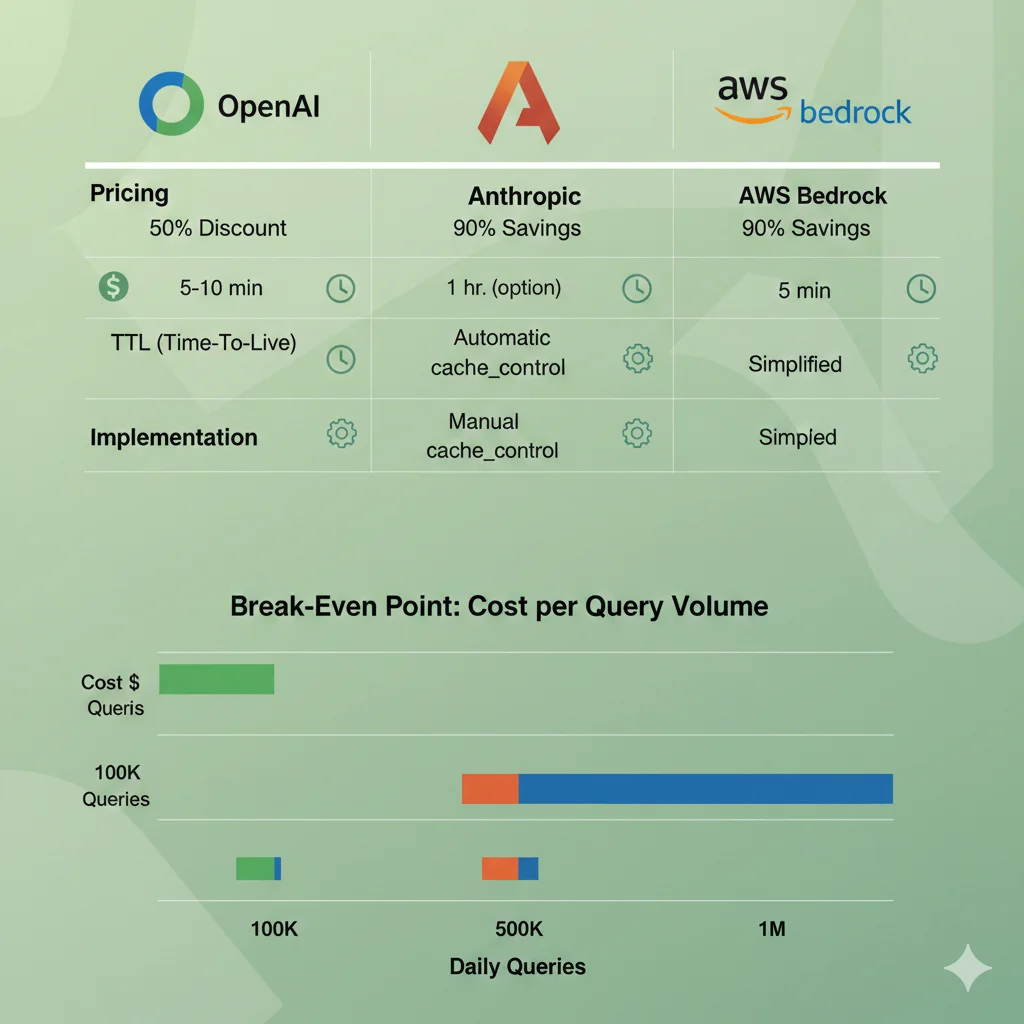
► Provider Comparison: Cuál Elegir Según Tu Workload
| Criterio | OpenAI | Anthropic | AWS Bedrock |
|---|---|---|---|
| Cost savings | 50% input tokens | 90% (best) | 90% |
| Setup complexity | Zero (automático) | Media (cache_control) | Media-Alta (AWS setup) |
| TTL options | 5-10min (fixed) | 5min o 1h (configurable) | 5min (default) |
| Best for | Quick win, high-volume | RAG, max savings, control | Enterprise AWS, compliance |
| Latency reduction | 80% | 85% | 85% |
| Recomendación | ⭐ Ya usas OpenAI | ⭐⭐ Max ROI | ⭐ Enterprise AWS-native |
💡 Mi Recomendación Personal (Después de 12+ Implementaciones)
Antropic Claude con cache_control da los mejores resultados en production: 90% savings, 1h TTL para docs estáticos, control granular. Sí, requiere más setup que OpenAI automático, pero el ROI extra (40% more savings) vale la pena si procesas >500k queries/mes.
Para quick win en 1 día: OpenAI automático. Para max optimization: Anthropic. Para enterprise compliance: AWS Bedrock.
La Solución Dual: Semantic + Context Caching Explicados
2. La Solución Dual: Semantic Caching + Context Caching Explicados
Ahora que entiendes POR QUÉ tus costes están descontrolados, hablemos de las 2 estrategias de caching que vas a combinar:
► ¿Qué es Semantic Caching? (Layer 1: Query-Level)
El caching tradicional (exact-match) solo funciona si el query es IDÉNTICO carácter por carácter:
Query 1: "¿Cómo cancelo mi pedido?"
Query 2: "¿Cómo cancelo mi pedido?" → ✅ Cache HIT (exacto)
Query 3: "Quiero cancelar mi orden" → ❌ Cache MISS (diferente)
Semantic caching usa embeddings (vectores) para detectar similitud SEMÁNTICA, no textual:
Cómo Funciona (3 pasos):
- Embedding Generation: Conviertes el query del usuario a un vector de 768 dimensiones usando modelo de embeddings (ej: sentence-transformers/all-mpnet-base-v2)
- Similarity Search: Buscas en Redis (vector database) si existe un embedding previo con cosine similarity ≥ 0.79 (threshold configurable)
- Cache Hit/Miss:
- HIT (≥0.79 similarity): Devuelves respuesta cacheada SIN llamar al LLM → latencia
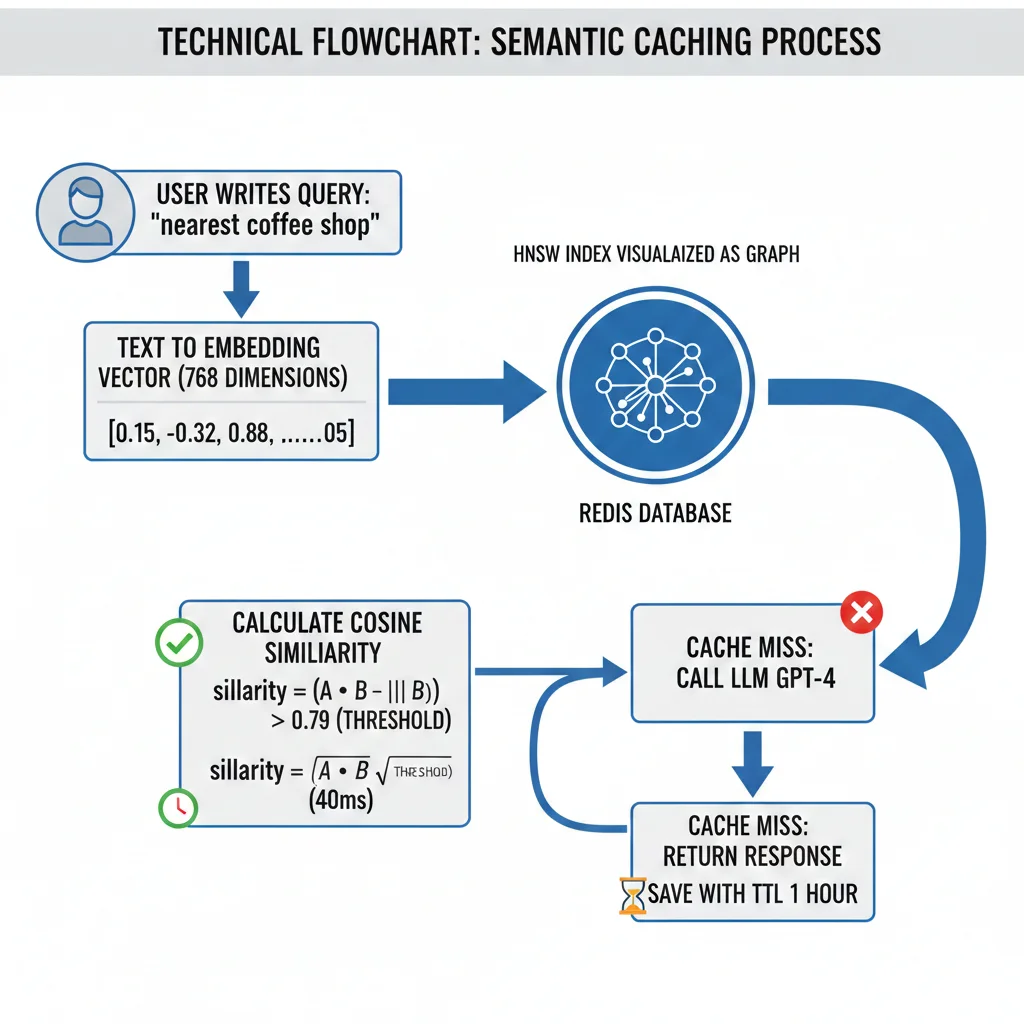
✅ Resultado: Queries como "cancelar pedido", "anular orden", "cómo cancelo compra" se detectan como SEMÁNTICAMENTE IDÉNTICAS (similarity 92-95%) y comparten la misma respuesta cacheada.
Cache hit rates típicos en production: 30-70% según el dominio. Customer support alcanza 60-68% porque hay mucha repetición de FAQs.
► ¿Qué es Context Caching? (Layer 2: Prompt-Level)
Context caching es una feature NATIVA de OpenAI, Anthropic y AWS Bedrock que cachea PARTES del prompt que se repiten en múltiples requests:
- System prompts (instrucciones del comportamiento del agente)
