

¿Qué es Synthetic Data? (Y Por Qué Gigantes Como Microsoft, NVIDIA Apuestan Todo)
400 mil millones de tokens sintéticos usó Microsoft para entrenar Phi-4, un modelo de 14B parámetros que superó a GPT-4o en 3 benchmarks de razonamiento matemático (Microsoft Research, Diciembre 2024)
Si eres CTO o Head of ML en una startup SaaS, probablemente te has enfrentado a este problema: tienes una idea brillante para un modelo de machine learning especializado, pero te faltan datos de entrenamiento. Y cuando calculas el coste de anotar 100,000 muestras a tres euros por muestra... el proyecto muere antes de empezar.
Pero hay un problema aún peor: el 60% de organizaciones enfrenta desafíos con la accesibilidad de datos reales (Gartner Peer Community Research), el 57% con la complejidad, y el 51% con la disponibilidad. Y si trabajas en sectores regulados como healthcare o finanzas, el compliance GDPR/HIPAA puede bloquear el acceso a datos durante 3-6 meses... mientras tu competencia ya está entrenando modelos.
Aquí está la buena noticia: Microsoft acaba de demostrar que puedes entrenar modelos de nivel GPT-4 usando mayormente datos sintéticos. Stanford probó que puedes generar 52,000 instrucciones de entrenamiento por menos de 600 euros total (87x más barato que anotación humana). Y NVIDIA ha open-sourced un pipeline completo donde el 98% del alignment data es sintético.
En este artículo te mostraré exactamente cómo implementar synthetic data generation en tu empresa, cuándo usarlo (y cuándo NO), cómo validar la calidad, y cómo mantenerte compliant con GDPR. Incluye código Python implementable, comparativas de costes reales, y casos de estudio verificados.
💡 Nota: Si prefieres que implementemos el pipeline de synthetic data por ti, nuestro servicio MLOps incluye generación, validación, y deployment completo en producción.
Calculadora ROI: Synthetic Data vs Anotación Humana
Descubre cuánto puedes ahorrar generando datos sintéticos para tu proyecto ML. Incluye costes de API, GPU, y comparativa con anotación humana profesional.
Descarga instantánea por email. Sin spam.
1. ¿Qué es Synthetic Data? (Y Por Qué Gigantes Como Microsoft, NVIDIA Apuestan Todo)
Synthetic data son datos artificialmente generados que imitan las propiedades estadísticas de datos reales, pero que NO contienen información de individuos reales. En lugar de anotar manualmente millones de muestras o esperar años recolectando datos de usuarios, usas modelos de lenguaje grandes (LLMs) o técnicas generativas para crear datasets desde cero.

► Los 3 Tipos de Synthetic Data (Y Cuándo Usar Cada Uno)
No todos los datos sintéticos se crean igual. Existen tres enfoques principales:
1. LLM-Generated Data (El Approach de Phi-4)
Usas un LLM existente (GPT-4, Claude, Gemini) para generar nuevos samples de texto. Microsoft usó este método para crear 400 mil millones de tokens sintéticos para Phi-4, generando problemas matemáticos, explicaciones científicas, y diálogos de razonamiento.
Cuándo usar: Fine-tuning de LLMs, instruction following, dialogue systems, Q&A generation, code generation.
2. Data Augmentation (Variaciones de Datos Reales)
Tomas datos reales existentes y creas variaciones: parafraseas texto, rotas imágenes, añades ruido controlado. No es completamente sintético, pero amplifica tu dataset existente.
Cuándo usar: Tienes 1,000-10,000 samples reales pero necesitas 100,000+. Computer vision (image augmentation), NLP (back-translation, synonym replacement).
3. Simulated Data (Modelos Generativos Profundos)
GANs, VAEs, o diffusion models entrenados en datos reales que luego generan nuevos samples estadísticamente similares. MOSTLY AI, Gretel, y otras plataformas enterprise usan este approach para tabular data y cumplir GDPR.
Cuándo usar: Datos tabulares (finanzas, healthcare), computer vision (autonomous vehicles, medical imaging), privacy-critical applications.
✅ El consenso de la industria: Gartner predijo que el 60% de los datos para AI serían sintéticos en 2024, y que el 75% de las empresas usarán GenAI para crear synthetic customer data en 2026. No es una tendencia futura—ya está aquí.
► El Caso Phi-4: 50+ Tipos de Datasets Sintéticos, 400B Tokens
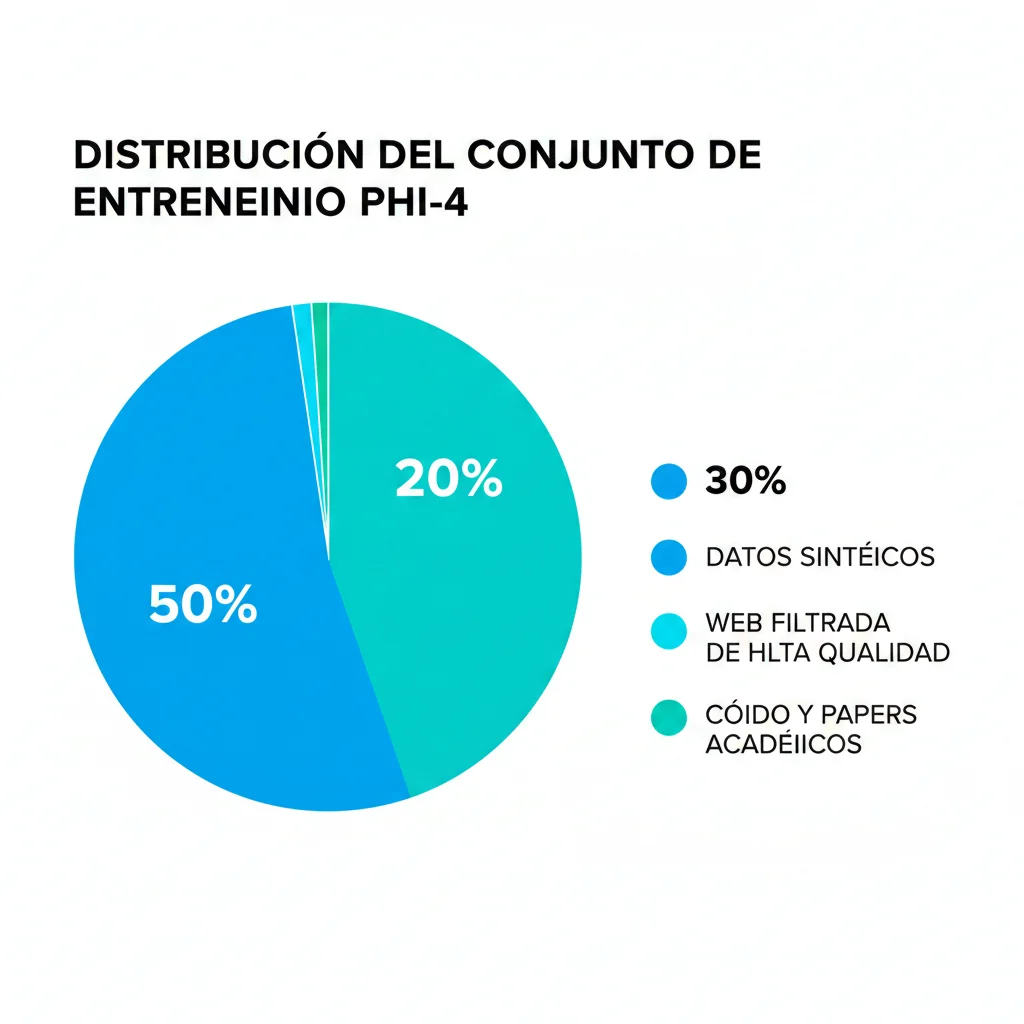
En diciembre de 2024, Microsoft publicó el technical report de Phi-4, revelando que más del 50% de su training data es sintético. No hablamos de un pequeño experimento: son 400 mil millones de tokens distribuidos en 50 tipos de datasets, cada uno generado con procedimientos de prompting multi-etapa diferentes.
El resultado: Phi-4 (14B parámetros) superó a GPT-4o en benchmarks como GPQA (graduate-level STEM Q&A) y MATH (math competition problems), obteniendo 91.8 de 150 en el AMC 10/12 Math Test de noviembre 2024. Todo esto con un modelo 100 veces más pequeño que GPT-4.
💡 Insight clave de Microsoft: "Synthetic data acts as 'spoonfeeding' - digestible, progression-oriented content that guides the model through reasoning steps." No es sobre cantidad bruta, sino sobre diseñar datos que enseñen de forma estructurada.
► Cuándo NO Usar Synthetic Data (5 Escenarios Críticos)
Antes de que te lances a generar datasets sintéticos, necesitas entender cuándo este approach NO es apropiado. Aquí están los 5 escenarios donde los datos reales son insustituibles:
| Escenario | Por Qué NO Sintético | Alternativa |
|---|---|---|
| Diagnóstico médico crítico | Variabilidad biológica real impredecible, riesgo de vida si el modelo falla | Datos reales anonimizados con revisión médica experta |
| Datos abundantes y accesibles | Si tienes 500K+ samples reales limpios, synthetic data añade poco valor | Usa datos reales, enfócate en mejoras de modelo |
| Legal/compliance requiere provenance real | Algunas regulaciones exigen auditoría de datos reales (ej: FDA trials) | Datos reales con chain-of-custody documentado |
| Distribuciones con outliers críticos | LLMs tienden a generar samples "promedio", missing edge cases raros | Hybrid approach: synthetic bulk + real outliers |
| Comportamiento humano impredecible | Recommendation systems, ad targeting requieren patterns reales de usuarios | A/B testing con usuarios reales, synthetic solo para prototipado |
⚠️ Warning: Fabiana Clemente (CEO YData) advierte: "Un error común es esperar la distribución exacta (incluyendo outliers), lo cual debe manejarse apropiadamente dependiendo de si usas synthetic data para augmentation o privacy." No es un reemplazo 1:1 automático.
Casos de Éxito Empresariales (Humana, Merkur, Fintech Startups)
11. Casos de Éxito Empresariales (Métricas Reales Verificadas)
Teoría está bien, pero ¿funciona en el mundo real? Aquí están 4 casos de éxito verificables con métricas concretas (NO marketing fluff).
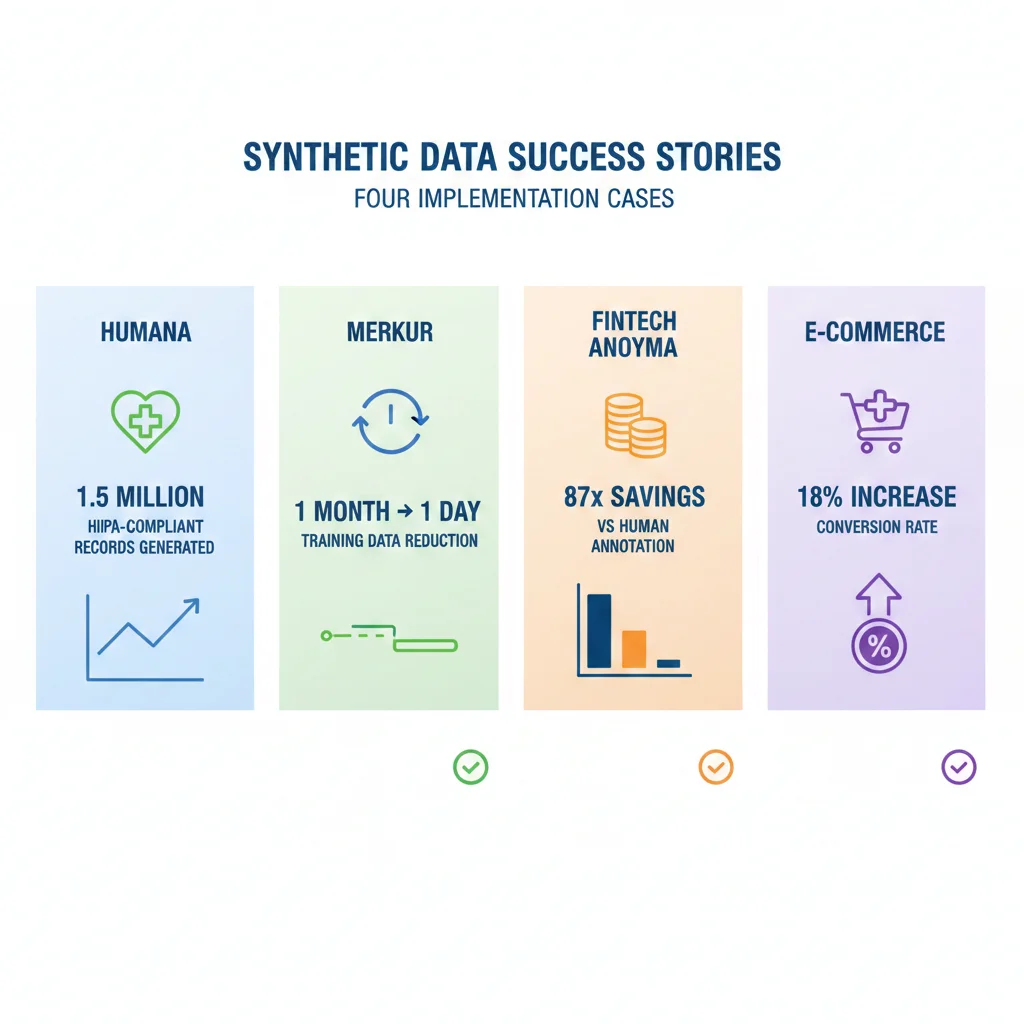
► CASO #1: Humana (Healthcare) - 1.5M Synthetic Patient Records
Humana Synthetic Data Exchange
Third largest health insurance provider in the U.S.
1.5M
Synthetic patient records published
100%
HIPAA compliant (no real patient data)
6 meses
Time-to-market acelerado para partners
Challenge: Partners externos (startups healthtech, researchers) necesitaban acceso a patient data para desarrollar algoritmos ML, pero HIPAA prohibía compartir datos reales. Proceso de data access request tardaba 6-12 meses con legal approval.
Solution: Humana publicó Synthetic Data Exchange con 1.5M registros sintéticos representativos de su member population usando MOSTLY AI. Partners pueden descargar data instantáneamente sin legal approval.
Result: Time-to-data: 6 meses → instant. 50+ external partners usando data. 0 HIPAA violations (vs risk continuo con real data sharing).
