

La Anatomía de una Factura AI Inflada
🚨 ALERTA: Tu factura de inference está fuera de control
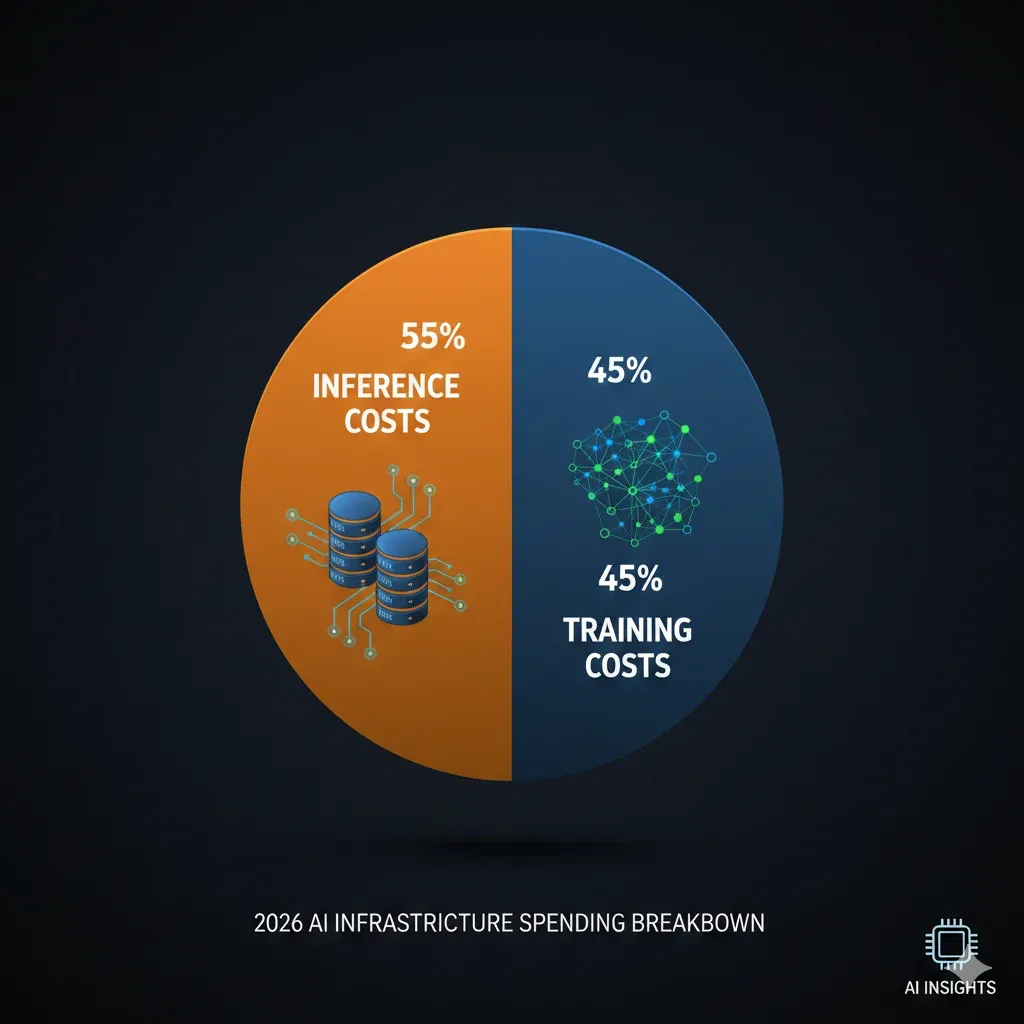
En 2026, el 55% del gasto en infraestructura AI ya no es entrenamiento — es INFERENCE. Y si no estás optimizando activamente, estás quemando hasta el 60% de tu presupuesto cloud en queries que modelos más pequeños podrían manejar igual de bien.
El momento que temíamos ha llegado. Por primera vez en la historia de la industria AI, los costes de inference han superado a los de training como el principal driver de gasto en infraestructura cloud optimizada para IA.
Según datos de IDC publicados en enero de 2026, las empresas están descubriendo una verdad incómoda: mientras invertían millones en entrenar modelos o acceder a APIs premium, el verdadero agujero negro de su presupuesto estaba en otro lugar. Cada query, cada llamada a la API, cada token generado — todo suma. Y suma RÁPIDO.
💡 El problema en números:
- • 55% del gasto AI cloud es inference (IDC 2026)
- • 60-80% de queries pueden ser manejadas por modelos más pequeños
- • 60% de sobrepago promedio sin model routing inteligente
- • 90% de ahorro posible con semantic caching
He trabajado con empresas que pasaron de $45,000/mes en APIs de LLM a $12,000/mes implementando las técnicas que voy a compartir en esta guía. No es magia — es ingeniería de costes aplicada sistemáticamente.
La buena noticia: los precios de inference han caído 280x entre 2020 y 2024 según el Stanford AI Index. La mala noticia: el volumen de queries ha crecido exponencialmente, anulando esas mejoras para muchas empresas.
En esta guía completa, te voy a mostrar exactamente cómo las empresas más sofisticadas del mercado — desde Midjourney hasta ByteDance — están reduciendo sus costes de inference entre un 50% y un 85% sin sacrificar calidad. Y lo más importante: cómo puedes implementar estas mismas estrategias en tu infraestructura.
¿Tu factura de inference te tiene preocupado? Realizo auditorías técnicas gratuitas donde analizo tu arquitectura actual y te muestro exactamente dónde estás perdiendo dinero — y cómo recuperarlo.