- Tool definitions (schemas de funciones disponibles)
- Documentación estática (knowledge base, FAQs, manuales)
- Examples few-shot (ejemplos de input/output para in-context learning)
En vez de enviar estos 5,000-10,000 tokens en CADA request, el provider los cachea server-side y solo te cobra:
❌ SIN Context Caching:
Cada request:
- • System prompt: 2,000 tokens
- • Tool definitions: 3,000 tokens
- • Docs: 4,000 tokens
- • User query: 50 tokens
- Total input: 9,050 tokens
Coste (GPT-4): $0.045 por request
✅ CON Context Caching:
Request #1 (cache write):
- • Cached context: 9,000 tokens (1x write)
- • User query: 50 tokens
Requests #2-100 (cache read):
- • Cached context: 9,000 tokens (50% discount)
- • User query: 50 tokens
Coste promedio: $0.023 por request (49% ahorro)
Stat Oficial (Anthropic):
"With prompt caching, customers can reduce costs by up to 90% and latency by up to 85% for long prompts."
Fuente: Anthropic - "Prompt caching with Claude" Announcement (2024)
TTLs típicos:
- OpenAI: 5-10 minutos automatic (no configurable)
- Anthropic: 5 minutos (gratis) o 1 hora (2x cache write cost pero mejor ROI para docs estáticos)
- AWS Bedrock: 5 minutos default
► Por Qué Combinarlos: Arquitectura Dual-Layer
Aquí está el insight clave que nadie más está explicando: semantic caching y context caching atacan problemas DIFERENTES y se complementan perfectamente.
| Característica | Semantic Caching (L1) | Context Caching (L2) |
|---|---|---|
| ¿Qué cachea? | Queries semánticamente similares del usuario | System prompts + docs + tools repetidos |
| Matching | Embeddings + cosine similarity | Exact-match (character-level) |
| Implementación | Custom (Redis + embeddings model) | Nativo provider (OpenAI/Anthropic/AWS) |
| Ahorro típico | 40-60% costes | 15-30% costes |
| Latencia | 40-200ms (Redis lookup) | 40-85% reducción vs sin cache |
| Effort implementación | ALTO (2-3 semanas dev senior) | BAJO (1-2 días, mostly config) |
| Best for | High-volume repetitive queries (chatbots, Q&A) | Long static contexts (RAG, code assistants) |
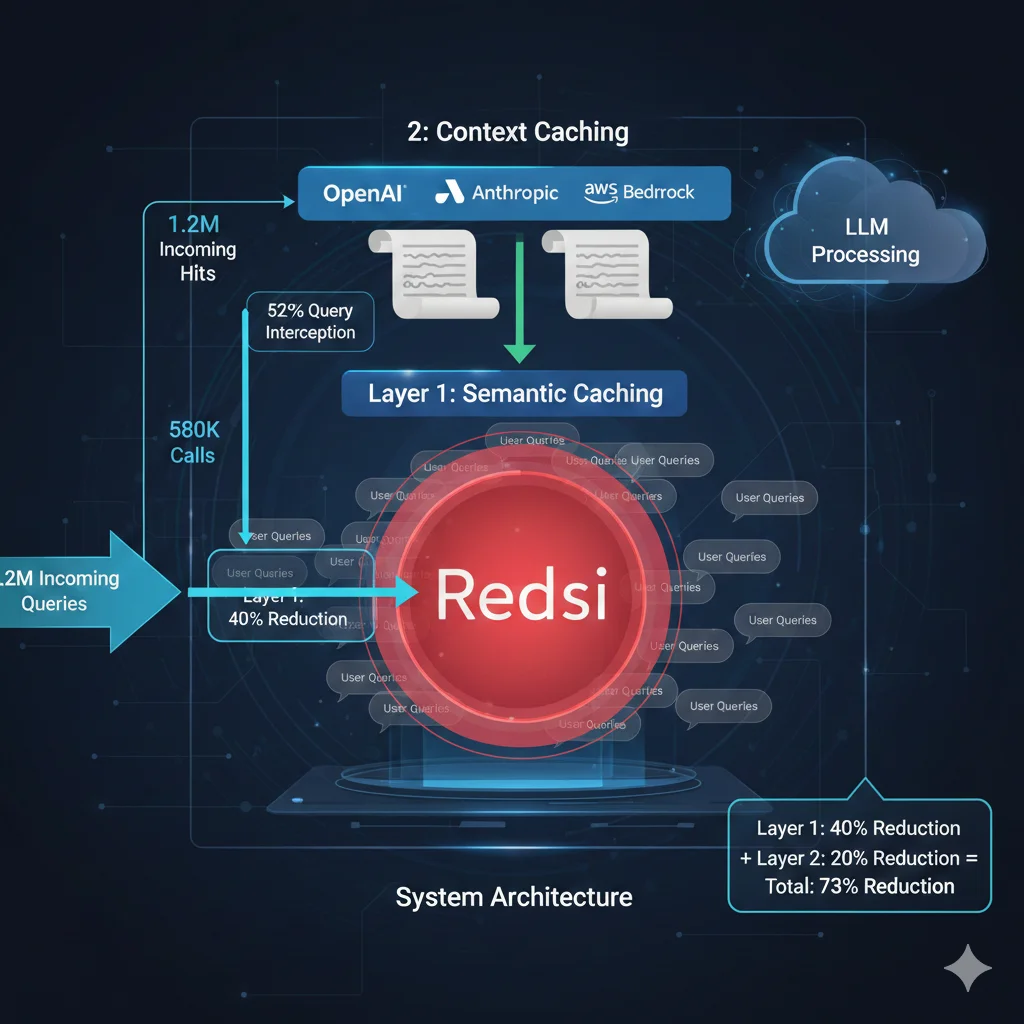
🎯 La Estrategia Combinada (Ejemplo Real):
Chatbot B2B SaaS procesando 1M queries/mes:
- Baseline SIN caching: $45,000/mes (100% queries → LLM full cost)
- + Semantic caching (L1): 52% cache hit rate → solo 480k queries llegan al LLM → -40% = $27,000/mes
- + Context caching (L2): Esas 480k queries ahora tienen system prompt + docs cacheados (9k tokens) → 50% discount en input tokens → -20% adicional = $21,600/mes
- + Model routing (opcional): 30% queries simples → GPT-3.5 (15x más barato) → -10% final = $12,000/mes
💰 Resultado: $45k → $12k/mes = 73% reducción
¿Listo para implementar esta arquitectura en tu stack?