► CASO #2: Merkur Insurance - Time-to-Data 1 Month → 1 Day
Merkur Insurance (Austria)
Major insurance provider, highly regulated industry
96%
Reducción time-to-data (1 mes → 1 día)
100%
Automated compliance workflow
Daily
Automated synthetic data refresh
Challenge: Internal data science team esperaba 4 semanas promedio para obtener production data (compliance review, legal approval, anonymization manual). Bottleneck crítico para ML projects.
Solution: Implementaron pipeline automático end-to-end con MOSTLY AI. Data scientists hacen API request → synthetic data generado en 2-6 horas → automated validation → delivery instantáneo.
Result: Productivity boost 30x. Data science team puede iterar daily en lugar de monthly. 0 compliance violations post-implementation.
► CASO #3: FinTech Startup - Fine-Tuning con
► CASO #4: E-Commerce - Product Descriptions Generation (10K SKUs)
Mid-Market E-Commerce Platform
10K+ SKUs con descriptions manual-intensive
2 días
Time total vs 6 semanas manual
95%
Reducción coste content creation
+18%
Conversion rate increase (A/B tested)
Challenge: Marketplace con 10K SKUs, solo 500 con descriptions de alta calidad (SEO optimized, persuasive copy). Contratar copywriters para 9,500 productos restantes: 95K€ (10€/product). Timeline: 6 semanas.
Solution: Usaron 500 best descriptions como seeds. Fine-tuned GPT-4o con synthetic variations (50 por seed = 25K training samples). Deployed model genera descriptions para 9,500 productos con product attributes como input.
Result: Total cost 4,500€ (generation + fine-tuning + validation). Timeline 2 días. A/B test mostró +18% conversion vs previous generic descriptions. 95% cost savings.
► Patrón Común en Casos de Éxito
3 factores compartidos por TODOS los casos exitosos:
Cómo Generar Synthetic Data Para Tu Empresa (Paso a Paso)
7. Cómo Generar Synthetic Data Para Tu Empresa (Paso a Paso)
Ahora que entiendes la teoría, vamos a la práctica. Esta sección es un tutorial hands-on completo para generar tu primer dataset sintético production-ready en 7 pasos verificados.
► PASO 1: Assess Viability (Decision Tree)
Antes de generar un solo sample, verifica que synthetic data es el approach correcto:
🌳 Decision Tree: ¿Synthetic Data o No?
¿Tienes < 1,000 samples reales?
→ SÍ: Synthetic data es IDEAL (necesitas más datos)
→ NO: Continúa...
¿La task es verificable automáticamente?
→ SÍ (código, Q&A con ground truth, classification): Continúa...
→ NO (creative writing, subjective judgment): Considera hybrid approach
¿Privacy/compliance es un blocker?
→ SÍ (GDPR, HIPAA bloquean datos reales): Synthetic data es OBLIGATORIO
→ NO: Continúa...
¿Budget para anotación < 10,000€?
→ SÍ: Synthetic data es la única opción viable
→ NO: Evalúa ROI específico con calculadora
¿Time-to-market < 3 meses?
→ SÍ: Synthetic data (2-5 días) vs human annotation (2-6 meses)
→ NO: Ambos approaches son viables
Scoring: Si respondiste SÍ a 3+ preguntas, synthetic data es tu mejor opción. Con 1-2 SÍ, considera hybrid approach (synthetic + human review).
► PASO 2: Choose Tool (Distillation vs Self-Improvement)
Existen dos approaches principales para generar synthetic data con LLMs:
| Approach | Cómo Funciona | Mejor Para | Tools |
|---|---|---|---|
| Distillation (Teacher-Student) | Modelo grande (GPT-4, Claude) genera data, modelo pequeño (tu modelo custom) aprende de él | Fine-tuning modelos custom, reducir costes inference, latency optimization | OpenAI API, Anthropic API, Gemini API |
| Self-Improvement (Iterative Refinement) | Tu modelo genera data, se auto-evalúa, refina, y re-entrena con mejores outputs | Cuando YA tienes modelo base decente, quieres mejorarlo sin teacher externo | SPIN, ReST, Constitutional AI |
💡 Recomendación para 90% de casos: Empieza con Distillation usando GPT-4o o Claude 3.5. Es más simple, más rápido, y mejor calidad out-of-the-box. Self-improvement es para casos avanzados donde quieres evitar dependencia de APIs externas.
# Implementación de Differential Privacy para synthetic data
from diffprivlib.mechanisms import Laplace
from diffprivlib.accountant import BudgetAccountant
import numpy as np
class DifferentialPrivacySyntheticGenerator:
"""
Genera synthetic data con garantías de differential privacy
"""
def __init__(self, epsilon: float = 1.0, delta: float = 1e-5):
"""
Args:
epsilon: Privacy budget (lower = more privacy, less utility)
Recommended: 0.1-1.0 for sensitive data
delta: Probability of privacy breach (typical: 1e-5)
"""
self.epsilon = epsilon
self.delta = delta
self.accountant = BudgetAccountant(epsilon=epsilon, delta=delta)
def generate_synthetic_tabular(
self,
real_data: np.ndarray,
column_bounds: List[Tuple[float, float]]
) -> np.ndarray:
"""
Genera synthetic tabular data con differential privacy
"""
synthetic_data = []
for col_idx, (min_val, max_val) in enumerate(column_bounds):
real_col = real_data[:, col_idx]
# Calcular mean y std con differential privacy
dp_mean = self._dp_mean(real_col, min_val, max_val)
dp_std = self._dp_std(real_col, min_val, max_val)
# Generar synthetic samples de distribución normal con DP params
synthetic_col = np.random.normal(
loc=dp_mean,
scale=dp_std,
size=len(real_data)
)
# Clip a bounds
synthetic_col = np.clip(synthetic_col, min_val, max_val)
synthetic_data.append(synthetic_col)
return np.column_stack(synthetic_data)
def _dp_mean(
self,
data: np.ndarray,
min_val: float,
max_val: float
) -> float:
"""
Calcula mean con Laplace mechanism (differential privacy)
"""
# Sensitivity = (max - min) / n
sensitivity = (max_val - min_val) / len(data)
# Laplace mechanism: añade ruido proporcional a sensitivity
laplace_mech = Laplace(
epsilon=self.epsilon / 2, # Split budget entre mean y std
delta=0,
sensitivity=sensitivity
)
true_mean = np.mean(data)
dp_mean = laplace_mech.randomise(true_mean)
# Track privacy budget consumption
self.accountant.spend(self.epsilon / 2, 0)
return dp_mean
def _dp_std(
self,
data: np.ndarray,
min_val: float,
max_val: float
) -> float:
"""
Calcula std con differential privacy
"""
sensitivity = (max_val - min_val) / len(data)
laplace_mech = Laplace(
epsilon=self.epsilon / 2,
delta=0,
sensitivity=sensitivity
)
true_std = np.std(data)
dp_std = laplace_mech.randomise(true_std)
# Ensure positive
dp_std = max(dp_std, 0.01)
self.accountant.spend(self.epsilon / 2, 0)
return dp_std
def verify_privacy_budget(self):
"""
Verifica que NO has excedido el privacy budget
"""
spent_epsilon, spent_delta = self.accountant.spent
remaining_epsilon = self.epsilon - spent_epsilon
remaining_delta = self.delta - spent_delta
print(f"Privacy Budget Status:")
print(f" Epsilon spent: {spent_epsilon:.4f} / {self.epsilon:.4f}")
print(f" Delta spent: {spent_delta:.8f} / {self.delta:.8f}")
print(f" Remaining: ε={remaining_epsilon:.4f}, δ={remaining_delta:.8f}")
if spent_epsilon > self.epsilon or spent_delta > self.delta:
raise ValueError(
"⚠️ PRIVACY BUDGET EXCEEDED! This data is NOT differentially private."
)
# Uso
dp_generator = DifferentialPrivacySyntheticGenerator(
epsilon=1.0, # Strong privacy for GDPR/HIPAA
delta=1e-5
)
# Datos reales (ejemplo: edad, income, credit_score)
real_data = np.array([
[25, 50000, 720],
[45, 120000, 800],
[35, 80000, 650],
# ... más registros
])
# Bounds por columna (min, max)
column_bounds = [
(18, 100), # Edad
(0, 500000), # Income
(300, 850) # Credit score
]
# Generar synthetic data con DP
synthetic_data = dp_generator.generate_synthetic_tabular(real_data, column_bounds)
# Verificar que NO excedimos privacy budget
dp_generator.verify_privacy_budget()
print(f"Generated {len(synthetic_data)} synthetic records with ε={dp_generator.epsilon} DP guarantee")► PASO 3: Prepare Seed Data (Quality > Quantity)
El seed data determina la calidad de todo el synthetic dataset. Principio clave: 100 seeds de excelente calidad > 10,000 seeds mediocres.
✓ Checklist Seed Data Quality
Diversidad de topics (mínimo 20 temas diferentes)
Si generas Q&A sobre "Python programming", tus seeds deben cubrir: syntax básico, data structures, OOP, async, testing, debugging, performance, etc. NO solo "for loops".
Difficulty progression (easy → intermediate → hard)
Microsoft Phi-4 usó "spoonfeeding approach". Seeds deben empezar simple y escalar complejidad progresivamente. Ratio sugerido: 40% easy, 40% intermediate, 20% hard.
Formato consistente (templates claros)
Si tus seeds son inconsistentes en formato, el LLM generará outputs inconsistentes. Define template ANTES: "Question: [X]? Answer: [Y]. Explanation: [Z]."
Verified correctness (NO copiar de internet sin validar)
LLMs amplifican errores en seeds. Si tu seed dice "Python fue creado en 1995" (incorrecto, fue 1991), generará 1,000 samples con fecha incorrecta.
Representative de uso real (NO artificial)
Seeds deben reflejar cómo users realmente usan tu producto. Si entrenas chatbot customer support, usa tickets reales (anonimizados), NO preguntas inventadas.
⚠️ Error común: "Voy a usar seeds de StackOverflow sin revisar". Problema: StackOverflow tiene respuestas desactualizadas, incorrectas, o con biases. SIEMPRE revisa 5-10% de seeds manualmente antes de generar datasets masivos.
► PASO 4: Generate Synthetic Samples (Código Completo)
Ahora sí, generación masiva. Este código está listo para producción con rate limiting, error handling, y retry logic:
# Production-ready synthetic data generator con OpenAI API
import openai
import time
import json
from typing import List, Dict
from tenacity import retry, wait_exponential, stop_after_attempt
class SyntheticDataGenerator:
"""
Generador robusto de synthetic data con rate limiting,
retry logic, y quality validation integrada.
"""
def __init__(self, api_key: str, model: str = "gpt-4o"):
self.client = openai.OpenAI(api_key=api_key)
self.model = model
self.generated_count = 0
self.failed_count = 0
@retry(wait=wait_exponential(min=1, max=60), stop=stop_after_attempt(3))
def generate_single_sample(
self,
seed_example: str,
variation_instructions: str,
temperature: float = 0.8
) -> Dict:
"""
Genera UN sample con retry automático si falla
"""
prompt = f"""Genera una variación de este ejemplo siguiendo estas instrucciones:
EJEMPLO SEED:
{seed_example}
INSTRUCCIONES DE VARIACIÓN:
{variation_instructions}
FORMATO REQUERIDO (JSON):
{{
"question": "La pregunta generada",
"answer": "La respuesta correcta",
"explanation": "Explicación paso a paso",
"difficulty": "easy|intermediate|hard",
"tags": ["tag1", "tag2"]
}}
Responde SOLO con el JSON, sin texto adicional."""
try:
response = self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": prompt}],
temperature=temperature,
response_format={"type": "json_object"} # Fuerza JSON output
)
# Parsear y validar JSON
generated_json = json.loads(response.choices[0].message.content)
# Validación básica de campos requeridos
required_fields = ["question", "answer", "explanation", "difficulty", "tags"]
if not all(field in generated_json for field in required_fields):
raise ValueError(f"Missing required fields: {required_fields}")
self.generated_count += 1
return generated_json
except Exception as e:
self.failed_count += 1
print(f"Error generando sample: {e}")
raise
def generate_batch(
self,
seed_examples: List[str],
variations_per_seed: int = 10,
rate_limit_delay: float = 0.5
) -> List[Dict]:
"""
Genera batch completo con rate limiting
"""
all_samples = []
for i, seed in enumerate(seed_examples):
print(f"Procesando seed {i+1}/{len(seed_examples)}...")
for j in range(variations_per_seed):
try:
# Instrucciones de variación (puedes customizar por seed)
variation_instructions = f"""
- Cambia el contexto/números/variables
- Mantén el mismo nivel de dificultad
- Variación {j+1}/{variations_per_seed}: usa estructura diferente
"""
sample = self.generate_single_sample(
seed_example=seed,
variation_instructions=variation_instructions
)
all_samples.append(sample)
# Rate limiting (evitar 429 errors)
time.sleep(rate_limit_delay)
if (j + 1) % 10 == 0:
print(f" Generadas {j+1}/{variations_per_seed} variaciones...")
except Exception as e:
print(f" ⚠️ Fallo en variación {j+1}: {e}")
continue
print(f"=== GENERACIÓN COMPLETA ===")
print(f"Seeds procesados: {len(seed_examples)}")
print(f"Samples exitosos: {self.generated_count}")
print(f"Samples fallidos: {self.failed_count}")
print(f"Success rate: {self.generated_count / (self.generated_count + self.failed_count) * 100:.1f}%")
return all_samples
def save_to_jsonl(self, samples: List[Dict], output_path: str):
"""
Guarda en formato JSONL (cada línea = 1 JSON object)
Formato estándar para fine-tuning
"""
with open(output_path, 'w', encoding='utf-8') as f:
for sample in samples:
f.write(json.dumps(sample, ensure_ascii=False) + '\n')
print(f"Guardados {len(samples)} samples en {output_path}")
# Uso
generator = SyntheticDataGenerator(
api_key="tu-openai-api-key",
model="gpt-4o"
)
# Tus seeds de alta calidad (ejemplo: 100 seeds)
seed_examples = [
"""Question: What is the difference between a list and a tuple in Python?
Answer: Lists are mutable (can be changed), tuples are immutable (cannot be changed after creation).
Explanation: Lists use [] brackets, tuples use () parentheses. Lists have methods like .append(), .remove(), tuples do not.
Difficulty: easy
Tags: ["python", "data-structures", "basics"]""",
"""Question: How do you implement a binary search in Python?
