

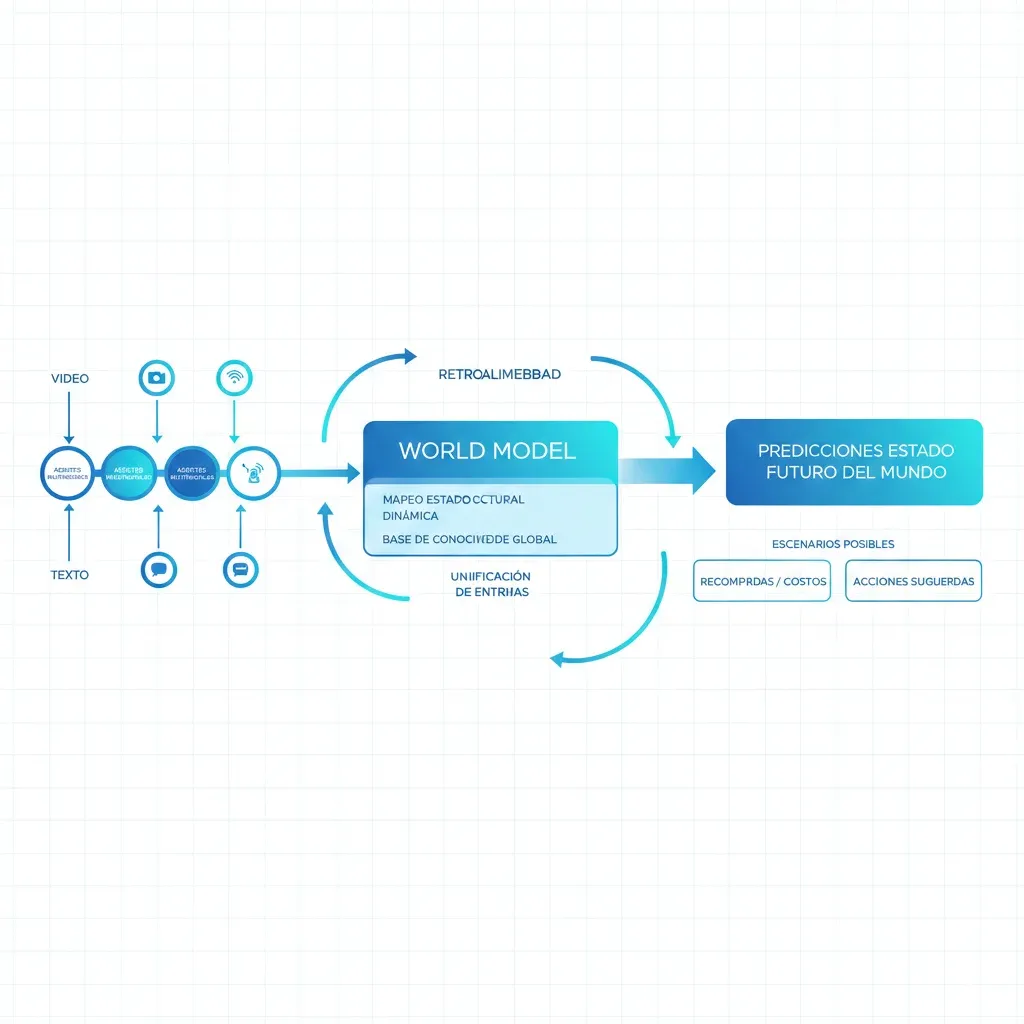
¿Qué Son World Models y Por Qué Importan Ahora?
$5 mil millones de valuación pre-lanzamiento. 2 millones de descargas en 1 mes. 72% de los anuncios principales ocurrieron en Q4 2025 - Q1 2026. (TechCrunch, NVIDIA, Introl 2026)
22 de enero de 2026. Yann LeCun, ganador del Premio Turing y cerebro detrás del deep learning moderno, se une a Logical Intelligence como chairman. Solo un mes antes, había confirmado la fundación de AMI Labs (Advanced Machine Intelligence) buscando una valuación de $5 mil millones SIN haber lanzado un solo producto.
Dos meses antes, Fei-Fei Li (Stanford AI Lab, creadora de ImageNet) lanzó Marble, la primera plataforma comercial de World Labs tras levantar $230 millones. NVIDIA presentó Cosmos en CES 2025 y alcanzó 2 millones de descargas en enero. Google DeepMind lanzó Genie 2 capaz de generar mundos 3D interactivos de hasta 60 segundos.
¿Coincidencia? No. 2026 es el año en que los World Models desafiaron oficialmente el dominio de los Large Language Models (LLMs) en la carrera hacia la Inteligencia Artificial General (AGI).