Solicitar Auditoría Gratuita →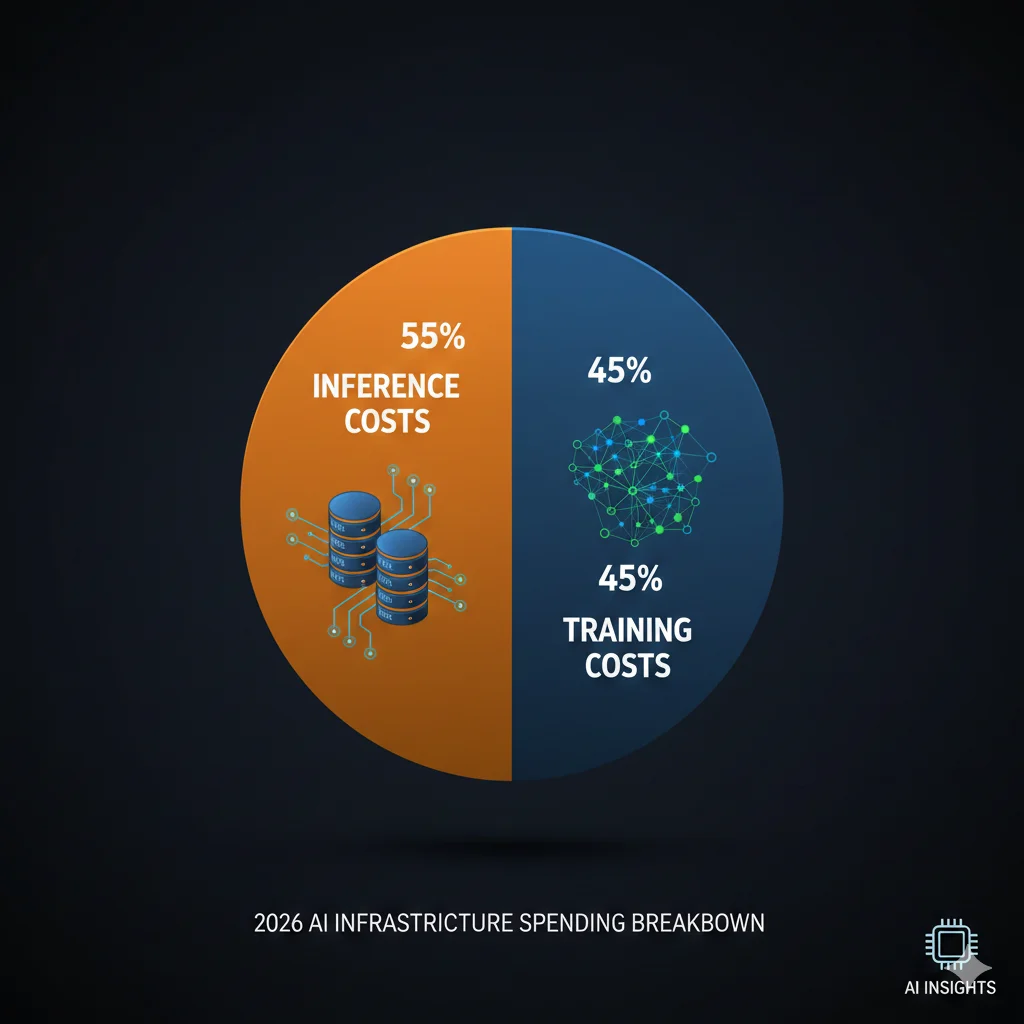
Para entender por qué tu factura cloud está explotando, primero necesitas entender cómo se compone. La mayoría de CTOs y Engineering Managers que consulto tienen una imagen mental completamente errónea de dónde va su dinero.
El Mito del Training Dominante
Durante años, la narrativa de la industria fue clara: "El entrenamiento de modelos es carísimo, pero una vez entrenados, la inferencia es barata." Esta narrativa era correcta... en 2022.
En 2026, la realidad es exactamente opuesta:
Training Costs
45%
One-time o periódico, amortizable
Inference Costs
55%
Recurrente, escala con uso, difícil de predecir
Por Qué Inference Supera a Training
1. Volumen de Queries Exponencial
Cada feature de AI que añades a tu producto multiplica las llamadas a inference. Un chatbot que atiende 10,000 usuarios/día puede generar 500,000+ tokens diarios fácilmente. A $10/millón de tokens de output con GPT-4o, eso son $150/día solo en un feature.
2. La Trampa del "Mejor Modelo"
Muchos equipos caen en la trampa de usar el modelo más capaz para TODAS las tareas. ¿Un usuario pregunta "¿Cuál es el horario de atención?" → GPT-4 Turbo. ¿Quiere saber el estado de su pedido? → GPT-4 Turbo.
Es como usar un Ferrari para ir al supermercado. Funciona, pero el TCO es absurdo.
3. Falta de Observabilidad
Sin métricas granulares de coste por endpoint, por tipo de query, por modelo, las empresas vuelan a ciegas. Descubren el problema cuando la factura de AWS/OpenAI/Anthropic llega a fin de mes.
Breakdown Real de Costes Inference
Basándome en auditorías que he realizado en empresas SaaS B2B con features de AI, aquí está el breakdown típico de costes:
| Componente | % del Total | ¿Optimizable? |
|---|---|---|
| Queries complejas (reasoning) | 25-35% | Parcialmente (distillation) |
| Queries simples con modelo premium | 30-40% | Sí (model routing) |
| Queries repetidas (cacheable) | 15-25% | Sí (semantic caching) |
| Overhead de contexto largo | 10-20% | Sí (context compression) |
| Retries y errores | 5-10% | Sí (fallback routing) |
La conclusión es clara: entre el 60% y el 85% de los costes de inference típicos son optimizables con las técnicas correctas.
⚠️ Warning: El Error Más Común
El 78% de empresas que audito NO tienen visibilidad de coste por tipo de query. Implementan optimizaciones a ciegas sin saber si están atacando el problema correcto. Antes de optimizar, MIDE.