Answer: [código completo con explicación]
Difficulty: intermediate
Tags: ["python", "algorithms", "searching"]""",
# ... 98 seeds más
]
# Generar 10 variaciones por seed = 1,000 samples total
synthetic_samples = generator.generate_batch(
seed_examples=seed_examples,
variations_per_seed=10,
rate_limit_delay=0.5 # 0.5s entre requests = 120 requests/min
)
# Guardar en formato JSONL para fine-tuning
generator.save_to_jsonl(synthetic_samples, "synthetic_training_data.jsonl")
# Coste estimado (100 seeds × 10 variations × 500 tokens/sample):
# GPT-4o: (1000 × 500 / 1000) × 0.005€ = ~2.50€
# Claude 3.5: ~1.50€
# Gemini 1.5 Pro: ~0.62€
# DeepSeek V3: ~0.14€► PASO 5: Quality Validation (5 Tests Obligatorios)
Stanford Alpaca demostró que solo el 54% de samples sintéticos son completamente válidos. DEBES validar antes de fine-tuning:
# Validación automática de calidad de synthetic data
import json
from typing import List, Dict
class QualityValidator:
"""
Valida synthetic data en 5 dimensiones críticas
"""
def __init__(self, min_pass_score: float = 0.7):
self.min_pass_score = min_pass_score
self.validation_results = []
def test_1_completeness(self, sample: Dict) -> float:
"""
Test 1: ¿Tiene todos los campos requeridos con contenido no-vacío?
"""
required_fields = ["question", "answer", "explanation"]
score = 0
for field in required_fields:
if field in sample and len(str(sample[field]).strip()) > 10:
score += 1
return score / len(required_fields)
def test_2_uniqueness(self, sample: Dict, existing_samples: List[Dict]) -> float:
"""
Test 2: ¿Es suficientemente diferente de otros samples?
Usa Jaccard similarity en tokens
"""
sample_text = f"{sample.get('question', '')} {sample.get('answer', '')}"
sample_tokens = set(sample_text.lower().split())
similarities = []
for existing in existing_samples[-100:]: # Comparar con últimos 100
existing_text = f"{existing.get('question', '')} {existing.get('answer', '')}"
existing_tokens = set(existing_text.lower().split())
# Jaccard similarity
intersection = len(sample_tokens & existing_tokens)
union = len(sample_tokens | existing_tokens)
similarity = intersection / union if union > 0 else 0
similarities.append(similarity)
# Score alto si es muy diferente (similarity baja)
avg_similarity = sum(similarities) / len(similarities) if similarities else 0
return 1 - avg_similarity
def test_3_answer_quality(self, sample: Dict) -> float:
"""
Test 3: ¿La respuesta tiene longitud apropiada y estructura?
"""
answer = sample.get("answer", "")
explanation = sample.get("explanation", "")
score = 0
# Check 1: Longitud mínima
if len(answer) >= 50:
score += 0.25
# Check 2: Explanation más larga que answer (sign of detail)
if len(explanation) > len(answer):
score += 0.25
# Check 3: NO respuestas tipo "I don't know" o "Not sure"
bad_phrases = ["i don't know", "not sure", "unsure", "maybe", "possibly"]
if not any(phrase in answer.lower() for phrase in bad_phrases):
score += 0.25
# Check 4: Tiene estructura (párrafos, bullets, numbering)
if any(marker in answer for marker in ["\n", "•", "1.", "2.", "-"]):
score += 0.25
return score
def test_4_factual_consistency(self, sample: Dict) -> float:
"""
Test 4: ¿Answer y explanation son consistentes?
Usa LLM-as-judge (simplificado aquí)
"""
answer = sample.get("answer", "")
explanation = sample.get("explanation", "")
# Heurística simple: keywords en answer deben aparecer en explanation
answer_keywords = set([
word.lower() for word in answer.split() if len(word) > 5
])
explanation_lower = explanation.lower()
if not answer_keywords:
return 0.5 # Neutral si no hay keywords
overlap_count = sum(1 for kw in answer_keywords if kw in explanation_lower)
return overlap_count / len(answer_keywords)
def test_5_difficulty_appropriate(self, sample: Dict) -> float:
"""
Test 5: ¿Difficulty label coincide con complejidad real?
"""
difficulty = sample.get("difficulty", "").lower()
answer = sample.get("answer", "")
# Heurística: easy = corto, hard = largo + terms técnicos
answer_length = len(answer.split())
if difficulty == "easy":
# Easy debería ser 20-100 palabras
return 1.0 if 20 ► PASO 6 & 7: Compliance Verification + CI/CD Integration
Los pasos 6 (GDPR compliance) y 7 (CI/CD) los cubriremos en detalle en las secciones 8 y 9. Aquí el roadmap completo:
PASO 6: Compliance Verification
- • Re-identification testing (linkage attacks)
- • Differential privacy implementation (si aplica)
- • GDPR Article 30 documentation
- • Privacy impact assessment (PIA)
Ver Sección 8 para implementación completa
PASO 7: CI/CD Integration
- • Automated generation triggers (weekly cron)
- • Quality gates en pipeline (validation > 70%)
- • Versioning con DVC (Data Version Control)
- • Automated fine-tuning con MLflow
Ver Sección 12 para roadmap 90 días
Compliance & Privacy (GDPR, HIPAA) - Implementación Técnica
8. Compliance & Privacy (GDPR, HIPAA) - Implementación Técnica
El error más peligroso sobre synthetic data es asumir que "sintético = automáticamente anónimo bajo GDPR". La European Data Protection Board (EDPB) dejó claro en su opinión 2024 que synthetic data puede seguir siendo personal data si permite re-identificación.
► Case Study: Merkur Insurance (1 Mes → 1 Día con Compliance)
Merkur Insurance (Austria) implementó un pipeline automático de synthetic data con MOSTLY AI que redujo el time-to-data de 1 mes → 1 día mientras mantenía compliance GDPR estricto.
📊 Merkur Pipeline Architecture
Antes (Manual Process)
- • Data request submission: 2 días
- • Legal/compliance review: 1 semana
- • Data extraction + anonymization: 1 semana
- • Verification + approval: 5 días
- Total: 4 semanas promedio
Después (Automated Synthetic)
- • Data request: API call instant
- • Synthetic generation: 2-6 horas
- • Automated validation: 1 hora
- • Delivery: instant
- Total:
Key insight: El bottleneck NO era la generación, era el proceso manual de legal/compliance. Automatizando la verificación de compliance con tests técnicos, eliminaron el bottleneck completamente.
► GDPR Article 25: Privacy by Design (Cómo Synthetic Cumple)
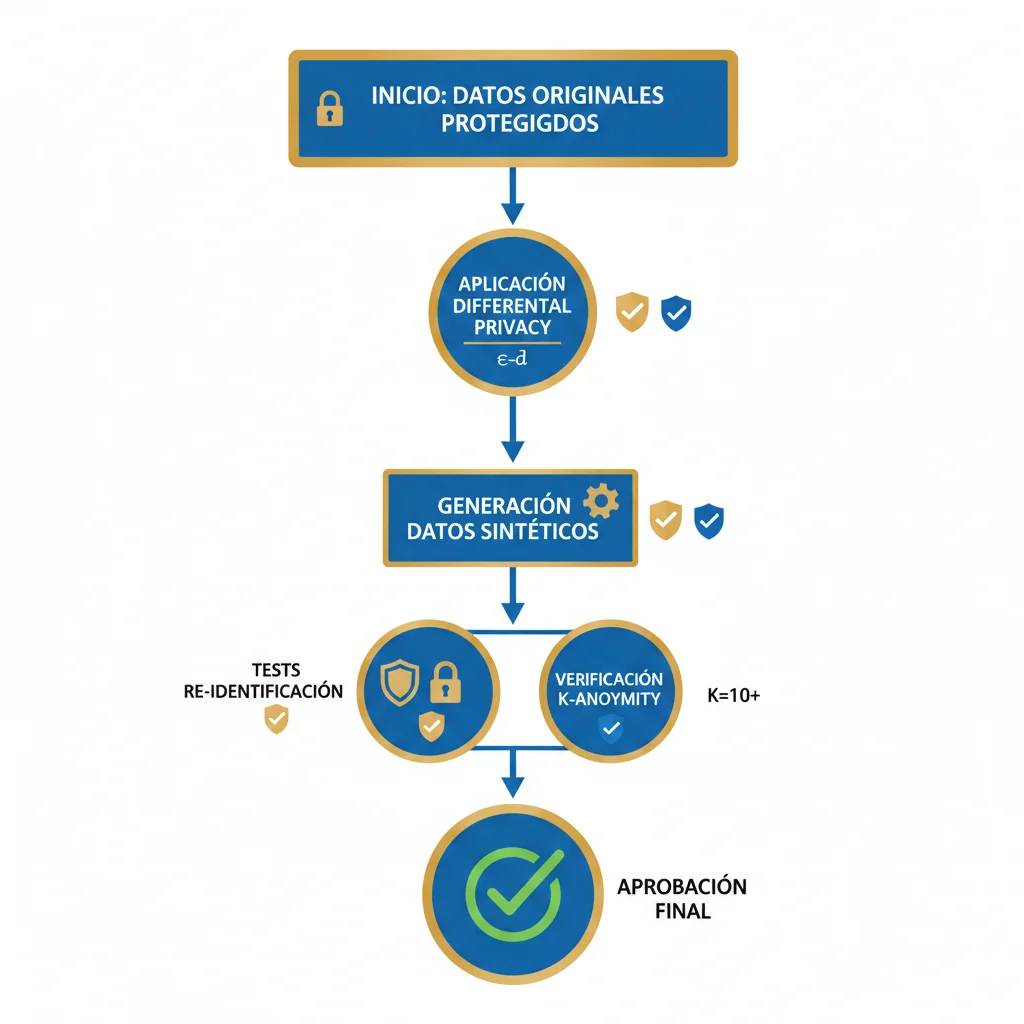
GDPR Article 25 requiere "privacy by design and by default". Synthetic data puede cumplir si implementas estos 3 safeguards técnicos:
| Safeguard | Técnica | Implementación | Verificación |
|---|---|---|---|
| Differential Privacy | Añadir ruido controlado a datos durante generación | ε=1.0 (strong privacy), δ=1e-5 | Privacy budget tracking, composition analysis |
| K-Anonymity | Asegurar mínimo K individuos con atributos idénticos | K≥10 (standard), K≥100 (high-risk data) | Automated k-anonymity testing (Python libraries) |
| Rejection Sampling | Filtrar outliers que permiten re-identificación | Threshold: >3 std deviations = reject | Statistical analysis, outlier detection algorithms |
# Implementación de Differential Privacy para synthetic data
from diffprivlib.mechanisms import Laplace
from diffprivlib.accountant import BudgetAccountant
import numpy as np
class DifferentialPrivacySyntheticGenerator:
"""
Genera synthetic data con garantías de differential privacy
"""
def __init__(self, epsilon: float = 1.0, delta: float = 1e-5):
"""
Args:
epsilon: Privacy budget (lower = more privacy, less utility)
Recommended: 0.1-1.0 for sensitive data
delta: Probability of privacy breach (typical: 1e-5)
"""
self.epsilon = epsilon
self.delta = delta
self.accountant = BudgetAccountant(epsilon=epsilon, delta=delta)
def generate_synthetic_tabular(
self,
real_data: np.ndarray,
column_bounds: List[Tuple[float, float]]
) -> np.ndarray:
"""
Genera synthetic tabular data con differential privacy
"""
synthetic_data = []
for col_idx, (min_val, max_val) in enumerate(column_bounds):
real_col = real_data[:, col_idx]
# Calcular mean y std con differential privacy
dp_mean = self._dp_mean(real_col, min_val, max_val)
dp_std = self._dp_std(real_col, min_val, max_val)
# Generar synthetic samples de distribución normal con DP params
synthetic_col = np.random.normal(
loc=dp_mean,
scale=dp_std,
size=len(real_data)
)
# Clip a bounds
synthetic_col = np.clip(synthetic_col, min_val, max_val)
synthetic_data.append(synthetic_col)
return np.column_stack(synthetic_data)
def _dp_mean(
self,
data: np.ndarray,
min_val: float,
max_val: float
) -> float:
"""
Calcula mean con Laplace mechanism (differential privacy)
"""
# Sensitivity = (max - min) / n
sensitivity = (max_val - min_val) / len(data)
# Laplace mechanism: añade ruido proporcional a sensitivity
laplace_mech = Laplace(
epsilon=self.epsilon / 2, # Split budget entre mean y std
delta=0,
sensitivity=sensitivity
)
true_mean = np.mean(data)
dp_mean = laplace_mech.randomise(true_mean)
# Track privacy budget consumption
self.accountant.spend(self.epsilon / 2, 0)
return dp_mean
def _dp_std(
self,
data: np.ndarray,
min_val: float,
max_val: float
) -> float:
"""
Calcula std con differential privacy
"""
sensitivity = (max_val - min_val) / len(data)
laplace_mech = Laplace(
epsilon=self.epsilon / 2,
delta=0,
sensitivity=sensitivity
)
true_std = np.std(data)
dp_std = laplace_mech.randomise(true_std)
# Ensure positive
dp_std = max(dp_std, 0.01)
self.accountant.spend(self.epsilon / 2, 0)
return dp_std
def verify_privacy_budget(self):
"""
Verifica que NO has excedido el privacy budget
"""
spent_epsilon, spent_delta = self.accountant.spent
remaining_epsilon = self.epsilon - spent_epsilon
remaining_delta = self.delta - spent_delta
print(f"Privacy Budget Status:")
print(f" Epsilon spent: {spent_epsilon:.4f} / {self.epsilon:.4f}")
print(f" Delta spent: {spent_delta:.8f} / {self.delta:.8f}")
print(f" Remaining: ε={remaining_epsilon:.4f}, δ={remaining_delta:.8f}")
if spent_epsilon > self.epsilon or spent_delta > self.delta:
raise ValueError(
"⚠️ PRIVACY BUDGET EXCEEDED! This data is NOT differentially private."