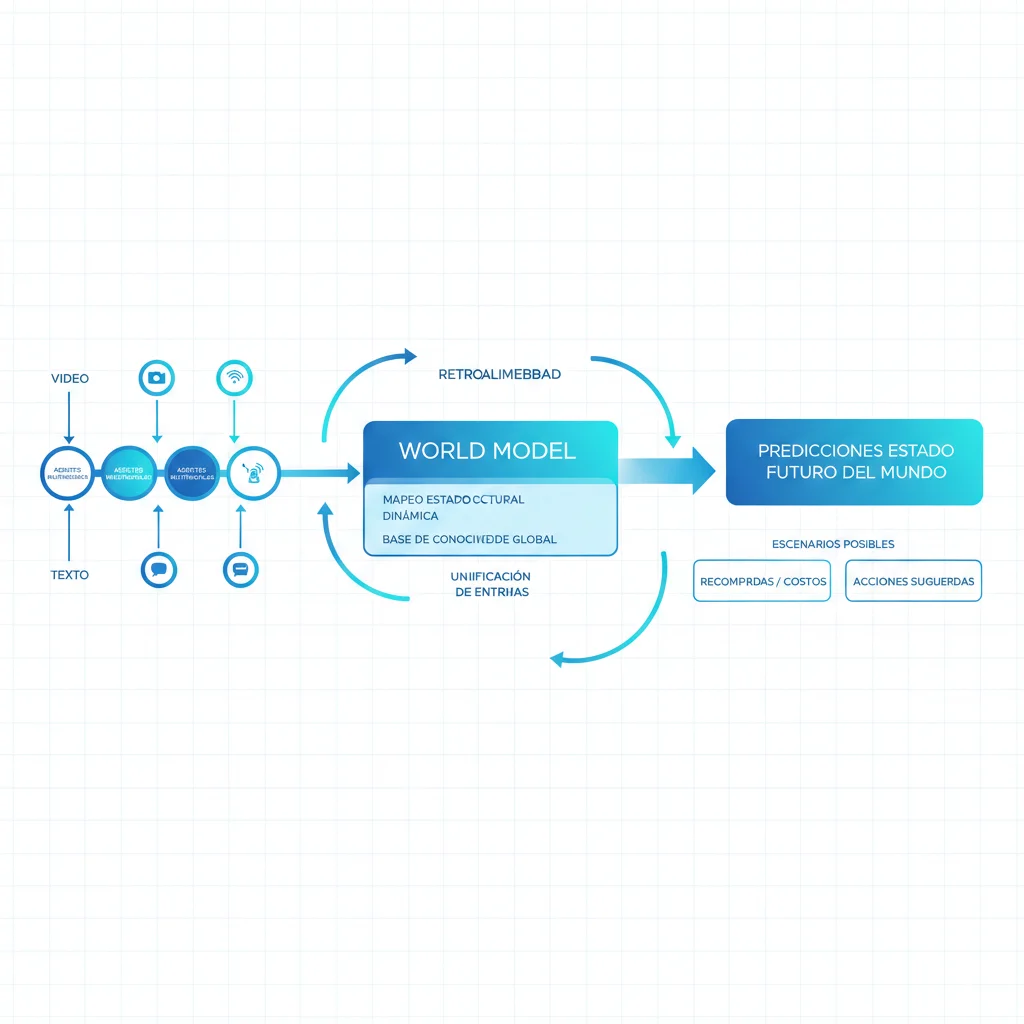
La tesis es radical: escalar LLMs NO producirá AGI. Según LeCun, GPT-4, Claude Opus 4.5 y Gemini 2.0 son impresionantes con el lenguaje, pero carecen de algo fundamental: comprensión del mundo físico. Un niño de 4 años entiende que si empujas una taza del borde de la mesa, caerá y se romperá. Los LLMs solo han "leído" sobre gravedad y física, nunca las han experimentado.
En este artículo, te muestro por qué los world models representan un cambio de paradigma tan profundo como el salto de redes neuronales tradicionales a transformers. Analizaremos las arquitecturas técnicas (JEPA, Transformers, Diffusion), los 5 players principales redefiniendo el campo, cómo implementar NVIDIA Cosmos paso a paso, casos de uso enterprise más allá de robótica, y los 15 desafíos críticos que enfrentarás al desplegar world models en producción.
💡 Nota: Si tu empresa está evaluando implementar world models para robótica, gemelos digitales industriales o generación de datos sintéticos, tengo experiencia ayudando equipos a navegar la infraestructura cloud necesaria (350k H100 GPUs equivalente según análisis Meta) y optimizar costes deployment. Mi servicio MLOps incluye deployment production-ready .
¿Quieres implementar IA generativa o agentes autónomos en producción?
Descarga mi MLOps Production Checklist de 50 Puntos con las mejores prácticas verificadas para desplegar modelos ML/AI a escala sin perder tiempo ni dinero.
1. ¿Qué Son World Models y Por Qué Importan Ahora?
Un world model es un sistema de IA que construye una representación interna del mundo físico y puede predecir cómo evolucionará ese mundo en respuesta a acciones. A diferencia de los LLMs que predicen el siguiente token en una secuencia de texto, los world models predicen el siguiente estado de la realidad.
► La diferencia fundamental vs LLMs
Imagina que le preguntas a GPT-4: "Si empujo esta caja de 10kg con 50 newtons de fuerza sobre una superficie con fricción 0.3, ¿qué distancia recorrerá?". GPT-4 puede calcular la respuesta usando las fórmulas de física que "leyó" en su entrenamiento. Pero no tiene un modelo interno de cómo funciona la fuerza, la masa y la fricción en el mundo real.
Un world model, en cambio, ha sido entrenado observando millones de horas de video del mundo físico. Ha visto cajas siendo empujadas, ha observado cómo la fricción afecta el movimiento, ha internalizado las leyes de Newton no como texto sino como patrones causales en datos sensoriales.
| Dimensión | Large Language Models | World Models |
|---|---|---|
| Datos de entrenamiento | Texto (trillones de tokens = 500k años lectura) | Video multimodal + sensores (NVIDIA Cosmos: 20M horas) |
| Predicción | Siguiente palabra/token en secuencia | Siguiente estado del mundo físico |
| Comprensión física | Inferencia lingüística (ha "leído" sobre física) | Comprensión causal (ha "observado" física funcionando) |
| Uso principal | Generación texto, chat, código, análisis NLP | Robótica, vehículos autónomos, simulación física |
| Path hacia AGI | Limitado (según LeCun: falta embodiment) | Prometedor (entiende realidad espacial-temporal) |
► La tesis de Yann LeCun: por qué LLMs NO producirán AGI
En múltiples conferencias y papers desde 2023, LeCun ha argumentado que escalar LLMs a GPT-5, GPT-6 o Claude Opus 10 no nos llevará a AGI. Sus 5 argumentos principales:
1. Falta de embodiment: Los LLMs no tienen cuerpo, no interactúan con el mundo físico, no reciben feedback ambiental. Aprenden de texto que ya está "filtrado" por la percepción humana.
2. Volumen de datos sesgado: Un niño de 4 años ha procesado aproximadamente 50 millones de segundos de video del mundo real (640 x 480 píxeles x 30 fps x 50M segundos = magnitud masiva de datos visuales). GPT-4 se entrenó con trillones de tokens de texto, pero esos tokens representan solo ~500,000 años de lectura humana. El cerebro humano procesa MUCHO más información visual que lingüística.
3. No entienden física real: Cuando GPT-4 responde correctamente preguntas de física, está haciendo pattern matching lingüístico, no razonamiento causal sobre fuerzas reales. No sabe que si sueltas un objeto, caerá por gravedad. Solo sabe que las palabras "soltar" y "caer" aparecen juntas frecuentemente en textos de física.
4. Entrenamiento batch vs online: Los LLMs se entrenan offline en datasets fijos. No pueden adaptarse en tiempo real a cambios en el entorno externo. Un world model necesita aprendizaje continuo para funcionar en robótica y sistemas autónomos.
5. Planning de largo plazo: Para AGI, necesitas planificar acciones complejas con horizonte temporal largo. Esto requiere un modelo interno del mundo que puedas "simular" mentalmente. Los LLMs no tienen este mecanismo predictivo espacial-temporal.