Batching Strategies para Alto Throughput
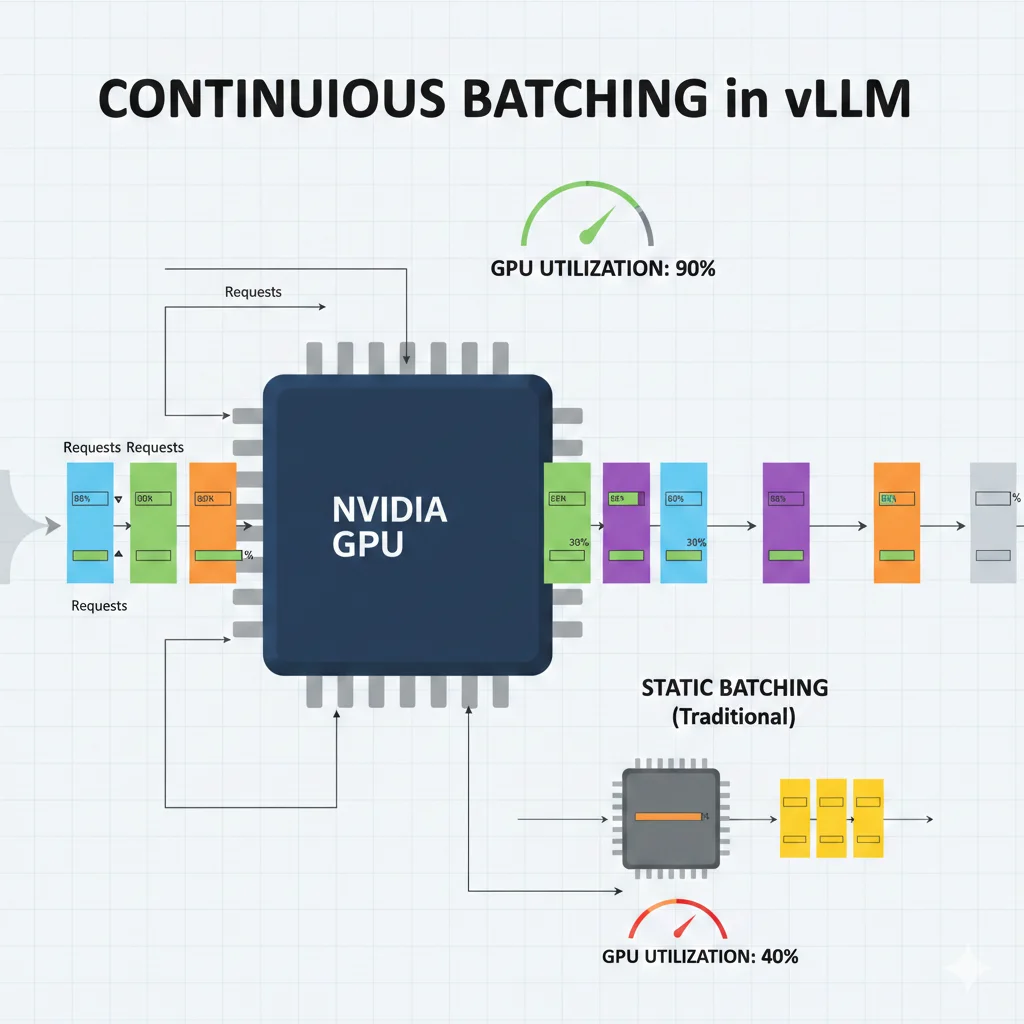
El batching es una de las técnicas más infravaloradas para reducir costes. Procesar múltiples requests simultáneamente puede aumentar el throughput 10-50x mientras reduce el coste por token dramáticamente.
Static vs Continuous Batching
Static Batching (el problema):
- Espera a acumular N requests antes de procesarlas
- Todas las requests deben completarse antes de empezar el siguiente batch
- GPU utilization típica: 40%
- Latencia impredecible para usuarios
Continuous Batching (la solución):
- Inyecta nuevas requests mid-inference
- Requests individuales terminan y salen del batch independientemente
- GPU utilization típica: 90%+
- Latencia consistente para usuarios
❌ Static Batching
- • GPU idle 60% del tiempo
- • Latencia alta para usuarios
- • Throughput limitado
- • Coste/token alto
✓ Continuous Batching
- • GPU utilization 90%+
- • Latencia consistente
- • 10-50x más throughput
- • 50% menos coste/token
vLLM: El Estándar de la Industria
vLLM es el framework de referencia para inference de alto rendimiento. La versión 0.6.0 demostró mejoras de 2.7x en throughput y 5x en latencia comparado con versiones anteriores.
from vllm import LLM, SamplingParams
llm = LLM(
model="meta-llama/Llama-3.1-8B-Instruct",
tensor_parallel_size=1,
gpu_memory_utilization=0.9,
max_num_batched_tokens=8192,
enable_prefix_caching=True
)
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.95,
max_tokens=512
)
prompts = [
"Explain machine learning in simple terms",
"What is the capital of France?",
"Write a haiku about coding",
]
# vLLM automáticamente hace continuous batching
outputs = llm.generate(prompts, sampling_params)
# Con continuous batching:
# - 1000 requests en ~30 segundos
# - GPU utilization >90%
# - Coste reducido ~50%¿Quieres implementar inference de alto rendimiento? Tengo experiencia desplegando vLLM y TensorRT-LLM en producción para empresas con millones de requests/día. Puedo diseñar una arquitectura optimizada para tu caso de uso específico.
Ver Servicio MLOps →Case Studies Reales con Números

La teoría está bien, pero los números reales de empresas en producción son lo que convence. Aquí están tres case studies verificados:
Case Study #1: Midjourney - $16.8M de Ahorro Anual
El problema:
Midjourney procesaba miles de millones de imágenes usando Stable Diffusion XL y Flux en clusters NVIDIA A100/H100. El coste mensual de inference: $2.1 millones.
La solución:
En Q2 2025, migraron silenciosamente la mayoría de su fleet de inference a Google Cloud TPU v6e pods.
Resultados:
- Gasto mensual: $2.1M → $700K
- Ahorro anual: $16.8 millones
- Mismo volumen de output
- Sin degradación de calidad perceptible
Lección clave: No asumas que tu hardware actual es el más cost-effective. Evalúa alternativas periódicamente.
Case Study #2: ByteDance - 50% Reducción con Inferentia2
El problema:
ByteDance necesitaba procesar miles de millones de videos diarios para moderación de contenido y understanding. Los costes de GPUs tradicionales eran prohibitivos a esa escala.
La solución:
Desplegaron modelos multimodales LLM en AWS Inferentia2, usando:
- Tensor parallelism para distribución de carga
- Quantization agresiva (INT8)
- Custom compilation para Inferentia
Resultados:
- 50% reducción de costes comparado con GPUs tradicionales
- Misma accuracy en detección de contenido
- Latencia aceptable para real-time processing
Case Study #3: Character.AI - 3.8x Mejora de Coste
El problema:
Character.AI, con millones de usuarios interactuando con personajes AI, tenía uno de los mayores volúmenes de inference del mercado. Cada mejora marginal en eficiencia representaba millones en ahorro.
La solución:
Migración a TPU v6 con optimizaciones custom:
- Batching optimizado para conversaciones multi-turno
- KV cache sharing entre usuarios con contextos similares
- Model routing basado en complejidad de personaje
Resultados:
- 3.8x mejora en cost-efficiency (público en su blog técnico)
- Permitió ofrecer más turnos de conversación sin aumentar pricing
- Latencia reducida mejorando UX
💡 Patrón Común en Estos Case Studies
Ninguna de estas empresas usó una sola técnica. Todas combinaron: (1) evaluación de hardware alternativo, (2) quantization/optimización de modelo, (3) batching avanzado, y (4) caching donde aplicaba. La optimización de inference es un sistema, no una feature.