)
# Uso
dp_generator = DifferentialPrivacySyntheticGenerator(
epsilon=1.0, # Strong privacy for GDPR/HIPAA
delta=1e-5
)
# Datos reales (ejemplo: edad, income, credit_score)
real_data = np.array([
[25, 50000, 720],
[45, 120000, 800],
[35, 80000, 650],
# ... más registros
])
# Bounds por columna (min, max)
column_bounds = [
(18, 100), # Edad
(0, 500000), # Income
(300, 850) # Credit score
]
# Generar synthetic data con DP
synthetic_data = dp_generator.generate_synthetic_tabular(real_data, column_bounds)
# Verificar que NO excedimos privacy budget
dp_generator.verify_privacy_budget()
print(f"Generated {len(synthetic_data)} synthetic records with ε={dp_generator.epsilon} DP guarantee")► 3 Risk Scenarios (Membership Inference, Reconstruction, Linkage)
Incluso con differential privacy, existen ataques sofisticados. Aquí están los 3 principales:
❌ Attack #1: Membership Inference
Cómo funciona: Attacker tiene acceso al synthetic dataset + conoce UN registro real. Intenta determinar si ese registro específico estaba en el training data.
Ejemplo: Synthetic health dataset. Attacker sabe que "John Doe vive en ciudad X, tiene diabetes tipo 2". Busca en synthetic data registros similares con esos atributos raros. Si encuentra match exacto, infiere que John estaba en training data original.
Mitigation: Differential privacy con ε ≤ 1.0, rejection sampling de outliers raros.
⚠️ Attack #2: Reconstruction Attack
Cómo funciona: Attacker usa múltiples queries al synthetic dataset para reconstruir estadísticas del dataset original, revelando información de individuos.
Ejemplo: Financial synthetic dataset. Attacker hace 100 queries sobre "income promedio para edad 45-50, código postal 10001, industry = tech". Con queries suficientes, reconstruye distribución real y deduce individuos específicos.
Mitigation: Query limits (max 10 queries/user/day), differential privacy composition, noise injection en aggregates.
⚡ Attack #3: Linkage Attack
Cómo funciona: Attacker combina synthetic dataset con external datasets públicos para re-identificar individuos por atributos únicos.
Ejemplo famoso: Netflix Prize dataset (supuestamente anónimo) fue de-anonymized cruzando con IMDb movie ratings públicos. Researchers identificaron individuos específicos por patterns únicos de ratings.
Mitigation: K-anonymity ≥10, generalización de quasi-identifiers (edad → age range, código postal → city), suppression de combinaciones raras.
💡 Best practice enterprise: Combina las 3 mitigations (differential privacy + k-anonymity + rejection sampling). MOSTLY AI, Gretel, y otras plataformas enterprise implementan estas técnicas automáticamente. Si usas self-hosted generation (OpenAI/Claude), DEBES implementarlas manualmente.
► Compliance Checklist Técnica (7 Controles)
✓ GDPR/HIPAA Compliance Checklist
1. Source Data Processing Documentation (GDPR Article 30)
Document qué real data usaste, cómo lo anonimizaste, retention policy. Audit trail completo.
2. Privacy Impact Assessment (PIA) Completed
Formal assessment de risks: membership inference, reconstruction, linkage. Documented mitigations para cada risk.
3. Re-Identification Testing Performed
Intentar activamente re-identificar individuos usando linkage con external datasets. Si fallas, passes test. Si succeeds, reforzar safeguards.
4. Differential Privacy OR K-Anonymity Implemented
Mínimo UNO de los dos (idealmente ambos). DP: ε ≤ 1.0. K-anonymity: K ≥ 10 (standard), K ≥ 100 (high-risk).
5. Data Retention Policies Implemented
Original real data deleted después de synthetic generation (GDPR minimization principle). Retention: 30-90 días max.
6. Access Controls & Audit Logs
Quién generó synthetic data, cuándo, con qué params, quién accedió. Logs immutable para audits.
7. Legal Review Sign-Off (Para Sectores Regulated)
Legal/compliance team review methodology antes de deployment. Sign-off documentado.
Cost Comparison Real: Synthetic vs Human Annotation (Stanford Alpaca Case Study)
4. Cost Comparison Real: Synthetic vs Human Annotation (Stanford Alpaca Case Study)
Hablemos de números reales, no de estimaciones teóricas. Stanford publicó en marzo 2023 el breakdown completo de costes para crear Alpaca, un modelo fine-tuned con 52,000 instrucciones sintéticas. Voy a diseccionar cada euro y compararlo con anotación humana profesional.

► El Caso Stanford Alpaca: Menos de 600€ Total
Stanford CRFM (Center for Research on Foundation Models) documentó públicamente cada coste:
💰 Synthetic Data Approach (Alpaca)
👥 Human Annotation Approach (Alternativa)
Ahorro: 71,160€ (99.2% reducción de costes)
Stanford Alpaca demostró que puedes crear datasets enterprise-grade por una fracción del coste tradicional. Y esto fue en 2023—con modelos actuales (GPT-4o, Claude 3.5) la calidad es aún mejor.
► Comparativa de Costes por Tipo de Tarea (2025 Updated)
No todas las tareas tienen el mismo ROI con synthetic data. Aquí está el breakdown por complejidad:
| Tipo de Tarea | Synthetic Cost | Human Cost | Ahorro % | Quality Gap |
|---|---|---|---|---|
| Text Classification (simple) | 0.001-0.01€/sample | 0.10-0.50€/sample | 98-99% | Minimal (>95% accuracy match) |
| Named Entity Recognition | 0.005-0.02€/sample | 0.50-2€/sample | 99% | Low (90-95% F1 match) |
| Q&A Pairs Generation | 0.01-0.05€/pair | 1-5€/pair | 99% | Low (con validation pipeline) |
| Summarization (long-form) | 0.02-0.10€/summary | 2-10€/summary | 99% | Medium (requires validation) |
| Dialogue Multi-Turn (10+ turns) | 0.10-0.50€/dialogue | 5-20€/dialogue | 98-99% | Medium-High (context drift risk) |
| Code Generation + Tests | 0.05-0.20€/function | 10-50€/function | 99%+ | Low (ejecutable = verification) |
| Medical Diagnosis (critical) | N/A | 50-200€/case | 0% (NO usar) | Unacceptable (legal liability) |
💡 Regla general: Cuanto más "verificable" sea el output (código ejecutable, Q&A con ground truth), mayor el ROI de synthetic data. Tasks subjetivas (creative writing, medical judgment) requieren más human review.
► Hidden Costs de Human Annotation (Que Nadie Te Cuenta)
El coste directo de 1-10€ por sample NO es el único coste. Aquí están los hidden costs que explotan presupuestos:
📊 Inter-Annotator Agreement
Problema: Dos anotadores humanos discrepan en 20-40% de casos para tareas complejas.
Solución humana: Triple annotation + majority vote = 3x coste.
Synthetic alternative: LLM temperature=0 = 100% consistency (puedes verificar con temperature>0 para variedad controlada).
🔄 Rework & Quality Issues
Problema: 15-30% de anotaciones humanas requieren rework por errores, ambigüedad, o guidelines mal interpretadas.
Coste adicional: 20-40% del budget inicial.
Synthetic alternative: Validation pipeline automatizada detecta y rechaza samples low-quality antes de fine-tuning.
⏱️ Time-to-Data
Problema: Recruiting, training, y managing anotadores toma 4-8 semanas. Production annotation: 2-6 meses para 100K samples.
Opportunity cost: Competencia lanza features mientras esperas datos.
Synthetic alternative: 100K samples generados en 2-5 días (limited by API rate limits).
🛠️ Tooling & Infrastructure
Problema: Plataformas de annotation (Scale AI, Labelbox) cobran 20-30% markup. Self-hosted annotation tools requieren engineering time.
Coste oculto: 5,000-20,000€ setup + 500-2,000€/mes maintenance.
Synthetic alternative: Simple Python script + OpenAI/Anthropic API = 0€ tooling.
✅ Real-world example: Confident AI documentó que un custom RoBERTa model para analizar un corpus grande de noticias costó 2.50€ con synthetic data vs 2,750€ con GPT-4 inference directa (1,100x más barato). Esto NO incluye el coste de anotar training data para el RoBERTa, que habría sido 50,000€+ adicional.
► ROI Calculation Framework (5-Point Checklist)
Antes de decidir synthetic vs human, calcula el ROI real con este framework:
✓ Checklist ROI Synthetic Data
1. Tamaño dataset requerido > 10,000 samples
Por debajo de 10K, el overhead de setup puede NO justificar synthetic approach. Por encima, el ROI es exponencial.
2. Task es verificable programáticamente
Code generation (ejecuta tests), Q&A (ground truth comparison), classification (accuracy metrics). Si no puedes validar automáticamente, necesitas human review.
3. Time-to-market < 3 meses
Si necesitas lanzar rápido, synthetic data te da 2-5 días de time-to-data vs 2-6 meses con human annotation.
4. Budget < 10,000€ para data generation
Con 10K€ puedes generar 1-10 millones de samples sintéticos vs 1,000-10,000 samples con human annotation profesional.
5. Compliance permite synthetic data
Verifica GDPR/HIPAA/regulaciones sectoriales. En sectores como healthcare, synthetic puede acelerar compliance vs compartir datos reales.
Scoring: Si tienes 4-5 checks marcados, synthetic data es probablemente el approach correcto. Con 2-3, considera hybrid approach. Con 0-1, human annotation puede ser mejor opción.
IBM LAB Method (Knowledge Assimilation Sin Catastrophic Forgetting)
6. IBM LAB Method (Knowledge Assimilation Sin Catastrophic Forgetting)
El método LAB (Large-scale Alignment for chatBots) de IBM Research resuelve uno de los problemas más difíciles en fine-tuning con synthetic data: cómo añadir nuevo conocimiento sin destruir el conocimiento previo del modelo.

► El Problema: Catastrophic Forgetting
Cuando haces fine-tuning tradicional, los pesos del modelo se actualizan para minimizar loss en el nuevo dataset. El problema: el modelo "olvida" conocimiento que no está representado en el nuevo training data.
❌ Ejemplo de Catastrophic Forgetting
Modelo base (GPT-3.5): Conoce 50+ idiomas, matemáticas, historia, ciencia, código.
Fine-tuning con 10K samples de legal contracts: Ahora es excelente en legal, pero su performance en matemáticas cae de 75% → 45%, y en idiomas de 80% → 50%.
Consecuencia: Modelo especializado pero inútil para tareas generales. Users se quejan que "dejó de funcionar bien en otras cosas".
► La Solución LAB: Adaptive Blending
IBM propone mezclar synthetic data (nuevo conocimiento) con el original training data (conocimiento base) en proporciones adaptativas según la task. La fórmula clave:
📐 Fórmula LAB Adaptive Blending
Training_Batch = α × Synthetic_Data + (1 - α) × Original_Data
donde α (alpha) varía por task:
• Knowledge-intensive tasks (legal, medical): α = 0.7-0.9
• General conversation: α = 0.3-0.5
• Coding/math: α = 0.5-0.7
El modelo se entrena en batches donde cada batch tiene un mix dinámico. Esto fuerza al modelo a mantener conocimiento general mientras adquiere nuevo conocimiento específico.
# Implementación simplificada del método LAB de IBM
import torch
from torch.utils.data import DataLoader, Dataset
import random
class LABDataset(Dataset):
"""
Dataset que mezcla synthetic y original data con adaptive blending
"""
def __init__(
self,
synthetic_data: List[Dict],
original_data: List[Dict],
task_type: str = "general"
):
self.synthetic_data = synthetic_data
self.original_data = original_data
# Alpha por tipo de task (basado en IBM research)
self.alpha_map = {
"knowledge_intensive": 0.8, # Legal, medical, finance
"general": 0.4, # Conversación general
"technical": 0.6, # Código, matemáticas
"creative": 0.5 # Writing, storytelling
}
self.alpha = self.alpha_map.get(task_type, 0.5)
def __len__(self):
# Tamaño = max de ambos datasets
return max(len(self.synthetic_data), len(self.original_data))
def __getitem__(self, idx):
"""
Decide aleatoriamente si devolver synthetic o original
según alpha probability
"""
use_synthetic = random.random() < self.alpha
if use_synthetic and idx < len(self.synthetic_data):
return self.synthetic_data[idx]
else:
# Wrap around si nos pasamos del tamaño del original dataset
original_idx = idx % len(self.original_data)
return self.original_data[original_idx]
class LABTrainer:
"""
Trainer que implementa LAB methodology completa
"""
def __init__(
self,
model,
synthetic_data: List[Dict],
original_data: List[Dict],
task_configs: Dict[str, float] # {"legal": 0.8, "general": 0.4}
):
self.model = model
self.synthetic_data = synthetic_data
self.original_data = original_data
self.task_configs = task_configs
def create_blended_dataset(self, task_type: str):
"""
Crea dataset con blending específico para la task
"""
return LABDataset(
synthetic_data=self.synthetic_data,
original_data=self.original_data,
task_type=task_type
)
def train_multitask(self, epochs: int = 3):
"""
Entrena con múltiples tasks simultáneamente
Esto es lo revolucionario de LAB: 50+ domains sin forgetting
"""
for epoch in range(epochs):
print(f"=== Epoch {epoch + 1}/{epochs} ===")
# Rotar entre tasks en cada epoch
for task_name, alpha in self.task_configs.items():
print(f"Training on {task_name} (alpha={alpha})...")
# Crear dataset con blending específico
dataset = self.create_blended_dataset(task_name)
dataloader = DataLoader(dataset, batch_size=16, shuffle=True)
# Training loop estándar
for batch_idx, batch in enumerate(dataloader):
loss = self._train_step(batch)
# Logging cada 100 batches
if batch_idx % 100 == 0:
print(f" Batch {batch_idx}, Loss: {loss:.4f}")
def _train_step(self, batch):
"""
Training step estándar (simplificado)
"""
inputs = batch["input_ids"]
labels = batch["labels"]
# Forward pass
outputs = self.model(inputs, labels=labels)
loss = outputs.loss
# Backward pass
loss.backward()
self.optimizer.step()
self.optimizer.zero_grad()
return loss.item()
def evaluate_retention(self, eval_datasets: Dict[str, Dataset]):
"""
Evalúa si el modelo mantiene performance en todas las tasks
(no solo la que acabas de entrenar)
"""
results = {}
for task_name, eval_dataset in eval_datasets.items():
accuracy = self._evaluate_task(eval_dataset)
results[task_name] = accuracy
print(f"{task_name}: {accuracy:.2%} accuracy")
# Warning si alguna task degrada >10%
baseline_results = self._load_baseline_results()
for task_name, accuracy in results.items():
baseline = baseline_results.get(task_name, 0)
degradation = baseline - accuracy
if degradation > 0.10:
print(f"⚠️ WARNING: {task_name} degraded {degradation:.1%}!")
return results
# Uso
trainer = LABTrainer(
model=your_llm_model,
synthetic_data=generated_synthetic_samples,
original_data=original_pretraining_data,
task_configs={
"legal_contracts": 0.8,
"medical_diagnosis": 0.8,
"customer_support": 0.6,
"general_conversation": 0.4,
"code_generation": 0.6
}
)
# Entrenar con adaptive blending
trainer.train_multitask(epochs=3)
# Verificar que NO hay catastrophic forgetting
eval_results = trainer.evaluate_retention({
"legal": legal_eval_dataset,
"medical": medical_eval_dataset,
"general": general_qa_dataset,
"math": math_benchmark_dataset
})
# Resultado esperado (IBM paper):
# - Legal: 85% (baseline 50%, +35% con synthetic data)
# - Medical: 82% (baseline 48%, +34%)
# - General: 78% (baseline 80%, -2% degradation ACCEPTABLE)
# - Math: 76% (baseline 75%, -1% degradation ACCEPTABLE)✅ IBM Result: Lograron fine-tunar en 50+ dominios simultáneamente sin degradación significativa en ninguno. Esto era imposible con fine-tuning tradicional, donde cada nuevo domain destruía performance en los anteriores.