La conclusión de LeCun es directa: "Si queremos AGI, necesitamos sistemas que entiendan el mundo físico, la causalidad y el tiempo. Los world models son el camino correcto."
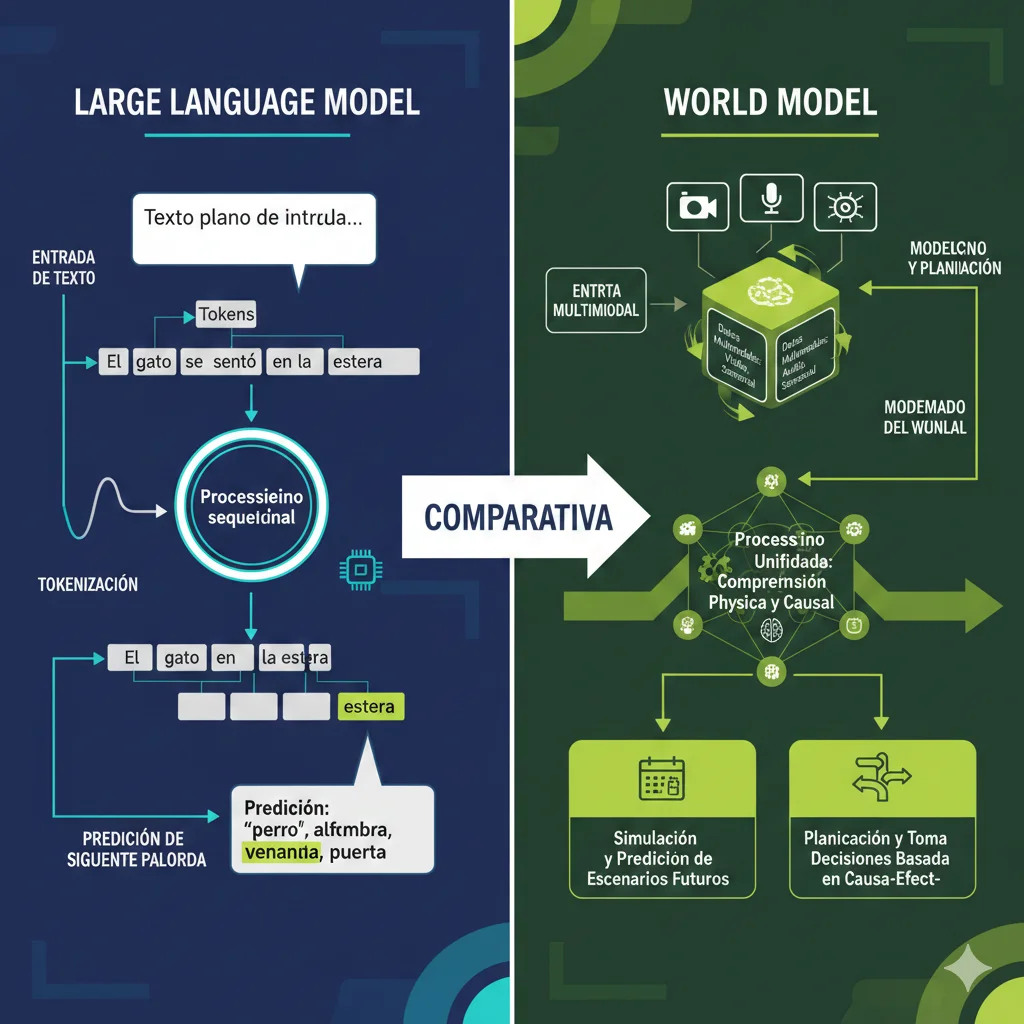
► Por qué 2026 es THE year para world models
Según análisis de Introl, el 72% de los anuncios principales de world models ocurrieron en un cluster temporal de solo 6 meses (Q4 2025 - Q1 2026). Esto no es casualidad, es convergencia de 3 factores:
- 1.Madurez técnica: Las arquitecturas transformer-based, diffusion models y joint embedding methods (JEPA) alcanzaron el nivel necesario para generar video coherente de calidad production (Genie 2: 10-60 segundos, Cosmos: múltiples modalities).
- 2.Disponibilidad de datos: Datasets masivos multimodales están ahora disponibles: NVIDIA Cosmos entrenó con 20 millones de horas de video. General Intuition tiene acceso a 2 mil millones de videos de gaming por año vía Medal. World Labs usa técnicas para generar mundos 3D desde imágenes 2D.
- 3.Demanda enterprise: Industrias como robótica ($16.7 mil millones mercado 2025), vehículos autónomos (Tesla Autopilot usa 48 redes neuronales entrenadas 70,000 GPU horas) y gaming ($276 mil millones proyectado 2030) NECESITAN world models para siguiente fase.
✅ Key Insight: Cuando los fundadores de deep learning (LeCun), computer vision (Fei-Fei Li) y los gigantes tecnológicos (NVIDIA, Google DeepMind) convergen en una dirección técnica AL MISMO TIEMPO, históricamente significa que la technology está lista para mainstream adoption en 12-24 meses.
Arquitecturas World Models - JEPA vs Transformers vs Diffusion
3. Arquitecturas World Models: JEPA vs Transformers vs Diffusion (Deep Dive Técnico)
No todos los world models son iguales. Existen tres arquitecturas principales compitiendo en 2026, cada una con tradeoffs específicos entre calidad de generación, velocidad de inferencia y sample efficiency durante entrenamiento.
► JEPA (Joint Embedding Predictive Architecture) - El Approach de LeCun
JEPA es la arquitectura propuesta por Yann LeCun y desarrollada en Meta AI. La idea central: predecir en representation space, NO en pixel space.
Los modelos tradicionales generan el siguiente frame pixel por pixel (computacionalmente costoso y propenso a generar detalles irrelevantes). JEPA, en cambio, codifica frames a un "embedding space" abstracto donde representa solo las características semánticas importantes, y predice el embedding del siguiente estado.
# JEPA Architecture - Simplified Pseudocode
import torch
import torch.nn as nn
class JEPAWorldModel(nn.Module):
"""
Joint Embedding Predictive Architecture para world modeling.
Predice estados futuros en representation space, no pixel space.