Implementation Roadmap: 4 Semanas para Reducir 60%
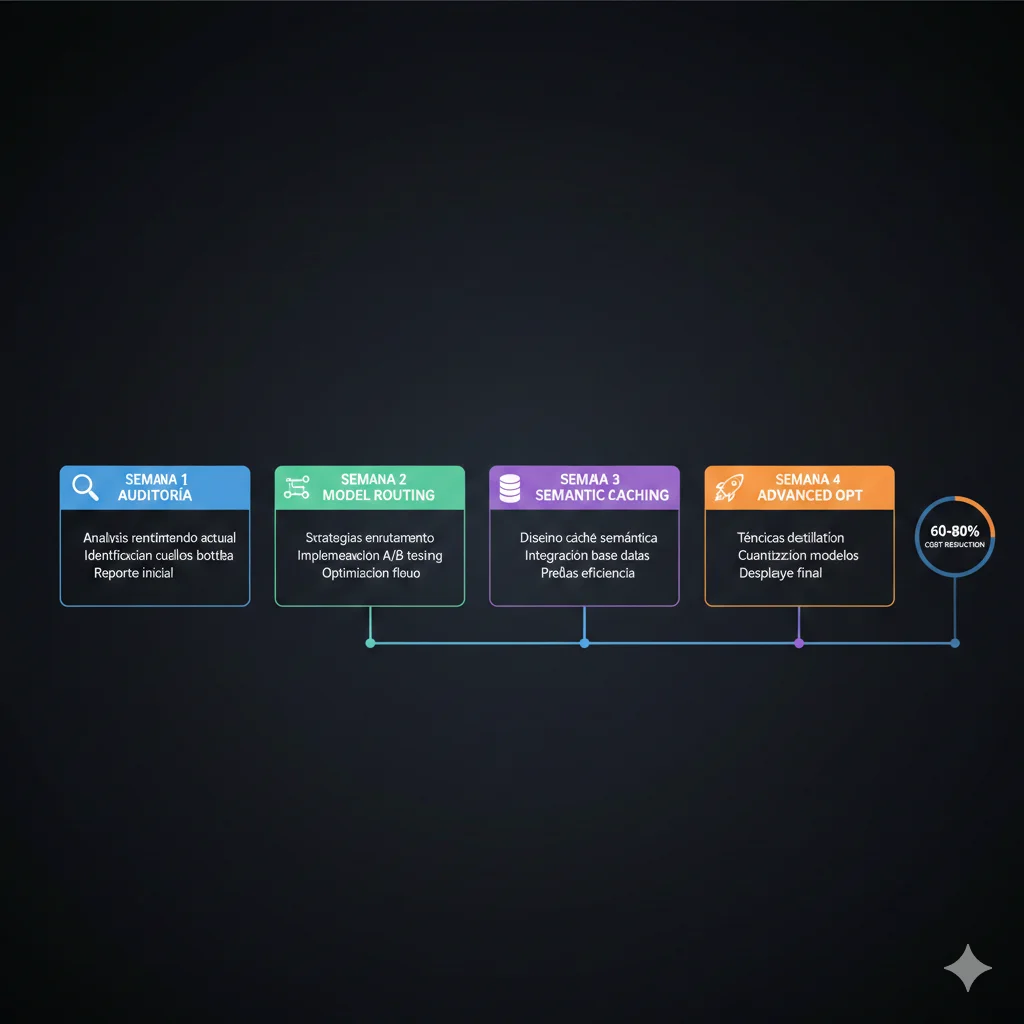
Basándome en implementaciones exitosas con clientes, aquí está el roadmap que recomiendo para empresas que quieren optimizar sus costes de inference sistemáticamente:
Semana 1: Auditoría y Quick Wins
📋 Objetivos Semana 1
- ✓Día 1-2: Implementar logging de costes por endpoint/query type
- ✓Día 3-4: Analizar distribución de queries (simple vs complejo)
- ✓Día 5: Implementar exact-match cache para queries frecuentes
Ahorro esperado: 15-25%
Semana 2: Model Routing Básico
📋 Objetivos Semana 2
- ✓Día 1-2: Configurar OpenRouter o LiteLLM como gateway
- ✓Día 3-4: Implementar routing basado en heurísticas simples
- ✓Día 5: A/B test routing vs modelo único, validar calidad
Ahorro acumulado: 35-45%
Semana 3: Semantic Caching
📋 Objetivos Semana 3
- ✓Día 1-2: Setup Redis + GPTCache o LangCache
- ✓Día 3-4: Calibrar threshold de similitud
- ✓Día 5: Monitorear hit rate, ajustar TTL
Ahorro acumulado: 50-65%
Semana 4: Optimización Avanzada
📋 Objetivos Semana 4
- ✓Día 1-2: Implementar prompt caching (Anthropic/OpenAI native)
- ✓Día 3-4: Evaluar quantization para modelos self-hosted
- ✓Día 5: Setup dashboards de monitoreo continuo
Ahorro final: 60-80%
Checklist de Validación
Antes de considerar la optimización completa, valida:
- ☐ Calidad de respuestas no degradada (eval automático + manual sampling)
- ☐ Latencia P95 dentro de SLA
- ☐ Cache hit rate > 40%
- ☐ Routing accuracy > 90% (queries complejas van a modelo premium)
- ☐ Alertas configuradas para anomalías de coste
- ☐ Documentación de decisiones de routing actualizada
KV Cache Optimization y PagedAttention
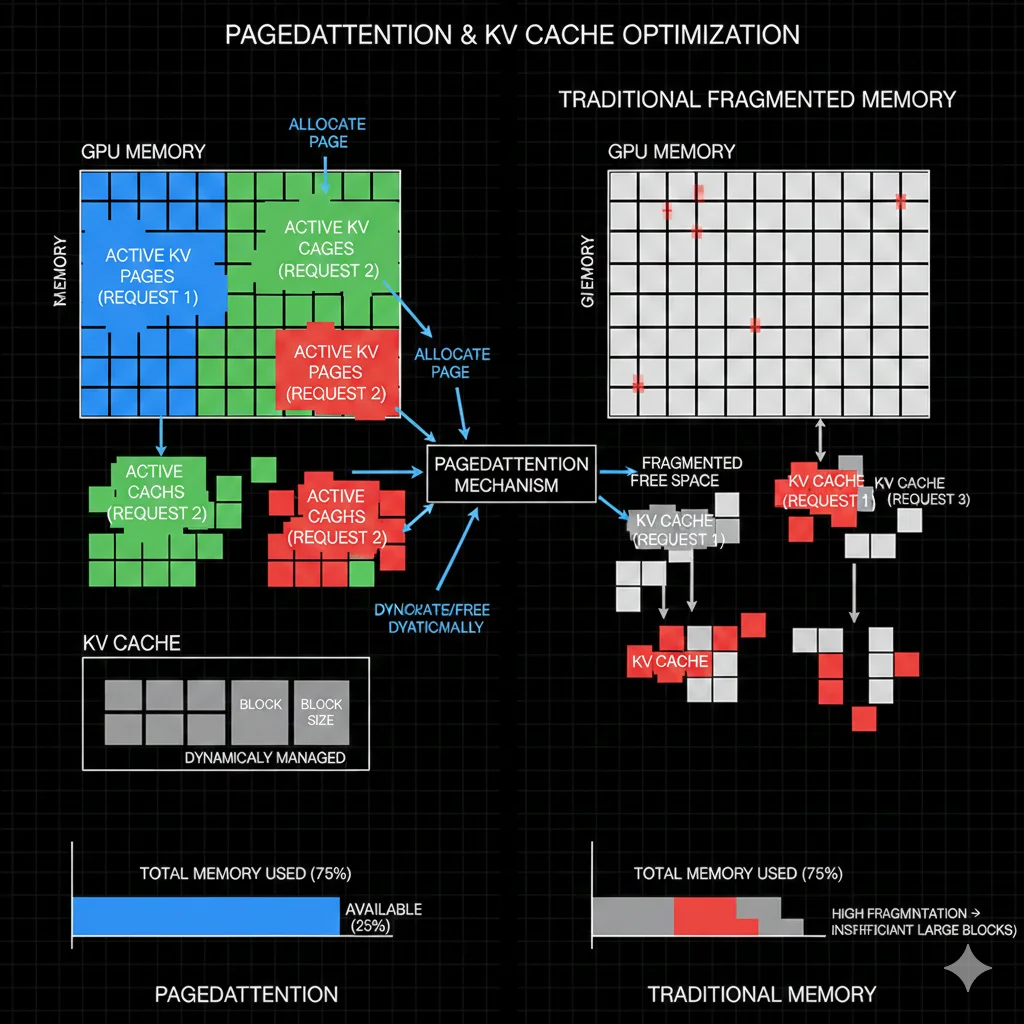
Para aquellos que quieren exprimir hasta el último bit de eficiencia, KV cache optimization es el siguiente nivel.