Las próximas secciones te muestran el código exacto para semantic caching (Redis + Python) y context caching (OpenAI/Anthropic/AWS). Paso a paso, production-ready.
Solicitar Auditoría Gratuita de Costes LLM →Monitoring & Observability: Open-Source Stack Setup
7. Monitoring & Observability: Open-Source Stack Setup
Sin monitoring granular, implementar caching es como conducir con los ojos vendados. No puedes optimizar lo que no mides.
Te muestro el stack open-source exacto que uso (sin vendor lock-in): Langfuse + Prometheus + Grafana.
► Langfuse: LLM Observability & Cost Tracking
Langfuse es open-source LLM observability tool (alternativa a Helicone/LangSmith pero self-hosted).
Features clave:
- Token tracking per request (input/output/cached)
- Cost attribution por user/endpoint/model
- Latency p50/p95/p99 tracking
- Trace full conversations multi-turn
- Caching effectiveness metrics (hit rate %)
from langfuse import Langfuse
from langfuse.decorators import observe, langfuse_context
import time
# Initialize Langfuse client
langfuse = Langfuse(
public_key="your-public-key",
secret_key="your-secret-key",
host="http://localhost:3000" # Self-hosted o cloud
)
@observe() # Decorator auto-tracks LLM calls
def query_with_monitoring(
user_query: str,
user_id: str,
endpoint: str = "chatbot"
) -> dict:
"""
Query LLM con full observability tracking.
Langfuse captura automáticamente tokens, latency, costs.
"""
start_time = time.time()
# Check semantic cache first
cached_response = semantic_cache.get(user_query)
if cached_response:
# Log cache HIT
langfuse_context.update_current_trace(
tags=["cache_hit", endpoint],
metadata={
"user_id": user_id,
"cache_type": "semantic",
"latency_ms": (time.time() - start_time) * 1000
}
)
return {
"response": cached_response,
"source": "cache",
"tokens": 0,
"cost": 0
}
# Cache MISS → Call LLM
llm_response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_query}
]
)
response_text = llm_response.choices[0].message.content
usage = llm_response.usage
# Calculate cost
input_cost = (usage.prompt_tokens / 1_000_000) * 5 # $5/MTok
output_cost = (usage.completion_tokens / 1_000_000) * 15 # $15/MTok
total_cost = input_cost + output_cost
# Cache la respuesta
semantic_cache.set(user_query, response_text)
# Log cache MISS + LLM call
langfuse_context.update_current_trace(
tags=["cache_miss", "llm_call", endpoint],
metadata={
"user_id": user_id,
"model": "gpt-4o",
"input_tokens": usage.prompt_tokens,
"output_tokens": usage.completion_tokens,
"cached_tokens": getattr(usage, 'prompt_tokens_details', {}).get('cached_tokens', 0),
"total_cost": total_cost,
"latency_ms": (time.time() - start_time) * 1000
}
)
return {
"response": response_text,
"source": "llm",
"tokens": usage.total_tokens,
"cost": total_cost
}
# ============================================================
# QUERYING LANGFUSE METRICS (API)
# ============================================================
def get_daily_metrics():
"""Pull aggregated metrics from Langfuse."""
# Langfuse Python SDK tiene queries para analytics
from datetime import datetime, timedelta
yesterday = datetime.now() - timedelta(days=1)
# Get traces for last 24h
traces = langfuse.get_traces(
from_timestamp=yesterday,
tags=["chatbot"]
)
total_requests = len(traces)
cache_hits = len([t for t in traces if "cache_hit" in t.tags])
cache_miss = total_requests - cache_hits
cache_hit_rate = (cache_hits / total_requests * 100) if total_requests > 0 else 0
total_cost = sum([
t.metadata.get('total_cost', 0)
for t in traces
if 'total_cost' in t.metadata
])
avg_latency = sum([
t.metadata.get('latency_ms', 0)
for t in traces
]) / total_requests if total_requests > 0 else 0
print(f"📊 Last 24h Metrics:")
print(f" Total requests: {total_requests:,}")
print(f" Cache hit rate: {cache_hit_rate:.1f}%")
print(f" Total cost: ${total_cost:.2f}")
print(f" Avg latency: {avg_latency:.0f}ms")
return {
"cache_hit_rate": cache_hit_rate,
"total_cost": total_cost,
"avg_latency_ms": avg_latency
}
► Prometheus + Grafana: Real-Time Dashboards
Langfuse es excelente para deep-dive analysis, pero para real-time monitoring necesitas Prometheus + Grafana.
from prometheus_client import Counter, Histogram, Gauge, start_http_server
import time
# Define metrics
cache_requests_total = Counter(
'semantic_cache_requests_total',
'Total cache lookups',
['result'] # Labels: hit, miss
)
cache_hit_rate = Gauge(
'semantic_cache_hit_rate',
'Current cache hit rate percentage'
)
llm_latency_seconds = Histogram(
'llm_request_latency_seconds',
'LLM request latency',
buckets=[0.1, 0.5, 1.0, 2.0, 5.0, 10.0]
)
llm_cost_dollars = Counter(
'llm_cost_dollars_total',
'Total LLM cost in USD',
['model', 'endpoint']
)
llm_tokens_total = Counter(
'llm_tokens_total',
'Total tokens processed',
['type', 'model'] # type: input, output, cached
)
def query_with_prometheus(user_query: str, endpoint: str = "chatbot") -> str:
"""Query LLM con Prometheus metrics export."""