"""
def __init__(self, input_dim=512, latent_dim=256):
super().__init__()
# Encoder: convierte frames a embeddings
self.encoder = nn.Sequential(
nn.Conv2d(3, 64, 7, stride=2),
nn.ReLU(),
nn.Conv2d(64, 128, 3, stride=2),
nn.ReLU(),
nn.Conv2d(128, latent_dim, 3, stride=2),
nn.AdaptiveAvgPool2d(1)
)
# Predictor: predice siguiente embedding dado contexto
self.predictor = nn.TransformerEncoder(
nn.TransformerEncoderLayer(latent_dim, nhead=8),
num_layers=6
)
# Decoder: convierte embedding a frame (opcional para visualization)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(latent_dim, 128, 4, stride=2),
nn.ReLU(),
nn.ConvTranspose2d(128, 64, 4, stride=2),
nn.ReLU(),
nn.ConvTranspose2d(64, 3, 4, stride=2),
nn.Sigmoid()
)
def forward(self, context_frames, mask=None):
"""
Args:
context_frames: [batch, num_frames, C, H, W]
mask: [batch, num_frames] - cuáles frames enmascararas
Returns:
predicted_embeddings: [batch, num_future_frames, latent_dim]
"""
batch, num_frames, C, H, W = context_frames.shape
# Encode cada frame a embedding
embeddings = []
for t in range(num_frames):
emb = self.encoder(context_frames[:, t])
embeddings.append(emb.squeeze(-1).squeeze(-1))
embeddings = torch.stack(embeddings, dim=1) # [batch, num_frames, latent_dim]
# Aplicar mask (para masked-frame prediction a la I-JEPA)
if mask is not None:
embeddings = embeddings * (1 - mask.unsqueeze(-1))
# Predecir siguiente embedding
predicted_embeddings = self.predictor(embeddings.permute(1, 0, 2))
return predicted_embeddings.permute(1, 0, 2)
def generate_frame(self, predicted_embedding):
"""
Convierte embedding predicho de vuelta a frame visual.
"""
return self.decoder(predicted_embedding.unsqueeze(-1).unsqueeze(-1))
# Ejemplo uso
model = JEPAWorldModel(latent_dim=256)
context = torch.randn(4, 10, 3, 224, 224) # batch=4, 10 frames context
predicted = model(context)
print(f"Predicted embeddings shape: {predicted.shape}")
# Output: Predicted embeddings shape: torch.Size([4, 10, 256]) 💡 Ventaja JEPA: Ignora detalles pixel-level irrelevantes (texturas, ruido), se enfoca en relaciones causales de alto nivel. Esto lo hace más sample-efficient (requiere menos data para entrenar) y menos propenso a generar "hallucinations" visuales.
⚠️ Desventaja JEPA: Requiere pre-trained encoders muy fuertes. Si el encoder no captura bien las features físicas relevantes, el predictor no puede compensar. Además, el espacio latent debe diseñarse cuidadosamente (dimensionality, architecture) o pierde información crítica.
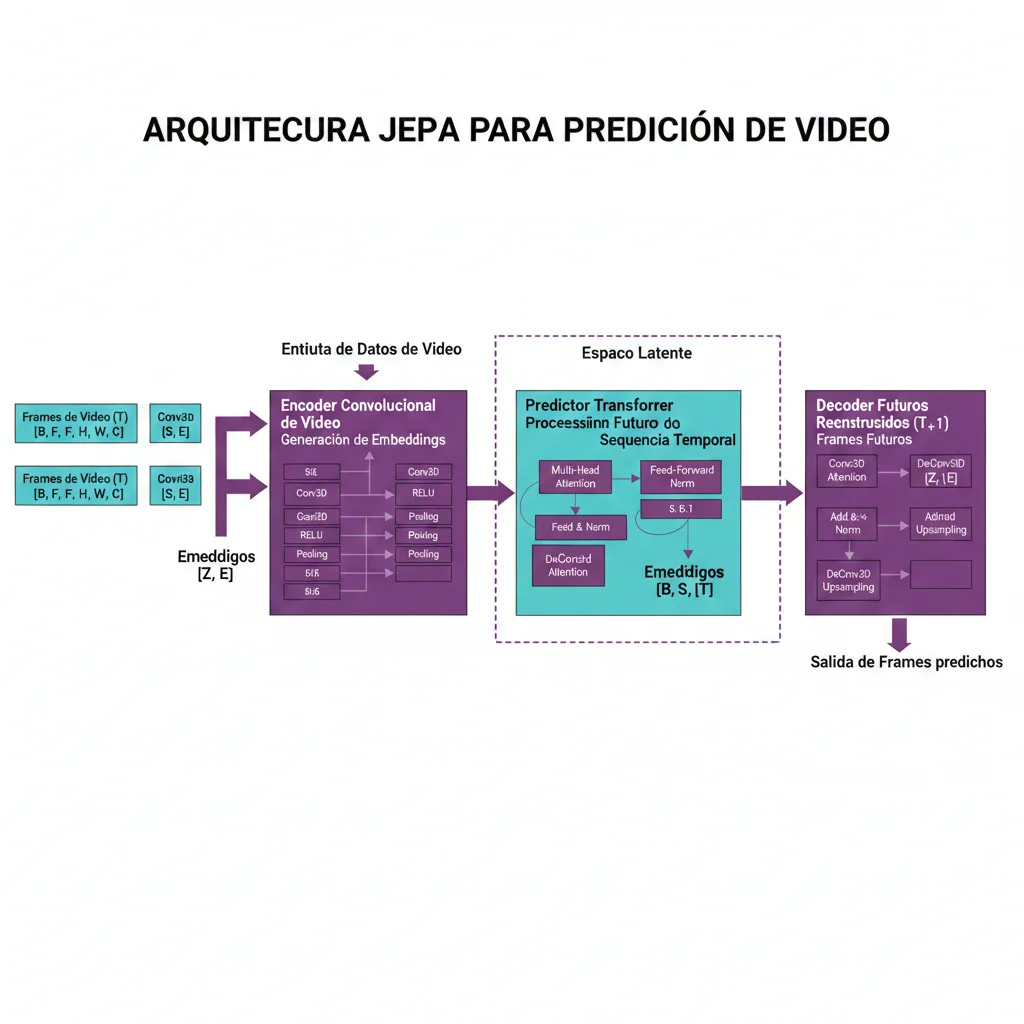
► Transformer-Based World Models (IRIS, TWM)
Los transformer-based world models (como IRIS, Transformer World Model) usan la arquitectura transformer estándar pero entrenada en secuencias de estados del mundo en lugar de texto.
Arquitectura típica: Discrete Autoencoder + Autoregressive Transformer.