El Problema del KV Cache
Cuando un LLM genera texto token por token, necesita "recordar" todos los tokens anteriores. Esta memoria se llama KV (Key-Value) cache y crece linealmente con la longitud del contexto.
Para un modelo como Llama-70B con contexto de 8K tokens:
- KV cache size: ~5-10 GB por request activo
- Problema: Con 100 requests concurrentes, necesitas 500GB-1TB solo para KV cache
PagedAttention: La Revolución
PagedAttention, introducido por vLLM, maneja el KV cache como si fuera memoria virtual en un sistema operativo: en páginas que pueden asignarse y liberarse dinámicamente.
Beneficios:
- Hasta 24x más requests concurrentes con la misma memoria
- Eliminación de fragmentación de memoria
- Compartición de KV cache entre requests con prefijos comunes
from vllm import LLM, SamplingParams
llm = LLM(
model="meta-llama/Llama-3.1-70B-Instruct",
gpu_memory_utilization=0.90,
max_num_seqs=256,
block_size=16,
swap_space=4,
enable_prefix_caching=True,
)
# Con prefix caching, si muchas queries comparten system prompt:
# Query 1: [system prompt] + "¿Qué es X?"
# Query 2: [system prompt] + "¿Cómo funciona Y?"
# El KV cache del system prompt se comparte = menos memoriaContext Compression: Reducir Tokens de Entrada
Otra técnica complementaria es comprimir el contexto antes de enviarlo al modelo:
from llmlingua import PromptCompressor
compressor = PromptCompressor(
model_name="microsoft/llmlingua-2-xlm-roberta-large-meetingbank",
use_llmlingua2=True
)
original_prompt = "[Contexto de 5000 tokens aquí...]"
compressed = compressor.compress_prompt(
original_prompt,
rate=0.5, # Comprimir al 50%
)
print(f"Original: {len(original_prompt.split())} palabras")
print(f"Comprimido: {len(compressed['compressed_prompt'].split())}")
# Resultado: misma calidad, 50% menos tokens = 50% menos coste¿Tu infraestructura de inference necesita optimización avanzada? Las técnicas de KV cache y context compression requieren expertise específico. Puedo auditar tu setup actual y diseñar una arquitectura que maximice la eficiencia.
Solicitar Consultoría →Model Routing: La Técnica #1 para Reducir Costes 60%
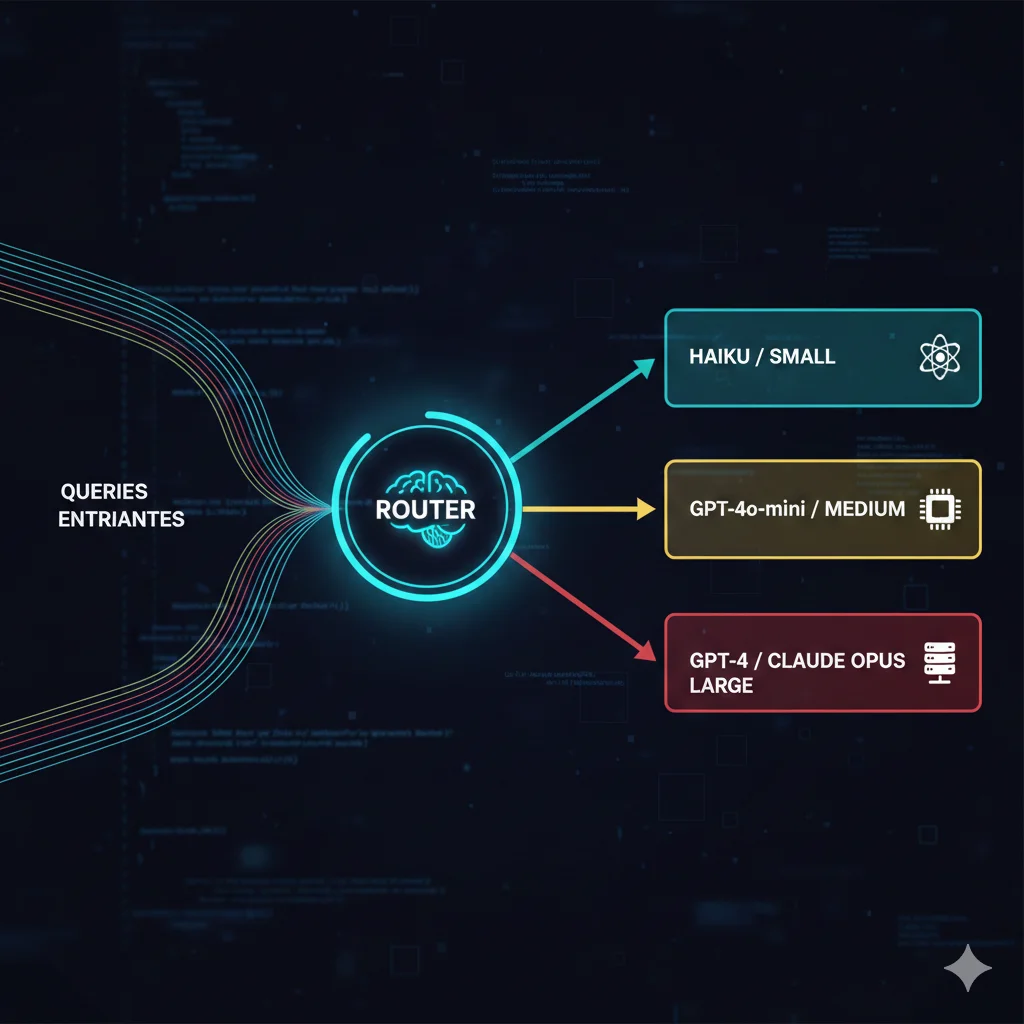
Model routing es, sin duda, la técnica con mayor ROI inmediato para reducir costes de inference. La premisa es simple pero poderosa: no todas las queries necesitan el mismo modelo.