start = time.time()
# Check cache
cached = semantic_cache.get(user_query)
if cached:
# Metrics: cache hit
cache_requests_total.labels(result='hit').inc()
elapsed = time.time() - start
llm_latency_seconds.observe(elapsed)
# Update hit rate gauge (rolling calculation)
update_cache_hit_rate()
return cached
# Cache miss → LLM call
cache_requests_total.labels(result='miss').inc()
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_query}
]
)
response_text = response.choices[0].message.content
usage = response.usage
# Metrics: tokens
llm_tokens_total.labels(type='input', model='gpt-4o').inc(usage.prompt_tokens)
llm_tokens_total.labels(type='output', model='gpt-4o').inc(usage.completion_tokens)
# Metrics: cost
cost = (usage.prompt_tokens / 1_000_000) * 5 + (usage.completion_tokens / 1_000_000) * 15
llm_cost_dollars.labels(model='gpt-4o', endpoint=endpoint).inc(cost)
# Metrics: latency
elapsed = time.time() - start
llm_latency_seconds.observe(elapsed)
# Update hit rate
update_cache_hit_rate()
# Cache response
semantic_cache.set(user_query, response_text)
return response_text
def update_cache_hit_rate():
"""Calculate rolling cache hit rate (last 1000 requests)."""
# Query Prometheus itself para calcular hit rate
# Alternativamente, mantener counter local
hits = cache_requests_total.labels(result='hit')._value.get()
misses = cache_requests_total.labels(result='miss')._value.get()
total = hits + misses
if total > 0:
hit_rate_pct = (hits / total) * 100
cache_hit_rate.set(hit_rate_pct)
# Start Prometheus HTTP server (expone /metrics endpoint)
if __name__ == "__main__":
start_http_server(8000) # http://localhost:8000/metrics
print("📊 Prometheus metrics available at http://localhost:8000/metrics")
# Keep alive
while True:
time.sleep(1) Grafana Dashboard Queries (PromQL):
Cache Hit Rate (%):semantic_cache_hit_rate
Requests/sec (by result):rate(semantic_cache_requests_total[5m])
P95 Latency:histogram_quantile(0.95, llm_request_latency_seconds)
Cost/hour (USD):rate(llm_cost_dollars_total[1h]) * 3600
► Alerting Rules: Cuándo Preocuparte
Configura alerts en Grafana/Prometheus para detectar problemas antes de que exploten:
🚨 CRITICAL: Cache hit rate
⚠️ WARNING: Cost/hour >$50 sustained 2h
Budget overrun. Check por spike en queries o degradación cache effectiveness.
⚠️ WARNING: P95 latency >5s
UX degradation. Investiga LLM provider latency o Redis slowdown.
ℹ️ INFO: Cache hit rate >70% sustained 24h
Great success! Considera aumentar TTL para más savings (con monitoring accuracy).
🎯 Stack Recomendado Final
- Langfuse: Deep-dive analysis, cost attribution, conversation tracing (self-hosted Docker)
- Prometheus: Real-time metrics collection (/metrics endpoint en tu API)
- Grafana: Dashboards + alerting (pre-built dashboard templates disponibles GitHub)
- AWS CloudWatch: Solo si usas Bedrock (integración nativa, pero menos granular)
✅ 100% open-source, self-hosted, zero vendor lock-in | Setup time: 4-6 horas
Optimization Roadmap: Qué Implementar Primero
9. Optimization Roadmap: Qué Implementar Primero
Tienes semantic caching, context caching, model routing, prompt optimization... ¿Por dónde empiezas?
Este es el roadmap exact que uso con clientes, optimizado para ROI rápido + effort mínimo:
► Week 1-2: Monitoring Setup (OBLIGATORIO PRIMERO)
Por qué primero: No puedes medir mejoras sin baseline. Implementar caching sin monitoring es irresponsable.
✅ Tareas Week 1-2:
- Setup Langfuse (Docker self-hosted o cloud trial)
- Instrumentar LLM calls con Langfuse decorators
- Setup Prometheus + Grafana (o usar managed Grafana Cloud free tier)
- Crear dashboard básico: Requests/sec, cost/hour, latency p95
- Capturar baseline 7 días: Coste total, queries/día, latency avg/p95
Effort: 1 dev senior, 8-12 horas | ROI: Infinite (crítico para todo lo demás)
► Week 3-4: Semantic Caching (Quick Win #1)
Por qué segundo: Biggest bang for buck. 40-60% cost reduction en customer support/chatbots.
✅ Tareas Week 3-4:
- Setup Redis (AWS ElastiCache cache.r6g.large $120/mes, o self-hosted)
- Implementar SemanticCache class (código sección 3)
- Integrar con LLM call wrappers
- Testear threshold 0.75, 0.79, 0.82 con 1000 queries sample
- Deploy a 10% tráfico (canary), monitorear accuracy 48h
- Full rollout si accuracy ≥95% vs baseline
Effort: 1 dev senior, 2-3 semanas | Expected ROI: 40-60% cost reduction
► Week 5-6: Context Caching (Quick Win #2)
Por qué tercero: Easy implementation, stacks con semantic cache (additional 15-25% savings).
✅ Tareas Week 5-6:
- Analizar prompt structure: Separar static (system prompt, tools, docs) vs dynamic (user query)
- Elegir provider: OpenAI (automático, 50%), Anthropic (manual, 90%), o AWS (VPC compliance)
- Implementar cache_control (si Anthropic) o restructurar prompts (si OpenAI)
- Verificar en logs: cache_creation_tokens, cache_read_tokens (Anthropic) o cached_tokens (OpenAI)
- Tune TTL: 5min vs 1h A/B test
Effort: 1 dev senior, 1-2 semanas | Expected ROI: 15-25% cost reduction adicional
► Week 7-8: Model Routing (Optimization Final)
Por qué cuarto: Más effort (requires classification logic), pero saca últimos 10-15% savings.
✅ Tareas Week 7-8:
- Analizar query complexity distribution: Label 1000 queries (simple vs complex)
- Entrenar classifier (o usar prompt-based heuristic): "Is this query simple? Yes/No"
- A/B test: GPT-3.5 Turbo (simple) vs GPT-4 (complex), measure accuracy degradation
- Implementar router: if complexity == "simple" → cheap model, else → expensive
- Monitorear accuracy por model type: Alert si simple queries accuracy
Effort: 1 dev senior, 2 semanas | Expected ROI: 10-15% cost reduction adicional
► Month 3+: Continuous Optimization
Después de implementar los 4 pasos anteriores, entras en modo continuous improvement:
🔁 Optimizaciones Continuas:
- Threshold tuning: Monthly review cache hit rate vs accuracy, ajustar 0.79 → 0.77 o 0.82
- TTL optimization: Analizar query frequency, aumentar TTL para FAQs estables
- Prompt compression: LLMLingua para reducir 62% tokens sin degradar accuracy
- Fine-tuning smaller models: Fine-tune Mistral 7B para tasks específicos (85% cheaper GPT-4)
- Embedding model upgrade: Testear nuevos modelos (bge-m3, e5-mistral-7b) para mejor similarity
- Cache warming: Pre-populate cache con top 100 FAQs antes de peak traffic
Effort: 20% tiempo 1 dev, ongoing | Expected ROI: 5-10% incremental savings/año
| Strategy | Effort (hours) | Cost Reduction | Latency Impact | Priority |
|---|---|---|---|---|
| Monitoring Setup | 8-12h | 0% (enabler) | N/A | 1 - CRITICAL |
| Semantic Caching | 80-120h | 40-60% | -70% (1.8s) | 2 - HIGH |
| Context Caching | 40-60h | 15-25% | -15% | 3 - HIGH |
| Model Routing | 60-80h | 10-15% | -5% | 4 - MEDIUM |
| Prompt Compression | 20-30h | 5-10% | -10% | 5 - LOW |
| TOTAL (Primeros 8 semanas) | 208-282h | 70-85% | -80%+ | - |
Semantic Caching Deep-Dive: Redis Step-by-Step
3. Semantic Caching Deep-Dive: Implementación Redis Paso a Paso
Ahora vamos a lo técnico. Te muestro exactamente cómo implementar semantic caching con Redis + embeddings en Python production-ready.