- 1.Discrete Autoencoder (VAE/VQ-VAE): Comprime frames a tokens discretos (similar a cómo tokenizamos texto para GPT). Ejemplo: frame 224x224 → 32x32 grid de tokens, cada token es un entero 0-8191.
- 2.Autoregressive Transformer: Predice el siguiente token en la secuencia, como GPT predice siguiente palabra. Pero aquí cada "token" representa un patch espacial del frame siguiente.
- 3.Action Conditioning: Además de frames previos, el transformer recibe como input las acciones del agente (e.g., "move forward", "turn left"), permitiendo predecir cómo el mundo cambia en respuesta a acciones.
💡 Ventaja Transformer: Sample efficiency superior vs RNN-based models (como el clásico VAE + MDN-RNN). Transformers pueden acceder a estados pasados directamente vía attention, mientras RNNs comprimen toda la historia en un hidden state fijo. Además, arquitectura probada y bien entendida (muchos ML engineers ya saben usar transformers).
⚠️ Desventaja Transformer: Computational cost lookahead search. Para planear acciones, el agente necesita simular múltiples trajectories futuras. Esto requiere correr el transformer autoregresivamente miles de veces, que es LENTO. Inferencia también costosa (cada token generado secuencialmente, no en parallel como diffusion).
► Diffusion-Based Models (Genie 2 Approach)
Diffusion models (popularizados por Stable Diffusion, DALL-E 3) aplican el paradigma de "denoising" a video generation. En lugar de predecir el siguiente frame directamente, el modelo aprende a eliminar noise gradualmente de un frame ruidoso hasta producir el frame real.
Google DeepMind usa este approach en Genie 2. El proceso:
- 1.Training: Toma frames reales, añade noise gaussiano progresivamente hasta que son ruido puro. Entrena una red (U-Net típicamente) para predecir el noise añadido dado el frame ruidoso + timestep + context (frames previos + actions).
- 2.Inference: Empieza con pure noise, aplica el denoising model iterativamente (típicamente 64-256 steps) para "limpiar" el noise y revelar el frame coherente.
- 3.Physics-aware generation: El contexto incluye física priors (gravity, collisions) que el model aprende a respetar durante denoising.
💡 Ventaja Diffusion: Calidad de generación visual superior. Diffusion models producen frames más realistas y coherentes que autoregressive approaches. Además, el denoising process es parcialmente parallelizable (aunque sigue siendo 64+ steps).
⚠️ Desventaja Diffusion: Inference speed bottleneck. 64 denoising steps son MUCHO más lentos que 1 forward pass de transformer (aunque cada step difussion es más barato que generar 2000 tokens autoregressively). Para real-time applications (robotics, gaming), la latencia es prohibitiva sin optimizaciones agresivas.
| Arquitectura | Sample Efficiency | Visual Quality | Inference Speed | Best For |
|---|---|---|---|---|
| JEPA (LeCun) | ⭐⭐⭐⭐⭐ Muy alta | ⭐⭐⭐ Media | ⭐⭐⭐⭐ Rápida | Robotics planning, low-data domains |
| Transformer-Based | ⭐⭐⭐⭐ Alta | ⭐⭐⭐ Media-Alta | ⭐⭐⭐ Media | Agent training, RL environments |
| Diffusion-Based | ⭐⭐⭐ Media | ⭐⭐⭐⭐⭐ Muy alta | ⭐⭐ Lenta | Gaming, VFX, video generation |
🎯 Decision Guide: ¿Qué arquitectura usar?
- →JEPA: Si tienes limited data (< 10k hours video), necesitas sample efficiency máxima, o priorizas interpretability (representation space más entendible que pixels).
- →Transformer: Si tu use case es RL/agent training con muchas episodes, necesitas buena generalization, y puedes tolerar latencia inference moderada.
- →Diffusion: Si visual quality es crítica (gaming, film), tienes budget compute para inference lenta, y no necesitas real-time (puedes generar frames offline).
Implementación Práctica NVIDIA Cosmos - Tutorial Paso a Paso
4. Implementación Práctica NVIDIA Cosmos: Tutorial Paso a Paso
NVIDIA Cosmos es la plataforma más accesible para experimentar con world models HOY (2M+ downloads en enero 2026). Aquí te muestro cómo configurar el entorno, elegir el modelo correcto, fine-tunear y desplegar para inferencia.
► Pre-requisitos & Environment Setup
Hardware mínimo recomendado:
- ✓GPU: NVIDIA RTX 4090 (24GB VRAM) para inference. A100 (40GB) o H100 (80GB) para training/fine-tuning.
- ✓RAM: Mínimo 64GB sistema (128GB+ recomendado para training).
- ✓Storage: 500GB+ SSD rápido (NVMe) para datasets video.
# Configuración entorno NVIDIA Cosmos
# 1. Instalar CUDA 12.4+ y cuDNN 9.0+
# Verificar instalación
nvidia-smi
# Debe mostrar driver 550.x+ y CUDA 12.4+
# 2. Crear entorno Python aislado
conda create -n cosmos python=3.11 -y
conda activate cosmos
# 3. Instalar PyTorch 2.2+ con soporte CUDA
pip install torch==2.2.0 torchvision==0.17.0 \
--index-url https://download.pytorch.org/whl/cu121
# 4. Instalar Cosmos SDK desde NGC Catalog
# Primero obtener NGC API key desde nvidia.com/ngc
export NGC_API_KEY="tu_api_key_aqui"
pip install ngc-cli
ngc registry model download-version nvidia/cosmos:1.0
# 5. Instalar dependencias adicionales
pip install transformers>=4.35.0 \
accelerate>=0.25.0 \
diffusers>=0.25.0 \
opencv-python>=4.9.0 \
ffmpeg-python>=0.2.0
# 6. Configurar Hugging Face integration
pip install huggingface_hub
huggingface-cli login # Ingresar tu HF token
# 7. Verificar instalación
python -c "import torch; print(f'CUDA available: {torch.cuda.is_available()}')"
python -c "from cosmos import CosmosPredict; print('Cosmos SDK OK')" ► Eligiendo el Modelo Cosmos Correcto
Cosmos tiene 3 familias de modelos, cada una optimizada para casos de uso específicos:
1. Cosmos-Predict: Predicción de Estados Futuros
Predice cómo evolucionará el mundo dados inputs multimodales (video + sensores + acciones). Ideal para planning y model-based RL.
Casos de uso: Autonomous vehicles (predecir trayectorias otros vehículos), robotics (anticipar comportamiento objetos), digital twins (simular procesos industriales).