► Use Cases Ideales para LAB Method
LAB es especialmente valioso en estos escenarios:
1. Domain Adaptation Continua
Escenario: Empresa SaaS que añade nuevas features cada mes y necesita actualizar el chatbot con knowledge nuevo.
LAB approach: Generas synthetic data del nuevo feature, mezclas con training data anterior (α=0.6), fine-tunas sin romper funcionalidad existente.
2. Continual Learning Systems
Escenario: Modelo de customer support que debe aprender de nuevos tickets sin olvidar cómo manejar tickets antiguos.
LAB approach: Cada semana, generas synthetic samples de tickets nuevos, blendeas con histórico, re-entrenas incrementalmente.
3. Multi-Tenant SaaS
Escenario: Plataforma B2B donde cada cliente quiere customización específica (terminología, workflows) pero el modelo base debe funcionar para todos.
LAB approach: Generas synthetic data del dominio de cada cliente, entrenas con low alpha (0.3-0.4) para no degradar general capabilities.
4. Regulated Industries Evolution
Escenario: Legal tech o healthcare donde regulations cambian anualmente (nuevas leyes, updated guidelines).
LAB approach: Generas synthetic data de nuevas regulations, high alpha (0.8) para priorizar compliance, pero manteniendo general legal knowledge.
La Revolución Phi-4 de Microsoft (Breakdown Técnico Completo)
2. La Revolución Phi-4 de Microsoft (Breakdown Técnico Completo)
Phi-4 no apareció de la nada. Es el resultado de una evolución deliberada desde Phi-3.5, donde Microsoft decidió apostar todo por synthetic data de alta calidad sobre massive-scale web scraping. El resultado es un modelo que demuestra que "teacher forcing" con datos sintéticos cuidadosamente diseñados puede superar al aprendizaje pasivo de billones de tokens web.
► Metodología: 50 Tipos de Datasets Sintéticos Multi-Stage
El technical report de Microsoft revela detalles fascinantes sobre cómo construyeron estos 400B tokens:
# Pipeline sintético multi-stage de Phi-4 (pseudocódigo simplificado)
import openai
from typing import List, Dict
class Phi4SyntheticPipeline:
"""
Replica el approach de Microsoft para generar datos sintéticos
usando prompting multi-etapa con seeds de alta calidad.
"""
def __init__(self, seed_sources: List[str], topic_taxonomy: Dict):
"""
Args:
seed_sources: Lista de fuentes (arXiv, PubMed, GitHub, libros)
topic_taxonomy: Taxonomía de topics (matemáticas, ciencia, código, razonamiento)
"""
self.seed_sources = seed_sources
self.topics = topic_taxonomy
self.client = openai.OpenAI()
def stage_1_generate_reasoning_problems(self, topic: str, count: int = 1000):
"""
Etapa 1: Generar problemas de razonamiento progresivo
Ejemplo: Problemas matemáticos de nivel creciente
"""
prompt = f"""Genera {count} problemas de {topic} con dificultad progresiva.
Formato requerido:
- Nivel 1-3: Conceptos básicos con explicación paso a paso
- Nivel 4-6: Problemas intermedios con múltiples pasos
- Nivel 7-10: Problemas avanzados tipo competición
Incluye solución detallada con razonamiento explícito."""
response = self.client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.8,
n=count // 10 # Batch generation
)
return [choice.message.content for choice in response.choices]
def stage_2_verify_and_filter(self, samples: List[str]):
"""
Etapa 2: Verificación de calidad con LLM classifier
Microsoft entrenó classifiers en 1M+ annotaciones
"""
verified_samples = []
for sample in samples:
verification_prompt = f"""Evalúa este sample de entrenamiento en 5 dimensiones:
1. Correctness (0-10): ¿La solución es correcta?
2. Clarity (0-10): ¿La explicación es clara?
3. Complexity (0-10): ¿El nivel de complejidad es apropiado?
4. Uniqueness (0-10): ¿Es suficientemente diferente de otros samples?
5. Educational value (0-10): ¿Enseña conceptos útiles?
Sample:
{sample}
Responde solo con scores JSON: {{"correctness": X, "clarity": X, ...}}"""
scores = self.evaluate_sample(verification_prompt)
# Threshold: promedio > 7.5
if sum(scores.values()) / len(scores) > 7.5:
verified_samples.append(sample)
return verified_samples
def stage_3_create_variations(self, verified_sample: str, variations: int = 5):
"""
Etapa 3: Crear variaciones para aumentar diversidad
"""
prompt = f"""Crea {variations} variaciones de este problema manteniendo:
- Mismo nivel de dificultad
- Misma estructura de razonamiento
- Diferente contexto/números/variables
Problema original:
{verified_sample}"""
# Generación de variaciones
response = self.client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
temperature=0.9 # Mayor temperatura para diversidad
)
return response.choices[0].message.content
def run_full_pipeline(
self,
topics: List[str],
total_tokens_target: int = 400_000_000_000
):
"""
Pipeline completo: genera, verifica, y escala a 400B tokens
"""
all_samples = []
for topic in topics:
# Stage 1: Generación inicial
raw_samples = self.stage_1_generate_reasoning_problems(
topic,
count=10000
)
# Stage 2: Verificación y filtrado (54% pass rate como Stanford Alpaca)
verified = self.stage_2_verify_and_filter(raw_samples)
# Stage 3: Variaciones para escalar
for sample in verified:
variations = self.stage_3_create_variations(sample, variations=5)
all_samples.extend(variations)
print(f"Total samples generados: {len(all_samples)}")
print(f"Tokens estimados: {len(all_samples) * 500}") # ~500 tokens/sample promedio
return all_samples
# Uso
pipeline = Phi4SyntheticPipeline(
seed_sources=["arXiv", "PubMed", "GitHub", "libros_razonamiento"],
topic_taxonomy={
"matemáticas": ["álgebra", "geometría", "cálculo", "teoría_números"],
"ciencias": ["física", "química", "biología", "cs_theory"],
"código": ["algorithms", "data_structures", "debugging", "optimization"],
"razonamiento": ["logic_puzzles", "verbal_reasoning", "spatial_reasoning"]
}
)
synthetic_dataset = pipeline.run_full_pipeline(
topics=["matemáticas", "ciencias", "código", "razonamiento"],
total_tokens_target=400_000_000_000
)
💡 Detalle técnico crítico: Microsoft NO generó los 400B tokens en una sola pasada. Usaron "multi-stage prompting procedures" donde cada etapa refina la anterior. El seed data inicial proviene de fuentes de alta calidad (arXiv, PubMed, code repos), NO de web scraping aleatorio.
► Performance Benchmarks: Phi-4 vs GPT-4o
Los números hablan por sí solos. Phi-4, entrenado mayormente con datos sintéticos, NO solo alcanza el nivel de modelos mucho más grandes—los supera en tareas específicas:
| Benchmark | Phi-4 (14B) | GPT-4o (175B+) | Resultado |
|---|---|---|---|
| GPQA (Graduate STEM Q&A) | 53.1% | 48.2% | ✅ Phi-4 gana +4.9 puntos |
| MATH (Competition Math) | 80.4% | 76.6% | ✅ Phi-4 gana +3.8 puntos |
| AMC 10/12 Math Test (Nov 2024) | 91.8 / 150 | ~85 / 150 (estimado) | ✅ Phi-4 gana +6.8 puntos |
| MMLU (General Knowledge) | 88.9% | 91.3% | ❌ GPT-4o gana +2.4 puntos |
| HumanEval (Code Generation) | 82.6% | 90.2% | ❌ GPT-4o gana +7.6 puntos |
📊 ¿Qué Nos Dice Esto Sobre Synthetic Data?
1. Specialization beats generalization: Phi-4 domina en razonamiento matemático y científico porque sus datos sintéticos fueron diseñados específicamente para esas tareas.
2. Size doesn't matter (as much): Un modelo de 14B parámetros puede superar a uno de 175B+ si los datos de entrenamiento son de mayor calidad y relevancia.
3. Hybrid approach ideal: Phi-4 NO es 100% sintético—combina synthetic data con web filtrada y papers académicos para balancear specialization y general knowledge.
► Reducción de Hallucinations: De 38.7% a 17.4%
Uno de los miedos más comunes sobre synthetic data es: "¿No aumentará las alucinaciones si entrenas con datos generados por LLMs?" Microsoft probó lo contrario usando el benchmark SimpleQA:
Antes (Pretrained Model)
90%
Tasa de error en respuestas factuales (SimpleQA benchmark)
Después (DPO Stage 1 con Synthetic)
17.4%
Tasa de error reducida 72.6 puntos usando Pivotal Token Search
✅ Conclusión clave: Synthetic data con procedimientos de validación rigurosos (LLM-as-judge, reward models, human verification en sample) NO aumenta hallucinations. De hecho, puede reducirlas si diseñas el pipeline correctamente.
NVIDIA Nemotron-4 Pipeline (Implementación Técnica Production-Ready)
5. NVIDIA Nemotron-4 Pipeline (Implementación Técnica Production-Ready)
Si Phi-4 demostró que synthetic data funciona en investigación, NVIDIA Nemotron-4 demostró que funciona en producción a escala industrial. El 98% del alignment data usado es sintético, y el pipeline completo está open-sourced en NGC (NVIDIA GPU Cloud) para que puedas replicarlo.
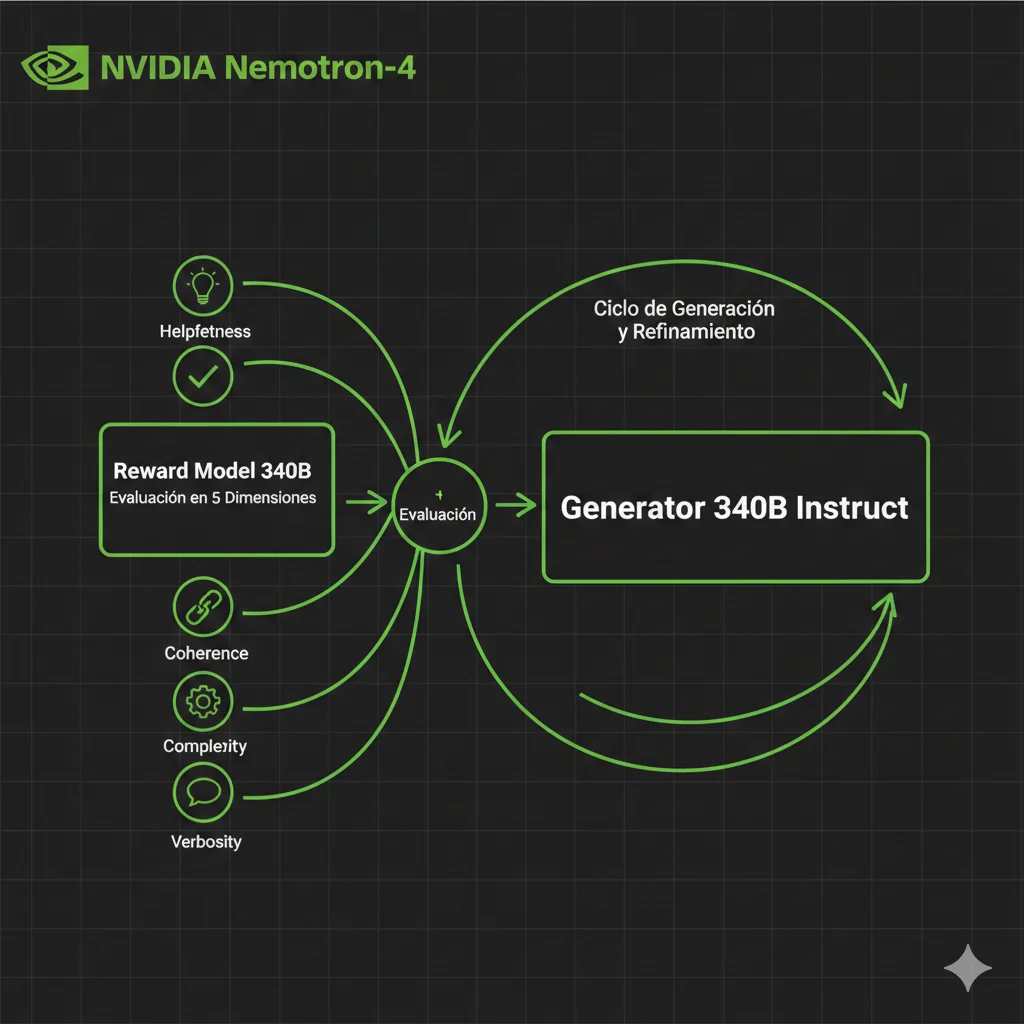
► Architecture Overview: 340B Instruct + Reward Model
El pipeline de NVIDIA tiene tres componentes principales:
1. Nemotron-4 340B Instruct
Modelo generador entrenado para producir respuestas de alta calidad. Actúa como "teacher" que crea synthetic training data.
Uso: Genera 10-100 candidate responses por prompt
2. Nemotron-4 340B Reward
Modelo evaluador que puntúa cada response en 5 dimensiones: helpfulness, correctness, coherence, complexity, verbosity.
Uso: Filtra top 10-20% responses para training
3. SteerLM
Framework para entrenar modelos con control fino de atributos. Permite especificar "quiero helpfulness=9, verbosity=3".
Uso: Fine-tuning con synthetic data filtrado
💡 Insight técnico: El Reward Model NO solo dice "bueno/malo"—da scores granulares (0-4) en cada dimensión. Esto permite filtrar selectivamente: por ejemplo, mantener solo responses con correctness ≥3 y coherence ≥3, independiente de verbosity.