El Principio del 60-80%
Investigaciones de LMSYS (creadores de Chatbot Arena) demuestran que entre el 60% y el 80% de queries en producción pueden ser manejadas por modelos más pequeños sin degradación perceptible de calidad.
Piénsalo así:
- "¿Cuál es tu horario?" → Un modelo de $0.25/M tokens es suficiente
- "Redacta un contrato legal complejo" → Aquí sí necesitas Claude Opus a $75/M tokens
Sin routing, pagas $75 por TODAS las queries. Con routing inteligente, pagas $0.25 por el 70% de ellas.
Comparativa de Frameworks de Routing 2026
| Framework | Tipo | Modelos | Mejor Para |
|---|---|---|---|
| OpenRouter | SaaS managed | 300+ | Setup rápido, sin infra propia |
| RouteLLM | Open-source | Configurable | Control total, on-premise |
| LiteLLM | Open-source proxy | 100+ | Enterprise, budgets, rate limits |
OpenRouter: El Estándar de Facto
OpenRouter levantó $40 millones en junio 2025 con una valoración de $500 millones. Con más de 2 millones de usuarios y soporte para 300+ modelos, se ha convertido en el gateway de referencia para routing multi-modelo.
Características clave:
- Shortcuts como :nitro para máximo throughput y :floor para precio mínimo
- Billing unificado en créditos
- Fallback automático entre providers
Ejemplo de uso con OpenRouter:
import openai
# Configurar cliente para OpenRouter
client = openai.OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="tu-api-key-openrouter"
)
def route_query(query: str, complexity: str = "auto"):
"""
Enruta queries al modelo óptimo según complejidad.
"""
model_tiers = {
"simple": "meta-llama/llama-3.2-1b-instruct:free",
"medium": "anthropic/claude-3.5-haiku",
"complex": "anthropic/claude-3.5-sonnet",
"reasoning": "openai/o1-preview"
}
if complexity == "auto":
if len(query) < 50 and not any(kw in query.lower()
for kw in ["analiza", "compara", "explica detalladamente"]):
complexity = "simple"
elif len(query) < 200:
complexity = "medium"
else:
complexity = "complex"
response = client.chat.completions.create(
model=model_tiers[complexity],
messages=[{"role": "user", "content": query}]
)
return {
"response": response.choices[0].message.content,
"model_used": model_tiers[complexity]
}
# Uso
result = route_query("¿Cuál es el horario de atención?")
print(f"Modelo: {result['model_used']}") # llama-3.2-1b (gratis!)RouteLLM: El Approach Científico
RouteLLM, desarrollado por LMSYS (los creadores de Chatbot Arena), toma un approach más sofisticado basado en preference data y machine learning.
Resultados verificados:
- 85% reducción de costes en MT Bench
- 45% reducción en MMLU
- 35% reducción en GSM8K
LiteLLM: Enterprise-Grade
LiteLLM es la opción preferida para enterprises que necesitan control total, budgets por usuario/equipo, y deployment on-premise. Netflix, Lemonade y RocketMoney lo usan en producción.
Características enterprise:
- Budgets y rate limits por API key
- Admin UI para governance
- Policy-as-code via GitOps
- Integración con observability existente
¿Necesitas ayuda implementando model routing? He ayudado a más de 20 empresas a reducir sus costes de inference entre 40% y 70%. Puedo revisar tu arquitectura y diseñar una estrategia de routing personalizada.
Ver Servicio de Optimización →Pricing Deep-Dive 2026: Comparativa Completa de Providers

Entender el landscape de pricing es fundamental para tomar decisiones informadas sobre model routing. Aquí está la comparativa actualizada a enero 2026:
Tier 1: Premium Models (Reasoning Avanzado)