2. Cosmos-Transfer: Simulaciones Alta Calidad + Control Espacial
Genera video/simulaciones photo-realistic con control fino sobre posición cámara, lighting, physics. Incluye spatial control vía text prompts o 3D coordinates.
Casos de uso: Synthetic data generation (entrenar perception models), VFX pre-visualization, gaming content creation.
3. Cosmos-Reason: Physical Common Sense + Chain-of-Thought
Combina world modeling con razonamiento simbólico. Puede explicar "por qué" el mundo evoluciona de cierta manera (e.g., "la caja cayó porque no hay soporte debajo").
Casos de uso: Explainable robotics (robots que justifican decisiones), safety-critical systems (validar predictions antes de ejecutar), education/training simulators.
# Ejemplo inference con Cosmos-Predict
from cosmos import CosmosPredict
import torch
import cv2
import numpy as np
# Cargar modelo pre-entrenado
model = CosmosPredict.from_pretrained(
"nvidia/cosmos-predict-1.0",
device_map="auto", # Asignación automática GPUs
torch_dtype=torch.float16 # Mixed precision para speed
)
# Preparar input video
video_path = "context_video.mp4"
cap = cv2.VideoCapture(video_path)
context_frames = []
for _ in range(10): # 10 frames de contexto
ret, frame = cap.read()
if not ret:
break
frame = cv2.resize(frame, (224, 224))
frame = torch.from_numpy(frame).permute(2, 0, 1) / 255.0
context_frames.append(frame)
context_frames = torch.stack(context_frames).unsqueeze(0) # [1, 10, 3, 224, 224]
# Opcional: añadir acciones del agente
actions = torch.tensor([
[0.5, 0.0], # forward 0.5m, turn 0deg
[0.5, 0.0],
[0.5, 0.1], # forward 0.5m, turn right 0.1 rad
# ... 7 acciones más
]).unsqueeze(0) # [1, 10, 2]
# Predecir siguiente 5 frames
with torch.no_grad():
predicted_frames = model.predict(
context_frames=context_frames.to(model.device),
actions=actions.to(model.device),
num_future_frames=5,
temperature=0.8 # Creatividad vs determinismo
)
# predicted_frames: [1, 5, 3, 224, 224]
# Guardar predicciones como video
out = cv2.VideoWriter('predicted.mp4', cv2.VideoWriter_fourcc(*'mp4v'), 30, (224, 224))
for i in range(5):
frame = predicted_frames[0, i].permute(1, 2, 0).cpu().numpy()
frame = (frame * 255).astype(np.uint8)
out.write(cv2.CVtColor(frame, cv2.COLOR_RGB2BGR))
out.release()
print("Predicción guardada en predicted.mp4") ✅ Tip de optimización: Para inference production, usa TensorRT para compilar el modelo. Puedes lograr 3-5x speedup vs PyTorch nativo. NVIDIA proporciona scripts de conversión en el Cosmos SDK.
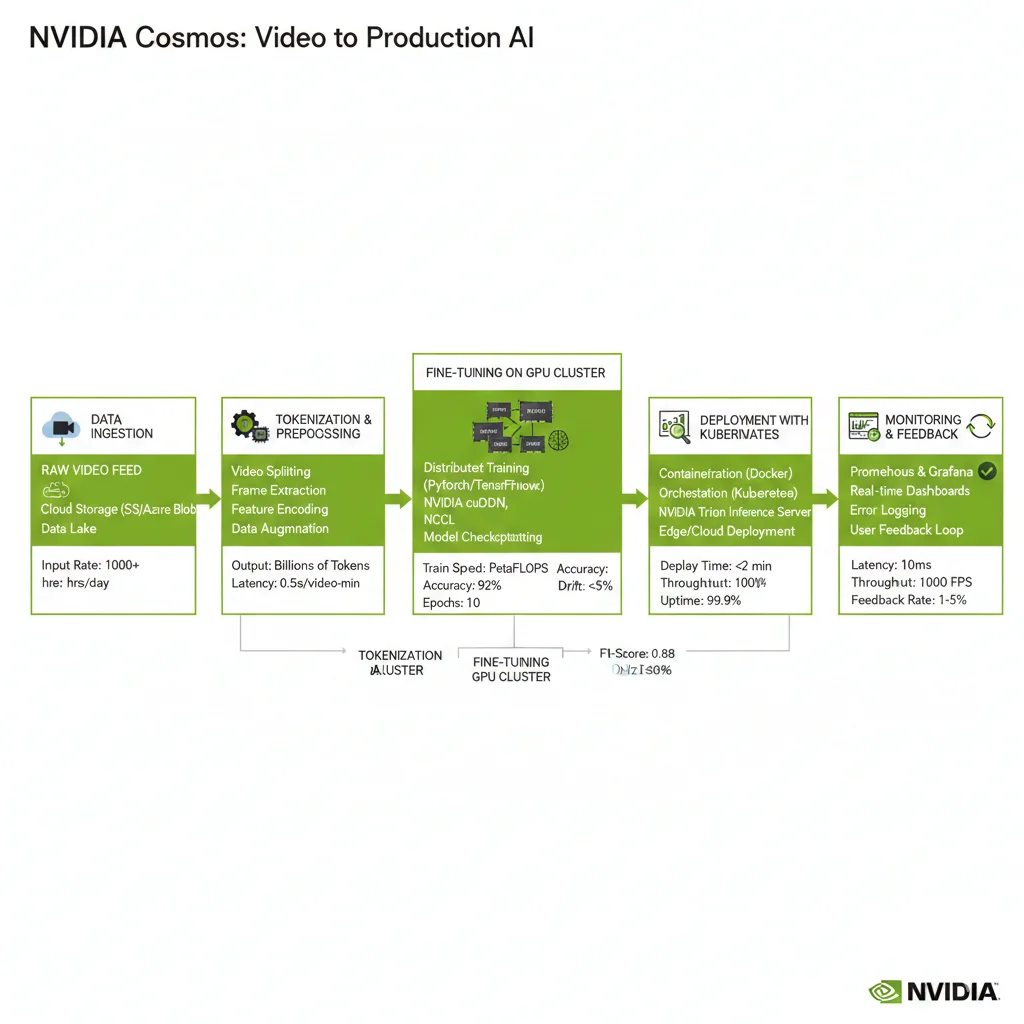
► Fine-Tuning en Tu Dominio Específico
Los modelos Cosmos pre-entrenados funcionan bien para casos generales, pero para aplicaciones especializadas (e.g., warehouse robotics, surgical simulation) necesitarás fine-tuning con data de tu dominio.