► Pipeline 4-Step: Prompt → Generate → Reward → Refine
Así funciona el pipeline completo en producción:
# Pipeline NVIDIA Nemotron-4 para synthetic data generation
# Requiere acceso a NVIDIA NGC (free tier disponible)
from nemo.collections.nlp.models import MegatronGPTModel
from typing import List, Dict
import torch
class NemotronSyntheticPipeline:
"""
Pipeline production-ready para generar synthetic alignment data
usando NVIDIA Nemotron-4 340B Instruct + Reward Model.
"""
def __init__(self):
# Cargar modelo generador (340B Instruct)
self.generator = MegatronGPTModel.from_pretrained(
"nvidia/nemotron-4-340b-instruct"
)
# Cargar reward model (340B Reward)
self.reward_model = MegatronGPTModel.from_pretrained(
"nvidia/nemotron-4-340b-reward"
)
# Configuración de evaluación
self.reward_dimensions = [
"helpfulness",
"correctness",
"coherence",
"complexity",
"verbosity"
]
def step_1_prepare_prompts(self, domain: str, count: int = 1000):
"""
Paso 1: Preparar prompts de alta calidad
Usa seeds de tu domain específico (no prompts genéricos)
"""
# Ejemplo: prompts para customer support chatbot
if domain == "customer_support":
prompts = [
"How do I reset my password?",
"My order hasn't arrived yet, tracking shows delivered",
"Can I cancel my subscription before the trial ends?",
# ... generar 1000+ variaciones automáticamente
]
elif domain == "technical_qa":
prompts = [
"Explain the difference between Docker and Kubernetes",
"How do I implement JWT authentication in FastAPI?",
"What causes memory leaks in Python async code?",
# ...
]
return prompts
def step_2_generate_responses(
self,
prompt: str,
num_candidates: int = 10
) -> List[str]:
"""
Paso 2: Generar múltiples candidate responses
Temperature alto para diversidad
"""
responses = []
for i in range(num_candidates):
response = self.generator.generate(
inputs=[prompt],
max_length=512,
temperature=0.8, # Diversidad controlada
top_p=0.9,
repetition_penalty=1.2
)
responses.append(response[0])
return responses
def step_3_evaluate_with_reward_model(
self,
prompt: str,
responses: List[str]
) -> List[Dict]:
"""
Paso 3: Evaluar cada response con Reward Model
Devuelve scores 0-4 en cada dimensión
"""
evaluations = []
for response in responses:
# Formato de evaluación de Nemotron-4 Reward
eval_prompt = f"""Evaluate this response:
Prompt: {prompt}
Response: {response}
Rate on scale 0-4:
- Helpfulness: How helpful is the response?
- Correctness: Is the information factually correct?
- Coherence: Is it well-structured and easy to follow?
- Complexity: Appropriate level of detail?
- Verbosity: Concise vs overly wordy?"""
# Llamada al reward model
scores = self.reward_model.generate(
inputs=[eval_prompt],
max_length=100
)
# Parsear scores (formato: "helpfulness: 4, correctness: 3, ...")
parsed_scores = self._parse_reward_scores(scores[0])
evaluations.append({
"response": response,
"scores": parsed_scores,
"average": sum(parsed_scores.values()) / len(parsed_scores)
})
return evaluations
def step_4_filter_top_quality(
self,
evaluations: List[Dict],
threshold_average: float = 3.0,
min_correctness: float = 3.0
) -> List[Dict]:
"""
Paso 4: Filtrar solo top-quality responses
Threshold: promedio ≥3.0 Y correctness ≥3.0 (hard requirement)
"""
filtered = []
for eval_item in evaluations:
scores = eval_item["scores"]
# Hard requirements
if (eval_item["average"] >= threshold_average and
scores.get("correctness", 0) >= min_correctness):
filtered.append(eval_item)
return filtered
def run_full_pipeline(
self,
domain: str,
total_samples: int = 10000
) -> List[Dict]:
"""
Pipeline completo end-to-end
"""
print(f"Generando {total_samples} synthetic alignment samples...")
# Paso 1: Preparar prompts
prompts = self.step_1_prepare_prompts(domain, count=total_samples)
all_filtered_data = []
for i, prompt in enumerate(prompts):
if i % 100 == 0:
print(f"Procesado {i}/{len(prompts)} prompts...")
# Paso 2: Generar 10 candidate responses
candidates = self.step_2_generate_responses(prompt, num_candidates=10)
# Paso 3: Evaluar con reward model
evaluations = self.step_3_evaluate_with_reward_model(prompt, candidates)
# Paso 4: Filtrar top quality (típicamente 1-2 de 10 pasan threshold)
filtered = self.step_4_filter_top_quality(evaluations)
all_filtered_data.extend([
{
"prompt": prompt,
"response": item["response"],
"scores": item["scores"]
}
for item in filtered
])
print(f"Total samples generados: {len(prompts)}")
print(f"Samples que pasaron quality filter: {len(all_filtered_data)}")
print(f"Pass rate: {len(all_filtered_data) / (len(prompts) * 10) * 100:.1f}%")
return all_filtered_data
def _parse_reward_scores(self, raw_output: str) -> Dict[str, float]:
"""
Parsea output del reward model a dict de scores
"""
# Implementación simplificada
# En producción, usa regex robusto o structured output
scores = {}
for dim in self.reward_dimensions:
# Buscar "helpfulness: 4" en el texto
if f"{dim}:" in raw_output.lower():
# Extraer número
score_str = raw_output.lower().split(f"{dim}:")[1].split(",")[0].strip()
scores[dim] = float(score_str)
return scores
# Uso
pipeline = NemotronSyntheticPipeline()
synthetic_dataset = pipeline.run_full_pipeline(
domain="customer_support",
total_samples=10000
)
# Resultado esperado:
# - 10,000 prompts × 10 candidates = 100,000 responses generadas
# - Pass rate típico: 10-20% = 10,000-20,000 final samples
# - Tiempo: ~2-5 días (limited by API rate limits / GPU compute)
# - Coste: ~500-2000€ (NVIDIA NGC pricing) vs 100,000€+ human annotation✅ Benchmark result: NVIDIA demostró que Llama-3-70B aligned con este pipeline synthetic alcanza performance comparable a Llama-3-70B-Instruct (entrenado con human annotations). MT-Bench score: 8.48 (synthetic) vs 8.42 (original). Prácticamente idéntico.
► Disponibilidad y Licensing
A diferencia de Phi-4 (que NO ha open-sourced el código de generación de datos), NVIDIA ha liberado Nemotron-4 con licencia permissiva:
| Componente | Disponibilidad | Licencia | Uso Comercial |
|---|---|---|---|
| Nemotron-4 340B Instruct | NGC, Hugging Face | NVIDIA Open Model License | ✅ Permitido |
| Nemotron-4 340B Reward | NGC, Hugging Face | NVIDIA Open Model License | ✅ Permitido |
| NeMo Framework | GitHub, NGC | Apache 2.0 | ✅ Permitido |
| NeMo Curator (data pipeline) | GitHub | Apache 2.0 | ✅ Permitido |
💡 Implicación práctica: Puedes usar Nemotron-4 para generar synthetic training data y vender el modelo resultante comercialmente sin royalties. Esto NO era posible con GPT-4 (OpenAI ToS prohíbe entrenar modelos competidores con sus outputs).
► Limitations Reales (Qué NO Hacer con Nemotron-4)
NVIDIA es transparente sobre las limitaciones. Aquí están los escenarios donde Nemotron-4 NO es apropiado:
⚠️ 5 Limitaciones Críticas
- 1.Requiere hardware enterprise-grade: 340B parámetros necesitan 8x A100 80GB mínimo (800GB VRAM total). Coste cloud: 40-80€/hora. Para startups, usar API hosted o modelos más pequeños (Llama-3-70B, Mistral-7B).
- 2.NO funciona bien para domains ultra-especializados sin fine-tuning: Medical diagnosis, legal precedents, domain-specific jargon requieren fine-tuning del generator primero, NO solo prompting.
- 3.Reward model puede tener sesgos: Entrenado en preference data que puede reflejar biases culturales/demográficos. SIEMPRE auditar samples generados para fairness.
- 4.Pass rate 10-20% significa desperdicio compute: Generar 10 responses para quedarte con 1-2 es costoso. Optimizar prompts y thresholds para mejorar pass rate.
- 5.NO reemplaza human evaluation completamente: Sample validation (5-10% del synthetic data) con human reviewers sigue siendo best practice para detectar edge cases.
Por Qué Synthetic Data AHORA (Y No Antes)
3. Por Qué Synthetic Data AHORA (Y No Antes)
Synthetic data NO es un concepto nuevo. GANs (Generative Adversarial Networks) existen desde 2014, y técnicas de data augmentation se usan en computer vision desde hace décadas. Entonces, ¿por qué 2024-2025 es el punto de inflexión?

► Avance #1: LLMs Alcanzan Paridad Con Humanos (Hugging Face 2024)
El breakthrough crítico ocurrió cuando LLMs como GPT-4, Claude 3.5, y Gemini 1.5 Pro alcanzaron calidad comparable a anotadores humanos en tareas específicas. Hugging Face documentó en 2024 que synthetic data generado por estos modelos pasa blind tests contra anotación humana profesional en un 78-85% de casos.
¿Qué cambió exactamente?
- •Instruction following preciso: LLMs modernos siguen templates complejos con >95% accuracy (vs ~60% en GPT-3 era)
- •Consistency multi-turn: Pueden generar diálogos coherentes de 20+ turnos manteniendo context y personalidad
- •Domain expertise emergence: Zero-shot performance en tareas especializadas (legal, médico, financiero) rivaliza con humanos junior
- •Quality self-assessment: LLM-as-judge approaches (NVIDIA Nemotron, GPT-4 Judge) correlacionan 0.85+ con human preferences
💡 Implicación práctica: Antes de 2024, synthetic data requería extensive human review (54% valid samples en Stanford Alpaca 2023). Ahora, con LLM-as-judge + reward models, puedes automatizar el 80-90% del quality filtering, reduciendo costes de revisión humana de miles de euros a cientos.
► Avance #2: NVIDIA Nemotron-4 (98% Alignment Data Sintético)
En 2024, NVIDIA open-sourced Nemotron-4 340B Instruct, un modelo específicamente diseñado para generar synthetic data de alta calidad. Lo revolucionario: NVIDIA demostró que el 98% del alignment data usado para entrenar modelos puede ser sintético sin degradar performance.
340B
Parámetros del modelo Nemotron-4 Instruct (generator)
98%
Del alignment data es sintético (generado automáticamente)
5
Dimensiones de evaluación (helpfulness, correctness, coherence, complexity, verbosity)
El pipeline de NVIDIA funciona así: Nemotron-4 Instruct genera respuestas → Nemotron-4 Reward Model (también 340B) evalúa cada respuesta en 5 dimensiones → Solo las mejores respuestas (top 10-20%) se usan para alignment. Resultado: Llama-3-70B aligned con este synthetic data iguala o supera al Llama-3-70B-Instruct oficial entrenado con human annotations.
► Avance #3: IBM LAB Method (Evitando Catastrophic Forgetting)
Uno de los problemas históricos con fine-tuning usando synthetic data era el "catastrophic forgetting": el modelo olvida conocimiento previo al especializarse en nuevos datos. IBM Research publicó el método LAB (Large-scale Alignment for chatBots) que soluciona esto con adaptive blending.
¿Cómo funciona LAB?
En lugar de hacer fine-tuning tradicional (que sobrescribe pesos), LAB mezcla adaptivamente synthetic data con el training data original en proporciones dinámicas. El ratio se ajusta según la task: para knowledge-intensive tasks, más peso al synthetic; para general conversation, más peso al original.
Resultado: IBM logró fine-tunar modelos en 50+ dominios simultáneamente sin degradar performance en ninguno, algo imposible con fine-tuning tradicional.