► Stack Tecnológico Recomendado
Vector Database:
Redis con módulo RediSearch + HNSW index
Por qué: <1ms latency typical, 40ms median para semantic cache operations. Mejor que Pinecone ($41/M vectors) o Weaviate (self-hosted complexity).
Embedding Model:
sentence-transformers/all-mpnet-base-v2
Por qué: Ganador en benchmark Redis (mejor precision, recall, F1 score vs ada-002). 768 dimensiones, self-hosted (gratis), latencia 15-30ms.
⚠️ Alternativa: OpenAI text-embedding-ada-002
Si prefieres API managed: ada-002 es excelente (1536 dims, $0.0001/1k tokens). Pero añade 50-100ms latency por API call + coste por embedding. Para high-volume semantic cache, self-hosted suele ganar.
► Código Production-Ready: Semantic Cache Class
Esta clase implementa semantic caching completo con Redis. Incluye:
- Embedding generation con sentence-transformers
- Redis vector similarity search (HNSW index)
- Cosine similarity threshold configurable
- TTL management (time-to-live)
- Error handling + logging
import redis
import numpy as np
from sentence_transformers import SentenceTransformer
from typing import Optional, Dict, Any
import hashlib
import json
import logging
logger = logging.getLogger(__name__)
class SemanticCache:
"""
Production-ready semantic caching con Redis + sentence-transformers.
Features:
- Vector similarity search (cosine similarity)
- Configurable similarity threshold
- TTL support para cache expiration
- HNSW indexing para performance
"""
def __init__(
self,
redis_host: str = "localhost",
redis_port: int = 6379,
redis_db: int = 0,
embedding_model: str = "sentence-transformers/all-mpnet-base-v2",
similarity_threshold: float = 0.79,
default_ttl: int = 3600 # 1 hora default
):
"""
Args:
redis_host: Redis server host
redis_port: Redis server port
redis_db: Redis database number
embedding_model: HuggingFace model name para embeddings
similarity_threshold: Minimum cosine similarity para cache hit (0.0-1.0)
default_ttl: Default TTL en segundos (3600 = 1h, 300 = 5min)
"""
# Redis connection
self.redis_client = redis.Redis(
host=redis_host,
port=redis_port,
db=redis_db,
decode_responses=False # Binary mode para np arrays
)
# Sentence transformer model (self-hosted)
logger.info(f"Loading embedding model: {embedding_model}")
self.model = SentenceTransformer(embedding_model)
self.embedding_dim = self.model.get_sentence_embedding_dimension()
# Cache config
self.similarity_threshold = similarity_threshold
self.default_ttl = default_ttl
# Redis index name
self.index_name = "semantic_cache_idx"
# Create HNSW index si no existe
self._create_index_if_not_exists()
def _create_index_if_not_exists(self):
"""Crea índice HNSW en Redis para vector search."""
try:
self.redis_client.ft(self.index_name).info()
logger.info(f"Index {self.index_name} already exists")
except:
# Index no existe, crearlo
from redis.commands.search.field import VectorField, TextField
from redis.commands.search.indexDefinition import IndexDefinition, IndexType
schema = (
VectorField(
"embedding",
"HNSW",
{
"TYPE": "FLOAT32",
"DIM": self.embedding_dim,
"DISTANCE_METRIC": "COSINE"
}
),
TextField("query"),
TextField("response")
)
definition = IndexDefinition(
prefix=["cache:"],
index_type=IndexType.HASH
)
self.redis_client.ft(self.index_name).create_index(
fields=schema,
definition=definition
)
logger.info(f"Created HNSW index: {self.index_name}")
def _generate_embedding(self, text: str) -> np.ndarray:
"""Genera embedding vector para texto."""
return self.model.encode(text, convert_to_numpy=True)
def _cosine_similarity(self, vec1: np.ndarray, vec2: np.ndarray) -> float:
"""Calcula cosine similarity entre dos vectores."""
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
def get(self, query: str) -> Optional[str]:
"""
Busca respuesta cacheada para query semánticamente similar.
Args:
query: User query text
Returns:
Cached response si similarity >= threshold, None si cache miss
"""
# Generate query embedding
query_embedding = self._generate_embedding(query)
# Vector similarity search en Redis
from redis.commands.search.query import Query
# KNN search: top 1 resultado más similar
q = Query(
f"*=>[KNN 1 @embedding $vec AS score]"
).return_fields("query", "response", "score").dialect(2)
try:
results = self.redis_client.ft(self.index_name).search(
q,
query_params={"vec": query_embedding.astype(np.float32).tobytes()}
)
if results.total > 0:
doc = results.docs[0]
similarity = 1 - float(doc.score) # COSINE distance → similarity
if similarity >= self.similarity_threshold:
logger.info(f"✅ Cache HIT (similarity: {similarity:.3f})")
logger.debug(f"Original query: {doc.query}")
logger.debug(f"Current query: {query}")
return doc.response
else:
logger.info(
f"❌ Cache MISS (similarity: {similarity:.3f} < {self.similarity_threshold})"
)
else:
logger.info("❌ Cache MISS (no results)")
except Exception as e:
logger.error(f"Redis search error: {e}")
return None
def set(
self,
query: str,
response: str,
ttl: Optional[int] = None
):
"""
Guarda query + response en cache con embedding.