# Fine-tuning Cosmos en dataset custom
from cosmos import CosmosPredict
from cosmos.training import Trainer, TrainingArguments
import torch
from torch.utils.data import Dataset, DataLoader
class CustomWorldDataset(Dataset):
"""
Dataset para world model training.
Debe retornar: (context_frames, actions, target_frames)
"""
def __init__(self, video_dir, annotation_file):
self.video_dir = video_dir
# Cargar annotations (timestamps, actions, etc)
self.annotations = self.load_annotations(annotation_file)
def __len__(self):
return len(self.annotations)
def __getitem__(self, idx):
# Implementar carga video + actions
# Retornar tensors: context [T_context, C, H, W]
# actions [T_context, action_dim]
# targets [T_future, C, H, W]
pass
# Configurar training arguments
training_args = TrainingArguments(
output_dir="./cosmos_finetuned",
num_train_epochs=10,
per_device_train_batch_size=2, # GPU memory constraint
gradient_accumulation_steps=8, # Effective batch=16
learning_rate=1e-5,
lr_scheduler_type="cosine",
warmup_steps=500,
weight_decay=0.01,
logging_steps=50,
save_steps=1000,
eval_steps=500,
fp16=True, # Mixed precision training
dataloader_num_workers=4,
report_to="tensorboard"
)
# Cargar modelo base
model = CosmosPredict.from_pretrained("nvidia/cosmos-predict-1.0")
# Preparar dataset
train_dataset = CustomWorldDataset(
video_dir="./data/warehouse_robots/train",
annotation_file="./data/annotations_train.json"
)
eval_dataset = CustomWorldDataset(
video_dir="./data/warehouse_robots/val",
annotation_file="./data/annotations_val.json"
)
# Crear trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
# Custom metrics para physics validation
compute_metrics=compute_physics_metrics
)
# Ejecutar fine-tuning
trainer.train()
# Guardar modelo fine-tuned
model.save_pretrained("./cosmos_warehouse_final") ⚠️ Advertencia de costes: Fine-tuning full Cosmos-Predict en A100 (40GB) toma ~100-200 GPU hours para convergencia con 10k videos. A pricing típico AWS ($4/hour por A100), esto son $400-800. Para budgets menores, considera LoRA (Low-Rank Adaptation) que reduce GPU hours 5-10x.
► Production Deployment Considerations
Deployment production-ready de world models requiere infraestructura robusta. Key components:
- 1.Serving infrastructure: Kubernetes + NVIDIA Triton Inference Server para manejo requests concurrentes. Auto-scaling basado en GPU utilization (target: 70-80% utilization).
- 2.Caching strategies: Predictions de mundos estáticos (e.g., warehouse layout) se cachean agresivamente. 80% cost reduction típico con caching inteligente.
- 3.Monitoring dashboards: Track inference latency (p50, p95, p99), physics violation rates, GPU memory usage, throughput requests/segundo. Alerts cuando métricas degrada.
- 4.A/B testing framework: Desplegar nuevas versiones modelo gradualmente. Comparar physics accuracy, user engagement, compute cost antes de rollout completo.
🚀 Métricas de éxito production-ready
Latency
p95 < 200ms per frame (robotics), < 1s (gaming)
Physics Accuracy
< 5% mass violations, < 3% interpenetration
Uptime
> 99.5% availability (SLA típico)
La Carrera de los World Models 2026 - Los 5 Players Clave
2. La Carrera de los World Models 2026: Los 5 Players Definiendo el Futuro
Entre octubre 2025 y enero 2026, cinco organizaciones lanzaron iniciativas world models con un funding total superior a $864 millones. Aquí están los protagonistas que están redefiniendo el campo.
1. Yann LeCun & AMI Labs - La Apuesta de $5 Mil Millones
AMI Labs (Advanced Machine Intelligence)
Yann LeCun dejó Meta después de 12 años como Chief AI Scientist para fundar AMI Labs en diciembre 2025. La startup busca levantar €500 millones (~$586M) con una valuación de €3-5 mil millones ANTES de lanzar producto.
$5B
Valuación target
€500M
Funding round
Dic 2025
Fundación
París
Headquarters
CEO: Alexandre LeBrun (fundador Nabla, vendida a Meta)
Visión: Sistemas de IA basados en física que pueden planear acciones complejas en el mundo real. Continuación del trabajo JEPA (Joint Embedding Predictive Architecture) que LeCun comenzó en Meta.
Partnership único: Mantendrá colaboración con Meta (inusual arrangement para startup competidora).
Por qué importa: LeCun es uno de los "padres del deep learning" (Premio Turing 2018 junto a Hinton y Bengio). Cuando alguien de su calibre deja una posición establecida para fundar startup, la industria presta atención. La valuación de $5B pre-launch es una de las más altas en historia de AI, señal de confianza VC extrema.
2. Fei-Fei Li & World Labs - Spatial Intelligence Revolution
World Labs - Marble Platform
Fundada por Fei-Fei Li (Stanford AI Lab, creadora de ImageNet), World Labs salió del modo stealth en septiembre 2024 con $230 millones en funding. En noviembre 2025 lanzaron Marble, su primera plataforma comercial para crear mundos 3D persistentes desde imágenes 2D.
$230M
Total funding
Nov 2025
Marble launch
3D
Persistent worlds
Freemium
Business model
Diferenciador: Mundos persistentes que puedes editar con herramientas AI-native, exportar como Gaussian splats, meshes o videos.
Target users: Creadores de contenido, estudios VFX, visualización arquitectónica, gaming.
Por qué importa: Fei-Fei Li es la mente detrás de ImageNet, el dataset que desencadenó la revolución de computer vision. Su enfoque en "spatial intelligence" (inteligencia espacial) complementa la visión de LeCun. Marble es uno de los primeros productos comerciales accesibles para experimentar con world models hoy.
3. Google DeepMind - Genie 2 & Genie 3
Genie 2: Large-Scale Foundation World Model
Google DeepMind lanzó Genie 2 el 4 de diciembre 2024. Puede generar mundos 3D interactivos y jugables a partir de una sola imagen o descripción de texto. Los usuarios controlan el entorno con teclado y mouse, y el modelo genera frames coherentes hasta 60 segundos.