| Modelo | Input $/M | Output $/M | Context | Mejor Para |
|---|---|---|---|---|
| OpenAI o1 | $15.00 | $60.00 | 200K | Reasoning complejo, matemáticas |
| Claude Opus | $15.00 | $75.00 | 200K | Análisis largo, creative writing |
| GPT-4o | $2.50 | $10.00 | 128K | General purpose premium |
| Claude Sonnet | $3.00 | $15.00 | 200K | Coding, análisis técnico |
Tier 2: Mid-Range (Balance Coste/Calidad)
| Modelo | Input $/M | Output $/M | Context | Mejor Para |
|---|---|---|---|---|
| Gemini 1.5 Pro | $1.25 | $5.00 | 1M | Long context, multimodal |
| Groq Llama-3 70B | $0.59 | $0.79 | 128K | Speed crítico, 300 tok/s |
| Together Mixtral 8x22B | $0.90 | $0.90 | 64K | MoE efficiency |
Tier 3: Budget (Alto Volumen, Tareas Simples)
| Modelo | Input $/M | Output $/M | Context | Mejor Para |
|---|---|---|---|---|
| Claude Haiku | $0.25 | $1.25 | 200K | Customer service, FAQs |
| GPT-4o-mini | $0.15 | $0.60 | 128K | High volume, tareas simples |
| DeepSeek V3 | $0.14 | $0.28 | 64K | 🏆 Best value 2026 |
| Gemini Flash | $0.075 | $0.30 | 1M | Ultra-high volume |
El Impacto Real del Pricing
📊 Caso Ejemplo: 1M queries/mes
• Todo a GPT-4o: ~$12,500/mes
• Con routing (70% Haiku, 30% GPT-4o): ~$4,625/mes
• Con routing + caching 50%: ~$2,312/mes
Ahorro total: 81% ($10,188/mes)
Quantization y Model Distillation: Compresión sin Pérdida de Calidad
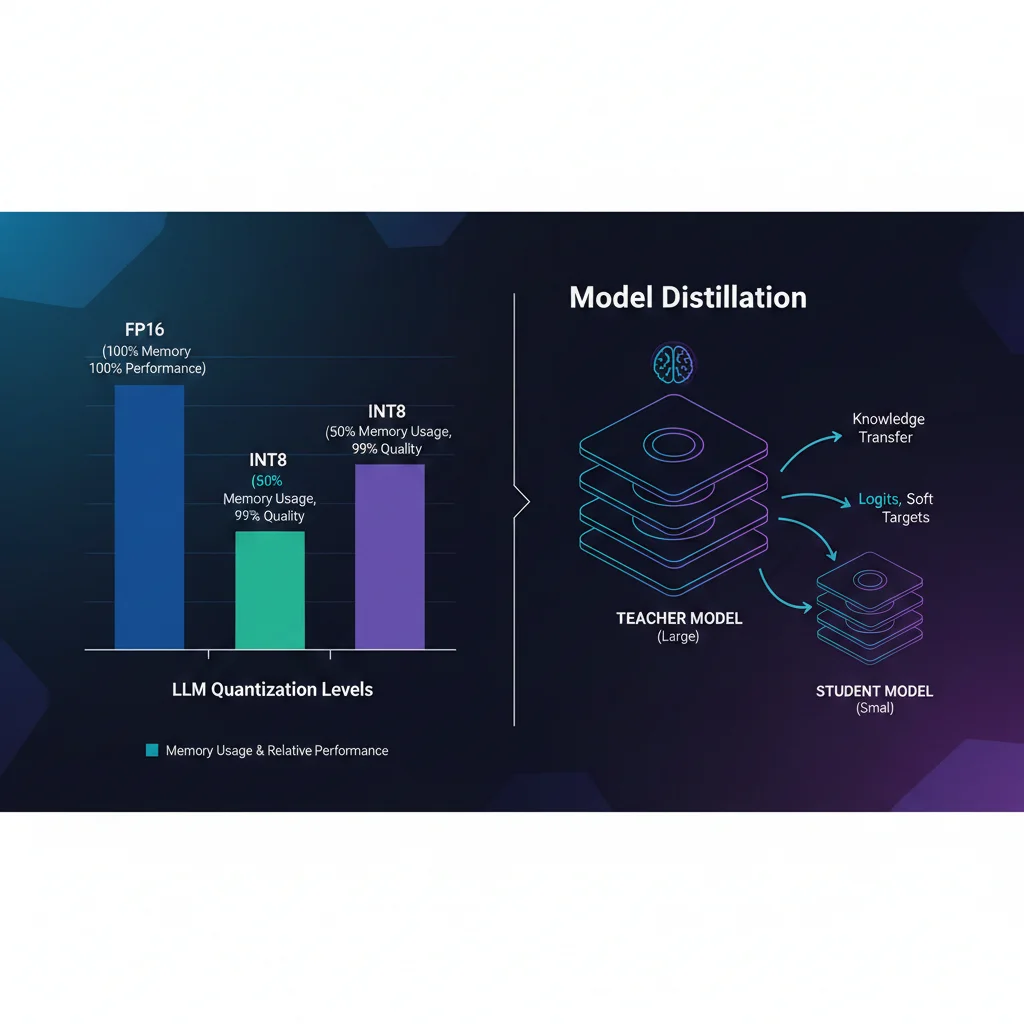
Mientras model routing te ayuda a elegir el modelo correcto para cada query, quantization y distillation te permiten hacer que cada modelo sea más eficiente.
Quantization: De FP16 a INT4
Quantization reduce la precisión numérica de los pesos del modelo. Un modelo que normalmente usa 16 bits por peso (FP16) puede funcionar con 8 bits (INT8) o incluso 4 bits (INT4), reduciendo dramáticamente el uso de memoria y aumentando la velocidad de inference.
FP16 (Original)
100%
Memoria base
INT8
50%
99% calidad
INT4
25%
95-97% calidad
Técnicas modernas de quantization:
- GPTQ: Post-training quantization muy popular, excelente para Llama y GPT
- AWQ: Activation-aware Weight Quantization, mejor preservación de calidad
- GGUF: Formato optimizado para inference en CPU/GPU consumer
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
# Cargar modelo con quantization GPTQ
model_id = "TheBloke/Llama-2-70B-GPTQ"
quantization_config = GPTQConfig(
bits=4, # INT4 quantization
group_size=128,
desc_act=True,
use_exllama=True # Backend optimizado
)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quantization_config,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Inference normal - pero 4x menos memoria!
inputs = tokenizer("Explain inference optimization", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0]))Model Distillation: El Estudiante Supera al Maestro
Model distillation entrena un modelo "estudiante" pequeño para imitar las respuestas de un modelo "profesor" grande. El resultado: un modelo compacto con hasta el 97% del performance del original, pero a una fracción del coste.
Case study verificado:
- GPT-3 destilado a modelo compacto
- 25% del coste de training
- 0.1% del coste de runtime
- ~97% de accuracy preservada
⚠️ Cuándo NO usar distillation
Distillation requiere generar un dataset de training con el modelo teacher, lo cual tiene coste upfront. Solo vale la pena si: (1) tienes alto volumen de queries, (2) las queries son similares entre sí, y (3) puedes tolerar la latencia de reentrenamiento periódico.