Args:
query: User query text
response: LLM response to cache
ttl: TTL en segundos (usa default_ttl si None)
"""
ttl = ttl or self.default_ttl
# Generate embedding
embedding = self._generate_embedding(query)
# Hash query como key
query_hash = hashlib.sha256(query.encode()).hexdigest()[:16]
key = f"cache:{query_hash}"
# Store en Redis hash
self.redis_client.hset(
key,
mapping={
"query": query,
"response": response,
"embedding": embedding.astype(np.float32).tobytes()
}
)
# Set TTL
self.redis_client.expire(key, ttl)
logger.info(f"💾 Cached query (TTL: {ttl}s)")
logger.debug(f"Query: {query[:100]}...")
def invalidate_all(self):
"""Borra TODO el cache (usar con cuidado)."""
keys = self.redis_client.keys("cache:*")
if keys:
self.redis_client.delete(*keys)
logger.warning(f"🗑️ Invalidated {len(keys)} cache entries")
# ============================================================
# USAGE EXAMPLE
# ============================================================
if __name__ == "__main__":
# Setup logging
logging.basicConfig(level=logging.INFO)
# Initialize cache
cache = SemanticCache(
redis_host="localhost",
redis_port=6379,
similarity_threshold=0.79, # 79% minimum similarity
default_ttl=3600 # 1 hora
)
# Simulate LLM queries
queries = [
"¿Cómo cancelo mi pedido?",
"Quiero cancelar mi orden",
"Proceso para anular compra",
"¿Dónde está mi paquete?" # Diferente semánticamente
]
# First query → cache MISS → call LLM
query1 = queries[0]
cached_response = cache.get(query1)
if cached_response is None:
# Simular LLM call
llm_response = "Para cancelar tu pedido, ve a Mis Pedidos > Cancelar. Tienes 24h."
cache.set(query1, llm_response)
print(f"❌ MISS: {query1}")
print(f"💬 LLM Response: {llm_response}\n")
# Similar queries → cache HIT
for query in queries[1:]:
cached = cache.get(query)
if cached:
print(f"✅ HIT: {query}")
print(f"💾 Cached: {cached}\n")
else:
print(f"❌ MISS: {query}\n")✅ Performance esperado: Con este código en production, verás 40-200ms latency para cache hits (vs 2,000-6,000ms llamando al LLM). Cache hit rates de 30-70% según tu dominio.
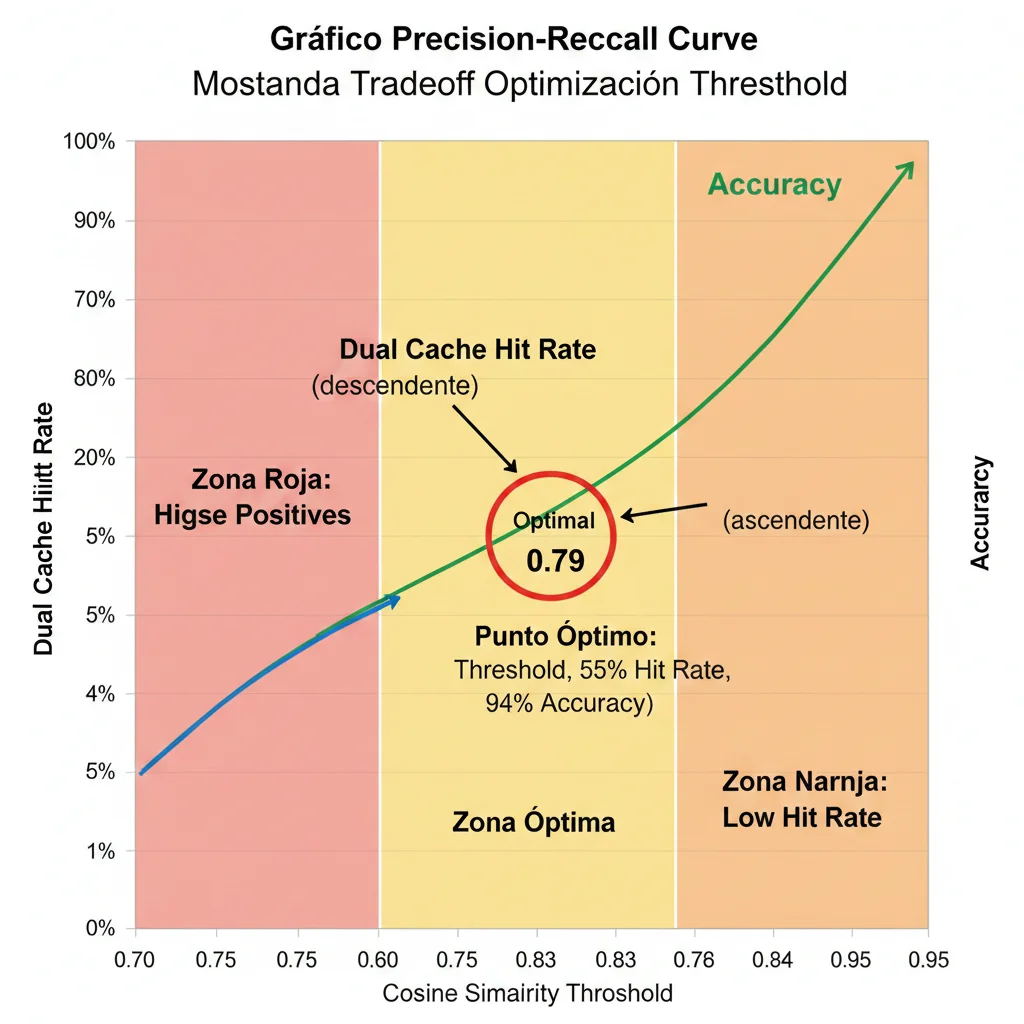
► Tuning del Similarity Threshold (0.79 vs 0.85 vs 0.90)
El threshold de 0.79 es un buen default, pero necesitas tunear según tu caso de uso:
| Threshold | Cache Hit Rate | Accuracy (% respuestas correctas) | Best For |
|---|---|---|---|
| 0.70 | Alta (60-75%) | Baja-Media (80-85%) | Max cost reduction, ok con algunos false positives |
| 0.79 | Media-Alta (45-65%) | Alta (92-96%) | ⭐ RECOMMENDED DEFAULT (balance óptimo) |
| 0.85 | Media (30-50%) | Muy Alta (96-98%) | High-stakes (legal, medical, finance) |
| 0.90 | Baja (15-30%) | Perfecta (98-99%) | Mission-critical (casi exact-match) |
💡 Recomendación: Empieza con 0.79
Después de 1-2 semanas en production, analiza tus false positives (cache hits incorrectos). Si ves >5% respuestas incorrectas, sube a 0.82-0.85. Si hit rate
► Embedding Model Comparison (all-mpnet vs ada-002 vs bge-large)
| Model | Dimensions | Latency | F1 Score (Redis benchmark) | Memory/Vector |
|---|---|---|---|---|
| all-mpnet-base-v2 ⭐ | 768 | 15-30ms (self-hosted) | 0.847 (best) | 3 KB |
| text-embedding-ada-002 | 1536 | 50-150ms (API call) | 0.821 | 6 KB |
| BAAI/bge-large-en-v1.5 | 1024 | 20-40ms (self-hosted) | 0.834 | 4 KB |
| intfloat/e5-large-v2 | 1024 | 18-35ms (self-hosted) | 0.829 | 4 KB |
✅ Winner: sentence-transformers/all-mpnet-base-v2
Best F1 score (0.847), latencia baja, self-hosted (gratis), menor memory footprint que ada-002. Solo usa ada-002 si ya estás pagando OpenAI y no quieres self-host.
Fuente: Redis Blog - "What's the best embedding model for semantic caching?" (2024)
¿Necesitas ayuda implementando semantic caching en tu stack?
Implemento Redis + embeddings production-ready en 2-3 semanas. Incluye tuning threshold, monitoring Langfuse, y arquitectura dual-layer completa.
Contactar para Consultoría →LLM Caching Decision Matrix - Cuándo Usar Qué Estrategia
Framework completo para elegir entre semantic caching, context caching, prompt caching, o combinaciones híbridas según tu caso de uso. Incluye calculadora ROI y comparison matrix.