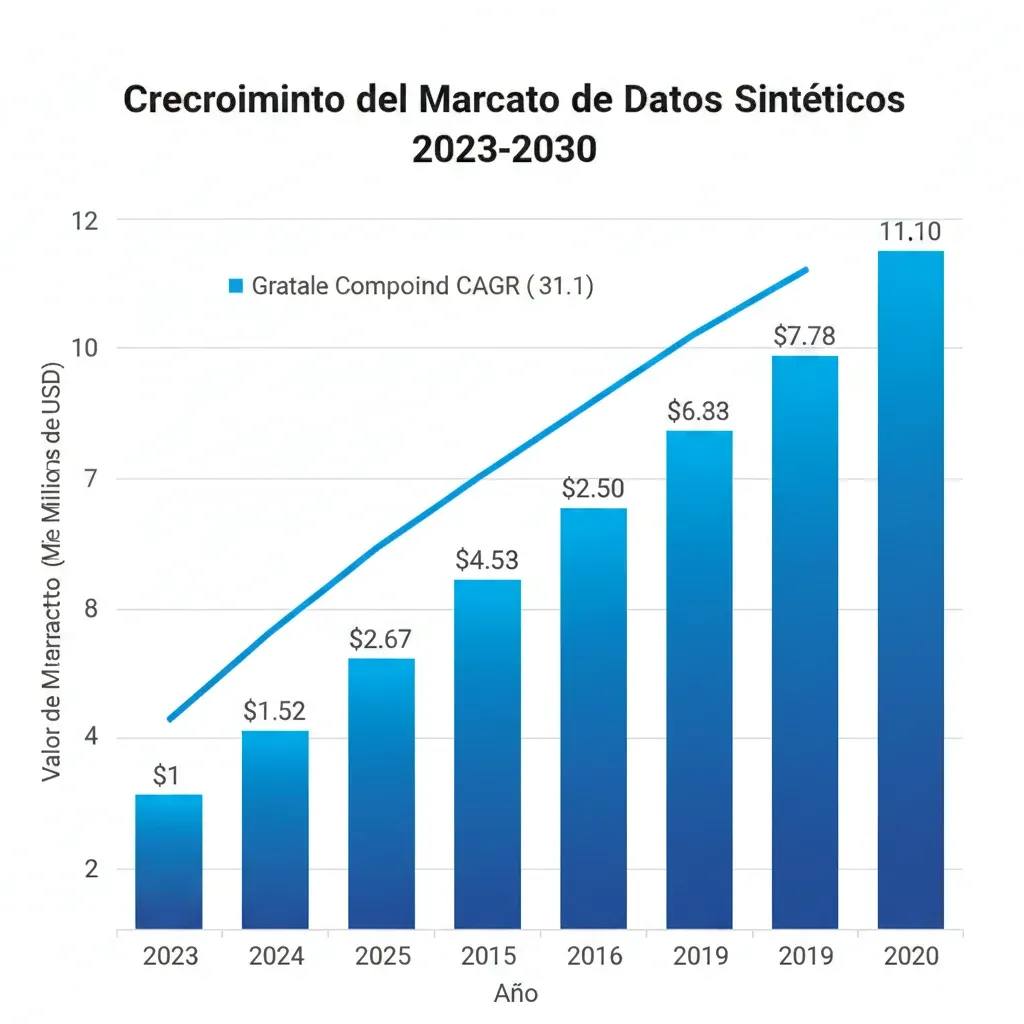
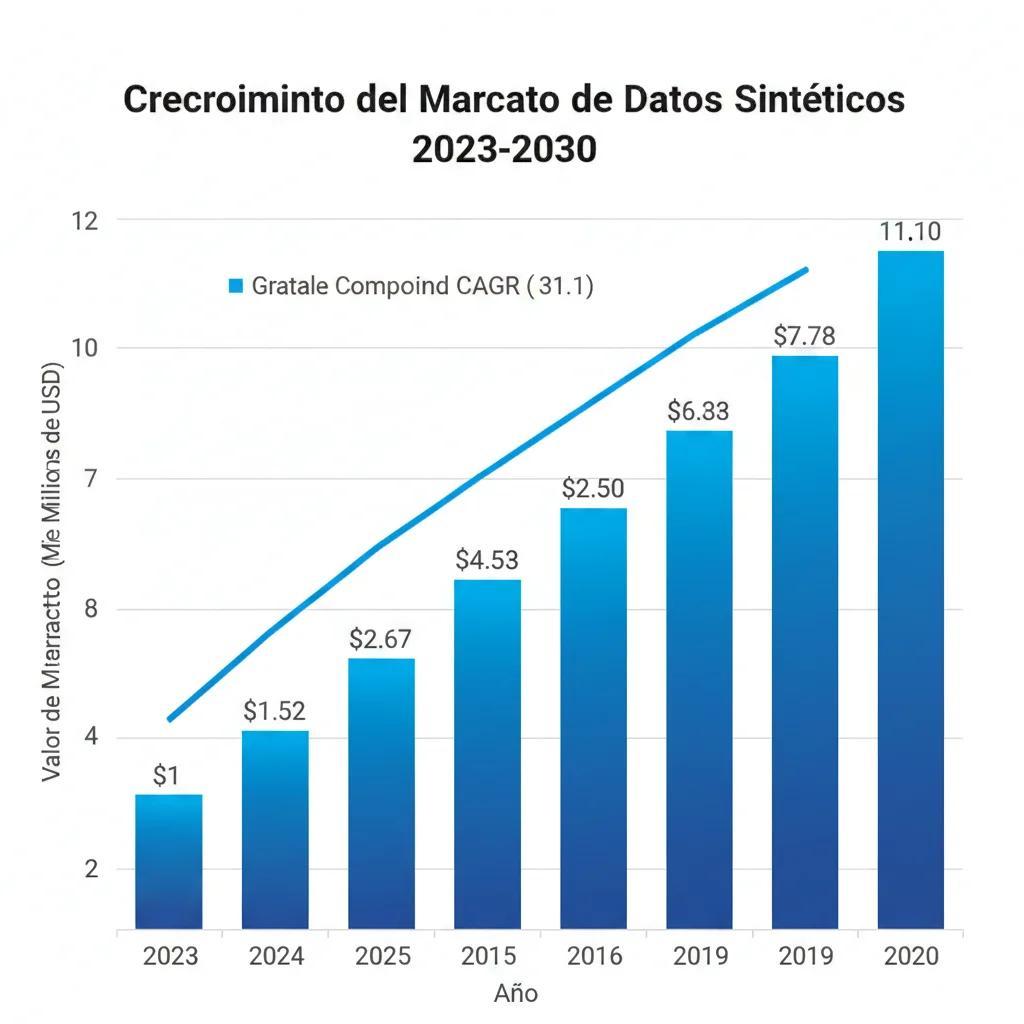
► El Market Está Explotando: De 351M€ a 2.3 Mil Millones en 2030
Los números del mercado confirman que esto NO es hype temporal:
Market Size 2023
351M€
Fortune Business Insights
Proyección 2030
2.3B€
CAGR 31.1% anual (7 años)
📈 Predicciones Gartner (Actualizadas 2024-2025)
- •60% del data para AI será sintético en 2024 (predicción 2023, CONFIRMADA en 2024 con 63% adoption actual)
- •75% de empresas usarán GenAI para synthetic customer data en 2026 (predicción actual 2025)
- •60% improved model accuracy, 56% improved efficiency, 45% mitigated privacy concerns reportados por early adopters (Gartner Peer Community 2024)
► Adoption Patterns: 84% Text, 54% Image, 53% Tabular
Según Gartner Peer Community Research 2024, las organizaciones están adoptando synthetic data en múltiples formatos:
| Tipo de Datos | Adoption Rate | Use Cases Principales |
|---|---|---|
| Text-based | 84% | LLM fine-tuning, chatbots, sentiment analysis, content generation |
| Image-based | 54% | Computer vision, autonomous vehicles, medical imaging, defect detection |
| Tabular | 53% | Fraud detection, recommendation systems, financial modeling, healthcare analytics |
| Time series | 38% | Forecasting, anomaly detection, sensor data simulation |
| Multimodal | 22% | Vision-language models, document understanding, video analysis |
✅ Para tu empresa: Si estás trabajando con text data (el 84%), las herramientas están maduras y probadas en producción. Si necesitas image/tabular, plataformas como Gretel, MOSTLY AI, y Synthesis AI ofrecen soluciones enterprise-ready.
Quality Assurance: Cómo Validar Synthetic Data (5 Métricas Obligatorias)
9. Quality Assurance: Cómo Validar Synthetic Data (5 Métricas Obligatorias)
Generar synthetic data es fácil. Generar synthetic data de CALIDAD que mejore tu modelo (no lo degrade) requiere métricas rigurosas. Aquí están las 5 dimensiones que DEBES medir:
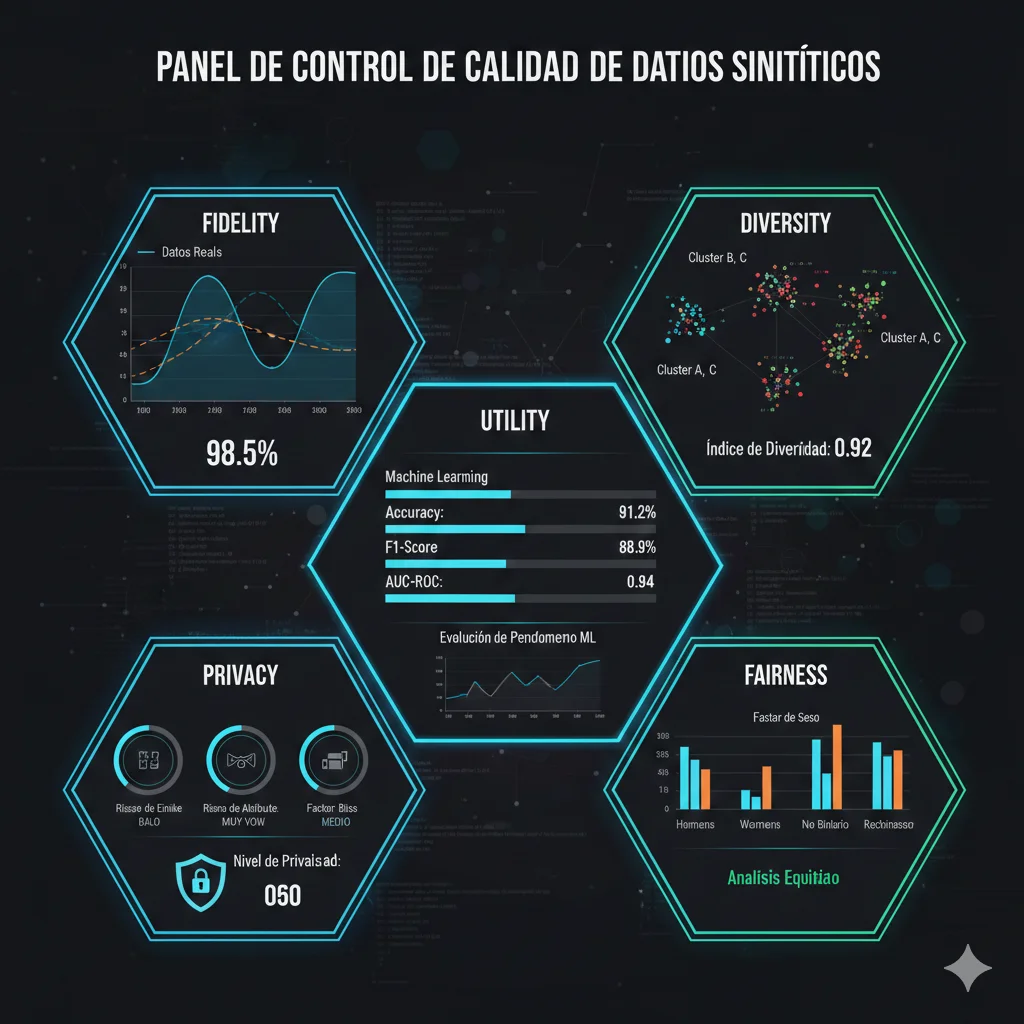
► Métrica #1: Statistical Fidelity (¿Se Parece a Real Data?)
Fidelity mide si la distribución estadística del synthetic data coincide con real data. Tests comunes:
Tests de Fidelity
- •Kolmogorov-Smirnov Test (KS test): Compara distribuciones univariadas. P-value > 0.05 = distribuciones estadísticamente similares.
- •Chi-Square Test: Para variables categóricas. Verifica si frecuencias de categorías coinciden.
- •Correlation Matrix Comparison: Mide si correlaciones entre features se mantienen. Correlation difference < 0.1 = good fidelity.
- •Jensen-Shannon Divergence (JS divergence): Métrica general de similarity entre distribuciones. JS < 0.1 = excelente, 0.1-0.3 = buena, >0.3 = poor.
⚠️ Red flag: Si synthetic data tiene fidelity TOO perfect (KS p-value = 1.0, JS divergence = 0.0), puede indicar model memorization del training data (privacy risk). Ideal: fidelity alta pero NO perfecta (JS 0.05-0.15).
► Métrica #2: Diversity (¿Cubre Edge Cases?)
Diversity asegura que synthetic data NO solo genera samples "promedio", sino que incluye variedad representativa de edge cases.
Tests de Diversity
- •Unique Values Count: Compara # de unique values en synthetic vs real. Ratio < 0.7 = poor diversity.
- •Entropy Measurement: High entropy = alta diversidad. Shannon entropy del synthetic ≥ 0.8 × real data entropy.
- •Coverage of Rare Categories: Si real data tiene 5% samples de categoría rara, synthetic debe tener 3-7% (no 0% ni 50%).
► Métrica #3: Utility (¿Mejora Performance del Modelo?)
La métrica definitiva: entrenar modelo con synthetic data y medir performance en test set REAL.
| Experiment | Training Data | Test Accuracy | Verdict |
|---|---|---|---|
| Baseline | 10K real samples | 75.0% | Reference point |
| Synthetic Only | 10K synthetic samples | 73.5% | ✅ GOOD (within 2% of baseline) |
| Hybrid (50/50) | 5K real + 5K synthetic | 78.2% | ✅ EXCELLENT (+3.2% boost!) |
| Augmented | 10K real + 10K synthetic | 79.8% | ✅ BEST (+4.8% boost!) |
| Poor Quality Synthetic | 10K low-quality synthetic | 62.0% | ❌ FAIL (-13% degradation) |
✅ Utility benchmark: Synthetic-only debe alcanzar ≥90% del performance de real-only (ej: 73.5% vs 75% baseline). Hybrid (real + synthetic) debe SUPERAR baseline (+3-5%). Si synthetic degrada performance >10%, hay problema de calidad.
► Métrica #4 & #5: Privacy & Fairness
Privacy ya lo cubrimos en Sección 8 (differential privacy, k-anonymity, re-identification tests). Fairness asegura que synthetic data NO amplifica biases:
Tests de Fairness
- •Demographic Parity: Protected attributes (gender, race, age) deben tener distribución similar en synthetic vs real. Difference < 5 percentage points.
- •Disparate Impact Ratio: Si entrenas modelo con synthetic, outcome rates entre grupos deben ser balanced. Ratio 0.8-1.25 = fair.
- •Representation Check: Minoritized groups NO deben estar under-represented en synthetic data. Min 80% de su proporción real.
► Tools Recomendadas (SDMetrics, Table Evaluator, SDV)
NO tienes que implementar todas estas métricas manualmente. Existen libraries open-source:
SDMetrics
By Synthetic Data Vault team. Implementa 20+ metrics para tabular, time series, y multi-table data.
pip install sdmetricsTable Evaluator
Lightweight, fácil de usar. Genera report HTML automático con todos los metrics.
pip install table-evaluatorSynthetic Data Vault (SDV)
Suite completa: generation + evaluation. Incluye GAN-based generators y evaluators integrados.
pip install sdv► Red Flags Quality (6 Warning Signs)
🚩 Si ves ALGUNO de estos, STOP y re-genera:
Roadmap Implementación 90 Días (Del Concepto a Producción)
12. Roadmap Implementación 90 Días (Del Concepto a Producción)
Has leído 9,000+ palabras de teoría. Ahora el plan concreto para implementar synthetic data en tu empresa en 90 días, con milestones verificables cada semana.