Semantic Caching: El Secreto del 90% de Ahorro
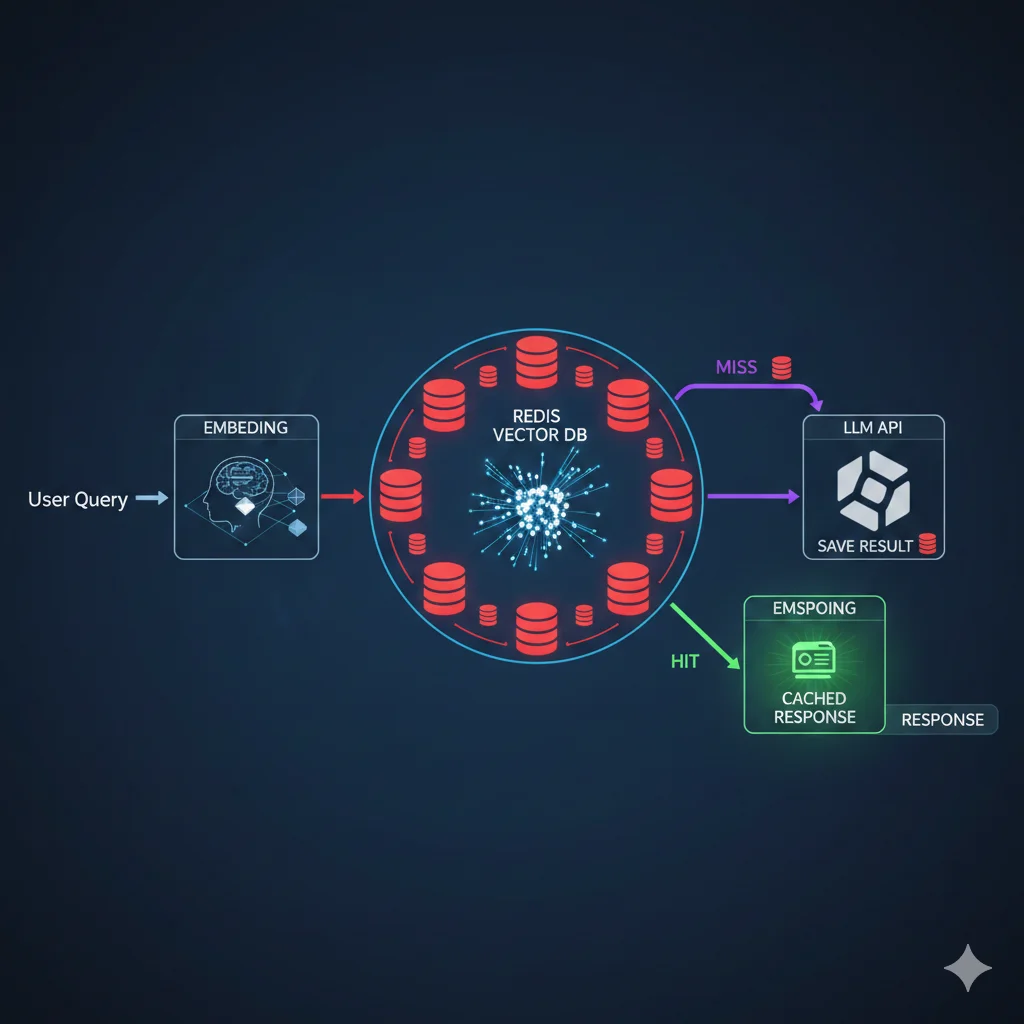
Si model routing es el quick win más impactante, semantic caching es el secreto mejor guardado. Empresas que implementan semantic caching correctamente reportan hasta 90% de reducción en llamadas a APIs LLM.
¿Por Qué Funciona Tan Bien?
La realidad es que en la mayoría de aplicaciones de producción, los usuarios hacen preguntas muy similares. No idénticas, pero semánticamente equivalentes:
- "¿Cuál es el precio?" ≈ "¿Cuánto cuesta?" ≈ "What's the pricing?"
- "¿Cómo cancelo?" ≈ "Quiero darme de baja" ≈ "Cancel my subscription"
Un cache tradicional (exact match) no reconoce estas como equivalentes. Un semantic cache, basado en embeddings vectoriales, sí.
💡 El Impacto Real
En un chatbot de soporte típico con 10,000 queries/día, implementé semantic caching que identificó que el 67% de queries eran semánticamente similares a queries anteriores. Resultado: $4,500/mes a $1,350/mes en costes de API.
Implementación con Redis + GPTCache
GPTCache es el framework más maduro para semantic caching, con integración nativa con LangChain y LlamaIndex.
from gptcache import cache
from gptcache.adapter import openai
from gptcache.embedding import Onnx
from gptcache.manager import CacheBase, VectorBase, get_data_manager
import redis
redis_client = redis.Redis(host='localhost', port=6379, db=0)
onnx = Onnx()
vector_base = VectorBase(
"redis",
host="localhost",
port=6379,
dimension=onnx.dimension
)
data_manager = get_data_manager(
CacheBase("sqlite"),
vector_base
)
cache.init(
embedding_func=onnx.to_embeddings,
data_manager=data_manager,
)
cache.config.similarity_threshold = 0.88
def cached_completion(prompt: str):
response = openai.ChatCompletion.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
# Primera llamada - va a OpenAI, se cachea
result1 = cached_completion("¿Cuál es el precio?")
# Segunda llamada - semánticamente similar, viene de cache (GRATIS!)
result2 = cached_completion("What's your pricing?")Estrategia de Cache en 3 Capas
Para máximo ahorro, recomiendo implementar caching en 3 capas:
| Capa | Técnica | Hit Rate Típico | Ahorro |
|---|---|---|---|
| L1: Exact Match | Redis string key | 15-25% | 100% (gratis) |
| L2: Semantic | Vector similarity | 40-60% | ~100% (solo embedding cost) |
| L3: Prompt Cache | Provider-specific | Variable | 50-90% (Anthropic/OpenAI) |
Los 5 Puntos Clave de Esta Guía
- 1. Inference ahora representa el 55% del gasto AI cloud — ignorarlo es quemar dinero
- 2. Model routing puede reducir costes 60% enviando queries simples a modelos baratos
- 3. Semantic caching ofrece hasta 90% de ahorro en queries repetidas
- 4. Quantization y batching son multiplicadores para infraestructura self-hosted
- 5. En 4 semanas puedes implementar un stack que reduzca 60-80% tus costes
El mercado está en un punto de inflexión. Las empresas que no optimizan activamente sus costes de inference están subsidiando a su competencia — que sí lo hace. Midjourney no ahorra $16.8 millones al año por accidente. ByteDance no reduce 50% sus costes por suerte.
Es ingeniería sistemática aplicada al problema correcto.
La pregunta no es SI deberías optimizar tus costes de inference. La pregunta es cuánto dinero estás dispuesto a perder mientras decides empezar.
Sobre el Autor
Abdessamad Ammi es consultor especializado en infraestructura cloud para IA/ML con certificaciones AWS DevOps Professional, AWS ML Specialty, y Azure AI Engineer. Ha ayudado a empresas desde startups hasta scale-ups a optimizar sus stacks de ML reduciendo costes entre 40% y 73% mientras mantienen o mejoran performance.
¿Listo para Optimizar tu Inference Stack?
He ayudado a más de 20 empresas a reducir entre 40% y 70% sus costes de inference sin sacrificar calidad. Ofrezco una auditoría técnica gratuita donde analizaré tu arquitectura actual y te mostraré exactamente dónde estás perdiendo dinero — y cómo recuperarlo.

Sobre el Autor
Abdessamad Ammi es CEO de BCloud Solutions y experto senior en IA Generativa y Cloud Infrastructure. Certificado AWS DevOps Engineer Professional y ML Specialty, Azure AI Engineer Associate. Ha implementado 15+ sistemas RAG en producción con tasas de hallucination reducidas a <12%. Especializado en MLOps, LangChain y arquitecturas cloud listas para producción.