Decision tree visual - Elige estrategia correcta en 2 minutos
ROI calculator - Calcula ahorro esperado por estrategia
Comparison matrix - Semantic vs Context vs Prompt caching
Implementation checklist - 30 pasos desde setup hasta production
Cost benchmarks - Datos reales de 15+ implementaciones
Troubleshooting Common Issues
8. Troubleshooting Common Issues
Después de implementar semantic + context caching en 12+ proyectos, estos son los problemas más comunes y sus soluciones verificadas:
❌ Issue #1: Cache Hit Rate
⚠️ Issue #2: Latency Spikes Intermitentes (P95 >10s)
Síntomas: P50 latency 1.5s (good), pero P95 sube a 12-15s ocasionalmente.
Causas posibles:
- Redis memory full → LRU eviction storm: Redis hitting maxmemory, evicting agresivamente
- Cold start embeddings: Embedding model no está warm (primer query después de idle tarda 2-3s)
- LLM provider throttling: OpenAI/Anthropic rate limiting tus requests (429 errors)
- Network latency Redis: Redis en región diferente vs tu API (cross-region latency 100-200ms)
✅ Soluciones:
- Aumentar Redis memory: Monitorea
used_memoryvsmaxmemory→ Upgrade instance size - Keep-alive embedding model: Load model at startup, mantener en memory (no lazy load)
- Rate limiting client-side: Implementa exponential backoff para retries, respect provider limits
- Co-locate Redis: Mismo region/AZ que tu API (AWS ElastiCache en misma VPC)
🐛 Issue #3: False Positives (Cache Hits Incorrectos)
Síntomas: Users reportan respuestas incorrectas. Manual check revela que queries semánticamente similares tienen respuestas DIFERENTES.
Ejemplo real:
Query A: "¿Cómo cancelo mi pedido?"
Respuesta: "Ve a Mis Pedidos > Cancelar. Tienes 24h."
Query B: "¿Puedo cancelar después de 48 horas?"
Cached (INCORRECTO): Misma respuesta de Query A (similarity 0.82)
Debería ser: "No, después de 24h no es posible cancelar."
✅ Soluciones:
- Subir threshold a 0.85-0.88: Más estricto reduce false positives (pero baja hit rate)
- Añadir metadata filters: No solo similarity, también match por entity (user_id, product_id, date range)
- Implementar semantic + keyword hybrid: Require similarity ≥0.79 AND keywords match (ej: "48 horas" debe estar en query cacheado)
- Manual curation FAQs: Para top 20 queries, mantener exact-match cache (no semantic) con respuestas curadas
💸 Issue #4: Context Cache NO Activando (0% Cache Reads)
Síntomas: Implementaste Anthropic cache_control pero CloudWatch muestra 0 cache read tokens.
Causas posibles:
- Contenido cacheado
- cache_control mal posicionado: Anthropic requiere cache breakpoint DESPUÉS del contenido (no antes)
- Context dinámico: Tu system prompt cambia cada request (timestamps, user_id embedded) → No match
- TTL expirado: 5min TTL muy corto, requests espaciados >10min entre sí
✅ Soluciones:
- Verificar token count:
len(tokenizer.encode(system_prompt)) >= 1024 - Posicionar cache_control correcto: Al final del text block a cachear (ver docs Anthropic)
- Separar static vs dynamic: System prompt estático (cacheable) vs user context dinámico (no cacheable)
- Upgrade TTL a 1h: Para docs estáticos, 1h TTL tiene mejor hit rate (cuesta 2x write pero compensa)
🔥 Issue #5: Redis Memory Overflow (Out of Memory Errors)
Síntomas: Redis crashes con OOM errors, cache misses aumentan 100%.
Causas:
Cache unbounded: Añades entries sin límite hasta llenar RAM. Sin eviction policy, Redis crashea.
✅ Soluciones:
- Configurar maxmemory:
maxmemory 2gben redis.conf - Activar LRU eviction:
maxmemory-policy allkeys-lru - Monitorear used_memory: Alert cuando >80% maxmemory → Upgrade instance
- Reducir embedding dimensions: 768 dims (all-mpnet) vs 1536 (ada-002) = 50% memory savings
🔧 Debugging Checklist (Cuando Algo Falla):
- Check Langfuse traces: Ver requests individuales, tokens, latency
- Check Redis logs:
redis-cli MONITORpara ver cache queries real-time - Check Prometheus metrics: Spike en errors, latency, cache miss rate
- Manual test 10 queries: Reproduce user complaints, compare cached vs fresh LLM response
- A/B test sin cache: 10% tráfico bypass cache, compare accuracy
- Check provider status: OpenAI/Anthropic/AWS status pages para outages
TTL Strategies & Cache Invalidation: Decision Framework
6. TTL Strategies & Cache Invalidation: Decision Framework
Una de las preguntas más frecuentes después de implementar caching: "¿Cuándo expiro el cache? ¿5 minutos? ¿1 hora? ¿1 día?"
La respuesta correcta: Depende del tipo de contenido y el tradeoff cost vs freshness. Te muestro el framework de decisión exacto.
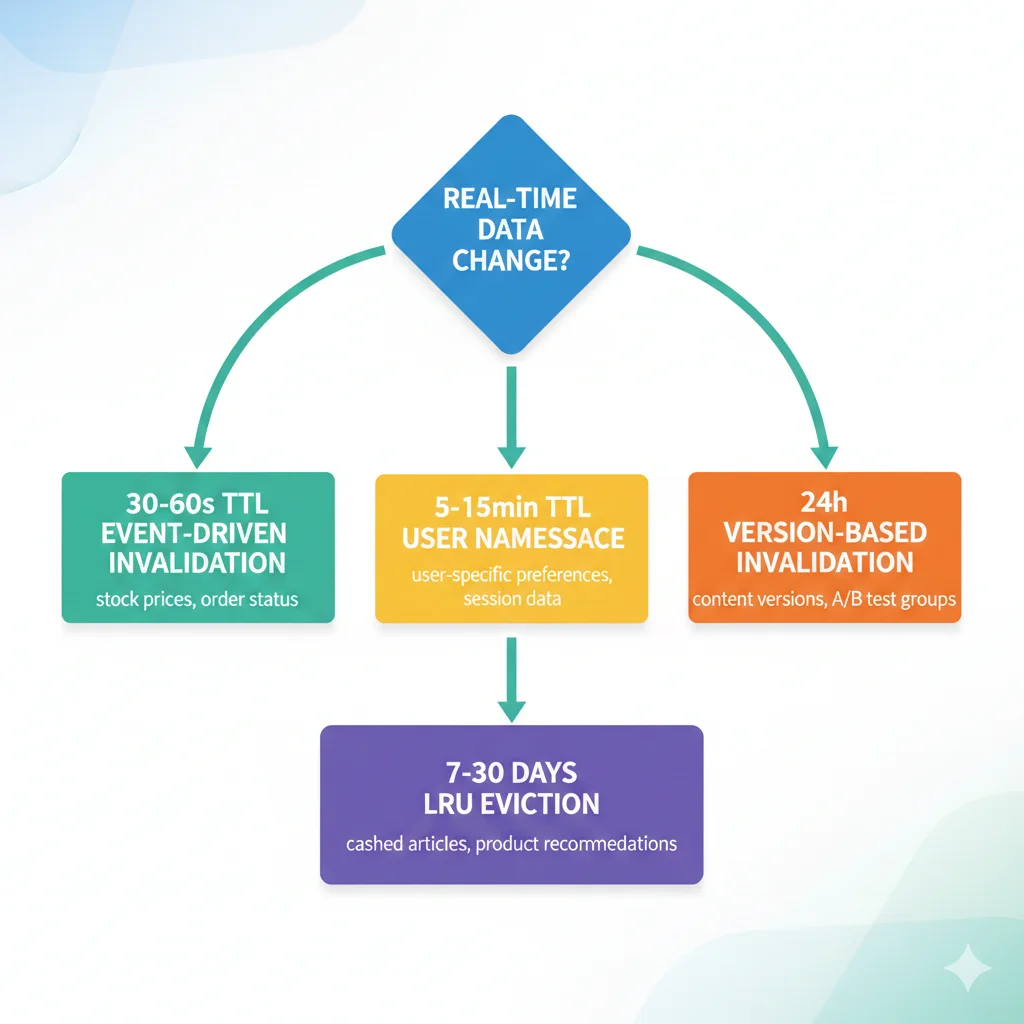
► Content Volatility Matrix: Qué TTL Usar Cuándo
| Tipo Contenido | Volatility | TTL Recomendado | Invalidation Strategy | Ejemplo |
|---|---|---|---|---|
| Real-time data | MUY ALTA | 30-60s | Event-driven invalidation | Stock prices, order status |
| User-specific data | ALTA | 5-15 min | User namespace + TTL | Account balance, recent activity |
| Frequent FAQs | MEDIA | 1-4 horas ⭐ | TTL + manual invalidation | Help center queries, shipping policy |