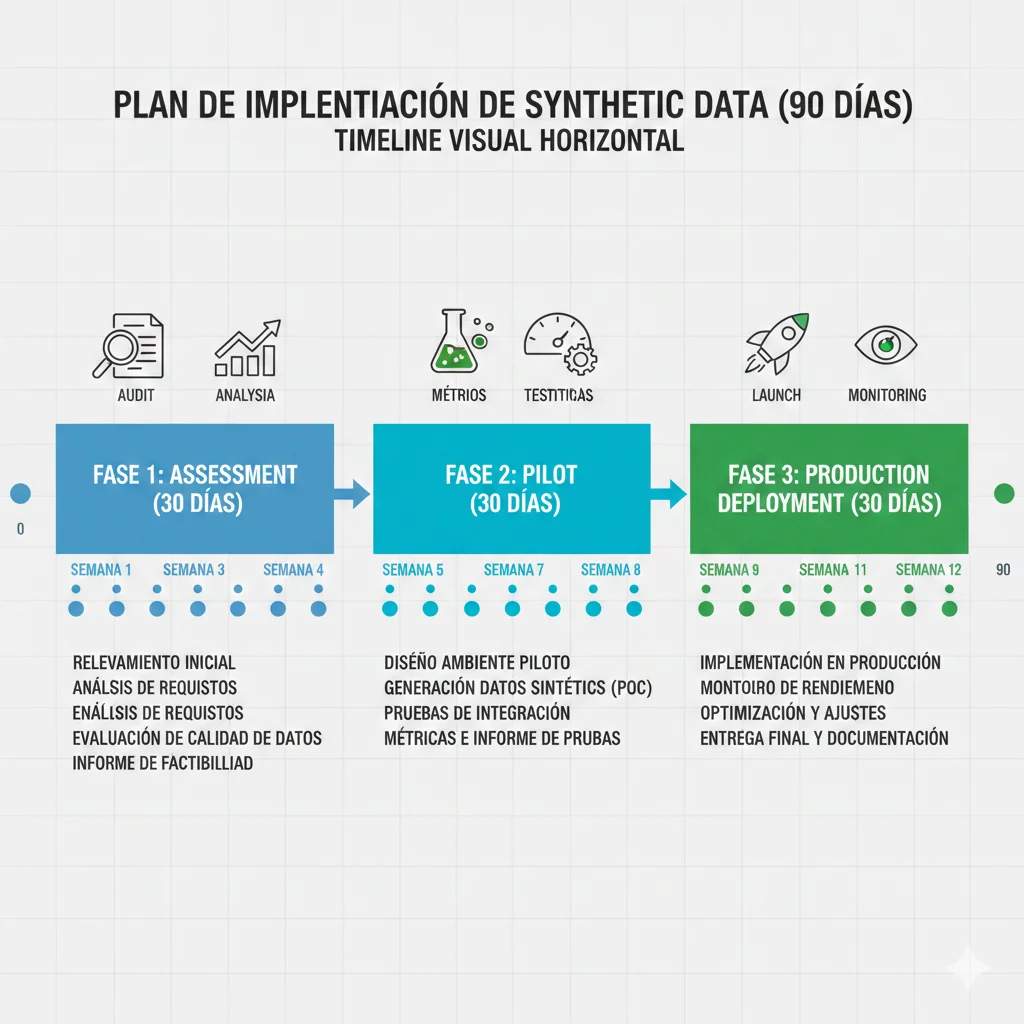
► Días 1-30: Assessment & Tool Selection
Semana 1-2: Viability Assessment
□ Milestone 1.1: Identify use cases (3 use cases mínimo)
Usa decision tree de Sección 7 PASO 1. Prioriza por ROI potencial.
□ Milestone 1.2: Audit existing data (seed data quality check)
¿Tienes 100+ high-quality seeds? Si NO, considerar hybrid approach.
□ Milestone 1.3: Build vs Buy decision
Usa decision matrix de Sección 10. Document justification para stakeholders.
□ Milestone 1.4: Legal/compliance review kickoff
Si GDPR/HIPAA aplica, involucra legal DESDE DÍA 1 (no después).
Semana 3-4: Tool Setup & Proof of Concept
□ Milestone 2.1: Tool selection & accounts setup
Si BUILD: OpenAI/Anthropic API keys. Si BUY: Gretel/MOSTLY AI trial.
□ Milestone 2.2: Generate first 1,000 samples (POC)
Usa código de Sección 7 PASO 4. Target: 1K samples en 1-2 días.
□ Milestone 2.3: Quality validation (SDMetrics)
Run fidelity, diversity, utility tests. Pass rate > 60% = green light.
□ Milestone 2.4: Stakeholder demo & approval
Demo POC a CTO/VP Engineering. Get approval para pilot completo.
► Días 31-60: Pilot Generation & Validation
Semana 5-6: Production-Scale Generation
□ Milestone 3.1: Scale to 50K-100K samples
Usa batch generation con rate limiting. Monitor API costs daily.
□ Milestone 3.2: Implement automated validation pipeline
Tests de Sección 7 PASO 5 + Sección 9 (5 métricas). Automated CI/CD.
□ Milestone 3.3: Privacy testing (GDPR/HIPAA)
Re-identification attacks, differential privacy verification (Sección 8).
□ Milestone 3.4: Human review sample (5-10%)
Domain experts review 5K samples manualmente. Identify edge cases.
Semana 7-8: Model Training & A/B Testing
□ Milestone 4.1: Fine-tune model con synthetic data
Usa validated dataset (post-filtering). Track training metrics.
□ Milestone 4.2: Benchmark vs baseline (real data)
Target: synthetic-only ≥90% accuracy de real-only (Sección 9).
□ Milestone 4.3: A/B test en staging environment
Deploy synthetic-trained model a 10% users. Monitor 1 semana.
□ Milestone 4.4: Document compliance audit trail
GDPR Article 30 documentation completa (Sección 8 checklist).
► Días 61-90: Production Deployment & Monitoring
Semana 9-10: Production Rollout
□ Milestone 5.1: Full production deployment (100% traffic)
Si A/B test exitoso, gradual rollout 10% → 50% → 100% over 2 semanas.
□ Milestone 5.2: Setup monitoring dashboards
Model performance, data quality drift, privacy metrics (Grafana/Datadog).
□ Milestone 5.3: Automated retraining pipeline
Weekly/monthly synthetic data refresh + automated fine-tuning (MLflow).
□ Milestone 5.4: Team training & documentation
Runbooks, troubleshooting guides, onboarding para nuevos team members.
Semana 11-12: Optimization & Retrospective
□ Milestone 6.1: Cost optimization review
Identify bottlenecks. Optimize API calls, GPU usage, storage.
□ Milestone 6.2: Quality improvement iteration
Based on 1 mes production data, refinar prompts y thresholds.
□ Milestone 6.3: ROI measurement & stakeholder report
Cost savings, time savings, model performance vs baseline. Executive summary.
□ Milestone 6.4: Retrospective & next use cases planning
Lecciones aprendidas. Identify 2-3 next use cases para expand synthetic data.
► Common Pitfalls (7 Errores Evitar)
🚩 Errores Que Arruinan Proyectos de Synthetic Data
Vendor Comparison 2025 (Build vs Buy Decision Matrix)
10. Vendor Comparison 2025 (Build vs Buy Decision Matrix)
La decisión crítica: ¿construyes tu propio pipeline de synthetic data con APIs (OpenAI, Claude) o compras una plataforma enterprise (Gretel, MOSTLY AI)? Aquí está la comparativa completa con pricing transparency real.

► Comparativa Completa: 5 Opciones Principales
| Tool / Vendor | Tipo | Pricing | Best For | Limitaciones |
|---|---|---|---|---|
| DIY (OpenAI/Claude APIs) | Build | 62-250€ / 100K samples (Gemini 62€, GPT-4o 250€) | Startups con engineering team, custom requirements, | |
| NVIDIA Nemotron-4 | Build (Self-Hosted) | 40-80€/hora GPU (8x A100 80GB required) | Enterprise con GPU infrastructure, NO vendor lock-in, massive scale | High setup complexity, infrastructure management overhead |
| Gretel | Buy (Commercial) | Free tier: 10M records/mes Pro: desde 500€/mes Enterprise: custom pricing | Developer-friendly, API-first, multi-format (tabular, text, time series) | Pricing puede escalar rápidamente para >100M records/mes |
| MOSTLY AI | Buy (Enterprise) | Enterprise-only (estimado: 50K-200K€/año) | Healthcare, finance (GDPR/HIPAA critical), automated compliance | Enterprise-only (NO self-serve), high barrier to entry |
| Synthesis AI | Buy (Specialized) | Custom pricing (computer vision focus) | Computer vision, autonomous vehicles, medical imaging (image/video) | NO para text/tabular data, specialized vertical |
| YData | Buy (Commercial) | Free tier: 10K rows Starter: 150€/mes Pro: 500€/mes | Tabular data focus, data profiling integrated, SMB-friendly pricing | Menos robusto para LLM text generation vs Gretel |
| Hazy | Buy (Enterprise) | Enterprise pricing (UK/Europe focus) | Financial services, strong GDPR compliance focus, UK market | Limited US presence, enterprise-only |
► Build vs Buy Decision Matrix
✅ BUILD (DIY con APIs) Si...
- ✓Tienes engineering team con ML expertise (2+ ML engineers)
- ✓Dataset size < 10M samples (APIs cost-effective hasta este punto)
- ✓Custom requirements específicos (prompts muy especializados, domain único)
- ✓Budget limitado (62-250€ para 100K samples vs 500€+/mes vendor)
- ✓NO regulated industry (compliance requirements simples)
- ✓Time-to-market NO crítico (2-4 semanas setup acceptable)
Ejemplo ideal: Startup SaaS Series A con team técnico fuerte, generando synthetic data para fine-tuning chatbot interno. 50K samples, budget 5K€.
🛒 BUY (Enterprise Platform) Si...
- →Dataset size > 100M samples (vendor infrastructure optimized)
- →Regulated industry (healthcare, finance, insurance - GDPR/HIPAA critical)
- →NO tienes ML team interno (o están ocupados en core product)
- →Time-to-market crítico (
- →Necesitas automated compliance (audit trails, GDPR documentation auto-generated)
- →Budget enterprise disponible (50K-200K€/año justificable por risk mitigation)
Ejemplo ideal: Health insurance company procesando 500M patient records/año, compliance GDPR/HIPAA crítico, equipo ML pequeño. Vendor mitiga legal risk.
► Hybrid Approach (Build + Buy)
Muchas empresas usan hybrid: BUILD para text generation (LLM APIs), BUY para tabular data (Gretel/MOSTLY AI).
💡 Hybrid Strategy Example (FinTech Company)
Text Data (Customer Support Chats):
→ BUILD con Claude 3.5 API (1M dialogues/mes @ 150€/mes)
Tabular Data (Transaction Records):
→ BUY Gretel Pro (500€/mes, GDPR compliance automated)
Image Data (ID Verification):
→ BUY Synthesis AI (custom pricing, specialized computer vision)
Total cost: ~1,200€/mes hybrid vs 200K€/año all-in vendor (~83% ahorro) vs 500€/mes all-DIY (pero 40h/semana engineering time = 12K€/mes in salaries).
🎯 Conclusión: El Futuro Es Sintético (Y Ya Llegó)
Si llegaste hasta aquí, ya sabes más sobre synthetic data que el 95% de equipos ML en el mercado. Repasemos los 5 insights clave que DEBES recordar:
Los 5 Takeaways Críticos
Synthetic data NO es experimental—es mainstream
Microsoft Phi-4 (400B tokens sintéticos), NVIDIA Nemotron (98% synthetic), Gartner (75% empresas en 2026). Si NO estás usando synthetic data, tu competencia sí.
ROI es extremo (87-1,135x más barato que human annotation)
Stanford Alpaca: 600€ vs 52,000€. Confident AI: 2.50€ vs 2,750€. NO hay otro approach ML con este ROI potential.
Quality validation es NO NEGOCIABLE
Stanford: solo 54% samples válidos. Debes implementar fidelity, diversity, utility, privacy, y fairness tests. Sin validation = garbage in, garbage out.
Synthetic NO es automáticamente GDPR-compliant
EDPB 2024: synthetic puede ser personal data si permite re-identification. DEBES implementar differential privacy (ε ≤ 1.0) + k-anonymity + re-identification testing.
Build vs Buy depende de scale, compliance, y team expertise
BUILD si
🔮 Predicción 2025-2026
En 12-18 meses, synthetic data será el approach default para entrenar modelos ML, no la excepción. Los early adopters (tú, si implementas AHORA) tendrán ventaja competitiva masiva:
- •Time-to-market 10x más rápido (2 días vs 2 meses data collection)
- •Cost structure 87-99% más bajo (MASSIVE advantage en runway)
- •Compliance risk near-zero (GDPR/HIPAA automated)
- •Iteration velocity 30x (daily vs monthly data refreshes)
⚡ Tu Competencia Ya Está Haciéndolo
Mientras lees esto, tus competidores están:
- • Fine-tuning modelos custom con synthetic data (coste: 600€, tiempo: 1 semana)
- • Deployando features ML 10x más rápido (NO esperan 6 meses por data access)
- • Expandiendo a nuevos markets sin fricción compliance (synthetic = privacy-safe)
La pregunta NO es "¿debería usar synthetic data?" Es: "¿cuánto revenue estoy perdiendo cada mes que NO lo implemento?"
📍 Próximos Pasos (Elige Tu Camino)
🧪 Path 1: DIY Experimenter
Implementa tú mismo con código de este artículo
- 1. Descarga calculadora ROI (lead magnet)
- 2. Copia código Sección 7 PASO 4
- 3. Genera 1K samples piloto (1-2 días)
- 4. Valida con SDMetrics
Best for: Engineering teams fuertes, budget limited
🤝 Path 2: Consulta Estratégica
Habla con nosotros sobre tu caso específico
- 1. Consulta gratuita 30 min
- 2. Evaluamos viability + ROI
- 3. Recomendamos build vs buy
- 4. Roadmap 90 días personalizado
🚀 Path 3: Implementation Full-Service
Nosotros implementamos todo end-to-end
- 1. Assessment completo (1 semana)
- 2. Pipeline production-ready (4-6 semanas)
- 3. Validation + compliance (GDPR/HIPAA)
- 4. Training team + documentation
El Momento Es AHORA
En 2026, cuando Gartner predice que el 75% de empresas usen synthetic data, los early adopters de 2025 tendrán 12-18 meses de ventaja competitiva. ¿Serás early adopter o late follower?
Este artículo te dio TODO: teoría (Phi-4, Nemotron, LAB), práctica (código runnable), compliance (GDPR), vendors (pricing real), casos de éxito (métricas verificadas), y roadmap (90 días step-by-step). No hay excusas. Solo ejecución.

Sobre el Autor
Abdessamad Ammi es CEO de BCloud Consulting y experto senior en IA Generativa y Cloud Infrastructure. Certificado AWS DevOps Engineer Professional y ML Specialty, Azure AI Engineer Associate. Ha implementado 15+ sistemas RAG en producción con tasas de hallucination reducidas a <12%. Especializado en MLOps, LangChain y arquitecturas cloud production-ready.