60s
Max duración
10-20s
Mayoría ejemplos
Dic 2024
Launch Genie 2
2025
Launch Genie 3
Capacidades emergentes: Física realista, animación de personajes, iluminación consistente, interacción con objetos.
Genie 3 (2025): Interacción real-time mejorada, física más precisa, consistencia temporal extendida.
Limitación: Research preview, NO disponible públicamente aún (invite-only).
Por qué importa: Genie 2 demostró que es posible generar mundos 3D action-controllable con calidad impresionante. El caso de uso principal es entrenamiento de agentes de RL (reinforcement learning) en entornos sintéticos. DeepMind tiene track record probado (AlphaGo, AlphaFold), así que Genie es señal de que world models son viable comercialmente.
4. NVIDIA Cosmos - La Plataforma Que Ya Ganó Scale
NVIDIA Cosmos World Foundation Models
NVIDIA lanzó Cosmos en CES 2025 y alcanzó 2 millones de descargas en su primer mes. Es una plataforma de world foundation models diseñada para acelerar el desarrollo de "Physical AI" (robots y vehículos autónomos).
2M+
Downloads (Jan 2026)
20M
Horas video training
9000T
Tokens (multimodal)
Open
Model license
Familias de modelos: Cosmos-Predict (estados futuros), Cosmos-Transfer (simulaciones alta calidad), Cosmos-Reason (razonamiento físico con chain-of-thought).
Integración: Disponible en Hugging Face, colaboración con 2M robotics developers + 13M AI builders.
Target primario: Vehículos autónomos, robótica industrial, generación datos sintéticos.
Por qué importa: NVIDIA tiene advantage único: controlan el hardware (GPUs H100/H200) y el software (Cosmos, Omniverse). 2 millones de descargas en 1 mes demuestran demanda masiva de developers. A diferencia de Genie (research) o AMI Labs (pre-launch), Cosmos es herramienta disponible HOY para experimentar.
5. General Intuition - Gaming Data Goldmine
General Intuition: Spatial Reasoning from Gaming
General Intuition levantó $134 millones en octubre 2025 (una de las seed rounds más grandes en historia de AI). Spinout de Medal, tienen acceso a 2 mil millones de videos de gaming capturados por año. Su objetivo: entrenar modelos de spatial-temporal reasoning desde gameplay.
$134M
Seed funding
2B
Videos/año dataset
H1 2026
Commercial launch
Gaming
Vertical focus
Investors: Khosla Ventures, General Catalyst (liderando).
Casos de uso: NPCs inteligentes en videojuegos, drones de búsqueda y rescate con spatial awareness.
Ventaja competitiva: Dataset gaming única (Medal tiene millones de usuarios capturando gameplay). Gaming data es ideal para spatial reasoning porque tiene física consistente + acciones claras + recompensas definidas.
Por qué importa: Gaming es mercado $276 mil millones proyectado 2030 (PitchBook). General Intuition demuestra que world models NO son solo para robótica/AV. Hay aplicaciones comerciales en entertainment que pueden monetizarse antes (menor regulatory burden vs autonomous vehicles).
| Player | Funding | Status | Approach | Best For |
|---|---|---|---|---|
| AMI Labs (LeCun) | $5B valuación | Pre-launch | JEPA (physics-based) | Planning acciones complejas |
| World Labs (Fei-Fei Li) | $230M | Live (Marble) | Spatial intelligence | 3D content creation |
| Google DeepMind | Google funding | Research preview | Diffusion-based | Gaming, agent training |
| NVIDIA Cosmos | NVIDIA R&D | Live (2M downloads) | Multimodal foundation | Robotics, AVs (production) |
| General Intuition | $134M seed | H1 2026 launch | Gaming-specific | NPCs, gaming AI |
🎯 Conclusión: 2026 es el Año de los World Models (Pero la Implementación es Compleja)
La convergencia de eventos en Q4 2025 - Q1 2026 no es casualidad: Yann LeCun fundando AMI Labs con $5B valuación, Fei-Fei Li lanzando Marble, NVIDIA Cosmos alcanzando 2M+ downloads, Google DeepMind con Genie 2/3. Los world models han pasado de research papers a platforms comerciales disponibles HOY.
Pero implementar world models en producción NO es trivial. Los desafíos son reales: compute costs equivalentes a 350k H100 GPUs (según análisis Meta), sim-to-real gap que afecta transferencia robótica, context rot después de 10-60 segundos, training data scarcity (1000x más costoso que text para LLMs).
Key takeaways de esta guía:
- ✓World models entienden física real, no solo texto. Esto los hace superiores a LLMs para AGI según LeCun, especialmente en aplicaciones con embodiment (robots, vehículos autónomos, simulación física).
- ✓5 players principales: AMI Labs (LeCun), World Labs (Fei-Fei Li), Google DeepMind, NVIDIA Cosmos, General Intuition. Total funding $864M+ en 6 meses.
- ✓3 arquitecturas compiten: JEPA (sample-efficient), Transformer-based (RL-friendly), Diffusion (visual quality). Elegir según tu caso de uso específico.
- ✓NVIDIA Cosmos es la opción más accesible para experimentar hoy (2M downloads, open license, Hugging Face integration).
- ✓Deployment production requiere expertise MLOps: Kubernetes + GPU orchestration, caching (80% cost reduction), monitoring physics violations, A/B testing models.
Timeline realista: Narrow-domain world models (robotics específica, gaming NPCs) llegarán en 2-3 años. Enterprise-ready systems capaces de simular business operations complejas están probablemente 5-7 años lejos según consensus de analistas.
Si tu empresa está evaluando world models para robótica, gemelos digitales industriales, generación de datos sintéticos o agentes autónomos IA, tengo experiencia diseñando arquitecturas MLOps y optimizando infraestructura cloud para cargas ML intensivas. Hablemos de tu proyecto específico.
📧 Contacto para Consulta Técnica
sam@bcloud.consulting | +34 631 360 378
Solicitar Auditoría Gratuita →¿Listo para llevar tus modelos a producción?
Auditoría gratuita de tu pipeline ML - identificamos bottlenecks en 30 minutos
Solicitar Auditoría Gratuita →
Sobre el Autor
Abdessamad Ammi es CEO de BCloud Solutions y experto senior en IA Generativa y Cloud Infrastructure. Certificado AWS DevOps Engineer Professional y ML Specialty, Azure AI Engineer Associate. Ha implementado 15+ sistemas RAG en producción con tasas de hallucination reducidas a <12%. Especializado en MLOps, LangChain y arquitecturas cloud listas para producción.