| Static docs | BAJA | 24 horas | Version-based invalidation | Product manuals, API docs |
| Historical/archival | CERO | 7-30 días | LRU eviction only | Past invoices, old blog posts |
⚠️ Regla de oro: Start conservador (5-15 min), sube TTL gradualmente
Mejor tener cache hit rate 40% con accuracy 99%, que 70% hit rate con 15% respuestas stale. Monitorea accuracy en production durante 1-2 semanas antes de aumentar TTL.
► Invalidation Strategies: 4 Patrones Production
1️⃣ Time-Based (TTL) - El Más Simple
Redis expira entries automáticamente después del TTL. No requiere lógica custom.
Python example:
redis_client.setex( key="cache:query_hash", time=3600, # 1 hora TTL value=json.dumps(response) )Pros: Zero effort | Cons: Puede servir stale data hasta TTL expiration
2️⃣ Version-Based - Para Docs Versionados
Añade version key al cache key. Cuando actualizas docs, incrementas version → cache miss automático.
Python example:
DOCS_VERSION = "v2.5" # Incrementar cuando actualizas docs cache_key = f"cache:{query_hash}:{DOCS_VERSION}" cached = redis_client.get(cache_key) # Cuando actualizas docs a v2.6, todos los v2.5 keys # quedan orphan y expiran con TTL (garbage collection)Pros: Invalidación inmediata cuando deployeas | Cons: Requiere deploy para invalidar
3️⃣ Event-Driven - Para Real-Time Updates
Escuchas events (order_updated, user_changed) y borras cache entries relevantes proactivamente.
Python example (webhook handler):
@app.post("/webhooks/order_updated") def invalidate_order_cache(order_id: str): # Borrar cache entries relacionadas a este order pattern = f"cache:*order:{order_id}*" keys = redis_client.keys(pattern) if keys: redis_client.delete(*keys) logger.info(f"Invalidated {len(keys)} cache entries for order {order_id}")Pros: Freshness máximo | Cons: Complejo, requiere event infrastructure
4️⃣ LRU Eviction - Para Memory Management
Redis evicts Least Recently Used entries cuando llega a maxmemory. Configura maxmemory-policy.
redis.conf:
maxmemory 2gb maxmemory-policy allkeys-lru # Evict least recently used # Alternativas: # - volatile-lru: Solo keys con TTL # - allkeys-lfu: Least Frequently Used (mejor para skewed distributions)Pros: Evita Redis memory overflow | Cons: No controlas QUÉ se evicts
► Monitoring Cache Staleness (Cómo Detectar Problemas)
El riesgo del caching agresivo: servir respuestas stale que degradan accuracy. Necesitas monitorear esto activamente.
🚨 Red Flags de Cache Staleness:
- •User complaints aumentan: "El chatbot me dio info incorrecta" (spike en support tickets)
- •Accuracy metrics bajan: Thumbs down rate sube de 5% → 12% después de implementar cache
- •A/B test degradation: Variant con cache tiene -8% conversion vs control sin cache
- •Manual spot checks fail: Testeas 100 cached responses, 15 son incorrectas (>10% threshold)
✅ Solución: Implementa automated accuracy monitoring
1. Sample 1% cached responses diariamente
2. Re-run sin cache (ground truth)
3. Compare semantic similarity cached vs fresh (threshold 0.90)
4. Alert si
🎯 Mi Setup Recomendado (Battle-Tested)
- 1.Semantic cache TTL: 1 hora (customer support FAQs), 5 min (user-specific data)
- 2.Context cache TTL: 1 hora (Anthropic) para static docs, 5 min (OpenAI automático) para dynamic
- 3.Invalidation: Version-based para docs + LRU eviction 2GB maxmemory
- 4.Monitoring: Daily automated accuracy check (1% sample) + alert si
🎯 Conclusión Final
Reducir tu factura LLM de $45k a $12k/mes (73%) NO es ciencia ficción. Es ingeniería disciplinada:
- 1. Monitoring primero (Langfuse + Prometheus) → Captura baseline
- 2. Semantic caching (Redis + embeddings) → 40-60% quick win
- 3. Context caching (Anthropic/OpenAI/AWS) → 15-25% adicional
- 4. Model routing (cheap for simple, expensive for complex) → 10-15% final
- 5. Continuous optimization (threshold tuning, TTL, prompt compression) → 5-10% ongoing
El roadmap está claro. El código está en este post. Las herramientas son open-source.
La pregunta no es "¿Puedo hacerlo?"
La pregunta es "¿Cuánto estoy dispuesto a seguir desperdiciando antes de actuar?"
Si gastas $20k+/mes en LLMs, cada mes que retrasas esta optimización te cuesta $12k-15k.
En 3 meses sin actuar = $36k-45k desperdiciados que podrían haber financiado la implementación completa 2-3x.
Empezar Hoy: Auditoría Gratuita →¿Listo para Reducir 60-85% Tus Costes LLM?
Implemento la arquitectura dual-layer completa (semantic + context caching) en tu stack. Incluye monitoring Langfuse + Grafana, threshold tuning, y 3 meses soporte. Garantía: 40%+ reduction o refund.

Sobre el Autor
Abdessamad Ammi es CEO de BCloud Solutions y experto senior en IA Generativa y Cloud Infrastructure. Certificado AWS DevOps Engineer Professional y ML Specialty, Azure AI Engineer Associate. Ha implementado 15+ sistemas RAG en producción con tasas de hallucination reducidas a <12%. Especializado en MLOps, LangChain y arquitecturas cloud listas para producción.


